Visualization of the flow of work in Node.js
In the comments to my previous topic on asynchronous programming, callbacks and the use of process.NextTick () in Node.js, many questions were asked about how to get or get better performance when using non-blocking code. I will try to demonstrate this clearly :) The article is intended mainly to clarify some aspects of the work of Node.js (and libeio in its composition), which in words can be difficult to describe.
An example of request processing by a server with a blocking read:
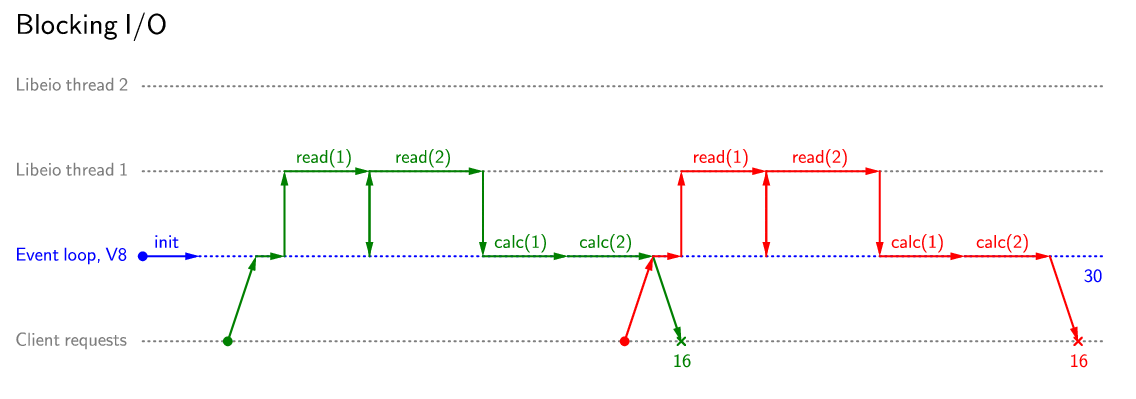
First of all, I will comment on the usefulness of using non-blocking I / O. As a rule, using blocking operations in Node.js is only at the initialization stage of the application, and that is not always the case. Correct error handling in any case will require the use of try / catch, so the code when using non-blocking operations will not be more complicated than when using blocking operations.
All you need to remember is that when there are more requests for non-blocking operations than there are libeio threads. In this case, new requests will queue and block execution, however, this will happen transparently for the programmer.
An example of processing requests from a server with a non-blocking read:

Of course, these two examples show the case when server performance is maximized. However, the benefit of non-blocking reading is at any time between incoming requests, even in the worst case it can be productively improved by involving libeio streams in the request processing process.
The total time for processing requests (the time between the client sending the first request and receiving the last processing result, the blue digit on the right) will be less in any case if there are enough threads for all requests. But even in the worst case, this time will not exceed the processing time when using synchronous read.
An example of reducing processing time when two requests arrive almost simultaneously:

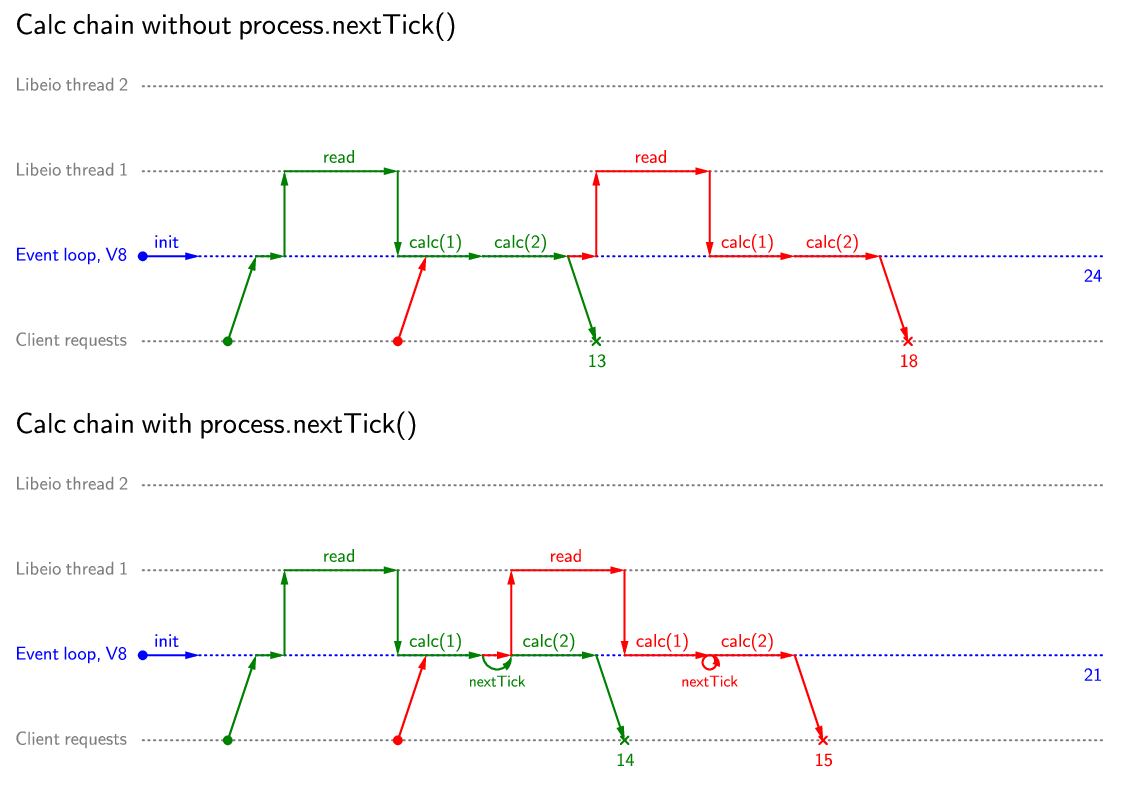
And here we come to the most illogical trick, which is used by Node.js programmers and can cause bewilderment for most developers. If I / O takes up most of the processing time of the request, then the rest of the code should not be optimized. However, the time it takes to get data from memcached can be commensurate with the runtime of the application business logic and templating. And if you use caching or a database in the memory of the Node.js process ( Dirty or Alfred ), then the working time with the database may be less than the working time of the rest of the application. Therefore, to break the code into separate parts and call the callbacks, use process.nextTick ():
Using this approach in separating the execution of calc (1) and calc (2), the total processing time for the previous example with almost simultaneous arrival of requests does not change, however, the first request will be returned to the client later.
An example of the “harm” from process.nextTick () when two requests arrive almost simultaneously:

However, this is the worst case in terms of applicability of process.nextTick (). In the event that requests come rarely, as in the first example considered, there will be no harm from process.nextTick () at all. If requests come with a “medium” frequency, the use of process.nextTick () will speed up the processing of requests due to the fact that at the time of interruption of the execution thread, the initial processing of a new request and the start of a non-blocking read may occur. In this case, both the total processing time and the average processing time of one request are reduced.
An example of the “good” from process.nextTick ():
To summarize the topic. First, when using Node.js, you should use non-blocking input / output. It is desirable even in cases where not the standard number of libeio streams is used, but a smaller one, or with a large number of incoming requests. emerging problems can be removed with the help of caching and in-process DB, and will not differ much from the use of other parallelization technologies. Secondly, the use of process.nextTick () “on average” can improve server performance, and in general it is more useful than harmful.
UPD (02.02): Slightly improved circuitry. Sources are available at: github.com/Sannis/papers_and_talks/tree/master/2011_node_article_async_process_nexttick .
An example of request processing by a server with a blocking read:
First of all, I will comment on the usefulness of using non-blocking I / O. As a rule, using blocking operations in Node.js is only at the initialization stage of the application, and that is not always the case. Correct error handling in any case will require the use of try / catch, so the code when using non-blocking operations will not be more complicated than when using blocking operations.
All you need to remember is that when there are more requests for non-blocking operations than there are libeio threads. In this case, new requests will queue and block execution, however, this will happen transparently for the programmer.
An example of processing requests from a server with a non-blocking read:
Of course, these two examples show the case when server performance is maximized. However, the benefit of non-blocking reading is at any time between incoming requests, even in the worst case it can be productively improved by involving libeio streams in the request processing process.
The total time for processing requests (the time between the client sending the first request and receiving the last processing result, the blue digit on the right) will be less in any case if there are enough threads for all requests. But even in the worst case, this time will not exceed the processing time when using synchronous read.
An example of reducing processing time when two requests arrive almost simultaneously:
And here we come to the most illogical trick, which is used by Node.js programmers and can cause bewilderment for most developers. If I / O takes up most of the processing time of the request, then the rest of the code should not be optimized. However, the time it takes to get data from memcached can be commensurate with the runtime of the application business logic and templating. And if you use caching or a database in the memory of the Node.js process ( Dirty or Alfred ), then the working time with the database may be less than the working time of the rest of the application. Therefore, to break the code into separate parts and call the callbacks, use process.nextTick ():
// blocking callbacksfunctionfunc1_cb(str, cb) {
var res = func1(str);
cb(res);
}
functionfunc2_cb(str, cb) {
var res = func2(str);
cb(res);
}
// non-blocking callbacksfunctionfunc1_cb(str, cb) {
var res = func1(str);
process.nextTick(function () {
cb(res);
});
}
functionfunc2_cb(str, cb) {
var res = func2(str);
process.nextTick(function () {
cb(res);
});
}
// usage example
func1_cb(content, function (str) {
func2_cb(str, function (result) {
// work with result
});
});Using this approach in separating the execution of calc (1) and calc (2), the total processing time for the previous example with almost simultaneous arrival of requests does not change, however, the first request will be returned to the client later.
An example of the “harm” from process.nextTick () when two requests arrive almost simultaneously:
However, this is the worst case in terms of applicability of process.nextTick (). In the event that requests come rarely, as in the first example considered, there will be no harm from process.nextTick () at all. If requests come with a “medium” frequency, the use of process.nextTick () will speed up the processing of requests due to the fact that at the time of interruption of the execution thread, the initial processing of a new request and the start of a non-blocking read may occur. In this case, both the total processing time and the average processing time of one request are reduced.
An example of the “good” from process.nextTick ():
To summarize the topic. First, when using Node.js, you should use non-blocking input / output. It is desirable even in cases where not the standard number of libeio streams is used, but a smaller one, or with a large number of incoming requests. emerging problems can be removed with the help of caching and in-process DB, and will not differ much from the use of other parallelization technologies. Secondly, the use of process.nextTick () “on average” can improve server performance, and in general it is more useful than harmful.
UPD (02.02): Slightly improved circuitry. Sources are available at: github.com/Sannis/papers_and_talks/tree/master/2011_node_article_async_process_nexttick .