Codeception tests for PHP backends
Hello! My name is Pasha and I am a QA engineer for the Order Processing team at Lamoda. I recently spoke at PHP Badoo Meetup. Today I want to provide a transcript of my report.
We will talk about Codeception, about how we use it in Lamoda and how to write tests on it.
Lamoda has many services. There are client services that interact directly with our users, with users of the site, mobile application. We will not talk about them. And there is what our company calls deep backends - these are our back-office systems that automate our business processes. These include delivery, storage, automation of photo studios and a call center. Most of these services are developed in PHP.
Speaking briefly about our stack, this is PHP + Symfony. Here and there are old projects on Zend'e. PostgreSQL and MySQL are used as databases, and Rabbit or Kafka are used as messaging systems.
Why PHP backends?
Because they usually have a branchy API - it's either REST, in some places there is a little bit of SOAP. If they have a UI, then this UI is more of an auxiliary one, which our internal users use.
Why do we need autotests at Lamoda?
In general, when I came to work at Lamoda, there was such a slogan: “Let's get rid of manual regression”. We will not manually test anything regression. And we worked on this task. Actually, this is one of the main reasons why we need autotests - so as not to drive regression by hand. Why do we need this? Right to release quickly. So that we can painlessly, very quickly roll out our releases and at the same time have some kind of grid from self-tests that they will tell us, good or bad. These are probably the most important goals. But there are a couple of auxiliary, about which I also want to say.
Why do we need autotests?
Ok, talked about why we need autotests. Now let's talk about what tests we write in Lamoda.
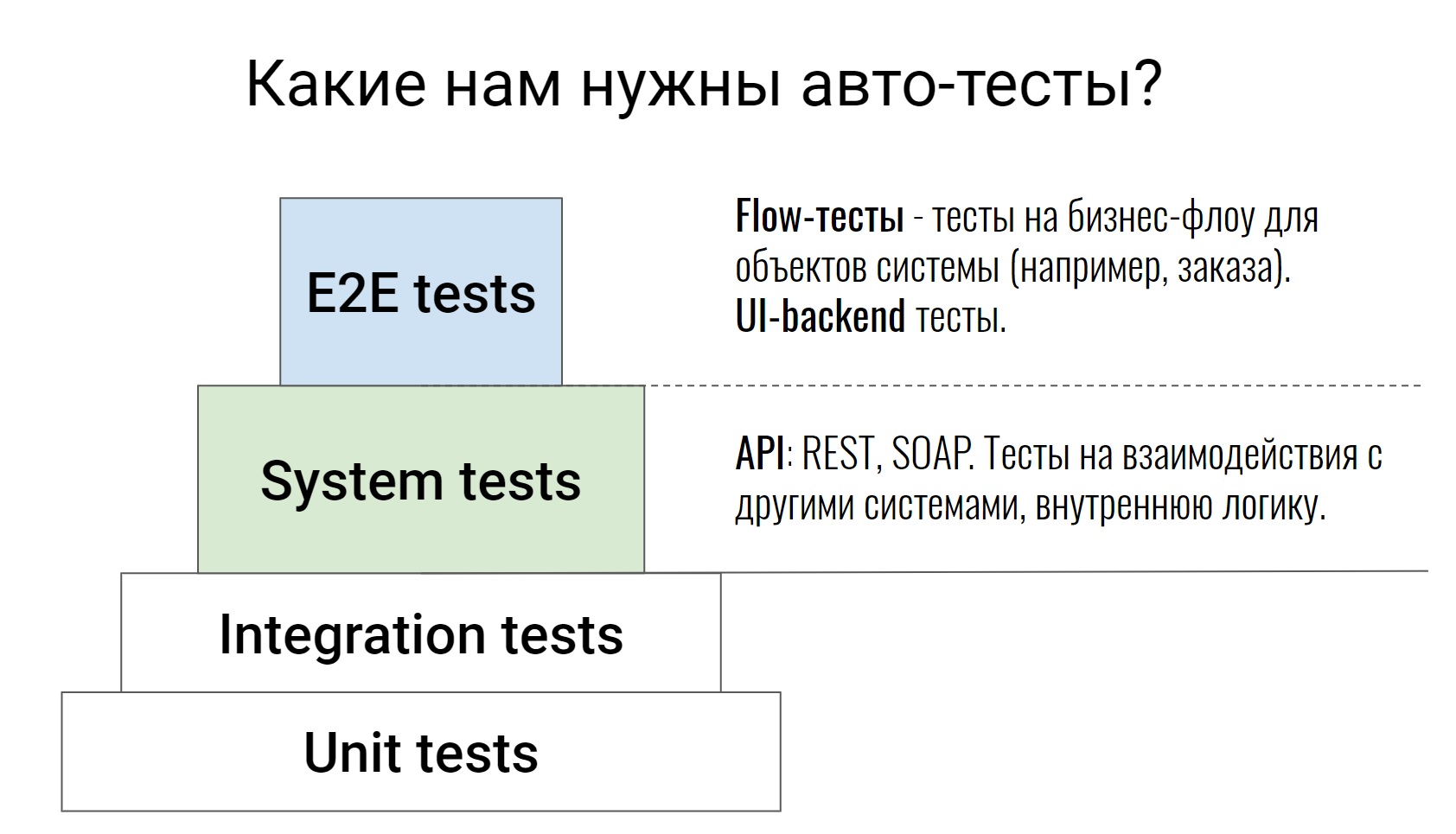
This is a fairly standard testing pyramid, from unit tests to E2E tests, where some business chains are already tested. I won’t talk about the lower two levels; it is not for nothing that they are painted over in such white color. These are tests on the code itself, they are written by our developers. In extreme cases, the tester can go into the Pull Request, look at the code and say: “Well, something is not enough cases here, let's cover something else.” This completes the work of the tester for these tests.
We will talk about the levels above, which are written by developers and testers. Let's start with system tests. These are tests that test the API (REST or SOAP), test some internal system logic, various commands, parse queues in Rabbit, or exchange with external systems. As a rule, these tests are quite atomic. They do not check any chain, but check one action. For example, one API method or one command. And they check as many cases as possible, both positive and negative.
Go ahead, E2E tests. I divided them into 2 parts. We have tests that test a bunch of UI and backend. And there are tests that we call flow tests. They test the chain - the life of an object from beginning to end.
For example, we have a system for managing the processing of our orders. Inside such a system there can be a test - an order from creation to delivery, that is, passing it through all statuses. It is on such tests that it is then very easy and simple to watch how the system works. You immediately see the entire flow of certain objects, with what external systems all this interacts, what commands are used for this.
Since we have this UI used by internal users, cross-browser access is not important to us. We do not drive these tests on any farms, it is enough for us to check in one browser, and sometimes we do not even need to use a browser.
“Why did we choose Codeception for test automation?” - you probably ask.
To be honest, I have no answer to this question. When I came to Lamoda, Codeception was already selected as the standard for writing autotests, and I came across it in fact. But after working with this framework for some time, I still understood why Codeception. This is what I want to share with you.
Why codeception?
I’ll briefly say what Codeception is like, since many worked with it.

Codeception works on an actor model. After you drag it into the project and initialize, such a structure is generated.
We have yml files, here below - functional.suite.yml , integration.suit.yml , unit.suite.yml . They create the configuration of your tests. There are daddies for each type of test, where these tests are, there are 3 auxiliary daddies:
_ data - for test data;
_ output - where reports are placed (xml, html);
_ support- where some auxiliary helpers, functions and everything that you write are put to use in your tests.
To begin with, I’ll tell you what we took from Codeception and use it out of the box, not modifying anything, not solving additional tasks or problems.
Standard modules
The first such module is PhpBrowser. This module is a wrapper over Guzzle that allows you to interact with your application: open pages, fill out forms, submit forms. And if you do not care about cross-browser and browser testing, if you are suddenly testing the UI, you can use PhpBrowser. As a rule, we use it in our UI tests, because we don’t need any complicated interaction logic, we just need to open the page and do something small there.
The second module we use is REST. I think the name makes it clear what he's doing. For any http interactions, you can use this module. It seems to me that almost all interactions are solved in it: headers, cookies, authorization. Everything you need is in it.
The third module that we use out of the box is the Db module. In recent versions of Codeception, support for not one, but several databases has been added there. Therefore, if you suddenly have several databases in your project, now it works out of the box.
The Cli module, which allows you to run shell and bash commands from tests, and we use it too.
There is an AMQP module that works with any message brokers that are based on this protocol. I want to note that it is officially tested on RabbitMQ. Since we use RabbitMQ, everything is okay with him.
In fact, Codeception, at least in our case, covers 80-85% of all the tasks we need. But I still had to work on something.
Let's start with SOAP.

In our services, in some places there are SOAP endpoints. They need to be tested, pulled, something to do with them. But you will say that in Codeception there is such a module that allows you to send requests and then do something with the answers. Somehow to parse, add checks and everything is OK. But the SOAP module does not work out of the box with multiple SOAP endpoints.

For example, we have monoliths that have several WSDLs, several SOAP endpoints. This means that it is impossible in the Codeception module to configure this in a yml file so that it can work with several.

Codeception has a dynamic module reconfiguration, and you can write some kind of your adapter to receive, for example, a SOAP module and dynamically reconfigure it. In this case, it is necessary to replace the endpoint and the scheme used. Then in the test, if you need to change the endpoint to which you want to send a request, we get our adapter and change it to a new endpoint, to a new circuit and send a request to it.

