"I got a backup on my tape." First person story
In the previous article, we told you about new features in the Update 4 release for Veeam Backup & Replication 9.5 (VBR), released in January, where the backups on the tape were not consciously mentioned. The story about this area deserves a separate article, because there were really many new features.
- QA guys, write an article?
- Why not!

The storage of data on magnetic tapes (cassettes, teips , as we call them in R&D) is not limited to the ZX-Spectrum computer, which was a thing of the past, one game for which could be loaded into 48 kb RAM from a tape cassette for several minutes. For a quarter century, the speed and capacity of the cassettes increased by 6-7 orders of magnitude. This is not a completely correct comparison, and Moore’s Law sets the LTO standardnot keeping up. Nevertheless, modern technologies allow recording 12 terabytes of data on a kilometer tape of a tape (up to 30 terabytes in compression mode), so the 160-dollar drive leaves competitors behind in the cost of long-term storage of a large amount of data, even taking into account investments in recording equipment / read. Data on such tapes is reliably stored for 15-30 years.
I’ll come from the other side. Ransomware viruses have reached a new level recently . They can wait their hours in the infrastructure of a large company for weeks and months, and with the advent of another zero-day vulnerability, they can destroy (not without human help, because a lot of money is at stake) not only all data, but also all backups that can only be reached . Here is a fresh examplewhen the company had to pay ransomware. The so-called air gap , i.e. backups that were physically isolated from the infrastructure, became, in fact, the only reliable salvation from such stories. Magnetic tape here is one of the timeless solutions.

But one specification and technological iron and barium-ferrite novelties from leading manufacturers (IBM, HPE, Oracle, Dell) for reliable data protection is not enough, you need good software. At Veeam, our whole team is engaged in tape backups, about 10 people analyze, plan, research, develop and test daily. You could see the results of this work in previous articles ( one , two ). What has been done over the past year?
There is a choice between liberties in relation to the native language and complicating the readability of clericalism. I prefer the first, so I apologize in advance if someone slang words from the list below will hurt the eye. Here I will briefly recall what a particular term means.
Immediately trump cards on the table. The most ambitious feature of our update, designed for cloud providers that use VBR in their infrastructure. Development was started two years ago. Soon we realized that we won’t have time to cope with such a serious task for the next release, took a short pause, and eventually released a feature in 9.5 Update 4.
In short, now providers have the opportunity to copy backups of their clients to tapes using tape jobs in GFS pool. This gives providers - and these are very large guys dear to our heart and the commercial department - two possibilities:
From the point of view of marketing, the functionality is very "tasty", from ours - no less difficult to implement.
The main problem encountered is data encryption. Most cloud backups are encrypted, statistics say about ⅔ of the total. For us, this figure was a surprise, it was assumed that almost everything is encrypted, but no - many customers seem to be unconditionally confident in their providers.
The paradigm is simple: the provider should not be able to decrypt the data of its tenants. At the same time, as part of the new feature, it is required on the provider’s side to open storage with backups. This is necessary in order to transfer data blocks, for example, to create a virtual full backup . The main thing is to do this regardless of tenant, when the necessary keys are not transmitted to the provider during the execution of the job.
The solution to this problem, used, incidentally, in another major feature of the released add-on - Capacity Tier - consists in adding an additional encryption key. The archive key (Archive key) is stored in the provider database in encrypted form. According to a tricky scheme on the provider’s side, it can be used to open the store, move and re-encrypt data blocks between the stores (after all, each has its own key), but the data itself cannot be decrypted.
