Our Gateway API Creation Experience
Some companies, including our customer, develop the product through an affiliate network. For example, large online stores are integrated with a delivery service - you order goods and soon receive a tracking number for the parcel. Another example - together with an air ticket, you buy insurance or an Aeroexpress ticket.
For this, one API is used, which must be issued to partners through the Gateway API. We have solved this problem. This article will provide details.
Given: ecosystem and API portal with an interface where users are registered, receive information, etc. We need to make a convenient and reliable Gateway API. In the process, we needed to provide
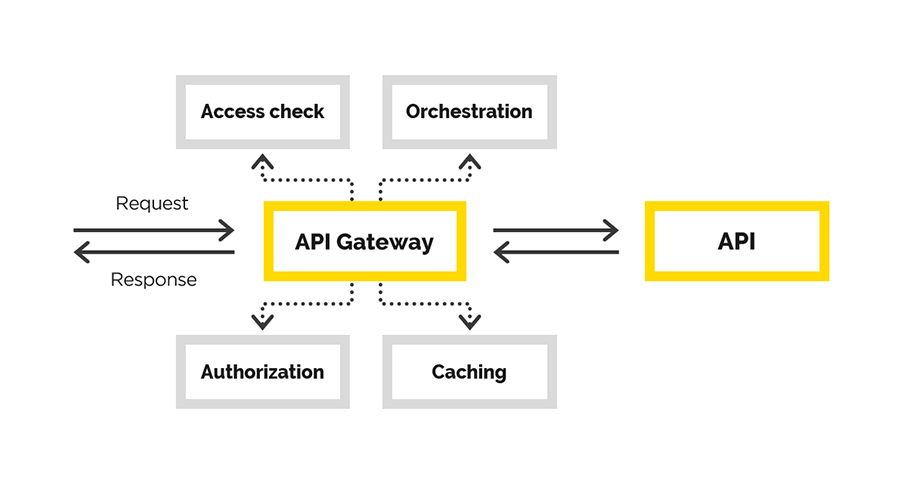
In the article, we will talk about our experience in creating the Gateway API, during which we solved the following tasks:
There are two types of API management:
1. Standard, which works as follows. Before connecting, the user tests the possibilities, then pays and embeds on his site. Most often it is used in small and medium-sized businesses.
2. A large B2B API Management, when the company first makes a business decision about connecting, becomes a partner company with a contractual obligation, and then connects to the API. And after settling all the formalities, the company gets test access, passes testing and goes into the sales. But this is not possible without a management decision to connect.
In this part, we’ll talk about creating the Gateway API.
End users of the created gateway to the API are our customer’s partners. For each of them, we already have the necessary contracts. We will only need to expand the functionality, noting the granted access to the gateway. Accordingly, a controlled connection and control process is needed.
Of course, one could take some ready-made solution for solving the API Management task and creating API Gateway in particular. For example, this could be Azure API Management. It did not suit us, because in our case we already had an API portal and a huge ecosystem built around it. All users have already been registered, they already understood where and how they can get the necessary information. The necessary interfaces already existed in the API portal, we just needed the API Gateway. Actually, we started to develop it.
What we call the Gateway API is a kind of proxy. Here we again had a choice - you can write your proxy, or you can choose something ready-made. In this case, we went the second way and chose the nginx + Lua bundle. Why? We needed a reliable, tested software that supports scaling. After the implementation, we did not want to check the correctness of the business logic and the correctness of the proxy.
Any web server has a request processing pipeline. In the case of nginx, it looks like this:

(scheme from GitHub Lua Nginx )
Our goal was to integrate into this pipeline at the moment where we can modify the original request.
We want to create a transparent proxy so that the request functionally remains as it came. We only control access to the final API, we help the request to get to it. In case the request was incorrect, the final API should show the error, but not us. The only reason we can reject the request is because of the lack of access to the client.
An extension for Lua already exists for nginx. Lua is a scripting language, it is very lightweight and easy to learn. Thus, we implemented the necessary logic using Lua.
The nginx configuration (analogy to the application’s route), where all the work is done, is understandable. Noteworthy here is the last directive - post_action.
