How to stop forgetting about indexes and start checking execution plan in tests

Some time ago, an unpleasant story happened to me, which served as a trigger for a small project on the github and resulted in this article.
A typical day, a regular release: all tasks are checked up and down by our QA engineer, so with the calmness of the sacred cow, we roll onto the stage. The application behaves well, in the logs - silence. We decide to do switch (stage <-> prod). We switch, look at the instruments ... A
couple of minutes pass, the flight is stable. The QA engineer does a smoke test, notices that the application is somehow unnaturally slowing down. We write off to warm the caches.
A couple of minutes pass, the first complaint is from the first line: the data is downloaded from the clients for a very long time, the application slows down, it takes a long time to respond, etc. We start to worry ... we look at the logs, we look for possible reasons.
A couple of minutes later, a letter arrives from DB admins. They write that the execution time of queries to the database (hereinafter referred to as the database) has broken through all possible boundaries and tends to infinity.
I open monitoring (I use JavaMelody ), I find these requests. I start PGAdmin, I reproduce. Really long. I add “explain”, I look at the execution plan ... it is, we forgot about the indexes.
Why is code review not enough?
That incident taught me a lot. Yes, I “extinguished the fire” for an hour, creating the right index directly on the prod in something like this (do not forget about the CONCURRENTLY option):
CREATE INDEX CONCURRENTLY IF NOT EXISTS ix_pets_name
ON pets_table (name_column);Agree, this was tantamount to a deployment with downtime. For the application I'm working on, this is unacceptable.
I made conclusions and added a special bold point to the checklist for code review: if I see that during the development process one of the Repository classes was added / changed - I check sql migrations for the presence of a script that creates and changes the index there. If he is not there, I am writing to the author a question: is he sure that the index is not needed here?
It is likely that an index is not needed if there is little data, but if we work with a table in which the number of rows are counted in millions, an index error can become fatal and lead to the story set out at the beginning of the article.
In this case, I ask the author of the pull request (hereinafter PR) to be 100% sure that the query that he wrote in HQL is at least partially covered by the index (Index Scan is used). For this, the developer:
- launches the application
- looking for converted (HQL -> SQL) query in the logs
- opens PGAdmin or another database administration tool
- generates in the local database, so as not to interfere with their experiments, an amount of data acceptable for tests (minimum 10K - 20K records)
- fulfills the request
- requests execution plan
- carefully studies it and draws appropriate conclusions
- adds / modifies the index, ensuring that the execution plan suits it
- unsubscribes in PR that the coverage of the request checked
- expertly assessing the risks and severity of the request, I can double-check its actions
A lot of routine actions and the human factor, but for some time I was satisfied, and I lived with this.
On the way home
They say it’s very useful at least sometimes to go from work without listening to music / podcasts along the way. At this time, just thinking about life, you can come to interesting conclusions and ideas.
One day I walked home and thought about what happened that day. There was a few review, I checked each one with a checklist and did a series of actions described above. I got so tired that time, I thought, what the hell? Is it not possible to do this automatically? .. I took a quick step, wanting to quickly “gash” this idea.
Formulation of the problem
What is most important for the developer in the execution plan?
Of course, seq scan on large amounts of data caused by the lack of an index.
Thus, it was necessary to do a test that:
- Performed on a database with a configuration similar to the prod
- Intercepts a database query made by a JPA repository (Hibernate)
- Gets It Execution Plan
- Parsit Execution Plan, laying it out in a data structure convenient for checks
- Using a convenient set of Assert methods, checks expectations. For example, that seq scan is not used.
It was necessary to quickly test this hypothesis by making a prototype.
Solution Architecture
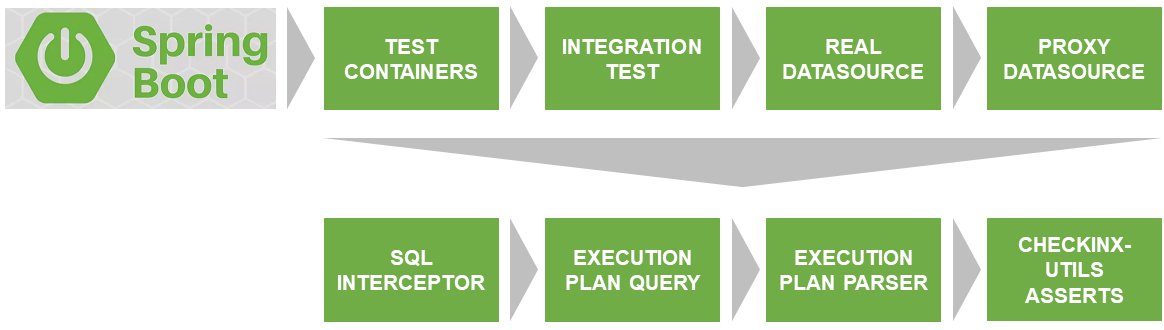
The first problem that was to be solved was the launch of the test on a real database that matches the version and settings with the one used on the prod.
