Some aspects of optimizing LINQ queries in C # .NET for MS SQL Server
- Tutorial
LINQ has entered .NET as a powerful new data manipulation language. LINQ to SQL as part of it allows you to conveniently communicate with the DBMS using, for example, the Entity Framework. However, quite often using it, developers forget to look at which particular SQL query the queryable provider will generate, in your case, the Entity Framework.
Let's analyze two main points using an example.
To do this, create the Test database in SQL Server, and create two tables in it using the following query:
Now fill the Ref table by running the following script:
Similarly, fill out the Customer table using the following script:
Thus, we got two tables, in one of which more than 1 million rows of data, and in the other, more than 10 million rows of data.
Now in Visual Studio you need to create a test project Visual C # Console App (.NET Framework): Next, you need to add a library for the Entity Framework to interact with the database. To add it, right-click on the project and select Manage NuGet Packages from the context menu: Then, in the window for managing NuGet packages in the search box, enter the word "Entity Framework" and select the Entity Framework package and install it: Next, in the App file. config after closing the configSections element, add the following block:

In connectionString you need to enter the connection string.
Now let's create 3 interfaces in separate files:
And in a separate file, create the BaseEntity base class for our two entities, which will include common fields:
Next, in separate files, create our two entities:
Now create a UserContext context in a separate file:
We got a ready-made solution for optimization tests with LINQ to SQL through EF for MS SQL Server: Now, in the Program.cs file, enter the following code:
Next, run our project.
At the end of the work, the console will display:
That is, in general, a very good LINQ query generated an SQL query to MS SQL Server DBMS.
Now let's change the AND condition to OR in the LINQ query:
And we will launch our application again.
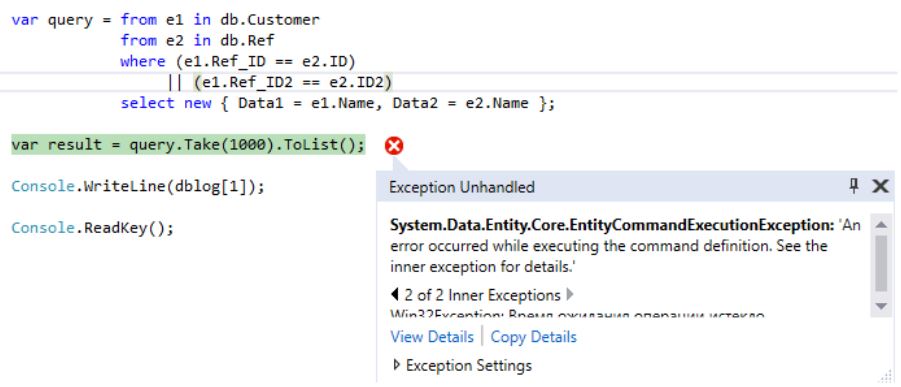
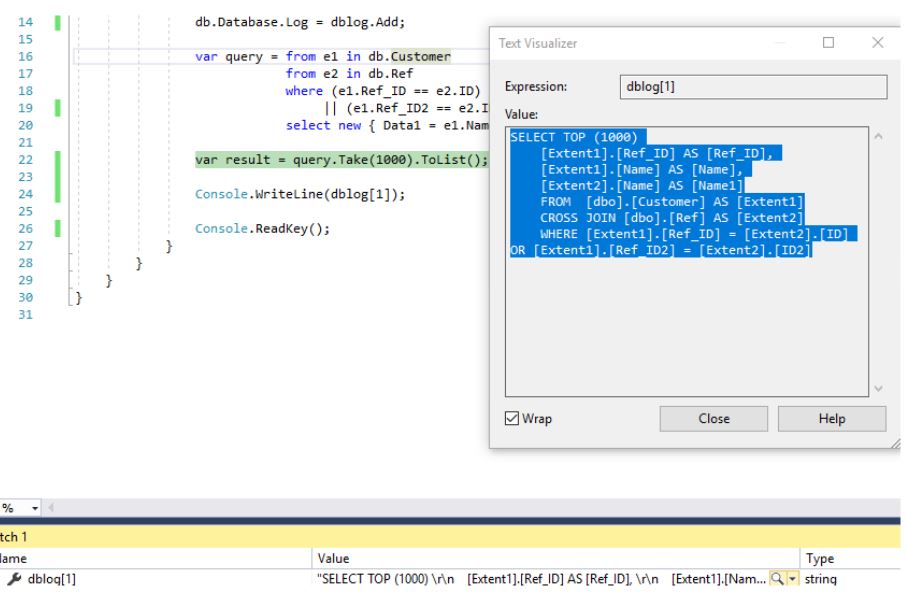
Execution will crash with an error related to exceeding the command execution time of 30 seconds: If you look at what query LINQ: was generated at the same time , you can make sure that the selection occurs through the Cartesian product of two sets (tables):
Let's rewrite the LINQ query as follows:
Then we get the following SQL query:
Alas, there can be only one connection condition in LINQ queries, therefore it is possible to make an equivalent query through two queries for each condition, followed by combining them through Union to remove duplicates among the rows.