Consider what happens in this configuration:
more_clear_input_headers - clears the value of the headers specified after the directive.
lua_need_request_body - controls whether to read the source body of the request before executing the rewrite / access / access_by_lua directives or not. By default, nginx does not read the client request body, and if you need to access it, this directive should be set to on.
rewrite_by_lua_file - the path to the script, which describes the logic for modifying the request
access_by_lua_file - the path to the script, which describes the logic that checks for access to the resource.
proxy_pass - url to which the request will be proxied.
body_filter_by_lua_file- the path to the script, which describes the logic for filtering the request before returning to the client.
And finally, post_action is an officially undocumented directive that can be used to perform any other actions after the response is given to the client.
Next, we will describe in order how we solved our problems.
Authorization
We built authorization and authentication using certificate accesses. There is a root certificate. Each new client of the customer generates his personal certificate with which he can access the API. This certificate is configured in the nginx settings server section.
Modification
A fair question may arise: what to do with a certified client if we suddenly want to disconnect it from the system? Do not reissue certificates for all other clients.
So we smoothly and approached the next task - modification of the original request. The original client request, generally speaking, is not valid for the final system. One of the tasks is to add the missing parts to the request in order to make it valid. The point is that the missing data is different for each client. We know that the client comes to us with a certificate from which we can take a fingerprint and extract the necessary client data from the database.
If at some point you need to disconnect the client from our service, his data will disappear from the database and he will not be able to do anything.
We needed to ensure high availability of the solution, especially how we get customer data. The difficulty is that the source of this data is a third-party service that does not guarantee uninterrupted and fairly high speed.
Therefore, we needed to ensure high availability of customer data. As a tool, we chose Hazelcast , which provides us with:
We went along the simplest strategy of delivering data to the cache:
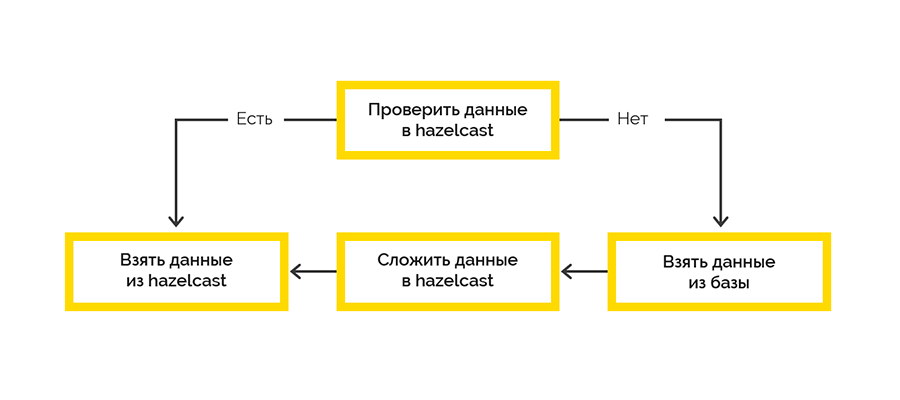
Work with the final system occurs within the framework of the sessions and there is a limit on the maximum number. If the client did not close the session, we will have to do this.
Open session data comes from the target system and is initially processed on the Lua side. We decided to use Hazelcast to save this data with a .NET writer. Then, at some intervals, we check the right to life of open sessions and close the foul.
