Psychology of code readability
- Transfer
Everything that is written below never claims to be the absolute truth, but it still represents some model that helps me personally find ways to write a little better code.
Every programmer tries to write good code. Readability is one of the main features of such a code. A lot of books have been written about it, but there are still gaps in the subject. For example, those same books are focused more on tips on how to write a readable code, and not on the reasons why one code is well readable, and the other not. The book tells us to "use the appropriate variable names" - but what makes one name more appropriate than another? Does this work for all examples of similar code? Does this work for all programmers who will catch this code? I would like to talk about the latter in more detail. Let's dive a bit into the human psyche. Our brain is our main tool, it would be good to study the specifics of his work.
Every programmer knows that the capabilities of our brain are not limitless. There is a limit on the number of things we can think about. This is our working memory limit . There is an old myth that a person can hold 7 ± 2 objects in memory at the same time. This is called " Magic number seven " and it is actually not very accurate. Recent studies speak of the number 4 ± 1, or even less. In any case, the number of ideas that we can keep in mind at the same time is very limited.
Some people will say that they can easily operate with more than four objects in memory at the same time. This is true: fortunately, there is another process that is constantly occurring in our head - this is grouping. We combine similar small entities into slightly larger ones and operate with them already. Remember how you call dates or phone numbers - not one digit at a time, but in groups of two, three or four. In addition, each group of numbers is an independent entity. Moreover, all the figures together form a "date" or "phone number" - also separate entities.
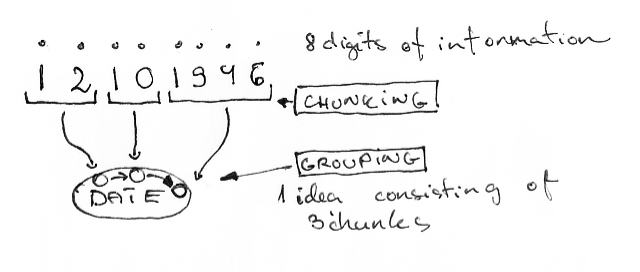
From these groups we build our long-term memory. I imagine it as a great web of such small groups and their sequences.
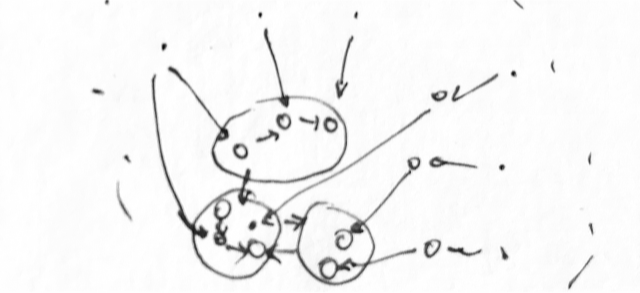
Based on this picture, it may seem to you that moving from one part of the memory to another is quite slow. And indeed it is. In the science of user interface design, there is the concept of a "single focus of attention." The name speaks for itself - we can only focus on one thing at a time. Moreover, in addition to the focus, there is also a “locus” - the limited attention in space.
You may think that this is the same as the working memory limit mentioned above, but there is an important difference. The working memory limit tells you how many entities we can hold in memory. The focus and locus of attention suggests that in order to perform some useful mental work, these entities also need to be “close by”, connected with something.
It is important to know about the focus and locus of attention, since switching between ideas is a very expensive process . And it becomes even more costly when we need to think about unknown entities and group them on the go. Fortunately, it works in the opposite direction - the better we know something, the less time it takes to switch attention to it and make sense of it. This is called experience.
We also remember things differently depending on the context. Once the following experiment was conducted: a group of divers read a set of words, and then, after a while, asked them to reproduce. Both the initial reading and the reproduction were carried out both on land and in water. Best of all was the case when the words were both read and reproduced on land. But in the second place was unexpectedly a combination with reading and reproduction in water. People remembered words in the context of the environment and similar environments helped to remember better.
From contexts and entities grouped in memory cells, we build mental representations and mental models.. Mental models play a key role in our ability to find solutions to problems. For the same problem, you can build different mental models, and each will have its pros and cons. There is also the main problem in their construction and application: our brain. Oh, our brain has a whole bunch of different flaws.
Firstly, it is difficult for him to work with abstractions. When some entities seem to be similar, they are located in the brain “close by” and are connected. This leads to the fact that the brain sometimes makes mistakes which of them should be extracted and used in each particular case. Example: confusion between l and 1, 0 and O. Another example is ambiguity. "Key" - are we now about the subject for opening locks, building a flock of birds or a tool to work with nuts?
