How Tesla Teaches Autopilot
- Transfer

Decryption of the 2nd part of Tesla Autonomy Investor Day. Autopilot training cycle, data collection infrastructure, automatic data labeling, imitation of human drivers, video distance detection, sensor-supervision and much more.
The first part is the development of Full Self-Driving Computer (FSDC) .
Host: FSDC can work with very complex neural networks for image processing. It's time to talk about how we get images and how we analyze them. We have a senior AI director at Tesla, Andrei Karpaty, who will explain all this to you.
Andrew:I have been training in neural networks for about ten years, and now for 5-6 years for industrial use. Including such well-known institutions as Stanford, Open AI and Google. This set of neural networks is not only for image processing, but also for natural language. I designed architectures that combine these two modalities for my doctoral dissertation.
At Stanford, I taught a course on deconvolutionary neural networks. I was the main teacher and developed the entire curriculum for him. At first I had about 150 students, over the next two or three years the number of students grew to 700. This is a very popular course, one of the largest and most successful courses at Stanford right now.
Ilon:Andrei is truly one of the best machine vision specialists in the world. Perhaps the best.
Andrew: Thank you. Hello everybody. Pete told you about a chip that we developed specifically for neural networks in a car. My team is responsible for training these neural networks. This includes data collection, training, and, in part, deployment.
What do neural networks in a car do. There are eight cameras in the car that shoot video. Neural networks watch these videos, process them, and make predictions about what they see. We are interested in road markings, traffic participants, other objects and their distances, roadway, traffic lights, traffic signs and so on.

My presentation can be divided into three parts. First, I will briefly introduce you to neural networks and how they work and how they are trained. This must be done so that in the second part it is clear why it is so important that we have a huge fleet of Tesla cars (fleet). Why is this a key factor in training neural networks that work efficiently on the road? In the third part, I will talk about machine vision, lidar, and how to estimate distance using only video.
How do neural networks work?
(There is not much new here, you can skip and go to the next heading)
The main task that networks solve in the car is pattern recognition. For us humans, this is a very simple task. You look at the images and see a cello, boat, iguana or scissors. Very easy and simple for you, but not for the computer. The reason is that these computer images are just an array of pixels, where each pixel is the brightness value at that point. Instead of just seeing the image, the computer receives a million numbers in an array.
Ilon: Matrix, if you want. Really matrix.

Andrew:Yes. We need to move from this grid of pixels and brightness values to higher-level concepts such as iguana and so on. As you can imagine, this image of an iguana has a specific brightness pattern. But iguanas can be depicted in different ways, in different poses, in different lighting conditions, on a different background. You can find many different images of the iguana and we must recognize it in any conditions.
The reason you and I can easily handle this is that we have a huge neural network inside that processes images. Light enters the retina and is sent to the back of your brain to the visual cortex. The cerebral cortex consists of many neurons that are connected to each other and perform pattern recognition.
In the last five years, modern approaches to image processing using computers have also begun to use neural networks, but in this case, artificial neural networks. Artificial neural networks are a crude mathematical approximation of the visual cortex. There are also neurons here, they are connected to each other. A typical neural network includes tens or hundreds of millions of neurons, and each neuron has thousands of links.
We can take a neural network and show it images, such as our iguana, and the network will make a prediction that it sees. First, neural networks are initialized completely by accident, all the weights of the connections between neurons are random numbers. Therefore, the network forecast will also be random. It may turn out that the net thinks it is probably a boat. During training, we know and note that the iguana is on the image. We simply say that we would like the probability of an iguana for this image to increase, and the likelihood of everything else to decrease. Then a mathematical process called the back propagation method is used. Stochastic gradient descent, which allows us to propagate the signal along the links and update their weights. We’ll update the weight of each of these connections quite a bit, and as soon as the update is completed,
Of course, we do this with more than one single image. We have a large set of tagged data. Usually these are millions of images, thousands of tags or so. The learning process is repeated again and again. You show the computer an image, it tells you its opinion, then you say the correct answer, and the network is slightly configured. You repeat this millions of times, sometimes displaying the same image hundreds of times. Training usually takes several hours or several days.
Now something counter-intuitive about the work of neural networks. They really need a lot of examples. It’s not just fit in your head, but they really start from scratch, they don’t know anything. Here's an example - a cute dog, and you probably don't know her breed. This is a Japanese spaniel. We are looking at this picture and we see a Japanese spaniel. We can say: "OK, I understand, now I know what the Japanese spaniel looks like." If I show you some more images of other dogs, you can find other Japanese spaniels among them. You only need one example, but computers cannot. They need a lot of data about Japanese spaniels, thousands of examples, in different poses, different lighting conditions, on different backgrounds, etc. You need to show the computer how the Japanese spaniel looks from different points of view. And he really needs all this data,
Image layout for autopilot
So how does this all relate to autonomous driving. We are not very concerned about dog breeds. Maybe they will care in the future. But now we are interested in road markings, objects on the road, where they are, where we can go, and so on. Now we don’t just have labels like iguana, but we have images of the road, and we are interested in, for example, road markings. A person looks at the image and marks it with the mouse.

