Queues - what is it, why and how to use it? Take a look at AWS SQS features

First, let's define the concept of “queue”.
Take for consideration the queue type “FIFO” (first in, first out). If you take the value from Wikipedia - "this is an abstract data type with the discipline of access to elements." In short, this means that we cannot get data from it in a random order, but only pick up what came first.
Next, you need to decide why they are needed at all?
1. For deferred operations. A classic example is image processing. For example, a user uploaded a picture to the site that we need to process, this operation takes a lot of time, the user does not want to wait so much. Therefore, we load the picture, then transfer it to the queue. And it will be processed when any “worker” gets it.
2. For handling peak loads. For example, there is some part of the system that sometimes causes a lot of traffic and it does not require an instant response. As an option, generating any reports. Throwing this task in the queue - we give the opportunity to handle it with a uniform load on the system.
3. Scalability. And probably the most important reason, the queue makes it possible
scale up. This means that you can bring up several services for processing in parallel, which will greatly increase productivity.
Now let's look at the problems that we will face if we create the queue ourselves:
1. Parallel access. Only one handler can take a message from a queue. That is, if at the same time two services ask for messages, each of them must return a unique set of messages. Otherwise, it turns out that one message is processed twice. What could be fraught.
2. The mechanism of deduplication. The service should have a system that protects the queue from duplicates. There may be a situation in which one and the same dataset will be sent to the queue by chance twice. As a result, we will process the same thing twice. Which again is fraught.
3. Error handling mechanism.Let's say our service took three messages from the queue. Two of which he successfully processed by sending removal requests from the queue. And the third he could not process and died. A message that is in processing status is not available for other services. And it should not forever remain in processing status. Such a message should be passed to another handler by some logic. An example of the implementation of this logic will be considered soon using AWS SQS (Simple Queue Service) as an example.
Amazon Web Services - Simple Queue Service
Now let's look at how SQS solves these problems and what it can do.
1. Parallel access. At the queue, you can set the Visibility timeout parameter . It determines how long the processing of a message can take as long as possible. By default, it is 30 seconds. When a service picks up a message, it is transferred to the “In Flight” status for 30 seconds. If during this time there was no command to remove this message from the queue, it returns to the beginning and the next service can receive it again for processing.
Small shemka work.
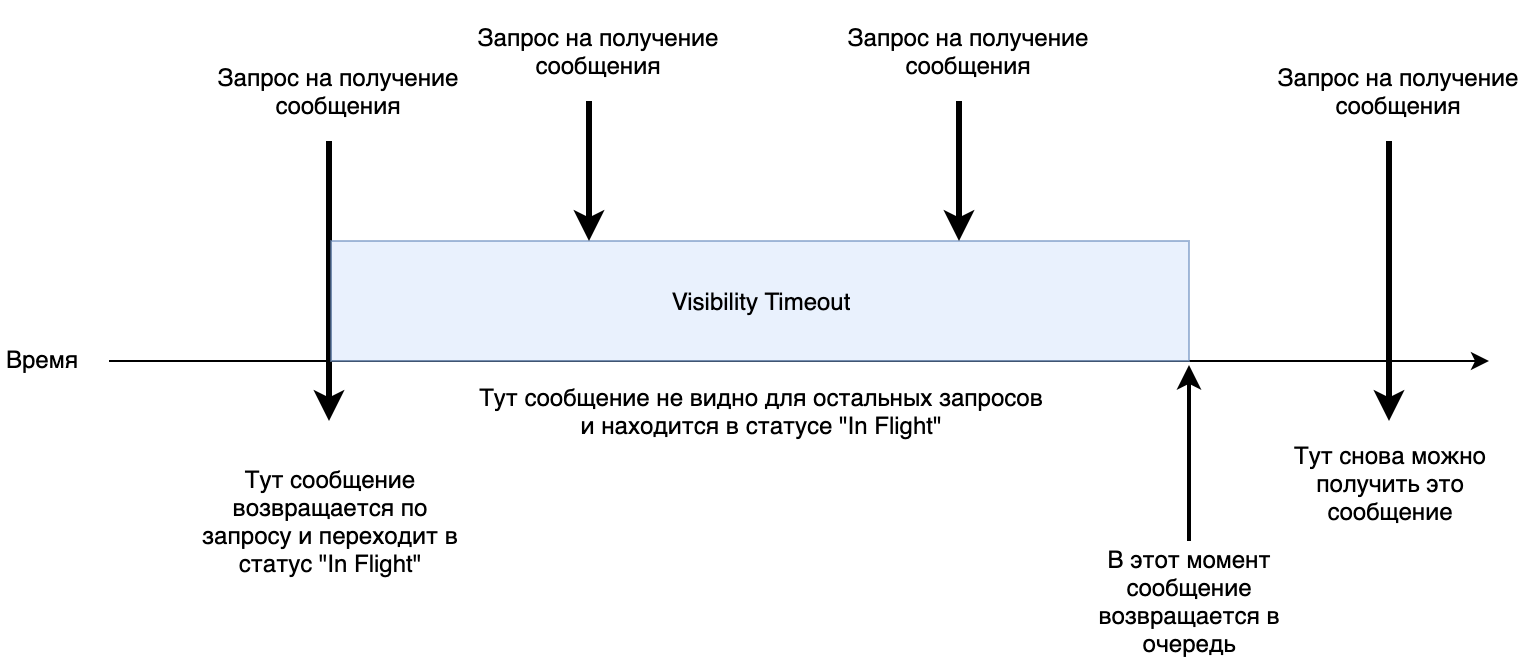
Notice: Be careful. SQS in some cases may send a duplicate message (Item "At-Least-Once Delivery"). Therefore, your service should be idempotent for processing .
2. Error handling mechanism. In SQS, you can configure the second turn for "dead" messages (Dead Letter Queue). That is, those that could not process our service will be sent to a separate queue, which you can dispose of at your discretion. You can also set after which the number of unsuccessful attempts the message will go into the "dead" queue. A failed attempt is the expiration of the "Visibility timeout". That is, if no deletion request was sent during this time, such a message will be considered unprocessed and will return to the main queue or go to the "dead".
3. Deduplication of messages. SQS also has a duplicate protection system. Each message has a “Deduplication Id” , SQS will not queue a message with
repeated “Deduplication Id” for 5 minutes. You must specify a “Deduplication Id” in each message or enable content-based id generation. This means that a hash generated based on your content will get into the “Deduplication Id”. The parameter "Content-Based Deduplication". More About Deduplication
Notice: Be careful if you send two identical messages within 5 minutes and you have “Content-Based Deduplication” turned on. SQS will not add a second message to the queue.
Notice: Be careful, for example, if the connection is lost on the device and it does not receive a response and then sends a second request after 5 minutes, a duplicate will be created.4. Long poll. Long survey . SQS supports this type of connection with a maximum timeout of 20 seconds. What allows us to save on traffic and "jerking" of the service.
5. Metrics. Amazon also provides detailed queue metrics. Such as the number of received / sent / deleted messages, the size in KB of these messages and so on. You can also connect SQS to the CloudWatch log service. There you can see even more. Also there you can configure the so-called “alarms” and you can configure actions for any events. Learn more about connecting to SQS. And CloudWatch Documentation
Now let's look at the queue settings:
The main ones:
Default Visibility Timeout - the number of seconds / minutes / hours for which the message after receiving will not be visible for receiving. The maximum processing time is 12 hours.
Message Retention Period - the number of seconds / minutes / hours / days, which means how long unprocessed messages will be stored in the queue. Maximum - 14 days.
Maximum Message Size - maximum message size in KB. The value is from 1KB to 256KB.
Delivery Delay - you can set the delay time for delivering a message to the queue. From 0 seconds to 15 minutes (In fact, messages will be in the queue, but will not be visible to receive).
Receive Message Wait Time -time, how long the connection will hold in case we use “Long poll” to receive new messages.
Content-Based Deduplication - the flag, if set to true, then a “Deduplication Id” will be added to each message in the form of a SHA-256 hash generated from the content.
Dead Queue Settings
Use Redrive Policy - a flag, if set, then messages will be redirected after several attempts.
Dead Letter Queue - the name of the "dead" queue to which raw messages will be sent.
Maximum Receives - the number of unsuccessful processing attempts, after which the message will be sent to the "dead" queue
Notice: Also note that we can send all the main parameters together with each message separately. For example, each individual message may have its own Visibility Timeout or Delivery Delay.
Now a little about the messages themselves and their properties:
A message has several parameters:
1. Message body - any text
2. Message Group Id - this is something like a tag, channel, required for all messages. Each such group is guaranteed to be processed in FIFO mode.
3. Message Deduplication Id - string to identify duplicates. If the "Content-Based Deduplication" mode is set, the parameter is optional.
There are also message attributes
Attributes consist of a name, type and value.
1. Name - string
2. Type - there are several types: string, number, binary. The type comes simply as a string, and it is possible to add a postfix to the type. In this case, the type will come with this postfix through the dot, for example string.example_postfix
3. Value - string
Notice: Please note that the maximum number of attributes is 10 DetailsPS: This article provides a brief description of the queue, as well as a little about the capabilities and mechanics of SQS. The following article will be devoted to AWS Lambda , and then their practical sharing.