Machine learning in an investment company: we classify technical support calls
In theory, the use of machine learning (ML) helps reduce human involvement in processes and operations, reallocate resources, and reduce costs. How does this work in a particular company and industry? As our experience shows, it works.
At a certain stage of development, we at VTB Capital were faced with an urgent need to reduce the time it takes to process requests for technical support. After analyzing the options, it was decided to use ML technology to categorize calls from business users of Calypso, the company's key investment platform. The fast processing of such requests is crucial for the high quality of the IT service. We asked our key partners, EPAM, to help solve this problem .

So, support requests are received by e-mail and transformed into tickets in Jira. Then, support specialists manually classify them, prioritize them, enter additional data (for example, from which department and location a request was received, which functional unit of the system it belongs to) and appoint performers. In total, about 10 categories of queries are used. This, for example, may be a request to analyze some data and provide the author of the request with information, add a new user, etc. Moreover, actions can be either standard or non-standard, so it is very important to immediately correctly determine the type of request and assign execution to the right specialist.
It is important to note: VTB Capital wanted not only to develop an applied technological solution, but also to evaluate the capabilities of various tools and technologies on the market. One task, two different approaches, two technology platforms and three and a half weeks: what was the result?
The basis for the development of the prototype was the approach proposed by the EPAM team, and historical data - about 10,000 tickets from Jira. The main attention was focused on the 3 required fields that each such ticket contains: Issue Type (type of problem), Summary ("header" of the letter or subject of the request) and Description (description). Within the framework of the project, it was planned to solve the problem of analyzing the text from the Summary and Description fields and automatically determine the type of request based on its results.
It is the features of the text in these two ticket fields that became the main technical difficulty in analyzing data and developing ML models. So, the Summary field can contain quite “clean” text, but including specific words and terms (for example, CWS reports not running).The Description field, on the contrary, is characterized by a more “dirty” text with an abundance of special characters, notations, backslashes and residues of non-text elements:
In addition, the text often combines several languages (mainly, naturally, Russian and English), business terminology, ruglish and programmer slang can be found. And of course, since requests are often written in a hurry, in both cases typos and spelling errors are not ruled out.
The technologies chosen by the EPAM team included Python 3.5 for prototype development, NLTK + Gensim + Re for text processing, Pandas + Sklearn for data analysis and model development, and Keras + Tensorflow as a deep learning framework and backend.
Taking into account the possible features of the initial data, three representations were constructed for character extraction from the Summary field: at the level of characters, combinations of characters and individual words. Each of the representations was used as an entrance to a recurrent neural network.
In turn, the service character statistics (important for processing text using exclamation points, slashes, etc.) and the average values of the strings after filtering the service characters and garbage (for compact preservation of the text structure) were chosen as a representation for the Description field; , as well as word-level representation after filtering stop words. Each representation served as an entrance to a neural network: statistics in a fully connected, line-by-line and at the level of words - in a recursive one.
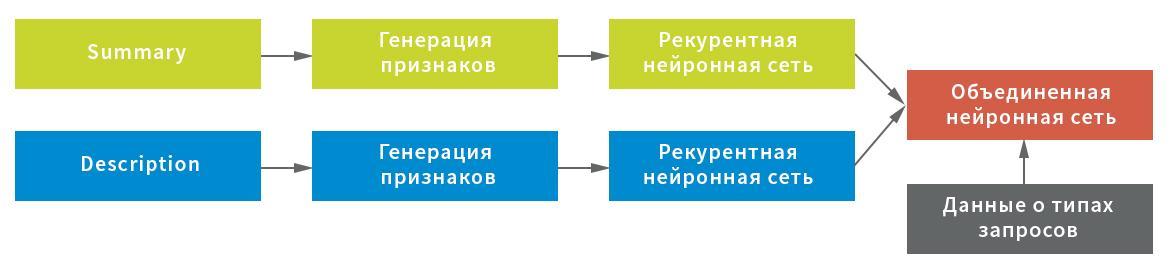
In this scheme, a neural network was used as a recurrent network, consisting of a bidirectional GRU layer with a recursive and normal dropout, a pool of hidden states of the recurrent network using the GlobalMaxPool1D layer and a fully connected (Dense) layer with a dropout. For each of the inputs, its own “head” of the neural network was built, and then they were combined through concatenation and locked to the target variable.
