Content-Based Image Search
Image databases can be very large and contain hundreds of thousands and even millions of images. In most cases, these databases are indexed by keywords only. These keywords are added to the database by the operator, which also distributes all the images into categories. But images can be found in the database and based on their own content. By content we can understand colors and their distribution, objects in the image and their spatial position, etc. Currently, segmentation and recognition algorithms are not well developed, however, now there are already several systems (including commercial) for searching images based on their content.
To work with the database of images, it is desirable to have some way of searching for images that would be more convenient and efficient than directly viewing the entire database. Most companies perform only two stages of processing: selection of images for inclusion in the database and classification of images by assigning keywords to them. Internet search engines usually get keywords automatically from picture captions. Using conventional databases, images can be found based on their text attributes. In a normal search, these attributes can be categories, the names of people in the image, and the date the image was created. To speed up the search, the contents of the database can be indexed in all of these fields. Then you can use the SQL language to search for images. For example, the query:
SELECT * FROM IMAGEBD
WHERE CATEGORY = ”MPEI”
could find and return all images from the database on which MPEI is depicted. But in reality, everything is not so simple. This type of search has a number of serious limitations. Assigning keywords to a person is a time consuming task. But, much worse, this task allows for ambiguous execution. Because of this, some of the images found can be very, very different from user expectations. The figure shows the issuance of google for the request "MEI". Taking as a fact that the use of keywords does not provide sufficient efficiency, we will consider a number of other image search methods.

Let's start with a pattern search. Instead of specifying keywords, the user could present a sample image to the system, or draw a sketch. Then our search engine should find similar images or images containing the desired objects. For simplicity, we assume that the user presents the system with a rough sketch of the expected image and some set of restrictions. If the user provides an empty sketch, then the system should return all images that meet the restrictions. Limitations are most logical to set in the form of keywords and various logical conditions that unite them. In the most general case, the request contains some kind of image that is compared with the images from the database according to the applied distance measure. If the distance is 0, then it is believed that the image exactly matches the request. Values greater than 0 correspond to varying degrees of similarity between the image in question and the request. The search engine should return images sorted by distance from the thumbnail.
The figure shows the searches in the QBIC system using distance measures based on the color layout. To determine the similarity of an image from a database with the image specified in the request, a certain measure of distance or characteristics is usually used, with which you can obtain a numerical estimate of the similarity of images. Similarity characteristics of images can be divided into four main groups: 1. Color similarity 2. Textural similarity 3. Similarity of form 4. Similarity of objects and relations between objects

For simplicity, we will only consider color similarity methods. Color similarity characteristics are often chosen very simple. They allow you to compare the color content of one image with the color content of another image or with the parameters specified in the request. For example, in the QBIC system, the user can specify the percentage of colors in the desired images. The figure shows a set of images obtained as a result of a query indicating 40% red, 30% yellow and 10% black. Although the images found contain very similar colors, the semantic content of these images is significantly different.

A similar search method is based on matching color histograms. Distance measures based on the color histogram should include an assessment of the similarity of two different colors. The QBIC system determines the distance as follows: where h (I), h (Q) are the histograms of the images I, Q, A is the similarity matrix. In the similarity matrix, elements whose values are close to 1 correspond to similar colors, close 0 correspond to very different colors. Another possible measure of distance is based on a color layout. When forming a request, the user is usually presented with an empty grid. For each cell, the user can specify a color from the table.
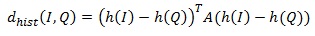
Similarity characteristics based on a color layout that use a shaded grid require a measure that takes into account the content of the two shaded grids. This measure should provide a comparison of each grid cell specified in the request with the corresponding grid cell of an arbitrary image from the database. Comparison results of all cells are combined to obtain the distance between the images: where C ^ I (g), C ^ Q (g) are the colors of cell g in images I, Q, respectively.
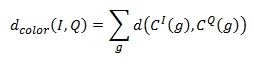
Searching on the basis of texture similarity, and even more so on the basis of similarity of form is much more complicated, but it is worth saying that the first steps have already been taken in this direction. For example, the ART MUSEUM system stores color images of many paintings. These color images are processed to provide an intermediate view. Pre-processing consists of three stages:
1. Reducing the image to a predetermined size and removing noise using a median filter.
2. Border detection. First, using the global threshold, then using the local threshold. The result is a cleared contour image.
3. On the cleared contour image, excess contours are removed. The resulting image is once again cleared of noise, and we get the required abstract representation.
When a user presents a sketch to the system, the same processing operations are performed on it, and we get a linear sketch. The matching algorithm has a correlation character: the image is divided into cells, and for each cell, the correlation with the same image cell from the database is calculated. For reliability, this procedure is performed several times for different linear sketch offset values. In most cases, this method allows you to successfully find the desired image.
It remains only to wait for the introduction of such systems in the familiar Internet search engines, and it will be possible to say that the problem of image search has become not so much a problem.
To work with the database of images, it is desirable to have some way of searching for images that would be more convenient and efficient than directly viewing the entire database. Most companies perform only two stages of processing: selection of images for inclusion in the database and classification of images by assigning keywords to them. Internet search engines usually get keywords automatically from picture captions. Using conventional databases, images can be found based on their text attributes. In a normal search, these attributes can be categories, the names of people in the image, and the date the image was created. To speed up the search, the contents of the database can be indexed in all of these fields. Then you can use the SQL language to search for images. For example, the query:
SELECT * FROM IMAGEBD
WHERE CATEGORY = ”MPEI”
could find and return all images from the database on which MPEI is depicted. But in reality, everything is not so simple. This type of search has a number of serious limitations. Assigning keywords to a person is a time consuming task. But, much worse, this task allows for ambiguous execution. Because of this, some of the images found can be very, very different from user expectations. The figure shows the issuance of google for the request "MEI". Taking as a fact that the use of keywords does not provide sufficient efficiency, we will consider a number of other image search methods.
Let's start with a pattern search. Instead of specifying keywords, the user could present a sample image to the system, or draw a sketch. Then our search engine should find similar images or images containing the desired objects. For simplicity, we assume that the user presents the system with a rough sketch of the expected image and some set of restrictions. If the user provides an empty sketch, then the system should return all images that meet the restrictions. Limitations are most logical to set in the form of keywords and various logical conditions that unite them. In the most general case, the request contains some kind of image that is compared with the images from the database according to the applied distance measure. If the distance is 0, then it is believed that the image exactly matches the request. Values greater than 0 correspond to varying degrees of similarity between the image in question and the request. The search engine should return images sorted by distance from the thumbnail.
The figure shows the searches in the QBIC system using distance measures based on the color layout. To determine the similarity of an image from a database with the image specified in the request, a certain measure of distance or characteristics is usually used, with which you can obtain a numerical estimate of the similarity of images. Similarity characteristics of images can be divided into four main groups: 1. Color similarity 2. Textural similarity 3. Similarity of form 4. Similarity of objects and relations between objects
For simplicity, we will only consider color similarity methods. Color similarity characteristics are often chosen very simple. They allow you to compare the color content of one image with the color content of another image or with the parameters specified in the request. For example, in the QBIC system, the user can specify the percentage of colors in the desired images. The figure shows a set of images obtained as a result of a query indicating 40% red, 30% yellow and 10% black. Although the images found contain very similar colors, the semantic content of these images is significantly different.
A similar search method is based on matching color histograms. Distance measures based on the color histogram should include an assessment of the similarity of two different colors. The QBIC system determines the distance as follows: where h (I), h (Q) are the histograms of the images I, Q, A is the similarity matrix. In the similarity matrix, elements whose values are close to 1 correspond to similar colors, close 0 correspond to very different colors. Another possible measure of distance is based on a color layout. When forming a request, the user is usually presented with an empty grid. For each cell, the user can specify a color from the table.
Similarity characteristics based on a color layout that use a shaded grid require a measure that takes into account the content of the two shaded grids. This measure should provide a comparison of each grid cell specified in the request with the corresponding grid cell of an arbitrary image from the database. Comparison results of all cells are combined to obtain the distance between the images: where C ^ I (g), C ^ Q (g) are the colors of cell g in images I, Q, respectively.
Searching on the basis of texture similarity, and even more so on the basis of similarity of form is much more complicated, but it is worth saying that the first steps have already been taken in this direction. For example, the ART MUSEUM system stores color images of many paintings. These color images are processed to provide an intermediate view. Pre-processing consists of three stages:
1. Reducing the image to a predetermined size and removing noise using a median filter.
2. Border detection. First, using the global threshold, then using the local threshold. The result is a cleared contour image.
3. On the cleared contour image, excess contours are removed. The resulting image is once again cleared of noise, and we get the required abstract representation.
When a user presents a sketch to the system, the same processing operations are performed on it, and we get a linear sketch. The matching algorithm has a correlation character: the image is divided into cells, and for each cell, the correlation with the same image cell from the database is calculated. For reliability, this procedure is performed several times for different linear sketch offset values. In most cases, this method allows you to successfully find the desired image.
It remains only to wait for the introduction of such systems in the familiar Internet search engines, and it will be possible to say that the problem of image search has become not so much a problem.