What else can be done in the search? Yandex Report
Yandex has a search component development service that builds a search base on MapReduce, provides data for typesetting for rendering, generates algorithms and data structures, and solves ML-tasks of quality growth. Alexey Shlyunkin, the head of one of the groups within this service, explains what the search runtime consists of and how we manage it.
- What is a search today? Yandex began by doing a search, developing it. 20 years have passed. We have a search base for hundreds of billions of documents.
We call a document any page on the Internet, but, in fact, not only it. Still - its contents, various statistics about which users like to go to it, how many of them. Plus the data we calculated.
They are also tens of thousands of instances that, in response to each request, process data, search for something, enrich the search response. Some instances are looking for pictures, some for ordinary text documents, some for video, etc. That is, tens of thousands of machines are activated for your every request. They all try to find something and improve the result that is shown to you. Accordingly, tens of thousands of machines serve thousands of requests per second. These tens of thousands of instances are combined into hundreds of services designed to solve a problem.

There is a search core - a web search service. And there is a video search service, etc. Accordingly, there is a thing that combines the answers of different searches and tries to choose what and in which order it is better to show the user. If this is some kind of request about music, then it is probably better to show Yandex.Music first, and then, for example, a page about this music group. This is called a blender. There are already hundreds of such services, and they also do something for every request and try to help users somehow. And, of course, this all uses machine learning of just all sorts, from some simple statistics, linear models, to gradient boostings, neural networks and so on.
I will talk about infrastructure and ML right now.
My group is called the new runtime development group, it is part of the search component development service. So that you have an idea, I’ll tell you a little what our service does.

In fact, to everyone. If you submit a search, then we launched our hands into almost everything, starting from building a search base. That is, we have MapReduce, we collect all the data about documents there, boil it, build all kinds of data structures, so that when we query them, we can efficiently calculate something. Accordingly, we work from the bottom when the document just gets to us, from the first stage, when these documents get something and rank it, and to the very top, where the layout receives conditional JSON and draws it with all the pictures and beautiful things. From bottom to top, we are developing something on the entire stack.
But we are not only writing code and, accordingly, we are doing all this in infrastructure. We are actually training neural networks, CatBoost. And other ML things that you can imagine and burn, we also teach. Also, since we have big loads, big data, we, of course, rummage through algorithms and data structures and never restrain ourselves from introducing them somewhere. For example, in several places we use segment trees. We have our own compression of indices that build boron and according to it consider the dynamics of how best to build dictionaries.
In general, dealing with such a large colossus as a search, we were saturated with such simple tasks. Therefore, we, of course, adore something complex, new, something that challenges us. And we did not just go and write, as usual, ten lines of code. We need to think about some experiments. In general, the tasks that we set ourselves are often on the verge of fiction. Sometimes you think: it's probably not possible. But then you, perhaps, somehow experimented - experiments can take a whole year - but in the end something turns out. Then we begin to introduce, remake something.
And besides any projects, skills, and so on, in general, we are one of the most ambitious and fast-growing teams in Yandex. For example, I came two years ago, was the ninth person in our service. Now we have a service of almost 60 people. This is, in fact, with the interns, but, in general, four times we have grown exactly in two years. This is to give you an idea of what our service is doing.
Now I want to tell you a bit about the top about our tasks and the direction that, it seems to me, in the near future we will be more and more relevant. But for this, you must first briefly describe how the most basic search layer works.
