Java Bytecode Fundamentals
- Transfer
Java developers usually don’t need to know about bytecode running in a virtual machine, but those who develop modern frameworks, compilers, or even Java tools may need to understand bytecode and maybe even understand how to use it. for their own purposes. Despite the fact that special libraries such as ASM, cglib, Javassist help in using bytecode, an understanding of the basics is necessary in order to use these libraries effectively.
The article describes the very basics from which you can build on further digging up this topic (approx. Per.).
Let's start with a simple example, namely a POJO with one field and a getter and setter for it.
When you compile the class using the javac Foo.java command, you will see the Foo.class file containing the bytecode. Here is how its contents look in a HEX editor:

Each pair of hexadecimal numbers (bytes) is translated into opcodes (mnemonics). It would be cruel to try to read this in binary format. Let's move on to the mnemonic representation.
The javap -c Foo command will output the bytecode:
The class is very simple, so it will be easy to see the relationship between the source code and the generated bytecode. First of all, we see that in the bytecode version of the class, the compiler calls the default constructor (as written in the JVM specifications).
Further, studying byte-code instructions (we have aload_0 and aload_1), we see that some of them have prefixes like aload_0 and istore_2. This refers to the type of data with which the instruction operates. The prefix “a” means that the opcode controls the reference to the object. "I", respectively, controls the integer.
An interesting point here is that some of the instructions operate on strange operands of type # 1 and # 2, which actually refers to the pool of class constants. It's time to study the class file closer. Run javap -c -s -verbose (-s to display signatures, -verbose to verbose output)
Now we see what kind of strange operands they are. For example, # 2:
const # 2 = Field # 3. # 18; // Foo.bar:Ljava/lang/String;
It refers to:
const # 3 = class # 19; // Foo
const # 18 = NameAndType # 5: # 6; // bar: Ljava / lang / String;
Etc.
Note that, each operation code is labeled with a number (0: aload_0). This is an indication of the position of the instruction inside the frame - I will further explain what this means.
To understand how bytecode works, just look at the execution model. The JVM uses a stack-based execution model. Each thread has a JVM stack containing frames. For example, if we run the application in the debugger, we will see the following frames:
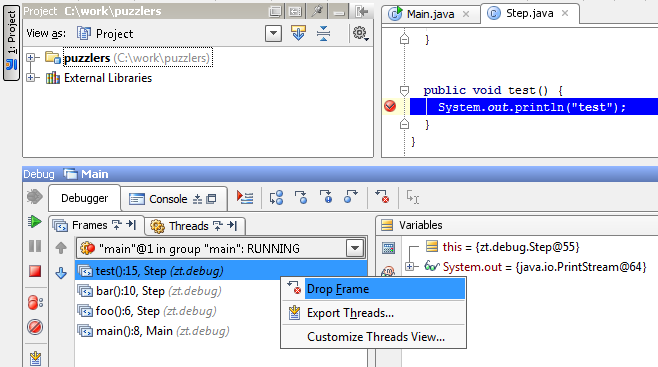
Each time the method is called, a new frame is created. The frame consists of the operand stack, an array of local variables, and a link to the pool of constants of the class of the executed method.
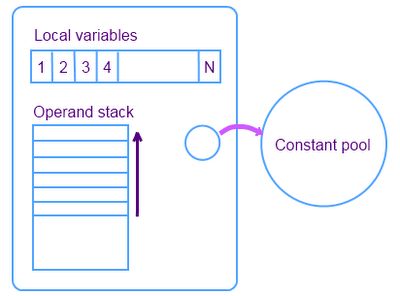
The size of the array of local variables is determined at compile time, depending on the number and size of local variables and method parameters. Stack of operands - LIFO-stack for writing and deleting values in the stack; size is also determined at compile time. Some opcodes add values to the stack, others take operands from the stack, change their state and return them to the stack. The operand stack is also used to get the values returned by the (return values) method.
The bytecode for this method consists of three opcodes. The first opcode, aload_0, pushes the value with index 0 from the table of local variables onto the stack. The this reference in the table of local variables for constructors and instance methods always has an index of 0. The next opcode, getfield, gets the object field. The last statement, areturn, returns the reference from the method.
