Prototype Sentiment Analysis with Python and TextBlob

What is important for a development team that is just starting to build a machine learning system? Architecture, components, testing capabilities using integration and unit tests, make a prototype and get the first results. And further to the assessment of labor input, planning development and implementation.
This article will focus on the prototype. Which was created some time after talking with Product Manager: why don't we “touch” Machine Learning? In particular, NLP and Sentiment Analysis?
"Why not?" I answered. Still, I’ve been doing backend development for more than 15 years, I like working with data and solving performance problems. But I still had to find out, “how deep the rabbit hole”.
Select components
In order to somehow outline the set of components that implement the logic of our ML core, let's take a look at a simple example of the implementation of sentiment analysis, one of the many available on GitHub.
One example of sentiment analysis in Python
import collections
import nltk
import os
from sklearn import (
datasets, model_selection, feature_extraction, linear_model
)
def extract_features(corpus):
'''Extract TF-IDF features from corpus'''
# vectorize means we turn non-numerical data into an array of numbers
count_vectorizer = feature_extraction.text.CountVectorizer(
lowercase=True, # for demonstration, True by default
tokenizer=nltk.word_tokenize, # use the NLTK tokenizer
stop_words='english', # remove stop words
min_df=1 # minimum document frequency, i.e. the word must appear more than once.
)
processed_corpus = count_vectorizer.fit_transform(corpus)
processed_corpus = feature_extraction.text.TfidfTransformer().fit_transform(
processed_corpus)
return processed_corpus
data_directory = 'movie_reviews'
movie_sentiment_data = datasets.load_files(data_directory, shuffle=True)
print('{} files loaded.'.format(len(movie_sentiment_data.data)))
print('They contain the following classes: {}.'.format(
movie_sentiment_data.target_names))
movie_tfidf = extract_features(movie_sentiment_data.data)
X_train, X_test, y_train, y_test = model_selection.train_test_split(
movie_tfidf, movie_sentiment_data.target, test_size=0.30, random_state=42)
# similar to nltk.NaiveBayesClassifier.train()
model = linear_model.LogisticRegression()
model.fit(X_train, y_train)
print('Model performance: {}'.format(model.score(X_test, y_test)))
y_pred = model.predict(X_test)
for i in range(5):
print('Review:\n{review}\n-\nCorrect label: {correct}; Predicted: {predict}'.format(
review=X_test[i], correct=y_test[i], predict=y_pred[i]
))
Parsing such examples is a separate challenge for the developer.
Only 45 lines of code, and 4 (four, Karl!) Logical blocks at once:
- Downloading data for model training (lines 25-26)
- Preparing uploaded data - feature extraction (lines 31-34)
- Creating and training a model (lines 36-39)
- Testing a trained model and outputting results (lines 41-45)
Each of these points deserves a separate article. And it certainly requires registration in a separate module. At least for the needs of unit testing.
Separately, it is worth highlighting the components of data preparation and model training.
In each of the ways to make the model more precise, hundreds of hours of scientific and engineering work are invested.
Fortunately, in order to quickly start with NLP, there is a ready-made solution - the NLTK and TextBlob libraries . The second is a wrapper over NLTK that does the chore - makes feature extraction from the training set, and then trains the model on the first classification request.
But before you train the model, you need to prepare data for it.
Preparing data
Download data
If we talk about the prototype, then loading data from a CSV / TSV file is elementary. You simply call the read_csv function from the pandas library:
import pandas as pd
data = pd.read_csv(data_path, delimiter)
But it will not be data ready for use in the model.
Firstly, if we ignore the csv format a bit, then it is easy to expect that each source will provide data with its own characteristics, and therefore we need some kind of source-dependent data preparation. Even for the simplest case of a CSV file, to just parse it, we need to know the delimiter.
In addition, you should determine which entries are positive and which are negative. Of course, this information is indicated in the annotation to the datasets that we want to use. But the fact is that in one case the sign of pos / neg is 0 or 1, in the other it is a logical True / False, in the third it is just a pos / neg string, and in some case, a tuple of integers from 0 to 5 The latter is relevant for the case of multiclass classification, but who said that such a data set cannot be used for binary classification? You just need to adequately identify the border of positive and negative values.
I would like to try the model on different data sets, and it is required that, after training, the model returns the result in one single format. And for this, its heterogeneous data should be brought to a single form.
