Create a voice application on the example of Google Assistant
Every fifth resident of the United States owns a smart column, and this is 47 million people. An assistant can create a reminder, to-do list, alarm clock, timer, read the news, play music, podcast, order delivery, buy movie tickets and call a taxi. All these are “skills” or “skills” helpers. They are also called voice applications. For Alexa and Google Assistant of such applications for 2018 70 000 are developed .
In 2017, Starbucks launched a feature on ordering a coffee home for Amazon Alexa. In addition to the increase in delivery orders, all possible media outlets wrote about it, creating a cool PR. The example of Starbucks was followed by Uber, Domino's, MacDonald's, and even Tide washing powder had its own skill for Alexa.
Like Starbucks, the voice application performs one or two functions: ordering coffee, setting an alarm or calling a courier. To design something like this, it’s not necessary to be an intercontinental corporation. The idea, design, testing, development and release are similar to similar stages in the world of mobile development, but with features for voice. Pavel Guay told in detail about the process : from idea to publication, with examples of real games, with historical inserts and analysis of the world of voice development.
About speaker : Pavel Guay ( pavelgvay ) - designs voice interfaces in the KODE mobile development studio. The studio is developing mobile applications, for example, for Utair, Pobeda, RosEvroBank, BlueOrange Bank and Whiskas, but KODE has a division that deals with voice applications for Yandex.Alisa and Google Assistant. Pavel has participated in several real-world projects, exchanges experience with developers and designers in this area, including from the USA, and speaks at thematic conferences. In addition, Pavel is the founder of the startup tortu.io - a tool for the design of voice applications.
What is a conversational application
In a conversational application, the interaction channel with the user is built through a conversation : oral - with a smart column, or through a written one, for example, with Google Assistant. In addition to the column, the device of interaction can be a screen, therefore conversational applications are also graphical.
Voice applications have an important advantage over mobile: they do not need to be downloaded and installed. It is enough to know the name, and the assistant will start everything himself.
All because there is nothing to download - both speech recognition and business logic - the entire application lives in the cloud. This is a huge advantage over mobile applications.
A bit of history
The history of voice assistants began with Interactive Voice Response - an interactive system of recorded voice responses. Perhaps no one heard this term, but everyone came across when they called technical support and heard the robot: “Press 1 to get to the main menu. Click 2 for more details ”- this is the IVR system. In part, IVR can be called the first generation of voice applications. Although they are already part of the story, they can teach us something.
When interacting with the IVR system, most people try to contact the operator. This is due to poor UX, when the interaction is based on hard commands, which is just inconvenient.
This brings us to the basic rule of a good conversational application.
A conversation with the application should be more like a call to a pizzeria to order, than to communicate with the chat bot teams. To achieve the same flexibility as in a conversation between people will not work, but to speak with the application in a comfortable and natural language is completely.
This is also the advantage of a voice over graphic applications: no need to learn to use . My grandmother does not know how to enter sites or order pizza through the application, but she can call delivery through the column. We must use this advantage and adapt to how people say, and not teach them to talk with our application.
From IVR-systems we move on to the present - to virtual assistants.
Virtual Assistants
The voice world revolves around virtual assistants: Google Assistant , Amazon Alexa and Alice .
Everything is arranged almost like in the mobile world, but instead of iOS and Android platforms, Alice is here, Google Assistant and Alexa, instead of graphical applications, voice, with their own names or names, and each assistant has their own internal store of voice applications. Again, saying “application” is wrong, because each platform has its own term: Alice has “skills,” Alex has “skills,” and Google has “actions.”
To start the skill, I ask the assistant: “Alex, tell Starbucks that I want coffee!” Alex will find the application of the coffee shop in his store and transfer the conversation to him. The conversation goes not between Alex and the user, butbetween the user and the application . Many people are confused and think that the assistant continues to speak with them, although the application has a different voice.
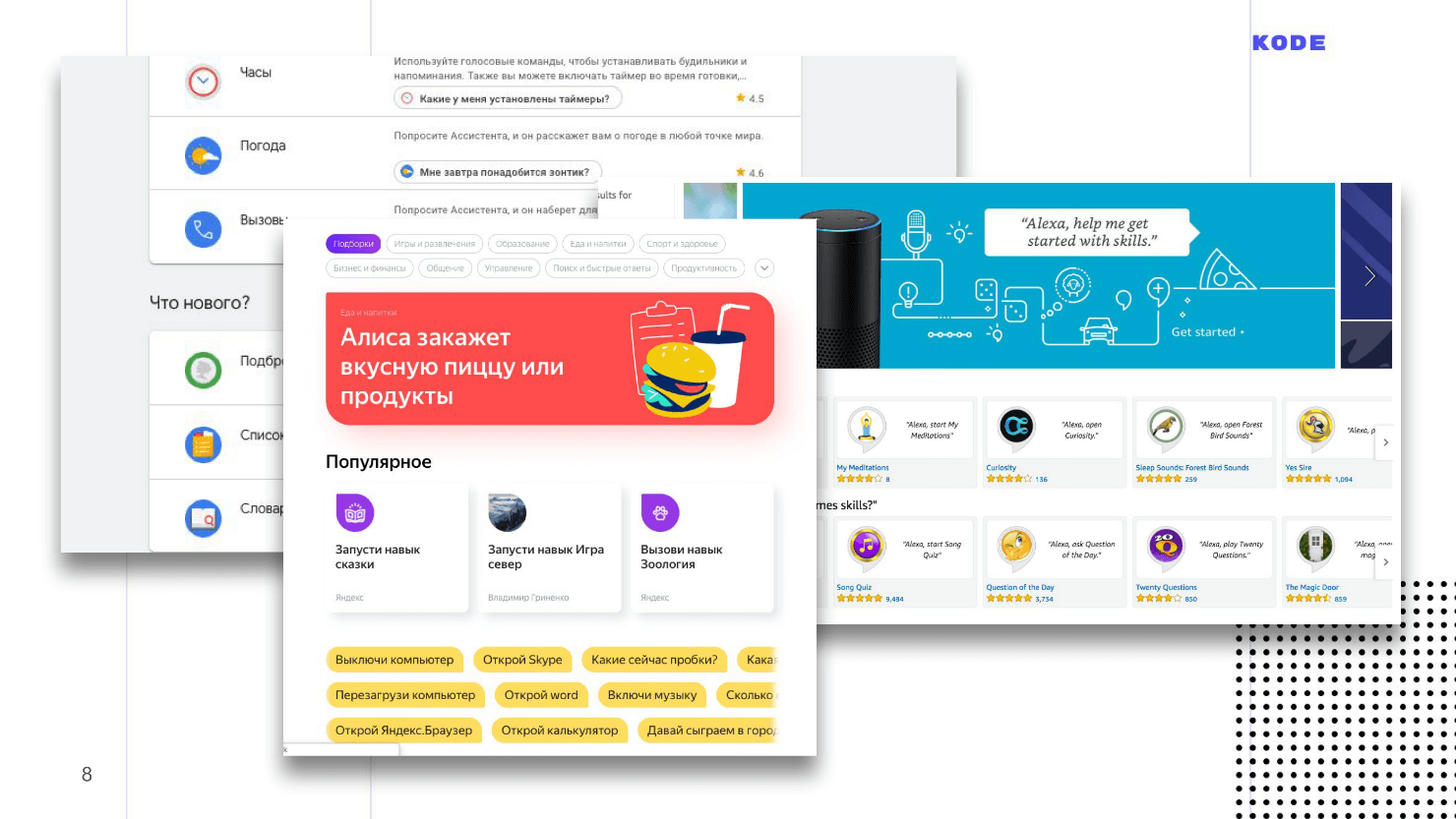
This is how app stores look. The interface resembles the App Store and Google Play.
Stages of development of conversational applications
For the user, the application has no graphic part - everything looks like a set of dialogue. Outwardly, it may seem that the application is a simple thing, to create it is simple, but it is not. Stages of development are the same as for mobile applications.
The first two stages are specific, as the applications are conversational, and the last two are standard.
Let's go through each of the stages on the example of the game "Guess the price" , which is running under Google Assistant. The mechanics are simple: the application shows the user a card with the goods, and he must guess the price.
Let's start the dive from the first stage: we decided on an idea, conducted an analytics, realized that the user has a need and proceed to create a voice application.
Design
The main goal is to design the interaction between the user and the application. In the mobile world, this stage is called design. If the graphic application designer draws maps of the screens, buttons, shapes and selects colors, the VUI designer works out the dialogue between the user and the application: prescribes various branches of the dialogue, thinks about forks and side scenarios, chooses variants of phrases.
Design is carried out in three stages.
Dialog examples
The first thing to do is to understand how the application will work. Understanding and vision will need to be broadcast on everyone else, especially if you are an outsourcing company, and you have to explain to the customer what he will receive in the end.
A powerful tool to help - examples of dialogue: a conversation between the user and the application on roles , as in the play.
An example of dialogue for our game.

The app greets, tells the user about the rules, offers to play, and, if the person agrees, shows a card with the goods so that the user guesses the price.
The script helps to quickly understand how the application will work, what it can do, but, in addition, examples of dialogues help weed out the main mistake in the world of voice interfaces -working on the wrong scenarios .