Thanks to Docker & TestContainers , they solve this problem.
SqlInterceptor, ExecutionPlanQuery, ExecutionPlanParse, and AssertService are the interfaces that I have currently implemented for Postgres. The plans are to implement for other databases. If you want to participate - welcome. The code is written in Kotlin.
All this together I posted on GitHub and called checkinx-utils . You do not need to repeat this, just connect the dependency to checkinx in maven / gradle and use convenient asserts. How to do this, I will describe in more detail below.
Description of the interaction of CheckInx components
ProxyDataSource
The first problem that was to be solved was the interception of database queries ready for execution. Already with the established parameters, without questioning, etc.
To do this, you need to wrap the real dataSource in a certain Proxy, which would allow you to integrate into the query execution pipeline and, accordingly, intercept them.
Such ProxyDataSource has already been implemented by many. I used the ready-made ttddyy solution , which allows me to install my Listener intercepting the request I need.
I substitute the original DataSource using the DataSourceWrapper (BeanPostProcessor) class.
SqlInterceptor
In essence, its start () method sets its Listener to proxyDataSource and starts intercepting requests, storing them in the internal statements list. The stop () method, respectively, removes the installed Listener.
ExecutionPlanQuery
Here, the original request is transformed into a request for an execution plan. In the case of Postgres, this is an addition to the query keyword "EXPLAIN".
Further, this query is executed on the same database from testcontainders and a “raw” execution plan (list of lines) is returned.
ExecutionPlanParser
It is inconvenient to work with a “raw” execution plan. Therefore, I parse it into a tree consisting of nodes (PlanNode).
Let's analyze the PlanNode fields using an example of a real ExecutionPlan:
Index Scan using ix_pets_age on pets (cost=0.29..8.77 rows=1 width=36)
Index Cond: (age < 10)
Filter: ((name)::text = 'Jack'::text)| Property | Example | Description |
|---|---|---|
| raw: String | Index Scan using ix_pets_age on pets (cost = 0.29..8.77 rows = 1 width = 36) | source string |
| table: String? | pets | table name |
| target: String? | ix_pets_age | index name |
| coverage: String? | Index scan | coating |
| coverageLevel | Half | coating abstraction (ZERO, HALF, FULL) |
| children: MutableList | - | child nodes |
| properties: MutableList | key : Index Cond, value : (age <10); key : Filter, value : ((name) :: text = 'Jack' :: text) | properties |
| others: MutableList | - | All that could not be recognized in the current version of checkinx |
AssertService
It is already possible to work normally with the data structure returned by the parser. CheckInxAssertService is a set of checks of the PlanNode tree described above. It allows you to set your own lambdas of checks or use the predefined, in my opinion, the most popular ones. For example, so that your query does not have Seq Scan, or you want to make sure that a specific index is used / not used.
Coveragelevel
Very important Enum, I will describe it separately:
| Value | Description |
|---|---|
| NOT_USING | checks that a specific target (index) is not used |
| ZERO | index not used (Seq Scan) |
| Half | partial coverage of the query by index (Index Scan). For example, a search is performed by index, but for the resulting data it refers to a table |
| FULL | full coverage of the query by index (Index Only Scan) |
| UNKNOWN | unknown coverage. For some reason, it was not possible to install it. |
Next, we’ll review a few usage examples.
Test Examples Using CheckInx
I did a separate project on GitHub checkinx-demo , where I implemented a JPA repository for the pets table and tests for this repository checking coverage, indexes, etc. It will be useful to look there as a starting point.
You might have a test like this:
@Test
fun testFindByLocation() {
// ARRANGE
val location = "Moscow"
// Генерируем тестовые данные, их должно быть достаточно много 10К-20К.
// Лучше использовать TestNG и вынести этот код в @BeforeClass
IntRange(1, 10000).forEach {
val pet = Pet()
pet.id = UUID.randomUUID()
pet.age = it
pet.location = "Saint Petersburg"
pet.name = "Jack-$it"
repository.save(pet)
}
// ACT
// Начинаем перехват запросов
sqlInterceptor.startInterception()
// Тестируемый метод
val pets = repository.findByLocation(location)
// Заканчиваем перехват
sqlInterceptor.stopInterception()
// ASSERT
// Здесь можно проверить сколько запросов было исполнено
assertEquals(1, sqlInterceptor.statements.size.toLong())
// Убеждаемся, что используется индекс ix_pets_location с частичным покрытием (Index Scan)
checkInxAssertService.assertCoverage(CoverageLevel.HALF, "ix_pets_location", sqlInterceptor.statements[0])
// Если нам все равно какой индекс будет использоваться, но важно чтобы не было Seq Scan, мы можем проверить минимальный уровень покрытия
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])
// ... тоже самое, но используя свою лямбду
checkInxAssertService.assertPlan(plan) {
it.coverageLevel.level < CoverageLevel.FULL.level
}
}The implementation plan could be as follows:
Index Scan using ix_pets_location on pets pet0_ (cost=0.29..4.30 rows=1 width=46)
Index Cond: ((location)::text = 'Moscow'::text)... or like this if we forgot about the index (tests turn red):
Seq Scan on pets pet0_ (cost=0.00..19.00 rows=4 width=84)
Filter: ((location)::text = 'Moscow'::text)In my project, I mostly use the simplest assert, which says that there is no Seq Scan in the execution plan:
checkInxAssertService.assertCoverage(CoverageLevel.HALF, sqlInterceptor.statements[0])The presence of such a test suggests that I, at least, studied the implementation plan.