We have the opportunity to contact Tesla cars and ask for even more photos. If you request random photos, you will get images where, as a rule, the car just goes along the highway. This will be a random data set and we will mark it up.
If you mark only random sets, your network will learn a simple, common traffic situation and will work well only in it. When you show her a slightly different example, let's say an image of a road turning in a residential area. Your network may give the wrong result. She will say "well, I have seen many times, the road goes straight."

Of course, this is completely untrue. But we cannot blame the neural network. She does not know whether the tree on the left, the car on the right, or those buildings in the background matter. The network does not know anything about this. We all know that the marking line matters and the fact that it turns a little to the side. The network should take this into account, but there is no mechanism by which we can simply tell the neural network that these strokes of the road markings really matter. The only tool in our hands is labeled data.

We take images on which the network is mistaken, and mark them correctly. In this case, we mark the turning markup. Then you need to transfer many similar images to the neural network. And over time, she will accumulate knowledge and learn to understand this pattern, to understand that this part of the image does not play a role, but this markup is very important. The network will learn how to correctly find the lane.
Not only the size of the training data set is important. We need more than just millions of images. A lot of work needs to be done to cover the space of situations that a car can meet on the road. You need to teach a computer to work at night and in the rain. The road can reflect light like a mirror, illumination can vary within wide limits, images will look very different.

We must teach the computer how to handle shadows, forks, and large objects that occupy most of the image. How to work with tunnels or in a road repair area. And in all these cases there is no direct mechanism to tell the network what to do. We have only a huge data set. We can take images, mark up, and train the network until it begins to understand their structure.
Large and diverse data sets help networks work very well. This is not our discovery. Experiments and research Google, Facebook, Baidu, Deepmind from Alphabet. All show similar results - neural networks really like data, like quantity and variety. Add more data and the accuracy of neural networks is growing.
You will have to develop an autopilot to simulate the behavior of cars in a simulation
A number of experts point out that we could use the simulation to get the necessary data on the right scale. At Tesla, we have repeatedly asked this question. We have our own simulator. We widely use simulation to develop and evaluate software. We used it for training quite successfully. But in the end, when it comes to training data for neural networks, nothing can replace real data. Simulations have problems with modeling the appearance, physics, and behavior of participants.

The real world throws us a bunch of unexpected situations. Difficult conditions with snow, trees, wind. Various visual artifacts that are difficult to model. Road repair areas, bushes, plastic bags hanging in the wind. There can be many people, adults, children and animals mixed up. Modeling the behavior and interaction of all this is an absolutely insoluble task.

