Surface and general reasoning about neural networks
On Habré there are a large number of articles on neural networks in which there is a picture of a neuron in the form of a circle with incoming arrows, a picture with lines of neurons and an obligatory formula for the sum of the product of weights for features. These articles often provoke the indignation of a respected public by its obviousness and similarity with the teaching of drawing owls. In this article I will go even further - there will not even be this. No mathematics, no comparisons with the brain. You are unlikely to learn something practical from this article and there is a high probability that everything stated will seem too obvious to you. The purpose of this article is the question: what can you do with neural networks? Not Yandex, not Google, not Facebook, but you - with your five-year experience as a web developer and a three-year laptop.
There is a lot of noise around neural networks (hereinafter - NS). So I decided to make some product based on them. And he asked himself: what do I need for this? And he answered himself (yes, I like to talk with an intelligent person): we need three things - knowledge in the field of neural networks, training data and hardware on which to train a neural network. By the way, after I heard in many videos on youtube speakers said that the reason for the renaissance of the National Assembly is just these things: improved algorithms (knowledge), the availability of a huge amount of data and the capabilities of modern computers (hardware). Such a coincidence of my thoughts and words of the experts is encouraging, so I will talk further about these three things: data, knowledge and iron.
The nature and type of data depends on the area in which you want to apply the NA.
Modern NNs began to solve such cool tasks as the recognition of objects in images, faces, speech recognition, were able to play video games themselves and won go.
A lot of data is needed for learning NAs - hundreds of thousands, millions of examples. Can you use your samopisny Internet grabber to find and download such a heap? I think yes. But there are several problems:
In the National Assembly, there are a hell of a lot of hyperparameters that strongly influence both the speed of work and convergence in principle. You can retrain, get stuck in a local maximum, stretch the training for weeks and so on. Knowledge of the architecture of the National Assembly, the principles of work you acquire, you are a programmer. There are a huge number of frameworks for machine learning - theano, tensorflow, and others. But setting up such parameters as learning speed, choosing a moment, choosing a regularization and its parameters, choosing an activation function and many more others is an experimental process that takes a lot of time. Due to the lack of an exact strategy and the need for each task to adjust and select the parameters manually, many people call the process of teaching the National Assembly art.
You need to process millions of examples many times, a large number of times: You gave examples, the National Assembly slightly adjusted the weights, you again gave the same examples, the National Assembly again adjusted the weights - and so many “epochs”. If you use cross-validation, then you also give the data for different partitions into a training and validation sample so that the NA does not retrain on the same data.
What are some resources you can afford? I wanted to buy myself a top-end computer based on the Kaby Lake 7700K (or Razen 1800X) with two NVidia GTX 1080 video cards working together using SLI. And my heart warmed the idea that its performance is equal to the performance of supercomputers a decade ago from the Top500 list. How long does it take to learn NA on it? This, of course, depends on the network architecture (number of layers, number of neurons in layers, connections), on the number of examples for training, on hyperparameters. But what struck me was that I spent several hours on the site playground.tensorflow.org so that the small network could correctly classify the points in the spiral in two-dimensional space. Only two measurements, not so much data, but so much time. The winner of the ImageNet contest at one time spent a week learning the network using two video cards, and he knew a lot about choosing hyper parameters. Hardly buy even a dozen servers. Do you have enough patience to learn NA?
Summary : it seems to me that at home you can solve some problems with the help of the National Assembly.
This is my intuitive opinion and a very rough estimate, it may be wrong, I will be happy if someone writes in the comments about the tasks that he solved at home, what was the amount of data and characteristics of iron.
Thanks for attention!
There is a lot of noise around neural networks (hereinafter - NS). So I decided to make some product based on them. And he asked himself: what do I need for this? And he answered himself (yes, I like to talk with an intelligent person): we need three things - knowledge in the field of neural networks, training data and hardware on which to train a neural network. By the way, after I heard in many videos on youtube speakers said that the reason for the renaissance of the National Assembly is just these things: improved algorithms (knowledge), the availability of a huge amount of data and the capabilities of modern computers (hardware). Such a coincidence of my thoughts and words of the experts is encouraging, so I will talk further about these three things: data, knowledge and iron.