So, there are three functions that we need at the data loading stage:
- Connection to the data source is for CSV, in our case it is implemented inside the read_csv function;
- Support for format features;
- Preliminary data preparation.
This is how it looks in code.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import logging
log = logging.getLogger()
class CsvSentimentDataLoader():
def __init__(self, file_path, delim, text_attr, rate_attr, pos_rates):
self.data_path = file_path
self.delimiter = delim
self.text_attr = text_attr
self.rate_attr = rate_attr
self.pos_rates = pos_rates
def load_data(self):
# Здесь данные вычитываются из csv или tsv файла
data = pd.read_csv(self.data_path, self.delimiter)
data.head()
# Отбрасываются все колонки,
# кроме текста и классифицирующего атрибута
data = data[[self.text_attr, self.rate_attr]]
# Значения классифицирующего атрибута
# приводятся к текстовым значениям ‘pos’ и ‘neg’
data[self.rate_attr] = np.where(
data[self.rate_attr].isin(self.pos_rates), 'pos', 'neg')
return data
The class CsvSentimentDataLoader was made , which in the constructor is passed the path to csv, the separator, the names of the text and classification attributes, as well as a list of values that advise the positive value of the text.
The loading itself occurs in the load_data method .
We divide the data into test and training sets
Ok, we uploaded the data, but we still need to divide it into the training and test sets.
This is done with the train_test_split function from the sklearn library . This function can take a lot of parameters as input, determining how exactly this dataset will be divided into train and test. These parameters significantly affect the resulting training and test sets, and it will probably be convenient for us to create a class (let's call it SimpleDataSplitter) that will manage these parameters and aggregate the call to this function.
from sklearn.model_selection import train_test_split # to split the training and testing data
import logging
log = logging.getLogger()
class SimpleDataSplitter():
def __init__(self, text_attr, rate_attr, test_part_size=.3):
self.text_attr = text_attr
self.rate_attr = rate_attr
self.test_part_size = test_part_size
def split_data(self, data):
x = data[self.text_attr]
y = data[self.rate_attr]
x_train, x_test, y_train, y_test = train_test_split(
x, y, test_size = self.test_part_size)
return x_train, x_test, y_train, y_test
Now this class includes the simplest implementation, which, when divided, will take into account only one parameter - the percentage of records that should be taken as a test set.
Datasets
To train the model, I used freely available datasets in CSV format:
- Amazon Alexa Reviews Data Set, available at Kaggle
- University of California Sentiment Labelled Sentences Data Set
And to make it even more convenient, for each of the datasets I made a class that loads data from the corresponding CSV file and splits it into training and test sets.
import os
import collections
import logging
from web.data.loaders import CsvSentimentDataLoader
from web.data.splitters import SimpleDataSplitter, TdIdfDataSplitter
log = logging.getLogger()
class AmazonAlexaDataset():
def __init__(self):
self.file_path = os.path.normpath(os.path.join(os.path.dirname(__file__), 'amazon_alexa/train.tsv'))
self.delim = '\t'
self.text_attr = 'verified_reviews'
self.rate_attr = 'feedback'
self.pos_rates = [1]
self.data = None
self.train = None
self.test = None
def load_data(self):
loader = CsvSentimentDataLoader(self.file_path, self.delim, self.text_attr, self.rate_attr, self.pos_rates)
splitter = SimpleDataSplitter(self.text_attr, self.rate_attr, test_part_size=.3)
self.data = loader.load_data()
x_train, x_test, y_train, y_test = splitter.split_data(self.data)
self.train = [x for x in zip(x_train, y_train)]
self.test = [x for x in zip(x_test, y_test)]
Yes, for data loading, it turned out a little more than 5 lines of code in the original example.
But now it’s now possible to create new datasets by juggling data sources and training set preparation algorithms.
Plus, individual components are much more convenient for unit testing.
We train the model
The model has been learning for quite some time. And this must be done once, at the start of the application.
