The use of machine learning to analyze a large number of respondent feedback
Any modern company cares about its reputation. Phrases: “Your opinion is very important for us” or “Rate your purchase”, “Would you recommend our company?” Literally haunt us at every step on the sites of stores, clinics and even the State service. Government agencies along with other companies have become interested in evaluating their work and are also paying attention to this. Medical facilities will not renew contracts with specialists who have been negatively prevailing for a long time. Service providers are trying to constantly monitor the reaction of consumers to goods and services in order to make their service more accessible and quality, and therefore competitive. Opinion helps other consumers understand an institution, institution, product or service before how it will be acquired and thereby avoids mistakes in purchases. Large companies without fail contain in their staff structures to combat the outflow of customers, PR departments, in which the key factor is the timely response to consumer requests. How to build the work of such structures without increasing costs and increasing their response speed? As one example, let us consider the use of machine learning for the operational analysis of a large number of respondent responses. How to build the work of such structures without increasing costs and increasing their response speed? As one example, let us consider the use of machine learning for the operational analysis of a large number of respondent responses. How to build the work of such structures without increasing costs and increasing their response speed? As one example, let us consider the use of machine learning for the operational analysis of a large number of respondent responses.
To begin, consider an example that demonstrates the features of the modern UX / UI approach to user interface development. Suppose you are the owner of a multinational service company worldwide.

After each purchase, you ask your customers to leave feedback about your product. Technically, your current software is organized in such a way that no matter what language the users leave feedback, they indiscriminately fall into the "basement" of the product. The problem arises of how to determine in which language a review is left, what is its tonality, and in the best case, translate it into several languages and demonstrate a suitable translation of all reviews for the current user in his native language, regardless of the original language.
If you contact your developer now, then most likely you will be offered an option in which the task of choosing the language will be entrusted to the user. This will probably look like this. The

user will be asked to select a language from a long list, and sometimes languages are listed without translation, which in turn confuses the user. It looks something like

this. Based on the fact that most users speak two languages, then only two lines will be clear to them, those, in fact, the choice turns into "torture".
Another, no less common approach that they can offer you is the definition of a region by IP address and, as a result, the most likely common language. The conditions of modern globalization are not the best approach, to indicate its shortcomings, it is enough to note the importunity of modern software in relation to the region of your location, only residents of Moscow were lucky in this regard, most likely their region is always determined correctly.
One of the elegant ways to solve such problems can be machine learning. Currently, this does not even need to be profoundly proficient in mathematics. For example, it’s enough to use the MS Azure Cognitive Service,

which by the entered phrase will allow you to determine a number of indicators of the entered text, including language, key phrases and its tonality. For the case under consideration, this gives the following simplification of the interface.

It is no longer necessary to request the input language and user rating - these facts follow automatically. After that, the task of distributing calls to regional branches, as well as monitoring the outflow of customers is greatly simplified

A significant part of the effort is shifted from the user and employees to a machine that does not get tired, works quickly and is much less mistaken in mechanical aspects.

First of all, you need to connect to the MS Azure Cognitive Service and get access to an API that analyzes the given text and return its characteristics. This process is not complicated and will be discussed in more detail in a separate article. There

are two ways to access the API using an HTTP request and using a client. In particular, for .net you need to connect the package,
then call the API
and parse the received answer
If we write the received data in the database, we get the following
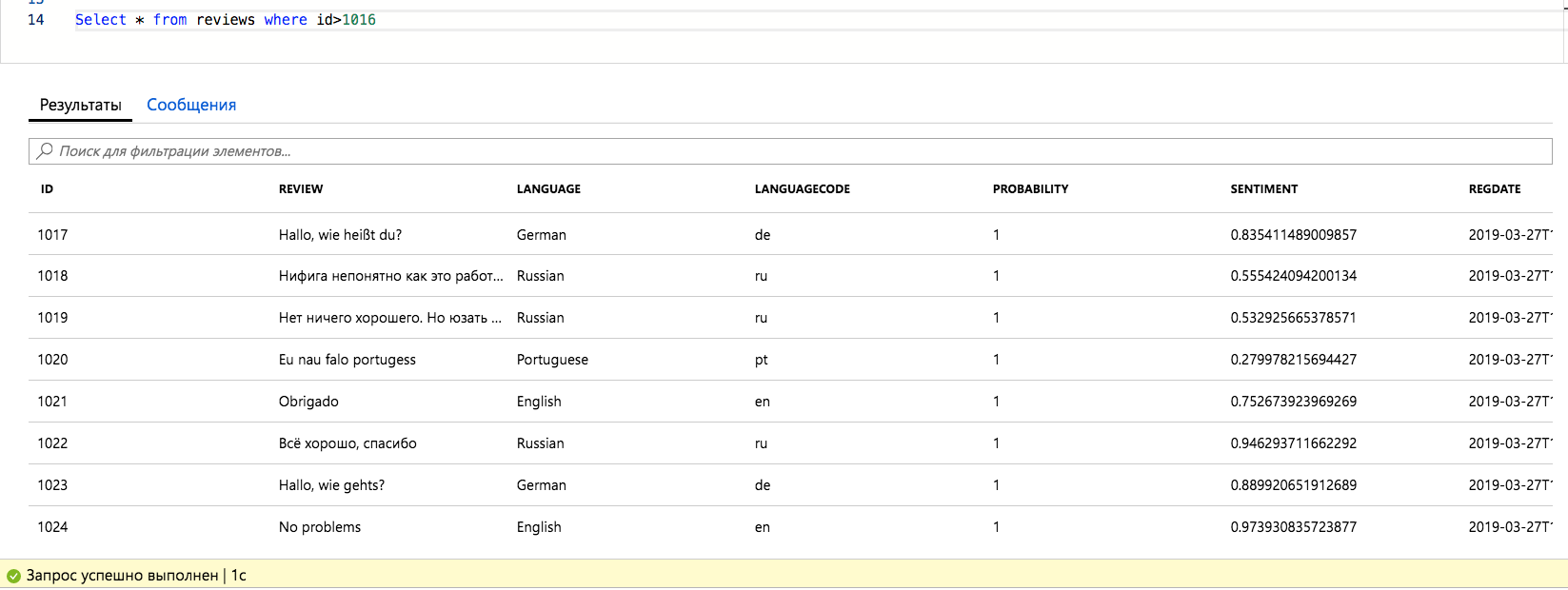
(Example added after user comment on the article)

We will analyze the results, for this we will build several reports, using the FastReport software package which has an open-source version of
youtu.be/Tyu7v24zer0
included in the delivery. We enable sorting by tonality (1-positive, 0-negative); we get positive reviews grouped at the top and negative ones grouped at the bottom .
youtu.be/HbuXMuDZFmo
If necessary, you can group reviews by language and send relevant reports to the regional offices of
youtu.be/YF8RG3g5FRs
New technologies not only significantly improve the user interface, but also optimize the work of employees, reduce development costs. Refuse costly modifications to existing software. The prospects for machine learning in the near future will significantly improve the quality of software and user satisfaction. The use of easily implemented reporting solutions will allow more users to access data without heavy programming.
github.com/ufocombat/Languages-open
azure.microsoft.com/en-us/services/cognitive-services/text-analytics
www.fast-report.com/en
youtu.be/Tyu7v24zer0
youtu.be/HbuXMuDZFmo
youtu.be / YF8RG3g5FRs
Multilingualism
To begin, consider an example that demonstrates the features of the modern UX / UI approach to user interface development. Suppose you are the owner of a multinational service company worldwide.
After each purchase, you ask your customers to leave feedback about your product. Technically, your current software is organized in such a way that no matter what language the users leave feedback, they indiscriminately fall into the "basement" of the product. The problem arises of how to determine in which language a review is left, what is its tonality, and in the best case, translate it into several languages and demonstrate a suitable translation of all reviews for the current user in his native language, regardless of the original language.
If you contact your developer now, then most likely you will be offered an option in which the task of choosing the language will be entrusted to the user. This will probably look like this. The
user will be asked to select a language from a long list, and sometimes languages are listed without translation, which in turn confuses the user. It looks something like
this. Based on the fact that most users speak two languages, then only two lines will be clear to them, those, in fact, the choice turns into "torture".
Another, no less common approach that they can offer you is the definition of a region by IP address and, as a result, the most likely common language. The conditions of modern globalization are not the best approach, to indicate its shortcomings, it is enough to note the importunity of modern software in relation to the region of your location, only residents of Moscow were lucky in this regard, most likely their region is always determined correctly.
Machine learning
One of the elegant ways to solve such problems can be machine learning. Currently, this does not even need to be profoundly proficient in mathematics. For example, it’s enough to use the MS Azure Cognitive Service,
which by the entered phrase will allow you to determine a number of indicators of the entered text, including language, key phrases and its tonality. For the case under consideration, this gives the following simplification of the interface.
It is no longer necessary to request the input language and user rating - these facts follow automatically. After that, the task of distributing calls to regional branches, as well as monitoring the outflow of customers is greatly simplified
A significant part of the effort is shifted from the user and employees to a machine that does not get tired, works quickly and is much less mistaken in mechanical aspects.
Cognitive service
First of all, you need to connect to the MS Azure Cognitive Service and get access to an API that analyzes the given text and return its characteristics. This process is not complicated and will be discussed in more detail in a separate article. There
are two ways to access the API using an HTTP request and using a client. In particular, for .net you need to connect the package,
then call the API
var httpWebRequest = (HttpWebRequest)WebRequest.Create("https://northeurope.api.cognitive.microsoft.com/text/analytics/v2.0/languages");
httpWebRequest.Method = "POST";
httpWebRequest.Headers.Add("Content-Type:application/json");
httpWebRequest.Headers.Add("Ocp-Apim-Subscription-Key:61...");
var documents = new Documents();
documents.Add(new Document(Description));
using (var streamWriter = new StreamWriter(httpWebRequest.GetRequestStream()))
{
string json = JsonConvert.SerializeObject(documents);
streamWriter.Write(json);
streamWriter.Flush();
streamWriter.Close();
}
and parse the received answer
var httpResponse = (HttpWebResponse)httpWebRequest.GetResponse();
String response;
using (var streamReader = new StreamReader(httpResponse.GetResponseStream(), Encoding.UTF8))
{
response = streamReader.ReadToEnd();
}
var result = JsonConvert.DeserializeObject(response);
var doc = result.documents[0].detectedLanguages[0];
If we write the received data in the database, we get the following
(Example added after user comment on the article)
Results Analysis
We will analyze the results, for this we will build several reports, using the FastReport software package which has an open-source version of
youtu.be/Tyu7v24zer0
included in the delivery. We enable sorting by tonality (1-positive, 0-negative); we get positive reviews grouped at the top and negative ones grouped at the bottom .
youtu.be/HbuXMuDZFmo
If necessary, you can group reviews by language and send relevant reports to the regional offices of
youtu.be/YF8RG3g5FRs
Conclusion
New technologies not only significantly improve the user interface, but also optimize the work of employees, reduce development costs. Refuse costly modifications to existing software. The prospects for machine learning in the near future will significantly improve the quality of software and user satisfaction. The use of easily implemented reporting solutions will allow more users to access data without heavy programming.
References
github.com/ufocombat/Languages-open
azure.microsoft.com/en-us/services/cognitive-services/text-analytics
www.fast-report.com/en
youtu.be/Tyu7v24zer0
youtu.be/HbuXMuDZFmo
youtu.be / YF8RG3g5FRs