Yes, queries will generally be nonequivalent, given that full duplicate rows can be returned. However, in real life, full duplicate lines are not needed and they are trying to get rid of them.
Now compare the execution plans for these two queries:
Let's analyze two main points using an example.
To do this, create the Test database in SQL Server, and create two tables in it using the following query:
Create tables
USE [TEST]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Ref](
[ID] [int] NOT NULL,
[ID2] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
[InsertUTCDate] [datetime] NOT NULL,
CONSTRAINT [PK_Ref] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Ref] ADD CONSTRAINT [DF_Ref_InsertUTCDate] DEFAULT (getutcdate()) FOR [InsertUTCDate]
GO
USE [TEST]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Customer](
[ID] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
[Ref_ID] [int] NOT NULL,
[InsertUTCDate] [datetime] NOT NULL,
[Ref_ID2] [int] NOT NULL,
CONSTRAINT [PK_Customer] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [DF_Customer_Ref_ID] DEFAULT ((0)) FOR [Ref_ID]
GO
ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [DF_Customer_InsertUTCDate] DEFAULT (getutcdate()) FOR [InsertUTCDate]
GO
Now fill the Ref table by running the following script:
Ref Table Fill
USE [TEST]
GO
DECLARE @ind INT=1;
WHILE(@ind<1200000)
BEGIN
INSERT INTO [dbo].[Ref]
([ID]
,[ID2]
,[Name])
SELECT
@ind
,@ind
,CAST(@ind AS NVARCHAR(255));
SET @ind=@ind+1;
END
GO
Similarly, fill out the Customer table using the following script:
Filling in the Customer table
USE [TEST]
GO
DECLARE @ind INT=1;
DECLARE @ind_ref INT=1;
WHILE(@ind<=12000000)
BEGIN
IF(@ind%3=0) SET @ind_ref=1;
ELSE IF (@ind%5=0) SET @ind_ref=2;
ELSE IF (@ind%7=0) SET @ind_ref=3;
ELSE IF (@ind%11=0) SET @ind_ref=4;
ELSE IF (@ind%13=0) SET @ind_ref=5;
ELSE IF (@ind%17=0) SET @ind_ref=6;
ELSE IF (@ind%19=0) SET @ind_ref=7;
ELSE IF (@ind%23=0) SET @ind_ref=8;
ELSE IF (@ind%29=0) SET @ind_ref=9;
ELSE IF (@ind%31=0) SET @ind_ref=10;
ELSE IF (@ind%37=0) SET @ind_ref=11;
ELSE SET @ind_ref=@ind%1190000;
INSERT INTO [dbo].[Customer]
([ID]
,[Name]
,[Ref_ID]
,[Ref_ID2])
SELECT
@ind,
CAST(@ind AS NVARCHAR(255)),
@ind_ref,
@ind_ref;
SET @ind=@ind+1;
END
GO
Thus, we got two tables, in one of which more than 1 million rows of data, and in the other, more than 10 million rows of data.
Now in Visual Studio you need to create a test project Visual C # Console App (.NET Framework): Next, you need to add a library for the Entity Framework to interact with the database. To add it, right-click on the project and select Manage NuGet Packages from the context menu: Then, in the window for managing NuGet packages in the search box, enter the word "Entity Framework" and select the Entity Framework package and install it: Next, in the App file. config after closing the configSections element, add the following block:
In connectionString you need to enter the connection string.