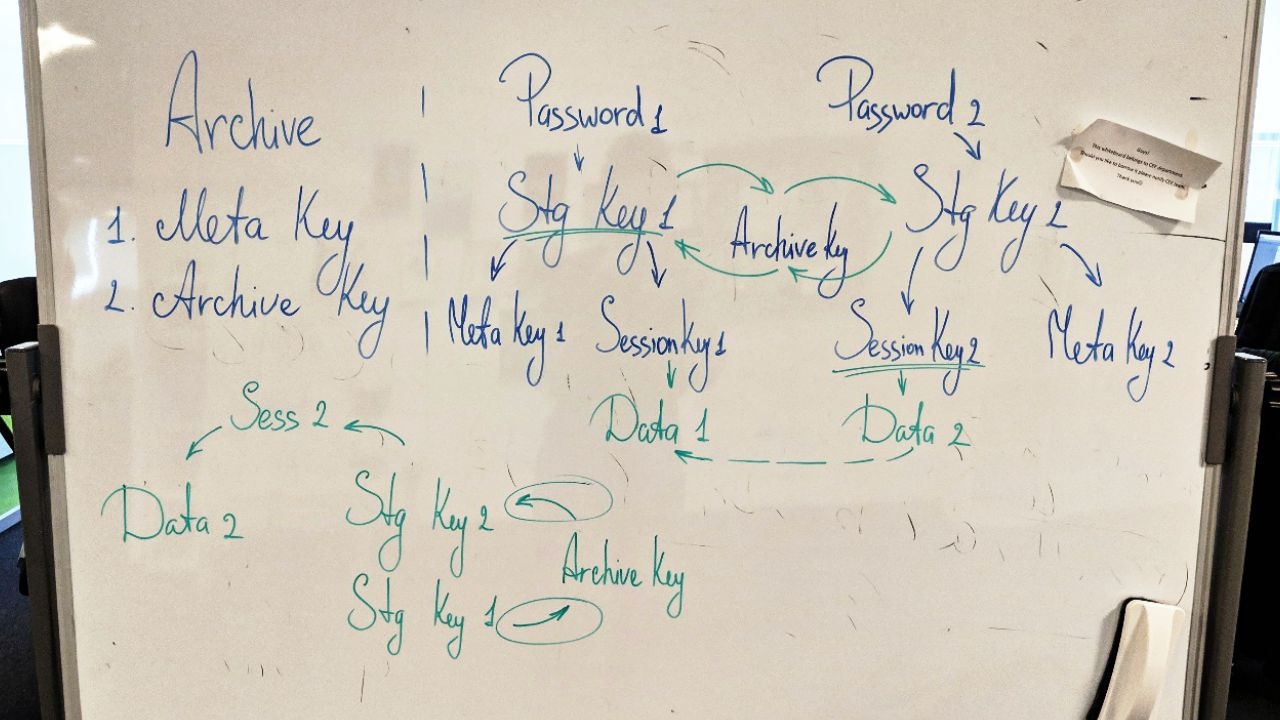
Tricky scheme (working version)
I’ll add that all engineers in R&D really like encryption in our product, however, no one knows in detail how it works. (There was still a joke “and why it works at all,” but the editors did not miss it.)
Hundreds of bugs were recorded on the feature. The most difficult areas are encryption, user interface, problems with restore.
From the point of view of testing, the great variability represented the “combinatorics” of the types and types of tenant jobs and repositories - I mean both source and target when restoring backups to the infrastructure. All this is strung on logic within the framework of the GFS model (including the new one - parallelism and daily media sets, more about this below), and, on the whole, on cloud specifics that are unusual for teips. Remember to season with plenty of encryption. To continue the metaphor, we ate a lot of this dish - but also tasted it from all sides.
Fragment of the test plan
A detailed description can be found in the user manual (so far in English): backup , recovery . I will dwell on the main points.
The provider adds tenants to the teip job with the GFS pool as a target. If there is a cloud license in the second step of the wizard, the Tenants option is available . You can add all tenants at once or separately, or you can choose only a separate quota (but not a subquot) of an individual tenant. You cannot mix tenant backups and regular local backups in the same job.

The rest of the tinctures are almost completely identical to the usual job in the GFS pool.
Data restoring is possible both on the side of the provider, and on the side of the tenant himself.