Uncertainty about the correctness of the found abstraction slows down the process of thinking. For a split second - but this may be enough to lose focus. There are many things that can knock us down, but if we are able to understand, localize and filter out major distractions, then we may not be aware of “every little thing”. If someone calls random numbers, as long as you think something, it will become much more difficult to count. This can happen with visual factors: if there are several important objects on the screen and a couple of dozens of unimportant in the current situation, it will be more difficult for you to select and realize only the important ones.
All of the above creates a cognitive load. This is the amount of mental effort that is needed to solve a task. Our “operating capacity” falls as we work and increases after a rest. If you don’t give your head a conscious rest, you won’t be fooled by nature anyway, and after a while your brain will begin to “soar in the clouds”.
Let's now get to the point and think about how it all concerns writing good code. Next will be a few recommendations, rules of thumb and paradigms that can somehow help you in terms of psychology. This, of course, is not a fundamental guide, but I hope you will catch the main ideas and will be able to use them further to evaluate other rules, tips and paradigms that you know.
Let's take a look at a simple for loop:
Which option do you like more? Most programmers recommend option A . Why? And because option B uses variable names that are too long, which prevents us from seeing at once a single (and well-known) pattern. In addition, in this case, such long names do not help to create a better context, they simply add noise.
Now let's look at the different ways of creating namespaces (these can be packages, modules, or something else in your programming language):
Option B is bad because "s" is too short a name and does not help us understand that "this is probably a string."
Option C is bad, because std.utils.strings is too long a name, we already understand that this is a string, you do not need to be reminded every time about where it is located.
Option D is bad, because without namespaces we don’t understand very well what kind of function we call, where it comes from and what objects it will work on.
It is important to note that if we are talking about lines in the code, then it would be logical to assume that the IndexOf call for the line does some work on the line. In this case, even the mention of the namespace "strings" will be redundant, as, for example, the addition operation on integers is more understandable in the form of a + b, and not in the form of int16.Add (a, b).
Some programming paradigms say that any modification of a variable is a bad thing, because “it becomes difficult to understand what changed and when.” But let's look at these examples here:
Here the first function (foo) is probably the easiest to understand. Why? Because the problem is not the modification of variables, but how exactly they are modified. Example A contains no complex calculations, unlike B and C .
Here is another example of code where a version with a modified value of a variable ( D ) is easier to read. Option E does not modify existing variables, but adds 3 new entities to describe the same idea. More noise is harder to understand.
Let's look at a few more cycles:
How long did it take for you to understand what each of them is doing? I bet option A you perceived on the fly. The remaining three options had to be read and understood. The main reason is experience. Variant A for many programmers lies in a separate, quickly accessible memory cell. The remaining three are not. For them, you need to build new temporary models in your head.
But for a beginner, all four options will look the same - their complexity is really about equal and none of them will seem to the person "from the side" better than the other. An experienced programmer at first glance will say "well, well, this is a passage through the array." The newcomer will tell you that "here we reset the variable i, then compare it with N, execute the code inside the loop body, increment i and compare again, etc.".
Option A is the “idiomatic way” of writing a cycle. It is not better than others in terms of computational complexity, but significantly better in terms of code readability, because it is included in the “basic vocabulary of the profession.”
Most programming languages have an idiomatic way of writing certain things. There are classic documents and books, such as APL idioms , C ++ idioms, as well as higher level things like the Gang of Four patterns . Using idioms from similar classic books, we can build more complex programs, some pieces of which will be understandable to other programmers (after all, they probably read the same books).
All this has a negative aspect. The more idioms we use, the more vocabulary you need to remember to understand them. Dynamic languages are subject to this problem more than others - programmers feel the opportunity to invent new flexible idioms for a clever solution to their current problem (and it even works), but each subsequent reader of this code will be forced to slow down, trying to understand the unexpected approaches of the author.
A good example of consistency can be the names of entities such as "model" and "controller". Having once learned what it is and how they relate to each other, you will always get a valuable pair of idioms in your head. Now in any code, when you see a class with the word Model or Controller in the name, you will understand what it was created for and what it is connected with.
Such things as frameworks or game engines are always trying to act in a similar way: to give us an understanding of the basic entities, the links between them, and the ways they are manipulated. Having learned the structure of one project on some framework or engine, a programmer can very quickly grasp the essence of another project on it.