Now let's create 3 interfaces in separate files:
- Implementing the IBaseEntityID Interface
namespace TestLINQ { public interface IBaseEntityID { int ID { get; set; } } } - Implementing the IBaseEntityName Interface
namespace TestLINQ { public interface IBaseEntityName { string Name { get; set; } } } - Implementing the IBaseNameInsertUTCDate Interface
namespace TestLINQ { public interface IBaseNameInsertUTCDate { DateTime InsertUTCDate { get; set; } } }
And in a separate file, create the BaseEntity base class for our two entities, which will include common fields:
BaseEntity Base Class Implementation
namespace TestLINQ
{
public class BaseEntity : IBaseEntityID, IBaseEntityName, IBaseNameInsertUTCDate
{
public int ID { get; set; }
public string Name { get; set; }
public DateTime InsertUTCDate { get; set; }
}
}
Next, in separate files, create our two entities:
- Ref class implementation
using System.ComponentModel.DataAnnotations.Schema; namespace TestLINQ { [Table("Ref")] public class Ref : BaseEntity { public int ID2 { get; set; } } } - Customer class implementation
using System.ComponentModel.DataAnnotations.Schema; namespace TestLINQ { [Table("Customer")] public class Customer: BaseEntity { public int Ref_ID { get; set; } public int Ref_ID2 { get; set; } } }
Now create a UserContext context in a separate file:
UserContex class implementation
using System.Data.Entity;
namespace TestLINQ
{
public class UserContext : DbContext
{
public UserContext()
: base("DbConnection")
{
Database.SetInitializer(null);
}
public DbSet Customer { get; set; }
public DbSet Ref { get; set; }
}
}
We got a ready-made solution for optimization tests with LINQ to SQL through EF for MS SQL Server: Now, in the Program.cs file, enter the following code:
Program.cs File
using System;
using System.Collections.Generic;
using System.Linq;
namespace TestLINQ
{
class Program
{
static void Main(string[] args)
{
using (UserContext db = new UserContext())
{
var dblog = new List();
db.Database.Log = dblog.Add;
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
&& (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
var result = query.Take(1000).ToList();
Console.WriteLine(dblog[1]);
Console.ReadKey();
}
}
}
}
Next, run our project.
At the end of the work, the console will display:
Generated SQL query
SELECT TOP (1000)
[Extent1].[Ref_ID] AS [Ref_ID],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON ([Extent1].[Ref_ID] = [Extent2].[ID]) AND ([Extent1].[Ref_ID2] = [Extent2].[ID2])
That is, in general, a very good LINQ query generated an SQL query to MS SQL Server DBMS.
Now let's change the AND condition to OR in the LINQ query:
LINQ query
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
|| (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
And we will launch our application again.
Execution will crash with an error related to exceeding the command execution time of 30 seconds: If you look at what query LINQ: was generated at the same time , you can make sure that the selection occurs through the Cartesian product of two sets (tables):
Generated SQL query
SELECT TOP (1000)
[Extent1].[Ref_ID] AS [Ref_ID],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
CROSS JOIN [dbo].[Ref] AS [Extent2]
WHERE [Extent1].[Ref_ID] = [Extent2].[ID] OR [Extent1].[Ref_ID2] = [Extent2].[ID2]
Let's rewrite the LINQ query as follows:
Optimized LINQ Query
var query = (from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID equals e2.ID
select new { Data1 = e1.Name, Data2 = e2.Name }).Union(
from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID2 equals e2.ID2
select new { Data1 = e1.Name, Data2 = e2.Name });
Then we get the following SQL query:
SQL query
SELECT
[Limit1].[C1] AS [C1],
[Limit1].[C2] AS [C2],
[Limit1].[C3] AS [C3]
FROM ( SELECT DISTINCT TOP (1000)
[UnionAll1].[C1] AS [C1],
[UnionAll1].[Name] AS [C2],
[UnionAll1].[Name1] AS [C3]
FROM (SELECT
1 AS [C1],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON [Extent1].[Ref_ID] = [Extent2].[ID]
UNION ALL
SELECT
1 AS [C1],
[Extent3].[Name] AS [Name],
[Extent4].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent3]
INNER JOIN [dbo].[Ref] AS [Extent4] ON [Extent3].[Ref_ID2] = [Extent4].[ID2]) AS [UnionAll1]
) AS [Limit1]
Alas, there can be only one connection condition in LINQ queries, therefore it is possible to make an equivalent query through two queries for each condition, followed by combining them through Union to remove duplicates among the rows.
Yes, queries will generally be nonequivalent, given that full duplicate rows can be returned. However, in real life, full duplicate lines are not needed and they are trying to get rid of them.