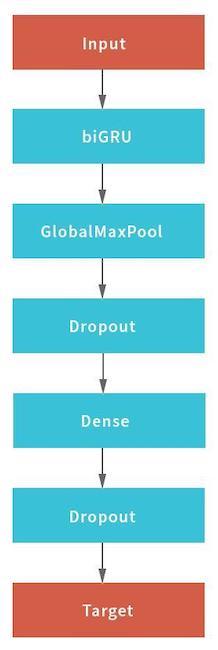
To obtain the final result, the combined neural network returned the probabilities of a particular request belonging to each type. The data were divided into five blocks without intersections: the model was built on four of them and checked on the fifth. Since each request can be assigned only one type of request, the rule for making a decision was simple - by the maximum probability value.
The second prototype, for which the proposal prepared by the VTB Capital team was taken, is an application on Microsoft .NET Core with Microsoft.ML libraries for implementing machine learning algorithms and the Atlassian.Net SDK for interacting with Jira via the REST API. The basis for building ML-models also became historical data - 50,000 Jira-tickets. As in the first case, machine learning covered the fields Summary and Description. Before use, both fields were also “cleaned”. Greetings, signatures, correspondence history and non-textual elements (for example, images) were deleted from the user's letter. In addition, using the built-in functionality in Microsoft ML, stop words that were not important for processing and analyzing the text were cleared from English text.
Averaged Perceptron (binary classification) was chosen as a machine learning algorithm, which is supplemented by the One Versus All method to provide multiclass classification
No ML model can (possibly, yet) provide 100% accuracy of the result.