In Codeception, there is no work with Kafka and there are no third-party more or less official add-ons to work with Kafka. There is nothing to worry about, we wrote our module.

So it is configured in a yml file. Some settings are set for brokers, for consumers and for topics. These settings, when you write your module, you can then pull it into modules with the initialize function and initialize this module with the same settings. And, in fact, the module has all the other methods to implement - put the message in the topic and read it. That is all you need from this module.

Conclusion : modules for Codeception are easy to write.
Move on. As I said, Codeception has a Cli module - a wrapper for shell commands and working with their output.

But sometimes the shell-the team needs to be run not in tests, but in the application. In general, tests and applications are slightly different entities, they can lie in different places. Tests can be run in one place, and the application may be in another.
So why do we need to run shell in tests?
We have commands in applications that, for example, parse queues in RabbitMQ and move objects by status. These commands in pro-mode are launched from under the supervisor. The supervisor monitors their implementation. If they fall, then he starts them again and so on.
When we test, the supervisor is not running. Otherwise, the tests become unstable, unpredictable. We ourselves want to control the launch of these commands inside the application. Therefore, we need to run these commands from the tests in the application. We use two options. That one, that the other - in principle, everything is the same, and everything works.
How to run a shell in an application?
First: run the tests in the same place where the application is located. Since all the applications we have in Docker, tests can be run in the same container where the service itself is located.
The second option: make a separate container for tests, some test runner , but make it the same as the application. That is, from the same Docker image, and then everything will work similarly.

Another problem that we encountered in the tests is working with various file systems. Below is an example of what you can and should work with. The first three are relevant for us. These are Webdav, SFTP, and the Amazon file system.
What do you need to work with?
If you rummage through Codeception, you can find some modules for almost any more or less popular file system.
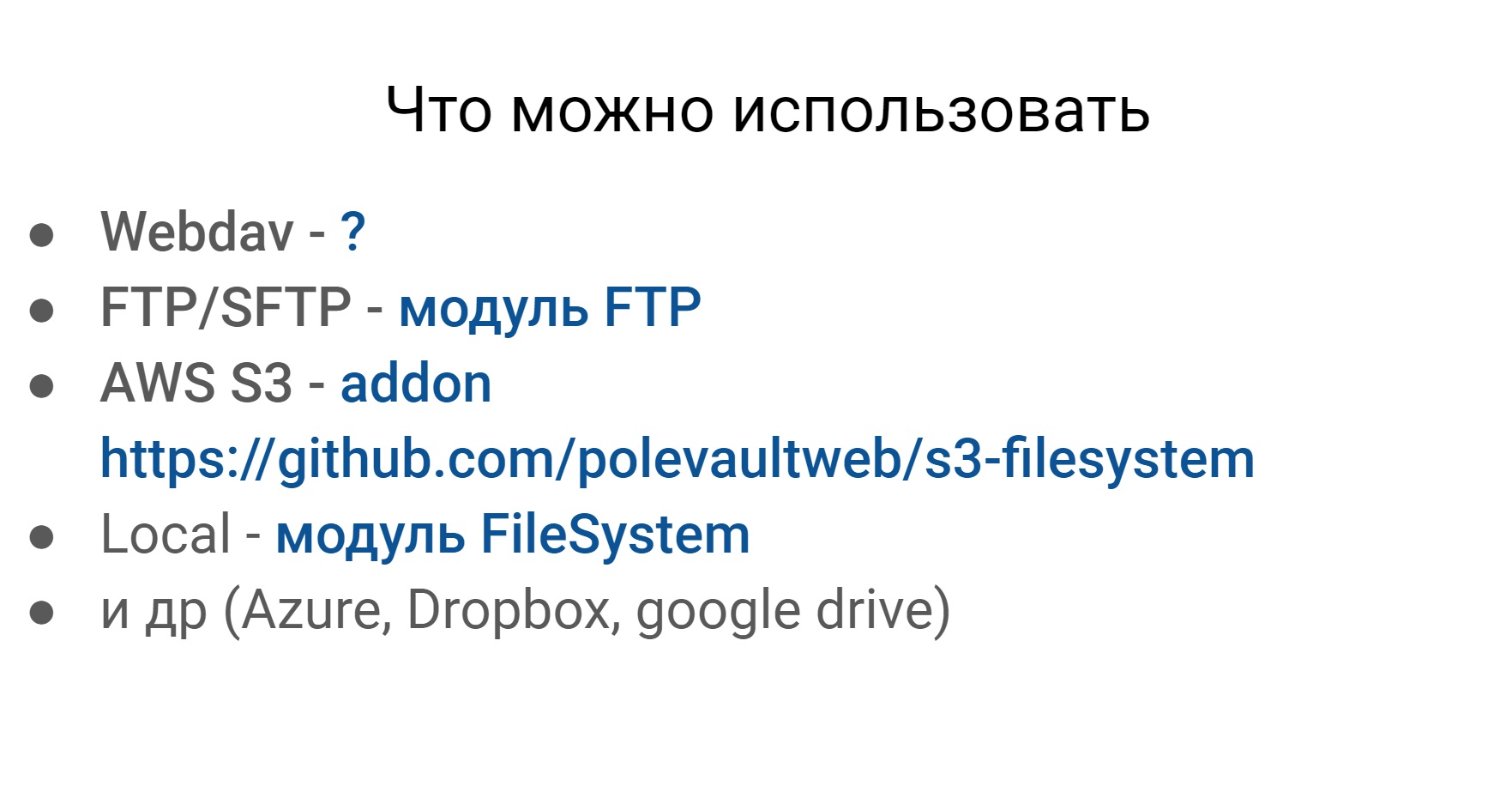
The only thing I did not find is for Webdav. But these file systems, plus or minus, are the same in terms of external work with them, and we want to work with them the same way.
We wrote our module called Flysystem. It lies on Github in the public domain and supports 2 file systems - SFTP and Webdav - and allows you to work with both using the same API.