Voice and graphics are significantly different, and not everything that works on graphical interfaces works well on voice. Almost every mobile application has a registration, but I can not imagine how you can register by voice? How to dictate a smart password column: "A capital letter, a small letter, es like a dollar ..." - and all this is out loud. And if I'm not alone, but at work? This is an example of an erroneous scenario. If you start developing a script with an error, problems will arise with it: you will not understand how to execute it, users will not understand how to use it.
Examples of dialogues will help to find such moments. To find errors in the scenarios, record the dialogue, select a colleague, put them in front of you and play the roles: you are the user, the colleague is the application. After role-playing the dialogue, it becomes clear whether the application sounds or not, and whether the user will be comfortable.
Such a problem will appear constantly. If you have an in-house development, there will be a temptation: “We already have a website, let's just convert it to voice and everything will be fine!” Or the customer will come and say: “Here is the mobile application. Do the same with your voice! ”But you can't do that. You, as a specialist, should quickly find scenarios that should not be worked on, and explain to the customer why. Dialog examples here will help.
Absolutely any text editor you are used to will be suitable for writing dialogs. The main thing - write down the text and read it by roles.
Block diagram
Dialogue examples are powerful, fast, and cheap, but they only describe linear developments, and conversations are always non-linear . For example, in our game “Guess the price”, the user can answer the question correctly or incorrectly - this is the first fork in the set of those that will be encountered later.
In order not to get confused in all branches of the dialogue of your application, make a flowchart - visualization of the dialogue. It consists of only two elements:
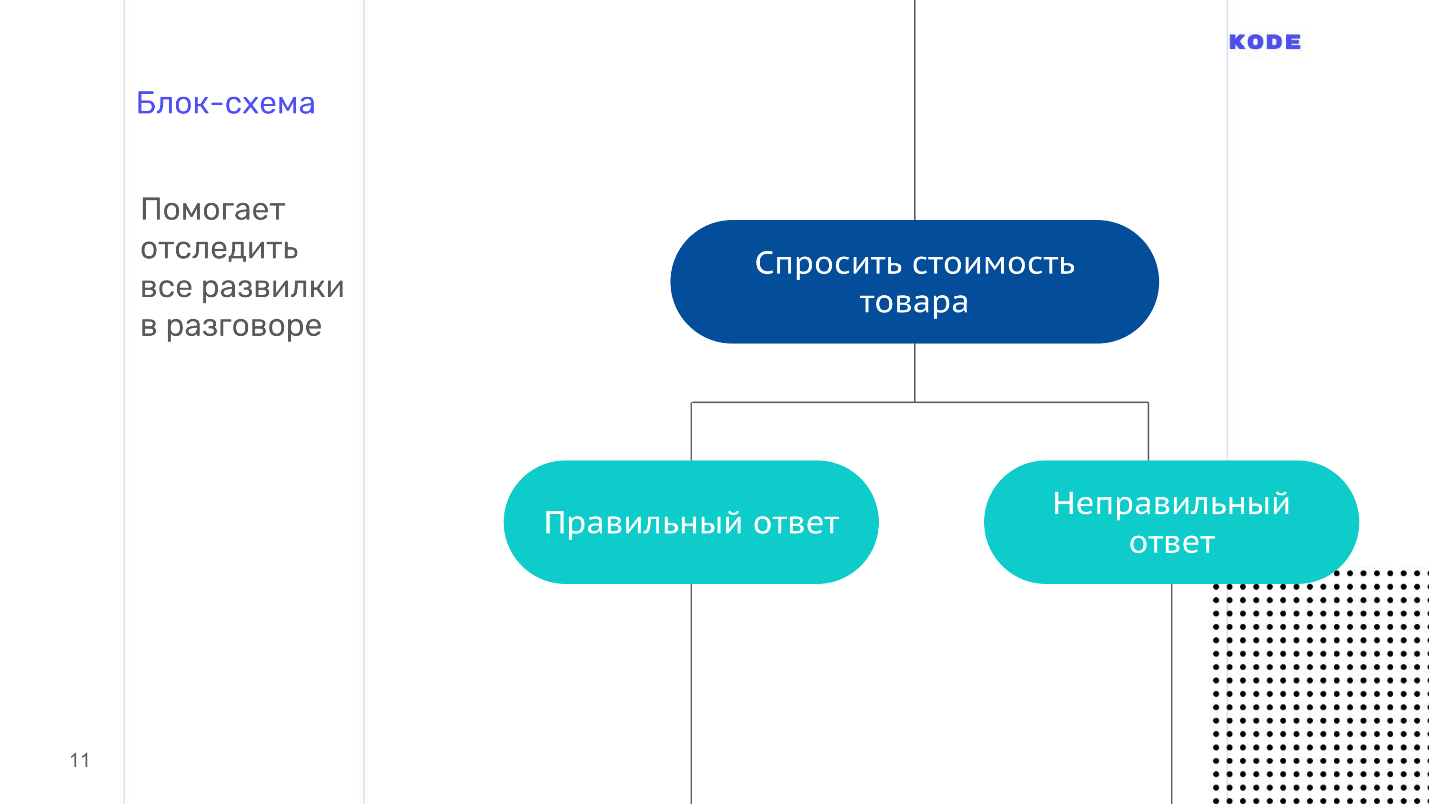
The block diagram is a map of our application, but with one unpleasant property - it grows heavily, becomes unreadable and visually incomprehensible. Here, for example, a screenshot with a part of the flowchart from the scenario where the user guesses the price, with several forks.
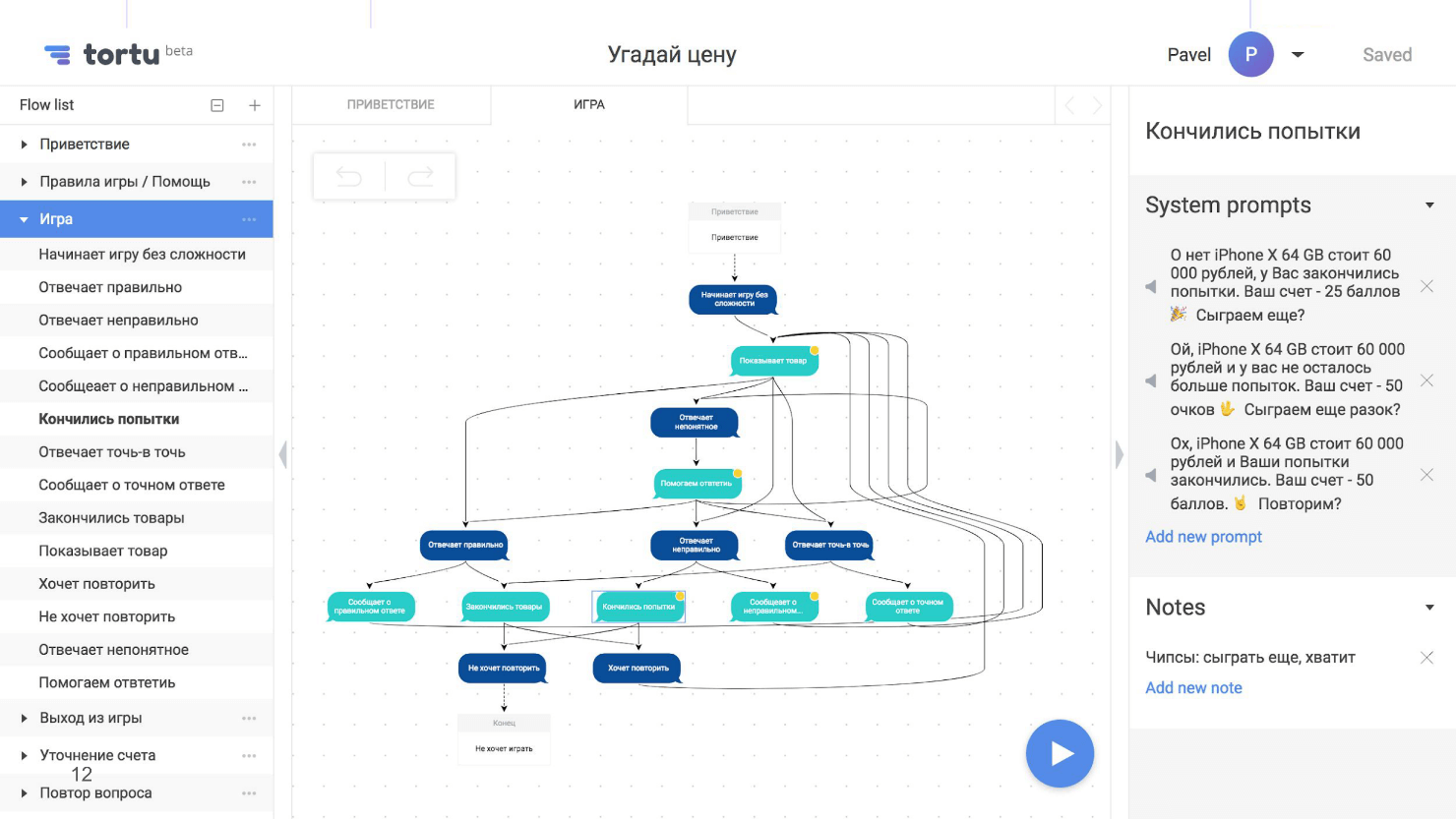
A few forks is not the limit, there may be tens or hundreds. We asked ourselves the questions: “What happens if a person answers correctly? And if not? What happens if the attempts end? What if the goods run out? And if he guesses the price exactly? What if the Internet disappears at this step or at another? ”As a result, we created a huge unreadable scheme.