Algorithm of Prototype No. 1 provides the share of the correct classification (Accuracy), equal to 0.8003 of the total number of requests, or 80%. Moreover, the value of a similar metric in a situation where it is assumed that the correct answer will be chosen by the person from the two presented by the solution reaches 0.901, or 90%. Certainly, there are cases where the developed solution works worse or cannot give the correct answer - as a rule, due to a very short set of words or specificity of the information in the request itself. The role is still played by the insufficiently large amount of data that was used in the learning process. According to preliminary estimates, an increase in the volume of processed information will make it possible to increase the classification accuracy by another 0.01-0.03 points.
The results of the best model in the metrics of accuracy (Precision) and completeness (Recall) are evaluated as follows:

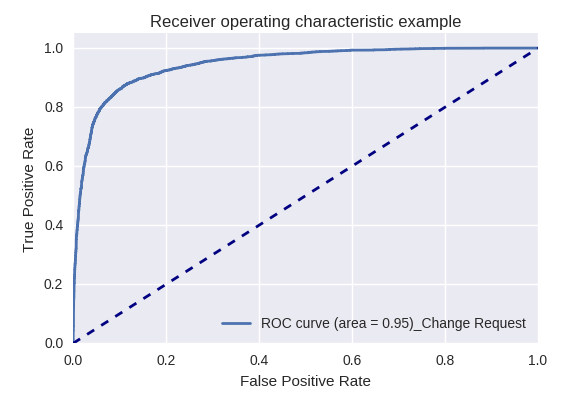
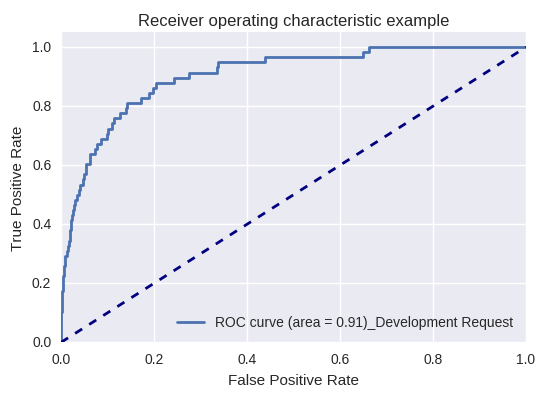
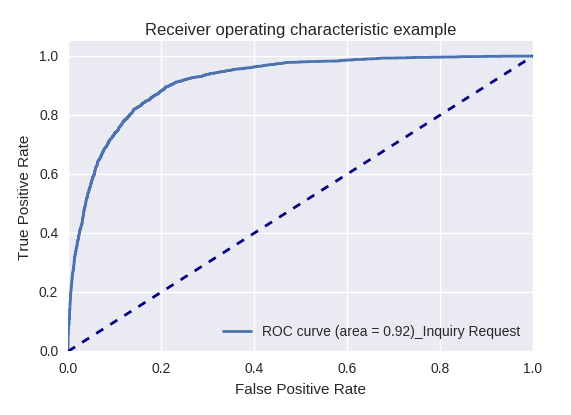
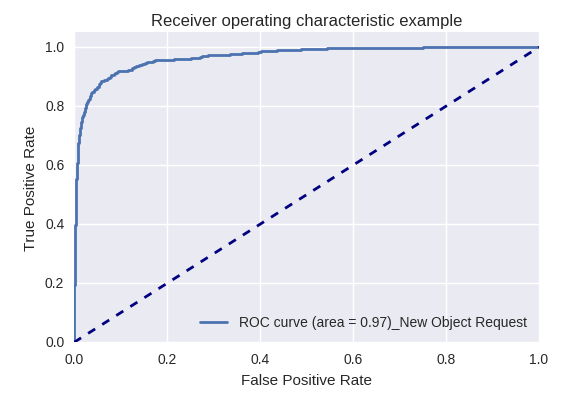
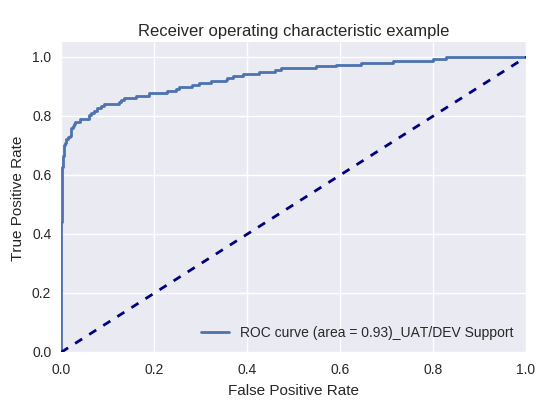
If you evaluate the quality of the model as a whole for various types of queries using ROC-AUC-curves, the results are as follows.
Requests for action (Action Request) and analysis of information (Analysis / Task Request)

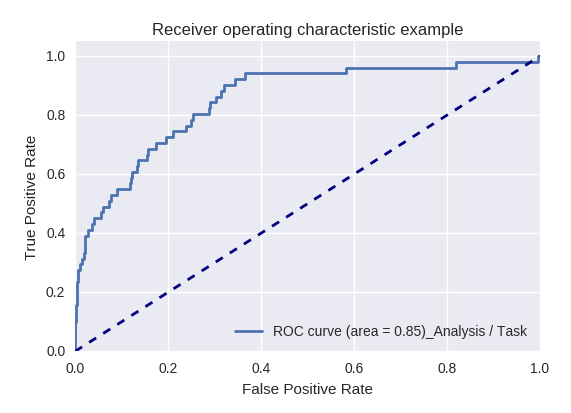
Requests for changes in business data (Business Data Request) and for changes (Change Request)
