Kaggle approaches for CV in prod: you cannot implement to cut
 Among the date of the Scientists, there are many holivars, and one of them concerns competitive machine learning. Does Kaggle’s success really show a specialist’s ability to solve typical work tasks? Arseny arseny_info (R&D Team Lead @ WANNABY , Kaggle Master , later in A. ) and Arthur n01z3 (Head of Computer Vision @ X5 Retail Group , Kaggle Grandmaster , later in N. ) scaled the holivar to a new level: instead of another discussion in they took microphones in the chat room and held a public discussion at the meeting , on the basis of which this article was born.
Among the date of the Scientists, there are many holivars, and one of them concerns competitive machine learning. Does Kaggle’s success really show a specialist’s ability to solve typical work tasks? Arseny arseny_info (R&D Team Lead @ WANNABY , Kaggle Master , later in A. ) and Arthur n01z3 (Head of Computer Vision @ X5 Retail Group , Kaggle Grandmaster , later in N. ) scaled the holivar to a new level: instead of another discussion in they took microphones in the chat room and held a public discussion at the meeting , on the basis of which this article was born.Metrics, kernels, leaderboard
A:
I would like to start with the expected argument that Kaggle does not teach the most important thing in a typical Scientist date - the statement of the problem. A correctly set task already contains half of the solution, and often this half is the most difficult, and to code some model and train it is much easier. Kaggle offers a task from an ideal world - the data is ready, the metric is ready, take and train.
Surprisingly, even with this, problems arise. It is not difficult to find many examples when “kagglers” are confused when they see an unfamiliar / incomprehensible metric.
N:
Yes, that’s the essence of kaggle. The organizers thought, formalized the task, collected the dataset and determined the metric. But if a person has the beginnings of critical thinking, then the first thing he will think about is why they decided that the chosen metric or proposed target is optimal.
Strong participants often redefine the task themselves and come up with a better target.
And when they figured out the metric, determined the target and collected the data, then optimizing the metric is what kagglers do best. After each competition, the customer can with great confidence believe that the participants showed the “ceiling” for the ideal algorithm with a top speed. And to achieve this, kagglers try many different approaches and ideas, validating them with fast iterations.
This approach is directly converted into successful work on real tasks. Moreover, experienced kugglers can immediately immediately intuitively or from a past experience select a list of ideas that are worth trying in the first place to get maximum profit. And here the whole arsenal of the kaggle community comes to the rescue: articles, slack, forum, kernels.

A:
You mentioned “kernels”, and I have a separate complaint to them. Many competitions have turned into kernel driven development. I will not focus on degenerate cases when a gold medal could get due to the successful launch of a public script. Nevertheless, even in deep learning competitions you can now get some kind of medal, almost without writing code. You can take several public decisions, especially not understanding the twist of some parameters, test yourself on the leaderboard, average the results and get a good metric.
Previously, even moderate successes in “picture” competitions (for example, a bronze medal, that is, getting into the top 10% of the final rating) showed that a person is capable of something - you had to at least write a normal pipeline from the very beginning to the end , prevent critical bugs. Now these successes have been devalued: Kaggle is promoting its core platform with might and main, which lower the threshold of entry and allow you to somehow experiment without realizing what's what.
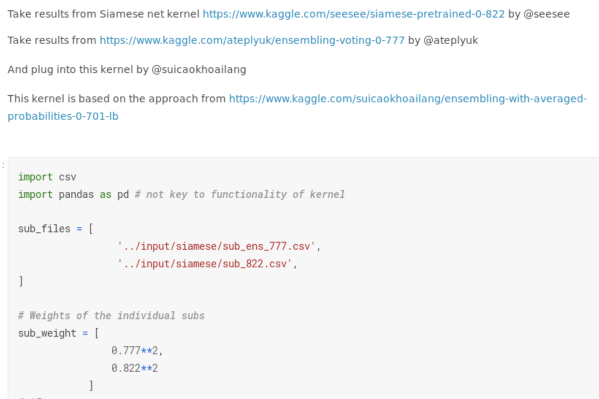
N: The
bronze medal has never been quoted. This is the level of "I launched something there, and it learned." And it’s not so bad. Lowering the input level due to kernels and the presence of GPUs in them creates competition and raises the general level of knowledge higher.If a year ago it was possible to get gold using vanilla Unet, now you can’t do without 5+ modifications and tricks. And these tricks work not only on Kaggle, but also beyond. For example, at aerial-Inria, our dudes from ods.ai got off their feet and showed state of the art simply with their powerful segmentation pipelines developed by Kaggle. This shows the applicability of such approaches in real work.

A:
The problem is that in real tasks there is no leaderboard . Usually there is no single number that shows that everything went wrong or, conversely, everything is fine. Often there are several numbers, they contradict each other, linking them into one system is another challenge.
N:
But metrics are somehow important. They show an objective performance of the algorithm. Without algorithms with metrics above some usable threshold, it is impossible to create ML-based services.
A:
But only if they honestly reflect the state of the product, which is not always the case. It happens that you need to drag the metric to some hygienic minimum, and further improvements of the “technical” metric do not correspond to product improvements (the user does not notice these +0.01 IoU), the correlation between the metric and the user's sensations is lost.
In addition, the classic kaggle methods of increasing the metric are not applicable in normal work. No need to search for “faces”, no need to reproduce the markup and find the correct answers by hashes of files.

