Architectural Template “Macro Shared Transactions for Microservices”
- Tutorial

Posted by Denis Tsyplakov , Solution Architect, DataArt
Formulation of the problem
One of the problems when building microservice architectures and especially when migrating a monolithic architecture to microservices is often transactions. Each microservice is responsible for its own group of functions, possibly controls the data associated with this group, and can serve user requests either autonomously or by sending requests to other microservices. All this works fine until we need to ensure the consistency of the data that is controlled by different microservices.
For example, our application works in some large online store. Among other things, we have three separate, weakly interconnected business areas:
- Warehouse - what, where, how and for how long it has been stored, how many goods of a certain type are currently in stock, etc.
- Sending goods - packaging, shipping, tracking of delivery, analysis of complaints about its delay, etc.
- Conducting customs reporting on the movement of goods if the goods are sent abroad (in fact, I do not know if in this case it is necessary to draw up something specially, but still I’ll connect the state services to the process to add drama).
Each of these three areas includes many disjoint functions and can be represented as several microservices.
There is one problem. Suppose a person bought a product, packed it and sent it by courier. Among other things, we need to indicate that there is one less unit of goods in the warehouse, to note that the process of goods delivery has begun, and if the goods are sent, say, to China, to take care of the papers for customs. If the application crashes (for example, a node crashes) at the second or third stage of the process, our data will come to an inconsistent state, and only a few such failures can lead to quite unpleasant problems for the business (for example, a visit by customs officers).
In a classical monolithic architecture of this kind, the problem is simply and elegantly solved by transactions in the database. But what if we use microservices? Even if we use the same database from all services (which is not very elegant, but in our case it is possible), working with this database comes from different processes, and we won’t be able to stretch the transaction between the processes.
Solutions
The problem has several solutions:
- Oddly enough, sometimes the problem can be ignored. If we know that a failure does not occur more than once a month, and manual elimination of the consequences costs money acceptable for the business, you can not pay attention to the problem, no matter how ugly it may look. I don’t know whether it is possible to ignore the claims of the customs service, but it can be assumed that in certain circumstances even this is possible.
- Compensation (this is not about monetary compensation to customs, for example, you paid a fine) is a group of various steps that complicate the processing sequence, but allow you to detect and process a failed process. For example, before starting the operation, we write to a special service that we are starting the shipment operation, and at the end we mark that everything ended well. Then we periodically check to see if there are any pending operations, and if there are any, looking at all three databases, we try to bring the data to a consistent state. This is a completely working method, but it significantly complicates the processing logic, and doing so for each operation is quite painful.
- Two-phase transactions, strictly speaking, the XA + specification, which allows you to create transactions that are distributed relative to applications, is a very heavyweight mechanism that few people like and, more importantly, few people can configure. In addition, with lightweight microservices, it is ideologically weakly compatible.
- In principle, a transaction is a special case of a consensus problem, and numerous distributed consensus systems can be used to solve the problem (roughly speaking, everything that is google with the keywords paxos, raft, zookeeper, etcd, consul). But in practical application for extensive and ramified data of warehouse activity, all this looks even more complicated than two-phase transactions.
- Queues and eventual consistency (consistency in the long run) - we divide the task into three asynchronous tasks, sequentially process the data, passing them between the services from the queue to the queue, and use the delivery confirmation mechanism. In this case, the code is not very complicated, but there are a few points to keep in mind:
- The queue guarantees delivery "one or more times", that is, when re-delivering the same message, the service must correctly handle this situation, and not ship the goods twice. This can be done, for example, through the unique UUID of the order.
- Data at any given time will be slightly inconsistent. That is, the goods will first disappear from the warehouse and only then, with a slight delay, an order for its dispatch will be created. Later, customs data will be processed. In our example, this is completely normal and does not cause problems for the business, but there are cases when such data behavior can be very unpleasant.
- If, as a result, the very first service has to return some data to the user, the sequence of calls that ultimately delivers the data to the user's browser can be quite non-trivial. The main problem is that the browser sends requests synchronously and usually expects a synchronous response. If you do asynchronous request processing, then you need to build asynchronous delivery of the response to the browser. Classically, this is done either through web sockets, or through periodic requests for new events from the browser to the server. There are mechanisms, such as SocksJS, for example, which simplify some aspects of building this link, but there will still be additional complexity.
In most cases, the latter option is most acceptable. It does not greatly complicate the processing request, although it works several times longer, but, as a rule, this is acceptable for this kind of operation. It also requires a slightly more complex data organization to cut off repeated requests, but there is nothing super complicated about this either.
Schematically, one of the options for processing transactions using queues and Eventual consistency may look like this:
- The user made a purchase, a message about this is sent to the queue (for example, a RabbitMQ cluster or, if we work in the Google Cloud Platform - Pub / Sub). The queue is persistent, guarantees delivery one or more times, and is transactional, that is, if the service processing the message suddenly drops, the message will not be lost, but will be delivered to a new instance of the service again.