An important factor here is the consistency of the code design. The more consistent the names of variables, classes, methods, code formatting, approaches to solving the same problems in different parts of the code base are in the code - the easier the reader understands the project, the faster he “trusts” him.
Uncertainty can slow both writing and code understanding. As an example, consider the ambiguity. For example, the following code:
for all its simplicity, all the same leaves open the question, what will be obtained in the end "2 and 3" or "1"? So we are “filtering” or “filtering” here? Most likely you will quickly find the answer in the documentation of your platform or library used - but you will have to digress, and then also remember the information found. True, it would be better if the name and syntax speak for themselves? Function names like select , discard, or keep would be much better .
We can also understand the meaning of an entity in different ways. For example, the function GetUser (string)some people may be perceived as searching for a user by name, while others will consider it to be a search using a unique user key. You can easily get out of this situation by creating a special type CustomerID (even if it will be an alias on the same line) and using it in the prototype of the GetUser (CustomerID) function , but you can call the search for a user by name GetUserByName (string) . There is already no uncertainty.
Similarity is another common cause of errors. If you have variables like total1 , total2 , total3- it is very easy to copy-paste a piece of code and forget to fix the index. The code will be compiled, and the error will be found (if there will be) much later. Calling these variables with names like sum , sum_of_squares , total_error is much safer.
Another problem is the naming of the same entity by different names in different modules of your code. This does not seem to be such a big problem: “I called it this way, another programmer put it in the base under that name, and in the UI it was called like this”. All is well, all is well. And then something breaks, and some other programmer, cursing, trying to understand how these things, which are completely different in name, are connected.
Problems of ambiguity and similarity are inherent not only in writing source code. In different contexts, the same words can mean different things. For example, the word “customer” means completely different things in the purchasing and sales departments of the same company. Thus, you should never be afraid to seem ridiculous or inappropriate, once again asking everyone around if you understand the same terms in your subject area.
We all saw examples of stupid novice comments like:
Yes, it looks a little dumb. But even such comments can make sense. Think about learning a second (or third) programming language. You already have knowledge of the syntax of one language, an understanding of all these conditional transitions, cycles, functions - and now you are learning the same thing in another language. You do not need to re-examine these concepts in a new language, but only to bind in your head this format of a cycle or assignment to the abstract idiom of a “cycle” or “assignment” - this is where similar comments can be useful.
As soon as this binding happened - these comments will become unnecessary garbage, since an explanation of what is happening will occur in your head when you look at the code itself. In the course of how a programmer gains experience, his comments carry less and less information about WHAT the code does and more and more about WHY and WHAT CONTEXT it does. “Approach X was chosen because alternative approaches Y and Z didn’t work for such reasons,” “when modifying this code, remember that ...”.
Good comments complement the mental code understanding model.
The limited working memory limit leads us to the necessity of code decomposition. We break a complex (or long) code into parts that operate with a limited number of objects. But it is also possible to break and decompose in different ways. Imagine, for example, a class that lies very deep in the inheritance tree. And here you write in it some method that calls several other methods - one from the same class, the other from the “parent”, the third from the “grandfather”. It seems that your class is quite simple - a couple of methods, rows of 5 in each. But reading its code is difficult, because even reading these 10 lines requires you to create an entire inheritance tree in your head (and keep reading all the time!). It's difficult. Each new layer of inheritance is another idiom that occupies and exhausts our working memory limit.
The same with tracking function calls. Each step deep into the call stack is a step to the limit of our mental abilities.
One of the ways to reduce the depth of our mental context model is to clearly separate them. One example would be the concept of an “early return”:
In the first version, when reading the code, we reach the “do something” part and still remember that this part is executed only under the condition specified above. However, when we reach the part of the “else” we have already far enough mentally departed from the original condition and to understand something this “else” is related, we need, first, to remove from the head the just read part “to do something ", Secondly, go back to the condition and realize it and, thirdly, go back to the" else "block already being in the context of the conditions under which we will get into it. Enough long way.
The second version of the code applies the concept of early return and is therefore the best alternative. We first check the boundary conditions and adequately respond to them. Then we go to the main code block and execute it. No mental jumps back and forth, no unnecessary change of contexts.