It also makes project management more explicit, and documentability and predictability of the code increases.
Experienced mode
I recommend using the CheckInxAssertService, but if necessary, you can bypass the parsed tree (ExecutionPlanParser) yourself or, in general, parse the raw execution plan (the result of executing ExecutionPlanQuery).
@Test
fun testFindByLocation() {
// ARRANGE
val location = "Moscow"
// ACT
// Начинаем перехват запросов
sqlInterceptor.startInterception()
// Тестируемый метод
val pets = repository.findByLocation(location)
// Заканчиваем перехват
sqlInterceptor.stopInterception()
// ASSERT
// Получаем "сырой" план выполнения
val executionPlan = executionPlanQuery.execute(sqlInterceptor.statements[0])
// Получаем распарсенный план - дерево
val plan = executionPlanParser.parse(executionPlan)
assertNotNull(plan)
// ... сами делаем обход
val rootNode = plan.rootPlanNode
assertEquals("Index Scan", rootNode.coverage)
assertEquals("ix_pets_location", rootNode.target)
assertEquals("pets pet0_", rootNode.table)
}Connection to the project
In my project, I allocated such tests to a separate group, calling it Intensive Integration Tests.
Connecting and starting using checkinx-utils is easy enough. Let's start with the build script.
Connect the repository first. Someday I will upload checkinx to maven, but now you can download artifact only from GitHub via jitpack.
repositories {
// ...
maven { url 'https://jitpack.io' }
}Next, add the dependency:
dependencies {
// ...
implementation 'com.github.tinkoffcreditsystems:checkinx-utils:0.2.0'
}We complete the connection by adding the configuration. Only Postgres is currently supported.
@Profile("test")
@ImportAutoConfiguration(classes = [PostgresConfig::class])
@Configuration
open class CheckInxConfigPay attention to the test profile. Otherwise, you will find ProxyDataSource in your prod.
PostgresConfig connects several beans:
- DataSourceWrapper
- PostgresInterceptor
- PostgresExecutionPlanParser
- PostgresExecutionPlanQuery
- CheckInxAssertServiceImpl
If you need some kind of customization that the current API does not provide, you can always replace one of the bean with your implementation.
Known Issues
Sometimes a DataSourceWrapper fails to replace the original dataSource due to the Spring CGLIB proxy. In this case, not a DataSource comes to BeanPostProcessor, but ScopedProxyFactoryBean and there are problems with type checking.
The easiest solution would be to manually create HikariDataSource for tests. Then your configuration will be as follows:
@Profile("test")
@ImportAutoConfiguration(classes = [PostgresConfig::class])
@Configuration
open class CheckInxConfig {
@Primary
@Bean
@ConfigurationProperties("spring.datasource")
open fun dataSource(): DataSource {
return DataSourceBuilder.create()
.type(HikariDataSource::class.java)
.build()
}
@Bean
@ConfigurationProperties("spring.datasource.configuration")
open fun dataSource(properties: DataSourceProperties): HikariDataSource {
return properties.initializeDataSourceBuilder()
.type(HikariDataSource::class.java)
.build()
}
}Development plans
- I would like to understand if anyone other than me needs this? To do this, create a survey. I will be glad to answer honestly.
- See what you really need and expand the standard list of assert methods.
- Write implementations for other databases.
- The construction of sqlInterceptor.statements [0] does not look very obvious, I want to improve it.
I would be glad if someone wants to join in and gain some credit by practicing in Kotlin.
Conclusion
I am sure that there will be comments: it is impossible to predict how the query planner will behave on the prod, it all depends on the statistics collected .
Indeed, a planner. Using the statistics collected earlier, it can build a plan different from the one being tested. The meaning is a little different.
The task of the planner is to improve, not worsen, the request. Therefore, for no apparent reason, he will not suddenly use Seq Scan, but you can unknowingly.
You need CheckInx so that when writing a test, do not forget to study the query execution plan and consider the possibility of creating an index, or vice versa, clearly show with a test that no indexes are needed here and you are satisfied with Seq Scan. This would save you unnecessary questions on the code review.
References
Only registered users can participate in the survey. Please come in.
Use of article material
- 8% I will use it now 5
- 53.2% Maybe someday I'll try 33
- 25.8% It was useful, but I will not use 16
- 12.9% Useless Material 8
- 0% Already checking execution plan in code with another tool 0