Analysis of virtual machine performance in VMware vSphere. Part 1: CPU
- Tutorial

If you administer a virtual infrastructure based on VMware vSphere (or any other technology stack), you probably often hear complaints from users: "The virtual machine is slow!". In this series of articles I will analyze performance metrics and explain what and why it “slows down” and how to make sure that it does not “slow down”.
I will consider the following performance aspects of virtual machines:
- CPU
- RAM
- DISK,
- Network
I'll start with the CPU.
For performance analysis we need:
- vCenter Performance Counters are performance counters whose graphs can be viewed through vSphere Client. Information on these counters is available in any client version (“thick” client in C #, web client on Flex and web client on HTML5). In these articles, we will use screenshots from the C # client, only because they look better in miniature :)
- ESXTOP is a utility that runs from the ESXi command line. With its help, you can get the values of performance counters in real time or upload these values for a certain period to a .csv file for further analysis. Next, I’ll tell you more about this tool and provide some useful links to documentation and related articles.
Bit of theory
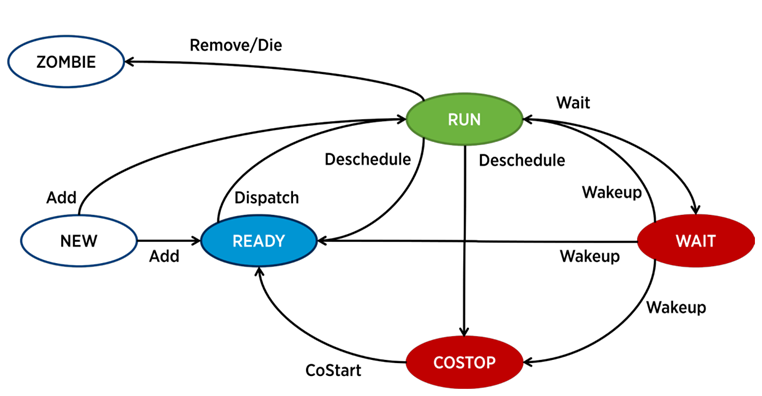
In ESXi, a separate process is responsible for the operation of each vCPU (virtual machine core) - the world in VMware terminology. There are also service processes, but from the point of view of VM performance analysis, they are less interesting.
A process in ESXi can be in one of four states:
- Run - the process does some useful work.
- Wait - the process does not do any work (idle) or is waiting for input / output.
- Costop- A condition that occurs in multi-core virtual machines. It occurs when the hypervisor CPU scheduler (ESXi CPU Scheduler) cannot schedule all active cores of the virtual machine to run simultaneously on the physical server cores. In the physical world, all processor cores work in parallel, the guest OS inside the VM expects similar behavior, so the hypervisor has to slow down the VM cores, which have the ability to finish the beat faster. In modern versions of ESXi, the CPU scheduler uses a mechanism called relaxed co-scheduling: the hypervisor considers the gap between the “fastest” and “slowest” virtual machine core (skew). If the gap exceeds a certain threshold, the “fast” core goes into costop state If VM cores spend a lot of time in this state,
- Ready - the process goes into this state when the hypervisor does not have the ability to allocate resources for its execution. High ready values can cause VM performance problems.
Basic CPU performance counters of a virtual machine
CPU Usage,%. Shows the percentage of CPU usage for a given period.