In this we are not alone. I spoke with a designer from the USA who was working on a serious project. In the project there was an IVR, a bank, and a skill at the same time, and the whole thing inflated the flowchart to 600 sheets. Nobody understood the scheme to the end, and when the designer saw it, she was simply terrified.
I have advice on how to prevent this. The scheme will always grow, but never try to build one big flowchart for the whole application - it will be cumbersome, and no one except you will understand it. Go back and break the circuit into logical parts.: a separate price guessing scenario, a separate help script. If necessary, break these scripts into sub-scenarios. The result is not one big map with incomprehensible connections, but many small, readable, well-connected schemes in which it is convenient for everyone to navigate.
For flowcharts fit any tool. I used to use RealtimeBoard , but I also have Draw.io and even XMind . As a result, I developed my own, because it is simply more convenient. In the picture it is just presented. This tool supports, including, a breakdown into subscenarios.
prompt lists
The last artifact we will form at the design stage. The prompt list is a list of all possible phrases that an application can say.
There is one subtlety. Conversation with the application should be flexible and similar to a conversation with a person. This means not only the opportunity to go through different branches, which we did at the stage of the flowchart, but the sound of the conversation as a whole. A person will never answer with the same phrase if you ask the same question. The answer will always be rephrased and sound somehow different. The application should do the same, so for each step of the dialogue on behalf of the application write not one answer, but at least five.

According to the prompt lists there is another important thing. Communication should not only be lively and flexible, but also consistent.in terms of style of speech and the general feeling of user communication with your application. For this, designers use an excellent technique - character creation . When I call my friend, I do not see him, but subconsciously imagine the interlocutor. The user when communicating with a smart column is the same. This is called pareidalia .
At the prompt lists page, you create a character on whose behalf the application will speak. With a character, your users will associate a brand and an app — this can be a real person or a fictional one. Work on his appearance, biography, character and humor, but if there is no time, just bring all your phrases in the prompt sheets to the same style. If you started to contact the user on "You", then do not contact in other places on "You". If you have an informal communication style, stick to it everywhere.
Usually, Excel or Google spreadsheets are used to create the prompt sheets, but with them there are huge temporary losses for routine work. The block diagram and the tablet with the phrases are in no way connected with each other, any changes have to be transferred manually, which translates into a permanent and long routine.
I use not Excel, but my tool, because in it all the phrases are written directly in the flowchart, they are assigned to the step of the dialogue. It eliminates the routine.
It seems that now everything is ready and you can give the task to the developers and get to the code, but there is one more important stage left - testing. We need to make sure that as designers did everything correctly, that the application will work as we want, that all the phrases are in the same style, that we have covered all the side branches and processed all the errors.
Testing
Testing at this early stage is especially important for voice applications. In the world of graphical user interfaces, the user is limited by what the designer has drawn: he will not go beyond the screen, will not find a button that does not exist, but will only click on what is ...
In the world of voices, everything is wrong: the user is free to say everything that whatever you want, and you don’t know how it will work with your application until you see it. It is better to do this at an early design stage and prepare for the unexpected, before the expensive development begins.
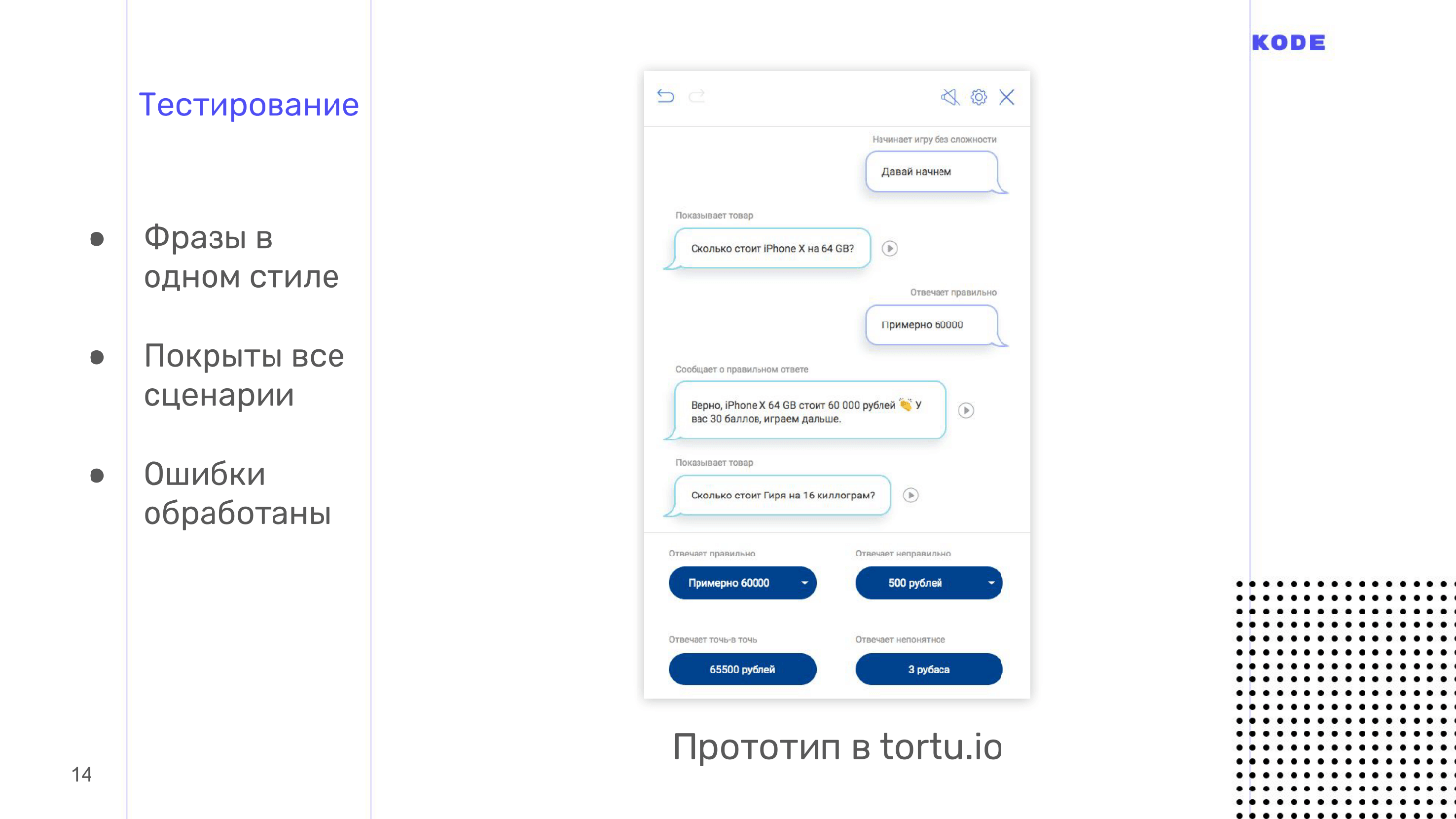
Applications are tested using the Wizard of Oz methodology.. It is used in graphic applications, but less often, but in a voice it is a must have. This is a method when a user interacts with the system, assuming that it exists and works on its own, but you manage the whole process.
Testing is done using interactive prototypes. Usually the designer has to ask developers to create a prototype, but personally I use my tool, because everything is done in it with one click and you don’t have to wait for anyone. We also need a user. We call a person who is not involved in the development at all, does not know anything about the application and, ideally, is included in your Central Asia. You invite a person, explain what kind of application it is, how to use it, plant it in a room, turn on an interactive prototype and the user starts talking to him. The prototype does not recognize speech, and this is what you hear, what the person says, and choose the answer option with which the application responds to each phrase.
If the user does not see the screen, then it seems to him that the application works by itself, but the process is controlled by you. This is the testing of the Wizard of Oz. With it, you will not only hear the sound of the application, but also see how people use it. I guarantee that you will find many uncovered scripts.
When I tested the game, I called my friend. He began to guess the price and said that some kind of ointment was worth "pyatikhat." I did not expect such a word, I thought that there would be options of 500 rubles, a thousand rubles, and not “pyatikhat” or “mower”. This is a trifle that came to light on testing. People use the application differently than you imagine, and testing reveals such trifles and non-working scenarios.
This is where the design phase ends and we have examples of dialogues in our hands, a block diagram is a logical description of the operation of an application, and prompt-lists are what the application says. We will give all this to the developers. Before I tell you how developers create applications, I’ll share design tips.
Tips
Use SSML markup language - as HTML, only for speech. SSML allows you to pause, set the level of empathy, stress, prescribe what to spell and where to focus.