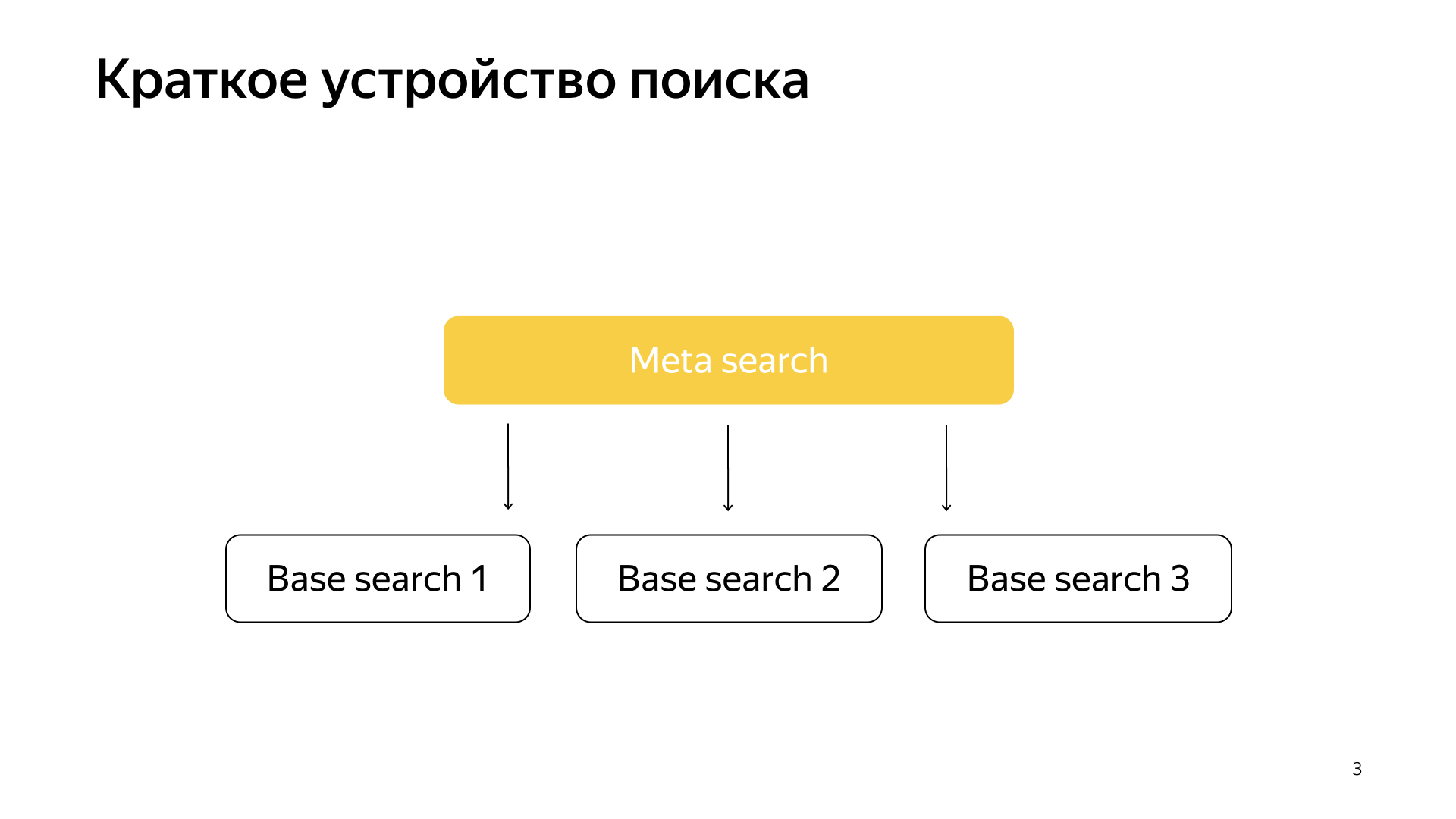
Generally speaking, everything works very simply. We have our search base, we have all the documents, and we divide all these documents more or less evenly into N pieces. They are called shards. And a program called “Basic Search” is launched over the shard. Her task is to search, accordingly, on this piece of the Internet. That is, she knows how to search for it and knows nothing more about the other Internet. And we have N shards like that. Basic searches are launched above them, and, accordingly, there is a meta search over this. The user's request falls into it and, accordingly, it simply goes to all shards, and each shard performs a search, then each returns a result, and it performs some kind of merge and gives an answer.
That’s how the search was arranged for almost all 20 years, and, in general, for a long time they thought that this would remain so, and nothing better could be done. But everything is changing, new technologies are emerging, and machine learning now not only allows you to increase quality, but also allows you to solve some kind of infrastructure problems. Recently, in our search, projects have been shot very much, right at the junction of infrastructure and machine learning. When two such mastodons merge, very interesting results are obtained.

Recently, neural networks have appeared. We have the text of the request, there is the text of the document. We want to get some vector of numbers from the request, to get some vector of numbers from the document so that the scalar product predicts the value that we want. For example, we want to train the scalar product to predict the probability of a user clicking on this document. Quite an understandable thing.
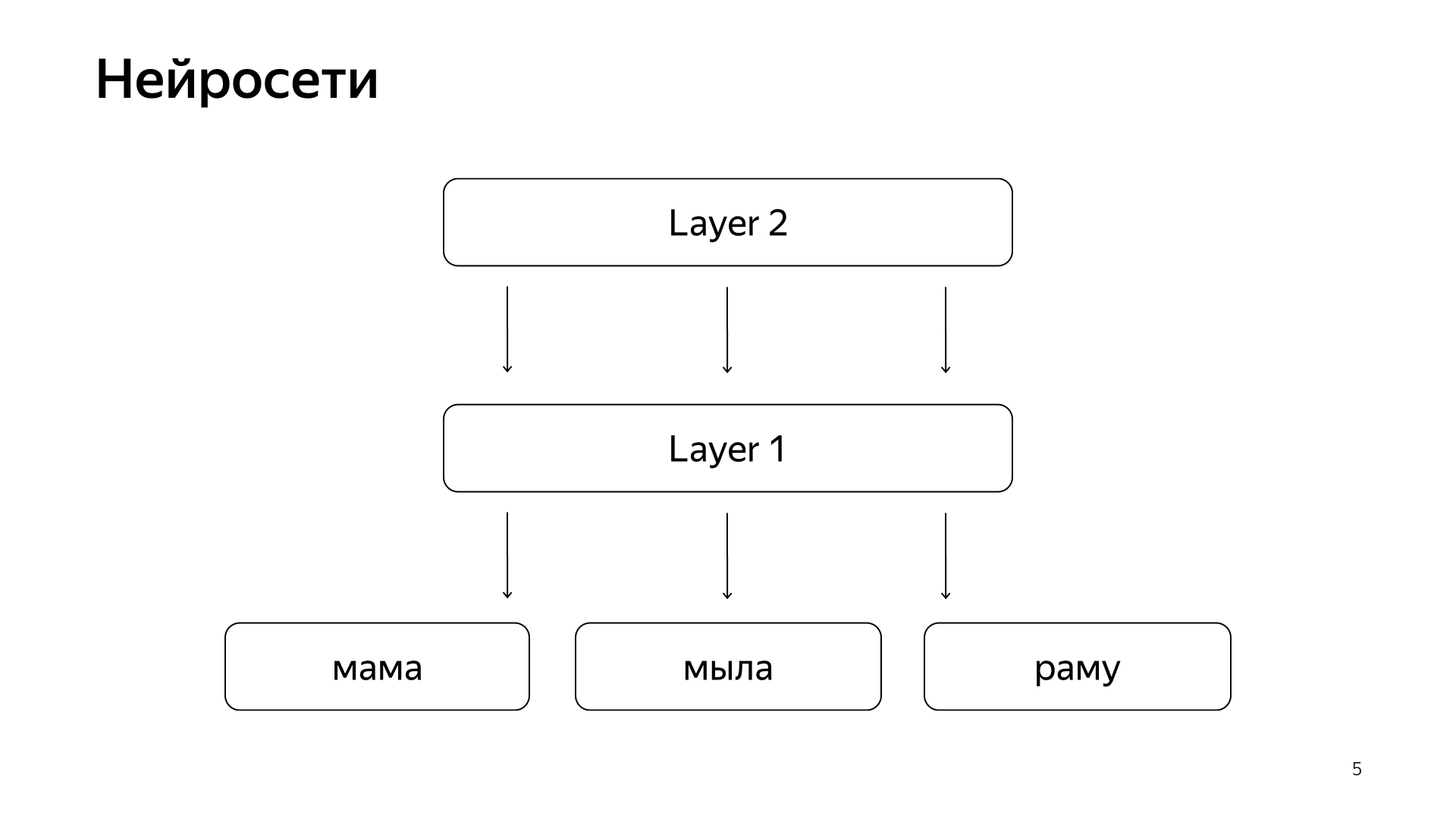
It is arranged approximately like this. If very, very rude, then we have some words on the bottom layer, and then there are several layers of the network. Each layer, in fact, takes a vector as its input. That is, the bottom layer is such a sparse vector, where each word is a request. Multiplies it by a matrix, gets some kind of vector, and then, accordingly, applies some nonlinearity to each component, and it does this several times. And the last layer, this is called just the vector that we just took the request, applied such layers, and here the last layer is the very request vector.
Accordingly, these neural networks have been actively introduced into the search in recent years, they brought a lot of benefits for quality. But they have one problem in that all the quantities that we want to predict are good, but rough enough, because in order to train such a neural network, the bottom layer is very large - all words are from tens of millions of words, so you need to be able to write her input several billion data.