This is not about the movement of a pedestrian. It's about how pedestrians react to each other, and how cars react to each other, how they react to you. All this is very difficult to simulate. You need to develop an autopilot first, only to simulate the behavior of cars in a simulation.
This is really hard. It can be dogs, exotic animals, and sometimes it’s not even something you can’t pretend to be, it’s something that simply never crosses your mind. I did not know that a truck can carry a truck that carries a truck that carries another truck. But in the real world, this and many other things are happening that are hard to come up with. The variety that I see in the data coming from the cars is just insane in relation to what we have in the simulator. Although we have a good simulator.
Ilon:Simulation is as if you were planning your own homework for yourself. If you know that you are going to pretend, Okay, that of course you will deal with this. But as Andrei said, you don’t know what you don’t know. The world is very strange, it has millions of special cases. If someone creates a driving simulation that faithfully reproduces reality, this in itself will be a monumental achievement for humanity. But no one can do this. There is simply no way.
Fleet is a key data source for training
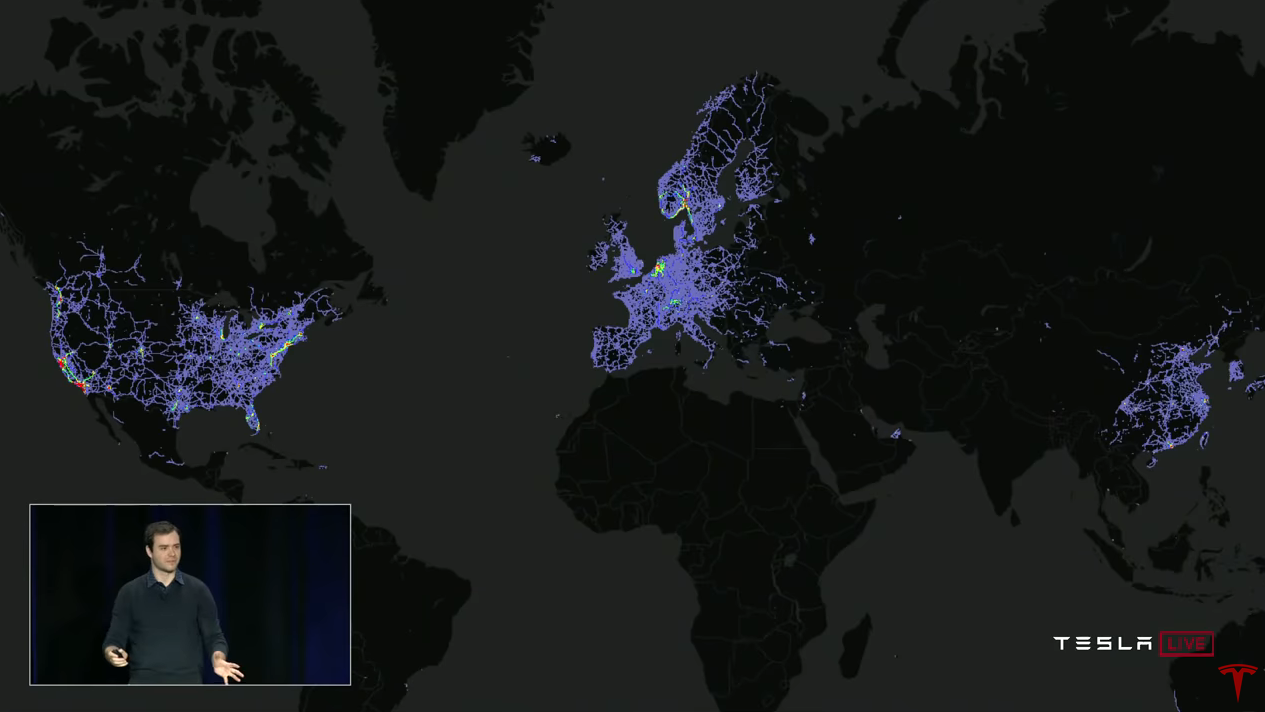
Andrei: For neural networks to work well, you need a large, diverse and real data set. And if you have one, you can train your neural network and it will work very well. So why is Tesla so special in this regard? The answer, of course, is the fleet (fleet, Tesla fleet). We can collect data from all Tesla vehicles and use them for training.
Let's look at a specific example of improving the operation of an object detector. This will give you an idea of how we train neural networks, how we use them, and how they get better over time.
Object detection is one of our most important tasks. We need to highlight the dimensions of cars and other objects in order to track them and understand how they can move. We can ask people to mark the images. People will say: “here are cars, here are bicycles” and so on. And we can train the neural network on this data. But in some cases, the network will make incorrect forecasts.