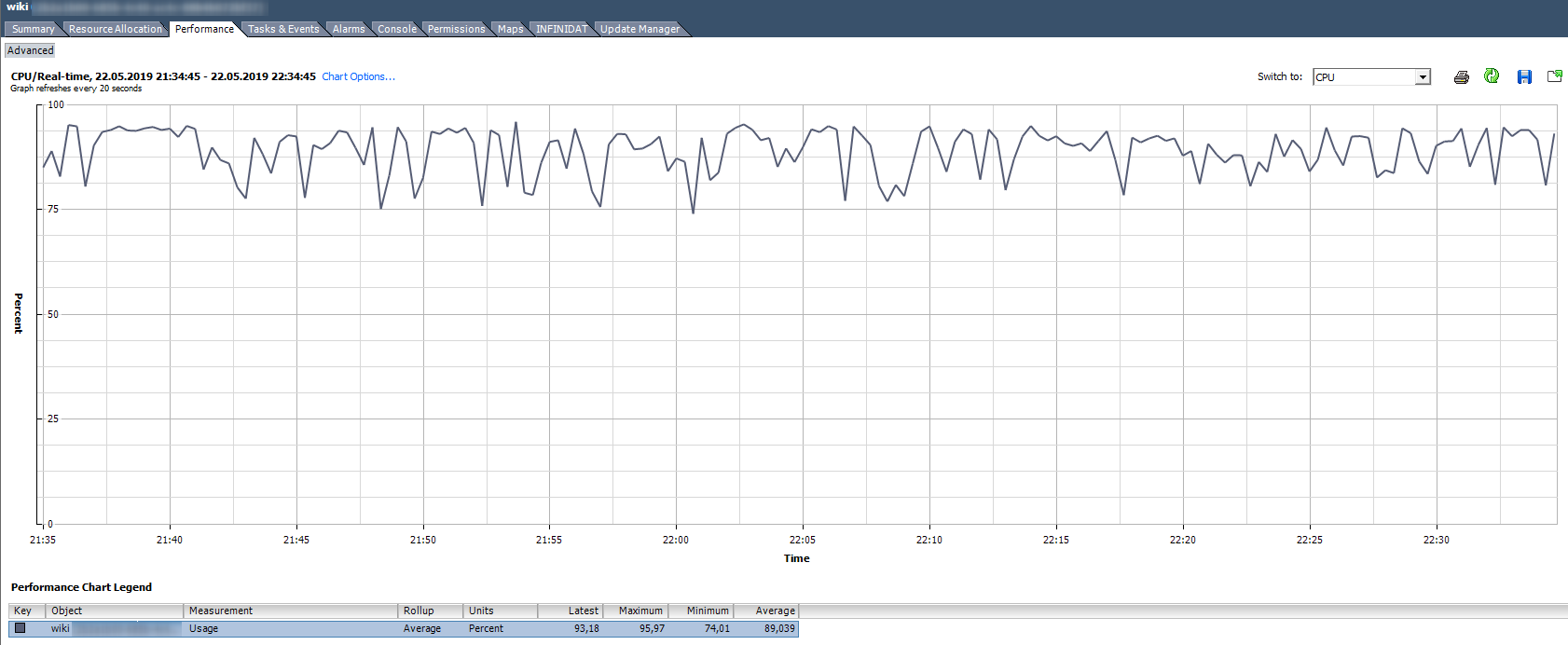
How to analyze? If the VM stably uses the CPU for 90% or there are peaks up to 100%, then we have problems. Problems can be expressed not only in the “slow” operation of the application inside the VM, but also in the inaccessibility of the VM over the network. If the monitoring system shows that the VM periodically falls off, pay attention to the peaks in the CPU Usage graph.
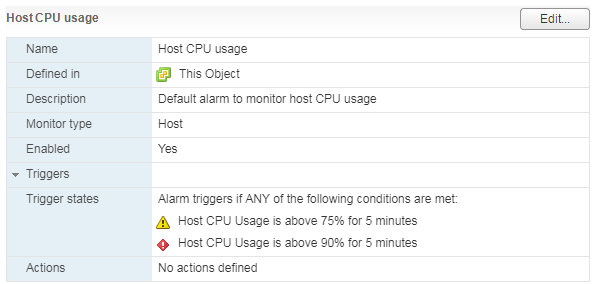
There is a standard Alarm that shows the CPU load of a virtual machine:
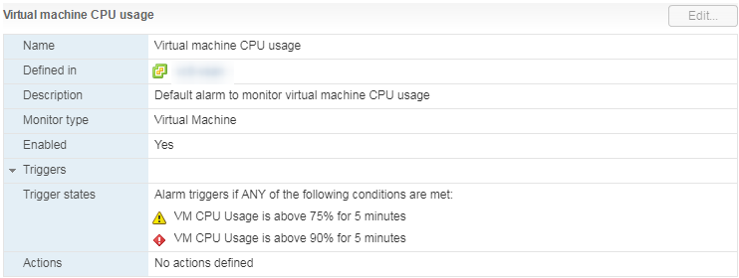
What should I do? If the CPU Usage is constantly overwhelming the VM, then you can think about increasing the number of vCPUs (unfortunately, this does not always help) or transferring the VMs to a server with more efficient processors.