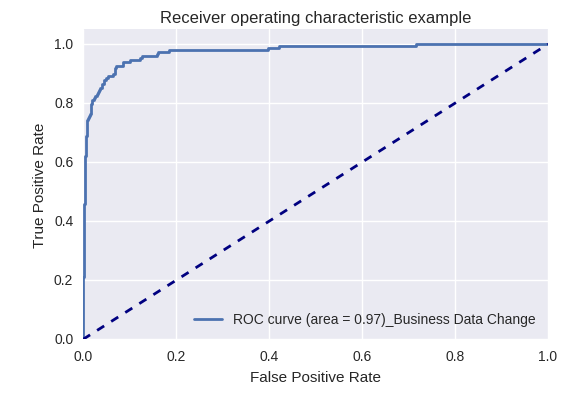
Requests for development (Development Request) and for the provision of information (Inquiry Request)
Requests to create a new object (New Object Request) and add a new user (New User Request)

Production request (Production Request) and a request related to UAT / DEV support (UAT / Dev Support Request)

Examples of correct and incorrect classification for some types of requests are given below:
Inquiry Request

Change Request
Correct classification
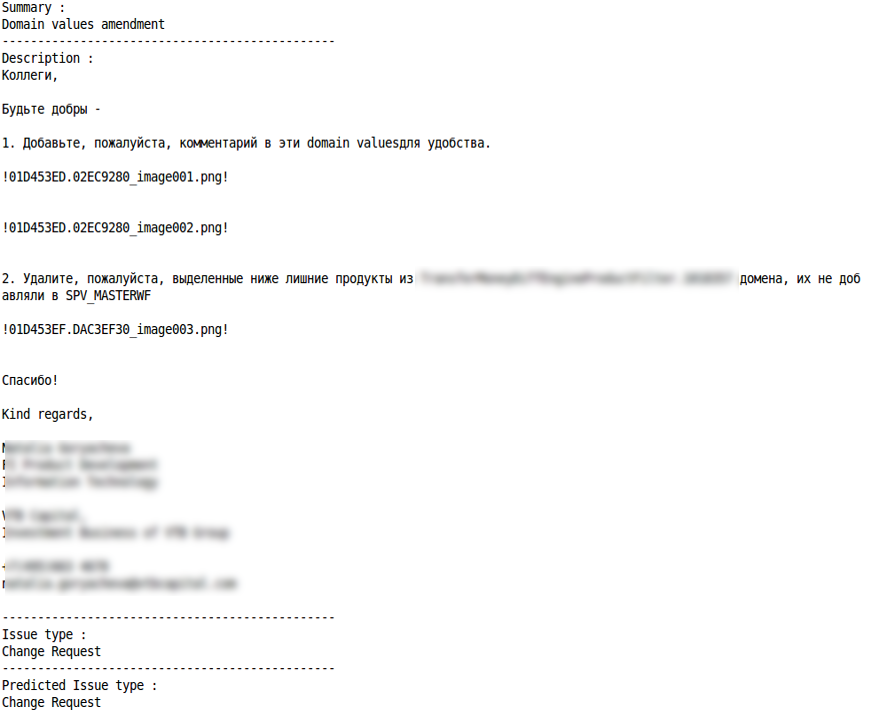
Misclassification

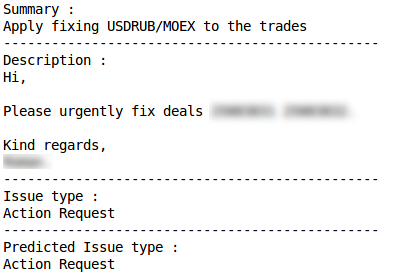
Action request
Correct classification
Misclassification
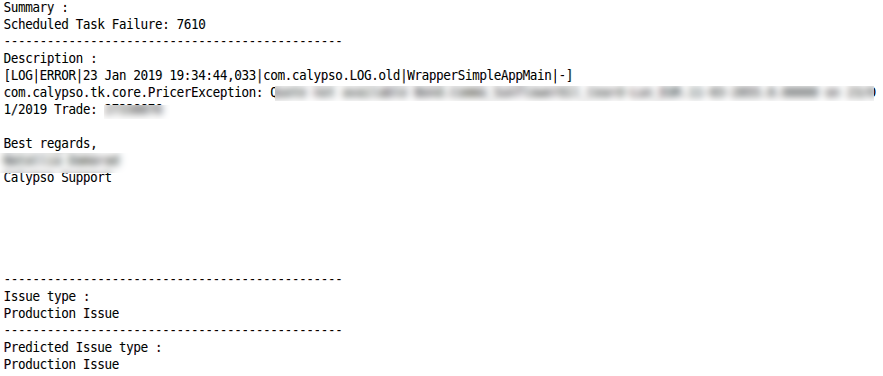
Production Issue
Correct Classification
Misclassification
Good The second prototype also showed the results: ML in approximately 75% of cases correctly determines the type of query (Accuracy metric). The opportunity to improve the indicator is associated with improving the quality of the source data, in particular, eliminating cases when the same queries were assigned to different types.
Each of the implemented prototypes has shown its effectiveness, and now a combination of two developed prototypes has been launched into pilot production at VTB Capital. A small experiment with ML in less than a month and at minimal cost allowed the company to get acquainted with machine learning tools and solve an important application problem for classifying user requests.
