WebAssembly development: real rake and examples

The announcement of WebAssembly took place in 2015 - but now, after years, there are still few who can boast of it in production. The materials on such experience are all the more valuable: first-hand information on how to live with it in practice is still in short supply.
At the HolyJS conference, a report on the experience of using WebAssembly received high marks from the audience, and now a text version of this report has been specially prepared for Habr (a video is also attached).
My name is Andrey, I will tell you about WebAssembly. We can say that I started to engage in the web in the last century, but I’m modest, so I won’t say that. During this time, I managed to work on both the backend and the frontend, and even drew a little design. Today I am interested in such things as WebAssembly, C ++ and other native things. I also really love typography and collect old technology.
First, I will talk about how the team and I implemented WebAssembly in our project, then we will discuss whether you need something from WebAssembly, and end with a few tips in case you want to implement it on your own.
How we implemented WebAssembly
I work for Inetra, we are located in Novosibirsk and are doing some of our own projects. One of them is ByteFog. This is peer-to-peer technology for delivering video to users. Our customers are services that distribute a huge amount of video. They have a problem: when some popular event happens, for example, someone’s press conference or some sporting event, how not to get ready for it, a bunch of clients come, leaning on the server, and the server is sad. Customers receive very poor video quality at this time.
But everyone is watching the same content. Let's ask neighboring devices of users to share pieces of video, and then we will unload the server, save bandwidth, and users will receive video in better quality. These clouds are our technology, our ByteFog proxy server.
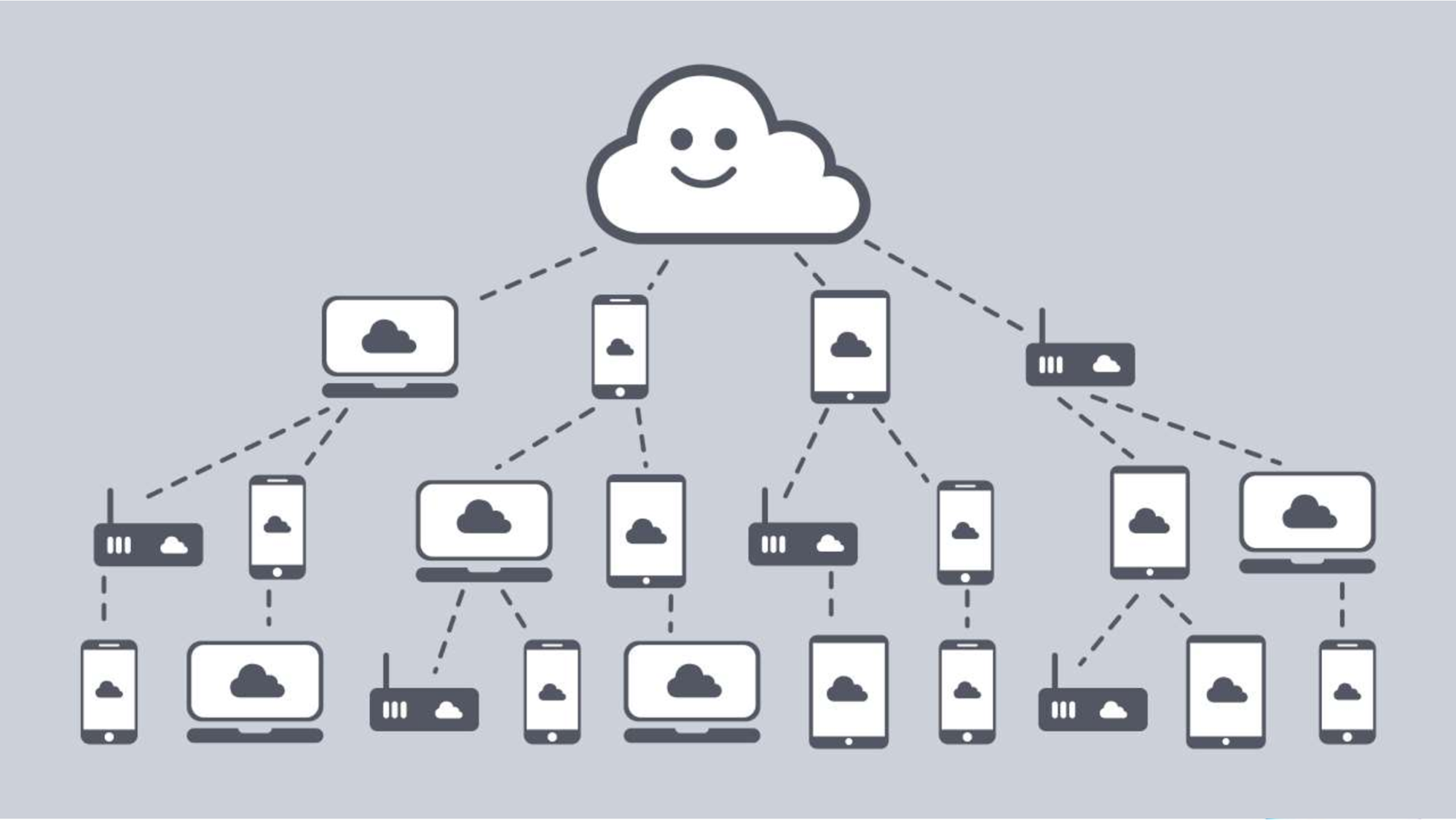
We must be installed in every device that can display video, therefore we support a very wide range of platforms: Windows, Linux, Android, iOS, Web, Tizen. What language to choose to have a single code base on all these platforms? We chose C ++ because it turned out to have the most advantages :-D More seriously, we have good expertise in C ++, it is a really fast language, and it is probably second only to C in portability
. We got a rather large application (900 classes ), but it works great. Under Windows and Linux, we compile into native code. For Android and iOS, we build a library that we connect to the application. We’ll talk about Tizen another time, but on the Web we used to work as a browser plugin.
This is the Netscape Plugin API technology. As the name implies, it is quite old, and also has a drawback: it gives very wide access to the system, so user code can cause a security problem. This is probably why Chrome turned off support for this technology in 2015, and then all browsers joined this flash mob. So we were left without a web version for almost two years.
In 2017, a new hope came. As you might imagine, this is WebAssembly. As a result, we set ourselves the task of porting our application to a browser. Since support for Firefox and Chrome already appeared in the spring, and by the fall of 2017, Edge and Safari pulled themselves up.
It was important for us to use the ready-made code, since we have a lot of business logic that we did not want to double, so as not to double the number of bugs. Take the compiler Emscripten. He does what we need - compiles the positive application into the browser and recreates the environment familiar to the native application in the browser. We can say that Emscripten is such a Browserify for C ++ code. It also allows you to forward objects from C ++ to JavaScript and vice versa. Our first thought was: now let's take Emscripten, just compile, and everything will work. Of course, it didn’t. From this began our journey along the rake.
The first thing we ran into was addiction. There were several libraries in our code base. Now it makes no sense to list them, but for those who understand, we have Boost. This is a large library that allows you to write cross-platform code, but it is very difficult to configure compilation with it. I wanted to drag as little code into the browser as possible.
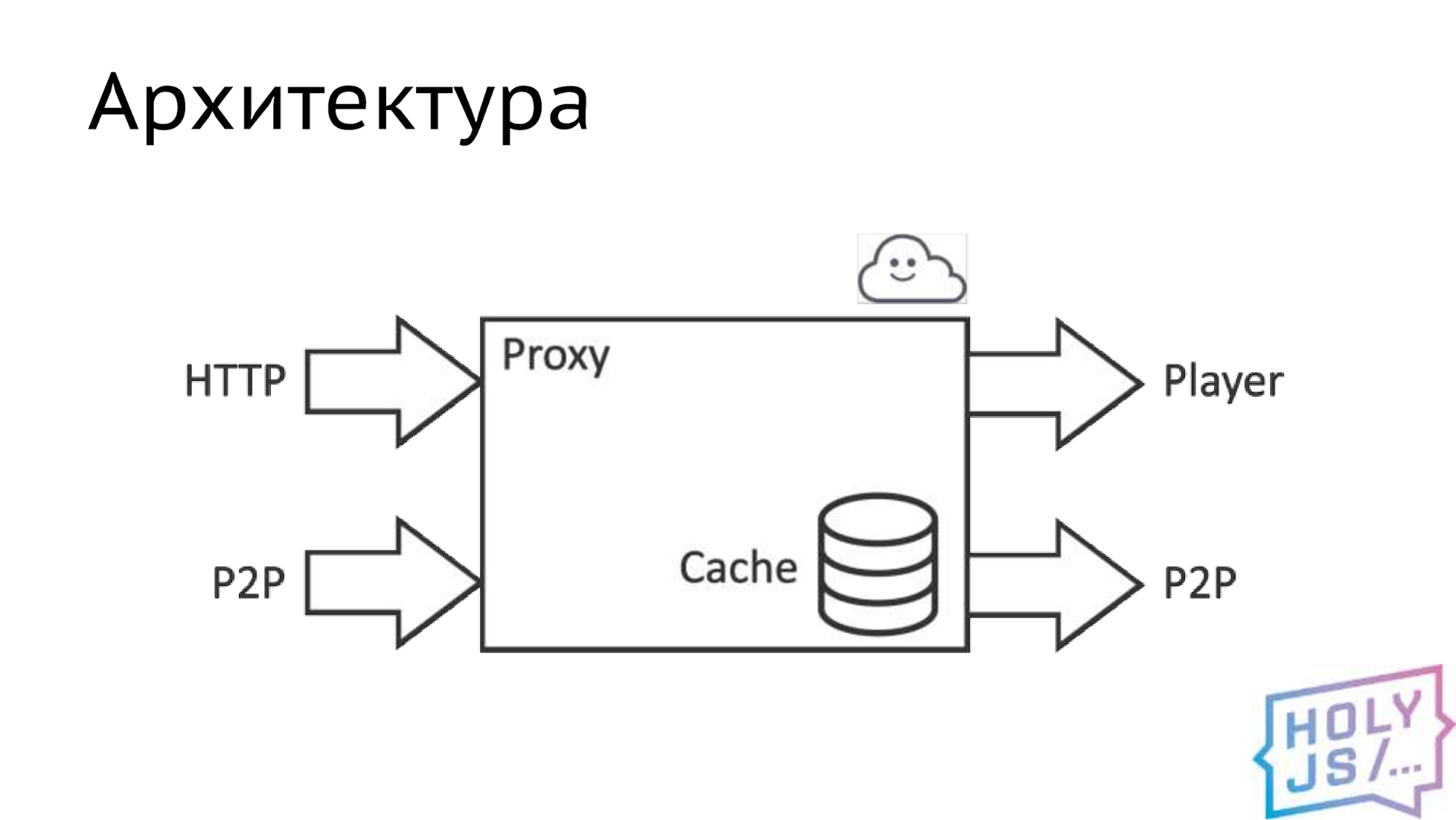
Bytefog Architecture
As a result, we identified the core: we can say that this is a proxy server that contains the main business logic. This proxy server takes data from two sources. The first and main one is HTTP, that is, a channel to the video distribution server, the second is our P2P network, that is, a channel to another same proxy from some other user. We give the data primarily to the player, since our task is to show high-quality content to the user. If resources remain, we distribute the content to the P2P network so that other users can download it. Inside there is a smart cache that does all the magic.
Having compiled all this, we are faced with the fact that WebAssembly is executed in the browser sandbox. That means it can't do more than JavaScript gives. While native applications use a lot of platform-specific things, such as a file system, a network, or random numbers. All these features will have to be implemented in JavaScript using what the browser gives us. This plate lists the fairly obvious replacements listed.

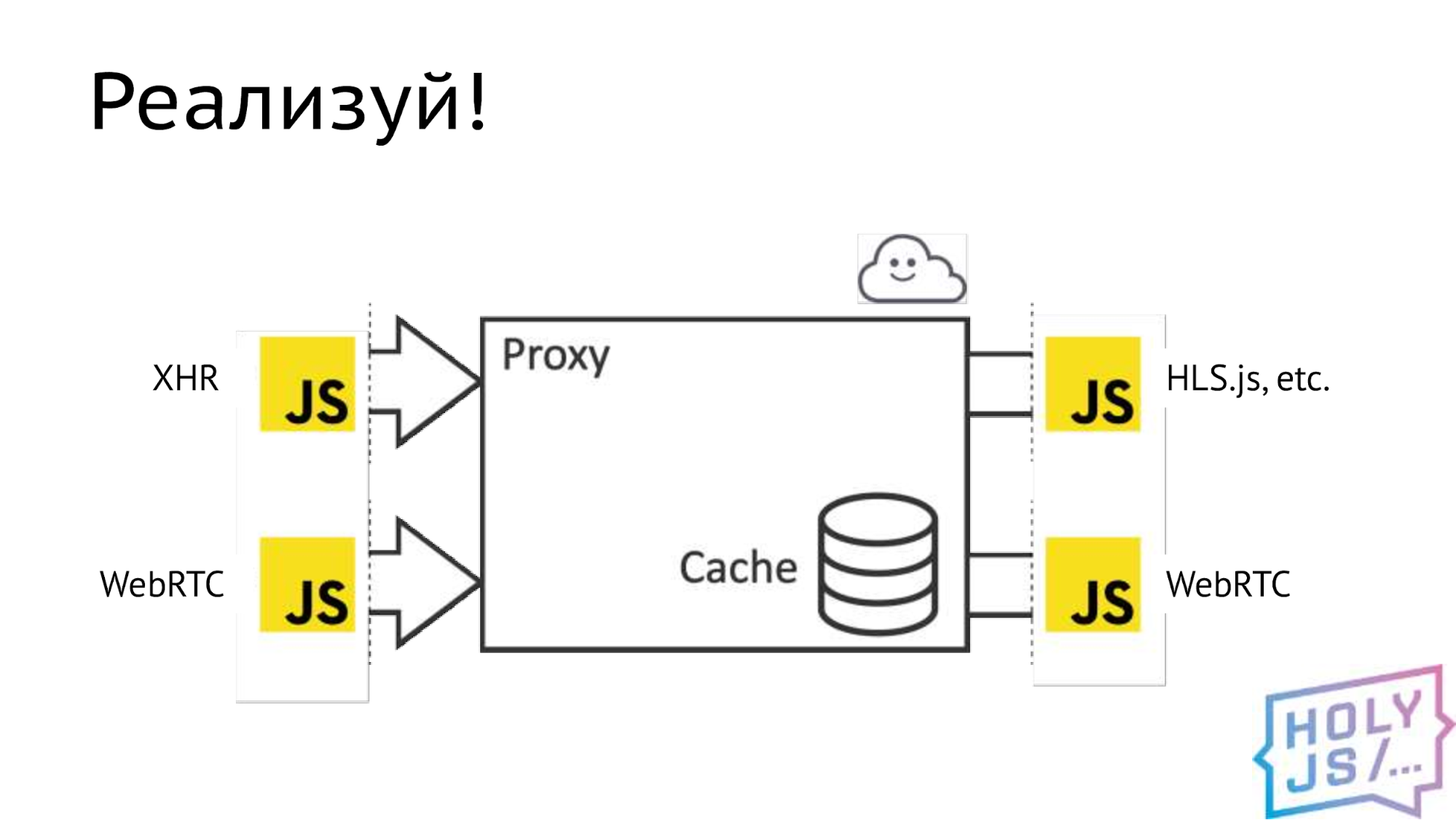
To make this possible, it is necessary to saw off the implementation of native capabilities in a native application and insert an interface there, that is, draw a certain border. Then you implement this in JavaScript and leave the native implementation, and already during the assembly the necessary one is selected. So, we looked at our architecture and found all the places where this border can be drawn. Coincidentally, this is a transport subsystem.