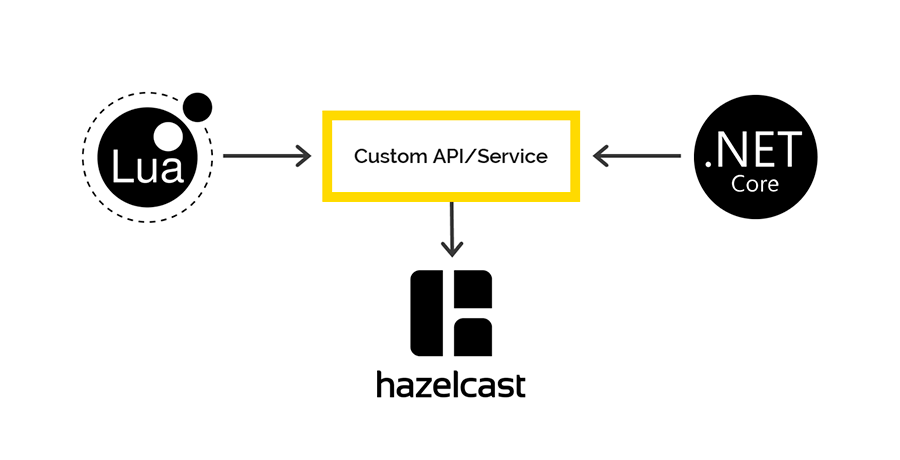
There are no clients on Lua to work with Hazelcast, but Hazelcast has a REST API, which we decided to use. For .NET, there is a client through which we planned to access Hazelcast data on the .NET side. But it was not there.

When saving data via REST and retrieving through the .NET client, different serializers / deserializers are used. Therefore, it is impossible to put data through REST, but to get through the .NET client and vice versa.
If you are interested, we will talk more about this problem in a separate article. Spoiler - on the shemka.
Our corporate standard for logging through .NET is Serilog, all logs end up in Elasticsearch, and we analyze them through Kibana. I wanted to do something similar in this case. The only client to work with Elastic on Lua that was found broke on the first require. And we used Fluentd.
Fluentd is an open source solution for providing a single application logging layer. Allows you to collect logs from different layers of the application, and then translate them into a single source.
Gateway API works in K8S, so we decided to add the container with fluentd to the same subtype to write logs to the existing open tcp port fluentd.
We also examined how fluentd would behave if he had no connection with Elasticsearch. For two days, requests were continuously sent to the gateway, logs were sent to fluentd, but IP Elastic was banned from fluentd. After reconnecting, fluentd perfectly surpassed absolutely all the logs in Elastic.
The chosen approach to implementation allowed us to deliver a really working product to the combat environment in just 2.5 months.
If you ever happen to do such things, we advise you first to clearly understand which problem you are solving and which of the resources you already have. Be aware of the complexities of integrating with existing API management systems.
Understand for yourself what exactly you are going to develop - only the business logic of request processing, or, as could be the case in our case, the whole proxy. Remember that everything you do yourself should be thoroughly tested afterwards.
For this, one API is used, which must be issued to partners through the Gateway API. We have solved this problem. This article will provide details.
Given: ecosystem and API portal with an interface where users are registered, receive information, etc. We need to make a convenient and reliable Gateway API. In the process, we needed to provide
- Registration
- API connection control
- Monitoring how users use the end system
- accounting of business indicators.
In the article, we will talk about our experience in creating the Gateway API, during which we solved the following tasks:
- user authentication
- user authorization
- modification of the original request,
- request proxying
- post-processing the response.
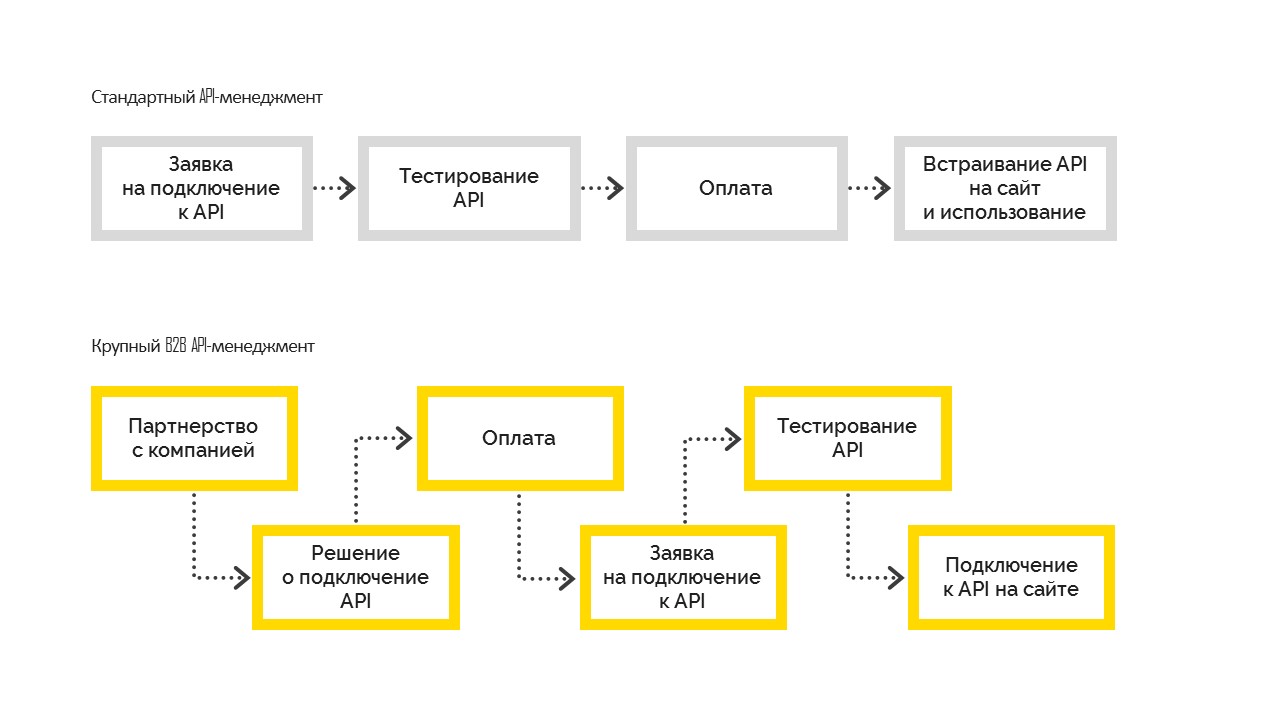
There are two types of API management:
1. Standard, which works as follows. Before connecting, the user tests the possibilities, then pays and embeds on his site. Most often it is used in small and medium-sized businesses.
2. A large B2B API Management, when the company first makes a business decision about connecting, becomes a partner company with a contractual obligation, and then connects to the API. And after settling all the formalities, the company gets test access, passes testing and goes into the sales. But this is not possible without a management decision to connect.