One of the fundamental rules of programming is “Avoid using global variables.” But how about the case when the value of such a variable is assigned only once during initialization and never changes in the future - is this also a problem? Yes, it's a problem. The point here is not even “variability” or “globality”. We introduce an entity that is accessible from everywhere, which means that it will explicitly or implicitly be present in any mental code model that you will build in your head. Even if it is a constant, even if it is not used in this function — knowledge of what is something, which of its own will (and not the will of this function) is visible and accessible — already gives him the right to claim a place in his head reader of this code. Of course, we do not write “programs in a vacuum,” they all work in some kind of environment, and even some “valid” idioms like Singleton have the same properties. So why are they considered a better option than global variables?
It's all about the principle of sole responsibility. Its purpose is to ensure that each entity in your code serves one purpose. Not zero, not two - exactly one. This restriction often leads to splitting into smaller parts. This is not always good - with such a crushing one can reach so small parts that to collect something really useful from them will require serious efforts. In addition, these small parts can be so tied to each other that this will lose the whole meaning of the principle of sole responsibility.
A good example of this could be Carmack’s comment. He showed these three pieces of code:
By making smaller pieces of code, we can better ensure that their contents match their idea and name. However, understanding the code does not make it any better. We cannot read the code in a linear manner (top to bottom) and understand it - instead, we have to jump to the code of the called functions and back. Veriant C proposes a solution to this problem - separating parts of the code into logical scopes, which, on the one hand, preserves their integrity and separation, and on the other, allows you to read the code sequentially and not lose the context for its execution.
In practice, there is no ideal way to organize the code, because besides readability, which we talked about above, there are equally important things, such as reliability, maintainability, performance, speed of creating a minimally working prototype, etc. Some of these values complement each other, but some directly contradict each other. In each case, it is important to understand what is the value of this particular project and what it is worth focusing efforts here and now.
Every programmer tries to write good code. Readability is one of the main features of such a code. A lot of books have been written about it, but there are still gaps in the subject. For example, those same books are focused more on tips on how to write a readable code, and not on the reasons why one code is well readable, and the other not. The book tells us to "use the appropriate variable names" - but what makes one name more appropriate than another? Does this work for all examples of similar code? Does this work for all programmers who will catch this code? I would like to talk about the latter in more detail. Let's dive a bit into the human psyche. Our brain is our main tool, it would be good to study the specifics of his work.
Psychological foundation
Every programmer knows that the capabilities of our brain are not limitless. There is a limit on the number of things we can think about. This is our working memory limit . There is an old myth that a person can hold 7 ± 2 objects in memory at the same time. This is called " Magic number seven " and it is actually not very accurate. Recent studies speak of the number 4 ± 1, or even less. In any case, the number of ideas that we can keep in mind at the same time is very limited.
Some people will say that they can easily operate with more than four objects in memory at the same time. This is true: fortunately, there is another process that is constantly occurring in our head - this is grouping. We combine similar small entities into slightly larger ones and operate with them already. Remember how you call dates or phone numbers - not one digit at a time, but in groups of two, three or four. In addition, each group of numbers is an independent entity. Moreover, all the figures together form a "date" or "phone number" - also separate entities.
From these groups we build our long-term memory. I imagine it as a great web of such small groups and their sequences.
Based on this picture, it may seem to you that moving from one part of the memory to another is quite slow. And indeed it is. In the science of user interface design, there is the concept of a "single focus of attention." The name speaks for itself - we can only focus on one thing at a time. Moreover, in addition to the focus, there is also a “locus” - the limited attention in space.
You may think that this is the same as the working memory limit mentioned above, but there is an important difference. The working memory limit tells you how many entities we can hold in memory. The focus and locus of attention suggests that in order to perform some useful mental work, these entities also need to be “close by”, connected with something.
It is important to know about the focus and locus of attention, since switching between ideas is a very expensive process . And it becomes even more costly when we need to think about unknown entities and group them on the go. Fortunately, it works in the opposite direction - the better we know something, the less time it takes to switch attention to it and make sense of it. This is called experience.
We also remember things differently depending on the context. Once the following experiment was conducted: a group of divers read a set of words, and then, after a while, asked them to reproduce. Both the initial reading and the reproduction were carried out both on land and in water. Best of all was the case when the words were both read and reproduced on land. But in the second place was unexpectedly a combination with reading and reproduction in water. People remembered words in the context of the environment and similar environments helped to remember better.