Data
The nature and type of data depends on the area in which you want to apply the NA.
Modern NNs began to solve such cool tasks as the recognition of objects in images, faces, speech recognition, were able to play video games themselves and won go.
Lyrical digression
Конечно, во многом этот хайп и пузырь вокруг НС – это влияние моды, вирусности, романтичного названия, аналогий с мозгом и мечтой о сильном ИИ. Ведь согласитесь, что если бы эти техники назывались «Перемножение матриц и оптимизация параметров методом градиентного спуска», всё это звучало бы менее эффектно и, возможно, не привлекло бы так много внимания. Некоторые возразят, что мол, чёрт с ним, с названием, не только из-за названия они так популярны, они же вызывают вау-эффект — посмотрите, что эти сети делают, они же выиграли в го! Хорошо, но когда ИИ выиграл в шахматы, ведь мало кто стал боготворить поиск в глубину и журналисты не писали о том, что A-star захватит мир, а программисты не стали его массово изучать.
НС кроме прочего окутаны ореолом таинственности — никто не понимает, как именно они выполняют свою работу: набор нелинейных функций, многочисленных матриц весов, загадочных слагаемых и множителей — всё это выглядит как чан ведьмы, куда она бросает всякие корешки, крылья нетопырей и кровь дракона. Но вернемся к вопросу статьи.
НС кроме прочего окутаны ореолом таинственности — никто не понимает, как именно они выполняют свою работу: набор нелинейных функций, многочисленных матриц весов, загадочных слагаемых и множителей — всё это выглядит как чан ведьмы, куда она бросает всякие корешки, крылья нетопырей и кровь дракона. Но вернемся к вопросу статьи.
A lot of data is needed for learning NAs - hundreds of thousands, millions of examples. Can you use your samopisny Internet grabber to find and download such a heap? I think yes. But there are several problems:
- For training with a teacher, the data must be tagged. Someone must mark these data, refer them to different classes, give a numerical estimate. If this is not initially for some reason (for example, you only have audio, but there is no transcript), then this requires tremendous effort. Of course, there is training without a teacher, with reinforcements, etc., but they solve other tasks (simply, not classification and regression (in fact, determining the value of an unknown function), but clustering or choosing the best actions). In view of the limited length of the article I will not touch on this issue.
- Data should be evenly distributed, whatever that means. This means that if you even have millions of data that contain information about bmw and dodge, but almost nothing about Ford and Mazda, then the National Assembly will never be able to adequately summarize the data, worse, it will inflate prices or draw round headlights and aggressive look.
- You need to know a lot about the nature of the data in order to be able to highlight important traits and possibly impose some restrictions on the NA. Yes, multi-layer NA is a universal approximator of any continuous functions, but no one said that it would be fast. Strange as it may seem, but the more restrictions, the faster the NA will be able to learn. Why are NA so good at image processing? Because smart guys laid in the very architecture of these networks information relating to images. They created a separate class of networks - convolutional networks, which take data from a group of pixels, compress the image in different versions, carry out mathematical transformations, the purpose of which is to level the influence of shifts, transformations, and different camera angles. Is this suitable for other data types? Hardly. Is it suitable for pictures, where angles carry important information? Who knows?
Knowledge
In the National Assembly, there are a hell of a lot of hyperparameters that strongly influence both the speed of work and convergence in principle. You can retrain, get stuck in a local maximum, stretch the training for weeks and so on. Knowledge of the architecture of the National Assembly, the principles of work you acquire, you are a programmer. There are a huge number of frameworks for machine learning - theano, tensorflow, and others. But setting up such parameters as learning speed, choosing a moment, choosing a regularization and its parameters, choosing an activation function and many more others is an experimental process that takes a lot of time. Due to the lack of an exact strategy and the need for each task to adjust and select the parameters manually, many people call the process of teaching the National Assembly art.
Resources
You need to process millions of examples many times, a large number of times: You gave examples, the National Assembly slightly adjusted the weights, you again gave the same examples, the National Assembly again adjusted the weights - and so many “epochs”. If you use cross-validation, then you also give the data for different partitions into a training and validation sample so that the NA does not retrain on the same data.
