How Perm students made it to the finals of the Data Mining Cup 2019 international data analysis championship
Hello. In this article, I will talk about our experience in participating in the Data Mining Cup 2019 (DMC) data analysis competition and how we managed to enter the TOP 10 teams and take part in the in-person championship finals in Berlin.

I will narrate on behalf of our team, which I enter (Alexander Perevalov), as well as my colleague Sergey Bobkov. We are graduate students of the Perm Polytechnic University , in our free time from work and study we are engaged in solving Data Science contests.
The Data Mining Cup is a global student data analysis championship held once a year. Its history began 20 years ago, long before Kaggle , it can be said that the DMC held data analysis competitions before it became mainstream .
DMC is hosted by the German company PrudSys , a retail intelligence company . Previously, only single-handed participation was allowed in the championship, then the participants were allowed to unite in teams from the university, by the way, the maximum number of teams from the university is only 2. Membership in the university is also strictly controlled, for participation it is necessary to have mail with the domain of your student institutions, as well as send a copy of your student card.
Today, if we compare the level of participants in DMC and Kaggle, of course, the level of Kaggle is much higher. This is due to the restriction on students in the DMC and the popularity of Kaggle. A distinctive feature of the DMC is the absence of a leaderboard , which eliminates the problems of fitting it.
I learned about the Data Mining Cup at the moment when we went with a group from our university for an internship in Germany, upon arrival at home, my friend and teammate invited me to participate, it was in mid-April. Honestly, I was skeptical of this idea, however, having learned that this year the data and the task are quite simple - we still started to solve it.
In 2019, the task lay in the field of self-checkout fraud detection. Surely you have already come across self-service checkout counters in supermarkets. These devices work both under the supervision of a store employee and fully automatically. Self-service cash registers allow you to optimize staff costs and minimize queues in supermarkets. However, there is one problem, human nature is such that in one way or another there is a desire to “not break through” the goods that we want to see in our refrigerator. To avoid this, control is necessary, but such that it does not embarrass or annoy customers.
Thus, based on the tagged data on self-checkout transactions, it is necessary to develop a mathematical model that would automatically classify a particular transaction as fraudulent or non-fraudulent.So, we solve the binary classification problem.
The data were as follows: The

size of the training sample was only ~ 1800 examples, while the test sample was 499000 examples. Also, the training sample was not balanced : only 4% of transactions were fraudulent, it is obvious that accuracy (the share of correct answers) is useless here. Surprisingly, there were no missing values in the data, and some of the attributes were evenly distributed. Based on this, we can conclude that the data is generated artificially.
Also, the organizers proposed their metric in the form of a Confusion Matrix, which is measured in monetary units:
After analyzing it, it became clear to us that Precision is more important in this case, because we bear the maximum loss if we mistakenly call an honest buyer a fraudster.
The course of our solution consisted of classical stages:
Slides with the content of our solution can be found at: www.docdroid.net/2XEDfYg/dmc-2019-1.pdf
Repository on GitHub here: github.com/Perevalov/dmc2019 (everything is scattered on different branches, until there was time to bring everything in order)
After we sent the final decision in early May, we began to expect results. The conditions of the organizers are such that the Top 10 teams are invited to an in-person final in Berlin , which is held as part of the Retail intelligence summit 2019 conference: Smart Decisions for Smart Retail.
For reference, in 2019, 149 teams from 114 universities located in 28 countries participated in the DMC.
To be honest, we did not even hope to get to the finals , but now, at the end of May, that cherished invitation letter comes. Moreover, all finalists were asked to pay expenses of up to 500 Euros, and they also offered accommodation in a hotel for one night, where the event was held.
Without hesitation, we bought tickets to Berlin and went to get visas. Being poor students, the amount of expenses for a 2-day trip turned out to be rather big for us. The costs of Perm-Berlin-Perm tickets and visa processing stood at about 40,000 rubles. per person, this is a little more than 500 euros.
Since we represent our university at the event, we decided to get material support from it. Moreover, the Perm Polytechnic University implements a program for the development of Russian-German relations and strongly supports initiative students (it seemed to us so). With the approval and signature of the head of the department in which we study, we went to the department of science and innovation. There began a month-long bureaucratic saga, which ended with something like the following: “There is no money, but you hold on”. Of course we were a little upset, but did not lose heart. Now it’s ridiculous to read various statements by the top management of our university about the “need to support young scientists” and other nonsense. Well it is, a digression.
We got visas in just 2 weeks. During the same time, we prepared a report for the speech and on July 2 in the evening we went to the airport.
Arriving in Berlin on July 3rd in the morning, we went to the nHow Hotel, where the conference was held. The level of organization, of course, is high. Indeed, the cost of participation in it was 1000 euros per person (for us it’s free). And this is what the hotel looks like:

Our performance was scheduled for 16:30. It took place in the main conference room, naturally in English. By the way, the performance itself was not taken into account in the final rating, it was calculated only on the basis of the final rate, which only the organizers had data on.
Among the first 10 teams were such universities as: George Washington University (USA), University of Geneva (Switzerland), Technological University of Chemnitz (Germany), University of Iowa (USA), etc. And of course, our Perm National Research Polytechnic University.
This was what the conference room looked like: A

small embarrassment was the fact that I had to speak not with slides, but with one poster displayed on the screen. Therefore, the performances of the participants were not sufficiently informative. However, there was an opportunity to approach and view the paper poster of each of the participants in the conference room. Basically, most people used stacking, blending and ensembling (we are among them), also, some participants used an increased thresholdto classification models, a couple of teams managed not to generate traits at all and built the model on the source.
By the way, we were the smallest team - only 2 people.
After the performances, a gala dinner and rewarding began. We hoped for prizes, but realized that this was unlikely, so our mundane desire was “at least not be 10”. It turned out exactly as we wanted - we took the honorable 9th place. Naturally, it was a little annoying, but the fact that we were in the final among such serious universities already says a lot. The winners were participants from the University of Iowa (USA), although you can’t say that they came from the states (see photo):

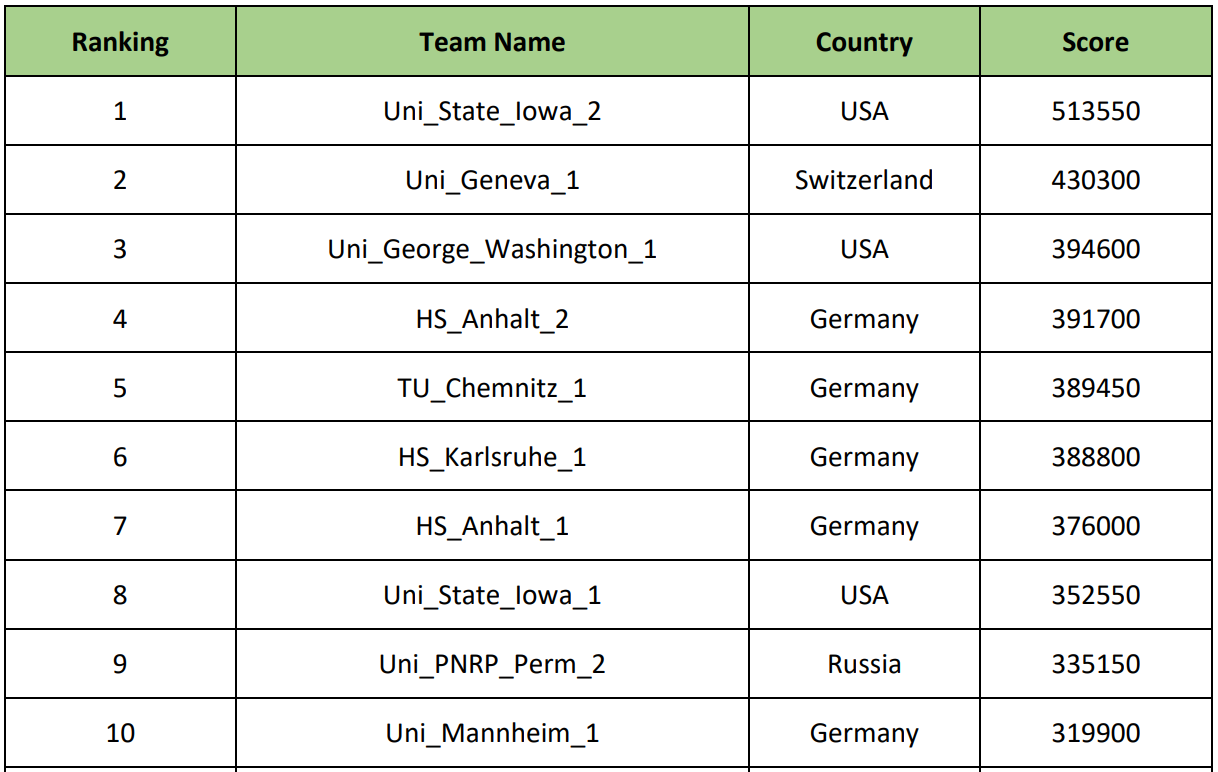
Prizes for 1st, 2nd and 3rd places were 2000, 1000 and 500 euros, respectively. The final rating is as follows:
We did not regret how much we participated in this competition. At a minimum, this is a +1 achievement in the portfolio, at the most useful contacts with people and the opportunity to represent our city and country at an international event.
I advise all Scientists to take part in such events, it's cool!
I will narrate on behalf of our team, which I enter (Alexander Perevalov), as well as my colleague Sergey Bobkov. We are graduate students of the Perm Polytechnic University , in our free time from work and study we are engaged in solving Data Science contests.
What is DMC and how did we find out about it
The Data Mining Cup is a global student data analysis championship held once a year. Its history began 20 years ago, long before Kaggle , it can be said that the DMC held data analysis competitions before it became mainstream .
DMC is hosted by the German company PrudSys , a retail intelligence company . Previously, only single-handed participation was allowed in the championship, then the participants were allowed to unite in teams from the university, by the way, the maximum number of teams from the university is only 2. Membership in the university is also strictly controlled, for participation it is necessary to have mail with the domain of your student institutions, as well as send a copy of your student card.
Today, if we compare the level of participants in DMC and Kaggle, of course, the level of Kaggle is much higher. This is due to the restriction on students in the DMC and the popularity of Kaggle. A distinctive feature of the DMC is the absence of a leaderboard , which eliminates the problems of fitting it.
I learned about the Data Mining Cup at the moment when we went with a group from our university for an internship in Germany, upon arrival at home, my friend and teammate invited me to participate, it was in mid-April. Honestly, I was skeptical of this idea, however, having learned that this year the data and the task are quite simple - we still started to solve it.
How we solved the task
In 2019, the task lay in the field of self-checkout fraud detection. Surely you have already come across self-service checkout counters in supermarkets. These devices work both under the supervision of a store employee and fully automatically. Self-service cash registers allow you to optimize staff costs and minimize queues in supermarkets. However, there is one problem, human nature is such that in one way or another there is a desire to “not break through” the goods that we want to see in our refrigerator. To avoid this, control is necessary, but such that it does not embarrass or annoy customers.
Thus, based on the tagged data on self-checkout transactions, it is necessary to develop a mathematical model that would automatically classify a particular transaction as fraudulent or non-fraudulent.So, we solve the binary classification problem.
The data were as follows: The
size of the training sample was only ~ 1800 examples, while the test sample was 499000 examples. Also, the training sample was not balanced : only 4% of transactions were fraudulent, it is obvious that accuracy (the share of correct answers) is useless here. Surprisingly, there were no missing values in the data, and some of the attributes were evenly distributed. Based on this, we can conclude that the data is generated artificially.
Also, the organizers proposed their metric in the form of a Confusion Matrix, which is measured in monetary units:
| Actual values | ||
|---|---|---|
| Fraud | Not fraud | |
| Fraud | 5 Euro (TP) | -25 Euro (FP) |
| Not fraud | -5 Euro (FN) | 0 Euro (TN) |
After analyzing it, it became clear to us that Precision is more important in this case, because we bear the maximum loss if we mistakenly call an honest buyer a fraudster.
The course of our solution consisted of classical stages:
- Basic data analysis
- Analysis of signs, their descriptive statistics and distributions
- Outlier removal
- Character Generation
- Building a model and setting parameters
- Validation and Final Forecast
Slides with the content of our solution can be found at: www.docdroid.net/2XEDfYg/dmc-2019-1.pdf
Repository on GitHub here: github.com/Perevalov/dmc2019 (everything is scattered on different branches, until there was time to bring everything in order)
Organizational Finals
After we sent the final decision in early May, we began to expect results. The conditions of the organizers are such that the Top 10 teams are invited to an in-person final in Berlin , which is held as part of the Retail intelligence summit 2019 conference: Smart Decisions for Smart Retail.
For reference, in 2019, 149 teams from 114 universities located in 28 countries participated in the DMC.
To be honest, we did not even hope to get to the finals , but now, at the end of May, that cherished invitation letter comes. Moreover, all finalists were asked to pay expenses of up to 500 Euros, and they also offered accommodation in a hotel for one night, where the event was held.
Without hesitation, we bought tickets to Berlin and went to get visas. Being poor students, the amount of expenses for a 2-day trip turned out to be rather big for us. The costs of Perm-Berlin-Perm tickets and visa processing stood at about 40,000 rubles. per person, this is a little more than 500 euros.
Since we represent our university at the event, we decided to get material support from it. Moreover, the Perm Polytechnic University implements a program for the development of Russian-German relations and strongly supports initiative students (it seemed to us so). With the approval and signature of the head of the department in which we study, we went to the department of science and innovation. There began a month-long bureaucratic saga, which ended with something like the following: “There is no money, but you hold on”. Of course we were a little upset, but did not lose heart. Now it’s ridiculous to read various statements by the top management of our university about the “need to support young scientists” and other nonsense. Well it is, a digression.
We got visas in just 2 weeks. During the same time, we prepared a report for the speech and on July 2 in the evening we went to the airport.
Performance at the final of the Data Mining Cup and awarding
Arriving in Berlin on July 3rd in the morning, we went to the nHow Hotel, where the conference was held. The level of organization, of course, is high. Indeed, the cost of participation in it was 1000 euros per person (for us it’s free). And this is what the hotel looks like:
Our performance was scheduled for 16:30. It took place in the main conference room, naturally in English. By the way, the performance itself was not taken into account in the final rating, it was calculated only on the basis of the final rate, which only the organizers had data on.
Among the first 10 teams were such universities as: George Washington University (USA), University of Geneva (Switzerland), Technological University of Chemnitz (Germany), University of Iowa (USA), etc. And of course, our Perm National Research Polytechnic University.
This was what the conference room looked like: A
small embarrassment was the fact that I had to speak not with slides, but with one poster displayed on the screen. Therefore, the performances of the participants were not sufficiently informative. However, there was an opportunity to approach and view the paper poster of each of the participants in the conference room. Basically, most people used stacking, blending and ensembling (we are among them), also, some participants used an increased thresholdto classification models, a couple of teams managed not to generate traits at all and built the model on the source.
By the way, we were the smallest team - only 2 people.
After the performances, a gala dinner and rewarding began. We hoped for prizes, but realized that this was unlikely, so our mundane desire was “at least not be 10”. It turned out exactly as we wanted - we took the honorable 9th place. Naturally, it was a little annoying, but the fact that we were in the final among such serious universities already says a lot. The winners were participants from the University of Iowa (USA), although you can’t say that they came from the states (see photo):
Prizes for 1st, 2nd and 3rd places were 2000, 1000 and 500 euros, respectively. The final rating is as follows:
conclusions
We did not regret how much we participated in this competition. At a minimum, this is a +1 achievement in the portfolio, at the most useful contacts with people and the opportunity to represent our city and country at an international event.
I advise all Scientists to take part in such events, it's cool!
Only registered users can participate in the survey. Please come in.
Have you participated in data analysis competitions?
- 25% Yes 5
- 50% No 10
- 25% Not Interested in Data Science 5