Flawless RabbitMQ migration to Kubernetes
- Tutorial

RabbitMQ is a message broker written in Erlang that allows you to organize a failover cluster with full data replication to several nodes, where each node can serve read and write requests. With many Kubernetes clusters in production, we support a large number of RabbitMQ installations and are faced with the need to migrate data from one cluster to another without downtime.
This operation was necessary for us in at least two cases:
- Transferring data from a RabbitMQ cluster, which is not in Kubernetes, to a new cluster that is already “tuned out” (that is, functioning in pods K8s).
- Migration of RabbitMQ within Kubernetes from one namespace to another (for example, if the paths are delimited by namespaces, then to transfer the infrastructure from one path to another).
The recipe proposed in this article is focused on situations (but not at all limited to them) in which there is an old RabbitMQ cluster (for example, of 3 nodes), located either in K8s or on some old servers. An application hosted in Kubernetes works with it (already there or in the future):

... and we are faced with the task of migrating it to a new production in Kubernetes.
First, a general approach to migration itself will be described, and after that, technical details on its implementation.
Migration algorithm
The first, preliminary, step before any action is to verify that high availability ( HA ) mode is enabled in the old RabbitMQ installation . The reason is obvious - we do not want to lose any data. To carry out this check, you can go to the RabbitMQ admin panel and make sure that the value is set in the Admin → Policies tab
ha-mode: all: 
The next step is to raise the new RabbitMQ cluster in Kubernetes pods (in our case, for example, consisting of 3 nodes, but their number may to be different).
After that, we merge the old and new RabbitMQ clusters, obtaining a single cluster (of 6 nodes):
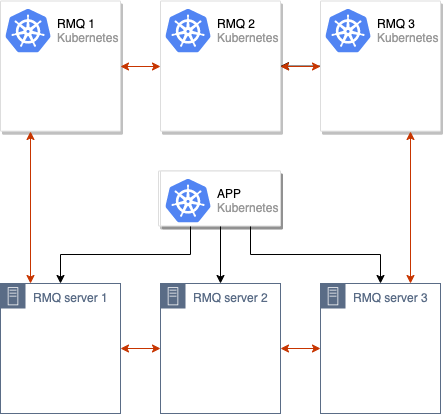
The process of synchronizing data between the old and new RabbitMQ clusters is initiated. After all the data is synchronized between all nodes in the cluster, we can switch the application to use a new cluster:
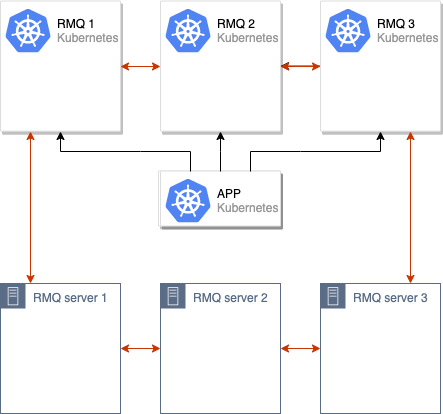
After these operations, it is enough to remove the old nodes from the RabbitMQ cluster, and the move can be considered completed:

We used this scheme in production several times. However, for their own convenience, they implemented it within the framework of a specialized system that distributes typical RMQ configurations on sets of Kubernetes clusters (for those who are curious: we are talking about addon-operator , which we recently talked about ). Below are presented individual instructions that anyone can apply on their installations to try the proposed solution in action.
We try in practice
Requirements
Details are very simple:
- Kubernetes cluster (minikube is also suitable);
- RabbitMQ cluster (can be deployed on bare metal, and made as a regular cluster in Kubernetes from the official Helm chart).
For the example below, I deployed RMQ to Kubernetes and named it
rmq-old.Stand preparation
1. Download the Helm chart and edit it a bit:
helm fetch --untar stable/rabbitmq-haFor convenience, we set a password
ErlangCookieand make a policy ha-allso that by default the queues are synchronized between all nodes of the RMQ cluster:rabbitmqPassword: guest
rabbitmqErlangCookie: mae9joopaol7aiVu3eechei2waiGa2we
definitions:
policies: |-
{
"name": "ha-all",
"pattern": ".*",
"vhost": "/",
"definition": {
"ha-mode": "all",
"ha-sync-mode": "automatic",
"ha-sync-batch-size": 81920
}
}2. Set the chart:
helm install . --name rmq-old --namespace rmq-old3. Go to the RabbitMQ admin panel, create a new queue and add a few messages. They will be needed so that after the migration we can make sure that all the data has been saved and that we haven’t lost anything:

The test bench is ready: we have the “old” RabbitMQ with the data that needs to be transferred.
RabbitMQ Cluster Migration
1. First, deploy the new RabbitMQ in a different namespace with the same
ErlangCookie password for the user. To do this, we perform the operations described above, changing the final RMQ installation command to the following:helm install . --name rmq-new --namespace rmq-new2. Now you need to merge the new cluster with the old one. To do this, go to each of the pods of the new RabbitMQ and execute the commands:
export OLD_RMQ=rabbit@rmq-old-rabbitmq-ha-0.rmq-old-rabbitmq-ha-discovery.rmq-old.svc.cluster.local && \
rabbitmqctl stop_app && \
rabbitmqctl join_cluster $OLD_RMQ && \
rabbitmqctl start_appThe variable
OLD_RMQcontains the address of one of the nodes of the old RMQ cluster. These commands will stop the current node of the new RMQ cluster, attach it to the old cluster, and restart it.
3. The 6-node RMQ cluster is ready: You

must wait until messages are synchronized between all nodes. It is easy to guess that the synchronization time of messages depends on the capacities of the iron on which the cluster is deployed, and on the number of messages. In the described scenario there are only 10 of them, so the data was synchronized instantly, but with a sufficiently large number of messages, synchronization can take hours.
Thus, the synchronization status:

It
+5means that messages are already moreon 5 nodes (except what is indicated in the field Node). Thus, the synchronization was successful. 4. It remains only to switch the RMQ address in the application to the new cluster (the specific actions here depend on the technology stack you are using and other application specifics), after which you can say goodbye to the old one.
For the last operation (i.e., after switching the application to a new cluster), we go to each node of the old cluster and execute the commands:
rabbitmqctl stop_app
rabbitmqctl resetThe cluster “forgot” about the old nodes: you can delete the old RMQ, which will complete the move.
Note : If you use RMQ with certificates, then basically nothing changes - the process of moving will be carried out exactly the same.
conclusions
The described scheme is suitable for almost all cases when we need to transfer RabbitMQ or just move to a new cluster.
In our case, difficulties occurred only once when RMQ was accessed from many places, and we did not have the opportunity to change the RMQ address to a new one everywhere. Then we launched a new RMQ in the same namespace with the same labels, so that it fell under the existing services and Ingresss, and when we started the pod, we manipulated the labels with our hands, deleting them at the beginning, so that requests did not fall on an empty RMQ, and adding them back after message synchronization.
We used the same strategy when updating RabbitMQ to a new version with a modified configuration - everything worked like a clock.
PS
As a logical continuation of this material, we are preparing articles about MongoDB (migration from an iron server to Kubernetes) and MySQL (one of the options for "preparing" this DBMS inside Kubernetes). They will be published in the coming months.
PPS
Read also in our blog: