JavaScript engines: how do they work? From the call stack to the promises, (almost) everything you need to know
- Transfer

Have you ever wondered how browsers read and execute JavaScript code? It looks mysterious, but in this post you can get an idea of what is happening under the hood.
We begin our journey into the language with an excursion into the wonderful world of JavaScript engines.
Open the console in Chrome and go to the Sources tab. You will see several sections, and one of the most interesting is called Call Stack (in Firefox you will see Call Stack when you put a breakpoint in the code):

What is a call stack? There seems to be a lot going on here, even for the sake of executing a couple lines of code. In fact, JavaScript does not come in a box with every browser. There is a large component that compiles and interprets our JavaScript code - it is a JavaScript engine. The most popular are V8, it is used in Google Chrome and Node.js, SpiderMonkey in Firefox, JavaScriptCore in Safari / WebKit.
JavaScript engines today are great examples of software engineering, and it will be almost impossible to talk about all aspects. However, the main work on code execution is done for us by only a few components of the engines: Call Stack (call stack), Global Memory (global memory) and Execution Context (execution context). Ready to meet them?
Content:
- JavaScript engines and global memory
- JavaScript engines: how do they work? Global execution context and call stack
- JavaScript is single-threaded and other fun stories
- Asynchronous JavaScript, callback queue and event loop
- Callback hell and promises ES6
- Creating and working with JavaScript Promises
- Error Handling in ES6 Promises
- ES6 Promise combinators: Promise.all, Promise.allSettled, Promise.any and others
- ES6 promises and microtask queue
- JavaScript engines: how do they work? Asynchronous evolution: from promises to async / await
- JavaScript engines: how do they work? Summary
1. JavaScript engines and global memory
I said that JavaScript is both a compiled and interpreted language. Believe it or not, JavaScript engines actually compile your code microseconds before it is executed.
Some kind of magic, huh? This magic is called JIT (Just in time compilation). It alone is a big topic of discussion, even books will not be enough to describe the work of JIT. But for now, we will skip the theory and focus on the execution phase, which is no less interesting.
To get started, look at this code:
var num = 2;
function pow(num) {
return num * num;
}Suppose I ask you how this code is processed in a browser? What will you answer? You can say: “the browser reads the code” or “the browser executes the code”. In reality, everything is not so simple. First, the code is read not by the browser, but by the engine. The JavaScript engine reads the code , and as soon as it defines the first line, it puts a couple of links into global memory .
Global memory (also called heap) is the area in which the JavaScript engine stores variables and function declarations. And when he reads the code above, two binders will appear in the global memory:

Even if the example contains only a variable and a function, imagine that your JavaScript code is executed in a larger environment: in a browser or in Node.js. In such environments, there are many predefined functions and variables that are called global. Therefore, global memory will contain much more data than just
numand pow, keep in mind. Nothing is running at the moment. Let's now try to execute our function:
var num = 2;
function pow(num) {
return num * num;
}
pow(num);What will happen? And something interesting will happen. When calling the function, the JavaScript engine will highlight two sections:
- Global Execution Context
- Call stack
What are they?
2. JavaScript engines: how do they work? Global execution context and call stack
You learned how the JavaScript engine reads variables and function declarations. They fall into the global memory (heap).
But now we are executing a JavaScript function, and the engine should take care of this. How? Each JavaScript engine has a key component called the call stack .
This is a stacked data structure : elements can be added to it from above, but they cannot be excluded from the structure while there are other elements above them. This is how JavaScript functions work. At execution, they cannot leave the call stack if another function is present in it. Pay attention to this, as this concept helps to understand the statement "JavaScript is single-threaded."
But back to our example.When a function is called, the engine sends it to the call stack :

I like to present the call stack as a stack of Pringles chips. We cannot eat chips from the bottom of the stack until we eat those that are on top. Fortunately, our function is synchronous: it is just a multiplication that is quickly calculated.
At the same time, the engine places the global execution context in memory , this is the global environment in which JavaScript code is executed. Here's what it looks like:

Imagine a global execution context in the form of a sea in which global JavaScript functions float like fish. How cute! But this is only half the story. What if our function has nested variables or internal functions?
