Fast 128-bit LFSR (MMX required)
Random numbers - the dark horse of providing security mechanisms in a digital environment. Undeservedly remaining in the shadow of cryptographic primitives, they are at the same time a key element for generating session keys, they are used in Monte Carlo numerical methods, in simulation modeling, and even to test theories of cyclone formation!
Moreover, the quality of the resulting sequence depends on the quality of implementation of the pseudo-random number generator itself. As the saying goes: "random number generation is too important to leave it to chance."

There are many options for implementing a pseudorandom number generator: Yarrow, using traditional crypto primitives, such as AES-256, SHA-1, MD5; Microsoft CryptoAPI exotic Chaos and PRAND and others.
But the purpose of this note is different. Here I want to consider a feature of the practical implementation of one very popular pseudo-random number generator, which is widely used, for example, in the Unix environment in the / dev / random pseudo-device, as well as in electronics and when creating stream ciphers. It will be about LFSR (Linear Feedback Shift Register) .
The fact is that there is an opinion that in the case of using dense polynomials, the states of the LFSR register are very slowly calculated. But as I see it, often the problem is not in the algorithm itself (although it is certainly not ideal), but in its implementation.
Literally, LFSR is a linear feedback shift register, consisting of two parts - a shift register and a feedback function. The register consists of bits, its length is the number of these bits.
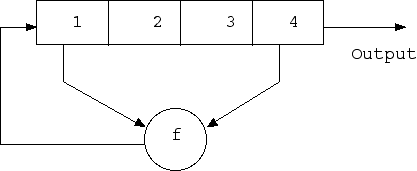
When a bit is retrieved, all bits of the register are shifted to the right by one position. In this case, the new leftmost bit is determined by the function of the remaining bits before extraction. The least significant bit appears at the output of the register.
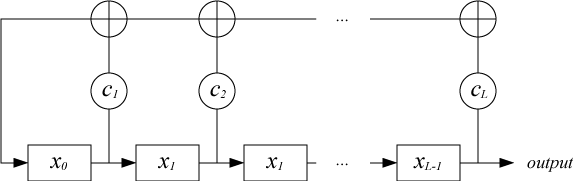
It is not difficult to determine the properties of the generated sequence are closely related to the properties of the associated polynomial: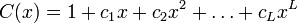
Moreover, its nonzero coefficients are called taps, on the basis of which the input values for the feedback function are determined.
Recommended tap indices depending on the bit field length of the LFSR register are well presented in the document “Effective Shift Registers, LFSR Counters, and Long PseudoRandom Sequence Generators . "
So, the implementation of LFSR is quite simple, but it is believed that due to the use of many bit operations to compute dense polynomials, such as XOR, the speed often leaves much to be desired, i.e. he needs some time to “warm up”. As an alternative, a LFSR modification with a Galois scheme was even proposed, a cycle of a fixed number of calls to the LFSR function in which it runs approximately two times faster.
Honestly, I can’t agree with that. As I see, often the problem is not in the algorithm itself, but in its implementation. Usually we see a construction of the following type:
It’s cruel. Here, at a minimum, we can get rid of a few XORs and shifts by using the value of the parity flag PF (Parity Flag) of the flag register. Indeed, modulo 2 (XOR) additions determine the parity of the number of bits set. The only parity flag PF is set if the least significant byte of the result contains an even number of unit (non-zero) bits, i.e. we’ll have to make at least one arithmetic shift:
In the case of using dense polynomials, when the taps are distributed throughout the bit field of a 32-bit register, then we will already receive 4 shift operations and 3 XOR operations:
Отступление: в случае, когда кол-во сдвигов sar ebx,08h четное либо равно нулю, перед исполнением XOR необходимо инвертировать значение регистра AH, поскольку PF установлен когда кол-во ненулевых битов четное. А нам нужно наоборот.
Что всё же несколько кошернее чем:
Следующий шаг — использование регистра для аккумуляции результатов, вместо непосредственного сброса в память на каждом состоянии LFSR:
and so on up to 32 states (edx DWORD), only after which we write to memory.