For these purposes, a small wrapper was made that allows you to download and prepare data, as well as train the model at the time of application initialization.
class TextBlobWrapper():
def __init__(self):
self.log = logging.getLogger()
self.is_model_trained = False
self.classifier = None
def init_app(self):
self.log.info('>>>>> TextBlob initialization started')
self.ensure_model_is_trained()
self.log.info('>>>>> TextBlob initialization completed')
def ensure_model_is_trained(self):
if not self.is_model_trained:
ds = SentimentLabelledDataset()
ds.load_data()
# train the classifier and test the accuracy
self.classifier = NaiveBayesClassifier(ds.train)
acr = self.classifier.accuracy(ds.test)
self.log.info(str.format('>>>>> NaiveBayesClassifier trained with accuracy {}', acr))
self.is_model_trained = True
return self.classifier
First we get training and test data, then we do feature extraction, and finally we train the classifier and check the accuracy on the test set.
Testing
Upon initialization, we get a log, judging by which, the data was downloaded and the model was successfully trained. And trained with very good (for starters) accuracy - 0.8878.
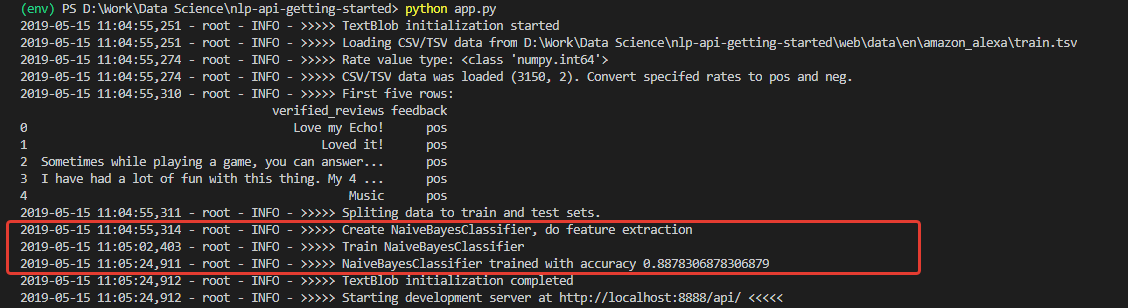
Having received such numbers, I was very enthusiastic. But my joy, unfortunately, was not long. The model trained on this set is an impenetrable optimist and, in principle, is not able to recognize negative comments.
The reason for this is in the training set data. The number of positive reviews in the set is over 90%. Accordingly, with a model accuracy of about 88%, negative reviews simply fall into the expected 12% of incorrect classifications.
In other words, with such a training set, it is simply impossible to train the model to recognize negative comments.
To really make sure of this, I did a unit test that runs the classification separately for 100 positive and 100 negative phrases from another data set - for testing I took the Sentiment Labelled Sentences Data Set from the University of California.
@loggingtestcase.capturelogs(None, level='INFO')
def test_classifier_on_separate_set(self, logs):
tb = TextBlobWrapper() # Going to be trained on Amazon Alexa dataset
ds = SentimentLabelledDataset() # Test dataset
ds.load_data()
# Check poisitives
true_pos = 0
data = ds.data.to_numpy()
seach_mask = np.isin(data[:, 1], ['pos'])
data = data[seach_mask][:100]
for e in data[:]:
# Model train will be performed on first classification call
r = tb.do_sentiment_classification(e[0])
if r == e[1]:
true_pos += 1
self.assertLessEqual(true_pos, 100)
print(str.format('\n\nTrue Positive answers - {} of 100', true_pos))
The algorithm for testing the classification of positive values is as follows:
- Download test data;
- Take 100 posts tagged 'pos'
- We run each of them through the model and count the number of correct results
- Display the final result in the console.
Similarly, a count is made for negative comments.