Even in the simple case, as shown below, the JavaScript engine creates a local execution context :
var num = 2;
function pow(num) {
var fixed = 89;
return num * num;
}
pow(num);Note that I added a
powvariable to the function fixed. In this case, the local execution context will contain a section for fixed. I'm not very good at drawing small rectangles inside other small little rectangles, so use your imagination. A
powlocal execution context will appear next to it , inside the green rectangle section located inside the global execution context. Imagine also how for each nested function inside the nested function, the engine creates other local execution contexts. All of these rectangle sections appear very quickly! Like a nesting doll! Let's get back to the single-threaded story. What does this mean?
3. JavaScript is single-threaded, and other fun stories
We say that JavaScript is single-threaded because only one call stack handles our functions . Let me remind you that functions cannot leave the call stack if other functions expect execution.
This is not a problem if we work with synchronous code. For example, the addition of two numbers is synchronous and is calculated in microseconds. What about network calls and other interactions with the outside world?
Fortunately, JavaScript engines are designed to work asynchronously by default . Even if they can execute only one function at a time, slower functions can be performed by an external entity - in our case, it is a browser. We will talk about this below.
At the same time, you know that when the browser loads some kind of JavaScript code, the engine reads this code line by line and performs the following steps:
- Puts variables and function declarations into the global memory (heap).
- Sends a call to each function on the call stack.
- Creates a global execution context in which global functions are executed.
- Creates many small local execution contexts (if there are internal variables or nested functions).
You now have a basic understanding of the synchronization mechanics that underlie all JavaScript engines. In the next chapter, we will talk about how asynchronous code works in JavaScript and why it works that way.
4. Asynchronous JavaScript, callback queue, and event loop
Thanks to global memory, execution context and call stack, synchronous JavaScript code is executed in our browsers. But we forgot something. What happens if you need to execute some kind of asynchronous function?
By asynchronous function, I mean every interaction with the outside world, which may take some time to complete. Calling the REST API or timer is asynchronous, because it can take seconds to execute them. Thanks to the elements available in the engine, we can process such functions without blocking the call stack and browser. Do not forget, the call stack can execute only one function at a time, and even one blocking function can literally stop the browser. Fortunately, JavaScript engines are smart, and with a little help from the browser, they can sort things out.
When we execute an asynchronous function, the browser takes it and performs it for us. Take a timer like this:
setTimeout(callback, 10000);
function callback(){
console.log('hello timer!');
}I’m sure that although you’ve
setTimeoutalready seen hundreds of times, you may not know that this function is not built into JavaScript . So, when JavaScript appeared, there was no function in it setTimeout. In fact, it is part of the so-called browser APIs, a collection of convenient tools that the browser provides us. Wonderful! But what does this mean in practice? Since it setTimeoutrefers to the browser API, this function is executed by the browser itself (for a moment it appears in the call stack, but is immediately deleted from there). After 10 seconds, the browser takes the callback function that we passed to it and puts it in the callback queue . At the moment, two more rectangle sections have appeared in the JavaScript engine. Take a look at this code:
var num = 2;
function pow(num) {
return num * num;
}
pow(num);
setTimeout(callback, 10000);
function callback(){
console.log('hello timer!');
}Now our scheme looks like this: it

setTimeoutis executed inside the browser context. After 10 seconds, the timer starts and the callback function is ready for execution. But first, it must go through the callback queue. This is a data structure in the form of a queue, and, as its name indicates, is an ordered queue of functions. Each asynchronous function must go through a callback queue before it gets on the call stack. But who sends the functions next? This makes a component called an event loop .
So far, the event loop deals with only one thing: it checks if the call stack is empty. If there is any function in the callback queue and if the call stack is free, then it's time to send a callback to the call stack.