And finally, in case we really need to implement a fast 128-bit LFSR (suddenly), we can use MMX registers, which will allow us to implement a shift on a 32-bit processor of the Pentium family without the need for memory access (only by means of registers).
Source code
Source code in assembly language (x86): pastebin.com/rwKfsYsN
Compiled executable code: www.sendspace.com/file/atg0cf
Update:
Optimized version of the code: pastebin.com/B3kPEaew
Compiled executable code: www.sendspace.com/ file / 9bl5di
Finally, about the speed of work - “warming up” a 128-bit LFSR by changing 2 097 120 (0FFFFh x 32) states using MMX and the coffee register flag with coffee break (display on the screen) took about 5 seconds on my PC. At the same time, the execution of the program in C ++, written by analogy with the above, but for the 128-bit version and also with the output to the screen, took about 2-3 minutes.
At the same time, the main cimesis is that in the Parity Flag use case, the polynomial density does not have a strong influence on the rate of calculation of the inverse function for the new state of the LFSR register. And accordingly, statements in the style of:“One of the main problems of RSLOS is that their software implementation is extremely inefficient. You have to avoid sparse feedback polynomials since they lead to easier cracking by correlation breaking. And the dense polynomials are very slowly calculated ”(from here: wikipedia.org/wiki/LFSR ) are somewhat ... untenable and need to be clarified :)
ps And this is interesting, is it possible to make the implementation of the program in a high-level language, without assembly language, time which, when enumerating 2 097 120 (0FFFFh x 32) states for a 128-bit LFSR, would take ... for example, less than 0.5 seconds?
Moreover, the quality of the resulting sequence depends on the quality of implementation of the pseudo-random number generator itself. As the saying goes: "random number generation is too important to leave it to chance."
There are many options for implementing a pseudorandom number generator: Yarrow, using traditional crypto primitives, such as AES-256, SHA-1, MD5; Microsoft CryptoAPI exotic Chaos and PRAND and others.
But the purpose of this note is different. Here I want to consider a feature of the practical implementation of one very popular pseudo-random number generator, which is widely used, for example, in the Unix environment in the / dev / random pseudo-device, as well as in electronics and when creating stream ciphers. It will be about LFSR (Linear Feedback Shift Register) .
The fact is that there is an opinion that in the case of using dense polynomials, the states of the LFSR register are very slowly calculated. But as I see it, often the problem is not in the algorithm itself (although it is certainly not ideal), but in its implementation.
A bit about LFSR
Literally, LFSR is a linear feedback shift register, consisting of two parts - a shift register and a feedback function. The register consists of bits, its length is the number of these bits.
When a bit is retrieved, all bits of the register are shifted to the right by one position. In this case, the new leftmost bit is determined by the function of the remaining bits before extraction. The least significant bit appears at the output of the register.
It is not difficult to determine the properties of the generated sequence are closely related to the properties of the associated polynomial:
Moreover, its nonzero coefficients are called taps, on the basis of which the input values for the feedback function are determined.
Recommended tap indices depending on the bit field length of the LFSR register are well presented in the document “Effective Shift Registers, LFSR Counters, and Long PseudoRandom Sequence Generators . "
Practical implementation
So, the implementation of LFSR is quite simple, but it is believed that due to the use of many bit operations to compute dense polynomials, such as XOR, the speed often leaves much to be desired, i.e. he needs some time to “warm up”. As an alternative, a LFSR modification with a Galois scheme was even proposed, a cycle of a fixed number of calls to the LFSR function in which it runs approximately two times faster.