Get a list of files, clean the directory, write a file, and so on. If you also add the Amazon file system there, our needs will definitely be covered.
The next point, I think, is very important for autotests, especially the system level, is working with databases. In general, I want it to be, as in the picture, - VZHUH and everything starts up, it works, and these databases should be less supported in tests.

What are the main tasks that I see here:
For all 3 tasks in Codeception, there are 2 modules - Db, which I already talked about, another is called Fixtures.
Of these 2 modules and 3 tasks, we use only DB for the third task.
For the first task, you can use DB. There you can configure the SQL dump from which the database will be deployed, well, the module with fixtures, I think it’s clear why it is needed.
There will be fixtures in the form of arrays that can be persisted into the database.
As I said, the first 2 tasks we solve a little differently, now I will tell you how we do it.
Database deployment
The first is about deploying a database. How does this happen in tests. We raise the container with the desired database - either PostgreSQL or MySQL, then roll all the necessary migrations using doctrine migrations . Everything, the database of the desired structure is ready, it can be used in tests.
Why we don’t use damps - because then it does not need to be supported. This is some kind of dump that lies with the tests, which needs to be constantly updated if something changes in the database. There are migrations - no need to maintain a dump.
The second point is the creation of test data. We do not use the Fixtures module from Codeception, we use the Symfony bundle for fixtures.