Marked speech sounds much better than the robot speech, and the better the application sounds, the more pleasant it is to use it. Therefore, use SSML - it is not so complicated.
Think about the moments in which users turn to your application for help.This is especially important for voice. A person can talk to a speaker alone in a room, or he can ride a bus and talk to a smartphone. These are two fundamentally different behavior scenarios for a voice application. We had a similar situation with the banking application. In the application there was a script when the user receives information about the account, and this is private information. I thought that if a person is talking at home, then everything is fine, but if he is traveling on a bus, and the application starts to voice the card balance out loud, it will be ugly.
Thinking about these moments, you can determine that if the user is talking to a smartphone, even if by voice, then it is better not to read out private information, but to show it on the screen.
This is a design for different surfaces and platforms. Voice devices are very different in their texture. In the mobile world, devices differ only in platform and screen size - form factor. The voice is different. For example, the speaker has no screen at all - only a voice. The smartphone has a screen, and you can tap it with your finger. The TV screen is huge, but it is useless to touch it. Think about how your application will work on each of these surfaces.
For example, a user made a purchase and we want to show a receipt. Reading the check out loud is a bad idea, because there is a lot of information and no one will remember it, because voice information is perceived difficult and difficult.

Using the principle of multimodal design, we understand that if there is a screen, then the check is better to show, instead of reading. If there is no screen, then we are forced to speak out loud the main data of the check.
This design is complete. What I have told is the basics, the tip of the iceberg. For self-study design, I gathered a lot of material on the design, at the end of the article will be links.
Development
We begin the conversation with a universal scheme of the application under any platform. The scheme works with Alice, Amazon Alexa, and Google Assistant.

When a user asks to start our application, the assistant does this and transfers control of the conversation to the application. The user says something and the application gets the raw text, which is processed by the speech recognition system.
For processing, we use Dialogflow , its structure is absolutely the same as that of other speech understanding systems, and we will consider the development using its example.
We are moving to the first link - the human speech understanding system or Natural Language Understanding - NLU.
Dialogflow
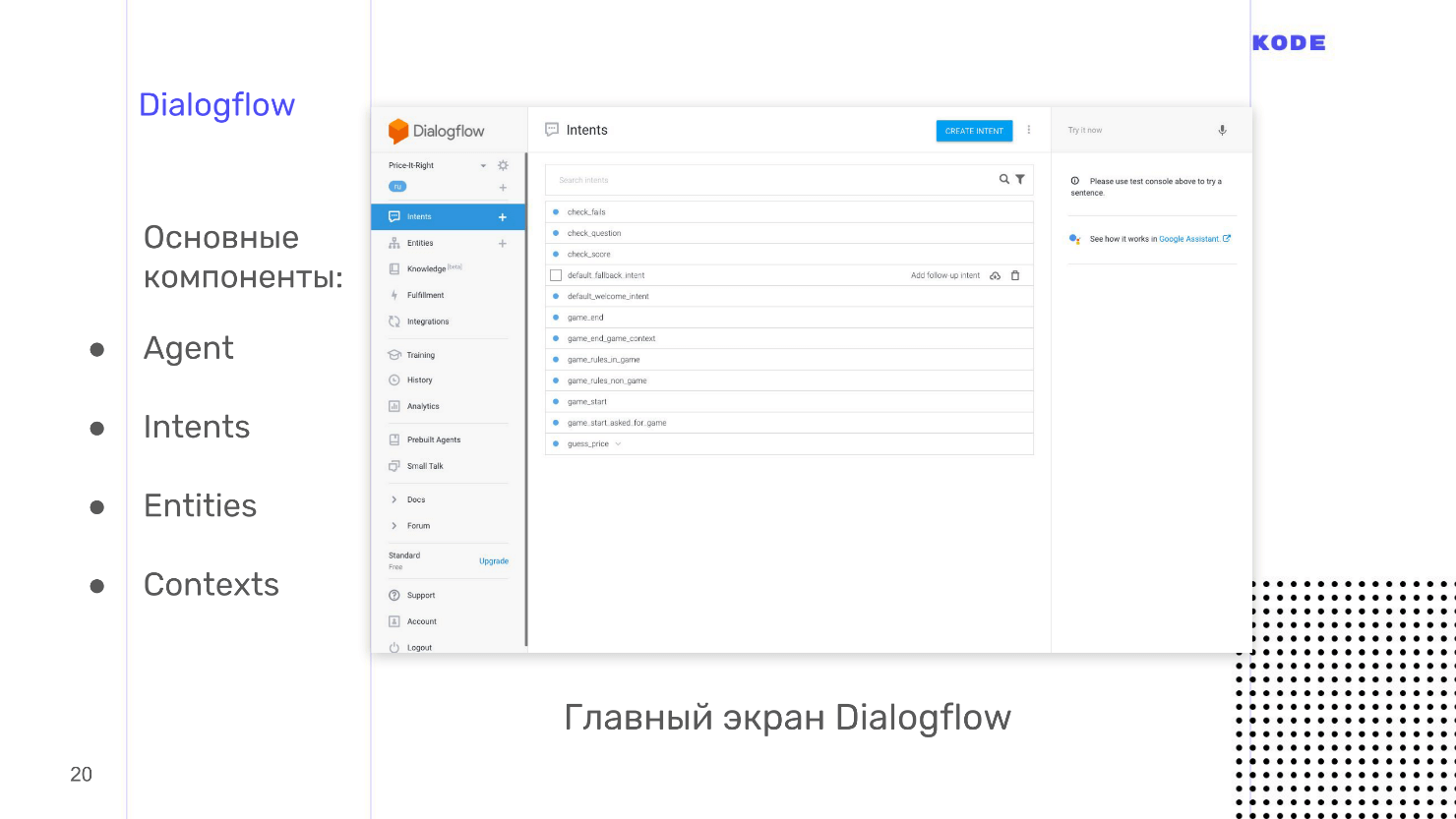
We use Dialogflow, because it has rich features, good documentation, live support and it is easy and quick to master. Dialogflow cross-platform tool: the main qualification is applications for Google Assistant, but for Yandex-Alice, Amazon Alexa and creating bots in Telegram it can also be used. Separate plus - open API. You can use the system to develop voice control for a website or an existing mobile application.
The main components of Dialogflow.
Let's go through all the components, but let's start with the main thing - this is Intents.
Intents
This is a user intention , what the user wants to accomplish. Intention expressed phrases. For example, in the game, the user wants to know the rules of the game and says: “Tell the rules of the game”, “Tell me how to play?”, “Help me - I'm confused” or something like that. Accordingly, we create a separate Intent for the rules of the game, and at the input we write all these phrases that we expect from the user.
I advise you to write 10 or more phrases. In this case, speech recognition will work better, because Dialogflow uses a neural network that accepts these 10 input phrases and generates a bunch of other similar ones from them. The more options, the better, but do not overdo it.
Intent should have the answer to any user question. In Dialogflow, an answer can be formed without applying logic, and if logic is needed, then we transmit the answer from the webhook. The answers may be different, but the standard one is the text: it is sounded on the speakers, shown or spoken on smartphones.
Depending on the platform, additional “buns” are available - graphic elements. For example, for Google Assistant, these are buttons, flashcards, lists, carousels. They are shown only if a person speaks with Google Assistant on a smartphone, TV, or other similar device.
Entities
Intent starts when the user says something. At this moment information is transmitted - the parameters, which are called slots , and the data type of the parameters - Entities . For example, for our game, these are examples of phrases that the user says when he guesses the price. There are two parameters: amount and currency.

Parameters may be required and optional . If the user answers "two thousand", then the phrase will be enough. By default, we take rubles, so the currency is an optional parameter. But without the sum, we cannot understand the answer, because the user can answer the question not specifically:
- How much does it cost?
- A lot!
For such cases, Dialogflow has the concept of re-prompt - this is the phrase that will be uttered when the user does not name the required parameter. For each parameter, the phrase is set separately. For the sum, it could be something like: "Give the exact figure how much it costs ..."
Each parameter must have a data type - Entities. Dialogflow has many standard data types - cities, names, and it saves. The system itself determines what is the name, what is the number, and what the city is, but you can also set your own custom types. Dialogflow currency is a custom type. We created it ourselves ^ described a technical system name, which we will use, and synonyms that correspond to this parameter. For the currency is the ruble, dollar, euro. When the user says: “Euro”, Dialogflow highlights that this is our “currency” parameter.
Context
Think of this word literally: context is the context of what you are talking about with the user. For example, you can ask the assistant: “Who wrote Mumu?” And he will answer that it is Turgenev. After that you can ask when he was born. I pay attention that we ask: "When he was born", without specifying who. Google will understand, because it remembers - in the context of the conversation Turgenev.
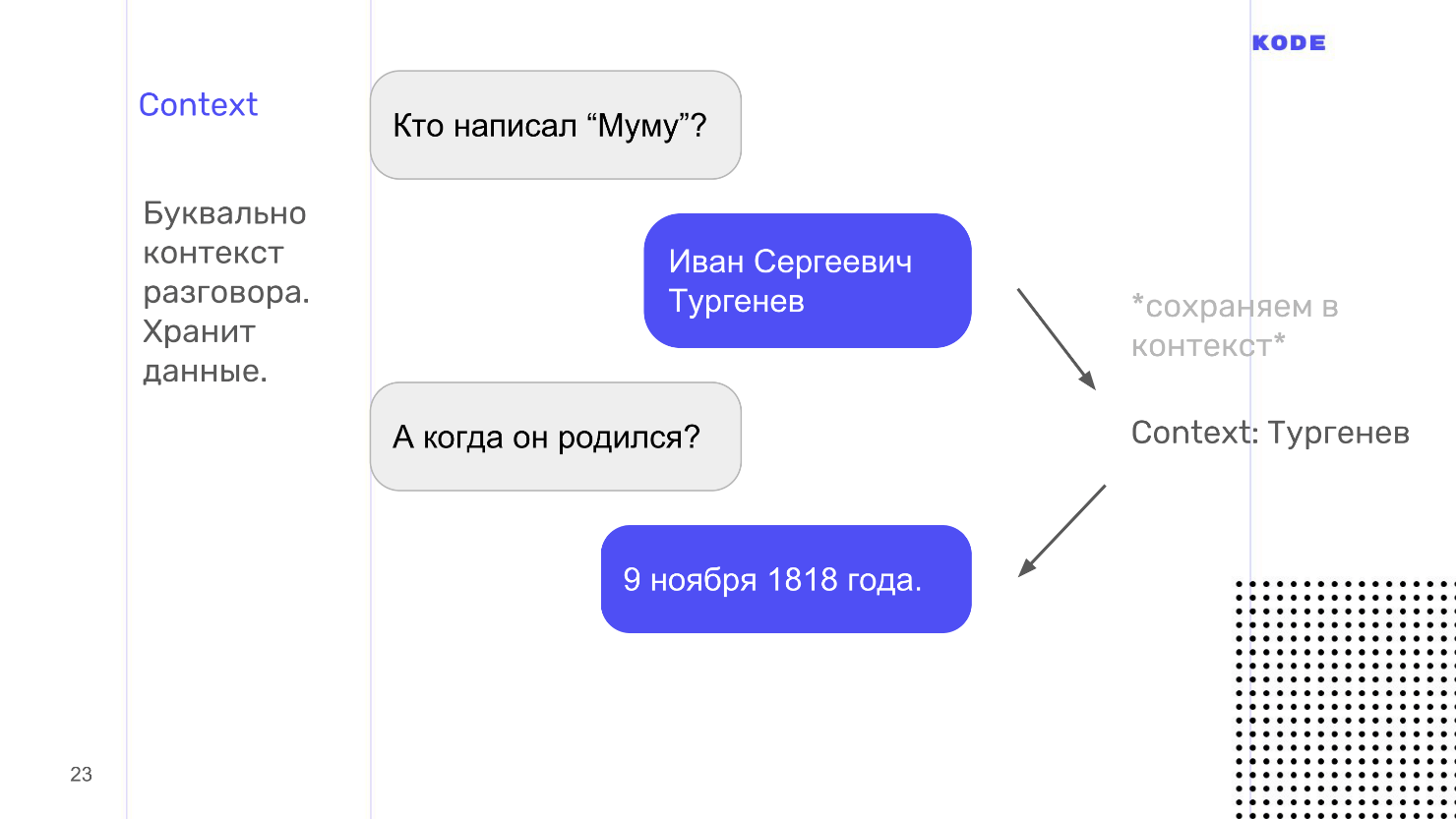
From a technical point of view, context is a key-value repositoryin which the information is stored. Intent can either emit the context from itself, add something to it, or accept it as input and retrieve information from there. The context has a lifetime. It is determined by the number of steps of the dialogue from the last mention: for example, after 5 steps of the dialogue, forget what we said about Turgenev.
The context has another important function - it can help us break the application into logical zones: into authorized and unauthorized ones, into a gaming session or not. The breakdown is constructed in such a way that the Intent that accepts a context for input cannot be started without a context and requires a previous launch of another Intent. So we can logically link and build our application.

I mentioned webhook. Dialogflow has libraries for completely different languages, we used JS. Google Assistant for webhook has a limitation - the answer from it should come no later than 5 seconds, otherwise an error will occur and the application will work in the fallback. For Alice, the response time is 1.5 or 3 seconds.
Publication
The publication is standard, almost like with mobile applications, but with a couple of nuances.
Pay a separate, special and very close attention to the name of the application . The user will say it out loud every time you start. Therefore, the name should be easy to pronounce and easy to recognize by an assistant, because sometimes there are problems with this.
The name has two rules:
In Google Assistant, the standard phrase that launches any application is “OK, Google, talk to ...”. You can use this feature, for example, say: “OK, Google, talk to Uber” - and he will launch the application on the main screen, at the starting point. But you can make the user say, “OK, Google, tell Uber to pick me up from here and take me there!” We shorten one iteration, and the user gets into the desired action.
The script is determined by the phrases that launch the application. They are installed when publishing, but often work incorrectly - in Russian for sure. For example, in our game, the phrase “Let's sy gray” worked, and “Let 's goplay "did not work. I do not know what the fundamental difference between "play" and "play" for Google Assistant. He recognized both phrases correctly, but the application did not work, although we had no problems with the English language.
The rest of the publication runs smoothly, without any questions. Support for Google Assistant is very lively, responds quickly, and the documentation is good.
I also want to mention different types of releases.
It would seem that this is all, but we are talking about the voice, so there is another important point here - this is the analyst.
Analytics
Especially important for voice. If for mobile applications, the analyst shows jambs, bugs and system errors, but in the world of voice, the analyst reveals missed opportunities to us - how people wanted to use our application, but could not.
This is a mandatory step. That is why Dialogflow has standard application analysis tools with the following modes:
They are shown in a list and look like in the picture. The user guessed the price of a motor and said: "4 pieces." I remembered about the "mowers" for testing, but I forgot about the "things" - so I’ll have to fix it.
Analytics helps to find flaws, so be sure to look in the logs and check what happens to your application and what users do with it.
That's all about voice applications. I hope that you have at least a minimal understanding of how they are developed. The report was general, but all additional materials about the development, design and business part are collected on the links.
Useful links and contacts
Telegram-chat of voice interface developers
Telegram-chat Yandex.
Dialogues Slack-chat developers Amazon Alexa
Slack-chat developers Google Assistant
Guidelines Google Assistant
Guideline Amazon Alexa
Designing VUI book by Cathy Pearl
Book VUX best practices, Voicebot My own
book higher on Medium
Documentation Google Assistant
Documentation Amazon Alexa
Documentation Yandex.Alise
News, analytics
Contacts of speaker Pavel Guaya: Twitter and Linkedin profiles , and a blog on Medium .
In 2017, Starbucks launched a feature on ordering a coffee home for Amazon Alexa. In addition to the increase in delivery orders, all possible media outlets wrote about it, creating a cool PR. The example of Starbucks was followed by Uber, Domino's, MacDonald's, and even Tide washing powder had its own skill for Alexa.
Like Starbucks, the voice application performs one or two functions: ordering coffee, setting an alarm or calling a courier. To design something like this, it’s not necessary to be an intercontinental corporation. The idea, design, testing, development and release are similar to similar stages in the world of mobile development, but with features for voice. Pavel Guay told in detail about the process : from idea to publication, with examples of real games, with historical inserts and analysis of the world of voice development.
About speaker : Pavel Guay ( pavelgvay ) - designs voice interfaces in the KODE mobile development studio. The studio is developing mobile applications, for example, for Utair, Pobeda, RosEvroBank, BlueOrange Bank and Whiskas, but KODE has a division that deals with voice applications for Yandex.Alisa and Google Assistant. Pavel has participated in several real-world projects, exchanges experience with developers and designers in this area, including from the USA, and speaks at thematic conferences. In addition, Pavel is the founder of the startup tortu.io - a tool for the design of voice applications.
What is a conversational application
In a conversational application, the interaction channel with the user is built through a conversation : oral - with a smart column, or through a written one, for example, with Google Assistant. In addition to the column, the device of interaction can be a screen, therefore conversational applications are also graphical.
It is correct to speak a conversational application , not a voice one, but this is already an established term, and I will also use it.
Voice applications have an important advantage over mobile: they do not need to be downloaded and installed. It is enough to know the name, and the assistant will start everything himself.
All because there is nothing to download - both speech recognition and business logic - the entire application lives in the cloud. This is a huge advantage over mobile applications.
A bit of history
The history of voice assistants began with Interactive Voice Response - an interactive system of recorded voice responses. Perhaps no one heard this term, but everyone came across when they called technical support and heard the robot: “Press 1 to get to the main menu. Click 2 for more details ”- this is the IVR system. In part, IVR can be called the first generation of voice applications. Although they are already part of the story, they can teach us something.
When interacting with the IVR system, most people try to contact the operator. This is due to poor UX, when the interaction is based on hard commands, which is just inconvenient.
This brings us to the basic rule of a good conversational application.
A good conversational application interacts with the user not through strict commands, but through lively, natural conversation, similar to communication between people.
A conversation with the application should be more like a call to a pizzeria to order, than to communicate with the chat bot teams. To achieve the same flexibility as in a conversation between people will not work, but to speak with the application in a comfortable and natural language is completely.
This is also the advantage of a voice over graphic applications: no need to learn to use . My grandmother does not know how to enter sites or order pizza through the application, but she can call delivery through the column. We must use this advantage and adapt to how people say, and not teach them to talk with our application.
From IVR-systems we move on to the present - to virtual assistants.
Virtual Assistants
The voice world revolves around virtual assistants: Google Assistant , Amazon Alexa and Alice .
Everything is arranged almost like in the mobile world, but instead of iOS and Android platforms, Alice is here, Google Assistant and Alexa, instead of graphical applications, voice, with their own names or names, and each assistant has their own internal store of voice applications. Again, saying “application” is wrong, because each platform has its own term: Alice has “skills,” Alex has “skills,” and Google has “actions.”
To start the skill, I ask the assistant: “Alex, tell Starbucks that I want coffee!” Alex will find the application of the coffee shop in his store and transfer the conversation to him. The conversation goes not between Alex and the user, butbetween the user and the application . Many people are confused and think that the assistant continues to speak with them, although the application has a different voice.
This is how app stores look. The interface resembles the App Store and Google Play.
Stages of development of conversational applications
For the user, the application has no graphic part - everything looks like a set of dialogue. Outwardly, it may seem that the application is a simple thing, to create it is simple, but it is not. Stages of development are the same as for mobile applications.
- Design. In the case of voices, not drawing the screens, but working out the dialogues.
- The development is divided into two parts: the development of a system for understanding speech and writing logic.
- Testing.
- Publication.
The first two stages are specific, as the applications are conversational, and the last two are standard.
Let's go through each of the stages on the example of the game "Guess the price" , which is running under Google Assistant. The mechanics are simple: the application shows the user a card with the goods, and he must guess the price.
Let's start the dive from the first stage: we decided on an idea, conducted an analytics, realized that the user has a need and proceed to create a voice application.
Design
The main goal is to design the interaction between the user and the application. In the mobile world, this stage is called design. If the graphic application designer draws maps of the screens, buttons, shapes and selects colors, the VUI designer works out the dialogue between the user and the application: prescribes various branches of the dialogue, thinks about forks and side scenarios, chooses variants of phrases.
Design is carried out in three stages.
- Dialog examples.
- Drawing a flowchart.
- Making prompt lists.
Dialog examples
The first thing to do is to understand how the application will work. Understanding and vision will need to be broadcast on everyone else, especially if you are an outsourcing company, and you have to explain to the customer what he will receive in the end.
A powerful tool to help - examples of dialogue: a conversation between the user and the application on roles , as in the play.
An example of dialogue for our game.
The app greets, tells the user about the rules, offers to play, and, if the person agrees, shows a card with the goods so that the user guesses the price.
The script helps to quickly understand how the application will work, what it can do, but, in addition, examples of dialogues help weed out the main mistake in the world of voice interfaces -working on the wrong scenarios .
There is a simple rule: if you cannot imagine how you pronounce the script with another person, then you should not work on it.
Voice and graphics are significantly different, and not everything that works on graphical interfaces works well on voice. Almost every mobile application has a registration, but I can not imagine how you can register by voice? How to dictate a smart password column: "A capital letter, a small letter, es like a dollar ..." - and all this is out loud. And if I'm not alone, but at work? This is an example of an erroneous scenario. If you start developing a script with an error, problems will arise with it: you will not understand how to execute it, users will not understand how to use it.
Examples of dialogues will help to find such moments. To find errors in the scenarios, record the dialogue, select a colleague, put them in front of you and play the roles: you are the user, the colleague is the application. After role-playing the dialogue, it becomes clear whether the application sounds or not, and whether the user will be comfortable.
Such a problem will appear constantly. If you have an in-house development, there will be a temptation: “We already have a website, let's just convert it to voice and everything will be fine!” Or the customer will come and say: “Here is the mobile application. Do the same with your voice! ”But you can't do that. You, as a specialist, should quickly find scenarios that should not be worked on, and explain to the customer why. Dialog examples here will help.
Absolutely any text editor you are used to will be suitable for writing dialogs. The main thing - write down the text and read it by roles.
Block diagram
Dialogue examples are powerful, fast, and cheap, but they only describe linear developments, and conversations are always non-linear . For example, in our game “Guess the price”, the user can answer the question correctly or incorrectly - this is the first fork in the set of those that will be encountered later.
In order not to get confused in all branches of the dialogue of your application, make a flowchart - visualization of the dialogue. It consists of only two elements:
- Step dialogue on behalf of the user.
- Step dialogue on behalf of the application.
The block diagram is a map of our application, but with one unpleasant property - it grows heavily, becomes unreadable and visually incomprehensible. Here, for example, a screenshot with a part of the flowchart from the scenario where the user guesses the price, with several forks.
A few forks is not the limit, there may be tens or hundreds. We asked ourselves the questions: “What happens if a person answers correctly? And if not? What happens if the attempts end? What if the goods run out? And if he guesses the price exactly? What if the Internet disappears at this step or at another? ”As a result, we created a huge unreadable scheme.
In this we are not alone. I spoke with a designer from the USA who was working on a serious project. In the project there was an IVR, a bank, and a skill at the same time, and the whole thing inflated the flowchart to 600 sheets. Nobody understood the scheme to the end, and when the designer saw it, she was simply terrified.
I have advice on how to prevent this. The scheme will always grow, but never try to build one big flowchart for the whole application - it will be cumbersome, and no one except you will understand it. Go back and break the circuit into logical parts.: a separate price guessing scenario, a separate help script. If necessary, break these scripts into sub-scenarios. The result is not one big map with incomprehensible connections, but many small, readable, well-connected schemes in which it is convenient for everyone to navigate.
For flowcharts fit any tool. I used to use RealtimeBoard , but I also have Draw.io and even XMind . As a result, I developed my own, because it is simply more convenient. In the picture it is just presented. This tool supports, including, a breakdown into subscenarios.
prompt lists
The last artifact we will form at the design stage. The prompt list is a list of all possible phrases that an application can say.
There is one subtlety. Conversation with the application should be flexible and similar to a conversation with a person. This means not only the opportunity to go through different branches, which we did at the stage of the flowchart, but the sound of the conversation as a whole. A person will never answer with the same phrase if you ask the same question. The answer will always be rephrased and sound somehow different. The application should do the same, so for each step of the dialogue on behalf of the application write not one answer, but at least five.
According to the prompt lists there is another important thing. Communication should not only be lively and flexible, but also consistent.in terms of style of speech and the general feeling of user communication with your application. For this, designers use an excellent technique - character creation . When I call my friend, I do not see him, but subconsciously imagine the interlocutor. The user when communicating with a smart column is the same. This is called pareidalia .
At the prompt lists page, you create a character on whose behalf the application will speak. With a character, your users will associate a brand and an app — this can be a real person or a fictional one. Work on his appearance, biography, character and humor, but if there is no time, just bring all your phrases in the prompt sheets to the same style. If you started to contact the user on "You", then do not contact in other places on "You". If you have an informal communication style, stick to it everywhere.
Usually, Excel or Google spreadsheets are used to create the prompt sheets, but with them there are huge temporary losses for routine work. The block diagram and the tablet with the phrases are in no way connected with each other, any changes have to be transferred manually, which translates into a permanent and long routine.
I use not Excel, but my tool, because in it all the phrases are written directly in the flowchart, they are assigned to the step of the dialogue. It eliminates the routine.
In design, we work through each scenario: we write an example of a dialogue, we find side branches, errors, we cover it with a flowchart, and then we work on the style of speech and phrases.
It seems that now everything is ready and you can give the task to the developers and get to the code, but there is one more important stage left - testing. We need to make sure that as designers did everything correctly, that the application will work as we want, that all the phrases are in the same style, that we have covered all the side branches and processed all the errors.
Testing
Testing at this early stage is especially important for voice applications. In the world of graphical user interfaces, the user is limited by what the designer has drawn: he will not go beyond the screen, will not find a button that does not exist, but will only click on what is ...
In the world of voices, everything is wrong: the user is free to say everything that whatever you want, and you don’t know how it will work with your application until you see it. It is better to do this at an early design stage and prepare for the unexpected, before the expensive development begins.
Applications are tested using the Wizard of Oz methodology.. It is used in graphic applications, but less often, but in a voice it is a must have. This is a method when a user interacts with the system, assuming that it exists and works on its own, but you manage the whole process.
Testing is done using interactive prototypes. Usually the designer has to ask developers to create a prototype, but personally I use my tool, because everything is done in it with one click and you don’t have to wait for anyone. We also need a user. We call a person who is not involved in the development at all, does not know anything about the application and, ideally, is included in your Central Asia. You invite a person, explain what kind of application it is, how to use it, plant it in a room, turn on an interactive prototype and the user starts talking to him. The prototype does not recognize speech, and this is what you hear, what the person says, and choose the answer option with which the application responds to each phrase.
If the user does not see the screen, then it seems to him that the application works by itself, but the process is controlled by you. This is the testing of the Wizard of Oz. With it, you will not only hear the sound of the application, but also see how people use it. I guarantee that you will find many uncovered scripts.