For example, if we stumble upon a car to which a bicycle is attached at the back, then our neural network will detect 2 objects - a car and a bicycle. That is how she worked when I first arrived. And in its own way it is right, because both of these objects are really present here. But the autopilot planner does not care about the fact that this bike is a separate object that moves with the car. The truth is that this bike is rigidly attached to the car. In terms of objects on the road, this is one object - one car.

Now we would like to mark many similar objects as “one car”. Our team uses the following approach. We take this image or several images in which such a model is present. And we have a machine learning mechanism with which we can ask the fleet to provide us with examples that look the same. And the fleet sends images in response.

Here is an example of six received images. They all contain bikes attached to cars. We will mark them correctly and our detector will work better. The network will begin to understand when the bike is attached to the car, and that it is one object. You can train the network in this, provided that you have enough examples. And that’s how we solve such problems.
I talk a lot about getting data from Tesla cars. And I want to say right away that we developed this system from the very beginning, taking into account confidentiality. All data that we use for training is anonymized.
The fleet sends us not only bicycles on cars. We are constantly looking for many different models. For example, we are looking for boats - the fleet sends images of boats on the roads. We want images of road repair areas, and the fleet sends us many such images from around the world. Or for example, trash on the road, this is also very important. The fleet sends us images of tires, cones, plastic bags and the like on the road.

We can get enough images, mark them up correctly, and the neural network will learn how to work with them in the real world. We need the neural network to understand what is happening and to respond correctly.
Neural network uncertainty triggers data collection
The procedure, which we repeat again and again to train the neural network, is as follows. We started with a random set of images received from the fleet. We mark up the images, train the neural network and load it into cars. We have mechanisms by which we detect inaccuracies in the operation of the autopilot. If we see that the neural network is not sure or there is driver intervention or other events, the data on which this happened is automatically sent.

For example, tunnel markings are poorly recognized. We notice that there is a problem in the tunnels. Corresponding images fall into our unit tests so that the problem cannot be repeated later. Now, to fix the problem, we need a lot of training examples. We ask the fleet to send us more images of the tunnels, mark them correctly, add them to the training set and retrain the network, and then load them into cars. This cycle repeats over and over. We call this iterative process the data engine (data engine? Data engine?). We turn on the network in shadow mode, detect inaccuracies, request more data, include them in the training set. We do this for all kinds of predictions of our neural networks.
Automatic data markup
I talked a lot about manual markup of images. This is a costly process, both in time and financially. It can be too expensive. I want to talk about how you can use the fleet here. Manual marking is a bottleneck. We just want to transfer the data and mark it up automatically. And there are several mechanisms for this.
As an example, one of our recent projects is rebuilding detection. You are driving on the highway, someone is driving on the left or right, and he is rebuilding into your lane.

Here's a video where the autopilot detects a rebuild. Of course, we would like to discover it as soon as possible. The approach to solving this problem is that we do not write code like: the left direction indicator is on, the right direction indicator is on, whether the car moved horizontally over time. Instead, we use fleet-based auto-learning.
How it works. We ask the fleet to send us data whenever a rebuild in our lane is recorded. Then we rewind time back and automatically note that this car will rebuild in front of you in 1.3 seconds. These data can be used to train the neural network. Thus, the neural network itself will extract the necessary signs. For example, a car is scouring and then rebuilding, or it has a turn signal turned on. The neural network learns about all this from automatically labeled examples.
Shadow Check
We ask the fleet to automatically send us the data. We can collect half a million images or so, and rebuilds will be marked on all. We train the network and load it into the fleet. But until we turn it on completely, but run it in shadow mode. In this mode, the network constantly makes predictions: "hey, I think this car is going to be rebuilt." And we are looking for erroneous forecasts.