For each such place we defined a specification, that is, we fixed a contract: what methods will be, what parameters they will have, what data types. Once you have done this, you can work in parallel, each developer on his side.
What is the result? We replaced the main video delivery channel from the provider with the usual AJAX. We issue data to the player through the popular HLS.js library, but there is a fundamental possibility to integrate with other players, if necessary. We replaced the entire P2P layer with WebRTC.
As a result of compilation, several files are obtained. The most important is the binary .wasm. It contains the compiled bytecode that the browser will execute and which contains all of your C ++ legacy. But by itself it does not work, the so-called “glue code” is necessary, it is also generated by the compiler. The glue code is downloading a binary file, and you upload both of these files to production. For debugging purposes, you can generate a textual representation of the assembler - a .wast file and sourcemap. You need to understand that they can be very large. In our case, they reached 100 megabytes or more.
Collecting the bundle
Let's take a closer look at the glue code. This is the usual good old ES5, assembled into a single file. When we connect it to a web page, we have a global variable that contains all of our instantiated wasm-module, which is ready to accept requests to its API.
But including a separate file is a rather serious complication for the library that users will use. We would like to put everything in a single bundle. For this we use Webpack and a special compilation option MODULARIZE.
It wraps the adhesive code in the “Module” pattern, and we can pick it up: import or use require if we write on ES5 - Webpack calmly understands this dependence. There was a problem with Babel - he did not like the large amount of code, but this is an ES5 code, it does not need to be transcribed, we just add it to ignore.
In pursuit of the number of files, I decided to use the SINGLE_FILE option. It translates all the binaries resulting from the compilation into the Base64 form and pushes it into the adhesive code as a string. Sounds like a great idea, but after that the bundle became 100 megabytes in size. Neither Webpack, nor Babel, nor even the browser work on such a volume. Anyway, we will not force the user to load 100 megabytes ?!
If you think about it, this option is not needed. Adhesive code downloads binary files on its own. He does it via HTTP, so we get caching out of the box, we can set any headers that we want, for example, enable compression, and WebAssembly files are perfectly compressed.
But the coolest technology is streaming compilation. That is, the WebAssembly file, while downloading from the server, can already be compiled in the browser as data arrives, and this greatly speeds up the loading of your application. In general, all WebAssembly technology has a focus on the quick start of a large code base.
Thenable
Another problem with the module is that it is a Thenable object, that is, it has a .then () method. This function allows you to hang a callback at the time the module starts, and it is very convenient. But I would like the interface to match Promise. Thenable is not Promise, but it's okay, let's wrap it up ourselves. Let's write such a simple code:
return new Promise((resolve, reject) => {
Module(config).then((module) => {
resolve(module);
});
});
We create Promise, start our module, and as a callback we call the resolve function and pass the module that we installed there. Everything seems to be obvious, everything is fine, we are launching - something is wrong, our browser is frozen, our DevTools are hanging, and the processor is heating up on the computer. We don’t understand anything - some kind of recursion or an infinite loop. Debugging is quite difficult, and when we interrupted JavaScript, we ended up in the Then function in the Emscripten module.
Module[‘then’] = function(func) {
if (Module[‘calledRun’]) {
func(Module);
} else {
Module[‘onRuntimeInitialized’] = function() {
func(Module);
};
};
return Module;
};
Let's look at it in more detail. Plot
Module[‘onRuntimeInitialized’] = function() {
func(Module);
};
responsible for hanging a callback. Everything is clear here: an asynchronous function that calls our callback. Everything as we want. There is another part to this feature.
if (Module[‘calledRun’]) {
func(Module);
It is called when the module has already started. Then callback is synchronously called immediately, and the module is passed to it in the parameter. This mimics the behavior of Promise, and it seems to be what we expect. But then what is wrong?
If you carefully read the documentation, it turns out that there is a very subtle point about Promise. When we resolve the Promise using a Thenable, the browser will unwrap the values from that Thenable, and to do this, it will call the .then () method. As a result, we resolve the Promise, pass the module to it. The browser asks: Then is this an object? Yes, this is a Thenable. Then the .then () function is called on the module, and the resolve function itself is passed as a callback.
The module checks if it is running. It is already running, so callback is called immediately, and the same module is passed to it again. As a callback, we have the resolve function, and the browser asks: is this a Thenable object? Yes, this is a Thenable. And it all starts again. As a result, we fall into an endless cycle from which the browser never returns.

I did not find an elegant solution to this problem. As a result, I simply delete the .then () method before resolve, and this works.
Emscripten
So, we compiled the module, assembled JS, but something is missing. We probably need to do some useful work. To do this, transfer data and connect the two worlds - JS and C ++. How to do it? Emscripten provides three options:
- The first is the ccall and cwrap functions. Most often you will meet them in some tutorials on WebAssembly, but they are not suitable for real work, because they do not support the capabilities of C ++.
- The second is WebIDL Binder. It already supports C ++ functions, you can already work with it. This is a serious interface description language used, for example, by W3C for their documentation. But we did not want to carry it into our project and used the third option
- Embind. We can say that this is a native way of connecting objects for Emscripten, it is based on C ++ templates and allows you to do a lot of things by forwarding different entities from C ++ to JS and vice versa.
Embind allows you to:
- Call C ++ functions from JavaScript code
- Create JS objects from a C ++ class
- From the C ++ code, turn to the browser API (if for some reason you want this, you can, for example, write the entire front-end framework in C ++).
- The main thing for us: implement the JavaScript interface described in C ++.
Data exchange
The last point is important, since this is exactly the action that you will constantly do when porting the application. Therefore, I would like to dwell on it in more detail. Now there will be C ++ code, but don’t be afraid, it’s almost like TypeScript :-D
The scheme is as follows:

On the C ++ side, there is a kernel that we want to give access to, for example, an external network - upload video. It used to do this with native sockets, there was some kind of HTTP client that did this, but there are no native sockets in WebAssembly. We need to somehow get out, so we cut off the old HTTP client, insert the interface into this place, and implement this interface in JavaScript using regular AJAX, in any way. After that, we will pass the resulting object back to C ++, where the kernel will use it.
Let's make the simplest HTTP client that can only make get requests:
class HTTPClient {
public:
virtual std::string get(std::string url) = 0;
};
To the input, it receives a string with the URL that needs to be downloaded, and to the output, a
string with the result of the request. In C ++, strings can have binary data, so this is suitable for video. Emscripten forces us to write
such a terrible Wrapper:

In it, the main thing is two things - the name of the function on the C ++ side (I marked them in green), and the corresponding names on the JavaScript side (I marked them in blue). As a result, we write a communication declaration:

It works like Lego blocks, from which we assemble it. We have a class, this class has a method, and we want to inherit from this class to implement the interface. It's all. We go to JavaScript and inherit. This can be done in two ways. The first is extend. This is very similar to the good old extend from Backbone.

The module contains everything that Emscripten compiled, and it has a property with an exported interface. We call the extend method and pass the object there with the implementation of this method, that is, the get function will implement some way of
obtaining information using AJAX.
On output, extend gives us a regular JavaScript constructor. We can call it as many times as necessary and generate objects in the quantity that we need. But there is a situation when we have one object, and we just want to pass it to the C ++ side.

To do this, somehow bind this object to a type that C ++ will understand. This is what the implement function does. At the output, it does not give a constructor, but a ready-to-use object, our client, which we can give back to C ++. You can do this, for example, like this:
var app = Module.makeApp(client, …)
Suppose we have a factory that creates our application, and it takes its dependencies into parameters, for example, client and something else. When this function works, we get the object of our application, which already contains the API that we need. You can do the opposite:
val client = val::global(″client″);
client.call(″get″, val(...) );
Directly from C ++, take our client from the global browser scope. Moreover, in place of the client, there can be any browser API, starting from the console, ending with the DOM API, WebRTC - whatever you like. Next, we call the methods that this object has, and we wrap all the values in the magic class val, which Emscripten provides us with.
Binding errors
In general, that’s all, but when you start development, binding errors await you. They look something like this:

Emscripten tries to help us and explain what is going wrong. If this is all summed up, then you need to make sure that they coincide (it is easy to seal up and get a binding error):
- Names
- Types
- Number of parameters
Embind syntax is unusual not only for front-end vendors, but also for people who deal with C ++. This is a kind of DSL in which it is easy to make a mistake, you need to follow this. Speaking about interfaces, when you implement some kind of interface in JavaScript, it is necessary that it exactly matches what you described in your contract.
We had an interesting case. My colleague Jura, who was involved in the project on the C ++ side, used Extend to test his modules. They worked perfectly for him, so he committed them and passed them to me. I used implement to integrate these modules into a JS project. And they stopped working for me. When we figured it out, it turned out that when binding in the names of the functions, we got a typo.
As the name implies, Extend is an extension of the interface, so if you have sealed it somewhere, Extend will not throw an error, it will decide that you just added a new method, and that's all right.
That is, it hides the binding errors until the method itself is called. I suggest using Implement in all cases where it suits you, since it immediately checks the correctness of the forwarded interface. But if you need Extend, you must cover with tests the call of each method so as not to mess it up.
Extend and ES6
Another problem with Extend is that it does not support ES6 classes. When you inherit an object derived from an ES6 class, Extend expects all properties to be enumerable in it, but with ES6 it is not. The methods are in the prototype and they have enumerable: false. I use a crutch like this, in which I go over the prototype and turn on enumerable: true:
function enumerateProto(obj) {
Object.getOwnPropertyNames(obj.prototype)
.forEach(prop =>
Object.defineProperty(obj.prototype, prop,
{enumerable: true})
)
}
I hope someday I can get rid of it, as there is talk in the Emscripten community about improving support for ES6.
RAM
Speaking about C ++, one cannot help but mention memory. When we checked everything on SD-quality video, everything was fine with us, it worked just perfect! As soon as we did the FullHD test, there was a lack of memory error. It doesn’t matter, there is the TOTAL_MEMORY option, which sets the starting memory value for the module. We made half a gigabyte, everything is fine, but somehow it's inhumane for users, because we reserve the memory for everyone, but not everyone has a subscription to FullHD content.
There is another option - ALLOW_MEMORY_GROWTH. It allows you to grow memory
gradually as needed. It works like this: Emscripten by default gives the module 16 megabytes for operation. When you all used them, a new piece of memory is allocated. All old data is copied there, and you still have the same amount of space for new ones. This happens until you reach 4 GB.
Suppose you allocated 256 megabytes of memory, but you know for sure that you thought that your application has enough 192. Then the rest of the memory will be used inefficiently. You highlighted it, took it from the user, but do nothing with it. I would like to somehow avoid this. There is a small trick: we begin work with the memory increased by one and a half times. Then in the third step we reach 192 megabytes, and this is exactly what we need. We have reduced memory consumption by that remainder and saved unnecessary memory allocation, and the further, the longer they take. Therefore, I recommend using both of these options together.
Dependency injection
It would seem that was all, but then the rake went a little more. There is a problem with Dependency Injection. We write the simplest class in which a dependency is needed.
class App {
constructor(httpClient) {
this.httpClient = httpClient
}
}
For example, we pass our HTTP client to our application. We save in the class property. It would seem that everything will work well.
Module.App.extend(
″App″,
new App(client)
)
We inherit from the C ++ interface, first create our object, pass the dependency to it, and then inherit. At the time of inheritance, Emscripten does something incredible with the object. It is easiest to think that it kills an old object, creates a new one based on its template and drags all public methods there. But at the same time, the state of the object is lost, and you get an object that is not formed and does not work correctly. Solving this problem is quite simple. We must use a constructor that works after the inheritance stage.
class App {
_construct(httpClient) {
this.httpClient = httpClient
this._parent._construct.call(this)
}
}
We do almost the same thing: we store the dependency in the field of the object, but this is the object that turned out after inheritance. We must not forget to forward the constructor call to the parent object, which is located on the C ++ side. The last line is an analogue of the super () method in ES6. This is how inheritance happens in this case:
const appConstr = Module.App.extend(
″App″,
new App()
)
const app = new appConstr(client)
First, we inherit, then create a new object into which the dependency is already passed, and this works.
Pointer Trick
Another problem is passing objects by pointer from C ++ to JavaScript. We already did an HTTP client. For simplicity, we have missed one important detail.
std::string get(std::string url)
The method returns the value immediately, that is, it turns out that the request should be synchronous. But after all, AJAX requests for AJAX and that they are asynchronous, so in real life the method will return either nothing, or we can return the request ID. But in order to have someone to return the answer, we pass the listener as the second parameter, in which there will be callbacks from C ++.
void get(std::string url, Listener listener)
In JS, it looks like this:
function get(url, listener) {
fetch(url).then(result) => {
listener.onResult(result)
})
}
We have a get function that takes this listener object. We start the file download and hang up callback. When the file is downloaded, we pull the desired function from the listener and pass the result to it.
It would seem that the plan is good, but when the get function completes, all local variables will be destroyed, and along with them the function parameters, that is, the pointer will be destroyed, and runtime emscripten will destroy the object on the C ++ side.
As a result, when it comes to calling the line listener.onResult (result), listener will no longer exist, and when accessing it, a memory access error will occur that will lead to the application crash.
I would like to avoid this, and there is a solution, but it took several weeks to find it.
function get(url, listener) {
const listenerCopy = listener.clone()
fetch(url).then((result) => {
listenerCopy.onResult(result)
listenerCopy.delete()
})
}
It turns out there is a method for cloning a pointer. For some reason, it is not documented, but it works fine, and allows you to increase the reference count in the Emscripten pointer. This allows us to suspend it in a closure, and then, when we launch our callback, our listener will be accessible by this pointer and we can work as we need.
The most important thing is not to forget to delete this pointer, otherwise it will lead to a memory leak error, which is very bad.
Fast write to memory
When we download videos, these are relatively large amounts of information, and I would like to reduce the amount of copying data back and forth in order to save both memory and time. There is one trick on how to write a large amount of information directly to WebAssembly memory from JavaScript.
var newData = new Uint8Array(…);
var size = newData.byteLength;
var ptr = Module._malloc(size);
var memory = new Uint8Array(
Module.buffer, ptr, size
);
memory.set(newData);
newData is our data as a typed array. We can take its length and request the allocation of memory of the size we need from the WebAssembly module. The malloc function will return a pointer to us, which is just the index of the array that contains all the memory in WebAssembly. From the JavaScript side, it just looks like an ArrayBuffer.
By the next step, we will cut a window into this ArrayBuffer of the right size from a certain place and copy our data there. Despite the fact that the set operation has copy semantics, when I looked at this section in the profiler, I did not see a long process. I think that the browser optimizes this operation with the help of move-semantics, that is, transfers the ownership of memory from one object to another.
And in our application, we also rely on move semantics to save memory copying.
Adblock
An interesting problem, rather, on the change, with Adblock. It turns out that in Russia all the popular blockers receive a subscription to the RU Adlist, and it has such a wonderful rule that prohibits downloading WebAssembly from third-party sites. For example, with a CDN.