CPU Usage in Mhz
In vCenter Usage graphs in% you can only see the entire virtual machine, there are no graphs for individual cores (Esxtop has values in% for cores). For each core, you can see Usage in MHz.
How to analyze? It happens that the application is not optimized for multi-core architecture: it uses 100% only one core, and the rest are idle without load. For example, with default backup settings, MS SQL starts the process on only one core. As a result, the backup is slowed down not because of the slow disk speed (this is what the user initially complained about), but because the processor cannot cope. The problem was solved by changing the parameters: the backup began to run in parallel in several files (respectively, in several processes).
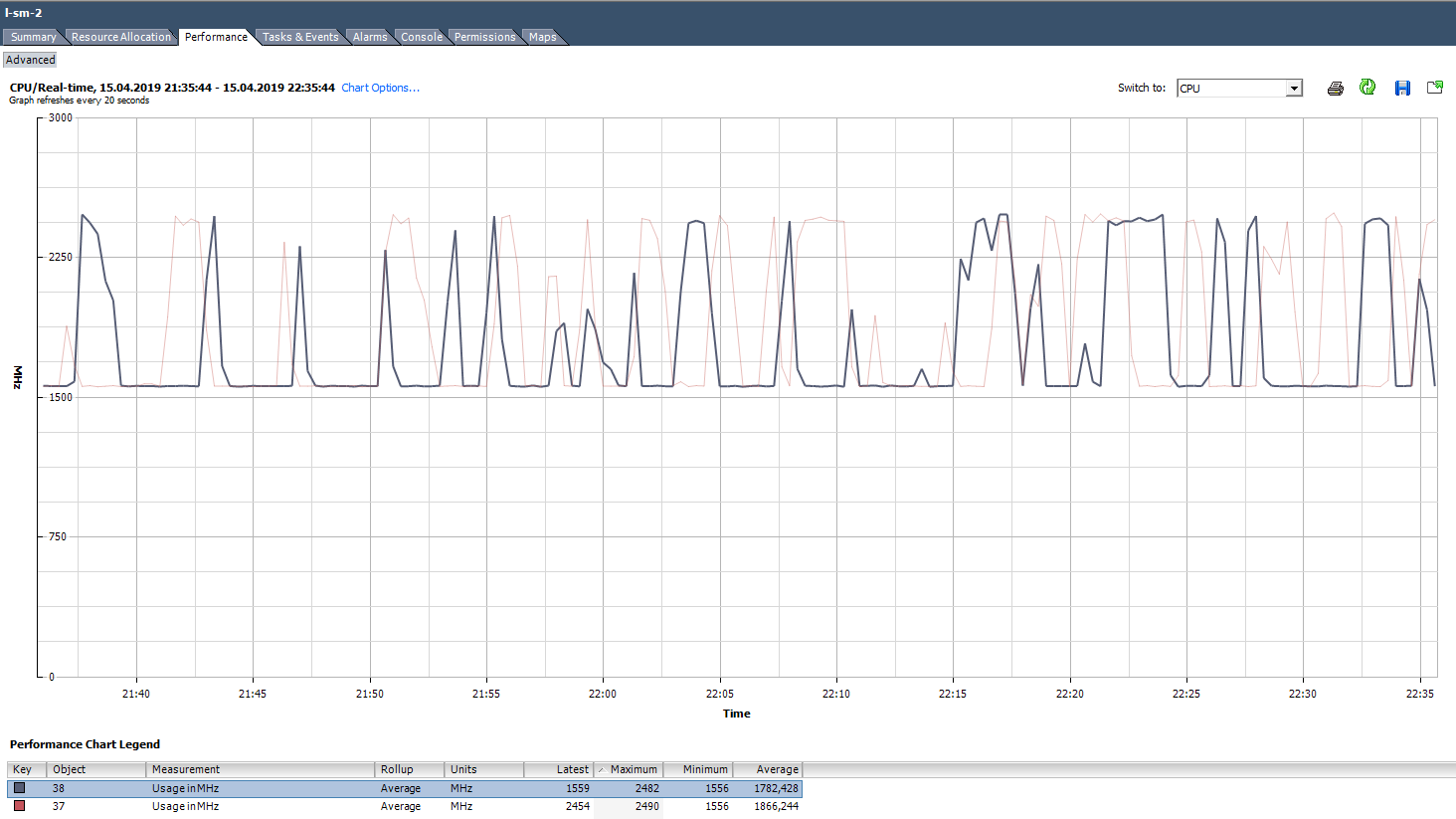
An example of an uneven load of nuclei.
There is also a situation (as in the graph above) when the cores are unevenly loaded and some of them have peaks of 100%. As with loading only one core, alarm on CPU Usage will not work (it is on the whole VM), but there will be performance problems.
What to do? If the software in the virtual machine loads the kernels unevenly (uses only one core or part of the kernels), there is no point in increasing their number. In this case, it is better to move the VM to a server with more efficient processors.
You can also try checking the power settings in the server BIOS. Many administrators turn on High Performance mode in the BIOS and thereby turn off the power-saving technologies of C-states and P-states. Modern Intel processors use Turbo Boost technology, which increases the frequency of individual processor cores due to other cores. But it works only with the included energy-saving technologies. If we turn them off, then the processor cannot reduce the power consumption of kernels that are not loaded.