Our decision
In this part, we’ll talk about creating the Gateway API.
End users of the created gateway to the API are our customer’s partners. For each of them, we already have the necessary contracts. We will only need to expand the functionality, noting the granted access to the gateway. Accordingly, a controlled connection and control process is needed.
Of course, one could take some ready-made solution for solving the API Management task and creating API Gateway in particular. For example, this could be Azure API Management. It did not suit us, because in our case we already had an API portal and a huge ecosystem built around it. All users have already been registered, they already understood where and how they can get the necessary information. The necessary interfaces already existed in the API portal, we just needed the API Gateway. Actually, we started to develop it.
What we call the Gateway API is a kind of proxy. Here we again had a choice - you can write your proxy, or you can choose something ready-made. In this case, we went the second way and chose the nginx + Lua bundle. Why? We needed a reliable, tested software that supports scaling. After the implementation, we did not want to check the correctness of the business logic and the correctness of the proxy.
Any web server has a request processing pipeline. In the case of nginx, it looks like this:
(scheme from GitHub Lua Nginx )
Our goal was to integrate into this pipeline at the moment where we can modify the original request.
We want to create a transparent proxy so that the request functionally remains as it came. We only control access to the final API, we help the request to get to it. In case the request was incorrect, the final API should show the error, but not us. The only reason we can reject the request is because of the lack of access to the client.
An extension for Lua already exists for nginx. Lua is a scripting language, it is very lightweight and easy to learn. Thus, we implemented the necessary logic using Lua.
The nginx configuration (analogy to the application’s route), where all the work is done, is understandable. Noteworthy here is the last directive - post_action.
location /middleware {
more_clear_input_headers Accept-Encoding;
lua_need_request_body on;
rewrite_by_lua_file 'middleware/rewrite.lua';
access_by_lua_file 'middleware/access.lua';
proxy_pass https://someurl.com;
body_filter_by_lua_file 'middleware/body_filter.lua';
post_action /process_session;
}
Consider what happens in this configuration:
more_clear_input_headers - clears the value of the headers specified after the directive.
lua_need_request_body - controls whether to read the source body of the request before executing the rewrite / access / access_by_lua directives or not. By default, nginx does not read the client request body, and if you need to access it, this directive should be set to on.
rewrite_by_lua_file - the path to the script, which describes the logic for modifying the request
access_by_lua_file - the path to the script, which describes the logic that checks for access to the resource.
proxy_pass - url to which the request will be proxied.
body_filter_by_lua_file- the path to the script, which describes the logic for filtering the request before returning to the client.
