ThunderX2 rating from Cavium: the dream of the Arm server came true (part 1, introduction)
- Transfer
Less than two years ago, we investigated the first Arm SoC server, which theoretically could compete with Intel's Xeon E5s - Cavium ThunderX. The SoC server demonstrated everything that was stated, however, due to the low single-threaded performance and difficulties in optimizing the energy characteristics, the 48-core SoC was classified as a niche market. As a result, the first Cavium SoC server could not compete with Intel's Xeon.

But Cavium did not give up for obvious reasons: at the moment the server market has become more attractive than ever. The data centers of the world giant Intel bring in revenue of about $ 20 billion (!) Per year. Moreover, profitability is 50%. In terms of profit and money turnover, the server market is many times greater than any other equipment market. So, after starting ThunderX, Cavium promised to release a second iteration: improved power management, improved single-threaded performance, and even more cores (54).
What is playing into the hands of Cavium is that if a user needs a server, he can simply take a streamlined and reliable Intel machine. After all, the loud promises from Arm, Calxeda, Broadcom, AppliedMicro over the past 5 years have remained promises, causing a serious wave of skepticism and distrust and the emergence of new SoCs Arm Server.
Nevertheless, the creation of an outsider Cavium deserves attention. A number of changes were made, and not just the addition of the number “2” to the title: Cavium bought the Vulcan design from Avago. Vulcan is a rather ambitious processor design, originally developed by the Arm server SoC Broadcom team, and has a much larger legacy than the original ThunderX. Plus, based on the experience with ThunderX, Cavium was able to implement some micro-architectural improvements to the Vulcan design, improving its performance and power.
As a result, ThunderX2 "turned out" a more thoughtful core than the previous generation. The ThunderX kernel had a very short pipeline and could hardly withstand two instructions per clock, however the Vulcan core was designed for fetching 8s and executing up to 4 instructions per clock. And even more: all 4 threads (SMT4) can be active at the same time, ensuring constant back-end loading. The new ThunderX2 SoC32 hosts 32 such cores with frequencies up to 2.5 GHz.
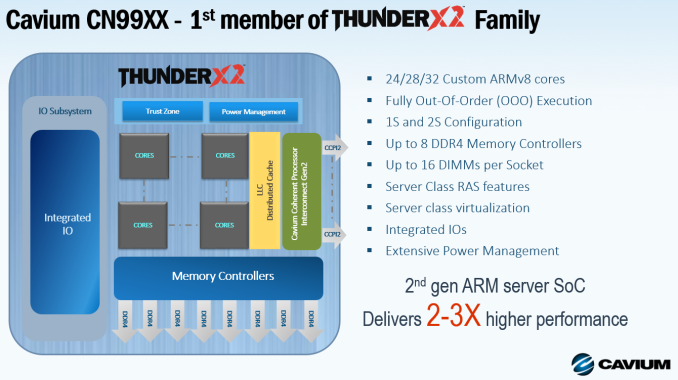
When using up to 128 threads and at least eight DDR4 controllers, this CPU should show itself well in all server loads. In other words, unlike ThunderX (1), ThunderX2 is the first processor of the Arm server and has every chance to shake the balance in the server market.
Thirty-two high IPC cores in the same package seem promising. But what does the new ThunderX2 look like in comparison with AMD, Qualcomm and Intel products? In the table below we compare the specifications of several top server SKUs.