The experience gained by the developers of EPAM and VTB Capital - in addition to using implemented algorithms for processing user requests for further development - can be reused in solving a variety of tasks related to stream processing of information. The movement in small iterations and the coverage of one process after another allows you to gradually master and combine various tools and technologies, choosing well-proven options and abandoning less effective ones. This is interesting for the IT team and at the same time helps to obtain results that are important for management and business.
At a certain stage of development, we at VTB Capital were faced with an urgent need to reduce the time it takes to process requests for technical support. After analyzing the options, it was decided to use ML technology to categorize calls from business users of Calypso, the company's key investment platform. The fast processing of such requests is crucial for the high quality of the IT service. We asked our key partners, EPAM, to help solve this problem .
So, support requests are received by e-mail and transformed into tickets in Jira. Then, support specialists manually classify them, prioritize them, enter additional data (for example, from which department and location a request was received, which functional unit of the system it belongs to) and appoint performers. In total, about 10 categories of queries are used. This, for example, may be a request to analyze some data and provide the author of the request with information, add a new user, etc. Moreover, actions can be either standard or non-standard, so it is very important to immediately correctly determine the type of request and assign execution to the right specialist.
It is important to note: VTB Capital wanted not only to develop an applied technological solution, but also to evaluate the capabilities of various tools and technologies on the market. One task, two different approaches, two technology platforms and three and a half weeks: what was the result?
Prototype No. 1: technologies and models
The basis for the development of the prototype was the approach proposed by the EPAM team, and historical data - about 10,000 tickets from Jira. The main attention was focused on the 3 required fields that each such ticket contains: Issue Type (type of problem), Summary ("header" of the letter or subject of the request) and Description (description). Within the framework of the project, it was planned to solve the problem of analyzing the text from the Summary and Description fields and automatically determine the type of request based on its results.
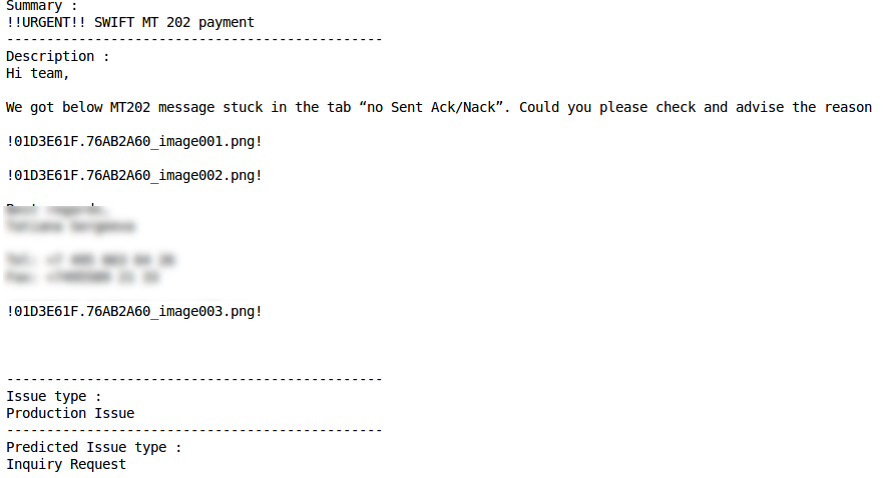
It is the features of the text in these two ticket fields that became the main technical difficulty in analyzing data and developing ML models. So, the Summary field can contain quite “clean” text, but including specific words and terms (for example, CWS reports not running).The Description field, on the contrary, is characterized by a more “dirty” text with an abundance of special characters, notations, backslashes and residues of non-text elements:
Dera colleagues,
Could you please explain to us what is the difference between FX_Opt_delta_all and FX_Opt_delta_cash risk measures?
! 01D39C59.62374C90_image001.png! )
In addition, the text often combines several languages (mainly, naturally, Russian and English), business terminology, ruglish and programmer slang can be found. And of course, since requests are often written in a hurry, in both cases typos and spelling errors are not ruled out.
The technologies chosen by the EPAM team included Python 3.5 for prototype development, NLTK + Gensim + Re for text processing, Pandas + Sklearn for data analysis and model development, and Keras + Tensorflow as a deep learning framework and backend.