From contexts and entities grouped in memory cells, we build mental representations and mental models.. Mental models play a key role in our ability to find solutions to problems. For the same problem, you can build different mental models, and each will have its pros and cons. There is also the main problem in their construction and application: our brain. Oh, our brain has a whole bunch of different flaws.
Firstly, it is difficult for him to work with abstractions. When some entities seem to be similar, they are located in the brain “close by” and are connected. This leads to the fact that the brain sometimes makes mistakes which of them should be extracted and used in each particular case. Example: confusion between l and 1, 0 and O. Another example is ambiguity. "Key" - are we now about the subject for opening locks, building a flock of birds or a tool to work with nuts?
Uncertainty about the correctness of the found abstraction slows down the process of thinking. For a split second - but this may be enough to lose focus. There are many things that can knock us down, but if we are able to understand, localize and filter out major distractions, then we may not be aware of “every little thing”. If someone calls random numbers, as long as you think something, it will become much more difficult to count. This can happen with visual factors: if there are several important objects on the screen and a couple of dozens of unimportant in the current situation, it will be more difficult for you to select and realize only the important ones.
All of the above creates a cognitive load. This is the amount of mental effort that is needed to solve a task. Our “operating capacity” falls as we work and increases after a rest. If you don’t give your head a conscious rest, you won’t be fooled by nature anyway, and after a while your brain will begin to “soar in the clouds”.
Let's now get to the point and think about how it all concerns writing good code. Next will be a few recommendations, rules of thumb and paradigms that can somehow help you in terms of psychology. This, of course, is not a fundamental guide, but I hope you will catch the main ideas and will be able to use them further to evaluate other rules, tips and paradigms that you know.
Entity naming
Let's take a look at a simple for loop:
- A . for (i = 0 to N)
- Bed and . for (theElementIndex = 0 to theNumberOfElementsInTheList)
Which option do you like more? Most programmers recommend option A . Why? And because option B uses variable names that are too long, which prevents us from seeing at once a single (and well-known) pattern. In addition, in this case, such long names do not help to create a better context, they simply add noise.
Now let's look at the different ways of creating namespaces (these can be packages, modules, or something else in your programming language):
- A . strings.IndexOf (x, y)
- Bed and . s.IndexOf (x, y)
- The C . std.utils.strings.IndexOf (x, y)
- D . IndexOf (x, y)
Option B is bad because "s" is too short a name and does not help us understand that "this is probably a string."
Option C is bad, because std.utils.strings is too long a name, we already understand that this is a string, you do not need to be reminded every time about where it is located.
Option D is bad, because without namespaces we don’t understand very well what kind of function we call, where it comes from and what objects it will work on.
It is important to note that if we are talking about lines in the code, then it would be logical to assume that the IndexOf call for the line does some work on the line. In this case, even the mention of the namespace "strings" will be redundant, as, for example, the addition operation on integers is more understandable in the form of a + b, and not in the form of int16.Add (a, b).
Variable state
Some programming paradigms say that any modification of a variable is a bad thing, because “it becomes difficult to understand what changed and when.” But let's look at these examples here:
// A.
func foo() (int, int) {
sum, sumOfSquares := 0, 0for _, v := range values {
sum += v
sumOfSquares += v * v
}
return sum, sumOfSquares
}// B.
func GCD(a, b int) int {
for b != 0 {
a, b = b, a % b
}
return a
}// C.
func GCD(a, b int) int {
if b == 0 {
return a
}
return GCD(b, a % b)
}Here the first function (foo) is probably the easiest to understand. Why? Because the problem is not the modification of variables, but how exactly they are modified. Example A contains no complex calculations, unlike B and C .
// D.
sum = sum + v.x
sum = sum + v.y
sum = sum + v.z
sum = sum + v.w// E.
sum1 = v.x
sum2 := sum1 + v.y
sum3 := sum2 + v.z
sum4 := sum3 + v.wHere is another example of code where a version with a modified value of a variable ( D ) is easier to read. Option E does not modify existing variables, but adds 3 new entities to describe the same idea. More noise is harder to understand.
Idioms
Let's look at a few more cycles:
- A . for (i = 0; i <N; i ++)
- Bed and . for (i = 0; N> i; i ++)
- D . for (i = 0; i <= N-1; i + = 1)
- The C . for (i = 0; N-1> = i; i + = 1)
How long did it take for you to understand what each of them is doing? I bet option A you perceived on the fly. The remaining three options had to be read and understood. The main reason is experience. Variant A for many programmers lies in a separate, quickly accessible memory cell. The remaining three are not. For them, you need to build new temporary models in your head.