VMware recommends not to turn off energy-saving technologies on servers, but to choose modes that maximize energy management for the hypervisor. At the same time, in the power settings of the hypervisor you need to select High Performance.
If you have separate VMs (or VM cores) in your infrastructure that require an increased CPU frequency, the correct configuration of power consumption can significantly improve their performance.
CPU Ready (Readiness)
If the VM core (vCPU) is in Ready state, it does not do useful work. This condition occurs when the hypervisor does not find a free physical core to which the vCPU process of the virtual machine can be assigned.
How to analyze? Typically, if the virtual machine cores are in Ready state for more than 10% of the time, then you will notice performance problems. Simply put, more than 10% of the time a VM waits for the availability of physical resources.
In vCenter, you can see 2 counters associated with the CPU Ready:
- Readiness
- Ready.
The values of both counters can be viewed both over the entire VM and for individual kernels.
Readiness shows the value immediately in percent, but only in Real-time (data for the last hour, measurement interval 20 seconds). This counter is best used only to search for problems "in hot pursuit."
Ready counter values can also be viewed in historical perspective. This is useful for establishing patterns and for a deeper analysis of the problem. For example, if a virtual machine starts having performance problems at a certain time, you can compare the intervals of the hung CPU Ready value with the total load on the server where this VM works, and take measures to reduce the load (if DRS could not cope).