There is a link hereon it and an example of how you can create fixtures in the database.
Your fixture will then be created as some object of the domain, it can be stored in the database, and the test data will be ready.
Why DoctrineFixtureBundle?
Why do we use it? Yes, for the same reason - these fixtures are much easier to maintain than fixtures from Codeception. It's easier to create chains of related objects, because it's all in the symfony bundle. Less data need to be duplicated, because fixtures can be inherited, these are classes. If the database structure changes, these arrays always need to be edited, and classes not always. Fixtures in the form of domain objects are always more visible than arrays.
We talked about databases, let's talk a little about moki.
Since these are tests of a sufficiently high level that test the entire system and since our systems are highly interconnected, it is clear that there are some exchanges and interactions. Now we will talk about mokeys on the interaction between systems.
Rules for mok
Interactions are some REST or SOAP http interactions. All these interactions within the framework of the tests we are wetting. That is, in our tests there is no real appeal to external systems anywhere. This makes the tests stable. Because an external service may work, may not work, may respond slowly, may quickly, in general, do not know what its behavior is. Therefore, we cover it all with moks.
We also have such a rule. We are wetting not only positive interactions, but also trying to check some negative cases. For example, when a third-party service responds with a 500th error or produces some more meaningful error, we try to check it all.
We use Wiremock for mocks, Codeception itself supports ..., it has such an official add-on Httpmock, but we liked Wiremock more. How does it work?
Wiremock rises as a separate Docker container during tests, and all requests that must go to the external system go to Wiremock.
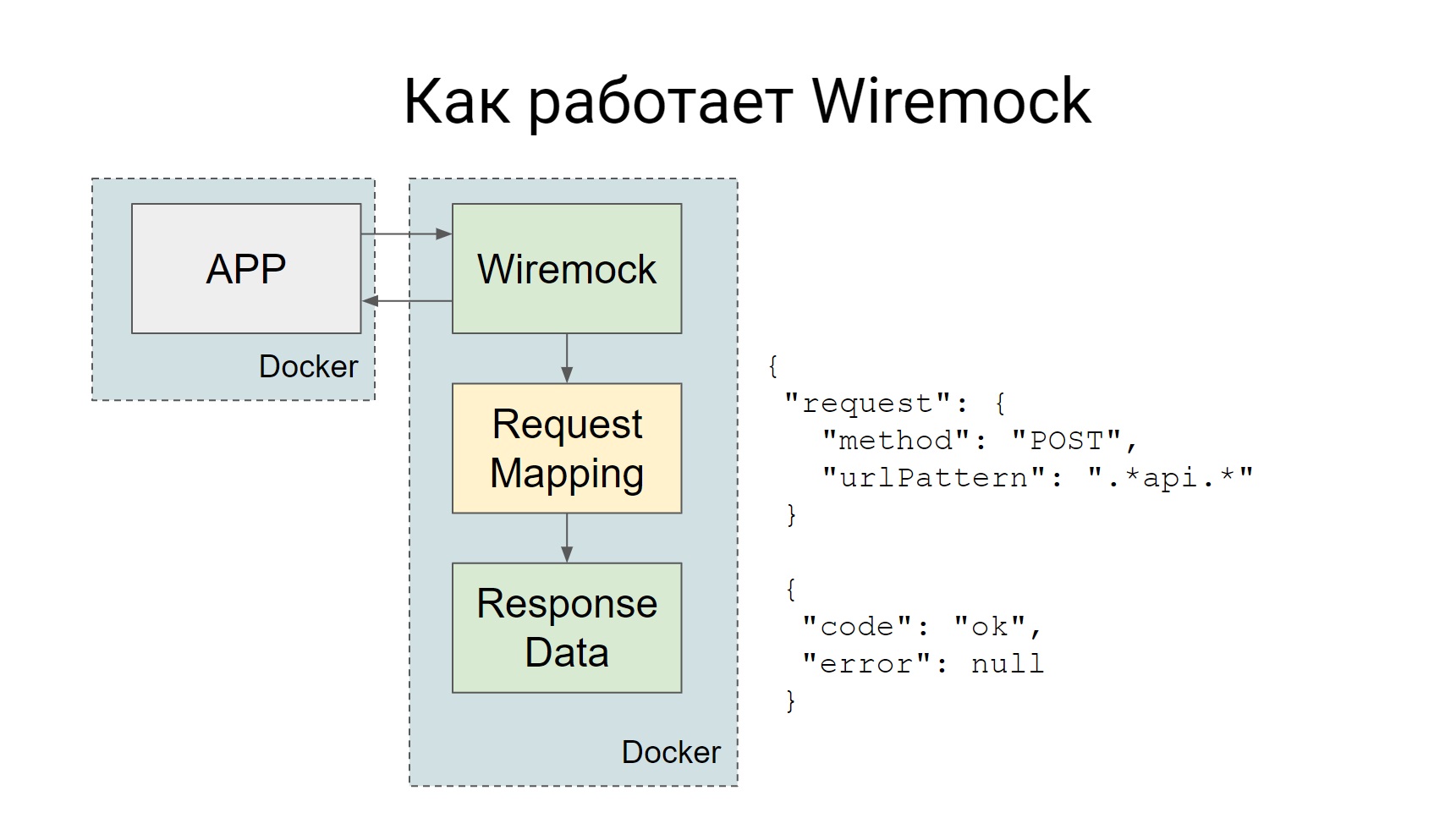
Wiremock, if you look at the slide - there is such a box, Request Mapping, it has a set of such mappings that say that if such a request arrives, you need to give such an answer. Everything is very simple: a request came - received a mock.
Mocks can be created statically, then the container, when already with Wiremock rises, these mocks will be available, they can be used in manual testing. You can create dynamically, right in the code, in some kind of test.
Here is an example of how to create a mock dynamically, you see, the description is quite declarative, it’s immediately clear from the code what kind of mock we are creating: a mock for the GET method that comes to such a URL, and, in fact, what to return.

In addition to the fact that this mock can be created, Wiremock has the opportunity then to check which request went to this mock. This is also very useful in tests.
About Codeception itself, probably, everything, and a few words about how our tests are run, and a bit of infrastructure.
What are we using?

Well, firstly, all the services we have in Docker, so launching a test environment is raising the right containers.
Make is used for internal commands, Bamboo is used as CI.
What does the CI test run look like?

First, we build the desired version of the application, then we raise the environment - this is the application, all the services that it needs, like Kafka, Rabbit, the database, and we roll the migration to the database.
All this environment is raised with the help of Docker Compose. It is in CI, on prod that all containers spin under Kubernetes. Then run the tests and run.
How long does it all take?
It all depends on the specific service, but, as a rule, raising the environment before running the tests is 5-10 minutes, tests - from 6 to 30 minutes.