Performed through a new wizard. Here you can already go down to a separate job, the whole chain that was in the repository on a certain day is restored.
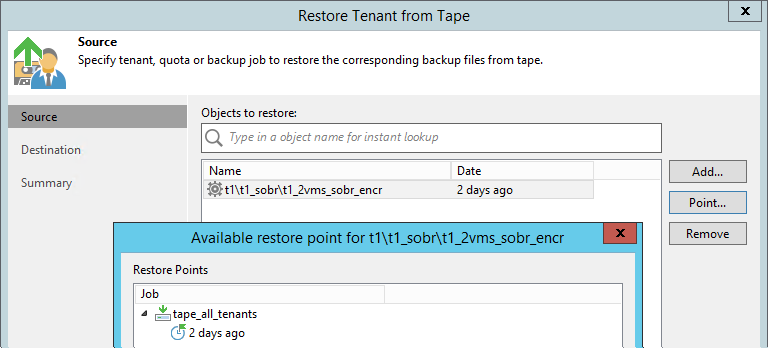
There are three restaurant options:

This option implies that the client has its own teip infrastructure and a large amount of data for the restaurant. The provider can physically send the tape with the recorded backups to the customer by the delivery service, he catalogs it on his equipment, decrypts the tapes and backups and works with the backups as if he himself wrote them on tape. Here is a life hack not to download terabytes on WAN.
GFS media pools appeared in VBR two years ago, in version 9.5. In the latest update, both in connection with the appearance of the Tenant to tape feature, and at the request of users, we pumped this functionality well.
A new daily media set has appeared. Now in the GFS pool you can store backups for every day, and not only complete, but also incremental. The latter take up significantly less space, and this was done in order to save tape. It is understood that these cassettes are constantly rotated in the library, not transported to remote storage. At the same time, for a restaurant from an incremental point, you will need the tapes of one of the senior media sets (weekly, monthly, quarterly or yearly). It is impossible to turn on the daily media set without including the weekly one so that in most cases it would take weekly cassettes to restore from an incremental copy. They are either always in the library, or stored in a not so remote warehouse.

The logic of the tape job in the GFS media poolnot the easiest , technical writers will not let you lie. If in a nutshell, omitting the details, then only full backups (including virtual full backups) are copied to the weekly and senior media sets, one for each date, and to the daily backup all backups that are in the repository for the current day, because backup -Job can start more often than once a day.
Now parallel recording of several chains or work on several library drives is also possible in GFS-media pools (earlier - only in ordinary). It is included in the Options step of the media pool.

An important clarification : the same file is always written to the same stream, therefore, in the case of several large virtual machines, it is recommended to enable per-VM configuration on the repository so that the backup consists of several chains.
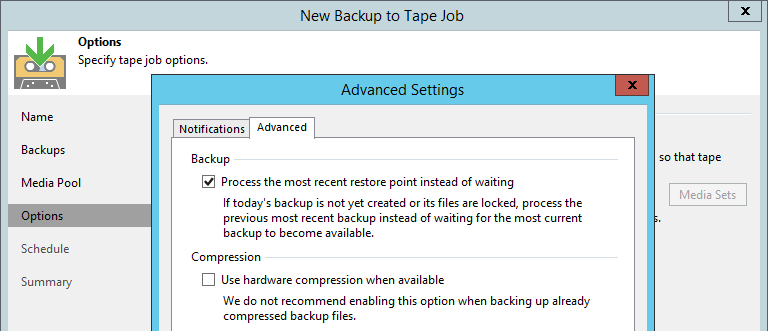
In addition, it became possible to choose the start time of the GFS job itself. Many users did not like starting at midnight and then waiting for almost the whole day until the sourcing job ended. Now this time can be set, for example, in the late evening, when there is already something to copy to tape. Moreover, at the request of users, we put in the advanced settings an option that previously could only be activated using the registry key. It is enough to select Process the most recent restore point instead of waiting - and what is in the repository at the time of the start of the tape job (the point for yesterday, for example) is copied to the tape, there is no waiting at all.
It will be about the situation when more than one library is added to one media pool. We supported this before, but from time to time clients came with complaints about not quite predictable behavior.
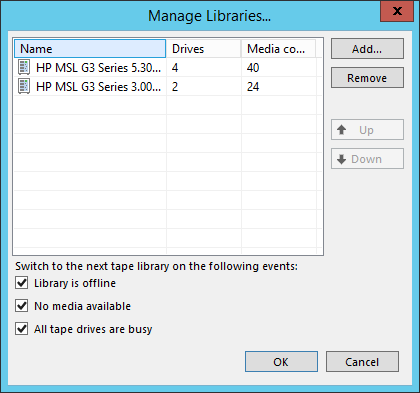
For example, the tape job started, it took two drives in the first library, but the concurrency settings allow it to use 4 drives at once. Should this job switch to the second library of the media pool and use it too, or will this be a waste of resources?
Another case. An option was selected to switch by the condition “there are no cassettes available”, in the first library there is only one cassette, but all data is potentially placed on it. However, the settings allow you to write in parallel on two cassettes. Should the second library be involved in this case?
We decided to put this area in order, making it possible to customize the behavior explicitly.

Libraries in the media pool appeared roles - active and passive . And most media pool - two modes: failover, or feylover (failover) and parallel recording (paralleling). Now, depending on the requirements, you can configure the media pool in different ways.
There is a more complicated situation that we do not yet support - several active libraries with passive ones. Feedback will show whether there is a need for such configurations and whether it is necessary to "finish" the feature in the future. Standard practice.
WORM - Write Once Read Many - tapes that cannot be erased or overwritten at the iron level can only append data. Their mandatory use is regulated by the rules of some organizations, for example, those working in the field of medicine. The main problem with such cassettes used to be that VBR, when taking inventory or cataloging, recorded a heading that could no longer be erased, and tape jobs fell with an error during such an attempt.
In 9.5 Update 4, full support for such tapes is implemented. Added WORM-media pools, regular and GFS, where you can put only tapes of this type.
New cassettes have a blue, “frozen” icon. From the point of view of the user, working with WORM-cassettes is no different from working with ordinary ones.
The "feed" of the cassettes is initially determined by the barcode suffix , if the barcode on them is regular or unreadable, the drive gives information when the cartridge is first inserted. Place WORM-tapes in a regular media pool and write to them will not work. From the funny: there were already users who pasted WORM-barcodes on ordinary cassettes and were surprised at the changes in their infrastructure after the update.
Along with the introduction of non-rewritable cassettes, they began to work with the chip . We did not use standard attributes in the chip before, now we write and read some of them, but we do not perceive them as the main data source. The main guideline is still the title of the cassette. This decision turned out to be correct: after a month after the release we see how the “zoo” of the user’s iron brings surprises in terms of working with the chip.
In conclusion, about the feature most requested by the number of reviews of this Update. The backup of NDMP volumes to tapes became available. It is necessary to add an NDMP server to the VBR infrastructure , after which it will become possible to select volumes from this host in the file teip job. They fall on the cassette in the form of files with a special attribute to distinguish them from the usual cataloging.
In the first implementation, there are certain limitations: extensions are not supported, plus backup and restore of only the full volume, but not individual files, is possible. Backup works through dump (in the case of NetApp - ufsdump ), there are some peculiarities: the maximum number of incremental points is 9, after which a full backup is forced.
These were only the largest innovations in the field of backup to tape in VBR 9.5 Update 4. Other changes are listed below:
For a change I will give some links to Russian-language resources:
- QA guys, write an article?
- Why not!
Tape Drives in the 21st Century
The storage of data on magnetic tapes (cassettes, teips , as we call them in R&D) is not limited to the ZX-Spectrum computer, which was a thing of the past, one game for which could be loaded into 48 kb RAM from a tape cassette for several minutes. For a quarter century, the speed and capacity of the cassettes increased by 6-7 orders of magnitude. This is not a completely correct comparison, and Moore’s Law sets the LTO standardnot keeping up. Nevertheless, modern technologies allow recording 12 terabytes of data on a kilometer tape of a tape (up to 30 terabytes in compression mode), so the 160-dollar drive leaves competitors behind in the cost of long-term storage of a large amount of data, even taking into account investments in recording equipment / read. Data on such tapes is reliably stored for 15-30 years.
I’ll come from the other side. Ransomware viruses have reached a new level recently . They can wait their hours in the infrastructure of a large company for weeks and months, and with the advent of another zero-day vulnerability, they can destroy (not without human help, because a lot of money is at stake) not only all data, but also all backups that can only be reached . Here is a fresh examplewhen the company had to pay ransomware. The so-called air gap , i.e. backups that were physically isolated from the infrastructure, became, in fact, the only reliable salvation from such stories. Magnetic tape here is one of the timeless solutions.
But one specification and technological iron and barium-ferrite novelties from leading manufacturers (IBM, HPE, Oracle, Dell) for reliable data protection is not enough, you need good software. At Veeam, our whole team is engaged in tape backups, about 10 people analyze, plan, research, develop and test daily. You could see the results of this work in previous articles ( one , two ). What has been done over the past year?
Glossary
There is a choice between liberties in relation to the native language and complicating the readability of clericalism. I prefer the first, so I apologize in advance if someone slang words from the list below will hurt the eye. Here I will briefly recall what a particular term means.
Luminaries VBR this part can be skipped
Joba - job - backup job. Actually, the whole VBR is built on job. In addition to backup and replication, it can also be copying to magnetic tape (backup to tape job, tape job). I will make a reservation that restoring from a backup copy (restore) is also a job, but in this article, this word will mean backup.
Storaj - storage - historically established name. These are files in the repository (repository - storage), containing backup copies - full and incremental . In one story, there can be one or several virtual machines.
Chain- chain - a sequence of related stories. To restore data from the n-th incremental store, all the previous ones from the (n-1) -st to the 1st and full store, to which the first incremental one refers, are needed.
Source , target - source, target. Source is the original entity that the job processes. In the case of backups / replicas, this is usually a virtual machine in the hypervisor. In the case of tape-job, the backup is the backup-job itself (well, or files in the case of file to tape-jobs). A backup job target is a repository where backups are stored. For tape work, this is a media pool.
Media pool - media pool- a pool of storage media, in our case, tapes. A logical container created by the user and containing the cassettes of one or more libraries. So, the tape job always has a media pool as a target, that is, data is not written to any particular tape or to any tape in the library, but to a specific set of them. The media pool has a setting for the data storage time, after which the cartridge can be overwritten. The user can create standard pools and GFS pools . Each of these species can now be WORM and non-WORM, more on that below.
Media Set - media set- a set of tapes in the media pool to which backups / files are continuously written. For GFS pools, media sets are also tied to an interval (for example, annual - yearly), cassettes rotate only within their interval.
Drive , changer - elements of the tape library. A drive reads and rewinds a cassette; a changer is a robot that moves cassettes between storage slots, unload slots, and the drive. There are standalone drives (standalone - freestanding), the role of the changer here is performed by a person. For a drive, a correctly installed manufacturer's driver is required on the Windows machine where the library is connected; we can work with a changer without drivers, using native SCSI.
Storaj - storage - historically established name. These are files in the repository (repository - storage), containing backup copies - full and incremental . In one story, there can be one or several virtual machines.
Chain- chain - a sequence of related stories. To restore data from the n-th incremental store, all the previous ones from the (n-1) -st to the 1st and full store, to which the first incremental one refers, are needed.
Source , target - source, target. Source is the original entity that the job processes. In the case of backups / replicas, this is usually a virtual machine in the hypervisor. In the case of tape-job, the backup is the backup-job itself (well, or files in the case of file to tape-jobs). A backup job target is a repository where backups are stored. For tape work, this is a media pool.
Media pool - media pool- a pool of storage media, in our case, tapes. A logical container created by the user and containing the cassettes of one or more libraries. So, the tape job always has a media pool as a target, that is, data is not written to any particular tape or to any tape in the library, but to a specific set of them. The media pool has a setting for the data storage time, after which the cartridge can be overwritten. The user can create standard pools and GFS pools . Each of these species can now be WORM and non-WORM, more on that below.
Media Set - media set- a set of tapes in the media pool to which backups / files are continuously written. For GFS pools, media sets are also tied to an interval (for example, annual - yearly), cassettes rotate only within their interval.
Drive , changer - elements of the tape library. A drive reads and rewinds a cassette; a changer is a robot that moves cassettes between storage slots, unload slots, and the drive. There are standalone drives (standalone - freestanding), the role of the changer here is performed by a person. For a drive, a correctly installed manufacturer's driver is required on the Windows machine where the library is connected; we can work with a changer without drivers, using native SCSI.
Tenant to tape. Provider Protected - Clients Protected
Immediately trump cards on the table. The most ambitious feature of our update, designed for cloud providers that use VBR in their infrastructure. Development was started two years ago. Soon we realized that we won’t have time to cope with such a serious task for the next release, took a short pause, and eventually released a feature in 9.5 Update 4.
In short, now providers have the opportunity to copy backups of their clients to tapes using tape jobs in GFS pool. This gives providers - and these are very large guys dear to our heart and the commercial department - two possibilities:
- protect their customers ( Tenant , tenant - the tenant) from data loss due to accidental deletion or infrastructure problems ( "flood the server");
- provide tenants with an additional service to restore data from an old backup, which has long been removed from the cloud repository according to the data storage policy, but still remains on tape.
From the point of view of marketing, the functionality is very "tasty", from ours - no less difficult to implement.
Development
The main problem encountered is data encryption. Most cloud backups are encrypted, statistics say about ⅔ of the total. For us, this figure was a surprise, it was assumed that almost everything is encrypted, but no - many customers seem to be unconditionally confident in their providers.
The paradigm is simple: the provider should not be able to decrypt the data of its tenants. At the same time, as part of the new feature, it is required on the provider’s side to open storage with backups. This is necessary in order to transfer data blocks, for example, to create a virtual full backup . The main thing is to do this regardless of tenant, when the necessary keys are not transmitted to the provider during the execution of the job.
The solution to this problem, used, incidentally, in another major feature of the released add-on - Capacity Tier - consists in adding an additional encryption key. The archive key (Archive key) is stored in the provider database in encrypted form. According to a tricky scheme on the provider’s side, it can be used to open the store, move and re-encrypt data blocks between the stores (after all, each has its own key), but the data itself cannot be decrypted.
Tricky scheme (working version)
I’ll add that all engineers in R&D really like encryption in our product, however, no one knows in detail how it works. (There was still a joke “and why it works at all,” but the editors did not miss it.)
Testing
Hundreds of bugs were recorded on the feature. The most difficult areas are encryption, user interface, problems with restore.
From the point of view of testing, the great variability represented the “combinatorics” of the types and types of tenant jobs and repositories - I mean both source and target when restoring backups to the infrastructure. All this is strung on logic within the framework of the GFS model (including the new one - parallelism and daily media sets, more about this below), and, on the whole, on cloud specifics that are unusual for teips. Remember to season with plenty of encryption. To continue the metaphor, we ate a lot of this dish - but also tasted it from all sides.
Fragment of the test plan
As a result
A detailed description can be found in the user manual (so far in English): backup , recovery . I will dwell on the main points.
Backup
The provider adds tenants to the teip job with the GFS pool as a target. If there is a cloud license in the second step of the wizard, the Tenants option is available . You can add all tenants at once or separately, or you can choose only a separate quota (but not a subquot) of an individual tenant. You cannot mix tenant backups and regular local backups in the same job.
The rest of the tinctures are almost completely identical to the usual job in the GFS pool.
Data restoring is possible both on the side of the provider, and on the side of the tenant himself.
Provider side recovery
Performed through a new wizard. Here you can already go down to a separate job, the whole chain that was in the repository on a certain day is restored.
There are three restaurant options:
- In the original location. In this case, the original backup, if any, is deleted; tenant jobs are automatically reconfigured to the restored chain. It is understood that such a restore will be generally invisible to the client, only for a short time it will be disconnected from the cloud repository.
- Into a new quota / repository. A provider can, for example, create a separate temporary account for this purpose, which it will subsequently delete. The backup appears in the tenant infrastructure after synchronization with the provider database.
- Just onto a Linux or Windows server drive registered in the provider's infrastructure. Further, this chain can be recorded on a flash drive and send tenant.
Tenant Recovery
This option implies that the client has its own teip infrastructure and a large amount of data for the restaurant. The provider can physically send the tape with the recorded backups to the customer by the delivery service, he catalogs it on his equipment, decrypts the tapes and backups and works with the backups as if he himself wrote them on tape. Here is a life hack not to download terabytes on WAN.
Large-scale improvements to the GFS pool
GFS media pools appeared in VBR two years ago, in version 9.5. In the latest update, both in connection with the appearance of the Tenant to tape feature, and at the request of users, we pumped this functionality well.
Daily Media Sets
A new daily media set has appeared. Now in the GFS pool you can store backups for every day, and not only complete, but also incremental. The latter take up significantly less space, and this was done in order to save tape. It is understood that these cassettes are constantly rotated in the library, not transported to remote storage. At the same time, for a restaurant from an incremental point, you will need the tapes of one of the senior media sets (weekly, monthly, quarterly or yearly). It is impossible to turn on the daily media set without including the weekly one so that in most cases it would take weekly cassettes to restore from an incremental copy. They are either always in the library, or stored in a not so remote warehouse.
The logic of the tape job in the GFS media poolnot the easiest , technical writers will not let you lie. If in a nutshell, omitting the details, then only full backups (including virtual full backups) are copied to the weekly and senior media sets, one for each date, and to the daily backup all backups that are in the repository for the current day, because backup -Job can start more often than once a day.
Concurrency, start time, and wait in GFS pools
Now parallel recording of several chains or work on several library drives is also possible in GFS-media pools (earlier - only in ordinary). It is included in the Options step of the media pool.
An important clarification : the same file is always written to the same stream, therefore, in the case of several large virtual machines, it is recommended to enable per-VM configuration on the repository so that the backup consists of several chains.
In addition, it became possible to choose the start time of the GFS job itself. Many users did not like starting at midnight and then waiting for almost the whole day until the sourcing job ended. Now this time can be set, for example, in the late evening, when there is already something to copy to tape. Moreover, at the request of users, we put in the advanced settings an option that previously could only be activated using the registry key. It is enough to select Process the most recent restore point instead of waiting - and what is in the repository at the time of the start of the tape job (the point for yesterday, for example) is copied to the tape, there is no waiting at all.
Improved work with multiple libraries
It will be about the situation when more than one library is added to one media pool. We supported this before, but from time to time clients came with complaints about not quite predictable behavior.
It was
For example, the tape job started, it took two drives in the first library, but the concurrency settings allow it to use 4 drives at once. Should this job switch to the second library of the media pool and use it too, or will this be a waste of resources?
Another case. An option was selected to switch by the condition “there are no cassettes available”, in the first library there is only one cassette, but all data is potentially placed on it. However, the settings allow you to write in parallel on two cassettes. Should the second library be involved in this case?
We decided to put this area in order, making it possible to customize the behavior explicitly.
Has become
Libraries in the media pool appeared roles - active and passive . And most media pool - two modes: failover, or feylover (failover) and parallel recording (paralleling). Now, depending on the requirements, you can configure the media pool in different ways.