Each method has a corresponding bytecode array. Looking at the contents of the .class file in the hex editor, you will see the following values in the bytecode array:
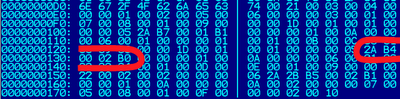
So, the bytecode for the getBar method is 2A B4 00 02 B0. 2A refers to aload_0, B0 refers to areturn. It may seem strange that the bytecode for the method has three instructions, and there are 5 elements in the byte array. This is due to the fact that getfield (B4) needs two parameters (00 02), occupying positions 2 and 3 in the array, hence 5 elements in the array. The areturn instruction is shifted 4 positions.
Table of local variables
To illustrate what happens with local variables, we use another example:
There are two local variables here - the method parameter and the local variable int b. Here's what the bytecode looks like:
LocalVariableTable:
Start Length Slot Name Signature
0 6 0 this LExample;
0 6 1 a I
2 4 2 b I
The method loads constant 1 with iconst_1 and puts it in local variable 2 with istore_2. Now, in the local variable table, slot 2 is occupied by variable b, as expected. Next, iload_1 loads the value onto the stack, iload_2 loads the value of b. iadd pops 2 operands from the stack, adds them and returns the value of the method.
Exception handling
An interesting example of how the bytecode is obtained in the case of exception handling, for example, for the try-catch-finally construct.
Bytecode for foo () method:
The compiler generates code for all the scripts possible inside the try-catch-finally: finallyMethod () block is called three times (!). The try block compiled as if there was no try and it was combined with finally:
0: aload_0
1: invokespecial # 2; // Method tryMethod :() V
4: aload_0
5: invokespecial # 3; // Method finallyMethod :() V
If the block is executed, the goto instruction throws the execution to the 30th position with the return opcode.
If tryMethod throws an Exception, the first suitable (internal) exception handler from the exception table will be selected. From the table of exceptions we see that the position with the exception catch is 11:
0 4 11 Class java / lang / Exception
This throws execution to catchMethod () and finallyMethod ():
11: astore_1
12: aload_0
13: invokespecial # 5; // catchMethod method :() V
16: aload_0
17: invokespecial # 3; // finallyMethod method :() V
If another exception is thrown during execution, we will see that in the exception table the position will be 23:
0 4 23 any
11 16 23 any
23 24 23 any
Instructions starting at
23:23: astore_2
24: aload_0
25: invokespecial # 3; // Method finallyMethod :() V
28: aload_2
29: athrow
30: return
So finallyMethod () will be executed anyway, with aload_2 and athrow throwing an unhandled exception.
Conclusion
These are just a few points from the JVM bytecode area. Most were from developerWorks Peter Haggar's article, Java bytecode: Understanding bytecode makes you a better programmer. The article is a bit outdated, but still relevant. The BCEL user guide contains a decent description of the basics of bytecode, so I would suggest reading it to those interested. In addition, the specification of a virtual machine can also be a useful source of information, but it is not easy to read, besides there is no graphic material that can be useful to understand.
In general, I think that understanding how bytecode works is an important point in deepening your knowledge of Java programming, especially for those who are looking at frameworks, JVM language compilers, or other utilities.
The article describes the very basics from which you can build on further digging up this topic (approx. Per.).
Let's start with a simple example, namely a POJO with one field and a getter and setter for it.
public class Foo {
private String bar;
public String getBar(){
return bar;
}
public void setBar(String bar) {
this.bar = bar;
}
}
When you compile the class using the javac Foo.java command, you will see the Foo.class file containing the bytecode. Here is how its contents look in a HEX editor:
Each pair of hexadecimal numbers (bytes) is translated into opcodes (mnemonics). It would be cruel to try to read this in binary format. Let's move on to the mnemonic representation.
The javap -c Foo command will output the bytecode:
public class Foo extends java.lang.Object {
public Foo();
Code:
0: aload_0
1: invokespecial #1; //Method java/lang/Object."":()V
4: return
public java.lang.String getBar();
Code:
0: aload_0
1: getfield #2; //Field bar:Ljava/lang/String;
4: areturn
public void setBar(java.lang.String);
Code:
0: aload_0
1: aload_1
2: putfield #2; //Field bar:Ljava/lang/String;
5: return
} The class is very simple, so it will be easy to see the relationship between the source code and the generated bytecode. First of all, we see that in the bytecode version of the class, the compiler calls the default constructor (as written in the JVM specifications).