Ready, unlike Readiness, is shown not in percentages, but in milliseconds. This is a Summation type counter, that is, it shows how long the VM core was in Ready state during the measurement period. You can translate this value into percent by a simple formula:
(CPU ready summation value / (chart default update interval in seconds * 1000)) * 100 = CPU ready%
For example, for VMs in the graph below, the Ready peak value for the entire virtual machine will be as follows:

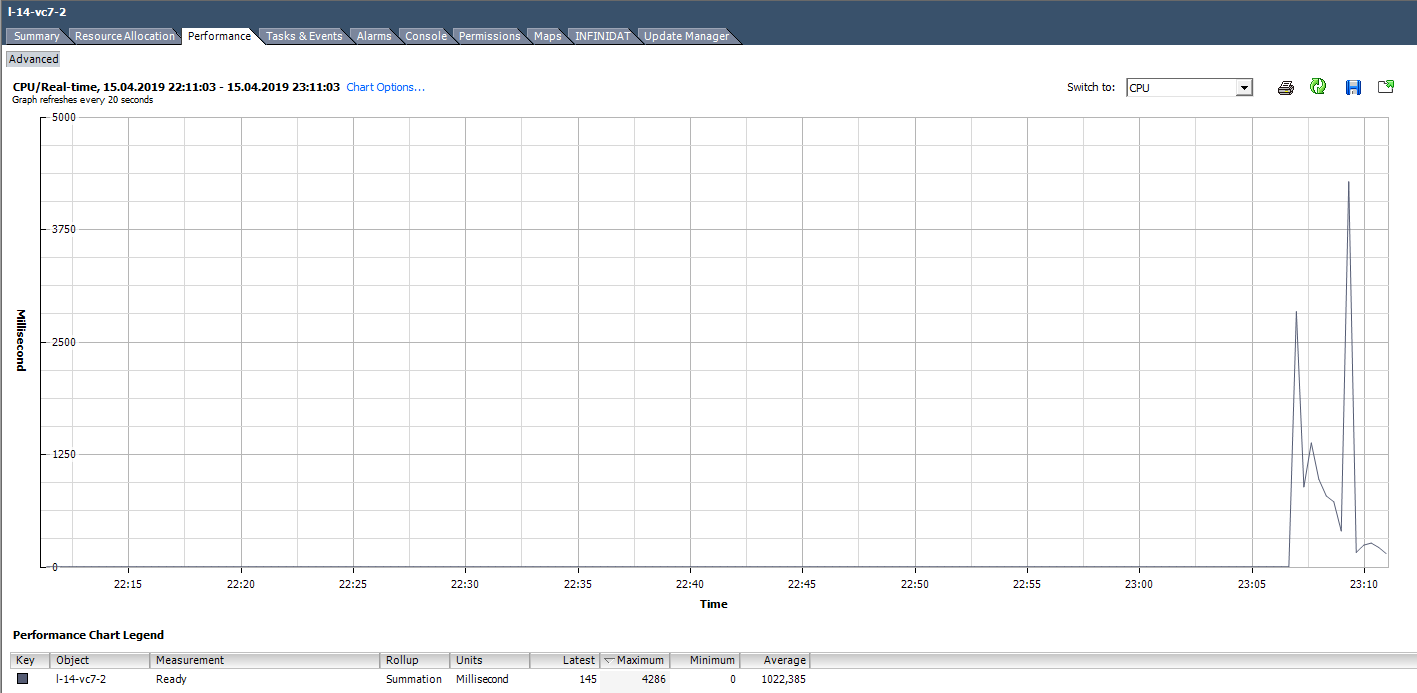
When calculating the Ready value as a percentage, you should pay attention to two points:
- The value of Ready across the entire VM is the sum of Ready across the cores.
- Measurement interval. For Real-time, this is 20 seconds, and, for example, on daily charts, it is 300 seconds.
With active troubleshooting, these simple points can be easily missed and valuable time can be spent on solving non-existent problems.
We calculate Ready based on the data from the graph below. (324474 / (20 * 1000)) * 100 = 1622% for the entire VM. If you look at the cores, it will turn out not so scary: 1622/64 = 25% per core. In this case, detecting a trick is quite simple: the Ready value is unrealistic. But if we are talking about 10–20% for the entire VM with several cores, then for each core the value can be within the normal range.