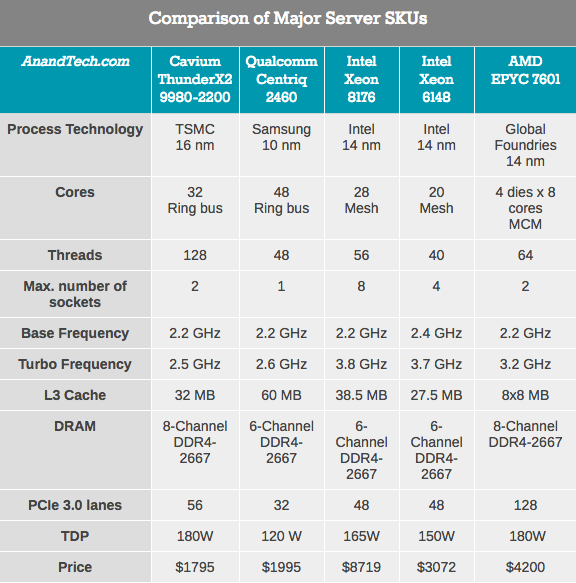
Knowledgeable readers will immediately notice that the top of the Intel processor line is the Xeon Platinum 8180. However, this SKU with a 205 W TDP and priced above $ 10,000 is not comparable to any processor in the list at all. We have almost crossed the line of reason, including 8176, which, it seems to us, falls into this list in terms of the parameters of the maximum SKU of the core / thread blocks. In fact, Cavium positions the Cavium 9980 as “comparable” to the Xeon Platinum 8164 (while Intel has 8176), but with slightly lower frequencies.
However, in terms of performance per dollar, Cavium compares its flagship 9980 with Intel Xeon Gold 6148, and in this case, the price of the Cavium processor looks quite appetizing. According to the test results, the fastest ThunderX2 is 30-40% ahead of the Xeon 6148, while the offer from Cavium is 1300 dollars cheaper. Such aggressive pricing explains the rumors that Qualcomm is not going to enter the server market.
The data in the table above demonstrate the important differences between the rivals. It seems that Intel has the most advanced kernel topology and the highest turbo speed. Meanwhile, Qualcomm looks more attractive when it comes to performance per watt.
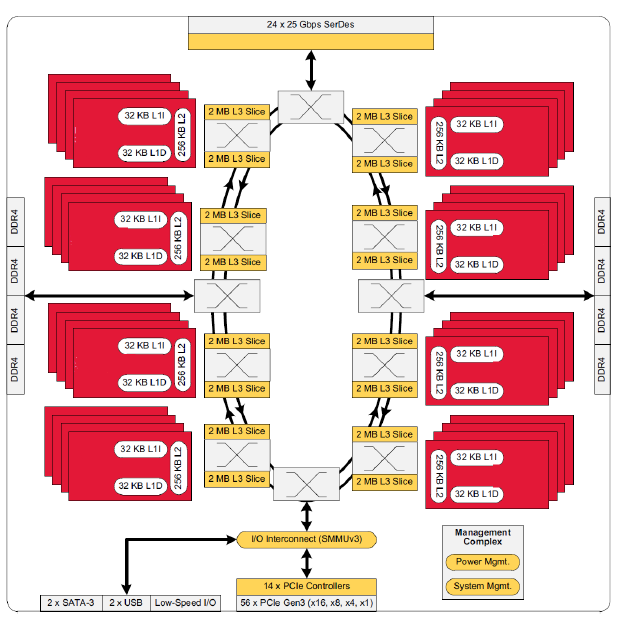
Like AMD's EPYC, Cavium's ThunderX2 is likely to shine on the high-performance computing market (throughput higher by 33%, high number of cores / threads). As in the case of AMD design, the EPYC L3 cache turns out to be slow if you need data that is not in the local 8 MB cache slot. ThunderX2 is much more complex - with a double ring architecture, similar to the ring architecture of Xeon v4 (Broadwell-EP). According to information from Cavium, their ring non-blocking architecture is capable of providing bandwidth up to 6 TB / s.
This ring architecture is connected to the Cavium's Coherent Processor Interconnect interconnect (CCPI2 - at the top of the figure), which operates at 600 Gbit / s. This connection connects the two socket nodes / NUMA. 56 PCIe 3.0 SoC lanes are connected to the ring, which Cavium placed among 14 PCIe controllers. These 14 controllers can, in turn, branch out to x4 or x1, as shown below.

Plus, SR-IOV is supported, which is so important for I / O virtualization (Xen and KVM).
Short briefing. The original ThunderX was an enhanced version of the Octeon III: a CPU with the ability to simultaneously execute two instructions (dual-issue core) with two short pipelines.

The advantage of the original ThunderX design is the high energy efficiency of the kernel, especially with workloads with a low ILP level (instruction level parallelism). Of course, such a short pipeline gives serious limitations on increasing the clock frequency, and the simple design of the design ensures low single-threaded performance with medium and high ILP loads, while more advanced out-of-order processors can extract as much “hidden parallelism” ".

Compared to the original ThunderX, the Vulcan ThunderX2 core is a completely different beast. Announced in 2014 by Broadcom, Vulcan is a relatively large kernel that manages 4 simultaneous streams (SMT4). As a result, the back end must be well loaded even when working with server loads with low ILP.
To ensure stability to the 4 SMT streams, the ThunderX2 front-end can extract up to 64 bytes from an 8-way 32KB associative command cache, which is equipped with a simple “next line” prefetcher. However, the choice of 8 commands is possible only if there is no branch in these 64 bytes. Otherwise, the sample is interrupted at the fork.
This means that in intensively branching code (databases, AI ...), the fetcher receives on average ± 5 instructions per clock, since one of the 5 instructions is a branch. The selected instructions are then sent to a smoothing buffer — a buffer in which stored instructions are stored for decoding.

Then the decoder works with a package of 4 instructions. Between the decoder and the renaming phase, each stream has a “slip buffer”, which consists of 8 packets. With 4 streams, up to 32 packets (128 instructions) can be buffered at any time.
These 4 instructions — a packet — move through the pipeline until they reach a single message queue in the scheduler. Like Intel's Loop Stream Detector (works like a small cache), it also has a loop buffer and predictor. This loop buffer eliminates incorrect branch predictions and contains decoded μops that “shrink” the pipeline and reduce the energy spent on decoding.
Up to 6 instructions can be executed simultaneously. The implementation includes 2 ALU / FP / NEON slots, 1 ALU / branch slot, 2 load / storage slots (16 bytes) and 1 empty storage slot, which sends 16 bytes to the D-cache. There is a small (Cavium will not disclose how much) L1 TLB to go with zero latency from virtual to physical addresses. For the D1-cache L1 there is no hardware prefetcher, but the L2 cache has a rather complicated hardware prefetter that can recognize patterns (it can also work step by step or extract the next line).
This is quite enough to “feed” the back-end, which can support 4 instructions per cycle of 4 different threads.
Cavium has published a limited amount of information about ThunderX2. Below is a summary of some key features of various processor architectures.
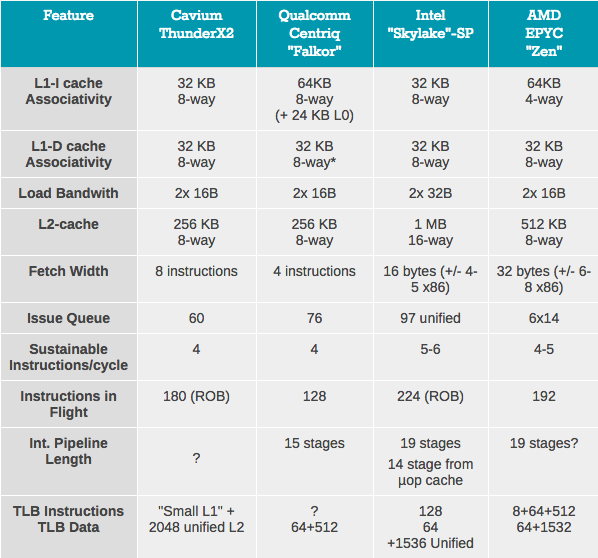
A detailed analysis is beyond the scope of this article. But you can read Johan De Gelas analyzes about the architecture of Falkor, Skylake and Zen in AnandTech. We confine ourselves to the most visible differences.
It's pretty obvious that Intel's single-threaded performance remains unrivaled: the Skylake core is the core that executes most of the instructions on the fly, and most importantly, it runs at a higher clock frequency. The core of ThunderX2 is different in that it extracts a maximum of instructions per cycle, capable of constantly supporting 4 threads. Fetcher will capture 8 commands from one thread, then 8 from the second thread, and will continue to cycle between threads. This means that poor prediction can significantly reduce the performance of a single stream.
SKU, which was used for the tests, ThunderX2 CN9980 2.2. This is a top-end SKU, contains 32 cores at a frequency of 2.2 GHz with the ability to boost up to 2.5 GHz.
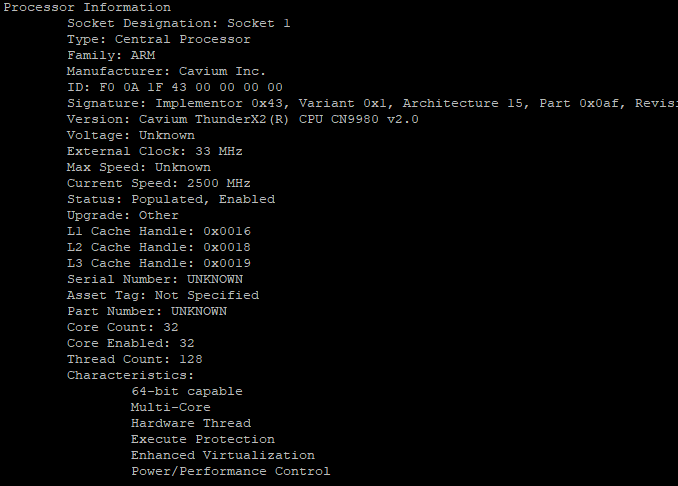
According to Cavium plans, many more SKUs will appear in the coming months. Cavium claims that CN9980 will soon be available at 2.5 GHz, and turbo up to 3 GHz.
Cavium listed all its planned SKUs along with comparable Intel SKUs. By definition, Cavium, a comparable Intel SKU, is a chip that achieves the same SPECInRate (2017) under gcc as Cavium's SKU.

Cavium believes that the CN9880 2.2 that we got is comparable to the much more expensive 8164. For our testing, we will compare it to the 8176 (Intel SKU available to us). Not that it was important: 8176 has only a 3% higher clock speed and 2 additional cores (+ 7%) compared to 8164. However, note that although the ThunderX2 Cavium can really compete with the specified Intel SKUs, they offer the same performance for one third the cost of an Intel SKU.
In the next part:
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?
But Cavium did not give up for obvious reasons: at the moment the server market has become more attractive than ever. The data centers of the world giant Intel bring in revenue of about $ 20 billion (!) Per year. Moreover, profitability is 50%. In terms of profit and money turnover, the server market is many times greater than any other equipment market. So, after starting ThunderX, Cavium promised to release a second iteration: improved power management, improved single-threaded performance, and even more cores (54).
What is playing into the hands of Cavium is that if a user needs a server, he can simply take a streamlined and reliable Intel machine. After all, the loud promises from Arm, Calxeda, Broadcom, AppliedMicro over the past 5 years have remained promises, causing a serious wave of skepticism and distrust and the emergence of new SoCs Arm Server.
Nevertheless, the creation of an outsider Cavium deserves attention. A number of changes were made, and not just the addition of the number “2” to the title: Cavium bought the Vulcan design from Avago. Vulcan is a rather ambitious processor design, originally developed by the Arm server SoC Broadcom team, and has a much larger legacy than the original ThunderX. Plus, based on the experience with ThunderX, Cavium was able to implement some micro-architectural improvements to the Vulcan design, improving its performance and power.