Reliable validation and ensembles of bold models
N:
Kaggle teaches you to validate correctly, including due to the presence of faces. You need to be very clear about how the speed on the leaderboard has improved. It is also necessary to build a representative local validation that reflects the private part of the leaderboard or the distribution of data in production, if we are talking about real work.
Another thing that Kagglers are often blamed for is ensembles. A Kaggle solution usually consists of a bunch of models, and it is impossible to drag in the prod. However, they forget that it is impossible to make a strong solution without strong single models. And to win, you need not just an ensemble, but an ensemble of diverse and strong single models. The “mix everything in a row” approach never gives a decent result.

A:
The concept of “simple single model” in the Kaggle get-together and for the production environment can be very different. Within the framework of the competition, this will be one architecture trained at 5/10 folds, with a spread encoder, in time you can expect test time augmentation. By competition standards, this is a really simple solution.
But production often needs solutions a couple of orders of magnitude easier , especially when it comes to mobile applications or IoT. For example, in my case Kaggle-models usually occupy 100+ megabytes, and in the work of the model more than a few megabytes are often not even considered; There is a similar gap in the requirements for the rate of inference.
N:
However, if the date the scientist knows how to train a heavy grid, then all the same techniques are also suitable for training lightweight models. In a first approximation, you can take just a similar mesh easier or mobile version of the same architecture. Quantization of scales and pruning beyond the competence of Kagglers - no doubt here. But these are already very specific skills, which are far from always urgently needed in prod.
But a much more frequent situation in real tasks is that there is a small one
A:
Pseudo-dabbing is useful, but in competitions it is not used for a good life - only because it is impossible to re-size the data. The data obtained using pseudo-dimming, although improving the metric, is not as useful as manually re-marking the missing data.
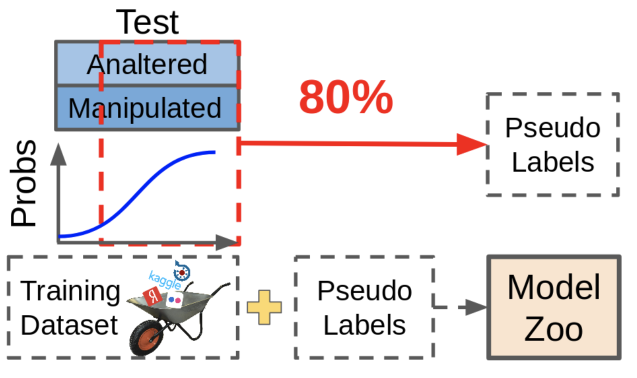
What is pseudo-dabbing? We take existing models, look where they give reliable predictions, we throw these samples together with predictions into our dataset. In this case, samples difficult for the model remain unlabeled, because these predictions are not good enough now. Vicious circle!
In practice, it is much more useful to find those samples that cause the network to produce uncertain predictions, and re-size them. It requires a lot of manual labor, but the effect is worth it.
About the beauty of code and teamwork
A:
Another issue is code quality and development culture. Kaggle not only doesn’t teach you how to write code, but it also provides many bad examples. Most kernels are poorly structured, unreadable, and inefficient code that is thoughtlessly copied. Some popular Kaggle personalities even practice uploading their code on Google Drive instead of the repository.

People are good at unsupervised learning. If you look a lot at bad code, you can get used to the idea that it should be so. This is especially dangerous for beginners, which are quite a lot on Kaggle.
N:
The quality of the code is a moot point on the cuggle, I agree. However, I also met people who wrote very worthy pipelines that could be reused for other tasks. But this is rather the exception: in the heat of the fight, the quality of the code is sacrificed in favor of quick checks of new ideas, especially towards the end of the competition.
But Kaggle teaches teamwork. And nothing unites people like a common cause, a common understandable goal. You can try to compete with a bunch of different people, get involved and develop soft skills.

A:
Kaggle-style teams are also very different. It’s good if there really is some kind of separation of tasks by roles, constructive interaction, and everyone makes a contribution. Nevertheless, the teams in which everyone makes his own big ball of mud, and in the last days of the competition all this is frantically mixed, are also enough, and this also doesn’t teach anything good - real software development (including data science) not done for a very long time.
Summary
Let's summarize.
Undoubtedly, participation in competitions gives its bonuses that are useful in daily work: first of all, it is the ability to quickly iterate, squeeze everything out of the data within the framework of the metric and do not hesitate to use state of the art approaches.
On the other hand, the abuse of Kaggle approaches often leads to suboptimal unreadable code, dubious work priorities, and a bit of bling.
However, any date the scientist knows that to successfully create an ensemble, you need to combine a variety of models. So in a team it’s worth combining people with different skill sets , and one or two experienced Kagglers will be useful to almost any team.