Jupyter Notebook on Netflix
- Transfer
Recently, Jupyter Notebook has become very popular among Data Science experts, becoming the de facto standard for rapid prototyping and data analysis. At Netflix, we try to push the boundaries of its capabilities even further by rethinking what Notebook can be, who it can be used for, and what they can do with it. We put a lot of effort into translating our vision into reality.
In this article we want to tell you why we think that Jupyter Notebooks is so attractive and that inspires us along the way. In addition, we describe the components of our infrastructure and review new ways to use Jupyter Notebook in Netflix.

Note from the translator: careful, a lot of text and few pictures
If you don’t have much time, we suggest that you immediately go to the Use Cases section .
Why all this?
Data is the power of Netflix. They permeate our thoughts, influence our decisions , and challenge our hypotheses . They charge experiments and the emergence of a new one on an unprecedented scale . The data reveals unexpected meanings and an incredible personalized experience to 130 million of our users around the world .
Making all of this a reality is a considerable achievement, requiring impressive engineering and infrastructure support. Every day, more than 1 trillion events are received in a stream (streaming ingestion pipeline) which is processed and recorded in a 100PB cloud storage. And every day, our users perform more than 150,000 tasks on this data, covering everything from reports to machine learning and recommendation algorithms.
To support such usage scenarios on such a scale, we have built one of the best in the industry, a flexible, powerful and, if necessary, sophisticated data platform (Netflix Data Platform). We also developed additional tools and services, such as Genie (task execution service) and Metacat (meta-storage). These tools reduce complexity, thereby making it possible to support a wider range of users throughout the company.

The variety of users is impressive, but you have to pay for it: The Netflix Data Platform and its ecosystem of tools and services must scale to support additional usage scenarios, languages, access schemes, and more. For a better understanding of the problem, we consider three common positions: an analyst engineer, a Data engineer and a Data scientist.

The difference in the preference of languages and tools for different positions
As a rule, each position prefers to use its own set of tools and languages. For example, a Data engineer can create a new data ensemble containing trillions of event streams using Scala in IntelliJ. The analyst can use them in a new global streaming quality report using SQL and Tableau. This report can go to a Data scientist who will build a new streaming compression model using R and RStudio. At first glance, these processes seem fragmented, albeit complementary, but if you look deeper, each of these processes has several overlapping tasks:
data exploration - occurs at an early stage of the project; may include an overview of sample data, queries for statistical analysis and data visualization
data preparation - a repetitive task, may include data cleaning, standardization, transformation, denormalization, and data aggregation; usually the most time-consuming part of a
data validation project is a regularly occurring task; may include a survey of sampled data, statistical analysis, aggregate analysis, and data visualization; usually occurs as part of data exploration, data preparation, development, pre-deployment, and post-deployment
productionalization - occurs at a late stage of the project; may include code deployment, sample additions, model training, data validation, and scheduling workflows
To expand the capabilities of our users, we want to make these tasks as easy as possible.
To expand the capabilities of our platform, we want to minimize the number of tools that need to be supported. But how? No single tool can cover all of these tasks. Moreover, often one task requires the use of several tools. However, if we disengage, a common pattern arises for all tools and languages: execute code, examine data, present the result.
It so happened that an open source project was developed specifically for this: Project Jupyter .
Jupyter notebooks

Jupyter notebook in nteract displays Vega and Altair
The Jupyter project was launched in 2014 with the goal of creating a consistent set of open source tools for research, reproducible workflow and data analysis. These tools have been highly acclaimed in the industry and today Jupyter has become an integral part of any Data scientist’s tools. To understand the extent of his influence, we note that Jupyter was awarded the 2017 ACM Software Systems Award - a prestigious award that he shares with Java, Unix, and the_Web.
To understand why the Jupyter Notebook is so attractive to us, consider its main features:
- messaging protocol for analyzing and executing code regardless of language
- file format with the ability to edit, for description, display and execution of code, output and markdown notes
- web interface for interactive writing, code execution, and visualization of results
The Jupyter protocol provides a standardized messaging API with kernels that act as compute modules and provides a composable architecture, thereby sharing where the code (UI) is stored and where it is executed (the kernel). Thus, separating the interface and the core, Notebooks can work in several languages while maintaining the flexibility to configure the runtime. If a language exists for a language that can exchange messages using the Jupyter protocol, Notebook can execute code by sending and receiving messages to that kernel.
In addition to everything, all this is supported by a file format that allows you to store both the code itself and the results of its execution in one place. This means that you can view the execution results later without having to restart the code itself. Notebooks can also store a detailed description of the context, and what exactly happens inside it. This makes it an ideal format for conveying a business context, fixing assumptions, commenting on code, describing conclusions, and much more.
Use cases
Among the many scenarios, the most popular use cases are: data access, notebook templates, and scheduling notebooks.
Data access
Jupyter Notebook originally appeared on Netflix to support data science workflows. As their use among Data science experts grew, we saw the potential for expanding the capabilities of our tools. We realized that we could use the versatility and architecture of the Jupyter Notebook and expand its capabilities for data sharing. In the third quarter of 2017, we seriously began work on making Notebook a tool for a narrow circle of specialists into a first-class representative of the Netflix Data Platform.
From the perspective of our users, Notebooks offer a convenient interface for interactive command execution, output research, and data visualization - all in one cloud development environment. We also support the Python library, which combines access to the platform API. This means that users have programmatic access to virtually the entire Netflix platform through a Notebook. Thanks to this combination of flexibility, power and ease of use, the company experienced a sharp increase in its use by all types of platform users.
Today, notebook is the most popular data tool in Netflix.
Notebook Templates
As support for Jupyter Notebooks expanded within the platform, we began to introduce new features to use it to meet new usage scenarios. From here came parameterized laptops. Parameterized laptops represent exactly what their name says: a notebook that allows you to set parameters in the code and receive input data at run time. This provides a good mechanism for users to define notebook as reusable templates.
Our users have found many ways to use such patterns. Here are a few commonly used ones:
- Data Scientist : experiment with different coefficients and summarize the results
- Data Engineer : Perform a collection of data quality audits as part of the deployment process.
- Data Analyst : share prepared queries and visualizations so that stakeholders can explore the data deeper than Tableau allows
- Software Engineer : send the results of a script to troubleshoot a crash
Scheduling Notebooks (Scheduler)
One of the original ways to use Notebook is to create a merging layer for scheduling workflows.
Since each laptop can run on an arbitrary kernel, we can support any user-defined runtime environment. And since notebooks describe a linear flow of execution divided into cells, we can relate the failure to a specific cell. This allows users to describe execution and visualizations in a more narrative form, which can be accurately captured at startup at a later point in time.
Such a paradigm allows you to use a laptop for interactive work and smoothly switch to multiple execution and use of the scheduler. Which turned out to be very convenient for users. Many users create entire workflows in notebook only to then duplicate them into separate files and run them at the right times. By treating notebook as a sequential process description, we can easily schedule them to run just like any other workflow.
We can plan the execution of other types of work through notebooks. When a Spark or Presto job is executed from the scheduler, the source code is inserted into the newly created notebook and executed. This notebook becomes a history repository containing source code, parameters, configurations, execution logs, error messages, etc. When troubleshooting, this provides a quick starting point for an investigation, since all relevant information is inside and notebook can be run for interactive debugging.
Notebook Infrastructure
Supporting the scenarios described above at the Netflix scale requires extensive supporting infrastructure. Briefly present several projects that will be discussed in the following sections:
nteract is a new generation of React-based UI for Jupyter notebooks. It provides a simple, intuitive interface and offers several enhancements for the classic Jupyter UI, such as inline cell toolbars, drag & drop cells and a built-in explorer.
Papermill library for parameterization, execution and analysis of Jupyter notebooks. With the help of which you can propagate several notebooks with various parameters and execute them simultaneously. Papermill also allows you to collect and summarize metrics for an entire notebook collection.
Commuter is a lightweight, vertically scalable service for viewing and sharing notebook. It provides a Jupyter-compatible version of the API for content and makes it easier to read notebooks stored locally on Amazon S3. Also offers an explorer for searching and sharing files.
Titus is a container management platform that provides scalable and reliable container launch and cloud-native integration with Amazon AWS. Titus was developed at Netflix and is used in combat to support Netflix streaming, recommendation, and content systems.
A more detailed description of the architecture can be found in the article Scheduling Notebooks at Netflix . For the purposes of this post, we restrict ourselves to the three fundamental components of the system: storage, execution, and interface.