As a result, ThunderX2 "turned out" a more thoughtful core than the previous generation. The ThunderX kernel had a very short pipeline and could hardly withstand two instructions per clock, however the Vulcan core was designed for fetching 8s and executing up to 4 instructions per clock. And even more: all 4 threads (SMT4) can be active at the same time, ensuring constant back-end loading. The new ThunderX2 SoC32 hosts 32 such cores with frequencies up to 2.5 GHz.
When using up to 128 threads and at least eight DDR4 controllers, this CPU should show itself well in all server loads. In other words, unlike ThunderX (1), ThunderX2 is the first processor of the Arm server and has every chance to shake the balance in the server market.
Who has more: technical characteristics
Thirty-two high IPC cores in the same package seem promising. But what does the new ThunderX2 look like in comparison with AMD, Qualcomm and Intel products? In the table below we compare the specifications of several top server SKUs.
Knowledgeable readers will immediately notice that the top of the Intel processor line is the Xeon Platinum 8180. However, this SKU with a 205 W TDP and priced above $ 10,000 is not comparable to any processor in the list at all. We have almost crossed the line of reason, including 8176, which, it seems to us, falls into this list in terms of the parameters of the maximum SKU of the core / thread blocks. In fact, Cavium positions the Cavium 9980 as “comparable” to the Xeon Platinum 8164 (while Intel has 8176), but with slightly lower frequencies.
However, in terms of performance per dollar, Cavium compares its flagship 9980 with Intel Xeon Gold 6148, and in this case, the price of the Cavium processor looks quite appetizing. According to the test results, the fastest ThunderX2 is 30-40% ahead of the Xeon 6148, while the offer from Cavium is 1300 dollars cheaper. Such aggressive pricing explains the rumors that Qualcomm is not going to enter the server market.
The data in the table above demonstrate the important differences between the rivals. It seems that Intel has the most advanced kernel topology and the highest turbo speed. Meanwhile, Qualcomm looks more attractive when it comes to performance per watt.
Like AMD's EPYC, Cavium's ThunderX2 is likely to shine on the high-performance computing market (throughput higher by 33%, high number of cores / threads). As in the case of AMD design, the EPYC L3 cache turns out to be slow if you need data that is not in the local 8 MB cache slot. ThunderX2 is much more complex - with a double ring architecture, similar to the ring architecture of Xeon v4 (Broadwell-EP). According to information from Cavium, their ring non-blocking architecture is capable of providing bandwidth up to 6 TB / s.
This ring architecture is connected to the Cavium's Coherent Processor Interconnect interconnect (CCPI2 - at the top of the figure), which operates at 600 Gbit / s. This connection connects the two socket nodes / NUMA. 56 PCIe 3.0 SoC lanes are connected to the ring, which Cavium placed among 14 PCIe controllers. These 14 controllers can, in turn, branch out to x4 or x1, as shown below.
Plus, SR-IOV is supported, which is so important for I / O virtualization (Xen and KVM).
ThunderX: from easy to hard
Short briefing. The original ThunderX was an enhanced version of the Octeon III: a CPU with the ability to simultaneously execute two instructions (dual-issue core) with two short pipelines.
The advantage of the original ThunderX design is the high energy efficiency of the kernel, especially with workloads with a low ILP level (instruction level parallelism). Of course, such a short pipeline gives serious limitations on increasing the clock frequency, and the simple design of the design ensures low single-threaded performance with medium and high ILP loads, while more advanced out-of-order processors can extract as much “hidden parallelism” ".
"New" core Cavium: Vulcan
Compared to the original ThunderX, the Vulcan ThunderX2 core is a completely different beast. Announced in 2014 by Broadcom, Vulcan is a relatively large kernel that manages 4 simultaneous streams (SMT4). As a result, the back end must be well loaded even when working with server loads with low ILP.
To ensure stability to the 4 SMT streams, the ThunderX2 front-end can extract up to 64 bytes from an 8-way 32KB associative command cache, which is equipped with a simple “next line” prefetcher. However, the choice of 8 commands is possible only if there is no branch in these 64 bytes. Otherwise, the sample is interrupted at the fork.
