Comparative analysis of frameworks for working with ontologies for .NET and Java
It's no secret that the lion's share of projects related to the Semantic Web are being developed in Java. Semantic ontology frameworks are no exception: all major projects (Jena, OWL API, Sesame, etc.) are written specifically in Java. The only major representative using .NET is Intellidimension with RDF Gateway and Semantics.SDK .
In this article I will describe my experience with the above frameworks and share the test results.
This article is not a comprehensive overview of the above frameworks. The article is aimed at analyzing the performance of the basic capabilities of frameworks: loading ontology, inference, and executing SPARQL queries.
Before diving into the technical details, I’ll say a few words about the framework from Intellidimension (as the least known product for the Java-oriented community). Unlike the rest of the frameworks discussed in this article, which are OpenSource projects, RDF Gateway and Semantics.SDK are distributed with closed source codes and cost quite decent money. So, RDF Gateway 3.0 Enterprise alone costs $ 10,000 (although version 2.0 cost "just" $ 2,000). By the way, the risoners used during testing - Pellet and Owlim - are also not free: Pellet is distributed under a dual license, and Owlim offers only a version that works in memory for free; the version that works with storage costs 700 euros for each processor core used.
My task was to select a framework for implementing a project for .NET, so Java projects in their pure form did not interest me (initially I did not even plan to test them). It was necessary to choose an interop tool between Java and .NET. My choice fell on ikvm.net , which allows you to convert jars to .NET dll. Having received the .NET version of Jena, OWL API and Sesame, I set about testing them. However, testing would be incomplete if it did not contain the results of testing Java frameworks in their native environment. Thus, the following people participate in the testing: Intellidimension Semantics.SDK 1.0, OWL API 2.2.0 + Pellet 2.0rc5 (both under Java and under .NET), Jena 2.5.7 + Pellet2.0rc5 (both under Java and under .NET) and partly Sesame 2.24 + SwiftOwlim 3.0b9.
Sesame had to be excluded from the initial testing due to the policy of logical inference in Owlim that is different from the Semantic SDK and Pellet (Owlim is the main risoner used in conjunction with Sesame). So, Pellet and Semantic SDK are aimed at output during query (query-time reasoning), although they include means of early output; Owlim is aimed at full inference (full materialization). We will talk about this in the section "General information about risoners".
The NCI Institute Thesaurus 09.02d ontology was chosen as a test one. True, in its pure form, it contains a number of inconsistency. After communicating with the support service inconsistencies were identified. I used the modified version 09.02d (which you can downloadfrom my dropbox), although version 09.04d is already available, in which there are no inconsistencies.
For testing, the following situation was simulated:
1. First, the ontology from the file was loaded into the model;
2. Then 3 SparQL queries were sequentially executed to this model (query texts can be downloaded here ).
First, consider the results of testing the first stage:
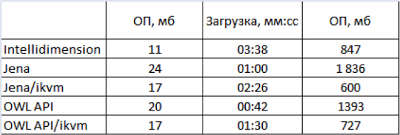
Despite the fact that .NET / ikvm frameworks are 2-3 times slower than their Java counterparts, they turned out to be faster than Intellidimension.
In terms of working with memory, .NET left a more pleasant impression. The Java garbage collector requires specifying the maximum amount of RAM that can be allocated to the heap (Xmx parameter); .NET uses a more logical, in my opinion, policy: it consumes as much memory as it needs (unless a restriction is specified). Xmx restriction is a very old bug, which, unfortunately, is still not fixed. As a solution, it is proposed to simply specify Xmx with a margin (if, of course, the amount of RAM allows), but in this case (testing was done with Xmx: 12g), the garbage collector does not bother itself (which we see from the test results). You can go the other way - select the minimum Xmx value for specific input data (though at the risk of running into an OutOfMemoryException). Thus, you can approximate the amount of memory consumed by the JVM to similar CLR indicators (albeit with some additional performance losses for more frequent garbage collections).