I’ll immediately warn this question while all the tests are chasing in one thread.
Well, such a question. How often should tests be run? Of course, the more often, the better. The sooner you can catch a problem, the faster you can solve it.
We have 2 main rules. When a task goes into testing, all tests, both unit and not unit tests, must pass on it. If some tests fail, this is an occasion to transfer the task to fixing.
Naturally, when we roll out the release. On the release, all tests must pass.
In the end, I would like to say something inspiring - write tests, let them be green, use Codeception, make moki. I think you all perfectly understand this.
We will talk about Codeception, about how we use it in Lamoda and how to write tests on it.
Lamoda has many services. There are client services that interact directly with our users, with users of the site, mobile application. We will not talk about them. And there is what our company calls deep backends - these are our back-office systems that automate our business processes. These include delivery, storage, automation of photo studios and a call center. Most of these services are developed in PHP.
Speaking briefly about our stack, this is PHP + Symfony. Here and there are old projects on Zend'e. PostgreSQL and MySQL are used as databases, and Rabbit or Kafka are used as messaging systems.
Why PHP backends?
Because they usually have a branchy API - it's either REST, in some places there is a little bit of SOAP. If they have a UI, then this UI is more of an auxiliary one, which our internal users use.
Why do we need autotests at Lamoda?
In general, when I came to work at Lamoda, there was such a slogan: “Let's get rid of manual regression”. We will not manually test anything regression. And we worked on this task. Actually, this is one of the main reasons why we need autotests - so as not to drive regression by hand. Why do we need this? Right to release quickly. So that we can painlessly, very quickly roll out our releases and at the same time have some kind of grid from self-tests that they will tell us, good or bad. These are probably the most important goals. But there are a couple of auxiliary, about which I also want to say.
Why do we need autotests?
- Do not test regression with your hands
- Quick release
- Use as documentation
- Speed up onboarding new employees
- Autotests are conveniently used (in some cases) as documentation. Sometimes it’s easier to go into the tests, see which cases are covered, how they work, and understand how this or that functionality works, and speed up the entry of new employees - both developers and testers - into a new project. When you sit down to write autotests, it immediately becomes clear how the system works.
Ok, talked about why we need autotests. Now let's talk about what tests we write in Lamoda.
This is a fairly standard testing pyramid, from unit tests to E2E tests, where some business chains are already tested. I won’t talk about the lower two levels; it is not for nothing that they are painted over in such white color. These are tests on the code itself, they are written by our developers. In extreme cases, the tester can go into the Pull Request, look at the code and say: “Well, something is not enough cases here, let's cover something else.” This completes the work of the tester for these tests.
We will talk about the levels above, which are written by developers and testers. Let's start with system tests. These are tests that test the API (REST or SOAP), test some internal system logic, various commands, parse queues in Rabbit, or exchange with external systems. As a rule, these tests are quite atomic. They do not check any chain, but check one action. For example, one API method or one command. And they check as many cases as possible, both positive and negative.
Go ahead, E2E tests. I divided them into 2 parts. We have tests that test a bunch of UI and backend. And there are tests that we call flow tests. They test the chain - the life of an object from beginning to end.
For example, we have a system for managing the processing of our orders. Inside such a system there can be a test - an order from creation to delivery, that is, passing it through all statuses. It is on such tests that it is then very easy and simple to watch how the system works. You immediately see the entire flow of certain objects, with what external systems all this interacts, what commands are used for this.
Since we have this UI used by internal users, cross-browser access is not important to us. We do not drive these tests on any farms, it is enough for us to check in one browser, and sometimes we do not even need to use a browser.
“Why did we choose Codeception for test automation?” - you probably ask.
To be honest, I have no answer to this question. When I came to Lamoda, Codeception was already selected as the standard for writing autotests, and I came across it in fact. But after working with this framework for some time, I still understood why Codeception. This is what I want to share with you.
Why codeception?
- You can write and run the same tests of any kind (unit, functional, acceptance).
- Many rakes have already been solved, many modules have already been written.
- In all projects, despite slightly different needs, the tests will look the same.
- The concept of Codeception suggests that you write any tests on this framework: unit, integration, functional, acceptance. And you, at least, they will be launched equally.
- Codeception is a powerful enough processor in which many problems, many questions, many tasks for tests have already been solved. If something is not decided, then most likely you will find something from the outside - some add-on for some specific work. You do not need to write any test wrappers for databases, for something else. Just take and connect modules to Codeception and work with them.
- Well, such a plus (probably it is more suitable for large companies when you have many projects and services) - in all projects the tests will look plus or minus the same. It's very nice.
I’ll briefly say what Codeception is like, since many worked with it.
Codeception works on an actor model. After you drag it into the project and initialize, such a structure is generated.