Further, studying byte-code instructions (we have aload_0 and aload_1), we see that some of them have prefixes like aload_0 and istore_2. This refers to the type of data with which the instruction operates. The prefix “a” means that the opcode controls the reference to the object. "I", respectively, controls the integer.
An interesting point here is that some of the instructions operate on strange operands of type # 1 and # 2, which actually refers to the pool of class constants. It's time to study the class file closer. Run javap -c -s -verbose (-s to display signatures, -verbose to verbose output)
Compiled from "Foo.java"
public class Foo extends java.lang.Object
SourceFile: "Foo.java"
minor version: 0
major version: 50
Constant pool:
const #1 = Method #4.#17; // java/lang/Object."":()V
const #2 = Field #3.#18; // Foo.bar:Ljava/lang/String;
const #3 = class #19; // Foo
const #4 = class #20; // java/lang/Object
const #5 = Asciz bar;
const #6 = Asciz Ljava/lang/String;;
const #7 = Asciz ;
const #8 = Asciz ()V;
const #9 = Asciz Code;
const #10 = Asciz LineNumberTable;
const #11 = Asciz getBar;
const #12 = Asciz ()Ljava/lang/String;;
const #13 = Asciz setBar;
const #14 = Asciz (Ljava/lang/String;)V;
const #15 = Asciz SourceFile;
const #16 = Asciz Foo.java;
const #17 = NameAndType #7:#8;// "":()V
const #18 = NameAndType #5:#6;// bar:Ljava/lang/String;
const #19 = Asciz Foo;
const #20 = Asciz java/lang/Object;
{
public Foo();
Signature: ()V
Code:
Stack=1, Locals=1, Args_size=1
0: aload_0
1: invokespecial #1; //Method java/lang/Object."":()V
4: return
LineNumberTable:
line 1: 0
public java.lang.String getBar();
Signature: ()Ljava/lang/String;
Code:
Stack=1, Locals=1, Args_size=1
0: aload_0
1: getfield #2; //Field bar:Ljava/lang/String;
4: areturn
LineNumberTable:
line 5: 0
public void setBar(java.lang.String);
Signature: (Ljava/lang/String;)V
Code:
Stack=2, Locals=2, Args_size=2
0: aload_0
1: aload_1
2: putfield #2; //Field bar:Ljava/lang/String;
5: return
LineNumberTable:
line 8: 0
line 9: 5
}
Now we see what kind of strange operands they are. For example, # 2:
const # 2 = Field # 3. # 18; // Foo.bar:Ljava/lang/String;
It refers to:
const # 3 = class # 19; // Foo
const # 18 = NameAndType # 5: # 6; // bar: Ljava / lang / String;
Etc.
Note that, each operation code is labeled with a number (0: aload_0). This is an indication of the position of the instruction inside the frame - I will further explain what this means.
To understand how bytecode works, just look at the execution model. The JVM uses a stack-based execution model. Each thread has a JVM stack containing frames. For example, if we run the application in the debugger, we will see the following frames:
Each time the method is called, a new frame is created. The frame consists of the operand stack, an array of local variables, and a link to the pool of constants of the class of the executed method.
The size of the array of local variables is determined at compile time, depending on the number and size of local variables and method parameters. Stack of operands - LIFO-stack for writing and deleting values in the stack; size is also determined at compile time. Some opcodes add values to the stack, others take operands from the stack, change their state and return them to the stack. The operand stack is also used to get the values returned by the (return values) method.
public String getBar(){
return bar;
}
public java.lang.String getBar();
Code:
0: aload_0
1: getfield #2; //Field bar:Ljava/lang/String;
4: areturn
The bytecode for this method consists of three opcodes. The first opcode, aload_0, pushes the value with index 0 from the table of local variables onto the stack. The this reference in the table of local variables for constructors and instance methods always has an index of 0. The next opcode, getfield, gets the object field. The last statement, areturn, returns the reference from the method.