Regarding the limitation on the maximum amount of memory used, a rather curious case occurred. After successfully loading the Thesaurus ontology using the .NET OWL API converted to .NET, I decided to open this ontology in Protége (which is based on the same version of the OWL API) to familiarize myself with its structure. However, instead of a tree of concepts and instances, I got an OutOfMemoryException (despite the fact that there was plenty of free memory). Although the increase in the value of the Xmx attribute resolved the problem, such non-independence of the garbage collector in Java does not please. The funny thing is that despite the fact that the Java application does not start in its native environment (without dancing with the JVM), it works after converting to .NET using ikvm.
Now let's move on to the second point of testing - executing SPARQL queries. Unfortunately, at this stage you will have to leave behind the leader of the first test - OWL API. The fact is that the OWL API that the risoners implement does not contain methods for executing SPARQL queries. This is due to the fact that SPARQL was created as a query language for RDF graphs (and it is not very friendly with OWL), and the OWL API, as the name suggests, is oriented specifically to OWL. Currently, work is underway on the SPARQL-DL standard and, possibly, its support will be implemented in one of the next versions of the OWL API. At the moment, it remains only to use class expressions, which allow you to write queries using the Manchester syntax. Class expressions are, of course, not SPARQL ... but for most tasks they are enough.
So, the test results:

First, I will comment on the dashes in the Intellidimension column. 6 hours have passed since the launch of the test application, the process weighed about 6 GB, but there was no result. I did not have the patience to wait longer. Forced to count Semantics.SDK technical defeat. In fairness, it is worth noting that Semantics.SDK manages smaller ontologies: it draws conclusions and processes requests ... however, comparing the results with Jena + Pellet, I can confidently say that Semantics.SDK does not always give the full result.
Pellet, however, dealt with the conclusion in a very reasonable time (the requests were not easy) and, like in the first stage of testing, the .NET / ikvm framework looks preferable to Intellidimension.
The testing phase is now complete. Summing up, we can say that the winner was the Jena + Pellet system, and the OWL API + Pellet went to the award of authorship.
In general, there are two approaches to the implementation of logical inference: based on rules (using forward-chaining and / or backward-chaining algorithms ) and based on a semantic scoreboard ( semantic tableau ). Based on the rules, Semantics.SDK and Owlim are implemented, and on the basis of the semantic scoreboard, Pellet.
As far as I can tell, rule-based risoners are advantageous for languages with low expressiveness, and semantic scoreboard-based ones for languages with high expressiveness. If Pellet (OWL-DL) and Owlim (OWL-Tiny) confirm this observation (being on opposite sides of the barricade), then Semantics.SDK (OWL-FULL) is an exception (and judging by performance tests, there is nothing good about this exception) .
Consider the diagram c from the official website of Owlim:
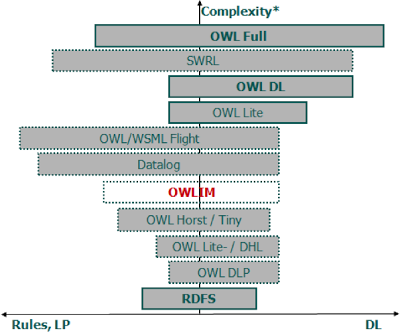
As you can see, Owlim only supports OWL Tiny. It is this feature that allows him to achieve very high performance.
Owlim is the only (among the reviewed) risoner that supports multi-threaded output. Thus, Owlim realizes the advantage of rule-based systems over the semantic scoreboard - the possibility of parallelization (there are no algorithms for parallelizing the process of constructing a semantic scoreboard yet). The developers of Semantics.SDK claim that their output is also parallelized ... but this is not implemented in the trial version (in my opinion, this is not a good limitation for the trial version). The request to give me a short-term license for testing remained unanswered, so I have to take the word for it.
In an ideal world, a risoner should definitely exist, which, when analyzing the ontology, would determine the level of expressiveness and use appropriate algorithms to derive it. At the moment, there is no such rizoner, and it is unlikely that he will ever appear.