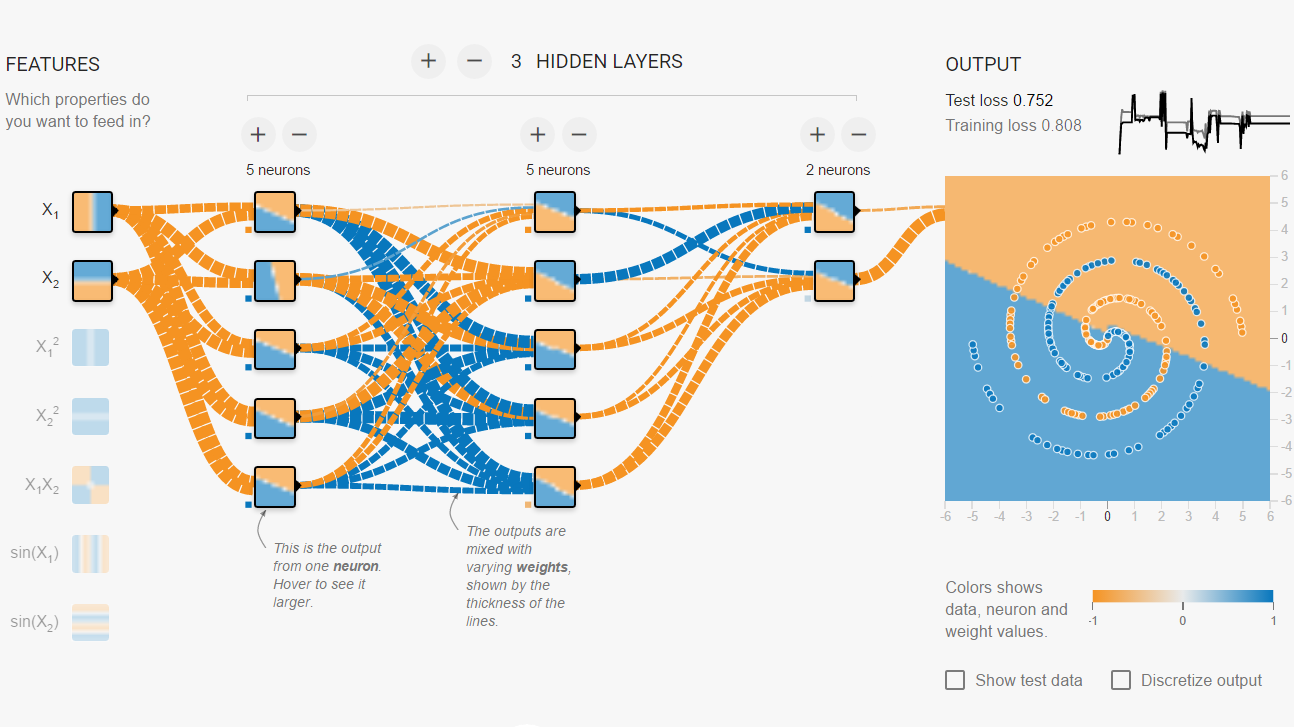
What are some resources you can afford? I wanted to buy myself a top-end computer based on the Kaby Lake 7700K (or Razen 1800X) with two NVidia GTX 1080 video cards working together using SLI. And my heart warmed the idea that its performance is equal to the performance of supercomputers a decade ago from the Top500 list. How long does it take to learn NA on it? This, of course, depends on the network architecture (number of layers, number of neurons in layers, connections), on the number of examples for training, on hyperparameters. But what struck me was that I spent several hours on the site playground.tensorflow.org so that the small network could correctly classify the points in the spiral in two-dimensional space. Only two measurements, not so much data, but so much time. The winner of the ImageNet contest at one time spent a week learning the network using two video cards, and he knew a lot about choosing hyper parameters. Hardly buy even a dozen servers. Do you have enough patience to learn NA?
Summary : it seems to me that at home you can solve some problems with the help of the National Assembly.
- The size of the training sample can be hundreds of thousands of examples.
- You can achieve an accuracy of about 80-90%.
- NA training may take you days.
This is my intuitive opinion and a very rough estimate, it may be wrong, I will be happy if someone writes in the comments about the tasks that he solved at home, what was the amount of data and characteristics of iron.
Thanks for attention!