State Duma Launches Open Bill Search API
 This article is the second of a series of articles on innovations on the website of the State Duma ( article 1 ).
This article is the second of a series of articles on innovations on the website of the State Duma ( article 1 ). Currently, the concept of open government is gaining popularity . For example, the site data.gov published large volumes of data, the US government agencies, and online data.gov.uk published UK similar materials. An important aspect of publishing structured information is the ability to receive it in a machine-readable form. It is clear that the HTML table can also be successfully parsed, but providing information in a form convenient for integration with external systems is a very important indicator of openness. Therefore, developing an API for a bill search systembecame an important stage in the implementation of the concept of "open state" in the framework of the website of the State Duma . Now data on bills can be easily integrated into external information systems. For example, an analytical portal may, next to an article on a particular bill, place a widget that will reflect current information on the progress of the bill.
API features
The provided API implements, in fact, a search for bills, taking into account many parameters. In addition, it provides access to all kinds of directories and viewing transcripts for each bill. A list of queries and their parameters can be found in the documentation .
Let's look at a few examples of search queries processed by the API:
- Rejected bills proposed by the deputy of the State Duma Zhirinovsky V.V .;
- The Bill on Police and amendments to it;
- Bills introduced by the president of the Russian Federation, currently awaiting consideration by committees of the State Duma.
You can see the search results for these queries here , and the source code for PHP in the documentation .
Interaction with the API is carried out in accordance with the REST architecture style, that is, the HTTP protocol is used, the response is issued in XML, JSON (including JSONP) and RSS formats. A wide range of supported formats allows you to apply the API in various situations. It can be accessed directly from the JavaScript browser. You can send requests from the server side of the application or even from a thick client. And you can subscribe to a specific search query via RSS, and directly follow the latest information.
Statistics
Since the introduction of the new website of the State Duma, more than 70 thousand people have used the bill search system. With the introduction of the API, the search promises to become even more popular, so it was important that it not only work, but also work quickly. Before direct optimization, statistics were collected on what queries users make in the existing search form for bills.
First, the frequency of using search parameters was analyzed (the sum of percent more than 100, because several parameters can be used in one request).
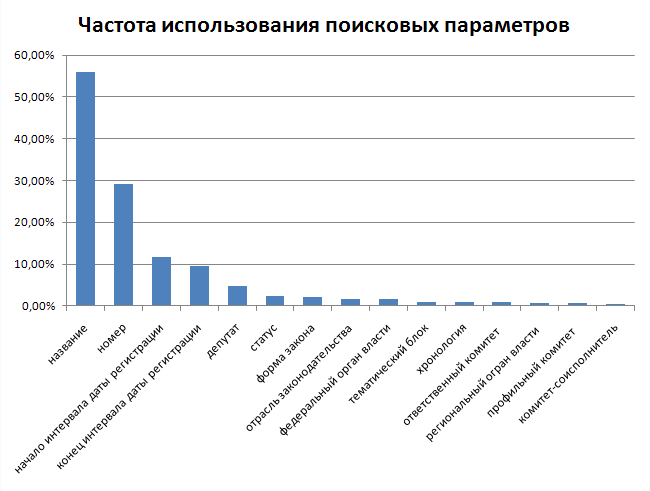
As you can see, the distribution is very uneven, you can immediately see by what parameters you need to index the data in the first place. Of course, after the publication of the API, the distribution of requests may turn out to be somewhat different than that of the search form for bills on the site, but a good guideline was obtained.
Now let's see how users use pagination.
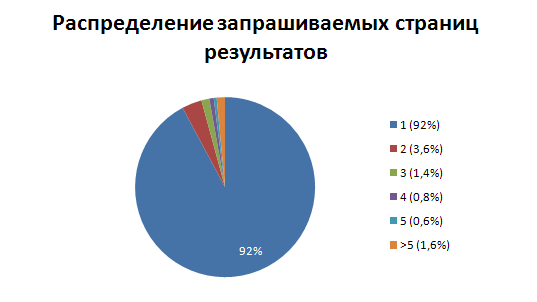
The graph well reflects the fact that users rarely scroll through the results far: more than 97% of requests fall on the first 3 pages. Thus, it was possible to neglect the optimization of the output of pages with a large number.
Next, the distribution of queries by sort type was considered.

As you can see, few people change the default sorting, so this sorting should be displayed first by index.
One way to optimize performance is to cache search query results. In order for caching to make sense, requests must be repeated often enough. How the number of queries with the same search parameters was distributed can be seen in the graph below.

You can see that requests are repeated often enough, so caching is justified.
And at the end of statistics, TOP-10 search queries.