Result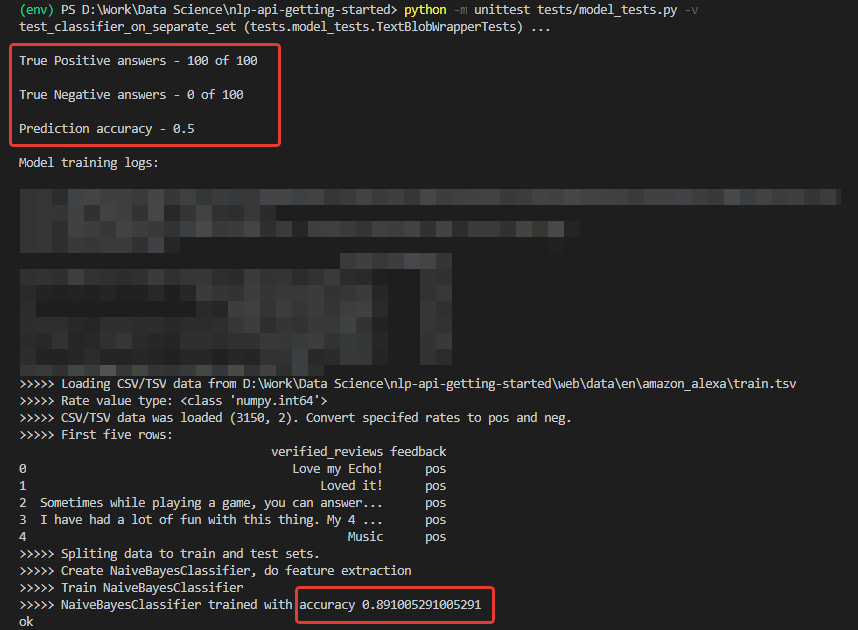
As expected, all negative comments were recognized as positive.
And if you train the model on the dataset used for testing - Sentiment Labelled ? There, the distribution of negative and positive comments is exactly 50 to 50.
Change the code and test, run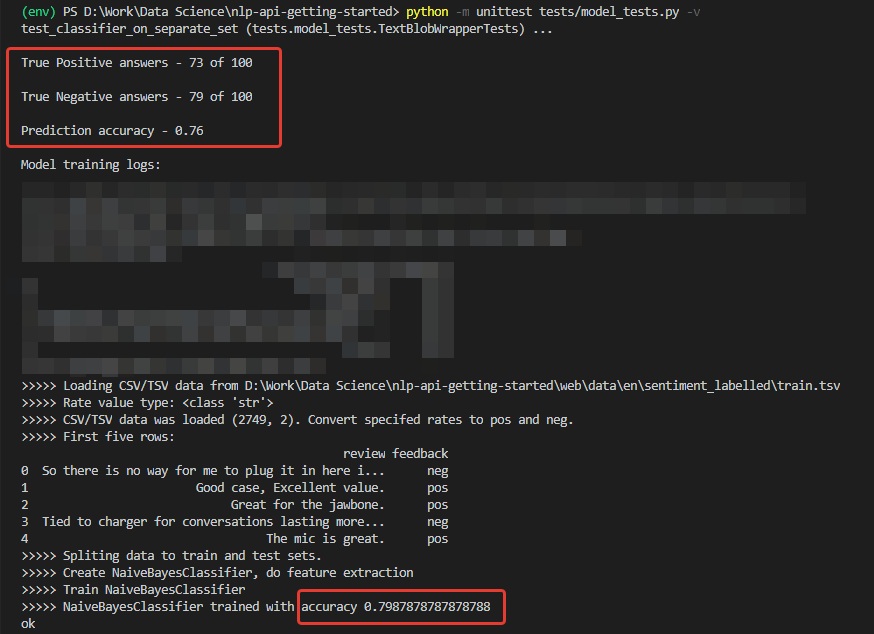
Something already. The actual accuracy of 200 entries from a third-party set is 76%, while the accuracy of classification of negative comments is 79%.
Of course, 76% will do for a prototype, but not enough for production. This means that additional measures will be required to improve the accuracy of the algorithm. But this is a topic for another report.
Summary
Firstly, we got an application with a dozen classes and 200+ lines of code, which is slightly more than the original example by 30 lines. And you should be honest - these are just hints at the structure, the first clarification of the boundaries of the future application. Prototype.
And this prototype made it possible to realize how far the distance between approaches to the code is from the point of view of Machine Learning specialists and from the point of view of developers of traditional applications. And this, in my opinion, is the main difficulty for developers who decide to try machine learning.
The next thing that can put a beginner in a stupor - the data is no less important than the selected model. This has been clearly shown.
Further, there always remains the possibility that a model trained on some data will show itself inadequately on others, or at some point its accuracy will begin to degrade.
Accordingly, metrics are required to monitor the state of the model, flexibility when working with data, technical capabilities to adjust learning on the fly. Etc.
As for me, all this should be taken into account when designing the architecture and building development processes.
In general, the "rabbit hole" was not only very deep, but also extremely cleverly laid. But all the more interesting for me, as a developer, to study this topic in the future.