The way out is not to use the CDN, but to store everything on your domain (this does not suit us). Or rename the .wasm file so that it does not fit this rule. You can still go to the forum of these comrades and try to convince them to remove this rule. I think they justify themselves by fighting the miners this way, though I don’t know why the miners cannot guess to rename the file.
Production
As a result, we went into production. Yes, it was not easy, it took 8 months and I want to ask myself if it was worth it. In my opinion - it was worth:
No need to install
We got that our code is delivered to the user without installing any programs. When we had a browser plug-in, the user had to download and install it, and this is a huge filter for technology distribution. Now the user just watches the video on the site and does not even understand that a whole machinery works under the hood, and that everything is complicated there. The browser just downloads an additional file with the code, like a picture or .css.
Unified code base and debugging on different platforms
At the same time, we were able to maintain our single code base. We can twist the same code on different platforms and it has repeatedly happened that bugs that were invisible on one of the platforms appeared on the other. And thus, we can detect hidden bugs with different tools on different platforms.
Quick release
We got a quick release, since we can be released as a simple web-application and update C ++ code with each new release. It does not compare with how to release new plugins, a mobile application or a SmartTV application. The release depends only on us: when we want, then it will be released.
Quick feedback
And that means quick feedback: if something goes wrong, we can find out during the day that there is a problem and respond to it.
I believe that all these problems were worth these advantages. Not everyone has a C ++ application, but if you have one and you want it to be in the browser - WebAssembly is a 100% use case for you.
Where to apply
Not everyone writes in C ++. But not only C ++ is available for WebAssembly. Yes, this is historically the very first platform that was still available in asm.js, an early Mozilla technology. By the way, therefore, it has pretty good tools, as they are older than the technology itself.
Rust
The new Rust language, which is also being developed by Mozilla, is now catching up with and overtaking C ++ in terms of tools. Everything goes to the point that they will make the coolest development process for WebAssembly.
Lua, Perl, Python, PHP, etc.
Almost all the languages that are interpreted are also available in WebAssembly, since their interpreters are written in C ++, they were simply compiled into WebAssembly and now you can twist PHP in a browser.
Go
In version 1.11 they made a beta version of compilation in WebAssembly, in 2.0 they promise release support. Their support appeared later, because WebAssembly does not support garbage collector, and Go is a managed-memory language. So they had to drag their garbage collector under WebAssembly.
Kotlin / Native
About the same story with Kotlin. Their compiler has experimental support, but they will also have to do something with the garbage collector. I don’t know what status there is.
3D graphics
What else can you think of? The first thing that revolves in the language is 3D applications. And, indeed, historically, asm.js and WebAssembly began with porting games to browsers. And it is not surprising that now all popular engines have export to WebAssembly.

Data processing locally
You can also think of processing user data right in his browser, on his computer: take a downloaded image or from a camera, record sound, process video. Read the archive uploaded by the user, or collect it yourself from a bunch of files and upload it to the server with one request.
Neural networks
This picture shows almost all the architecture of neural networks. And, indeed, you can take your neural network, train and give to the client so that it processes live stream from a video camera or microphone. Or, for example, track the movement of the user's mouse and make gesture control; face recognition - the possibilities are almost endless.
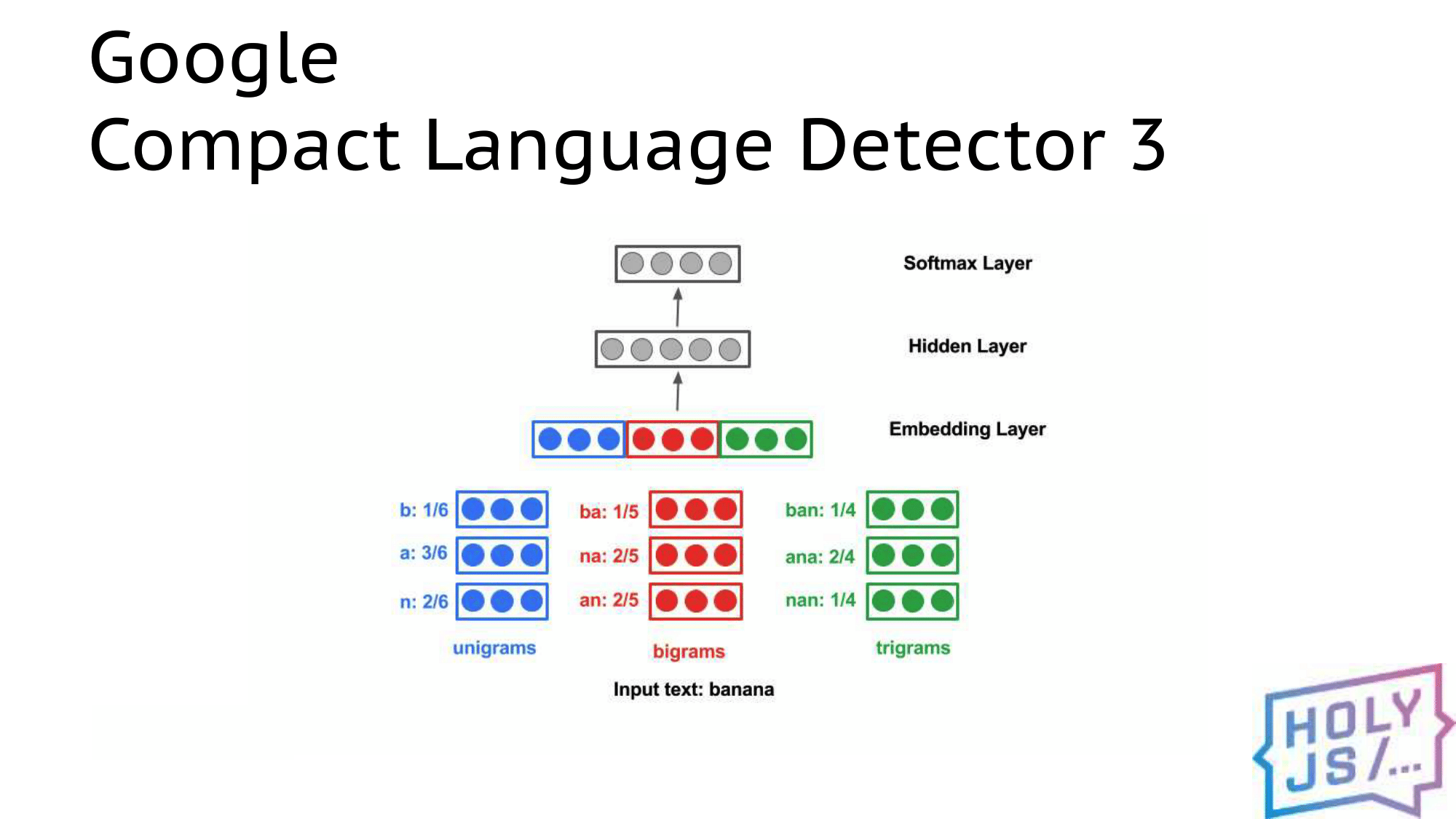
For example, the piece of Google Chrome that is responsible for determining the language of the text is already available as a WebAssembly library. It can be connected as an npm module and that’s it, you use Wasm, but you work with regular JS. You do not communicate with neural networks, C ++ or anything else - everything is available out of the box.
There is a popular HunSpell spell-checking library - just install and use it as a Wasm module.
Cryptography
Well, the first rule of cryptography is "Do not write your cryptography." If you want to sign user data, encrypt something and transfer it in such a form to the server, generate strong passwords or you need GOST - connect OpenSSL. There is already an instruction on how to compile under WebAssembly. OpenSSL is reliable code that has been tested by thousands of applications, no need to invent anything.
Removal of calculations from the server
A cool use case is on wotinspector.com. This is a service for World of Tanks players. You can upload your replay, analyze it, statistics on the game will be collected, a beautiful map will be drawn, in general, a very useful service for professional players.
One problem - analyzing such a replay takes a lot of resources. If this happened on the server, for sure it would be a closed paid service, not accessible to everyone. But the author of this service, Andrey Karpushin, wrote business logic in C ++, compiled it into WebAssembly, and now the user can start processing directly in his browser (and send it to the server so that other users can also access them).
This is an interesting case in terms of site monetization. Instead of taking money from users, we use the resources of their computer. This is similar to monetization using a miner. But unlike a miner, which simply burns users’s electricity, and in return brings a penny to the site’s authors, we do a service that does the work the user really needs. That is, the user agrees to share resources with us. Therefore, this circuit works.
Libraries
Also in the world there are a bunch of libraries written over a long history in C, C ++. For example, the FFmpeg project, which is a leader in video processing. Many people use video processing programs where inside ffmpeg. And now you can run it in a browser and encode the video. It will be long and slow, yes, but if you make a service that generates avatars or three-second videos, then browser resources will be sufficient.