In this article, the emphasis is on performance, however, when choosing a semantic framework for a particular project, the emphasis must first be on functionality (support for (non-relational) storage, support for OWL2, etc.). A discussion of these issues is beyond the scope of this article (and I am not so familiar with each of the frameworks to do such an analysis). In terms of functionality, I wanted to praise products from Intellidimension: the bundle of RDFGateway and Semantics.SDK is a very powerful framework that has no analogues in the Java world ... but the tricks of their rizoner cooled my feelings for this framework.
PS Many thanks for the educational program provided during the writing of the article to Pavel Klinov.
PP S. Original article on my blog .
In this article I will describe my experience with the above frameworks and share the test results.
Introduction
This article is not a comprehensive overview of the above frameworks. The article is aimed at analyzing the performance of the basic capabilities of frameworks: loading ontology, inference, and executing SPARQL queries.
Before diving into the technical details, I’ll say a few words about the framework from Intellidimension (as the least known product for the Java-oriented community). Unlike the rest of the frameworks discussed in this article, which are OpenSource projects, RDF Gateway and Semantics.SDK are distributed with closed source codes and cost quite decent money. So, RDF Gateway 3.0 Enterprise alone costs $ 10,000 (although version 2.0 cost "just" $ 2,000). By the way, the risoners used during testing - Pellet and Owlim - are also not free: Pellet is distributed under a dual license, and Owlim offers only a version that works in memory for free; the version that works with storage costs 700 euros for each processor core used.
Testing
My task was to select a framework for implementing a project for .NET, so Java projects in their pure form did not interest me (initially I did not even plan to test them). It was necessary to choose an interop tool between Java and .NET. My choice fell on ikvm.net , which allows you to convert jars to .NET dll. Having received the .NET version of Jena, OWL API and Sesame, I set about testing them. However, testing would be incomplete if it did not contain the results of testing Java frameworks in their native environment. Thus, the following people participate in the testing: Intellidimension Semantics.SDK 1.0, OWL API 2.2.0 + Pellet 2.0rc5 (both under Java and under .NET), Jena 2.5.7 + Pellet2.0rc5 (both under Java and under .NET) and partly Sesame 2.24 + SwiftOwlim 3.0b9.
Sesame had to be excluded from the initial testing due to the policy of logical inference in Owlim that is different from the Semantic SDK and Pellet (Owlim is the main risoner used in conjunction with Sesame). So, Pellet and Semantic SDK are aimed at output during query (query-time reasoning), although they include means of early output; Owlim is aimed at full inference (full materialization). We will talk about this in the section "General information about risoners".
The NCI Institute Thesaurus 09.02d ontology was chosen as a test one. True, in its pure form, it contains a number of inconsistency. After communicating with the support service inconsistencies were identified. I used the modified version 09.02d (which you can downloadfrom my dropbox), although version 09.04d is already available, in which there are no inconsistencies.
For testing, the following situation was simulated:
1. First, the ontology from the file was loaded into the model;
2. Then 3 SparQL queries were sequentially executed to this model (query texts can be downloaded here ).
First, consider the results of testing the first stage:
Despite the fact that .NET / ikvm frameworks are 2-3 times slower than their Java counterparts, they turned out to be faster than Intellidimension.
In terms of working with memory, .NET left a more pleasant impression. The Java garbage collector requires specifying the maximum amount of RAM that can be allocated to the heap (Xmx parameter); .NET uses a more logical, in my opinion, policy: it consumes as much memory as it needs (unless a restriction is specified). Xmx restriction is a very old bug, which, unfortunately, is still not fixed. As a solution, it is proposed to simply specify Xmx with a margin (if, of course, the amount of RAM allows), but in this case (testing was done with Xmx: 12g), the garbage collector does not bother itself (which we see from the test results). You can go the other way - select the minimum Xmx value for specific input data (though at the risk of running into an OutOfMemoryException). Thus, you can approximate the amount of memory consumed by the JVM to similar CLR indicators (albeit with some additional performance losses for more frequent garbage collections).