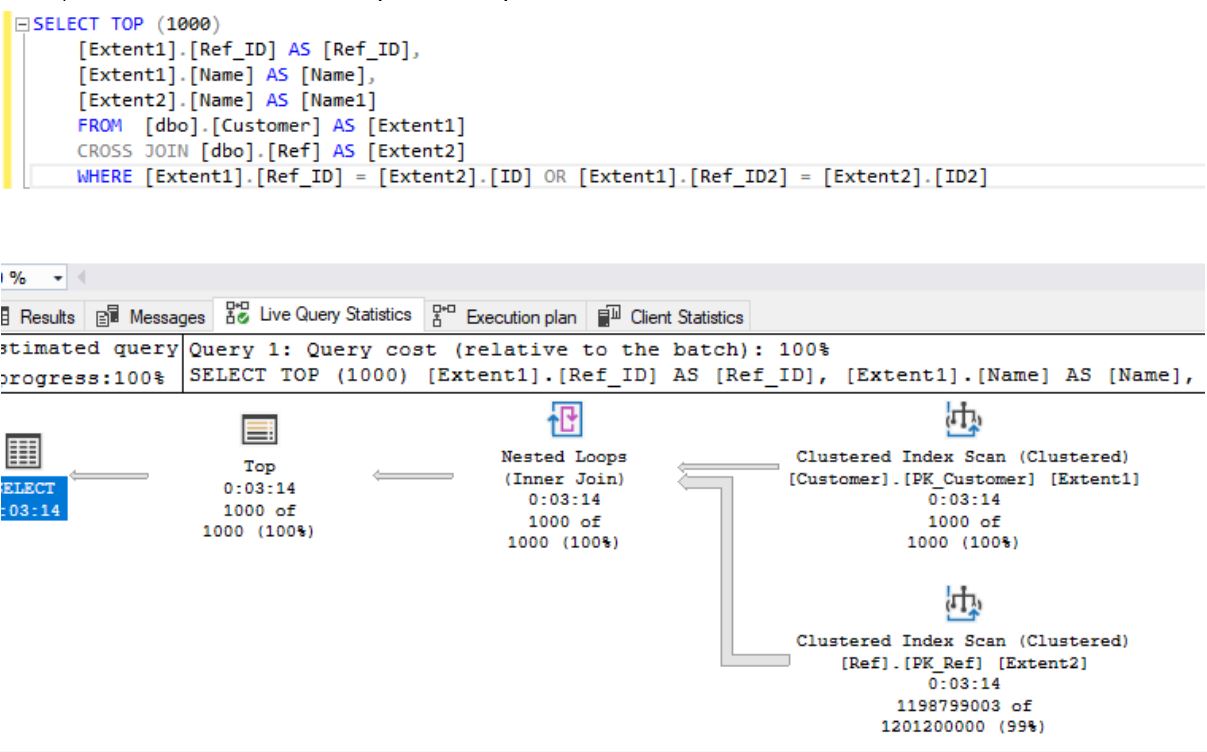
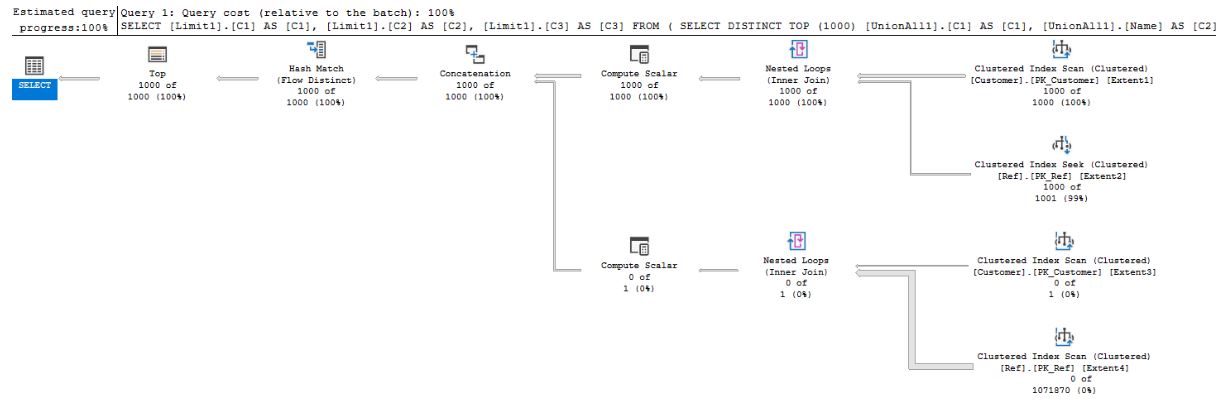
Now compare the execution plans for these two queries:
- for CROSS JOIN, the average runtime is 195 seconds:
- for an INNER JOIN-UNION, the average execution time is less than 24 seconds:
 .
.
Also in this repository in the Plans folder are plans for fulfilling requests with OR conditions.