The same with audio - you can record in a compressed format and send small files to the server already. And the OpenCV library - the leader in machine vision, is available in WebAssembly, you can do face recognition and control hand gestures. You can work with PDF. You can use the SQLite file database, which supports real SQL. Porting SQLite for WebAssembly was done by Emscripten, he probably tested the compiler on it.
Node.js
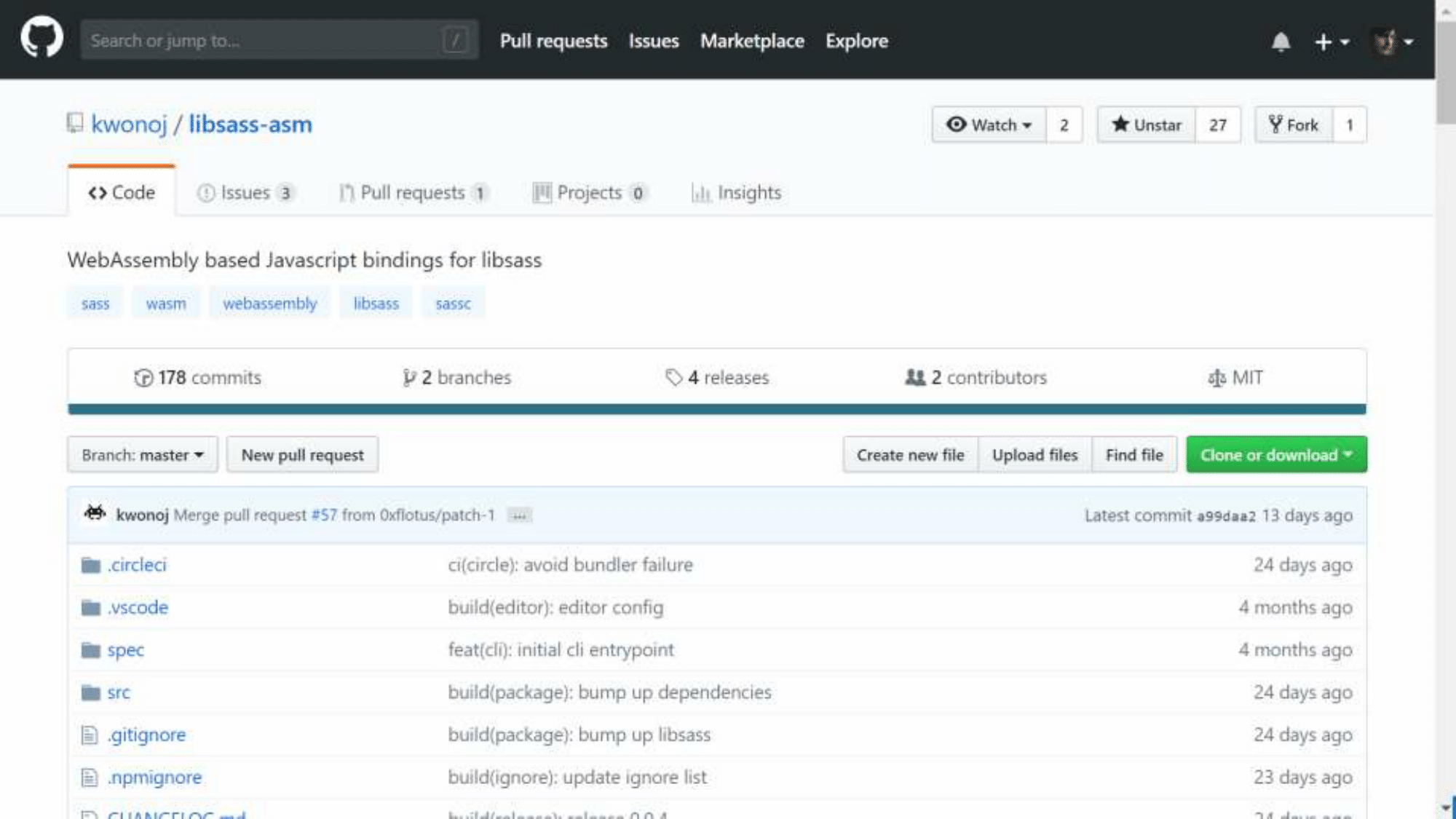
Not only does the browser receive bonuses from WebAssembly, you can also use Node.js. Probably everyone knows Sass - the css preprocessor. It was written in Ruby and then rewritten in C ++ for speed (libsass project). But no one wants to run a separate program for processing source codes, you want to integrate into the bundle assembly process with Webpack, and for this you need a module for Node.js. The node-sass project solves this problem, it is a JS wrapper for this library.
The library is native, which means we must compile it under the platform under which the user will run it. And that brings us to the version matrix. These columns need to be multiplied:

This leads to the fact that for one release of node-sass you need to do about 100 compilations for each combination from the table. Then all this needs to be stored, and these are tens of megabytes of files for each (even minor) release. How WebAssembly solves this problem: it collapses the entire table into a single file, because the WebAssembly executable is platform independent.
It will be enough to compile the code once and upload only one file to all platforms, regardless of the architecture or version of Node. Such a project already exists, porting under WebAssembly is already being done in the libsass-asm project . The work is carried out recently, and the project really needs assistants to work. This is a great chance to practice with WebAssembly on a real project ...
Application Acceleration
There is a popular Figma application - a graphics editor for web designers. This is to some extent an analogue of Sketch, which works on all platforms, because it runs in the browser. It is written in C ++ (which few people know about), and asm.js. was originally used there. The application is very large, so it did not start quickly.
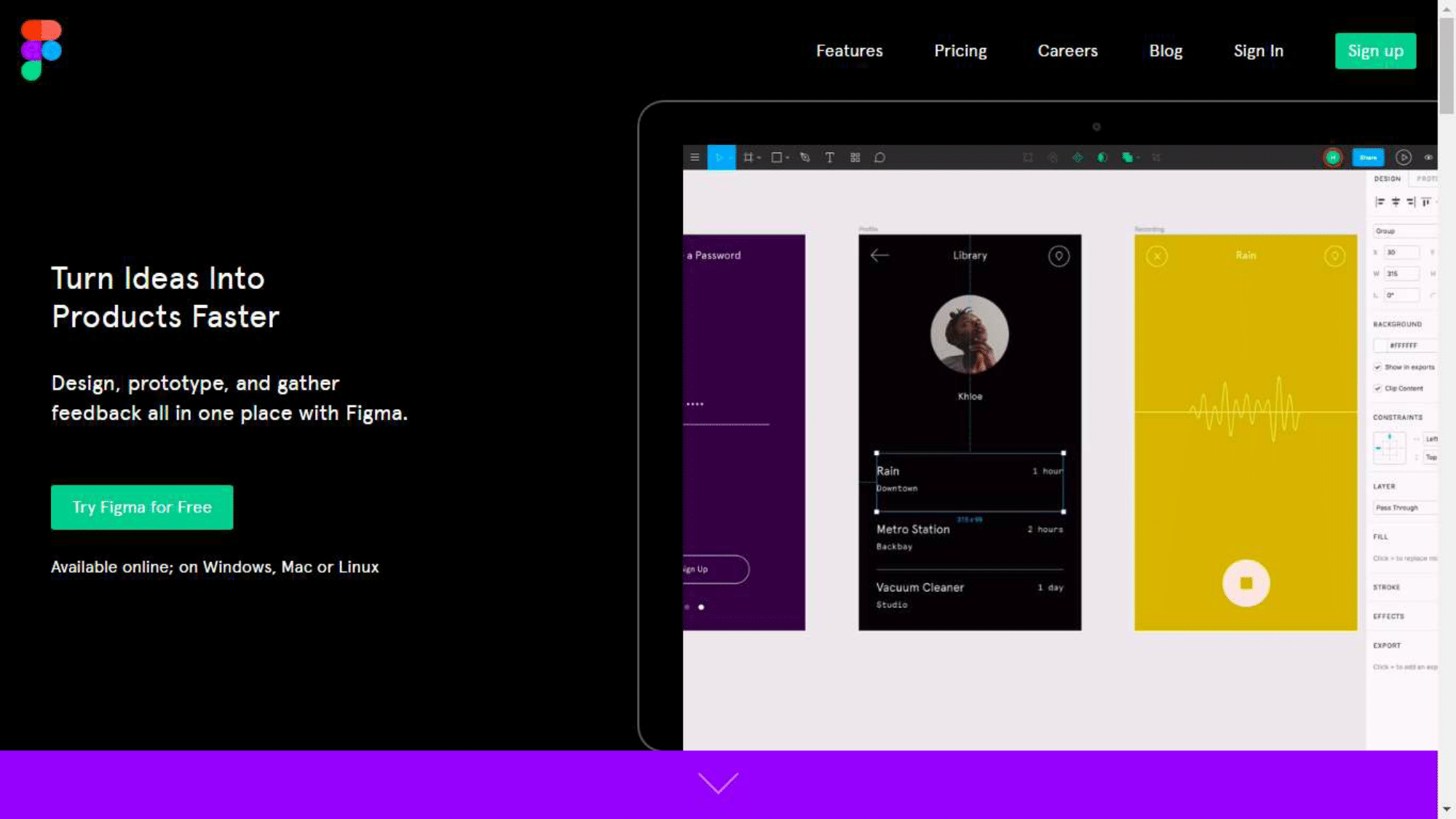
When WebAssembly appeared, the developers recompiled their sources, and the start of the application accelerated 3 times. This is a major improvement for the editor, who should be ready to work as quickly as possible.
Another familiar Visual Studio Code application, despite the fact that it works in Electron, uses native modules for the most critical sections of code, so they have the same problem with a huge number of versions as Node-sass has. Perhaps the developers control only the version of Node, but in order to support OS platforms and architectures, they have to rebuild these modules. Therefore, I am sure that the day is not far off when they will also switch to WebAssembly.
Porting applications to the browser
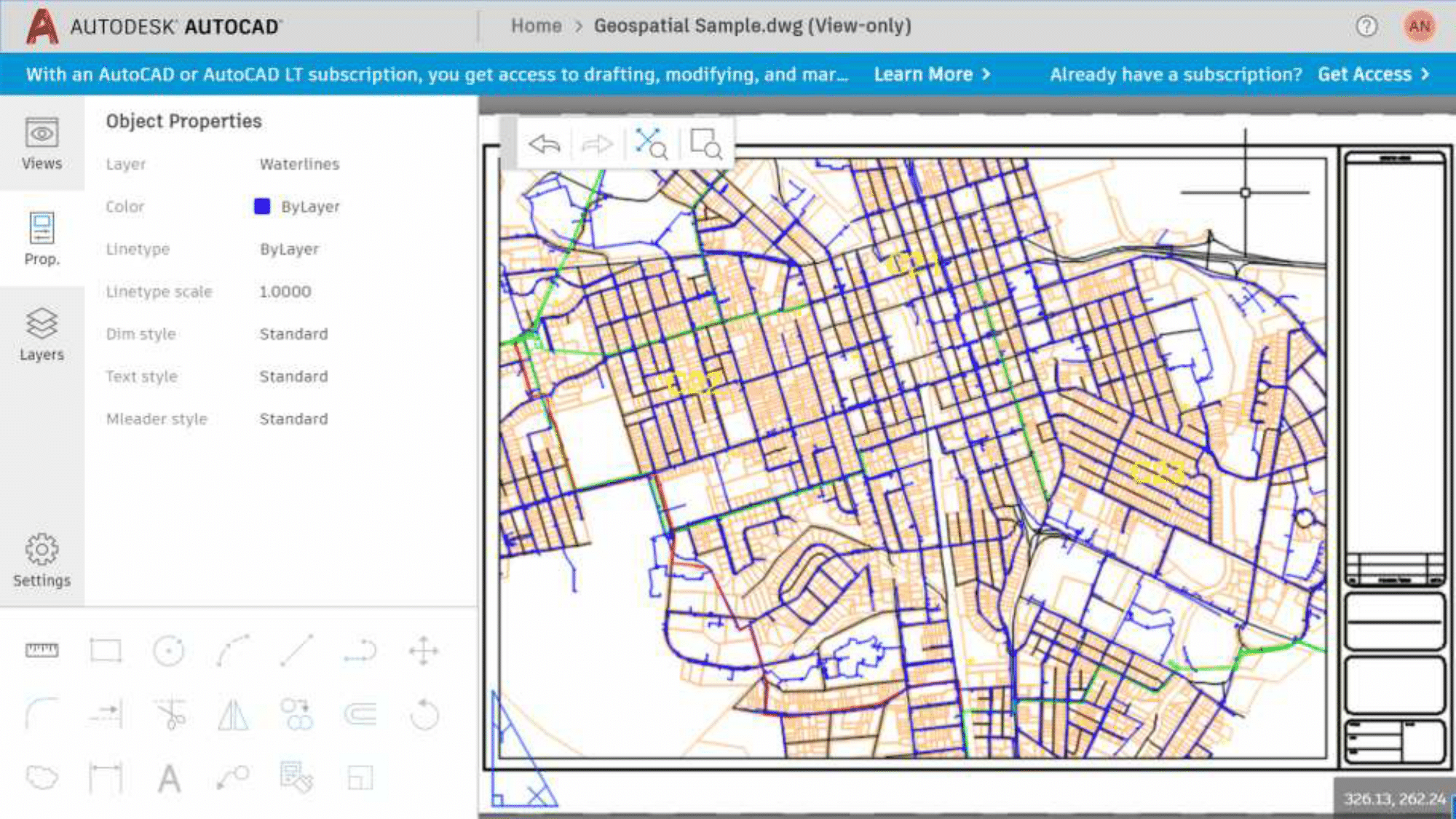
But the coolest example of porting a codebase is AutoCAD. Soft is already 30 years old, it is written in C ++, and this is a huge code base. The product is very popular among designers whose habits have long been established, so the development team would have to do a lot of work to port all the accumulated business logic to JavaScript, when porting to the browser, which made this venture almost hopeless. But now thanks to WebAssembly AutoCAD is available as a web service where you can register and start using it in 5 minutes.
There is a cool demo made by Fabrice Bellar, a unique programmer, in my opinion, because he has done many projects so popular that a regular programmer does, perhaps, alone in his life. I mentioned FFMpeg - this is his project, and his other development is QEMU. Perhaps few have heard of him, but the KVM virtualization system, which is certainly a leader in its field, is based on it.