After that, the function is considered executed. This is the general scheme for processing asynchronous and synchronous code with the JavaScript engine:
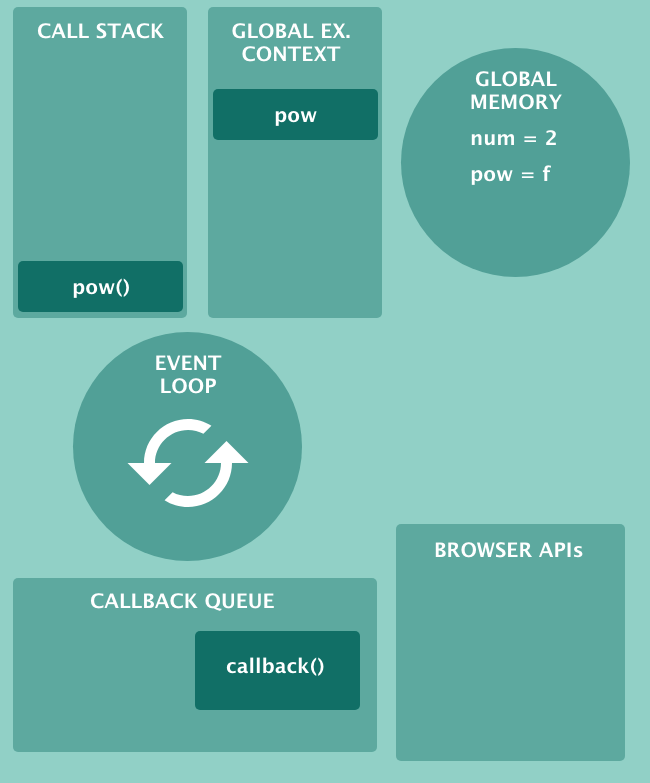
Let's say it
callback()is ready for execution. After execution is complete, pow()the call stack is freed and the event loop sends to itcallback() . And that’s it! Although I simplified things a bit, if you understand the above diagram, you can understand all JavaScript. Remember: browser-based APIs, callback queues, and event loops are the pillars of asynchronous JavaScript .
And if you're interested, you can watch the curious video “What the heck is the event loop anyway” by Philip Roberts. This is one of the best explanations for the event loop.
But we are not done with the asynchronous JavaScript theme yet. In the following chapters we will consider ES6 promises.
5. Callback hell and ES6 promises
Callback functions are used in JavaScript everywhere, both in synchronous and in asynchronous code. Consider this method:
function mapper(element){
return element * 2;
}
[1, 2, 3, 4, 5].map(mapper);
mapperIs a callback function that is passed inside map. The code above is synchronous. Now consider this interval:function runMeEvery(){
console.log('Ran!');
}
setInterval(runMeEvery, 5000);This code is asynchronous, because inside
setIntervalwe pass a callback runMeEvery. Callbacks are used throughout JavaScript, so for years we have had a problem called “callback hell” - “callback hell”. The term Callback hell in JavaScript is applied to the "style" of programming in which callbacks are embedded in other callbacks that are embedded in other callbacks ... Due to the asynchronous nature, JavaScript programmers have long fallen into this trap.
To be honest, I never created large pyramids of callbacks. Perhaps because I value readable code and always try to stick to its principles. If you hit the callback hell, it means that your function does too much.
I will not talk in detail about callback hell, if you are interested, then go to callbackhell.com , where this problem has been investigated in detail and various solutions have been proposed. And we'll talk about ES6 promises . This is a JavaScript addon designed to solve the hell callback problem. But what are promises?
A JavaScript promise is a representation of a future event . A promise may end successfully, or in a jargon of programmers, a promise will be “resolved” (resolved). But if the promise ends with an error, then we say that it is in the rejected state. Promises also have a default state: each new promise begins in a pending state. Can I create my own promise? Yes. We will talk about this in the next chapter.
6. Creating and working with JavaScript promises
To create a new promise, you need to call the constructor by passing a callback function to it. It can take only two parameters:
resolveand reject. Let's create a new promise that will be resolved in 5 seconds (you can test the examples in the browser console):const myPromise = new Promise(function(resolve){
setTimeout(function(){
resolve()
}, 5000)
});As you can see,
resolvethis is a function that we call so that the promise ends successfully. And it rejectwill create a rejected promise:const myPromise = new Promise(function(resolve, reject){
setTimeout(function(){
reject()
}, 5000)
});Please note that you can ignore
rejectit because it is the second parameter. But if you intend to use it reject, you cannot ignore itresolve . That is, the following code will not work and will end with an allowed promise:// Can't omit resolve !