And finally, post_action is an officially undocumented directive that can be used to perform any other actions after the response is given to the client.
Next, we will describe in order how we solved our problems.
Authorization / authentication and request modification
Authorization
We built authorization and authentication using certificate accesses. There is a root certificate. Each new client of the customer generates his personal certificate with which he can access the API. This certificate is configured in the nginx settings server section.
ssl on;
ssl_certificate /usr/local/openresty/nginx/ssl/cert.pem;
ssl_certificate_key /usr/local/openresty/nginx/ssl/cert.pem;
ssl_client_certificate /usr/local/openresty/nginx/ssl/ca.crt;
ssl_verify_client on;Modification
A fair question may arise: what to do with a certified client if we suddenly want to disconnect it from the system? Do not reissue certificates for all other clients.
So we smoothly and approached the next task - modification of the original request. The original client request, generally speaking, is not valid for the final system. One of the tasks is to add the missing parts to the request in order to make it valid. The point is that the missing data is different for each client. We know that the client comes to us with a certificate from which we can take a fingerprint and extract the necessary client data from the database.
If at some point you need to disconnect the client from our service, his data will disappear from the database and he will not be able to do anything.
Work with customer data
We needed to ensure high availability of the solution, especially how we get customer data. The difficulty is that the source of this data is a third-party service that does not guarantee uninterrupted and fairly high speed.
Therefore, we needed to ensure high availability of customer data. As a tool, we chose Hazelcast , which provides us with:
- quick access to data
- the ability to organize a cluster of several nodes with data replicated on different nodes.
We went along the simplest strategy of delivering data to the cache:
Work with the final system occurs within the framework of the sessions and there is a limit on the maximum number. If the client did not close the session, we will have to do this.
Open session data comes from the target system and is initially processed on the Lua side. We decided to use Hazelcast to save this data with a .NET writer. Then, at some intervals, we check the right to life of open sessions and close the foul.
Access to Hazelcast from both Lua and .NET
There are no clients on Lua to work with Hazelcast, but Hazelcast has a REST API, which we decided to use. For .NET, there is a client through which we planned to access Hazelcast data on the .NET side. But it was not there.
When saving data via REST and retrieving through the .NET client, different serializers / deserializers are used. Therefore, it is impossible to put data through REST, but to get through the .NET client and vice versa.
If you are interested, we will talk more about this problem in a separate article. Spoiler - on the shemka.
Logging and Monitoring
Our corporate standard for logging through .NET is Serilog, all logs end up in Elasticsearch, and we analyze them through Kibana. I wanted to do something similar in this case. The only client to work with Elastic on Lua that was found broke on the first require. And we used Fluentd.
Fluentd is an open source solution for providing a single application logging layer. Allows you to collect logs from different layers of the application, and then translate them into a single source.
Gateway API works in K8S, so we decided to add the container with fluentd to the same subtype to write logs to the existing open tcp port fluentd.
We also examined how fluentd would behave if he had no connection with Elasticsearch. For two days, requests were continuously sent to the gateway, logs were sent to fluentd, but IP Elastic was banned from fluentd. After reconnecting, fluentd perfectly surpassed absolutely all the logs in Elastic.
Conclusion
The chosen approach to implementation allowed us to deliver a really working product to the combat environment in just 2.5 months.
If you ever happen to do such things, we advise you first to clearly understand which problem you are solving and which of the resources you already have. Be aware of the complexities of integrating with existing API management systems.
Understand for yourself what exactly you are going to develop - only the business logic of request processing, or, as could be the case in our case, the whole proxy. Remember that everything you do yourself should be thoroughly tested afterwards.