Since 2011, Bellard has supported the QEMU port for the browser . This means that you can start any system using the emulator directly in your browser. In general, Linux with a console , a real Linux kernel running in a browser without a server, has some kind of additional connection.
You can turn off the Internet, and it will work. There is bash, you can do everything as in normal Linux. There is another demo - with a GUI . You can already launch a real browser in it. Unfortunately, there is no network in the demo, and you won’t be able to discover yourself in it ...
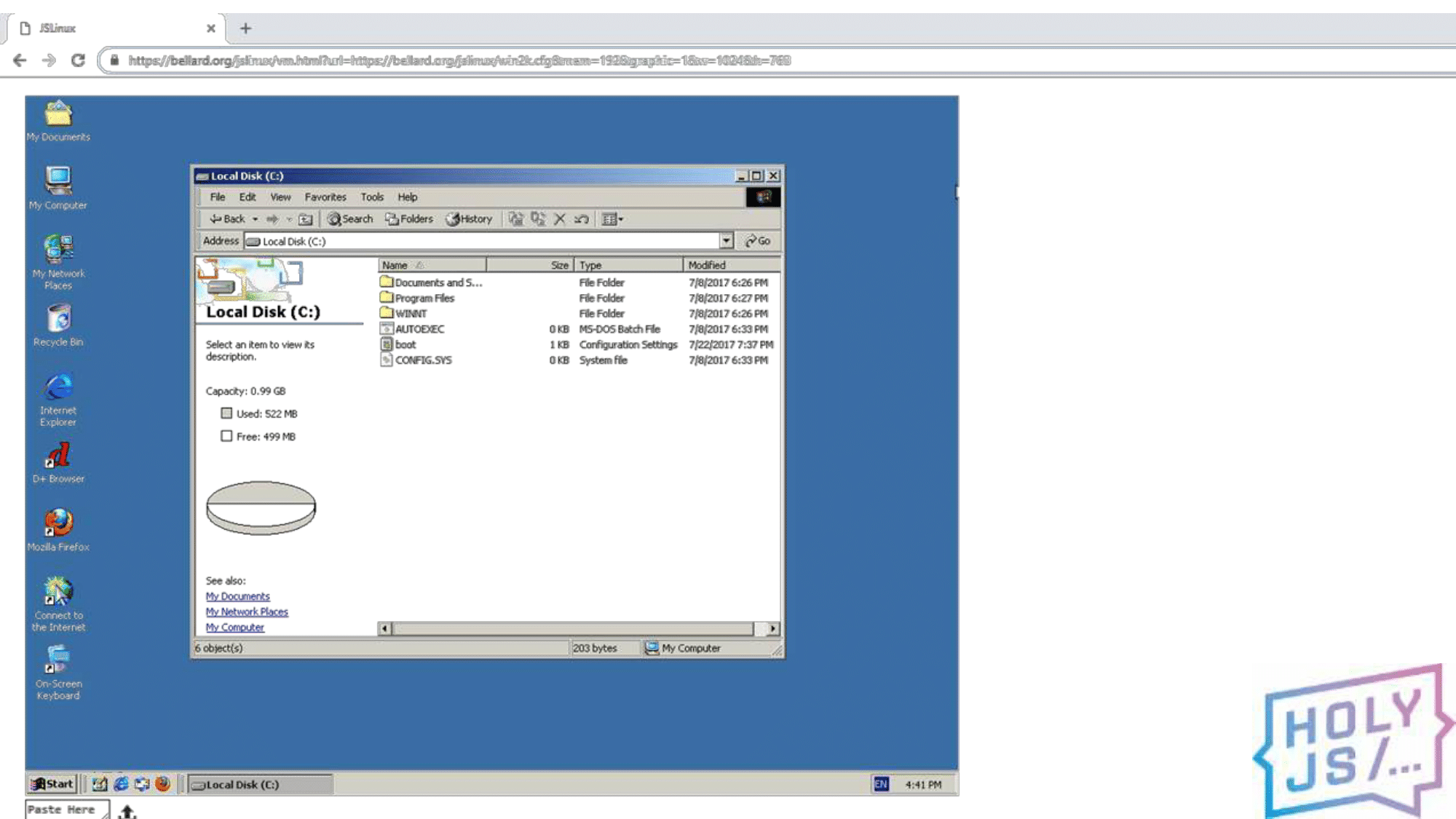
And, to convince you, I’ll show something incredible. This is Windows 2000 , the same one that was 18 years ago, only now it works in your browser. Previously, you needed a whole computer, but now you just need Chrome (or FireFox).
As you can see, there are many applications of WebAssembly, I have listed only what I found myself, and you will have new ideas and you can implement them.
How to implement it at home
I want to give some tips for those who are considering porting their application to WebAssembly. The first thing to start with is the team, of course. The minimum team is two people, one from the side of native technologies and a front-end.
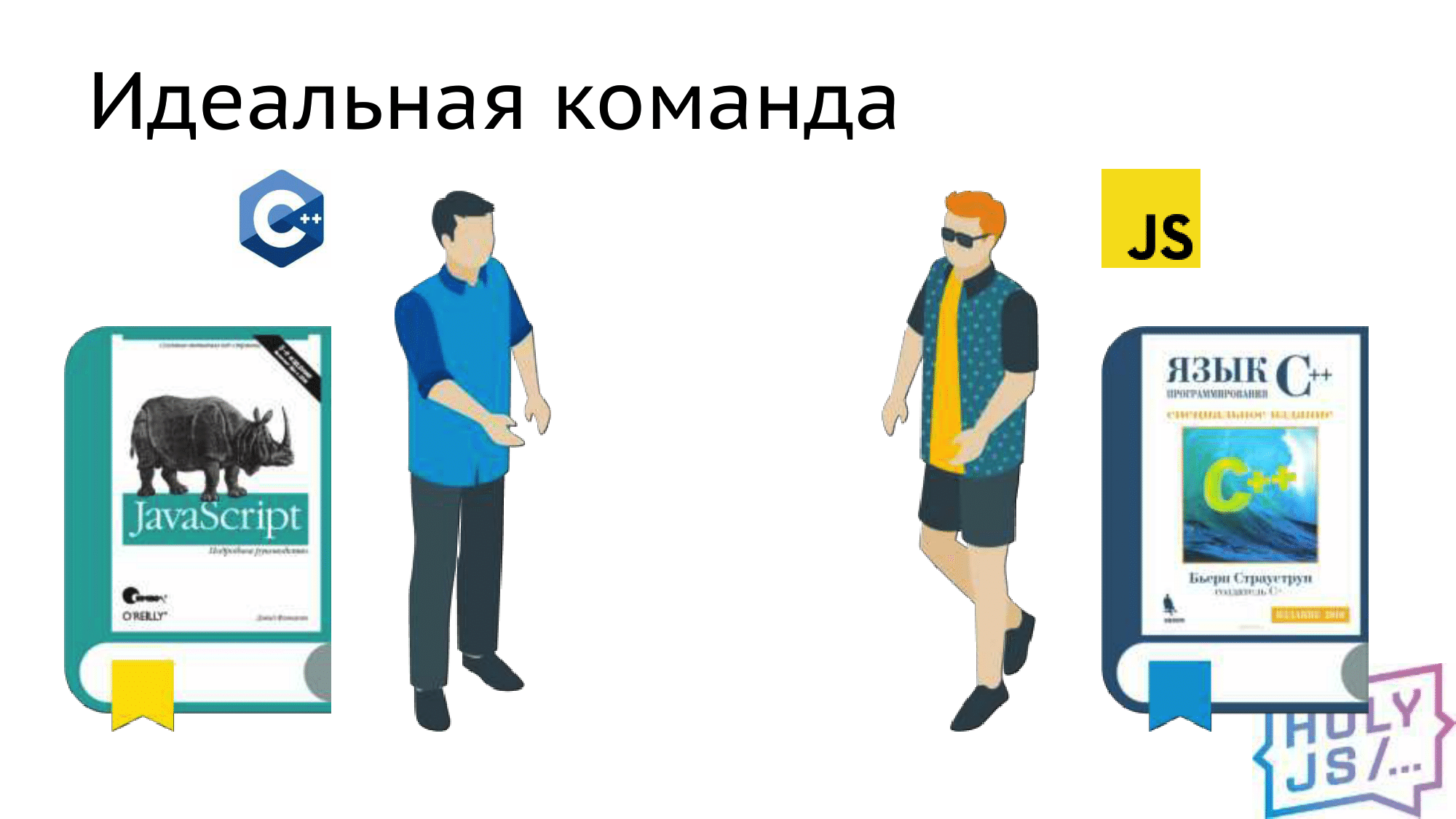
It so happens that C ++ application programmers are not very good at web technologies. Therefore, our task, as front-end, if we find ourselves in such a project is to take on this part of the work. But the ideal team is those people who are interested not only in their platform, but also want to understand the one on the other side of the compiler.
Fortunately, this is exactly what happened in our project. My colleague Jura, a great specialist in C ++, as it turned out, had long wanted to learn JavaScript, and the book of Flanagan helped him a lot in this. I took a volume of Straustrup, and with Yurina's help I began to delve into the basics of C ++. As a result, during the project we talked a lot about each other about our main languages, and we found surprisingly much in common between JS and C ++, no matter how strange this may seem.
And if such a team is selected from you, it will be perfect.
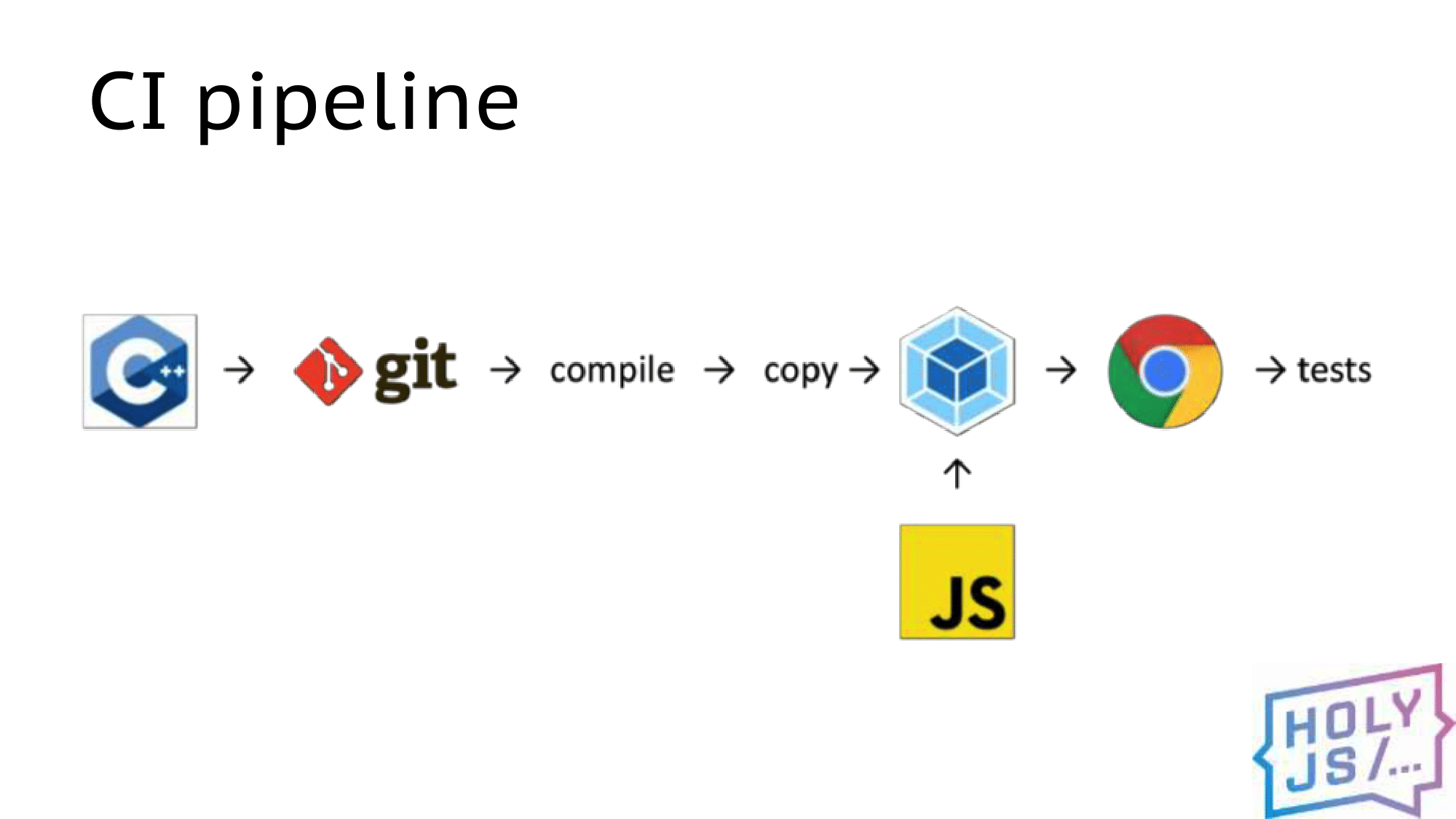
CI Pipeline