Taking into account the possible features of the initial data, three representations were constructed for character extraction from the Summary field: at the level of characters, combinations of characters and individual words. Each of the representations was used as an entrance to a recurrent neural network.
In turn, the service character statistics (important for processing text using exclamation points, slashes, etc.) and the average values of the strings after filtering the service characters and garbage (for compact preservation of the text structure) were chosen as a representation for the Description field; , as well as word-level representation after filtering stop words. Each representation served as an entrance to a neural network: statistics in a fully connected, line-by-line and at the level of words - in a recursive one.
In this scheme, a neural network was used as a recurrent network, consisting of a bidirectional GRU layer with a recursive and normal dropout, a pool of hidden states of the recurrent network using the GlobalMaxPool1D layer and a fully connected (Dense) layer with a dropout. For each of the inputs, its own “head” of the neural network was built, and then they were combined through concatenation and locked to the target variable.
To obtain the final result, the combined neural network returned the probabilities of a particular request belonging to each type. The data were divided into five blocks without intersections: the model was built on four of them and checked on the fifth. Since each request can be assigned only one type of request, the rule for making a decision was simple - by the maximum probability value.
Prototype No. 2: algorithms and principles of work
The second prototype, for which the proposal prepared by the VTB Capital team was taken, is an application on Microsoft .NET Core with Microsoft.ML libraries for implementing machine learning algorithms and the Atlassian.Net SDK for interacting with Jira via the REST API. The basis for building ML-models also became historical data - 50,000 Jira-tickets. As in the first case, machine learning covered the fields Summary and Description. Before use, both fields were also “cleaned”. Greetings, signatures, correspondence history and non-textual elements (for example, images) were deleted from the user's letter. In addition, using the built-in functionality in Microsoft ML, stop words that were not important for processing and analyzing the text were cleared from English text.
Averaged Perceptron (binary classification) was chosen as a machine learning algorithm, which is supplemented by the One Versus All method to provide multiclass classification
Evaluation of the results
No ML model can (possibly, yet) provide 100% accuracy of the result.
Algorithm of Prototype No. 1 provides the share of the correct classification (Accuracy), equal to 0.8003 of the total number of requests, or 80%. Moreover, the value of a similar metric in a situation where it is assumed that the correct answer will be chosen by the person from the two presented by the solution reaches 0.901, or 90%. Certainly, there are cases where the developed solution works worse or cannot give the correct answer - as a rule, due to a very short set of words or specificity of the information in the request itself. The role is still played by the insufficiently large amount of data that was used in the learning process. According to preliminary estimates, an increase in the volume of processed information will make it possible to increase the classification accuracy by another 0.01-0.03 points.
The results of the best model in the metrics of accuracy (Precision) and completeness (Recall) are evaluated as follows:
If you evaluate the quality of the model as a whole for various types of queries using ROC-AUC-curves, the results are as follows.
Requests for action (Action Request) and analysis of information (Analysis / Task Request)
Requests for changes in business data (Business Data Request) and for changes (Change Request)
Requests for development (Development Request) and for the provision of information (Inquiry Request)
Requests to create a new object (New Object Request) and add a new user (New User Request)
Production request (Production Request) and a request related to UAT / DEV support (UAT / Dev Support Request)
Examples of correct and incorrect classification for some types of requests are given below:
Inquiry Request
Change Request
Correct classification
Misclassification
Action request
Correct classification
Misclassification
Production Issue
Correct Classification
Misclassification
Good The second prototype also showed the results: ML in approximately 75% of cases correctly determines the type of query (Accuracy metric). The opportunity to improve the indicator is associated with improving the quality of the source data, in particular, eliminating cases when the same queries were assigned to different types.
To summarize
Each of the implemented prototypes has shown its effectiveness, and now a combination of two developed prototypes has been launched into pilot production at VTB Capital. A small experiment with ML in less than a month and at minimal cost allowed the company to get acquainted with machine learning tools and solve an important application problem for classifying user requests.
The experience gained by the developers of EPAM and VTB Capital - in addition to using implemented algorithms for processing user requests for further development - can be reused in solving a variety of tasks related to stream processing of information. The movement in small iterations and the coverage of one process after another allows you to gradually master and combine various tools and technologies, choosing well-proven options and abandoning less effective ones. This is interesting for the IT team and at the same time helps to obtain results that are important for management and business.