One of the hottest topics at the time of collecting statistics was the law on education.
Optimization
Along with the development of the API, there was also the task of transferring the Draft Law database from Oracle to PostgreSQL (data was imported using ora2pg). The following optimization methods were applied.
PostgreSQL's built-in full-text search using GIN indexes is used.
Indexes were constructed for those fields for which sorting is available, and for those for which filtering is most often carried out.
Previously, when using the Oracle DBMS, for page-by-page navigation, a restriction was imposed on the virtual rownum column, which reflects the row number in the selection. Those. if you need to show, for example, the first 20 rows returned by some query, the following construction was used.
SELECT x. * FROM (main_query) x WHERE rownum <= 20
This was, in general, not the most correct way, but in the version used (Oracle 9i) it worked fine. And when it was necessary to show, for example, 20 lines starting from 100, the following construction was applied. In it, the internal query selects the first 120 rows, and the external leaves only the last 20 of them.
SELECT
*
FROM (
SELECT
rownum AS xrownum,
x. *
FROM
(main_query) x
WHERE
rownum <= 120)
WHERE
xrownum> 100;
With the transition to PostgreSQL, the LIMIT and OFFSET constructs began to be applied. In addition, for optimization purposes, the LIMIT and OFFSET constructs were located as deep as possible in table joins. Consider an example. Let tables a and b be combined , sorting by field with index. Then if you apply LIMIT and OFFSET to the whole query, you get the following query plan.
SELECT
*
FROM
b
Join
a
ON
b.a_id = a.id
ORDER BY
b.value
b.id
LIMIT 20
OFFSET 100;
QUERY PLAN
-------------------------------------------------- ----------------------------------------------
Limit (cost = 52.30..62.76 rows = 20 width = 39)
-> Nested Loop (cost = 0.00..522980.13 rows = 1,000,000 width = 39)
-> Index Scan using b_value_id_idx on b (cost = 0.00..242736.13 rows = 1,000,000 width = 27)
-> Index Scan using a_pkey on a (cost = 0.00..0.27 rows = 1 width = 12)
Index Cond: (a.id = b.a_id)
Those. it passes through the index b_value_id_idx, and for each found record of table b , the records of table a are joined by the index a_pkey . The first 100 records found in this way are skipped and the next 20 are taken. Now let's see what happens if we apply LIMIT and OFFSET exclusively to table b . You can read more about the organization of page navigation here .
SELECT
*
FROM
(
SELECT
*
FROM
b
ORDER BY
b.value
b.id
LIMIT 20
OFFSET 100
) b
Join
a
ON
b.a_id = a.id;
QUERY PLAN
-------------------------------------------------- -------------------------------------------------- -
Hash Join (cost = 29.44..49.39 rows = 20 width = 60)
Hash Cond: (a.id = public.b.a_id)
-> Seq Scan on a (cost = 0.00..16.00 rows = 1000 width = 12)
-> Hash (cost = 29.19..29.19 rows = 20 width = 48)
-> Limit (cost = 24.16..28.99 rows = 20 width = 27)
-> Index Scan using b_value_id_idx on b (cost = 0.00..241620.14 rows = 1,000,000 width = 27)
As you can see, now the connection to table a is already after selecting only the necessary rows of table b , thereby saving. And if in this way not 2, but, say, 10 tables are joined, then the effect can be very significant. In principle, the glider has all the necessary information to carry out such an optimization itself, given that the field b.a_id is not null, and the field a.id is the primary key. But he does not know how to do it, perhaps the situation will change in future versions. So you can make it a rule to place LIMIT and OFFSET as "deeper" as possible, in any case it will not get worse.
Caching query results is organized using memcached. Each search for bills is characterized by:
- a set of superimposed filters,
- sorting method
- page number displayed.
Two types of cache were provided:
- The key is a set of superimposed filters, and the value is the number of satisfying results.
- The key is the set of filters applied, the sorting method and page number (i.e. all search parameters), and the value is the id of the bills found.
Thus, the data is compactly stored in the cache, thereby increasing the number of cached requests, although the cost of processing them increases since part of the data is loaded from the main database.
Database optimization allowed to reduce the processing time of a test sample of 65 thousand search queries from 10 hours to 15 minutes.
Total
Thanks to the work done, everything that could be done before through the search form for bills on the site can now be done programmatically and used in a variety of situations. We hope that our efforts were not in vain, and the developed API will become a useful and popular service.
As an example, we decided to develop a mobile application called “Search by Bills”, which will use all the features that are available in the API, as well as the functions of subscribing to search queries with the receipt of notifications of new bills. Soon we will publish it.