- The message arrives to the service, which marks the goods in the warehouse as being prepared for shipment and in turn sends the message “The goods are ready for shipment” to the queue.
- At the next step, the service responsible for the dispatch receives a message about readiness for dispatch, creates a dispatch task, and then sends a message “dispatch of goods is planned”.
- The next service, having received a message that the dispatch is planned, starts the process of paperwork for customs.
Moreover, each message received by the service is checked for uniqueness, and if a message with such a UUID has already been processed, it is ignored.
Here, the database base (s) at each moment of time is in a slightly inconsistent state, that is, the goods in the warehouse are already marked as being in the delivery process, but the delivery task itself is not yet there, it will appear in a second or two. But at the same time, we have 99.999% (in fact, this number is equal to the level of reliability of the queue service) guarantees that the sending task will appear. For most businesses, this is acceptable.
What is the article about then?
In the article I want to talk about another way to solve the transactionality problem in microservice applications. Despite the fact that microservices work best when each service has its own database, for small and medium-sized systems, all data, as a rule, easily fits into a modern relational database. This is true for almost any internal enterprise system. That is, we often do not have a strict need to share data between different physical machines. We can store data from different microservices in unrelated groups of tables of the same database. This is especially convenient if you are dividing an old, monolithic application into services and have already divided the code, but the data still lives in the same database. However, the problem of transaction splitting still remains - the transaction is rigidly tied to a network connection and, accordingly, the process that opened this connection, and the processes we have are divided. How to be
Above, I described several common ways to solve the problem, but further I want to offer another way for a special case, when all the data is in the same database. I do not recommend trying to implement this method in this project , but it is curious enough for me to present it in the article. Well, all of a sudden it will come in handy in some special case.
Its essence is very simple. A transaction is associated with a network connection, and the database does not really know who is sitting on that end of the open network connection. She doesn’t care, the main thing is that the correct commands are sent to the socket. It is clear that usually a socket belongs exclusively to one process on the client side, but I see at least three ways to get around this.
1. Change the database code
At the database code level for databases, the code of which we can change, making our own database assembly, we implement the mechanism for transferring transactions between connections. How it can work from the point of view of the client:
- We start the transaction, make some changes, it is time to transfer the transaction to the next service.
- We tell the DB to give us the UUID of the transaction and wait N seconds. If during this time another connection with this UUID does not come, roll back the transaction, if it does, transfer all the data structures associated with the transaction to the new connection and continue working with it.
- We pass the UUID to the next service (i.e., to another process, possibly to another VM).
- In it, open a connection and give the DB command - continue the transaction with the specified UUID.
- We continue to work with the database as part of a transaction started by another process.
This method is the most lightweight to use, but requires modification of the database code, application programmers usually do not do this, it requires a lot of special skills. Most likely, it will be necessary to transfer data between the database processes, and databases, the code of which we can safely change by and large, one - PostgreSQL. In addition, this will work only for unmanaged servers, you won’t go with it in RDS or Cloud SQL.
Schematically, it looks like this:

2. Manipulation of sockets
The second thing that comes to mind is the subtle manipulation of database connections by sockets. We can make some “Reverse socket proxy”, which directs the commands coming from several clients to a specific port in one command stream to the database.
In fact, this application is very similar to pgBouncer, only, in addition to its standard functionality, doing some manipulations with the byte stream from clients and being able to substitute one client instead of another on command.
I strongly dislike this method, for its implementation it is necessary to clean up the binary packets circulating between the server and clients. And it still requires a lot of system programming. I brought it solely for completeness.
3. Gateway JDBC
We can make a gateway JDBC driver - we take the standard JDBC driver for a specific database, let it be PostgreSQL. We wrap the class and make HTTP interfaces to all its external methods (not HTTP, but the difference is small). Next, we make another JDBC driver - a facade, which redirects all method calls to the JDBC gateway. That is, in fact, we are sawing the existing driver into two halves and connecting these halves over the network. We get the following component diagram:
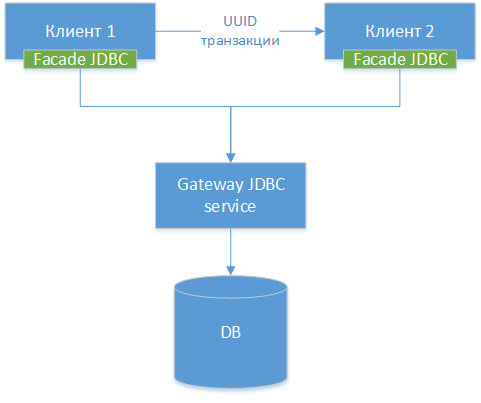
NB !: As we can see, all three options are similar, the only difference is at what level we transfer the connection and what tools we use for this.
After that, we teach our driver to do essentially the same trick with the UUID transaction that is described in method 1.
In Java application code, using this method might look like this.
Service A - start of transaction
Below is the code for some service that starts a transaction, makes changes to the database and passes it on to another service to complete it. In the code, we use direct work with JDBC classes. Of course, no one does this in 2019, but for the sake of simplicity, the code is simplified.
// В реальном приложении мы, конечно, соединение “руками”
// не открываем
Class.forName("org.postgresql.FacadeDriver");
var connection = DriverManager.getConnection(
"jdbc:postgresqlfacade://hostname:port/dbname","username", "password");
// Делаем какие-то изменения в БД
statement = dbConnection.createStatement();
var statement.executeUpdate(“insert ...”);
/* Все, мы сделали изменения и готовы передать транзакцию дальше.
transactionUUID(int) Это псевдо-функция, до БД она не доходит, а
обрабатывается JDBC gateway-сервисом. В ResultSet возвращается
единственная строка с одним полем типа Varchar, содержащим UUID.
После выполнения этого запроса соединение блокируется и на
все запросы возвращает ошибку. Чтобы его разблокировать, надо
дать команду на возобновления транзакции с данным UUID.
Число 60 — это таймаут, после которого транзакция откатывается.
В реальных приложениях такие запросы делаются с помощью, например,
JDBCTemplate. Здесь для иллюстративности у меня ResultSet
*/
var rs = statement.executeQuery(“select transactionUUID(60)”);
String uuid = extractUUIDFromResultSet(rs);
// передаем дальнейшую обработку удаленному сервису
remoteServiceProxy.continueProcessing(uuid, otherParams);
// Больше в рамках этого соединения никаких операций совершать нельзя
// освобождаем все ресурсы и выходим.
closeEverything();
return;
Service B - transaction completion
// Здесь мы продолжаем с места, где был вызван метод
// remoteServiceProxy.continueProcessing(...)
// Точно так же открываем соединение.
Class.forName("org.postgresql.FacadeDriver");
var connection = DriverManager.getConnection(
"jdbc:postgresqlfacade://hostname:port/dbname","username", "password");
// Теперь нам надо сказать Gateway JDBC, что мы продолжаем
// транзакцию. Команда continue transaction не идет в БД, а обрабатывается
// gateway JDBC
statement = dbConnection.createStatement();
statement.executeUpdate(“continue transaction ”+uuid);
// Все, мы подсоединились к транзакции, стартовавшей в другом сервисе и
// можем продолжать наполнять базу данными
statement.executeUpdate(“update ...");
// Завершаем транзакцию
connection.commit();
return;Interaction with other components and frameworks
Consider the possible side effects of such an architectural solution.
Connection pool
Since in reality we will have a real connection pool inside the JDBC gateway - it is better to turn off the connection pools in services, since they will capture and hold a connection inside the service that could be used by another service.
Plus, after receiving the UUID and waiting for the transfer to another process, the connection essentially becomes inoperative, and from the point of view of the frontend JDBC, it closes automatically, and from the point of view of the gateway JDBC, it must be held without giving to anyone other than who will come with the desired UUID.
In other words, the dual management of the connection pool in the Gateway JDBC and within each of the services can produce subtle, unpleasant errors.
Jpa
With JPA, I see two possible problems:
- Transaction management. When committing a JPA, the engine may think that it has saved all the data, while it has not been saved. Most likely, manual transaction management and flush () before transferring the transaction should solve the problem.
- The second-level cache is likely to work incorrectly, but in distributed systems its use is limited in any case.
Spring transactions
The Spring transaction management mechanism, perhaps, cannot be activated, and you will have to manage them manually. I’m almost sure that it can be expanded - for example, to write custom scope - but to say for sure, we need to study how the Spring Transactions extension is arranged there, but I have not looked there yet.
Pros and cons
pros
- Practically does not require modification of the existing monolithic code when sawing.
- You can write complex cross-server transactions with virtually no code complexity.
- Allows you to do cross-service trace of transaction execution.
- The solution is quite flexible, you can use classic transactions where distribution is not required and share the transaction only for those operations where cross-service interaction is required.
- The project team is not required to forcibly master new technologies. New technologies are, of course, good, but the task - it is imperative and urgent (until yesterday!) To teach 20 developers the concept of building reactive systems - can be very nontrivial. However, there is no guarantee that all 20 people will complete the training on time.
Minuses
- Unscalable and, in fact, non-modular at the database level, in contrast to a queued solution. You still have one database into which all the queries and the entire load converge. In this sense, the solution is dead-end: if you later want to increase the load or make the solution modular according to the data, you will have to redo everything.
- You must be very careful in transferring a transaction between processes, especially processes written in frameworks. Sessions have their own settings, and for various frameworks, a sudden change in connection with the database can lead to incorrect operation. See, for example, session settings and transactions for PostgreSQL.
- When I told the idea in our local architect’s chat on DataArt, the first thing my colleagues asked me was whether I was drinking (no, not drinking!). But I admit that the idea, let’s say, is not the most widespread one, and if you implement it in your project, it will look very unusual for its other participants.
- Requires a custom JDBC driver. Writing it takes time, you have to debug it, look for errors in it, including those caused by network communication errors, etc.
Warning
I warn you again: do not try to repeat this trick
All from the first of April!