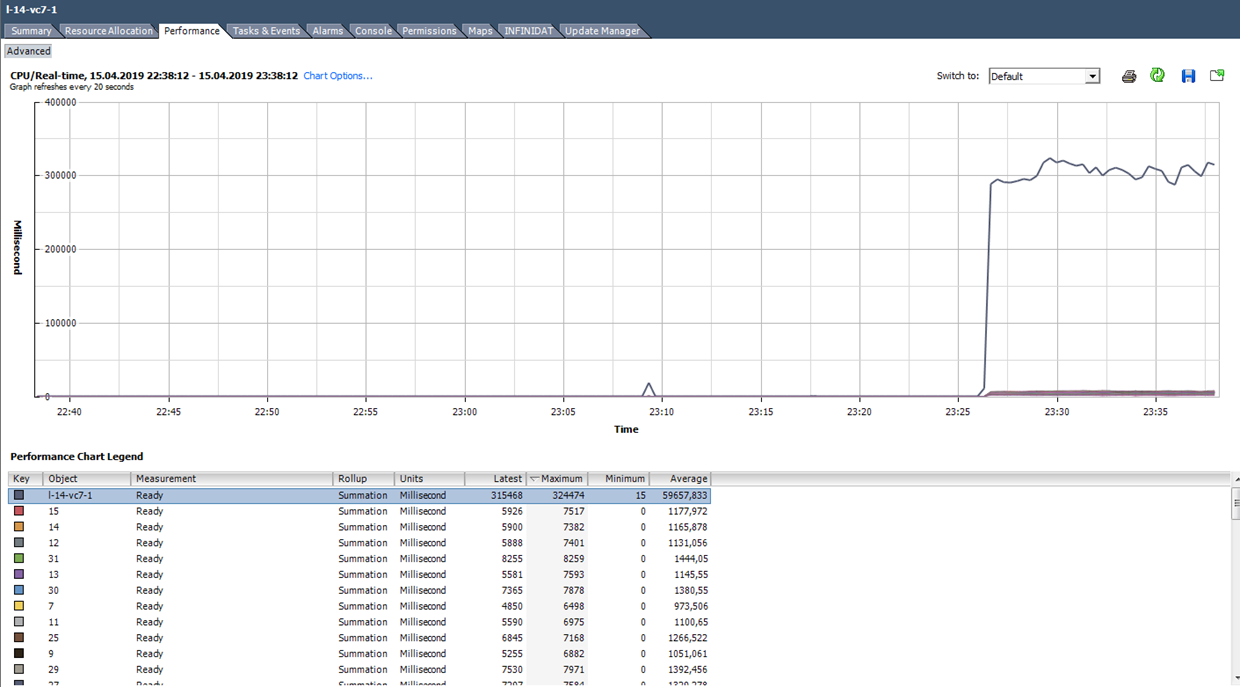
What to do?A high value of Ready indicates that the server does not have enough processor resources for the normal operation of virtual machines. In this situation, it remains only to reduce the oversubscription on the processor (vCPU: pCPU). Obviously, this can be achieved by reducing the parameters of existing VMs or by migrating part of the VM to other servers.
Co-stop
How to analyze? This counter also has the Summation type and translates into percentages like Ready:
(CPU co-stop summation value / (chart default update interval in seconds * 1000)) * 100 = CPU co-stop%
Here you also need to pay attention to the number of cores per VM and on the measurement interval.
In the costop state, the kernel does not do useful work. With the correct selection of the VM size and normal load on the server, the co-stop counter should be close to zero.

In this case, the load is clearly abnormal :)
What should I do? If several VMs with a large number of cores are running on the same hypervisor and there is oversubscription on the CPU, then the co-stop counter can grow, which will lead to problems with the performance of these VMs.
Also, co-stop will increase if threads are used for active kernels of one VM on the same physical server core with hyper-treading enabled. Such a situation may arise, for example, if the VM has more cores than it physically has on the server where it works, or if the “preferHT” setting is enabled for the VM. You can read about this setting here .