But for a beginner, all four options will look the same - their complexity is really about equal and none of them will seem to the person "from the side" better than the other. An experienced programmer at first glance will say "well, well, this is a passage through the array." The newcomer will tell you that "here we reset the variable i, then compare it with N, execute the code inside the loop body, increment i and compare again, etc.".
Option A is the “idiomatic way” of writing a cycle. It is not better than others in terms of computational complexity, but significantly better in terms of code readability, because it is included in the “basic vocabulary of the profession.”
Most programming languages have an idiomatic way of writing certain things. There are classic documents and books, such as APL idioms , C ++ idioms, as well as higher level things like the Gang of Four patterns . Using idioms from similar classic books, we can build more complex programs, some pieces of which will be understandable to other programmers (after all, they probably read the same books).
All this has a negative aspect. The more idioms we use, the more vocabulary you need to remember to understand them. Dynamic languages are subject to this problem more than others - programmers feel the opportunity to invent new flexible idioms for a clever solution to their current problem (and it even works), but each subsequent reader of this code will be forced to slow down, trying to understand the unexpected approaches of the author.
Consistency
A good example of consistency can be the names of entities such as "model" and "controller". Having once learned what it is and how they relate to each other, you will always get a valuable pair of idioms in your head. Now in any code, when you see a class with the word Model or Controller in the name, you will understand what it was created for and what it is connected with.
Such things as frameworks or game engines are always trying to act in a similar way: to give us an understanding of the basic entities, the links between them, and the ways they are manipulated. Having learned the structure of one project on some framework or engine, a programmer can very quickly grasp the essence of another project on it.
An important factor here is the consistency of the code design. The more consistent the names of variables, classes, methods, code formatting, approaches to solving the same problems in different parts of the code base are in the code - the easier the reader understands the project, the faster he “trusts” him.
Uncertainty
Uncertainty can slow both writing and code understanding. As an example, consider the ambiguity. For example, the following code:
[1,2,3].filter(v => v >= 2)for all its simplicity, all the same leaves open the question, what will be obtained in the end "2 and 3" or "1"? So we are “filtering” or “filtering” here? Most likely you will quickly find the answer in the documentation of your platform or library used - but you will have to digress, and then also remember the information found. True, it would be better if the name and syntax speak for themselves? Function names like select , discard, or keep would be much better .
We can also understand the meaning of an entity in different ways. For example, the function GetUser (string)some people may be perceived as searching for a user by name, while others will consider it to be a search using a unique user key. You can easily get out of this situation by creating a special type CustomerID (even if it will be an alias on the same line) and using it in the prototype of the GetUser (CustomerID) function , but you can call the search for a user by name GetUserByName (string) . There is already no uncertainty.
Similarity is another common cause of errors. If you have variables like total1 , total2 , total3- it is very easy to copy-paste a piece of code and forget to fix the index. The code will be compiled, and the error will be found (if there will be) much later. Calling these variables with names like sum , sum_of_squares , total_error is much safer.
Another problem is the naming of the same entity by different names in different modules of your code. This does not seem to be such a big problem: “I called it this way, another programmer put it in the base under that name, and in the UI it was called like this”. All is well, all is well. And then something breaks, and some other programmer, cursing, trying to understand how these things, which are completely different in name, are connected.
Problems of ambiguity and similarity are inherent not only in writing source code. In different contexts, the same words can mean different things. For example, the word “customer” means completely different things in the purchasing and sales departments of the same company. Thus, you should never be afraid to seem ridiculous or inappropriate, once again asking everyone around if you understand the same terms in your subject area.
Comments
We all saw examples of stupid novice comments like:
// увеличиваем в цикле переменную i от 0 до 99for(var i = 0; i < 100; i++) {
// присваиваем переменной а значение 4var a = 4;Yes, it looks a little dumb. But even such comments can make sense. Think about learning a second (or third) programming language. You already have knowledge of the syntax of one language, an understanding of all these conditional transitions, cycles, functions - and now you are learning the same thing in another language. You do not need to re-examine these concepts in a new language, but only to bind in your head this format of a cycle or assignment to the abstract idiom of a “cycle” or “assignment” - this is where similar comments can be useful.
As soon as this binding happened - these comments will become unnecessary garbage, since an explanation of what is happening will occur in your head when you look at the code itself. In the course of how a programmer gains experience, his comments carry less and less information about WHAT the code does and more and more about WHY and WHAT CONTEXT it does. “Approach X was chosen because alternative approaches Y and Z didn’t work for such reasons,” “when modifying this code, remember that ...”.