This means that in intensively branching code (databases, AI ...), the fetcher receives on average ± 5 instructions per clock, since one of the 5 instructions is a branch. The selected instructions are then sent to a smoothing buffer — a buffer in which stored instructions are stored for decoding.
Then the decoder works with a package of 4 instructions. Between the decoder and the renaming phase, each stream has a “slip buffer”, which consists of 8 packets. With 4 streams, up to 32 packets (128 instructions) can be buffered at any time.
These 4 instructions — a packet — move through the pipeline until they reach a single message queue in the scheduler. Like Intel's Loop Stream Detector (works like a small cache), it also has a loop buffer and predictor. This loop buffer eliminates incorrect branch predictions and contains decoded μops that “shrink” the pipeline and reduce the energy spent on decoding.
Up to 6 instructions can be executed simultaneously. The implementation includes 2 ALU / FP / NEON slots, 1 ALU / branch slot, 2 load / storage slots (16 bytes) and 1 empty storage slot, which sends 16 bytes to the D-cache. There is a small (Cavium will not disclose how much) L1 TLB to go with zero latency from virtual to physical addresses. For the D1-cache L1 there is no hardware prefetcher, but the L2 cache has a rather complicated hardware prefetter that can recognize patterns (it can also work step by step or extract the next line).
This is quite enough to “feed” the back-end, which can support 4 instructions per cycle of 4 different threads.
Differences in microarchitecture
Cavium has published a limited amount of information about ThunderX2. Below is a summary of some key features of various processor architectures.
A detailed analysis is beyond the scope of this article. But you can read Johan De Gelas analyzes about the architecture of Falkor, Skylake and Zen in AnandTech. We confine ourselves to the most visible differences.
It's pretty obvious that Intel's single-threaded performance remains unrivaled: the Skylake core is the core that executes most of the instructions on the fly, and most importantly, it runs at a higher clock frequency. The core of ThunderX2 is different in that it extracts a maximum of instructions per cycle, capable of constantly supporting 4 threads. Fetcher will capture 8 commands from one thread, then 8 from the second thread, and will continue to cycle between threads. This means that poor prediction can significantly reduce the performance of a single stream.
The ThunderX2 SKUs: 16 to 32 cores
SKU, which was used for the tests, ThunderX2 CN9980 2.2. This is a top-end SKU, contains 32 cores at a frequency of 2.2 GHz with the ability to boost up to 2.5 GHz.
According to Cavium plans, many more SKUs will appear in the coming months. Cavium claims that CN9980 will soon be available at 2.5 GHz, and turbo up to 3 GHz.
Cavium listed all its planned SKUs along with comparable Intel SKUs. By definition, Cavium, a comparable Intel SKU, is a chip that achieves the same SPECInRate (2017) under gcc as Cavium's SKU.
Cavium believes that the CN9880 2.2 that we got is comparable to the much more expensive 8164. For our testing, we will compare it to the 8176 (Intel SKU available to us). Not that it was important: 8176 has only a 3% higher clock speed and 2 additional cores (+ 7%) compared to 8164. However, note that although the ThunderX2 Cavium can really compete with the specified Intel SKUs, they offer the same performance for one third the cost of an Intel SKU.
In the next part:
- Test Configuration and Methodology
- Memory subsystem: bandwidth
- Single threaded performance: SPEC CPU2006
- SPEC CPU2006 Cont: kernel-based performance with SMT
Thank you for staying with us. Do you like our articles? Want to see more interesting materials? Support us by placing an order or recommending to friends, 30% discount for Habr's users on a unique analogue of the entry-level servers that we invented for you: The whole truth about VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps from $ 20 or how to share the server? (Options are available with RAID1 and RAID10, up to 24 cores and up to 40GB DDR4).
Dell R730xd 2 times cheaper? Only we have 2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA! Read about How to build an infrastructure building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny?