Neural networks and character recognition
 Recently on Habré has appeared, and also there are many substantial articles describing the work and the principle of the concept of “neural network”, but, unfortunately, as always there is very little description and analysis of the practical results obtained or not received. I think that many, like me, are more comfortable, easier and more understandable to understand a real example. Therefore, in this article I will try to describe an almost step-by-step solution to the problem of recognizing letters of the Latin alphabet + an example for independent research. The recognition of numbers using a single-layer perceptron has already been done, now let's figure it out and teach the computer how to recognize letters.
Recently on Habré has appeared, and also there are many substantial articles describing the work and the principle of the concept of “neural network”, but, unfortunately, as always there is very little description and analysis of the practical results obtained or not received. I think that many, like me, are more comfortable, easier and more understandable to understand a real example. Therefore, in this article I will try to describe an almost step-by-step solution to the problem of recognizing letters of the Latin alphabet + an example for independent research. The recognition of numbers using a single-layer perceptron has already been done, now let's figure it out and teach the computer how to recognize letters.Our problem
In short, I will say that neural networks in general can solve a very wide range of practical problems, in particular, recognition tasks. In most cases, the latter have a "template" character. For example, a system that "reads" bank checks, in terms of efficiency, is several times superior to the operator. In tasks of such a plan, the use of neural networks is justified and significantly saves money and resources.
Decide what we need to parse, understand and do. We need to build an expert system that can recognize the letters of the Latin alphabet. To do this, you need to understand the capabilities of neural networks (NS) and build a system that can recognize the letters of the Latin alphabet. Details of the theory of neural networks can be found at the links provided at the end of the article. This article does not find a description of the theory (mathematics) of NS operation or a description of commands when working with MATLAB (well, only if the links are at the end of the article), this remains on your conscience. The aim of the article is to show and tell the use of a neural network for a practical task, to show results, run into pitfalls, try to show that it is possible to squeeze out of a neural network without going into details about how it is implemented,
Let's try to figure out the possibilities when using a neural network with the back propagation of errors in order to recognize letters of the Latin alphabet. We will implement the algorithm in the software environment of the mathematical mathematical package MATLAB, namely, the power of the Neural Network Toolbox will be needed.
What is given
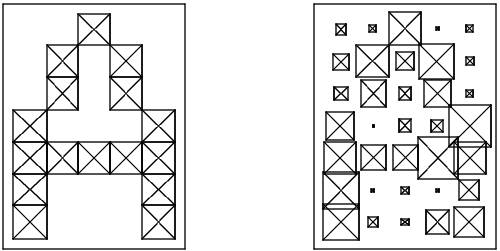
It is necessary to deal with the input data. We all imagine what the letters are, how they look on the monitor in a book, etc. (as, for example, presented in the figure below).

In reality, you often have to work not with ideal letters, as shown above, but more often as shown below, that is, distortions are introduced into the characters.

Now back to the problem of representing an image that is understandable for a neural network. It is clear that each letter in the image can be represented as a matrix with certain values of elements that can clearly identify the letter. That is, the representation of a character of the Latin alphabet is conveniently formalized by a matrix of n rows and m columns. Each element of such a matrix can take values in the range [0, 1]. So, the symbol A in such a formalized form will look like this (on the left - without distortion, on the right - with distortion):
Having not much imagined what is happening in the head, let us proceed with the implementation of this in MATLAB. The Latin alphabet is already provided in this package, there is even a demo example of working with it, but we will take only the alphabet from it. Therefore, you can use their data, or you can even draw all the letters yourself, this is optional.
MATLAB offers characters formalized by a matrix of 7 rows and 5 columns. But such a matrix cannot just be fed to the input of a neural network, for this it is still necessary to collect a 35 - element vector.
For compatibility with various versions and convenience, I saved the matrix of characters in a file (and you can use the prprob function, it will load the alphabet into the workspace).
From theory it is known that we need input data and output data (targets, target data) for training the network. The target vector will contain 26 elements, where one of the elements has a value of 1, and all other elements are 0, the number of the element containing the unit encodes the corresponding letter of the alphabet.
To summarize, an input 35-element vector is applied to the input of the neural network, which is compared with the corresponding letter from the 26-element output vector. The output of the NS is a 26-element vector, in which only one element that encodes the corresponding letter of the alphabet is 1. Having dealt with the creation of the interface for working with the NS, we will begin to create it.
Network building
We will build a neural network, which includes 35 inputs (because the vector consists of 35 elements) and 26 outputs (because there are 26 letters). This NS is a two-layer network. The activation function is a logarithmic sigmoid function, which is convenient to use because the output vectors contain elements with values in the range from 0 to 1, which can then be conveniently converted to Boolean algebra. We will allocate 10 neurons to the hidden level (because just like that, any value can be, then we’ll check how many of them are needed). If something is not clear to you from what was written above about building a network, please read about it in the literature (necessary concepts if you intend to work with NS). Schematically considered network can be represented by the following scheme:
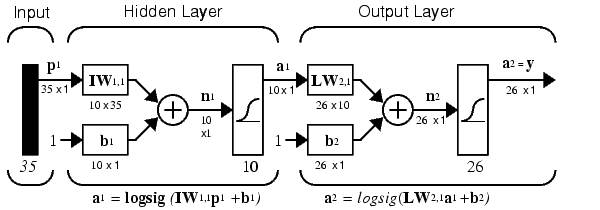
And if you write this in the syntax of the script language MATLAB, that's it, we get:
- S1 = 10; % количество нейронов на скрытом слое
- [S2,Q] = size(targets); % количество нейронов на втором слое (количество выходов сети)
- P = alphabet; % входная матрица, содержащая информацию о буквах
- % создаем новую сеть с использованием диалогового окна
- net = newff(minmax(P), % матрица минимальных и максимальных значений строк входной матрицы
- [S1 S2], % количество нейронов на слоях
- {’logsig’ ’logsig’}, % функция активации
- ’traingdx’ % алгоритм подстройки весов и смещений (обучающий алгоритм)
- );
Network training
Now that the National Assembly has been created, it is necessary to train it, because she, as a small child, knows nothing, a completely blank sheet. The neural network is trained using the backpropagation procedure - propagation of error signals from the NS outputs to its inputs, in the direction opposite to the direct propagation of signals in normal operation mode (there are still training methods, this is considered the most basic, and all others are modifications).
To create a neural network that can work with noisy input data, it is necessary to train the network by supplying data with or without noise. To do this, you must first train the network by supplying data without a noise component. Then, when we train the network on ideal data, we will train on sets of ideal and noisy input data (as we will see later, it is very important because such training increases the percentage of correct recognition of letters).
For all workouts, the traingdx function is used - a network training function that modifies the values of weights and offsets using the gradient descent method, taking into account the moments and using adaptive training.
First you need to train the network on noisy data, that is, starting with a simple one. In principle, the training order is not particularly important, but often changing the order, you can get a different quality of the adequacy of the National Assembly. Then, in order to be able to make a neural system that will not be sensitive to noise, we train the network with two ideal copies and two copies containing noise (noise with a dispersion of 0.1 and 0.2 is added). The target value will therefore contain 4 copies of the target vector.
After completing training with noisy input data, it is necessary to repeat training with ideal input data in order for the neural network to successfully cope with ideal input data. I don’t cite the pieces of code because they are very simple; one train function is used , which is easy to apply.
Network testing
The most interesting and significant stage is what we got. To do this, I will give dependency graphs with comments.
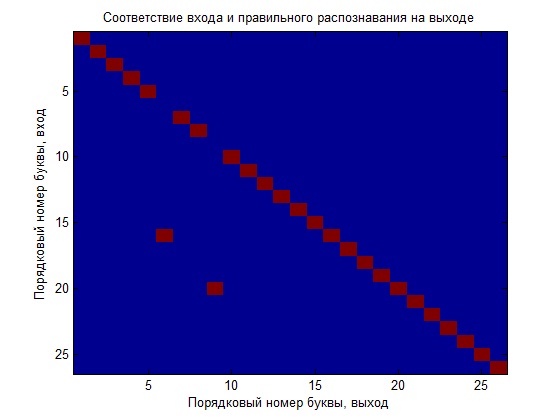
At first we trained the network only on ideal data and now we will see how it copes with recognition. For clarity, I will build a graph illustrating the input output ratio, that is, the number of the letter at the input should correspond to the number of the letter at the output (the ideal recognition would be the case when we get the diagonal of the quadrant on the graph).

It can be seen that the network did a poor job, of course you can play around with the training parameters (which is desirable), and this will give the best result, but we will make another comparison, create a new network and train it with noisy data, and then compare the resulting NSs.
Now back to the question, how many neurons in the hidden layer should be. To do this, we construct a relationship that clearly shows the ratio of neurons in the hidden layer and the percentage of erroneous recognition.

As you can see, with an increase in the number of neurons, one can achieve 100% recognition of input data. Also, an increase in the probability of correct recognition will be repeated training of a wound of a trained neural network with a large amount of data. After this stage, it is easy to notice that the percentage of correct recognition of letters is increasing. True, everything works well until a certain point, because when the number of more than 25 neurons is visible, the network begins to make mistakes.
Remember that we are going to train another network, using in addition to ideal data, also noisy data and compare. So let's look at which network is better, based on the results obtained in the graph below.
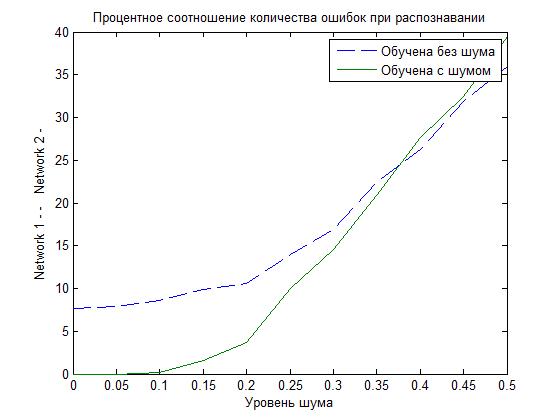
As you can see, with a not significant noise, the NS, which was trained with distorted data, copes much better (the percentage of erroneous recognition is lower).
Summarizing
I tried not to languish with details and trifles, tried to organize a “Murzilka” (a magazine with pictures), just to understand what the use of NS was.
Regarding the obtained results, they indicate that in order to increase the amount of correct recognition, it is necessary to train (train) the neural network and increase the number of neurons in the hidden layer. If possible, then increase the resolution of input vectors, for example, a 10x14 matrix formalizes a letter. The most important thing is that in the learning process it is necessary to use a larger number of sets of input data, if possible with greater noise of useful information.
Below is an example in which everything is described and described in the article (even a little more). I tried to tell you something useful and not to load with some strange formulas. More articles are planned, but it all depends on your wishes.
Example and literature
CharacterRecognition.zip
A selection of articles on neural networks
Description of neural network algorithms