When I tested the game, I called my friend. He began to guess the price and said that some kind of ointment was worth "pyatikhat." I did not expect such a word, I thought that there would be options of 500 rubles, a thousand rubles, and not “pyatikhat” or “mower”. This is a trifle that came to light on testing. People use the application differently than you imagine, and testing reveals such trifles and non-working scenarios.
Test a lot and for a long time before developing until you are sure that the application is working and users interact with it as you expect.
This is where the design phase ends and we have examples of dialogues in our hands, a block diagram is a logical description of the operation of an application, and prompt-lists are what the application says. We will give all this to the developers. Before I tell you how developers create applications, I’ll share design tips.
Tips
Use SSML markup language - as HTML, only for speech. SSML allows you to pause, set the level of empathy, stress, prescribe what to spell and where to focus.
Marked speech sounds much better than the robot speech, and the better the application sounds, the more pleasant it is to use it. Therefore, use SSML - it is not so complicated.
Think about the moments in which users turn to your application for help.This is especially important for voice. A person can talk to a speaker alone in a room, or he can ride a bus and talk to a smartphone. These are two fundamentally different behavior scenarios for a voice application. We had a similar situation with the banking application. In the application there was a script when the user receives information about the account, and this is private information. I thought that if a person is talking at home, then everything is fine, but if he is traveling on a bus, and the application starts to voice the card balance out loud, it will be ugly.
Thinking about these moments, you can determine that if the user is talking to a smartphone, even if by voice, then it is better not to read out private information, but to show it on the screen.
Use multimodal design.
This is a design for different surfaces and platforms. Voice devices are very different in their texture. In the mobile world, devices differ only in platform and screen size - form factor. The voice is different. For example, the speaker has no screen at all - only a voice. The smartphone has a screen, and you can tap it with your finger. The TV screen is huge, but it is useless to touch it. Think about how your application will work on each of these surfaces.
For example, a user made a purchase and we want to show a receipt. Reading the check out loud is a bad idea, because there is a lot of information and no one will remember it, because voice information is perceived difficult and difficult.
Using the principle of multimodal design, we understand that if there is a screen, then the check is better to show, instead of reading. If there is no screen, then we are forced to speak out loud the main data of the check.
This design is complete. What I have told is the basics, the tip of the iceberg. For self-study design, I gathered a lot of material on the design, at the end of the article will be links.
Development
We begin the conversation with a universal scheme of the application under any platform. The scheme works with Alice, Amazon Alexa, and Google Assistant.
When a user asks to start our application, the assistant does this and transfers control of the conversation to the application. The user says something and the application gets the raw text, which is processed by the speech recognition system.
- The raw text system determines the intent of the user — the intent , its parameters — slots , and forms the answer: immediately, if no logic and additional information is required, and uses the webhook , if logic is necessary. All business logic in voice applications lies in a webhook, from there requests are made to databases, API calls.
- The answer is formed and transmitted to the user by voice or shown on the screen.
For processing, we use Dialogflow , its structure is absolutely the same as that of other speech understanding systems, and we will consider the development using its example.
We are moving to the first link - the human speech understanding system or Natural Language Understanding - NLU.
Dialogflow
We use Dialogflow, because it has rich features, good documentation, live support and it is easy and quick to master. Dialogflow cross-platform tool: the main qualification is applications for Google Assistant, but for Yandex-Alice, Amazon Alexa and creating bots in Telegram it can also be used. Separate plus - open API. You can use the system to develop voice control for a website or an existing mobile application.
The main components of Dialogflow.
- Agent - your project, what's inside.
- Intents - the intentions of the user.
- Entities - data objects.
- Contexts - contexts, repositories for information.
Let's go through all the components, but let's start with the main thing - this is Intents.
Intents
This is a user intention , what the user wants to accomplish. Intention expressed phrases. For example, in the game, the user wants to know the rules of the game and says: “Tell the rules of the game”, “Tell me how to play?”, “Help me - I'm confused” or something like that. Accordingly, we create a separate Intent for the rules of the game, and at the input we write all these phrases that we expect from the user.
I advise you to write 10 or more phrases. In this case, speech recognition will work better, because Dialogflow uses a neural network that accepts these 10 input phrases and generates a bunch of other similar ones from them. The more options, the better, but do not overdo it.
Intent should have the answer to any user question. In Dialogflow, an answer can be formed without applying logic, and if logic is needed, then we transmit the answer from the webhook. The answers may be different, but the standard one is the text: it is sounded on the speakers, shown or spoken on smartphones.
Depending on the platform, additional “buns” are available - graphic elements. For example, for Google Assistant, these are buttons, flashcards, lists, carousels. They are shown only if a person speaks with Google Assistant on a smartphone, TV, or other similar device.
Entities
Intent starts when the user says something. At this moment information is transmitted - the parameters, which are called slots , and the data type of the parameters - Entities . For example, for our game, these are examples of phrases that the user says when he guesses the price. There are two parameters: amount and currency.
Parameters may be required and optional . If the user answers "two thousand", then the phrase will be enough. By default, we take rubles, so the currency is an optional parameter. But without the sum, we cannot understand the answer, because the user can answer the question not specifically:
- How much does it cost?
- A lot!
For such cases, Dialogflow has the concept of re-prompt - this is the phrase that will be uttered when the user does not name the required parameter. For each parameter, the phrase is set separately. For the sum, it could be something like: "Give the exact figure how much it costs ..."
Each parameter must have a data type - Entities. Dialogflow has many standard data types - cities, names, and it saves. The system itself determines what is the name, what is the number, and what the city is, but you can also set your own custom types. Dialogflow currency is a custom type. We created it ourselves ^ described a technical system name, which we will use, and synonyms that correspond to this parameter. For the currency is the ruble, dollar, euro. When the user says: “Euro”, Dialogflow highlights that this is our “currency” parameter.
Context
Think of this word literally: context is the context of what you are talking about with the user. For example, you can ask the assistant: “Who wrote Mumu?” And he will answer that it is Turgenev. After that you can ask when he was born. I pay attention that we ask: "When he was born", without specifying who. Google will understand, because it remembers - in the context of the conversation Turgenev.
From a technical point of view, context is a key-value repositoryin which the information is stored. Intent can either emit the context from itself, add something to it, or accept it as input and retrieve information from there. The context has a lifetime. It is determined by the number of steps of the dialogue from the last mention: for example, after 5 steps of the dialogue, forget what we said about Turgenev.
The context has another important function - it can help us break the application into logical zones: into authorized and unauthorized ones, into a gaming session or not. The breakdown is constructed in such a way that the Intent that accepts a context for input cannot be started without a context and requires a previous launch of another Intent. So we can logically link and build our application.
I mentioned webhook. Dialogflow has libraries for completely different languages, we used JS. Google Assistant for webhook has a limitation - the answer from it should come no later than 5 seconds, otherwise an error will occur and the application will work in the fallback. For Alice, the response time is 1.5 or 3 seconds.
We set up a speech understanding system, wrote a webhook and everything works for us, we launched QA, and now is the time for publication.
Publication
The publication is standard, almost like with mobile applications, but with a couple of nuances.
Pay a separate, special and very close attention to the name of the application . The user will say it out loud every time you start. Therefore, the name should be easy to pronounce and easy to recognize by an assistant, because sometimes there are problems with this.
The name has two rules:
- You can not use common phrases . In Yandex.Alisa, you can not use verbs. For example, you will not be able to take the name "Taxi Order" because it is a common phrase that many people want to use.
- If you want to use the name of your company, then be prepared for the fact that you will be asked to confirm the rights to use the brand .
In Google Assistant, the standard phrase that launches any application is “OK, Google, talk to ...”. You can use this feature, for example, say: “OK, Google, talk to Uber” - and he will launch the application on the main screen, at the starting point. But you can make the user say, “OK, Google, tell Uber to pick me up from here and take me there!” We shorten one iteration, and the user gets into the desired action.
The script is determined by the phrases that launch the application. They are installed when publishing, but often work incorrectly - in Russian for sure. For example, in our game, the phrase “Let's sy gray” worked, and “Let 's goplay "did not work. I do not know what the fundamental difference between "play" and "play" for Google Assistant. He recognized both phrases correctly, but the application did not work, although we had no problems with the English language.
The rest of the publication runs smoothly, without any questions. Support for Google Assistant is very lively, responds quickly, and the documentation is good.
