Oh these query plans
History is as old as the world. Two tables:
- Cities - 100 unique cities.
- People - 10 million people. For some people, the city may not be indicated.
The distribution of people by city is uniform.
Indices for the fields Cites.Id, Cites.Name, People .CityId are in stock.
You need to select the first 100 People entries sorted by Cites.
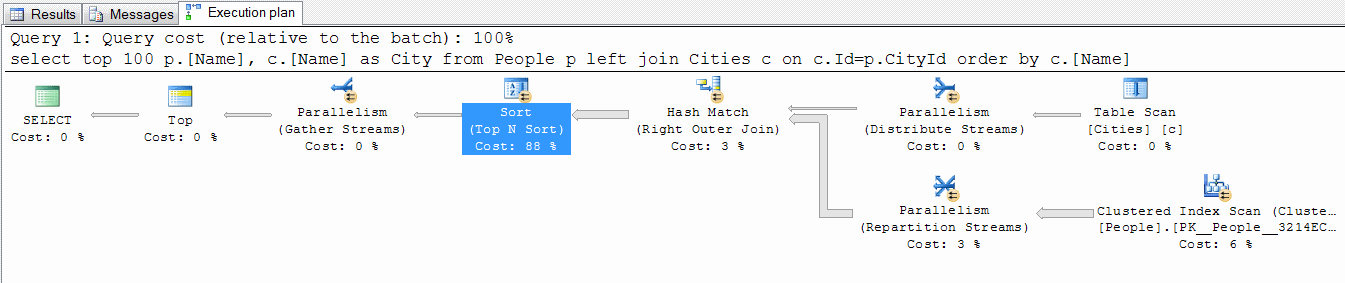
Having rolled up our sleeves, we cheerfully write: At the same time, we get something like: In ... 6 seconds. (MS SQL 2008 R2, i5 / 4Gb) But how so! Where is 6 seconds from ?! We know that in the first 100 entries there will be exclusively Almaty! After all, there are 10 million entries, which means the city accounts for 100 thousand. Even if this is not so, we can choose the first city in the list and check whether it will have at least 100 inhabitants. Why SQL Server, having statistics, does not do this:
select top 100 p.Name, c.Name as City from People p
left join Cities c on c.Id=p.CityId
order by c.Name
select * from People p
left join Cities c on c.Id=p.CityId
where p.CityId
in (select top 1 id from Cities order by Name)
order by c.[Name]
This query returns approximately 100 thousand records in less than a second! We were convinced that there were the required 100 records and gave them very, very quickly.
However, MSSQL does everything according to plan. And he has a plan, "pure thermonuclear poison" (c).
Question for experts:
how to fix the SQL query or do some action on the server to get the result 10 times faster on the first request?
PS PPS Where the legs grow from: The task is very real. There is a table with the main essence, many dimensions depart from it according to the “star” principle. The user needs to display it in the grid, providing sorting by fields.
CREATE TABLE [dbo].[People] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
[CityId] uniqueidentifier
)
ON [PRIMARY]
GO
CREATE TABLE [dbo].[Cities] (
[Id] uniqueidentifier NOT NULL,
[Name] nvarchar(50) NOT NULL,
)
ON [PRIMARY]
GO
Starting from a certain size of the main table, the sorting is reduced to the fact that a window with the same (extreme) values is selected (like "Almaty"), but the system starts to slow down terribly.
I would like to have ONE parameterized query that will work effectively with both the small size of the People table and the large one.
PPPS
Interestingly, if City were NotNull and InnerJoin was used, then the request is executed instantly.
Interestingly, EVEN IF the City field was NotNull but LeftJoin was used, the request slows down.
In the comments, the idea: First, select all InnerJoin and then Union by Null values. Tomorrow I will check this and other crazy ideas)
PPPPS I tried. It worked!
WITH Help AS
(
select top 100 p.Name, c.Name as City from People p
INNER join Cities c on c.Id = p.CityId
order by c.Name ASC
UNION
select top 100 p.Name, NULL as City from People p
WHERE p. CityId IS NULL
)
SELECT TOP 100 * FROM help
Gives 150 milliseconds under the same conditions! Thanks holem .