const myPromise = new Promise(function(reject){
setTimeout(function(){
reject()
}, 5000)
});Promises don't look so useful right now, right? These examples do not display anything to the user. Let's add something. And permitted, rejected promises can return data. For instance:
const myPromise = new Promise(function(resolve) {
resolve([{ name: "Chris" }]);
});But we still don’t see anything. To extract data from a promise, you need to associate the promise with the method
then . He takes a callback (what an irony!), Which receives the current data:const myPromise = new Promise(function(resolve, reject) {
resolve([{ name: "Chris" }]);
});
myPromise.then(function(data) {
console.log(data);
});As a JavaScript developer and consumer of other people's code, you mostly interact with external promises. Library creators most often wrap legacy code in a Promise constructor, like this:
const shinyNewUtil = new Promise(function(resolve, reject) {
// do stuff and resolve
// or reject
});And if necessary, we can also create and resolve a promise by calling
Promise.resolve():Promise.resolve({ msg: 'Resolve!'})
.then(msg => console.log(msg));So, let me remind you: JavaScript promises are a bookmark for an event that will happen in the future. An event starts in the “waiting for a decision” state, and can be successful (allowed, executed) or unsuccessful (rejected). A promise can return data that can be retrieved by attaching to a promise
then. In the next chapter, we will discuss how to deal with errors coming from promises.7. Error Handling in ES6 Promises
Handling errors in JavaScript was always easy, at least in synchronous code. Take a look at an example:
function makeAnError() {
throw Error("Sorry mate!");
}
try {
makeAnError();
} catch (error) {
console.log("Catching the error! " + error);
}The result will be:
Catching the error! Error: Sorry mate!As expected, the error fell into the block
catch. Now try the asynchronous function:function makeAnError() {
throw Error("Sorry mate!");
}
try {
setTimeout(makeAnError, 5000);
} catch (error) {
console.log("Catching the error! " + error);
}This code is asynchronous because of
setTimeout. What will happen if we execute it? throw Error("Sorry mate!");
^
Error: Sorry mate!
at Timeout.makeAnError [as _onTimeout] (/home/valentino/Code/piccolo-javascript/async.js:2:9)Now the result is different. The error was not caught by the block
catch, but freely rose up the stack. The reason is that it try/catchonly works with synchronous code. If you want to know more, then this problem is discussed in detail here . Fortunately, with promises, we can handle asynchronous errors as if they were synchronous. In the last chapter, I said that the challenge
rejectleads to a rejection of the promise:const myPromise = new Promise(function(resolve, reject) {
reject('Errored, sorry!');
});In this case, we can handle errors using the handler
catchby pulling (again) a callback:const myPromise = new Promise(function(resolve, reject) {
reject('Errored, sorry!');
});
myPromise.catch(err => console.log(err));In addition, to create and reject a promise in the right place, you can call
Promise.reject():Promise.reject({msg: 'Rejected!'}).catch(err => console.log(err));Let me remind you: the handler
thenis executed when the promise is executed, and the handler catch is executed for rejected promises. But this is not the end of the story. Below we will see how async/awaitwonderful they work with try/catch.8. Combinators of ES6 promises: Promise.all, Promise.allSettled, Promise.any and others
Promises are not designed to work alone. The Promise API offers a number of methods for combining promises . One of the most useful is Promise.all , it takes an array from promises and returns one promise. The only problem is that Promise.all is rejected if at least one promise in the array is rejected.
Promise.race allows or rejects as soon as one of the promises in the array receives the corresponding status.
In more recent versions of V8, two new combinators will also be introduced:
Promise.allSettledand Promise.any. Promise.any is still at an early stage of the proposed functionality, at the time of writing this article is not supported. However, in theory, he will be able to signal whether any promise has been executed. UnlikePromise.racethat Promise.any is not rejected, even if one of the promises is rejected . Promise.allSettledeven more interesting. He also takes an array of promises, but does not “shorten” if one of the promises is rejected. It is useful when you need to check whether all promises in an array have passed to some stage, regardless of the presence of rejected promises. It can be considered the opposite Promise.all.9. ES6 Promises and the microtask queue
If you remember from the previous chapter, each asynchronous callback function in JavaScript is in the callback queue before it hits the call stack. But callback functions passed to Promise have a different fate: they are processed by the microtask queue, rather than the task queue.
And here you need to be careful: the microtask queue precedes the call queue . Callbacks from the microtask queue take precedence when the event loop checks to see if new callbacks are ready to go on the call stack.