We have yml files, here below - functional.suite.yml , integration.suit.yml , unit.suite.yml . They create the configuration of your tests. There are daddies for each type of test, where these tests are, there are 3 auxiliary daddies:
_ data - for test data;
_ output - where reports are placed (xml, html);
_ support- where some auxiliary helpers, functions and everything that you write are put to use in your tests.
To begin with, I’ll tell you what we took from Codeception and use it out of the box, not modifying anything, not solving additional tasks or problems.
Standard modules
- Phpbrowser
- REST
- Db
- Cli
- AMQP
The first such module is PhpBrowser. This module is a wrapper over Guzzle that allows you to interact with your application: open pages, fill out forms, submit forms. And if you do not care about cross-browser and browser testing, if you are suddenly testing the UI, you can use PhpBrowser. As a rule, we use it in our UI tests, because we don’t need any complicated interaction logic, we just need to open the page and do something small there.
The second module we use is REST. I think the name makes it clear what he's doing. For any http interactions, you can use this module. It seems to me that almost all interactions are solved in it: headers, cookies, authorization. Everything you need is in it.
The third module that we use out of the box is the Db module. In recent versions of Codeception, support for not one, but several databases has been added there. Therefore, if you suddenly have several databases in your project, now it works out of the box.
The Cli module, which allows you to run shell and bash commands from tests, and we use it too.
There is an AMQP module that works with any message brokers that are based on this protocol. I want to note that it is officially tested on RabbitMQ. Since we use RabbitMQ, everything is okay with him.
In fact, Codeception, at least in our case, covers 80-85% of all the tasks we need. But I still had to work on something.
Let's start with SOAP.
In our services, in some places there are SOAP endpoints. They need to be tested, pulled, something to do with them. But you will say that in Codeception there is such a module that allows you to send requests and then do something with the answers. Somehow to parse, add checks and everything is OK. But the SOAP module does not work out of the box with multiple SOAP endpoints.
For example, we have monoliths that have several WSDLs, several SOAP endpoints. This means that it is impossible in the Codeception module to configure this in a yml file so that it can work with several.
Codeception has a dynamic module reconfiguration, and you can write some kind of your adapter to receive, for example, a SOAP module and dynamically reconfigure it. In this case, it is necessary to replace the endpoint and the scheme used. Then in the test, if you need to change the endpoint to which you want to send a request, we get our adapter and change it to a new endpoint, to a new circuit and send a request to it.
In Codeception, there is no work with Kafka and there are no third-party more or less official add-ons to work with Kafka. There is nothing to worry about, we wrote our module.
So it is configured in a yml file. Some settings are set for brokers, for consumers and for topics. These settings, when you write your module, you can then pull it into modules with the initialize function and initialize this module with the same settings. And, in fact, the module has all the other methods to implement - put the message in the topic and read it. That is all you need from this module.
Conclusion : modules for Codeception are easy to write.
Move on. As I said, Codeception has a Cli module - a wrapper for shell commands and working with their output.
But sometimes the shell-the team needs to be run not in tests, but in the application. In general, tests and applications are slightly different entities, they can lie in different places. Tests can be run in one place, and the application may be in another.
So why do we need to run shell in tests?
We have commands in applications that, for example, parse queues in RabbitMQ and move objects by status. These commands in pro-mode are launched from under the supervisor. The supervisor monitors their implementation. If they fall, then he starts them again and so on.
When we test, the supervisor is not running. Otherwise, the tests become unstable, unpredictable. We ourselves want to control the launch of these commands inside the application. Therefore, we need to run these commands from the tests in the application. We use two options. That one, that the other - in principle, everything is the same, and everything works.
How to run a shell in an application?
First: run the tests in the same place where the application is located. Since all the applications we have in Docker, tests can be run in the same container where the service itself is located.
The second option: make a separate container for tests, some test runner , but make it the same as the application. That is, from the same Docker image, and then everything will work similarly.
Another problem that we encountered in the tests is working with various file systems. Below is an example of what you can and should work with. The first three are relevant for us. These are Webdav, SFTP, and the Amazon file system.
What do you need to work with?
- Webdav
- FTP / SFTP
- AWS S3
- Local
- Azure, Dropbox, google drive
If you rummage through Codeception, you can find some modules for almost any more or less popular file system.
The only thing I did not find is for Webdav. But these file systems, plus or minus, are the same in terms of external work with them, and we want to work with them the same way.
We wrote our module called Flysystem. It lies on Github in the public domain and supports 2 file systems - SFTP and Webdav - and allows you to work with both using the same API.
Get a list of files, clean the directory, write a file, and so on. If you also add the Amazon file system there, our needs will definitely be covered.
The next point, I think, is very important for autotests, especially the system level, is working with databases. In general, I want it to be, as in the picture, - VZHUH and everything starts up, it works, and these databases should be less supported in tests.