Honestly, I can’t agree with that. As I see, often the problem is not in the algorithm itself, but in its implementation. Usually we see a construction of the following type:
int LFSR (void)
{
static unsigned long S = 0xFFFFFFFF;
/* taps: 32 31 30 28 26 1; charact. polynomial: x^32 + x^31 + x^30 + x^28 + x^26 + x^1 + 1 */
S = ((( (S>>0)^(S>>1)^(S>>2)^(S>>4)^(S>>6)^(S>>31) ) & 1 ) << 31 ) | (S>>1);
return S & 1;
}It’s cruel. Here, at a minimum, we can get rid of a few XORs and shifts by using the value of the parity flag PF (Parity Flag) of the flag register. Indeed, modulo 2 (XOR) additions determine the parity of the number of bits set. The only parity flag PF is set if the least significant byte of the result contains an even number of unit (non-zero) bits, i.e. we’ll have to make at least one arithmetic shift:
xor ecx,ecx
mov ebx,0FFFFFFFFh ; S
mov eax,080000057h ; taps (32,31,30,28,26,1)
and ebx,eax
mov cl,ah
sar ebx,018h
lahf
xor cl,ah
sar cl,02h
and cl,01hIn the case of using dense polynomials, when the taps are distributed throughout the bit field of a 32-bit register, then we will already receive 4 shift operations and 3 XOR operations:
xor ecx,ecx
mov ebx,0FFFFFFFFh ; S
mov eax,095324C57h ; taps (32,31,30,28,26,22,21,18,15,12,11,8,6,4,1)
and ebx,eax
lahf
mov cl,ah ; [0-7] bits
sar ebx,08h
lahf
xor cl,ah ; [8-15] bits
sar ebx,08h
lahf
xor cl,ah ; [16-23] bits
sar ebx,08h
lahf
xor cl,ah ; [24-31] bits
sar cl,02h
and cl,01hОтступление: в случае, когда кол-во сдвигов sar ebx,08h четное либо равно нулю, перед исполнением XOR необходимо инвертировать значение регистра AH, поскольку PF установлен когда кол-во ненулевых битов четное. А нам нужно наоборот.
Что всё же несколько кошернее чем:
int LFSR (void)
{
static unsigned long S = 0xFFFFFFFF;
S = ((( (S>>0)^(S>>1)^(S>>2)^(S>>4)^(S>>6)^(S>>10)^(S>>11)^
(S>>14)^(S>>17)^(S>>20)^(S>>21)^(S>>24)^(S>>26)^
(S>>28)^(S>>31) ) & 1 ) << 31 ) | (S>>1);
return S & 1;
}Следующий шаг — использование регистра для аккумуляции результатов, вместо непосредственного сброса в память на каждом состоянии LFSR:
sal edx,01h
or dl,cland so on up to 32 states (edx DWORD), only after which we write to memory.
And finally, in case we really need to implement a fast 128-bit LFSR (suddenly), we can use MMX registers, which will allow us to implement a shift on a 32-bit processor of the Pentium family without the need for memory access (only by means of registers).
Source code
Source code in assembly language (x86): pastebin.com/rwKfsYsN
Compiled executable code: www.sendspace.com/file/atg0cf
Update:
Optimized version of the code: pastebin.com/B3kPEaew
Compiled executable code: www.sendspace.com/ file / 9bl5di
- 128-bit LFSR
- used MMX registers
- x86 architecture
- change 2097120 (0FFFFh x 32) the status of the register LFSR
Eventually
Finally, about the speed of work - “warming up” a 128-bit LFSR by changing 2 097 120 (0FFFFh x 32) states using MMX and the coffee register flag with coffee break (display on the screen) took about 5 seconds on my PC. At the same time, the execution of the program in C ++, written by analogy with the above, but for the 128-bit version and also with the output to the screen, took about 2-3 minutes.
At the same time, the main cimesis is that in the Parity Flag use case, the polynomial density does not have a strong influence on the rate of calculation of the inverse function for the new state of the LFSR register. And accordingly, statements in the style of:“One of the main problems of RSLOS is that their software implementation is extremely inefficient. You have to avoid sparse feedback polynomials since they lead to easier cracking by correlation breaking. And the dense polynomials are very slowly calculated ”(from here: wikipedia.org/wiki/LFSR ) are somewhat ... untenable and need to be clarified :)
ps And this is interesting, is it possible to make the implementation of the program in a high-level language, without assembly language, time which, when enumerating 2 097 120 (0FFFFh x 32) states for a 128-bit LFSR, would take ... for example, less than 0.5 seconds?