Regarding the limitation on the maximum amount of memory used, a rather curious case occurred. After successfully loading the Thesaurus ontology using the .NET OWL API converted to .NET, I decided to open this ontology in Protége (which is based on the same version of the OWL API) to familiarize myself with its structure. However, instead of a tree of concepts and instances, I got an OutOfMemoryException (despite the fact that there was plenty of free memory). Although the increase in the value of the Xmx attribute resolved the problem, such non-independence of the garbage collector in Java does not please. The funny thing is that despite the fact that the Java application does not start in its native environment (without dancing with the JVM), it works after converting to .NET using ikvm.
Now let's move on to the second point of testing - executing SPARQL queries. Unfortunately, at this stage you will have to leave behind the leader of the first test - OWL API. The fact is that the OWL API that the risoners implement does not contain methods for executing SPARQL queries. This is due to the fact that SPARQL was created as a query language for RDF graphs (and it is not very friendly with OWL), and the OWL API, as the name suggests, is oriented specifically to OWL. Currently, work is underway on the SPARQL-DL standard and, possibly, its support will be implemented in one of the next versions of the OWL API. At the moment, it remains only to use class expressions, which allow you to write queries using the Manchester syntax. Class expressions are, of course, not SPARQL ... but for most tasks they are enough.
So, the test results:
First, I will comment on the dashes in the Intellidimension column. 6 hours have passed since the launch of the test application, the process weighed about 6 GB, but there was no result. I did not have the patience to wait longer. Forced to count Semantics.SDK technical defeat. In fairness, it is worth noting that Semantics.SDK manages smaller ontologies: it draws conclusions and processes requests ... however, comparing the results with Jena + Pellet, I can confidently say that Semantics.SDK does not always give the full result.
Pellet, however, dealt with the conclusion in a very reasonable time (the requests were not easy) and, like in the first stage of testing, the .NET / ikvm framework looks preferable to Intellidimension.
The testing phase is now complete. Summing up, we can say that the winner was the Jena + Pellet system, and the OWL API + Pellet went to the award of authorship.
General information about risoners
In general, there are two approaches to the implementation of logical inference: based on rules (using forward-chaining and / or backward-chaining algorithms ) and based on a semantic scoreboard ( semantic tableau ). Based on the rules, Semantics.SDK and Owlim are implemented, and on the basis of the semantic scoreboard, Pellet.
As far as I can tell, rule-based risoners are advantageous for languages with low expressiveness, and semantic scoreboard-based ones for languages with high expressiveness. If Pellet (OWL-DL) and Owlim (OWL-Tiny) confirm this observation (being on opposite sides of the barricade), then Semantics.SDK (OWL-FULL) is an exception (and judging by performance tests, there is nothing good about this exception) .
Consider the diagram c from the official website of Owlim:
As you can see, Owlim only supports OWL Tiny. It is this feature that allows him to achieve very high performance.
Owlim is the only (among the reviewed) risoner that supports multi-threaded output. Thus, Owlim realizes the advantage of rule-based systems over the semantic scoreboard - the possibility of parallelization (there are no algorithms for parallelizing the process of constructing a semantic scoreboard yet). The developers of Semantics.SDK claim that their output is also parallelized ... but this is not implemented in the trial version (in my opinion, this is not a good limitation for the trial version). The request to give me a short-term license for testing remained unanswered, so I have to take the word for it.
In an ideal world, a risoner should definitely exist, which, when analyzing the ontology, would determine the level of expressiveness and use appropriate algorithms to derive it. At the moment, there is no such rizoner, and it is unlikely that he will ever appear.
Conclusion
In this article, the emphasis is on performance, however, when choosing a semantic framework for a particular project, the emphasis must first be on functionality (support for (non-relational) storage, support for OWL2, etc.). A discussion of these issues is beyond the scope of this article (and I am not so familiar with each of the frameworks to do such an analysis). In terms of functionality, I wanted to praise products from Intellidimension: the bundle of RDFGateway and Semantics.SDK is a very powerful framework that has no analogues in the Java world ... but the tricks of their rizoner cooled my feelings for this framework.
PS Many thanks for the educational program provided during the writing of the article to Pavel Klinov.
PP S. Original article on my blog .