Here is an example of a clip that we got from shadow mode. Here the situation is not a little obvious, and the network thought that the car on the right was about to rebuild. And you may notice that he is flirting slightly with the marking line. The network reacted to this, and suggested that the car would soon be in our lane. But that did not happen.
The network operates in shadow mode and makes forecasts. Among them are false positive and false negative. Sometimes the network reacts erroneously, and sometimes, it skips events. All of these errors trigger data collection. Data is tagged and incorporated into training without additional effort. And we do not endanger people in this process. We retrain the network and use shadow mode again. We can repeat this several times, evaluating false alarms in real traffic conditions. Once the indicators suit us, we simply click the switch and let the network control the car.
We launched one of the first versions of the rebuild detector, about three months ago. If you notice that the machine has become much better at detecting rebuilding, this is training with the fleet in action. And not a single person was injured in this process. It’s just a lot of training of neural networks based on real data, using the shadow mode and analyzing the results.
Ilon: In fact, all drivers constantly train the network. It doesn’t matter whether autopilot is turned on or off. The network is learning. Each mile traversed by a machine with HW2.0 or higher equipment educates the network.
While you are driving, you are actually marking up the data

Andrei: Another interesting project that we use in the fleet training scheme is forecasting the way. When you drive, you are actually marking up the data. You tell us how to drive in different driving situations. Here is one of the drivers turned left at the intersection. We have a full video of all cameras, and we know the path that the driver chose. We also know what the speed and angle of rotation of the steering wheel was. We bring it all together and understand the path that a person has chosen in this traffic situation. And we can use this as teaching with a teacher. We just get the necessary amount of data from the fleet, train the network on these trajectories, and after that the neural network can predict the path.
This is called imitation learning. We take the trajectories of people from the real world and try to imitate them. And again we can take our iterative approach.
Here is an example of predicting a path in difficult road conditions. In the video we overlay the network forecast. Green marks the path that the network would move.

Ilon: The madness is that the network predicts a path that it cannot even see. With incredibly high precision. She does not see what is around the bend, but believes that the probability of this trajectory is extremely high. And it turns out to be right. Today you will see it in cars, we will include augmented vision so that you can see the markings and projections of the trajectory superimposed on the video.
Andrei: In fact, under the hood, the most is happening, and
Ilon: Actually, it’s a little scary (Andrey laughs).
Andrew: Of course, I miss a lot of details. You may not want to use all drivers in a row to mark up, you want to imitate the best. And we use a number of ways to prepare this data. Interestingly, this forecast is actually three-dimensional. This is a path in three-dimensional space that we display in 2D. But the network has information about the slope, and this is very important for driving.
Predicting the way currently works in cars. By the way, when you passed the junction on the highway, about five months ago, your car could not cope with it. Now it can. This is the prediction of the way, in action, in your cars. We turned it on a while ago. And today you can see how it works at intersections. A significant part of training to overcome intersections is obtained by automatically marking up data.
I managed to talk about the key components of neural network training. You need a large, diverse set of real data. In Tesla, we get it using the fleet. We use the data engine, shadow mode and automatic data partitioning using the fleet. And we can scale this approach.
Perception of depth by video

In the next part of my speech I will talk about perceiving depth through vision. You probably know that cars use at least two types of sensors. One is brightness video cameras, and the other is lidar, which many companies use. Lidar gives point measurements of the distance around you.
I would like to note that you all came here using only your neural network and vision. You didn’t shoot with lasers from your eyes and still ended up here.
It is clear that the human neural network extracts distance and perceives the world as three-dimensional exclusively through vision. She uses a number of tricks. I will briefly talk about some of them. For example, we have two eyes, so you get two images of the world in front of you. Your brain combines this information to get an estimate of distances, this is done by triangulating points in two images. In many animals, the eyes are located on the sides and their field of view is slightly crossed. These animals use structure (motion). They move their heads to get many images of the world from different points and can also apply triangulation.

Even with one eye closed and completely motionless, you retain a certain sense of perception of distance. If you close one eye, it will not seem to you that I have become two meters closer or one hundred meters further. This is because there are many powerful monocular techniques that your brain also applies. For example, a common optical illusion, with two identical stripes on the background of the rail. Your brain evaluates the scene and expects one of them to be larger than the other due to rail lines disappearing into the distance. Your brain does a lot of this automatically, and artificial neural networks can do that too.
I will give three examples of how you can achieve the perception of depth in the video. One classic approach and two based on neural networks.