Good comments complement the mental code understanding model.
Contexts
The limited working memory limit leads us to the necessity of code decomposition. We break a complex (or long) code into parts that operate with a limited number of objects. But it is also possible to break and decompose in different ways. Imagine, for example, a class that lies very deep in the inheritance tree. And here you write in it some method that calls several other methods - one from the same class, the other from the “parent”, the third from the “grandfather”. It seems that your class is quite simple - a couple of methods, rows of 5 in each. But reading its code is difficult, because even reading these 10 lines requires you to create an entire inheritance tree in your head (and keep reading all the time!). It's difficult. Each new layer of inheritance is another idiom that occupies and exhausts our working memory limit.
The same with tracking function calls. Each step deep into the call stack is a step to the limit of our mental abilities.
One of the ways to reduce the depth of our mental context model is to clearly separate them. One example would be the concept of an “early return”:
publicvoidSomeFunction(int age){
if (age >= 0) {
// сделать что-то
} else {
System.out.println("Не верный возраст");
}
}
publicvoidSomeFunction(int age){
if (age < 0){
System.out.println("Не верный возраст");
return;
}
// сделать что-то
}In the first version, when reading the code, we reach the “do something” part and still remember that this part is executed only under the condition specified above. However, when we reach the part of the “else” we have already far enough mentally departed from the original condition and to understand something this “else” is related, we need, first, to remove from the head the just read part “to do something ", Secondly, go back to the condition and realize it and, thirdly, go back to the" else "block already being in the context of the conditions under which we will get into it. Enough long way.
The second version of the code applies the concept of early return and is therefore the best alternative. We first check the boundary conditions and adequately respond to them. Then we go to the main code block and execute it. No mental jumps back and forth, no unnecessary change of contexts.
Rules of thumb
One of the fundamental rules of programming is “Avoid using global variables.” But how about the case when the value of such a variable is assigned only once during initialization and never changes in the future - is this also a problem? Yes, it's a problem. The point here is not even “variability” or “globality”. We introduce an entity that is accessible from everywhere, which means that it will explicitly or implicitly be present in any mental code model that you will build in your head. Even if it is a constant, even if it is not used in this function — knowledge of what is something, which of its own will (and not the will of this function) is visible and accessible — already gives him the right to claim a place in his head reader of this code. Of course, we do not write “programs in a vacuum,” they all work in some kind of environment, and even some “valid” idioms like Singleton have the same properties. So why are they considered a better option than global variables?
It's all about the principle of sole responsibility. Its purpose is to ensure that each entity in your code serves one purpose. Not zero, not two - exactly one. This restriction often leads to splitting into smaller parts. This is not always good - with such a crushing one can reach so small parts that to collect something really useful from them will require serious efforts. In addition, these small parts can be so tied to each other that this will lose the whole meaning of the principle of sole responsibility.
A good example of this could be Carmack’s comment. He showed these three pieces of code:
// AvoidMinorFunction1( void ){
}
voidMinorFunction2( void ){
}
voidMinorFunction3( void ){
}
voidMajorFunction( void ){
MinorFunction1();
MinorFunction2();
MinorFunction3();
}
// BvoidMajorFunction( void ){
MinorFunction1();
MinorFunction2();
MinorFunction3();
}
voidMinorFunction1( void ){
}
voidMinorFunction2( void ){
}
voidMinorFunction3( void ){
}
// C.voidMajorFunction( void ){
{ // MinorFunction1
}
{ // MinorFunction2
}
{ // MinorFunction3
}
}
By making smaller pieces of code, we can better ensure that their contents match their idea and name. However, understanding the code does not make it any better. We cannot read the code in a linear manner (top to bottom) and understand it - instead, we have to jump to the code of the called functions and back. Veriant C proposes a solution to this problem - separating parts of the code into logical scopes, which, on the one hand, preserves their integrity and separation, and on the other, allows you to read the code sequentially and not lose the context for its execution.
In practice, there is no ideal way to organize the code, because besides readability, which we talked about above, there are equally important things, such as reliability, maintainability, performance, speed of creating a minimally working prototype, etc. Some of these values complement each other, but some directly contradict each other. In each case, it is important to understand what is the value of this particular project and what it is worth focusing efforts here and now.