What are the main tasks that I see here:
- How to roll out the database of the desired structure - Db
- How to fill the database with test data - Db, Fixtures
- How to make selections and checks - Db
For all 3 tasks in Codeception, there are 2 modules - Db, which I already talked about, another is called Fixtures.
Of these 2 modules and 3 tasks, we use only DB for the third task.
For the first task, you can use DB. There you can configure the SQL dump from which the database will be deployed, well, the module with fixtures, I think it’s clear why it is needed.
There will be fixtures in the form of arrays that can be persisted into the database.
As I said, the first 2 tasks we solve a little differently, now I will tell you how we do it.
Database deployment
- Raising a container with PostgreSQL or MySQL
- We roll all migrations with doctrine migrations
The first is about deploying a database. How does this happen in tests. We raise the container with the desired database - either PostgreSQL or MySQL, then roll all the necessary migrations using doctrine migrations . Everything, the database of the desired structure is ready, it can be used in tests.
Why we don’t use damps - because then it does not need to be supported. This is some kind of dump that lies with the tests, which needs to be constantly updated if something changes in the database. There are migrations - no need to maintain a dump.
The second point is the creation of test data. We do not use the Fixtures module from Codeception, we use the Symfony bundle for fixtures.
There is a link hereon it and an example of how you can create fixtures in the database.
Your fixture will then be created as some object of the domain, it can be stored in the database, and the test data will be ready.
Why DoctrineFixtureBundle?
- Easier to create chains of related objects.
- Less data duplication if fixtures for different tests are similar.
- Less edits when changing the structure of the database.
- Fixture classes are much more visual than arrays.
Why do we use it? Yes, for the same reason - these fixtures are much easier to maintain than fixtures from Codeception. It's easier to create chains of related objects, because it's all in the symfony bundle. Less data need to be duplicated, because fixtures can be inherited, these are classes. If the database structure changes, these arrays always need to be edited, and classes not always. Fixtures in the form of domain objects are always more visible than arrays.
We talked about databases, let's talk a little about moki.
Since these are tests of a sufficiently high level that test the entire system and since our systems are highly interconnected, it is clear that there are some exchanges and interactions. Now we will talk about mokeys on the interaction between systems.
Rules for mok
- Weep all external http-service interactions
- Checking not only positive, but also negative scenarios
Interactions are some REST or SOAP http interactions. All these interactions within the framework of the tests we are wetting. That is, in our tests there is no real appeal to external systems anywhere. This makes the tests stable. Because an external service may work, may not work, may respond slowly, may quickly, in general, do not know what its behavior is. Therefore, we cover it all with moks.
We also have such a rule. We are wetting not only positive interactions, but also trying to check some negative cases. For example, when a third-party service responds with a 500th error or produces some more meaningful error, we try to check it all.
We use Wiremock for mocks, Codeception itself supports ..., it has such an official add-on Httpmock, but we liked Wiremock more. How does it work?
Wiremock rises as a separate Docker container during tests, and all requests that must go to the external system go to Wiremock.
Wiremock, if you look at the slide - there is such a box, Request Mapping, it has a set of such mappings that say that if such a request arrives, you need to give such an answer. Everything is very simple: a request came - received a mock.
Mocks can be created statically, then the container, when already with Wiremock rises, these mocks will be available, they can be used in manual testing. You can create dynamically, right in the code, in some kind of test.
Here is an example of how to create a mock dynamically, you see, the description is quite declarative, it’s immediately clear from the code what kind of mock we are creating: a mock for the GET method that comes to such a URL, and, in fact, what to return.
In addition to the fact that this mock can be created, Wiremock has the opportunity then to check which request went to this mock. This is also very useful in tests.
About Codeception itself, probably, everything, and a few words about how our tests are run, and a bit of infrastructure.
What are we using?
Well, firstly, all the services we have in Docker, so launching a test environment is raising the right containers.
Make is used for internal commands, Bamboo is used as CI.
What does the CI test run look like?
First, we build the desired version of the application, then we raise the environment - this is the application, all the services that it needs, like Kafka, Rabbit, the database, and we roll the migration to the database.
All this environment is raised with the help of Docker Compose. It is in CI, on prod that all containers spin under Kubernetes. Then run the tests and run.
How long does it all take?
It all depends on the specific service, but, as a rule, raising the environment before running the tests is 5-10 minutes, tests - from 6 to 30 minutes.
I’ll immediately warn this question while all the tests are chasing in one thread.
Well, such a question. How often should tests be run? Of course, the more often, the better. The sooner you can catch a problem, the faster you can solve it.
We have 2 main rules. When a task goes into testing, all tests, both unit and not unit tests, must pass on it. If some tests fail, this is an occasion to transfer the task to fixing.
Naturally, when we roll out the release. On the release, all tests must pass.
In the end, I would like to say something inspiring - write tests, let them be green, use Codeception, make moki. I think you all perfectly understand this.