To avoid problems with VM performance due to high co-stop, select the VM size in accordance with the recommendations of the software manufacturer that runs on this VM, and with the capabilities of the physical server where the VM is running.
Do not add kernels in reserve, this can cause performance problems not only of the VM itself, but also of its server neighbors.
Other Useful CPU Metrics
Run - how much time (ms) for the vCPU measurement period was in the RUN state, that is, actually performed useful work.
Idle - how much time (ms) for the vCPU measurement period was inactive. High Idle values are not a problem, just vCPU had "nothing to do."
Wait - how much time (ms) for the vCPU measurement period was in the Wait state. Since IDLE is included in this counter, high Wait values also do not indicate a problem. But if at high Wait IDLE is low, then the VM was waiting for the I / O operations to complete, and this, in turn, may indicate a problem with the performance of the hard disk or some virtual VM devices.
Max limited- how much time (ms) for the vCPU measurement period was in Ready state due to the set resource limit. If the performance is inexplicably low, it is useful to check the value of this counter and the CPU limit in the VM settings. VMs may indeed have limits that you are not aware of. For example, this happens when the VM was sloped from the template on which the CPU limit was set.
Swap wait - how long the vCPU waited for operation with VMkernel Swap during the measurement period. If the values of this counter are above zero, then the VM definitely has performance problems. We'll talk more about SWAP in the article about RAM counters.
ESXTOP
If performance counters in vCenter are good for analyzing historical data, then on-line analysis of the problem is best done in ESXTOP. Here, all values are presented in finished form (no need to translate anything), and the minimum measurement period is 2 seconds.
The ESXTOP screen for the CPU is called up with the “c” key and looks like this:

For convenience, you can leave only virtual machine processes by pressing Shift-V.
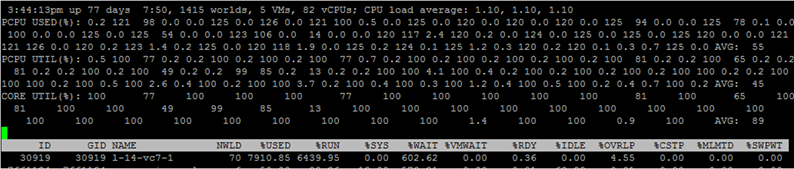
To view the metrics for individual VM cores, press “e” and type in the GID of the VM you are interested in (30919 in the screenshot below):

Briefly go through the columns that are presented by default. Additional columns can be added by pressing “f”.
NWLD (Number of Worlds)- the number of processes in the group. To expand the group and see the metrics for each process (for example, for each core of a multi-core VM), press “e”. If a group has more than one process, then the values of the metrics for the group are equal to the sum of the metrics for the individual processes.
% USED - how many cycles the CPU of the server uses a process or group of processes.
% RUN - how much time during the measurement period the process was in the RUN state, i.e. performed useful work. It differs from% USED in that it does not take into account hyper-threading, frequency scaling and time spent on system tasks (% SYS).
% SYS - time spent on system tasks, for example: handling interrupts, input / output, network operation, etc. The value can be high if there is a lot of input / output on the VM.
% OVRLP- how much time the physical core on which the VM process is running has spent on the tasks of other processes.
These metrics relate to each other as follows:
% USED =% RUN +% SYS -% OVRLP.
Usually the% USED metric is more informative.
% WAIT - how much time during the measurement period the process was in the Wait state. Includes IDLE.
% IDLE - how long the process was in IDLE state during the measurement period.
% SWPWT - how long did vCPU wait for operation with VMkernel Swap during the measurement period.
% VMWAIT- how much time for the vCPU measurement period was in the waiting state of the event (usually I / O). There is no similar counter in vCenter. High values indicate problems with input / output to the VM.
% WAIT =% VMWAIT +% IDLE +% SWPWT.
If the VM does not use VMkernel Swap, then when analyzing performance problems it is advisable to look at% VMWAIT, since this metric does not take into account the time when the VM did nothing (% IDLE).