What did our daily development process look like? We moved all the JS artifacts to a separate repository, so that it would be more convenient to configure the assembly there via Webpack. When changes appear in the native code, we pull them up, compile (sometimes it takes the most time), and the compilation result is copied to the JS project. Then it is picked up by webpack in watch mode, collects a bundle, and we can run the application in a browser or run tests.
Debugging
Of course, debugging is important to us during development. Unfortunately, this is not very good with this.
You need to enable DevTools experiments in Chrome, and we will see a folder with wasm units on the Sources tab. We see breakpoints (we can stop the browser in some place), but, unfortunately, we see the code in the textual representation of the assembler.
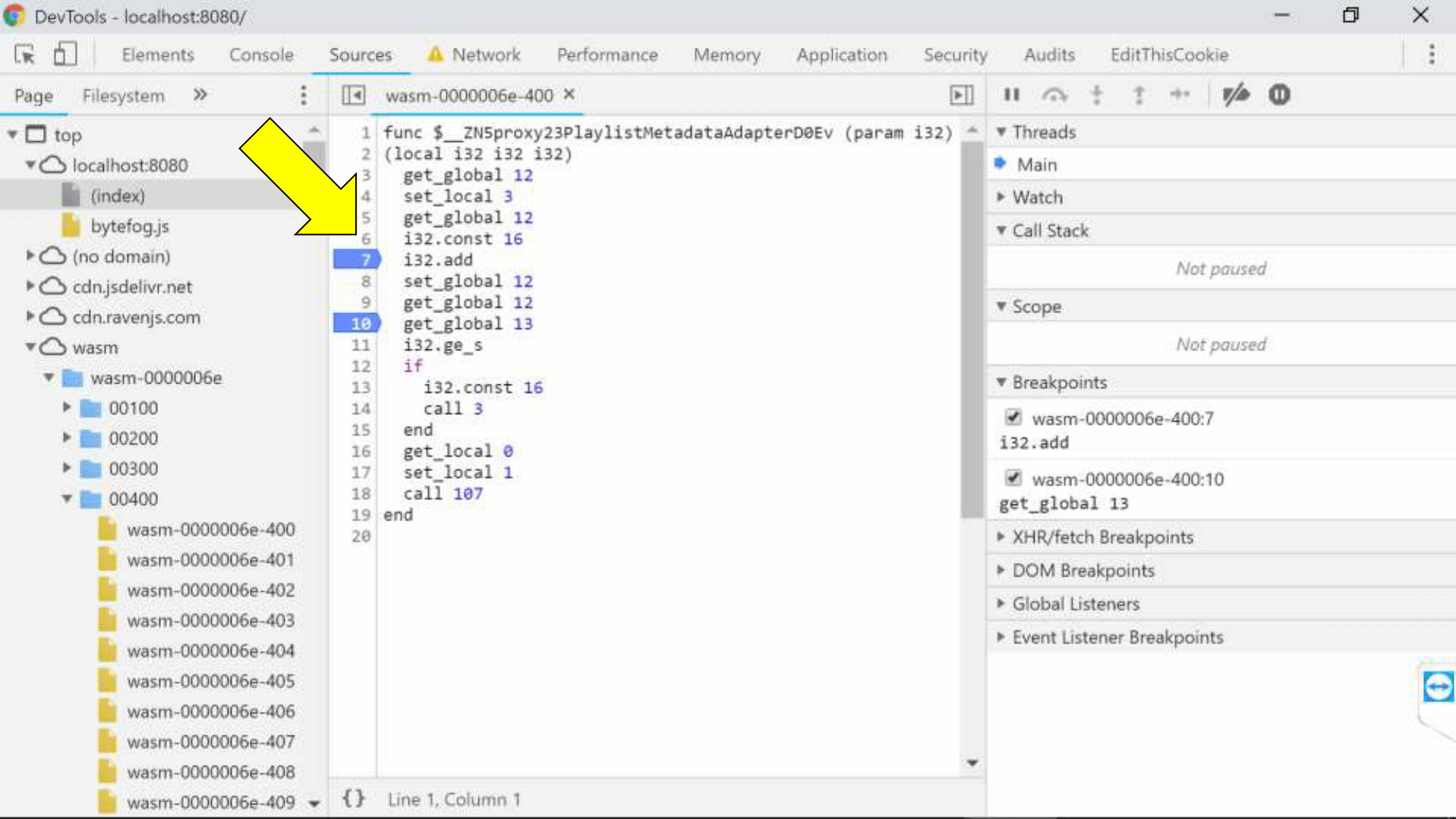
Although our architect Kolya, when he looked at this picture for the first time, he ran a glance over the listing and said: “Look, this is a stacking machine, here we are working with memory, here arithmetic, everything is clear!” In general, Kolya knows how to write for embedded systems, but we don’t, and would like some kind of explicit binding to the source code.
There is a small trick: at the maximum debugging level of -g4, additional comments appear in the wast file, and it looks like this.
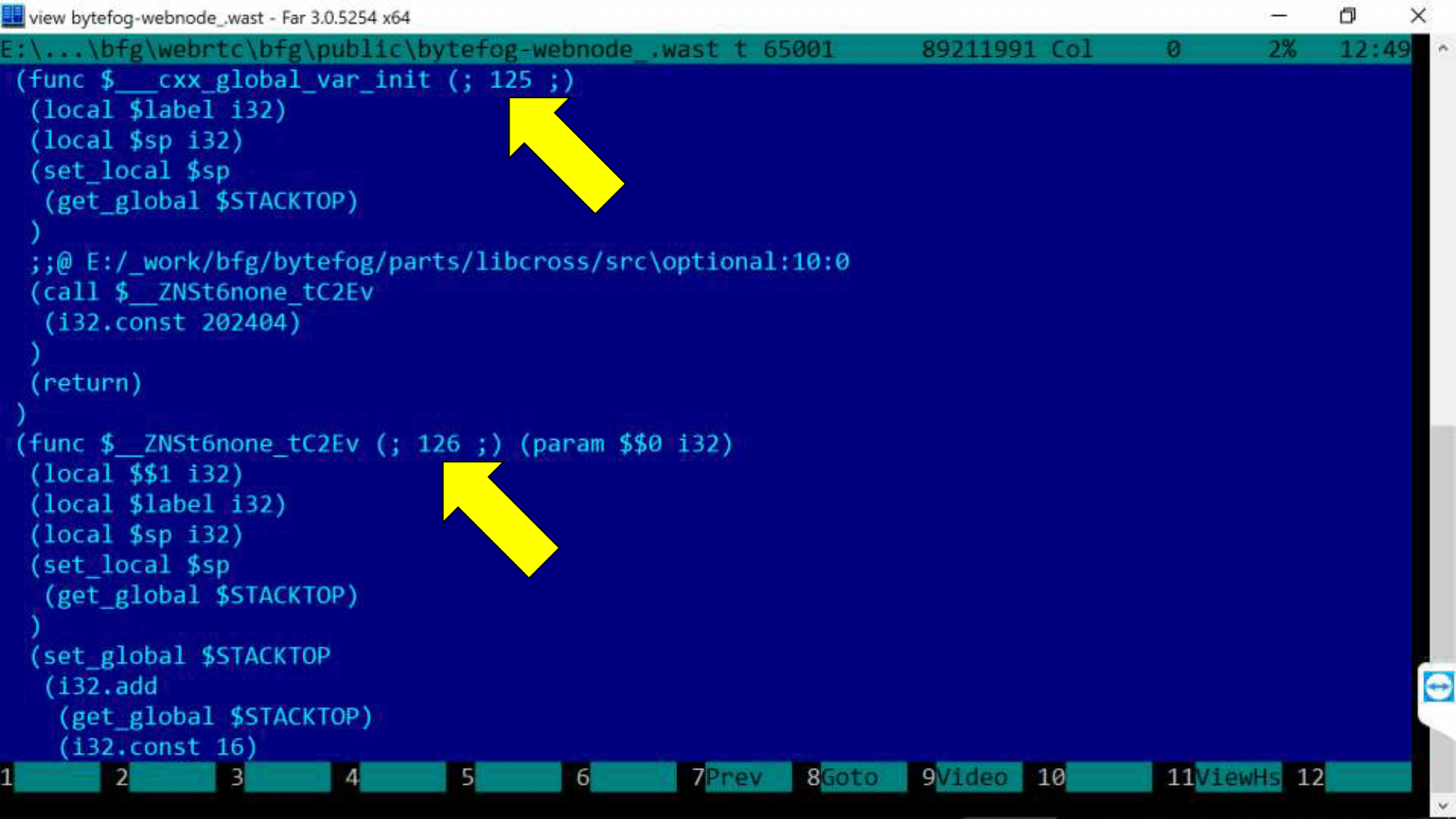
You need an editor that can open a file of 100 megabytes in size (we chose FAR). Numbers are the module numbers we’ve already seen in the Chrome console. E: / _ work / bfg / bytefrog / ... - link to the source code. You can live with this, but I would like to see the real C ++ code directly in the browser debugger. And that sounds like a challenge for SourceMap!
Sourcemap
Unfortunately, there are still problems with them.
- Works only in Firefox.
- --sourcemap-base = http: // localhost option specify that you need to generate SourceMap and the address of the web server where the source will be stored.
- Access to source through HTTP.
- The paths to the source files must be relative.
- On Windows there is a problem with ":" in the paths. All paths are truncated to a colon.
The last two points have affected us. CMake upon assembly builds all paths to an absolute view; as a result, files cannot be found at this URL on a web server. We solved it this way: preprocess the wast-file and bring all the paths to a relative form, removing at the same time the colons. I think you will not come across this.
In summary, it looks like this:

C ++ code in a browser debugger. Now we have seen everything! On the left is the source tree, there are breakpoints, we see a stack trace that brought us to this point. Unfortunately, if we touch any wasm call in stack trace, we fall into assembler, this is an annoying bug, which, I think, will be working.
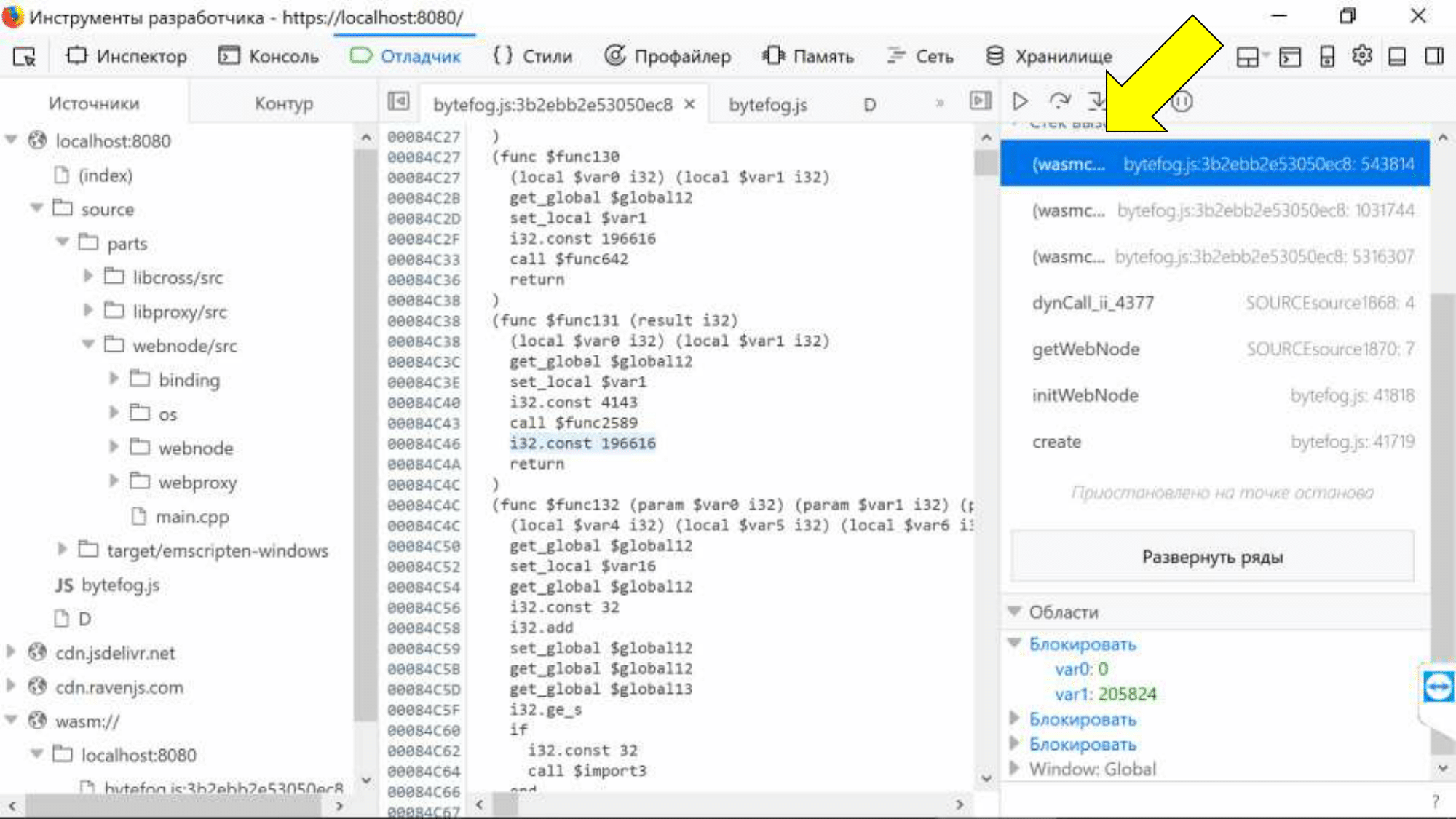
Unfortunately, another bug will not be fixed - SourceMap basically does not support variable binding. We see that local variables have lost not only their names, but also their types. Their meanings are presented as a symbolic whole and we won’t know what was really there.
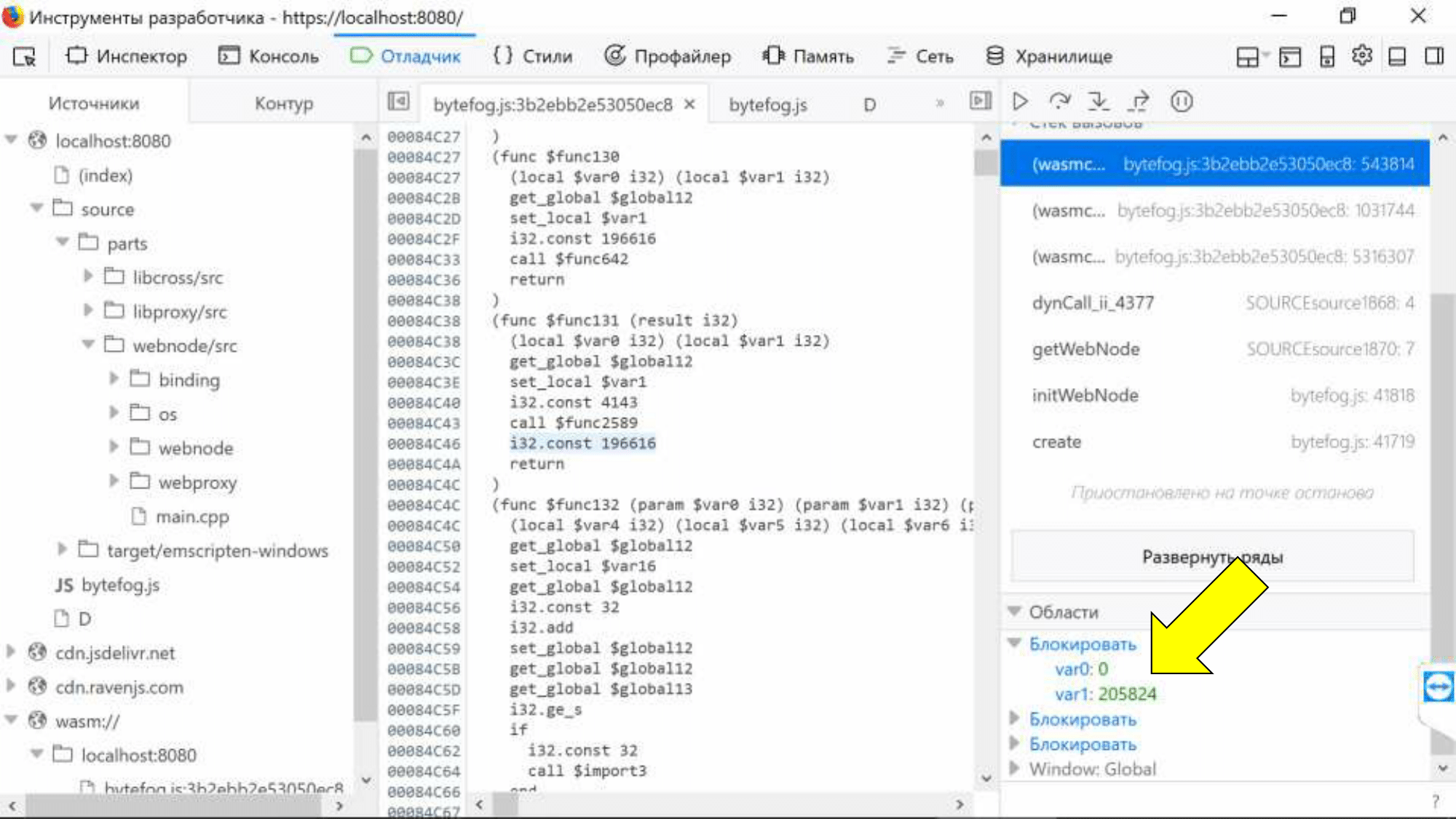
But we can bind them to a specific assembly location using the generated name "var0".
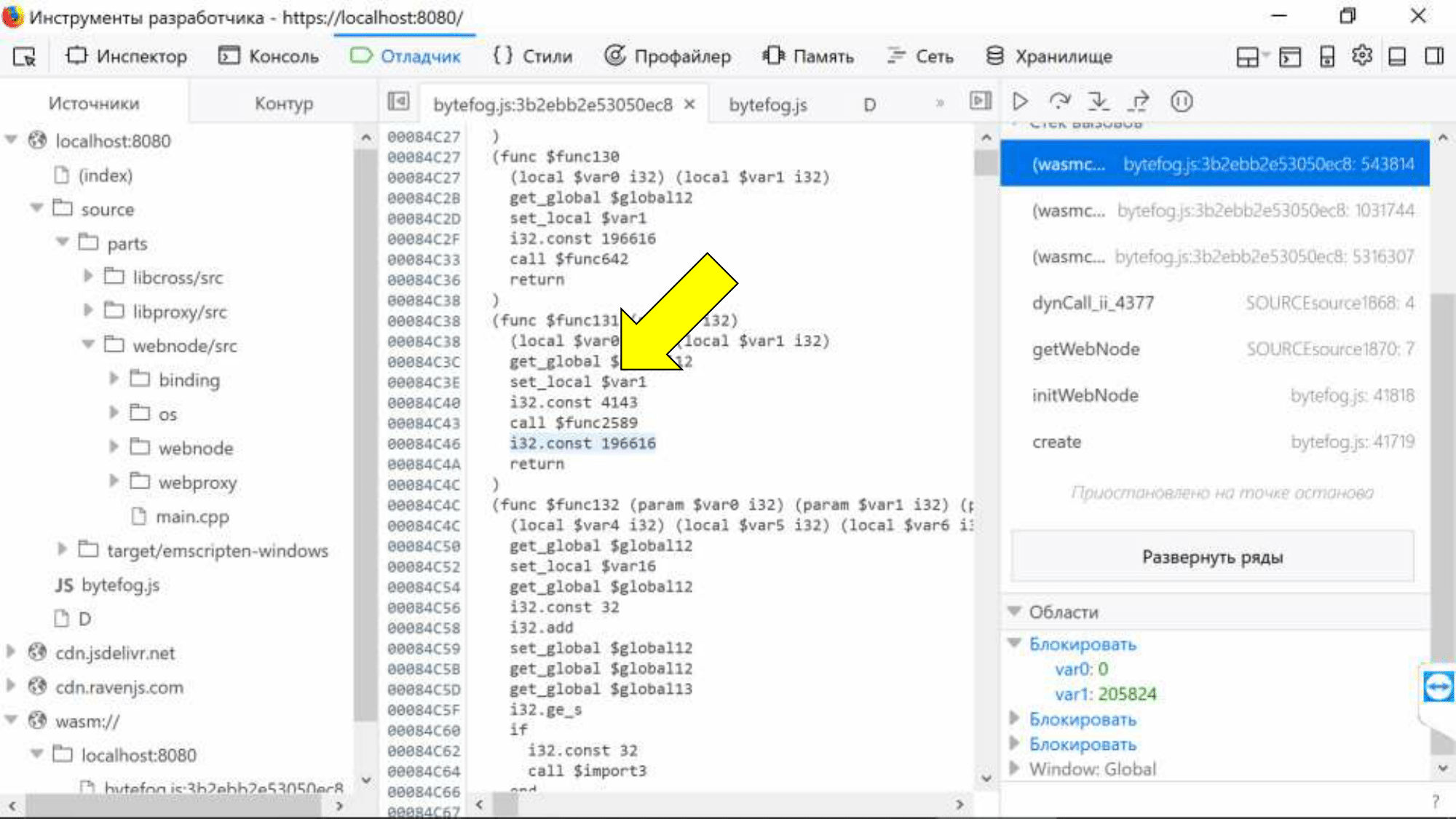
Of course, I would just like to move the mouse over the variable name and see the value. Perhaps in the future they will come up with a new SourceMap format, which will allow to bind not only the code base, but also variables.
Profiler
You can also take a look at the profiler. It works in both Chrome and Firefox. Firefox is better - it "unwinds" the names, and they can be seen as they are in the source code.
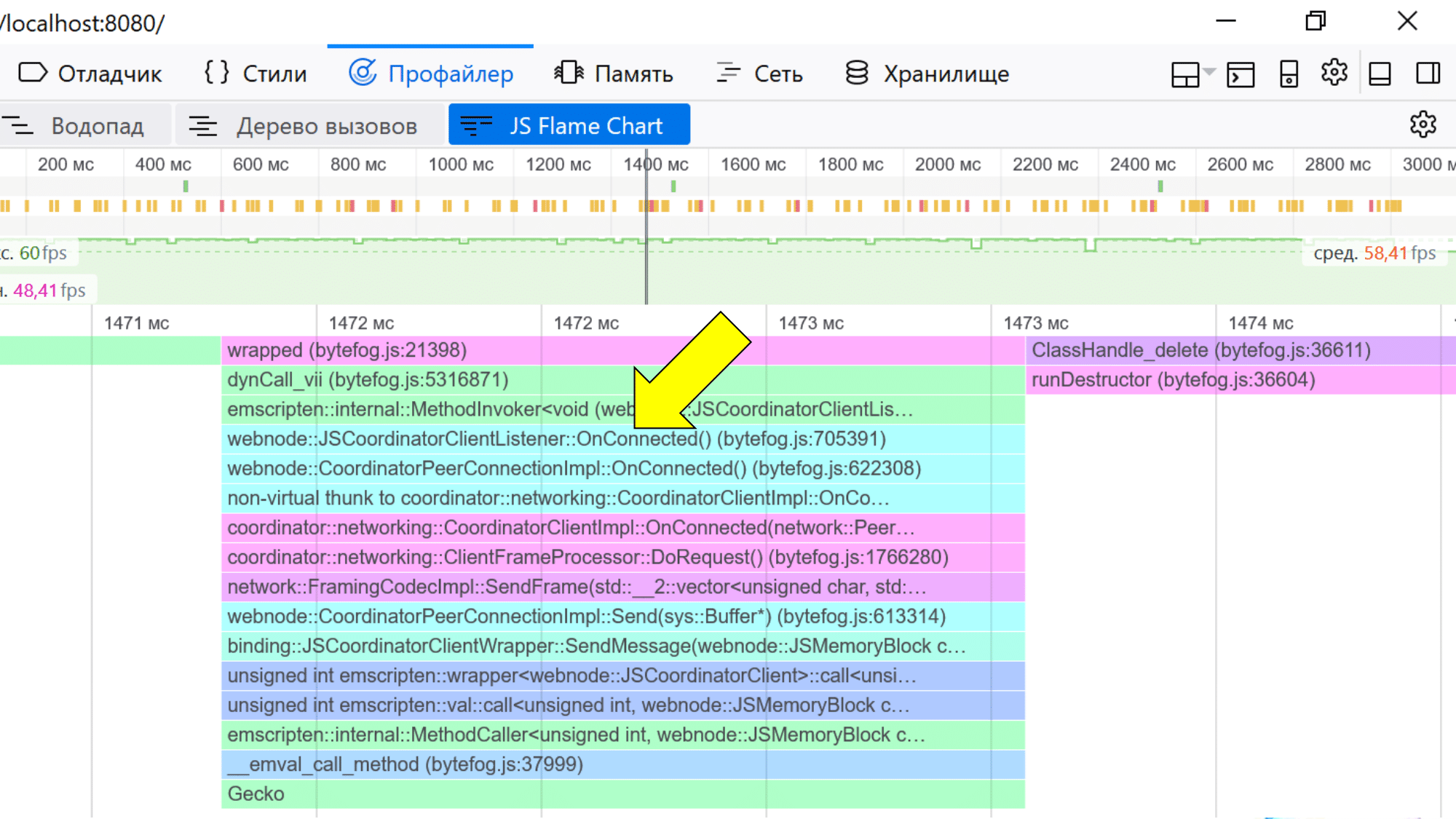
Chrome encodes them a bit (for those who understand, these are Mangled function names), but if you squint, you can understand what they refer to.
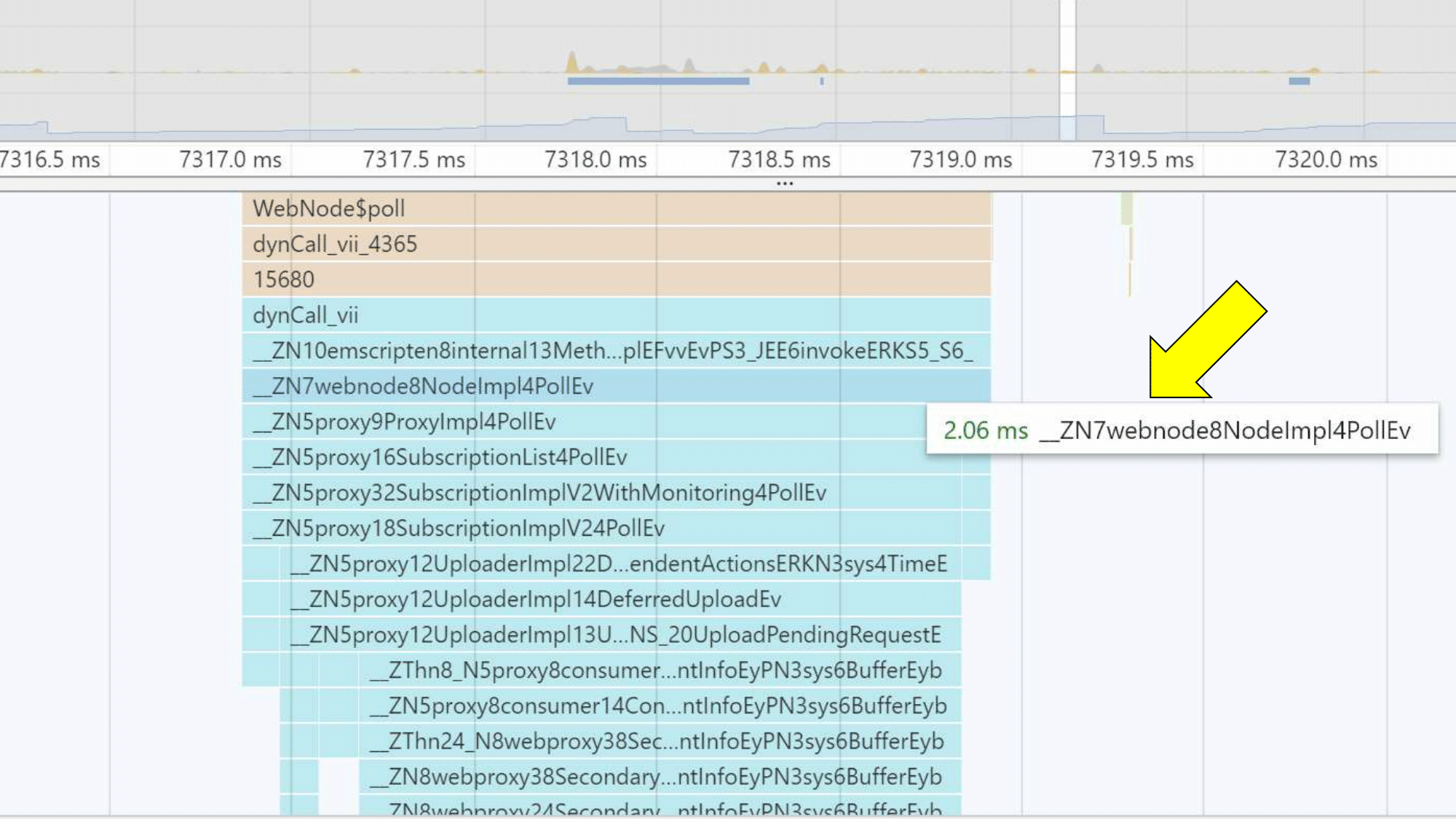
Performance
Talk about performance. This is a complex and multifaceted topic, and here's why:
- Rantime. Measurement of performance depends on the runtime you are using. Measurements in C ++ will differ from measurements in Rust or Go.
- Losses at the JS - Wasm border. Measuring math does not make sense, because performance losses occur at the intersection of the border between JS and Wasm. The more you make calls back and forth, the more you transfer objects, the more the speed sinks. Browsers are now working on this issue, and the situation is gradually improving.
- Technology is evolving. Those measurements that were made today will not make sense tomorrow, and even more so after a couple of months.
- Wasm speeds up the launch of the application. Wasm does not promise to speed up your code or replace JS. The WebAssembly team is focused on speeding up the launch of large application codebases.
- In synthetics, you get speed at the JS level.
We did a simple test: graphic filters for the image.
- wasp_cpp_bench
- Chrome 65.0.3325.181 (64-bit)
- Core i5-4690
- 24gb ram
- 5 measurements; max and min are discarded; averaging