Each method has a corresponding bytecode array. Looking at the contents of the .class file in the hex editor, you will see the following values in the bytecode array:
So, the bytecode for the getBar method is 2A B4 00 02 B0. 2A refers to aload_0, B0 refers to areturn. It may seem strange that the bytecode for the method has three instructions, and there are 5 elements in the byte array. This is due to the fact that getfield (B4) needs two parameters (00 02), occupying positions 2 and 3 in the array, hence 5 elements in the array. The areturn instruction is shifted 4 positions.
Table of local variables
To illustrate what happens with local variables, we use another example:
public class Example {
public int plus(int a){
int b = 1;
return a + b;
}
}
There are two local variables here - the method parameter and the local variable int b. Here's what the bytecode looks like:
public int plus(int);
Code:
Stack=2, Locals=3, Args_size=2
0: iconst_1
1: istore_2
2: iload_1
3: iload_2
4: iadd
5: ireturn
LineNumberTable:
line 5: 0
line 6: 2
LocalVariableTable:
Start Length Slot Name Signature
0 6 0 this LExample;
0 6 1 a I
2 4 2 b I
The method loads constant 1 with iconst_1 and puts it in local variable 2 with istore_2. Now, in the local variable table, slot 2 is occupied by variable b, as expected. Next, iload_1 loads the value onto the stack, iload_2 loads the value of b. iadd pops 2 operands from the stack, adds them and returns the value of the method.
Exception handling
An interesting example of how the bytecode is obtained in the case of exception handling, for example, for the try-catch-finally construct.
public class ExceptionExample {
public void foo(){
try {
tryMethod();
}
catch (Exception e) {
catchMethod();
}finally{
finallyMethod();
}
}
private void tryMethod() throws Exception{}
private void catchMethod() {}
private void finallyMethod(){}
}
Bytecode for foo () method:
public void foo();
Code:
0: aload_0
1: invokespecial #2; //Method tryMethod:()V
4: aload_0
5: invokespecial #3; //Method finallyMethod:()V
8: goto 30
11: astore_1
12: aload_0
13: invokespecial #5; //Method catchMethod:()V
16: aload_0
17: invokespecial #3; //Method finallyMethod:()V
20: goto 30
23: astore_2
24: aload_0
25: invokespecial #3; //Method finallyMethod:()V
28: aload_2
29: athrow
30: return
Exception table:
from to target type
0 4 11 Class java/lang/Exception
0 4 23 any
11 16 23 any
23 24 23 any
The compiler generates code for all the scripts possible inside the try-catch-finally: finallyMethod () block is called three times (!). The try block compiled as if there was no try and it was combined with finally:
0: aload_0
1: invokespecial # 2; // Method tryMethod :() V
4: aload_0
5: invokespecial # 3; // Method finallyMethod :() V
If the block is executed, the goto instruction throws the execution to the 30th position with the return opcode.
If tryMethod throws an Exception, the first suitable (internal) exception handler from the exception table will be selected. From the table of exceptions we see that the position with the exception catch is 11:
0 4 11 Class java / lang / Exception
This throws execution to catchMethod () and finallyMethod ():
11: astore_1
12: aload_0
13: invokespecial # 5; // catchMethod method :() V
16: aload_0
17: invokespecial # 3; // finallyMethod method :() V
If another exception is thrown during execution, we will see that in the exception table the position will be 23:
0 4 23 any
11 16 23 any
23 24 23 any
Instructions starting at
23:23: astore_2
24: aload_0
25: invokespecial # 3; // Method finallyMethod :() V
28: aload_2
29: athrow
30: return
So finallyMethod () will be executed anyway, with aload_2 and athrow throwing an unhandled exception.
Conclusion
These are just a few points from the JVM bytecode area. Most were from developerWorks Peter Haggar's article, Java bytecode: Understanding bytecode makes you a better programmer. The article is a bit outdated, but still relevant. The BCEL user guide contains a decent description of the basics of bytecode, so I would suggest reading it to those interested. In addition, the specification of a virtual machine can also be a useful source of information, but it is not easy to read, besides there is no graphic material that can be useful to understand.
In general, I think that understanding how bytecode works is an important point in deepening your knowledge of Java programming, especially for those who are looking at frameworks, JVM language compilers, or other utilities.