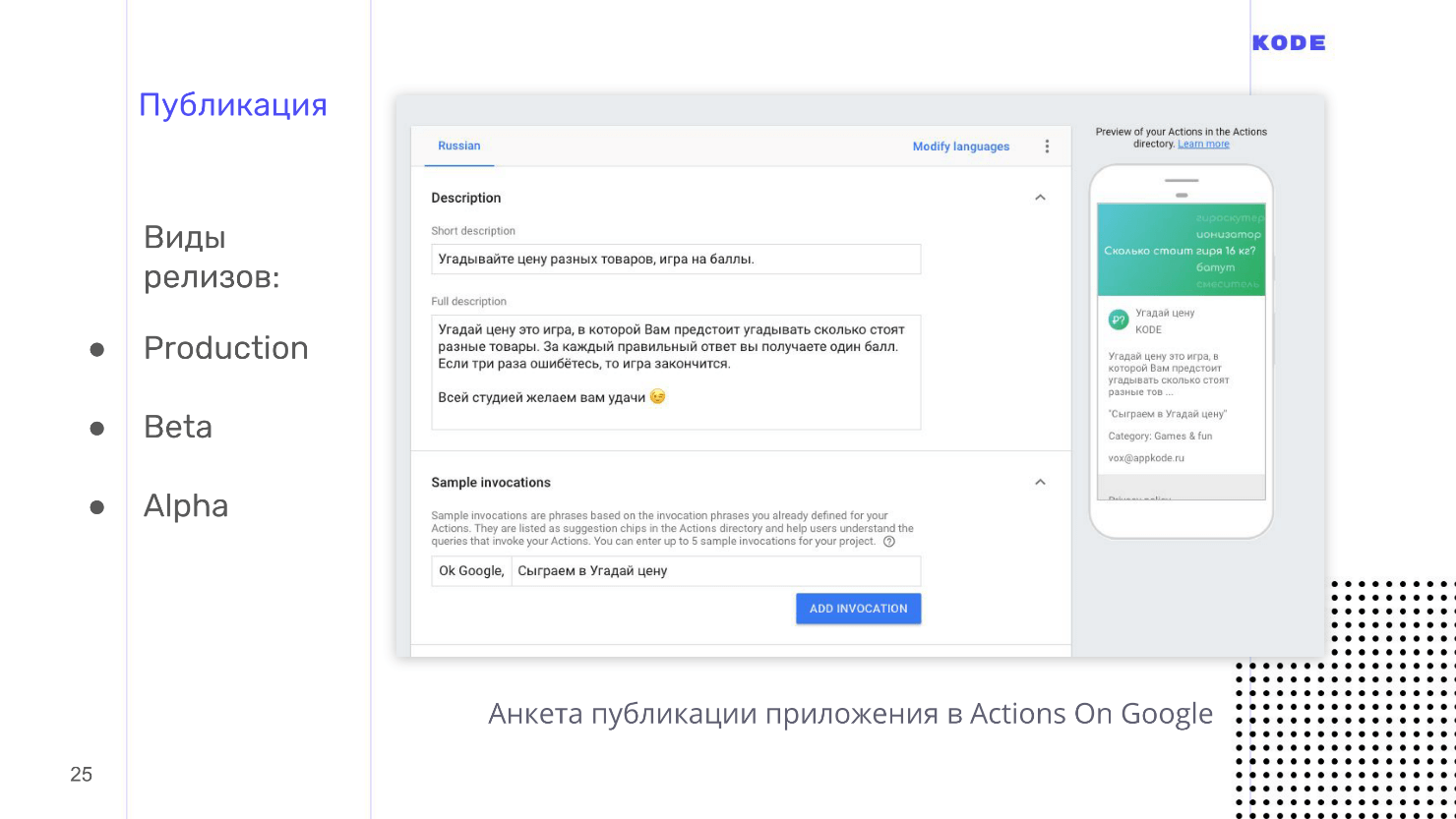
I also want to mention different types of releases.
- Alpha - for 20 people and without passing review.
- Beta - for 200 people.
- Production release - when the application gets to the store. If we publish in Production, then we must pass a review. People from Google manually check how the application works, and send feedback. If all is well, the application is published. If not, then you receive a letter with edits that does not work in your application and what to fix.
It would seem that this is all, but we are talking about the voice, so there is another important point here - this is the analyst.
Analytics
Especially important for voice. If for mobile applications, the analyst shows jambs, bugs and system errors, but in the world of voice, the analyst reveals missed opportunities to us - how people wanted to use our application, but could not.
This is a mandatory step. That is why Dialogflow has standard application analysis tools with the following modes:
- History - impersonal history of conversations with your application.
- Learning is an interesting mode that shows all the phrases that the application has recognized, but has not been able to process.
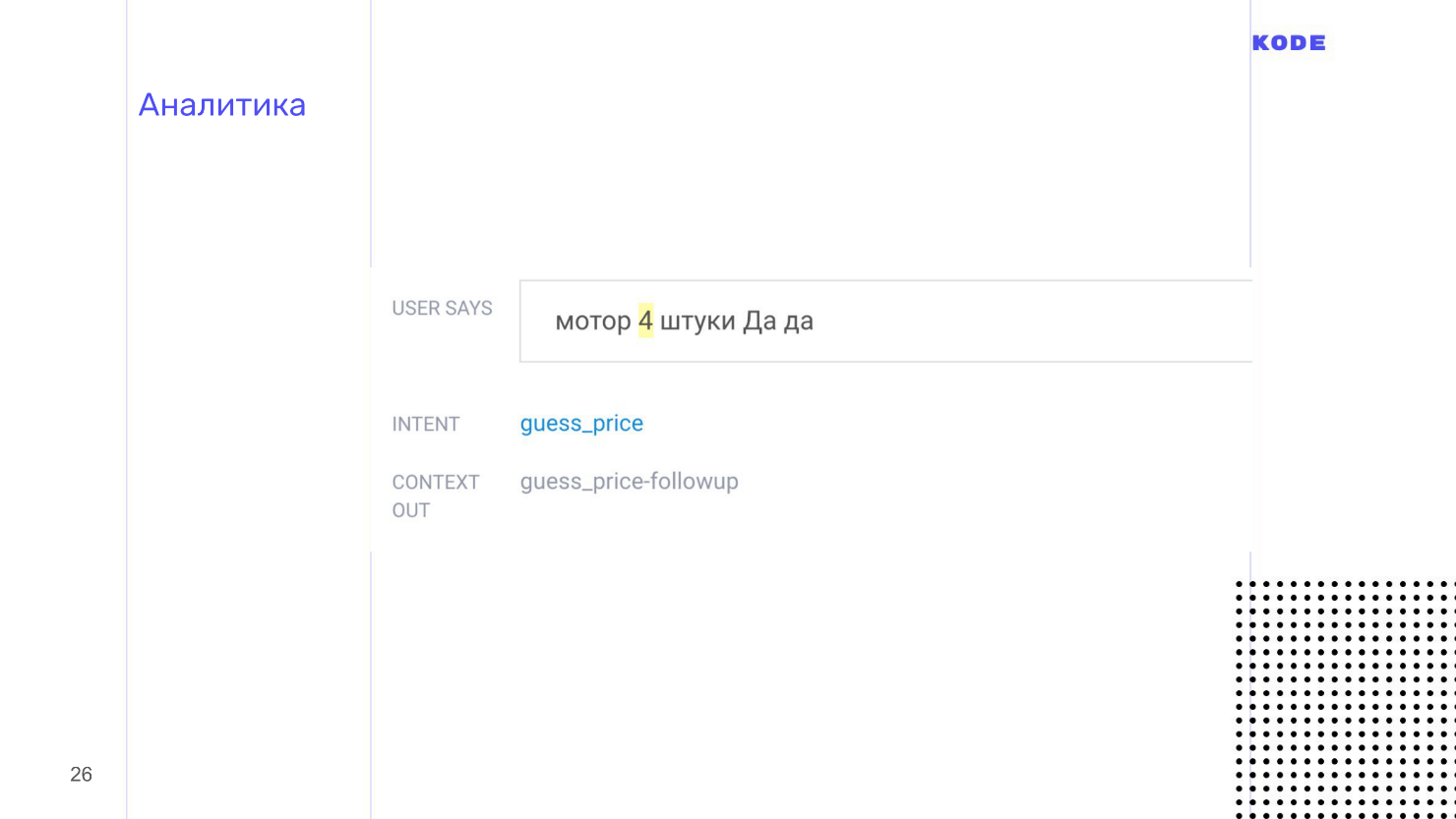
They are shown in a list and look like in the picture. The user guessed the price of a motor and said: "4 pieces." I remembered about the "mowers" for testing, but I forgot about the "things" - so I’ll have to fix it.
Analytics helps to find flaws, so be sure to look in the logs and check what happens to your application and what users do with it.
That's all about voice applications. I hope that you have at least a minimal understanding of how they are developed. The report was general, but all additional materials about the development, design and business part are collected on the links.
Useful links and contacts
Telegram-chat of voice interface developers
Telegram-chat Yandex.
Dialogues Slack-chat developers Amazon Alexa
Slack-chat developers Google Assistant
Guidelines Google Assistant
Guideline Amazon Alexa
Designing VUI book by Cathy Pearl
Book VUX best practices, Voicebot My own
book higher on Medium
Documentation Google Assistant
Documentation Amazon Alexa
Documentation Yandex.Alise
News, analytics
Contacts of speaker Pavel Guaya: Twitter and Linkedin profiles , and a blog on Medium .
AppsConf 2019 will be held in the center of Moscow, in Infospace on April 22 and 23. We promise even more usefulness in mobile development than last year, so book a ticket or leave a request for a report .
To keep up to date with news and announcements of reports - subscribe to our newsletter and YouTube channel on mobile development .
Only AppsConf, only hardcore!