Got these results. Here everything is normalized to the implementation of a similar filter on JS - a yellow column, in all cases exactly one.
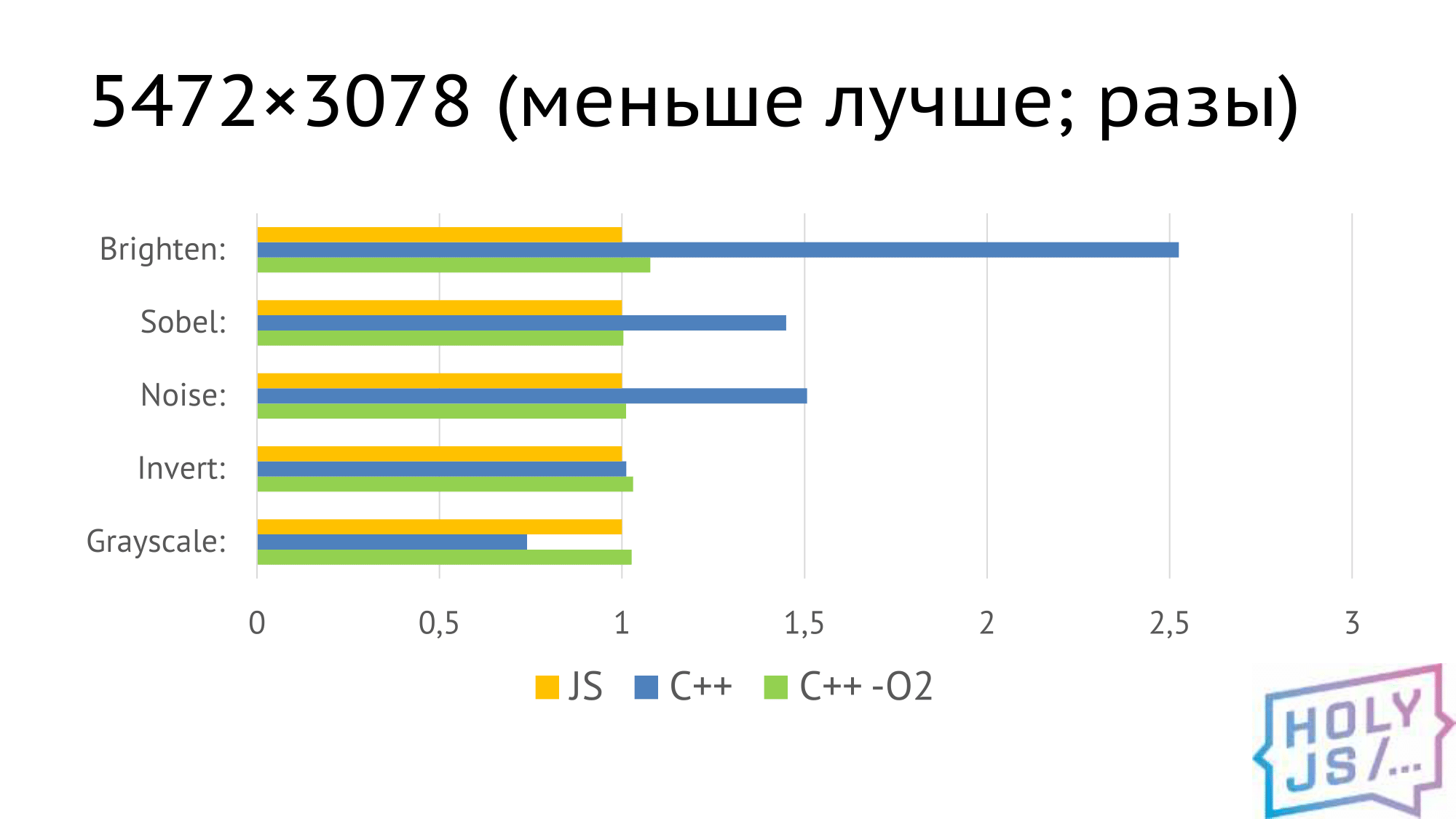
C ++ compiled without optimization behaves in some strange way. This can be seen in the example of the Grayscale filter. Even our C ++ developers could not explain why this is so. But when optimization is turned on (green bar), we get a time that almost coincides with JS. And, looking ahead, we get similar results in native code if we compile C ++ as a native application.
Collection of crashes and errors
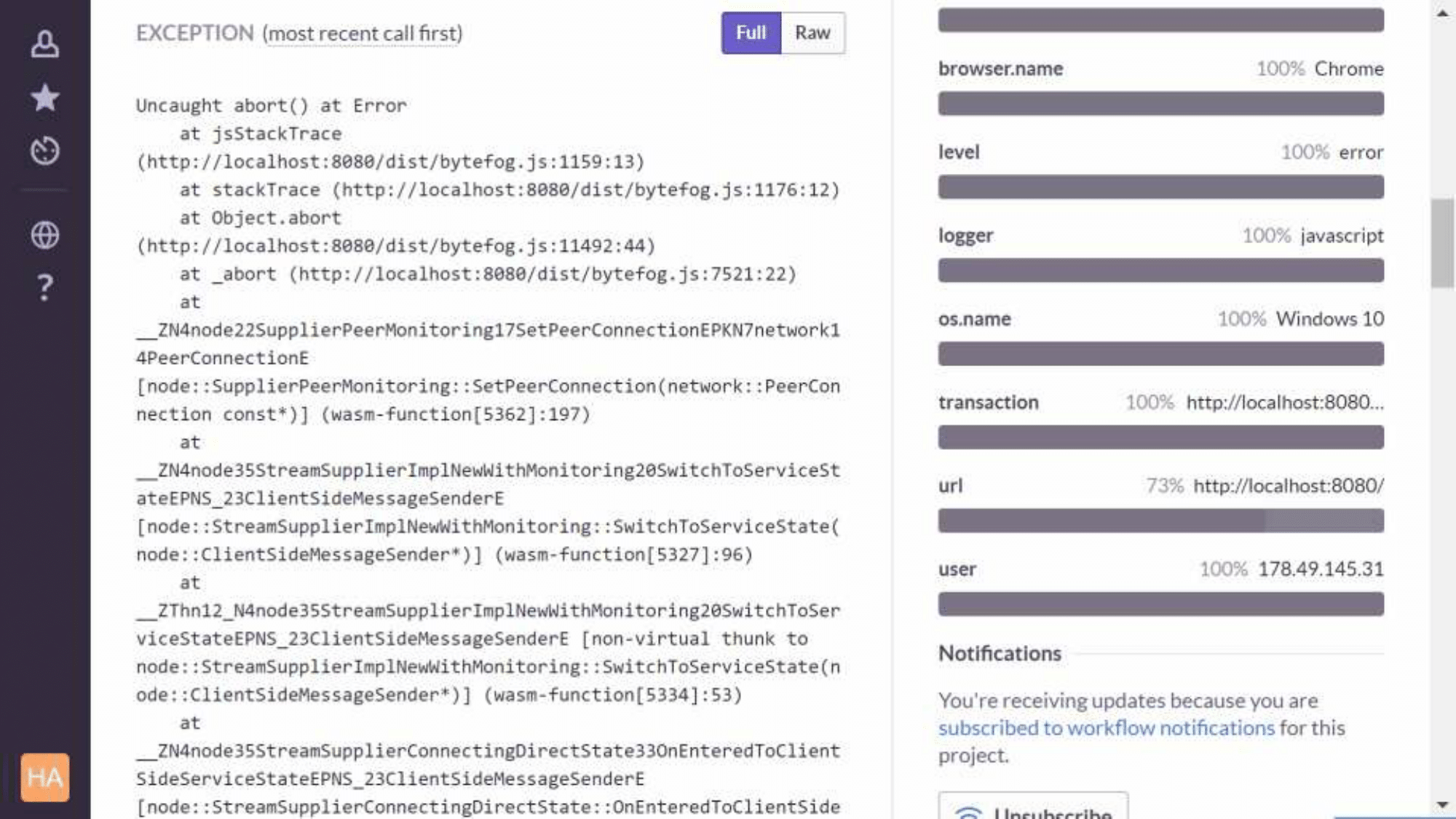
We use Sentry, and there is a problem with it - wasm frames disappear from the stackracks. It turned out that the traceKit library used by the Sentry client — Raven — simply contains a regular expression that doesn't take into account that wasm exists. We made a patch, and, probably, we will send it a pull request soon, but for now we use it with npm install of our JS project.
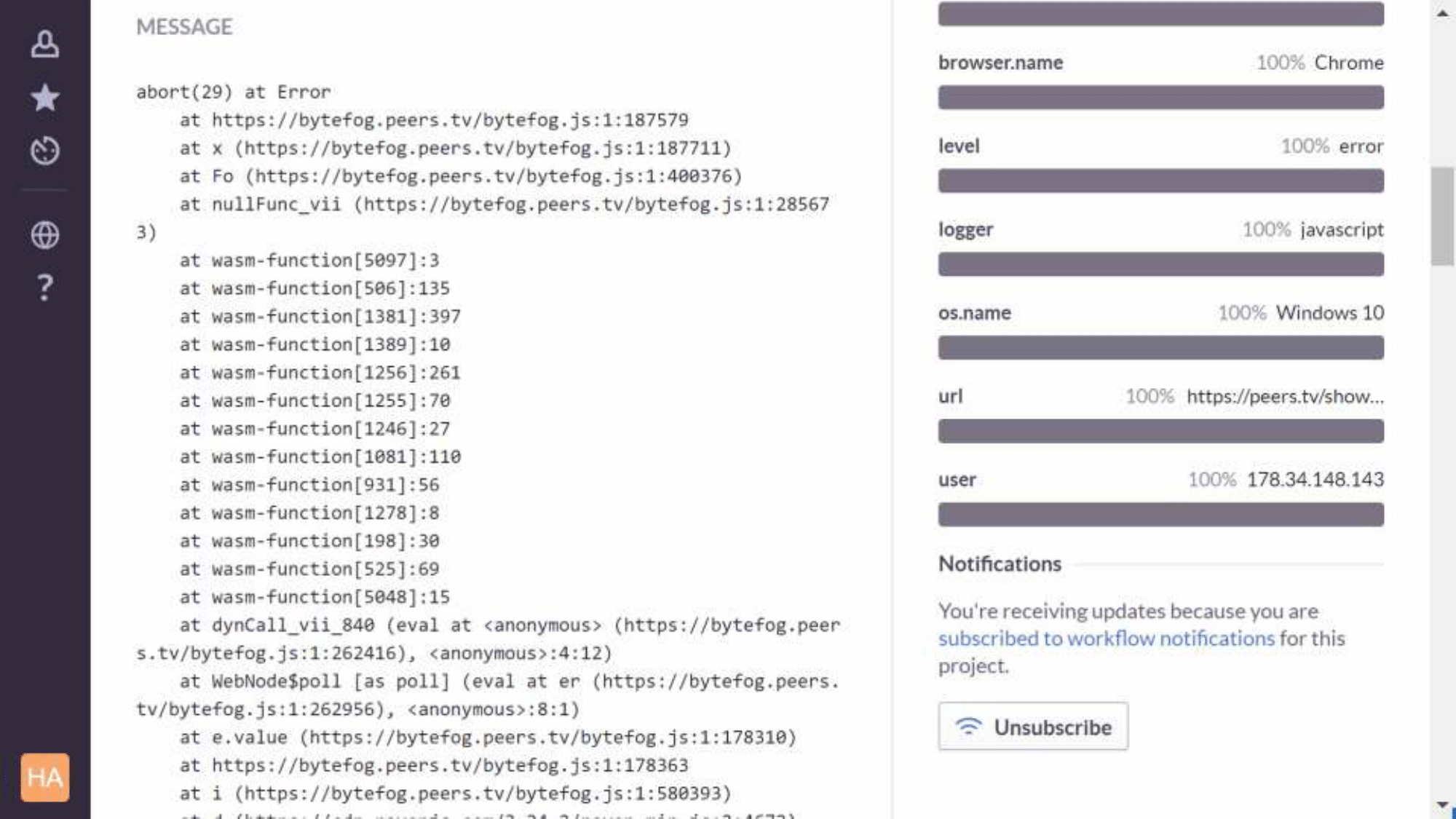
It looks like this. This is the production version, function names are not visible here, only unit numbers. And this is how the debug assembly looks, you can already figure out what went wrong:
Total
- WebAssembly can already be used in battle, and our project has proven it.
- Porting even a large application is real. It took us 8 months, the lion's share of which we spent on refactoring our application in C ++ in order to highlight borders, interfaces, and so on.
- The tools are still weak, but work in this direction is underway, since WebAssembly is actually the future of the web.
- Speed - at JS level. Modern JS-machines optimize the program code to such an extent that it simply "falls into" machine instructions, and runs at the speed with which your processor can.
If you get to work, I recommend:
- Take Emscripten and Embind. These are good and working technologies.
- If you need something strange in Emscripten, take a look at the tests. There is documentation, but it does not cover everything, and the test file contains 3000 lines of all possible situations of using Emscripten.
- Sentry is suitable for collecting errors.
- Debug in Firefox.
Thanks for attention! I am ready to answer your questions.

If you liked this report from the HolyJS conference, pay attention: the next HolyJS will be held on May 24-25 in St. Petersburg . The conference website already contains descriptions of some of the reports (for example, the creator of Node.js Ryan Dahl! Will come), tickets can also be purchased there - and from March 1, they will go up in price.