This mechanics is described in more detail by Jake Archibald in Tasks, microtasks, queues and schedules , great reading.
10. JavaScript engines: how do they work? Asynchronous evolution: from promises to async / await
JavaScript is evolving rapidly and we are constantly getting improvements every year. PROMIS looked like the final, but with ECMAScript 2017 (ES8), a new syntax
async/await . async/await- just a stylistic improvement, which we call syntactic sugar. async/awaitIt doesn’t change JavaScript in any way (do not forget that the language should be backward compatible with older browsers and should not break existing code). This is just a new way to write asynchronous code based on promises. Consider an example. Above, we have already saved the promise in the corresponding then:const myPromise = new Promise(function(resolve, reject) {
resolve([{ name: "Chris" }]);
});
myPromise.then((data) => console.log(data))Now with the help
async/awaitwe can process the asynchronous code so that for the reader of our listing the code looks synchronous . Instead of applying it, thenwe can wrap the promise in a function marked as async, and then we will expect ( await) the result:const myPromise = new Promise(function(resolve, reject) {
resolve([{ name: "Chris" }]);
});
async function getData() {
const data = await myPromise;
console.log(data);
}
getData();Looks good, right? It's funny that an async function always returns a promise, and no one can stop it from doing this:
async function getData() {
const data = await myPromise;
return data;
}
getData().then(data => console.log(data));What about mistakes? One of the advantages
async/awaitis that this design can allow us to take advantage try/catch. Read the introduction to error handling in async functions and their testing . Let's take a look at the promise again, in which we handle errors with a handler
catch:const myPromise = new Promise(function(resolve, reject) {
reject('Errored, sorry!');
});
myPromise.catch(err => console.log(err));With asynchronous functions, we can refactor like this:
async function getData() {
try {
const data = await myPromise;
console.log(data);
// or return the data with return data
} catch (error) {
console.log(error);
}
}
getData();However, not everyone has switched to this style.
try/catchmay complicate your code. There is one more thing to consider. See how an error occurs inside this block in this code try:async function getData() {
try {
if (true) {
throw Error("Catch me if you can");
}
} catch (err) {
console.log(err.message);
}
}
getData()
.then(() => console.log("I will run no matter what!"))
.catch(() => console.log("Catching err"));What about the two lines that are displayed in the console? Remember that it
try/catchis a synchronous construct, and our asynchronous function generates a promise . They follow two different paths, like trains. But they will never meet! Therefore, the error that it raised thrownever activates the handler catchin getData(). Execution of this code will lead to the fact that first appears the inscription "Catch me if you can", and then "I will run no matter what!". In the real world, we don’t need a
throwhandler to run then. This can be solved by, say, returning Promise.reject()from a function:async function getData() {
try {
if (true) {
return Promise.reject("Catch me if you can");
}
} catch (err) {
console.log(err.message);
}
}
Now the error will be handled as expected:
getData()
.then(() => console.log("I will NOT run no matter what!"))
.catch(() => console.log("Catching err"));
"Catching err" // outputOther than that,
async/awaitit looks like the best way to structure asynchronous code in JavaScript. We better handle error handling and the code looks cleaner. In any case, I do not recommend refactoring all your JS code to
async/await. Discuss this with the team. But if you work independently, then the choice between pure promises async/awaitis only a matter of taste.11. JavaScript engines: how do they work? Summary
JavaScript is a scripting language for the web, it is first compiled and then interpreted by the engine. The most popular JS engines: V8, used by Google Chrome and Node.js; SpiderMonkey, developed for Firefox; JavaScriptCore used in Safari.
JavaScript engines have many “moving” parts: call stack, global memory, event loop, callback queue. All these parts work perfectly together, providing synchronous and asynchronous code processing.
JavaScript engines are single-threaded, that is, a single call stack is used to execute functions. This limitation underlies the asynchronous nature of JavaScript: all operations that take some time to complete must be controlled by an external entity (such as a browser) or a callback function.
To simplify the work of asynchronous code, promises were introduced in ECMAScript 2015. A promise is an asynchronous object used to represent the success or failure of any asynchronous operation. But the improvements did not stop there. In 2017, they appeared
async/await: a stylistic improvement for promises, which allows you to write asynchronous code as if it were synchronous.