For example, we can train on some user clicks, and so on. But the main signal that is considered the most important in our search is manual marking by special people. They take the request, take the document, read it, understand how good it is and put a mark, that is, how much this document fits this request. For a long time, we could not predict such a magnitude by neural networks, because we still have millions of estimates, because hiring the entire planet to constantly mark it all up is very expensive. Therefore, we made some hack.
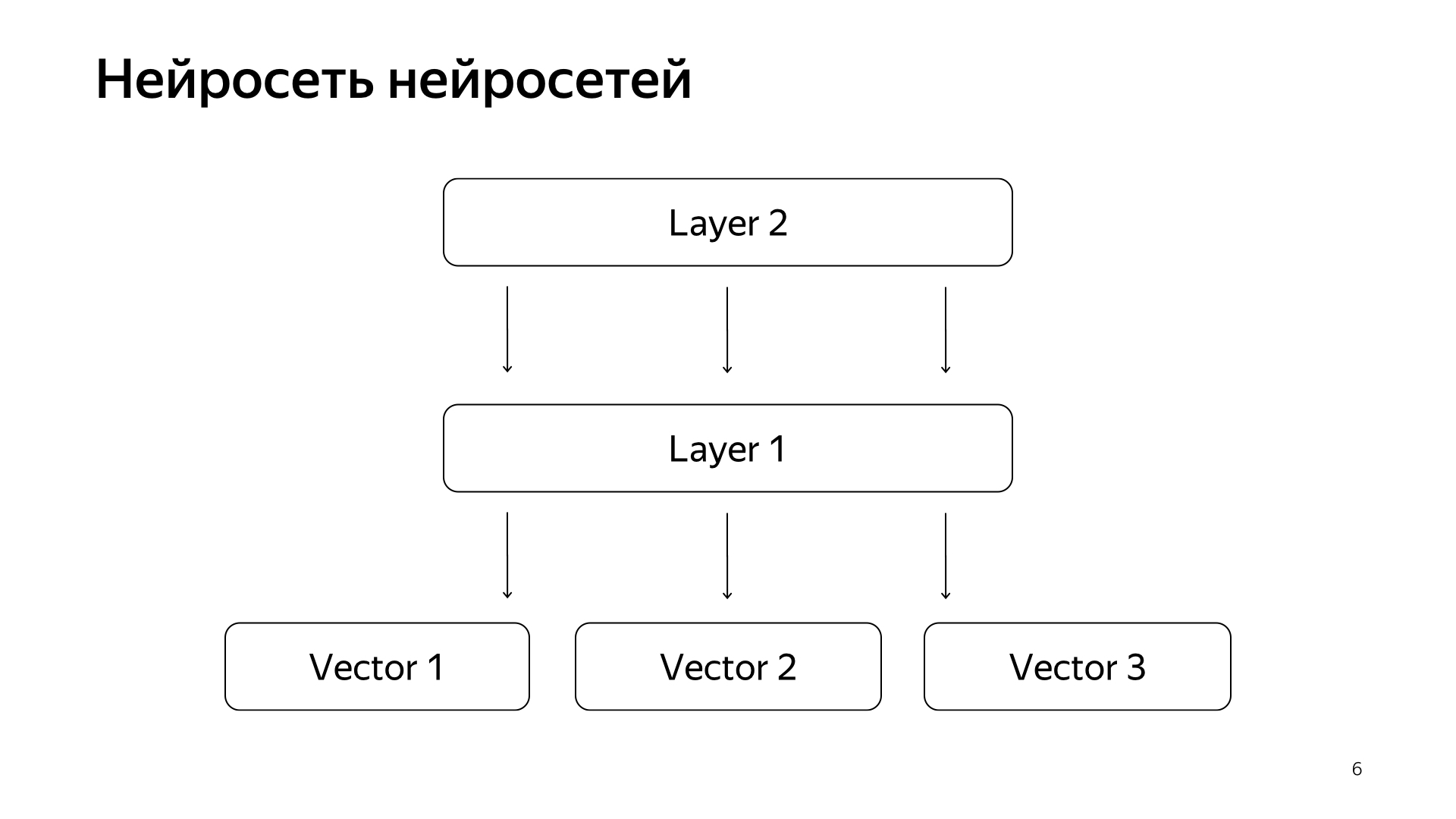
Neural network of neural networks. Over the past years, we have accumulated quite a lot of some neural networks that predict good signals, but a little rougher than the assessment of special people. Accordingly, we decided that we would submit the ready-made vectors of these networks to the lower layer, and then we will train the neural network to predict our search relevance on the smaller data network.
The result was a very good model. She brings the requests of documents into a vector, and their scalar product directly predicts the real relevance that we have long wanted to predict.
Further, we had an idea how to redo the search a bit. The project is called a KNN base (English k-nearest neighbors, k-nearest neighbors method).

The basic idea is this. We have a query vector and a document vector. We need to find the nearest one. We have each document represented by a vector. Let's highlight N clusters, those that characterize the entire document space. Roughly speaking. Strongly smaller than the number of documents, but for example, they characterize topics. In simple terms, there is a cluster of cats, a cluster of groceries, a cluster of programming, and so on.
Accordingly, we will not scatter documents randomly in shards, as before, but we will put the document in that shard, that is, the centroid of which is closest to the document. Accordingly, we will have such documents grouped by topic in shard.
And further, just for a request, now we can not go to all shards, but only to go to some small subset of those who are closest to this request.
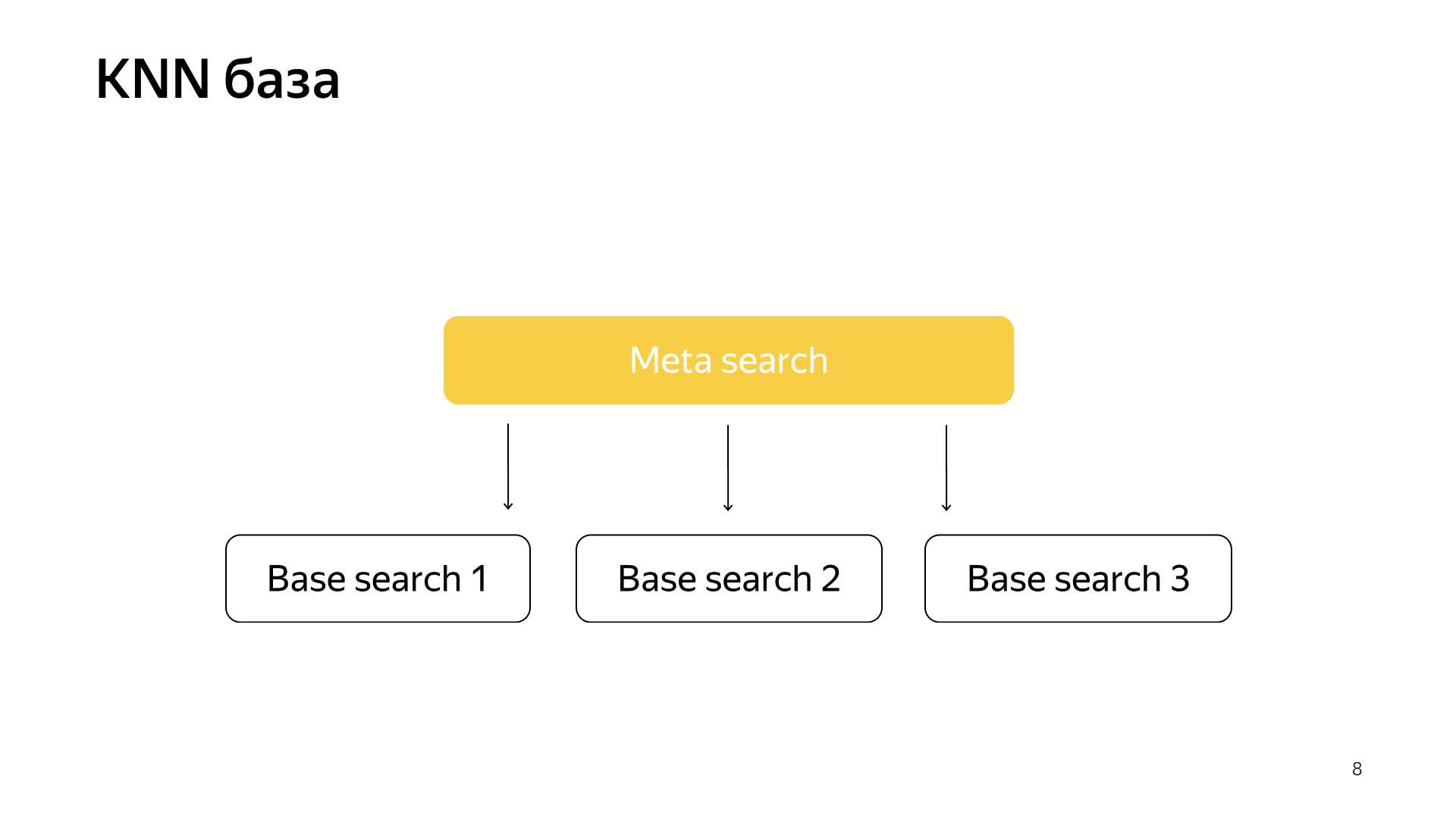
Accordingly, we had such a scheme, meta-search is included in all shards. And now he needs to go to a much smaller number, and at the same time we will still look for the nearest documents.
What do we actually get from this design? It significantly reduces the consumption of computing resources, simply because we go to fewer clusters. This, as I have already said, I consider one of the highlights of our service, this is the alloy of infrastructure and machine learning that gives such results that no one could think of before.

And, in the end, it's just a pretty funny thing, because you got the models here, and then you went, redid the entire search, turned off the petabytes of data, and your search works, it burns ten times less resources. You saved a billion dollars for the company, everyone is happy.

I talked about one of the projects that appears in our search and which is being implemented and done together with all the experiments for a suspended year. Our other typical tasks are to double the search base, because the Internet is constantly growing and we want to catch up with it and search on all pages on the Internet. And of course, this is the acceleration of the base layer, in which there are most instances, most iron. For example, speeding up your base search by one percent means saving about a million dollars.
We are also engaged in the search as a startup incubator. I will explain. The search has been done for 20 years. It has already done a lot of things, many times we came up against a dead end and thought that nothing more could be done. Then there was a long series of experiments. We again broke through this dead end. And during this time we have accumulated a lot of expertise on how to do big and cool things. Accordingly, now most of the new directions in Yandex are done in the search, because people in the search already know how to do all this, and it’s logical to ask them to at least design some new system. And as a maximum - go and do it yourself.
Now, I hope you have a little idea of our work. I will quickly tell the thematic part of my story about interns in our service. We love them very much. We have a lot of them, last summer only in my group there were 20 trainees, and I think this is good. When you take one or three interns, they feel a little lonely, sometimes they are afraid to ask older comrades. And when there are a lot of them, they communicate with each other as comrades in misfortune. If they’re afraid to ask developers something, they’ll go, they will whisper in the corner. Such an atmosphere helps to do everything efficiently.
We have a million tasks, the team is not very large, so our interns are fully loaded. We don’t ask the trainee to sit at the logger all the time, write tests, refactor the code, but immediately give some kind of complicated production task: speed up the search, improve index compression. Of course we help. We know that this all pays off, so we are happy to share our expertise. Since our field of activity is quite extensive, each of us will find a task for himself to his liking. Want to poke around in ML - poke around. You want only MapReduce - ok. Want runtime - runtime. There is anything.
What do you need to get to us? We do everything mainly in C ++ and Python. It is not necessary to know both. One can know one thing. We welcome knowledge of algorithms. It forms a certain style of thinking, and it helps a lot. But this is also not necessary: again, we are ready to teach everything, we are ready to invest our time, because we know that it pays off. The most important requirement that we make, our motto, is not to be afraid of anything and a lot of figures. Do not be afraid to drop production, do not be afraid to start doing something complicated. Therefore, we need people who are also not afraid of anything and who are also ready to turn mountains. Thanks a lot.
Want to poke around in ML - poke around. You want only MapReduce - ok. Want runtime - runtime.
- What is a search today? Yandex began by doing a search, developing it. 20 years have passed. We have a search base for hundreds of billions of documents.
We call a document any page on the Internet, but, in fact, not only it. Still - its contents, various statistics about which users like to go to it, how many of them. Plus the data we calculated.
They are also tens of thousands of instances that, in response to each request, process data, search for something, enrich the search response. Some instances are looking for pictures, some for ordinary text documents, some for video, etc. That is, tens of thousands of machines are activated for your every request. They all try to find something and improve the result that is shown to you. Accordingly, tens of thousands of machines serve thousands of requests per second. These tens of thousands of instances are combined into hundreds of services designed to solve a problem.
There is a search core - a web search service. And there is a video search service, etc. Accordingly, there is a thing that combines the answers of different searches and tries to choose what and in which order it is better to show the user. If this is some kind of request about music, then it is probably better to show Yandex.Music first, and then, for example, a page about this music group. This is called a blender. There are already hundreds of such services, and they also do something for every request and try to help users somehow. And, of course, this all uses machine learning of just all sorts, from some simple statistics, linear models, to gradient boostings, neural networks and so on.
I will talk about infrastructure and ML right now.
My group is called the new runtime development group, it is part of the search component development service. So that you have an idea, I’ll tell you a little what our service does.
In fact, to everyone. If you submit a search, then we launched our hands into almost everything, starting from building a search base. That is, we have MapReduce, we collect all the data about documents there, boil it, build all kinds of data structures, so that when we query them, we can efficiently calculate something. Accordingly, we work from the bottom when the document just gets to us, from the first stage, when these documents get something and rank it, and to the very top, where the layout receives conditional JSON and draws it with all the pictures and beautiful things. From bottom to top, we are developing something on the entire stack.
But we are not only writing code and, accordingly, we are doing all this in infrastructure. We are actually training neural networks, CatBoost. And other ML things that you can imagine and burn, we also teach. Also, since we have big loads, big data, we, of course, rummage through algorithms and data structures and never restrain ourselves from introducing them somewhere. For example, in several places we use segment trees. We have our own compression of indices that build boron and according to it consider the dynamics of how best to build dictionaries.
In general, dealing with such a large colossus as a search, we were saturated with such simple tasks. Therefore, we, of course, adore something complex, new, something that challenges us. And we did not just go and write, as usual, ten lines of code. We need to think about some experiments. In general, the tasks that we set ourselves are often on the verge of fiction. Sometimes you think: it's probably not possible. But then you, perhaps, somehow experimented - experiments can take a whole year - but in the end something turns out. Then we begin to introduce, remake something.
And besides any projects, skills, and so on, in general, we are one of the most ambitious and fast-growing teams in Yandex. For example, I came two years ago, was the ninth person in our service. Now we have a service of almost 60 people. This is, in fact, with the interns, but, in general, four times we have grown exactly in two years. This is to give you an idea of what our service is doing.
Now I want to tell you a bit about the top about our tasks and the direction that, it seems to me, in the near future we will be more and more relevant. But for this, you must first briefly describe how the most basic search layer works.
Generally speaking, everything works very simply. We have our search base, we have all the documents, and we divide all these documents more or less evenly into N pieces. They are called shards. And a program called “Basic Search” is launched over the shard. Her task is to search, accordingly, on this piece of the Internet. That is, she knows how to search for it and knows nothing more about the other Internet. And we have N shards like that. Basic searches are launched above them, and, accordingly, there is a meta search over this. The user's request falls into it and, accordingly, it simply goes to all shards, and each shard performs a search, then each returns a result, and it performs some kind of merge and gives an answer.
That’s how the search was arranged for almost all 20 years, and, in general, for a long time they thought that this would remain so, and nothing better could be done. But everything is changing, new technologies are emerging, and machine learning now not only allows you to increase quality, but also allows you to solve some kind of infrastructure problems. Recently, in our search, projects have been shot very much, right at the junction of infrastructure and machine learning. When two such mastodons merge, very interesting results are obtained.
Recently, neural networks have appeared. We have the text of the request, there is the text of the document. We want to get some vector of numbers from the request, to get some vector of numbers from the document so that the scalar product predicts the value that we want. For example, we want to train the scalar product to predict the probability of a user clicking on this document. Quite an understandable thing.
It is arranged approximately like this. If very, very rude, then we have some words on the bottom layer, and then there are several layers of the network. Each layer, in fact, takes a vector as its input. That is, the bottom layer is such a sparse vector, where each word is a request. Multiplies it by a matrix, gets some kind of vector, and then, accordingly, applies some nonlinearity to each component, and it does this several times. And the last layer, this is called just the vector that we just took the request, applied such layers, and here the last layer is the very request vector.
Accordingly, these neural networks have been actively introduced into the search in recent years, they brought a lot of benefits for quality. But they have one problem in that all the quantities that we want to predict are good, but rough enough, because in order to train such a neural network, the bottom layer is very large - all words are from tens of millions of words, so you need to be able to write her input several billion data.
For example, we can train on some user clicks, and so on. But the main signal that is considered the most important in our search is manual marking by special people. They take the request, take the document, read it, understand how good it is and put a mark, that is, how much this document fits this request. For a long time, we could not predict such a magnitude by neural networks, because we still have millions of estimates, because hiring the entire planet to constantly mark it all up is very expensive. Therefore, we made some hack.
Neural network of neural networks. Over the past years, we have accumulated quite a lot of some neural networks that predict good signals, but a little rougher than the assessment of special people. Accordingly, we decided that we would submit the ready-made vectors of these networks to the lower layer, and then we will train the neural network to predict our search relevance on the smaller data network.
The result was a very good model. She brings the requests of documents into a vector, and their scalar product directly predicts the real relevance that we have long wanted to predict.
Further, we had an idea how to redo the search a bit. The project is called a KNN base (English k-nearest neighbors, k-nearest neighbors method).
The basic idea is this. We have a query vector and a document vector. We need to find the nearest one. We have each document represented by a vector. Let's highlight N clusters, those that characterize the entire document space. Roughly speaking. Strongly smaller than the number of documents, but for example, they characterize topics. In simple terms, there is a cluster of cats, a cluster of groceries, a cluster of programming, and so on.
Accordingly, we will not scatter documents randomly in shards, as before, but we will put the document in that shard, that is, the centroid of which is closest to the document. Accordingly, we will have such documents grouped by topic in shard.
And further, just for a request, now we can not go to all shards, but only to go to some small subset of those who are closest to this request.
Accordingly, we had such a scheme, meta-search is included in all shards. And now he needs to go to a much smaller number, and at the same time we will still look for the nearest documents.
What do we actually get from this design? It significantly reduces the consumption of computing resources, simply because we go to fewer clusters. This, as I have already said, I consider one of the highlights of our service, this is the alloy of infrastructure and machine learning that gives such results that no one could think of before.
And, in the end, it's just a pretty funny thing, because you got the models here, and then you went, redid the entire search, turned off the petabytes of data, and your search works, it burns ten times less resources. You saved a billion dollars for the company, everyone is happy.
I talked about one of the projects that appears in our search and which is being implemented and done together with all the experiments for a suspended year. Our other typical tasks are to double the search base, because the Internet is constantly growing and we want to catch up with it and search on all pages on the Internet. And of course, this is the acceleration of the base layer, in which there are most instances, most iron. For example, speeding up your base search by one percent means saving about a million dollars.
We are also engaged in the search as a startup incubator. I will explain. The search has been done for 20 years. It has already done a lot of things, many times we came up against a dead end and thought that nothing more could be done. Then there was a long series of experiments. We again broke through this dead end. And during this time we have accumulated a lot of expertise on how to do big and cool things. Accordingly, now most of the new directions in Yandex are done in the search, because people in the search already know how to do all this, and it’s logical to ask them to at least design some new system. And as a maximum - go and do it yourself.
Now, I hope you have a little idea of our work. I will quickly tell the thematic part of my story about interns in our service. We love them very much. We have a lot of them, last summer only in my group there were 20 trainees, and I think this is good. When you take one or three interns, they feel a little lonely, sometimes they are afraid to ask older comrades. And when there are a lot of them, they communicate with each other as comrades in misfortune. If they’re afraid to ask developers something, they’ll go, they will whisper in the corner. Such an atmosphere helps to do everything efficiently.
We have a million tasks, the team is not very large, so our interns are fully loaded. We don’t ask the trainee to sit at the logger all the time, write tests, refactor the code, but immediately give some kind of complicated production task: speed up the search, improve index compression. Of course we help. We know that this all pays off, so we are happy to share our expertise. Since our field of activity is quite extensive, each of us will find a task for himself to his liking. Want to poke around in ML - poke around. You want only MapReduce - ok. Want runtime - runtime. There is anything.
What do you need to get to us? We do everything mainly in C ++ and Python. It is not necessary to know both. One can know one thing. We welcome knowledge of algorithms. It forms a certain style of thinking, and it helps a lot. But this is also not necessary: again, we are ready to teach everything, we are ready to invest our time, because we know that it pays off. The most important requirement that we make, our motto, is not to be afraid of anything and a lot of figures. Do not be afraid to drop production, do not be afraid to start doing something complicated. Therefore, we need people who are also not afraid of anything and who are also ready to turn mountains. Thanks a lot.