We can take a video clip in a few seconds and recreate the surroundings in 3D using triangulation and stereo vision methods. We apply similar methods in the car. The main thing is that the signal really has the necessary information, the only question is to extract it.
Marking distance using radar
As I said, neural networks are a very powerful visual recognition tool. If you want them to recognize the distance, you need to mark the distances, and then the network will learn how to do it. Nothing restricts networks in their ability to predict distance other than having tagged data.
We use a radar directed forward. This radar measures and marks the distance to objects that the neural network sees. Instead of telling people “this car is about 25 meters away”, you can mark up the data much better using sensors. Radar works very well at this distance. You mark up the data and train the neural network. If you have enough data, a neural network will be very good at predicting distance.

In this image, the circles show the objects received by the radar, and the cuboids are the objects received by the neural network. And if the network works well, then in the top view, the positions of the cuboids should coincide with the position of the circles, which we observe. Neural networks do very well with distance prediction. They can learn the sizes of different vehicles, and according to their size on the image, quite accurately determine the distance.
Self-supervision
The last mechanism, which I will talk about very briefly, is a bit more technical. There are only a few articles, mainly in the last year or two, about this approach. It is called Self-supervision.

What's going on here. You upload raw unlabeled videos to the neural network. And the network can still learn to recognize distance. Without going into details, the idea is that a neural network predicts the distance in each frame of this video. We do not have tags for verification, but there is a goal - time consistency. No matter what distance the network predicts, it must be consistent throughout the video. And the only way to be consistent is to predict the distance correctly. The network automatically predicts depth for all pixels. We managed to reproduce it, and it works pretty well.
Powerful visual recognition is a must for autopilot
To summarize. People use vision, no lasers. I want to emphasize that powerful visual recognition is absolutely essential for autonomous driving. We need neural networks that really understand the environment.

Data from the lidar is much less saturated with information. Is this silhouette on the road, is it a plastic bag or a tire? Lidar will simply give you a few points, while vision can tell you what it is. Is this guy on a bicycle looking back, is he trying to change lane or is he going straight? In the road repair zone, what do these signs mean and how should I behave here? Yes, the entire road infrastructure is designed for visual consumption. All signs, traffic lights, everything is for sight, that’s where all the information is. And we must use it.
This girl is passionate about the phone, is she going to step on the roadway? Answers to such questions can be found only with the help of vision and they are necessary for autopilot level 4-5. And that is what we are developing at Tesla. We do this through large-scale neural network training, our data engine and fleet assistance.
In this regard, lidar is an attempt to cut the path. It circumvents the fundamental task of machine vision, the solution of which is necessary for autonomous driving. It gives a false sense of progress. Lidar is only good for quick demonstrations.
Progress is proportional to the frequency of collisions with complex situations in the real world.