% RDY - how long the process was in Ready state during the measurement period.
% CSTP - how long the process was in the post state during the measurement period.
% MLMTD - how much time during the vCPU measurement period was in Ready state due to the set resource limit.
% WAIT +% RDY +% CSTP +% RUN = 100% - the VM core is always in one of these four states.
CPU on the hypervisor
There are also CPU performance counters for the hypervisor in vCenter, but they do not represent anything interesting - it's just the sum of the counters for all VMs on the server.
It is most convenient to look at the state of the CPU on the server on the Summary tab:

For the server, as well as for the virtual machine, there is a standard Alarm:
With a high load on the server’s CPU , VMs running on it begin to experience performance problems.
In ESXTOP, server CPU utilization data is presented at the top of the screen. In addition to the standard CPU load, which is uninformative for hypervisors, there are three more metrics:
CORE UTIL (%) - loading the core of the physical server. This counter shows how much time the kernel performed the work during the measurement period.
PCPU UTIL (%)- if hyper-threading is enabled, then for each physical core there are two threads (PCPU). This metric shows how much time each thread did the work.
PCPU USED (%) is the same as PCPU UTIL (%), but it takes into account frequency scaling (either reducing the core frequency for energy saving or increasing the core frequency due to Turbo Boost technology) and hyper-threading.
PCPU_USED% = PCPU_UTIL% * effective core frequency / nominal core frequency.
In this screenshot, for some cores, due to Turbo Boost's operation, the USED value is more than 100%, since the core frequency is higher than the nominal.
A few words about how hyper-threading is taken into account. If the processes run 100% of the time on both threads of the physical core of the server, while the core runs at the nominal frequency, then:
- CORE UTIL for the kernel will be 100%,
- PCPU UTIL for both threads will be 100%,
- PCED USED for both threads will be 50%.
If both threads did not work 100% of the time during the measurement period, then in those periods when the threads worked in parallel, the USED PCPU for cores is divided in half.
ESXTOP also has a screen with the power consumption parameters of the CPU server. Here you can see if the server uses energy-saving technologies: C-states and P-states. Called by the p key:

Common CPU Performance Issues
In the end, I’ll run for typical reasons of problems with the performance of the VM CPU and give short tips for solving them:
There is not enough core clock frequency. If there is no way to transfer VMs to more efficient kernels, you can try changing the energy settings to make Turbo Boost work more efficiently.
Wrong sizing of the VM (too many / few cores). If you put few cores, there will be a high load on the VM CPU. If a lot, catch a high co-stop.
Large oversubscription on the CPU on the server. If the VM is high Ready, reduce the oversubscription on the CPU.
Wrong NUMA topology on large VMs.The NUMA topology that the VM sees (vNUMA) must match the NUMA server topology (pNUMA). About diagnostics and possible solutions to this problem is written, for example, in the book "VMware vSphere 6.5 Host Resources Deep Dive" . If you do not want to go deeper and you do not have licensing restrictions on the OS installed on the VM, do a lot of virtual sockets on the VM on one core. You won’t lose much :)
That's all for the CPU. Ask questions. In the next part I will talk about RAM.
useful links
http://virtual-red-dot.info/vm-cpu-counters-vsphere/
https://kb.vmware.com/kb/1017926
http://www.yellow-bricks.com/2012/07/17 / why-is-wait-so-high /
https://communities.vmware.com/docs/DOC-9279
https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/ performance / whats-new-vsphere65-perf.pdf
https://pages.rubrik.com/host-resources-deep-dive_request.html
https://kb.vmware.com/kb/1017926
http://www.yellow-bricks.com/2012/07/17 / why-is-wait-so-high /
https://communities.vmware.com/docs/DOC-9279
https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/techpaper/ performance / whats-new-vsphere65-perf.pdf
https://pages.rubrik.com/host-resources-deep-dive_request.html