- If you have several peer libraries and you need to parallelize the recording in them, turn on the parallel recording mode, for this all libraries need to be assigned active roles. In this case, the new tapes and drives will be activated immediately, as soon as the need arises, regardless of which library they are in. There is still priority - first, we will try to find resources in the library located higher in the list.
- If there is one main library and one old or standalon drive in reserve, enable the feylover mode by placing the main library at the top of the list and choosing a passive role for backup devices. Switching to such a device will occur only when it is really necessary for the job to work at least somehow. This situation will be considered abnormal, which will be sent a notification by mail.
There is a more complicated situation that we do not yet support - several active libraries with passive ones. Feedback will show whether there is a need for such configurations and whether it is necessary to "finish" the feature in the future. Standard practice.
WORM Support
WORM - Write Once Read Many - tapes that cannot be erased or overwritten at the iron level can only append data. Their mandatory use is regulated by the rules of some organizations, for example, those working in the field of medicine. The main problem with such cassettes used to be that VBR, when taking inventory or cataloging, recorded a heading that could no longer be erased, and tape jobs fell with an error during such an attempt.
In 9.5 Update 4, full support for such tapes is implemented. Added WORM-media pools, regular and GFS, where you can put only tapes of this type.
New cassettes have a blue, “frozen” icon. From the point of view of the user, working with WORM-cassettes is no different from working with ordinary ones.
The "feed" of the cassettes is initially determined by the barcode suffix , if the barcode on them is regular or unreadable, the drive gives information when the cartridge is first inserted. Place WORM-tapes in a regular media pool and write to them will not work. From the funny: there were already users who pasted WORM-barcodes on ordinary cassettes and were surprised at the changes in their infrastructure after the update.
Cartridge chip
Along with the introduction of non-rewritable cassettes, they began to work with the chip . We did not use standard attributes in the chip before, now we write and read some of them, but we do not perceive them as the main data source. The main guideline is still the title of the cassette. This decision turned out to be correct: after a month after the release we see how the “zoo” of the user’s iron brings surprises in terms of working with the chip.
Tape backup of NDMP volumes
In conclusion, about the feature most requested by the number of reviews of this Update. The backup of NDMP volumes to tapes became available. It is necessary to add an NDMP server to the VBR infrastructure , after which it will become possible to select volumes from this host in the file teip job. They fall on the cassette in the form of files with a special attribute to distinguish them from the usual cataloging.
In the first implementation, there are certain limitations: extensions are not supported, plus backup and restore of only the full volume, but not individual files, is possible. Backup works through dump (in the case of NetApp - ufsdump ), there are some peculiarities: the maximum number of incremental points is 9, after which a full backup is forced.
In conclusion
These were only the largest innovations in the field of backup to tape in VBR 9.5 Update 4. Other changes are listed below:
- the ability to set the order of sourcing jobs and files in tape jobs;
- the Tape Operator role has been added (the user can do everything except restore from tape - there is a Restore Operator for this);
- Added full-fledged include / exclude masks in the file tape job (except for NDMP);
- recovery in the file teip job was improved (the folder is restored with those files that were there at the time of the backup, and not with all that were in it ever in the history of its backups - a very popular feature, by the way);
- increased recovery speed of a very large number of files from cassettes;
- the algorithm for selecting the next tape for recording has been improved, in particular, ceteris paribus we take into account the amount of data written / read over its entire life, we take the freshest;
- improved product stability.
useful links
For a change I will give some links to Russian-language resources:
- Download Trial for VBR 9.5 Update 4
- Article on Habr "Useful tips for archiving Veeam backups to magnetic tape"
- Article on Habr "7 useful tips for protecting backups from cryptographic viruses"
- The teip section of the user's guide (in English)
- Well, the review videos “How it works” (though in English so far) have returned to their former place - you can watch it here . Teiping is described on slides 95 - 102.