If I wanted to fit all that was said on one slide, it would look like this. We need level 4-5 systems that can handle all possible situations in 99.9999% of cases. The pursuit of the last nines will be difficult and very difficult. This will require a very powerful machine vision system.
Shown here are images that you may encounter on the way to the cherished decimal places. At first, you just have cars going forward, then these cars start to look a little unusual, bicycles appear on them, cars on cars. Then you come across really rare events, such as inverted cars or even cars in a jump. We meet a lot of everything in the data coming from the fleet.
And we see these rare events much more often than our competitors. This determines the speed with which we can obtain data and fix problems through training neural networks. The speed of progress is proportional to the frequency with which you are faced with difficult situations in the real world. And we come across them more often than anyone else. Therefore, our autopilot is better than others. Thanks.
Questions and answers
Question: How much data do you collect on average from each car?
Andrew: It's not just about the amount of data, it's about diversity. At some point, you already have enough images of driving along the highway, the network understands them, it is no longer necessary. Therefore, we are strategically focused on obtaining the right data. And our infrastructure, with a rather complicated analysis, allows us to get the data that we need right now. This is not about huge amounts of data, it is about very well selected data.
Question:I wonder how you are going to solve the problem of changing lanes. Whenever I try to rebuild into a dense stream, they cut me off. Human behavior is becoming irrational on the roads of Los Angeles. The autopilot wants to drive safely, and you almost have to do it unsafe.
Andrew:I talked about the data engine as learning neural networks. But we do the same at the software level. All the parameters that affect the choice, for example, when to rebuild, how aggressive. We also change them in shadow mode, and observe how well they work and adjust the heuristic. In fact, designing such heuristics for the general case is a difficult task. I think we will have to use fleet training to make such decisions. When do people change lanes? In what scenarios? When do they feel that changing lanes is unsafe? Let's just look at a large amount of data and teach the machine learning classifier to distinguish when rebuilding is safe. These classifiers will be able to write much better code than people,
Ilon: Probably, we will have the “traffic in Los Angeles” mode. Somewhere after the Mad Max mode. Yeah, Mad Max would have a hard time in Los Angeles.
Andrei Will have to compromise. You do not want to create unsafe situations, but want to get home. And the dances that people perform at the same time, it is very difficult to program. I think the right one is machine learning. Where we just look at the many ways people do this and try to imitate them.
Ilon:Now we are a little conservative, and as our confidence grows, it will become possible to choose a more aggressive regime. Users will be able to choose it. In aggressive modes, when trying to change lanes in a traffic jam, there is a slight chance of wrinkling the wing. No risk of a serious accident. You will have the choice of whether you agree to a non-zero chance of mashing the wing. Unfortunately, this is the only way to get stuck in traffic on the highway.
Question: Could it happen on one of those nines after the decimal point that lidar will be useful? The second question is, if lidars are really worthless, what will happen to those who build their decisions on them?
Ilon:They will all get rid of lidars, this is my forecast, you can write down. I must say, I do not hate lidar as much as it might seem. SpaceX Dragon uses the lidar to move to the ISS and dock. SpaceX has developed its own lidar from scratch for this. I personally led this project because lidar makes sense in this scenario. But in cars it’s damn stupid. It is expensive and not necessary. And, as Andrei said, as soon as you handle the video, the lidar will become useless. You will have expensive equipment that is useless for the car.
We have a forward radar. It is inexpensive and useful, especially in conditions of poor visibility. Fog, dust or snow, the radar can see through them. If you are going to use active photon generation, do not use the wavelength of visible light. Because, having passive optics, you have already taken care of everything in the visible spectrum. Now it’s better to use a wavelength with good penetrating properties, such as radar. Lidar is simply the active generation of photons in the visible spectrum. Want to actively generate photons, do it outside the visible spectrum. Using 3.8 mm versus 400-700 nm you will be able to see in bad weather conditions. Therefore, we have a radar. As well as twelve ultrasonic sensors for the immediate environment. The radar is most useful in the direction of movement, because it is directly that you are moving very fast.
We have raised the issue of sensors many times. Are there enough of them? Do we have everything we need? Need to add something else? Hmmm. Enough.
Question: It seems that the cars are doing some kind of calculation to determine what information to send you. Is this done in real time or based on stored information?
Andrey: Calculations are made in real time in the cars themselves. We convey the conditions that interest us, and the cars do all the necessary calculations. If they didn’t do this, we would have to transfer all the data in a row and process it in our back-end. We do not want to do this.
Ilon:We have four hundred twenty five thousand cars with HW2.0 +. This means that they have eight cameras, a radar, ultrasonic sensors and at least an nVidia computer. It is enough to calculate which information is important and which is not. They compress important information and send it to the network for training. This is a huge degree of data compression from the real world.
Question: You have this network of hundreds of thousands of computers, which resembles a powerful distributed data center. Do you see its application for purposes other than autopilot?
Ilon: I suppose this could be used for something else. While we focus on autopilot. As soon as we bring it to the right level, we can think about other applications. By then, it will be millions or tens of millions of cars with HW3.0 or FSDC.
Question: Calculating traffic?
Ilon: Yes, maybe. it could be something like AWS (Amazon Web Services).
Question: I am a Model 3 driver in Minnesota, where there is a lot of snow. The camera and radar cannot see the road markings through the snow. How are you going to solve this problem? Will you use high accuracy GPS?
Andrew:Already today, the autopilot behaves pretty well on a snowy road. Even when the markings are hidden, or frayed, or covered with water in heavy rain, the autopilot still behaves relatively well. We have not yet specifically handled the snowy road with our data engine. But I am sure that this problem can be solved. Because in many images of a snowy road, if you ask a person where the markings should be, he will show it to you. People agree on where to draw marking lines. And while people can agree and mark up your data, the neural network will be able to learn this and will work well. The only question is whether there is enough information in the original signal. Enough for a person annotator? If the answer is yes, then the neural network will do just fine.
Ilon:There are several important sources of information in the source signal. So markup, this is just one of them. The most important source is the driveway. Where you can go, and where you can’t. More important than markup. Roadway recognition works very well. I think, especially after the upcoming winter, it will work incredibly. We will wonder how this can work so well. This is just crazy.
Andrew:It's not even about the ability of people to mark up. As long as you, a person, can overcome this section of the road. The fleet will learn from you. We know how you drove here. And you obviously used vision for this. You did not see the markup, but you used the geometry of the whole scene. You see how the road bends, how other cars are located around you. The neural network will automatically highlight all of these patterns, you just need to get enough data about how people overcome such situations.
Ilon:It is very important not to stick tightly to GPS. GPS error can be very significant. And the real traffic situation can be unpredictable. It can be a road repair or detour. If the car relies too much on GPS, this is a bad situation. You are asking for trouble. GPS is good to use only as a hint.
Question: Some of your competitors talk about how they use high definition maps to improve perception and path planning. Do you use something similar in your system, do you see any benefit in this? Are there areas where you would like to have more data, not from the fleet, but something like cards?
Ilon:I think high-resolution maps are a very bad idea. The system becomes extremely unstable. Unable to adapt to changes if you are attached to GPS and high-resolution maps and do not give priority to vision. Vision is the thing that should do everything. See, markup is just a guideline, not the most important thing. We tried using markup cards and quickly realized that this was a big mistake. We completely abandoned them.
Question: Understanding where the objects are and how the cars are moving is all very useful. But what about the negotiation aspect? During parking, at roundabouts and in other situations where you interact with other cars that people drive. It is more an art than a science.
Ilon:This works pretty well. If you look at situations with rearrangements, etc., the autopilot normally copes.
Andrew: Now we use a lot of machine learning to create an idea of the real world. On top of this, we have a scheduler and controller and many heuristics about how to drive, how to take into account other cars, and so on. And just like in pattern recognition, there are many non-standard cases here, it's like a game of hawks and pigeons, which you play with other people. We are confident that ultimately we will use fleet-based training to solve this problem. Hand writing heuristics quickly rests on a plateau.
Question: Do you have a platooning mode? Is the system capable of this?
Andrew:I am absolutely sure that we could do such a regime. But again, if you just train the network to imitate people. People get attached and drive in front of the car and the network remembers this behavior. There is a kind of magic in it, everything happens by itself. Different problems come down to one, just collect the data set and use it to train the neural network.
Ilon:Three steps to autonomous driving. The first is to simply implement this functionality. The second is to bring it to such an extent that a person in a car does not need to pay attention to the road at all. And the third is to show the level of reliability that convinces regulators. These are three levels. We expect to reach the first level this year. And we expect, somewhere in the second quarter of next year, to reach a level of confidence when a person no longer needs to keep his hands on the steering wheel and look at the road. After that, we expect regulatory approval in at least some jurisdictions by the end of next year. These are my expectations.
For trucks, it is likely that the convoy regime will be approved by regulators sooner than anything else. Perhaps for long trips you can use one driver in the head car, and 4 Semi trucks behind him in the convoy mode.
Question: I am very impressed with the improvement of autopilot. Last week I was driving in the right lane of the motorway, and there was an entrance. My Model 3 was able to detect two cars entering the highway and slowed down so that one car quietly built in front of me and the other behind me. Then I thought, damn it, this is crazy, I did not know that my Model 3 is capable of such.
But that same week I was driving again in the right lane, and there was a narrowing, my right lane merged with the left. And my Model 3 was not able to react correctly, I had to intervene. Can you tell how Tesla can solve this problem?
Andrew: I talked about the data collection infrastructure. If you intervened, then most likely we got this clip. He got into the statistics, for example, with what probability we correctly flow into the stream. We look at these numbers, look at the clips, and we see what is wrong. And we are trying to correct the behavior in order to achieve improvement in comparison with the benchmarks.
Ilon:Well, we have another presentation on software. We had a presentation about equipment with Pete, then neural networks with Andrey, and now software with Stuart follows.
...