Netbook's Notebook Infrastructure
Storage
The Netflix Data Platform uses Amazon S3 and EFS cloud storage, which notebooks treats as virtual file systems. This means that each user has an EFS home directory containing a personal workspace for notebooks. In this space, we store any notebook created or loaded by the user. This is also the place where reading and writing occurs when the user interactively starts the laptop. We use the combination [workspace + filename] for the namespace, i.e. /efs/users/kylek/notebooks/MySparkJob.ipynb for viewing, sharing, and in the execution scheduler. Such an agreement prevents collisions and facilitates the identification of both the user and the location of the notebook in EFS.
The path to workspace allows you to ignore the complexity of cloud storage for the user. For example, only the names of the notebook files are displayed in the directory, i.e. MySparkJob.ipynb. The same file is available through the terminal: ~ / notebooks / MySparkJob.ipynb.

Notebook storage vs. access
When the user sets the task of starting notebook, the scheduler copies the user's notebook from EFS to the shared directory on S3. Notebook in S3 becomes the source of truth for the scheduler, or the source notebook. Each time the scheduler (dispatcher) starts notebook, it creates a new notebook from the source. This new notebook is what actually starts and becomes an invariable record of a specific execution, containing the executable code, output, and logs of each cell. We call it output (output) notebook.
Co-creation is a fundamental feature of Netflix. Therefore, it was not surprising when users began exchanging URL links to notebook. With the growth of this practice, we are faced with the problem of accidental rewriting caused by the simultaneous access of several users to the same notebook. Our users wanted a way to share their active notebook in read-only mode. This led to the creation of Commuter . Under the hood, Commuter displays the Jupyter API to list / files and / api / contents in a directory list, to view the contents of files, and access file metadata. This means that users can view notebooks without consequences for combat tasks or live-running notebooks.
Compute
Managing computing resources is one of the most difficult parts of working with data. This is especially true in Netflix, where we use the highly scalable container architecture in AWS. All jobs on the Data Platform are executed in containers, including queries, pipelines, and notebook. Naturally, we wanted to abstract as much as possible from this complexity.
A container is provided when the user starts the notebook server. We provide rational defaults for container resources that work for ~ 87.3% of execution patterns. When this is not enough, users can request more resources using a simple interface.

Users can select as much or as little compute + memory as they need
We also provide a unified runtime with a finished container image. The image has shared libraries and a predefined set of default kernels. Not everything in the image is static - our kernels use the latest Spark versions and the latest cluster configurations for our platform. This reduces interference and tuning time for new laptops and generally keeps us in a single runtime environment.
Under the hood, we manage orchestration and environments with Titus , our Docker container management service. We additionally create a wrapper over this service, managing specific user server configurations and images. The image also includes user security groups and roles, as well as common environment variables for identification in the included libraries. This means that our users can spend less time on infrastructure and more time on data.
Interface
Earlier, we described our vision that notebooks should be the most effective and optimal tool for working with data. But this presents an interesting challenge: how can a single interface support all users? We do not know the exact answer, but we have some ideas.
We know that simplicity is needed. It means an intuitive UI with a minimalist style, and it also requires a thoughtful UX that makes complex things easy to do. This philosophy fits well with the goals of nteract , written on the React frontend for the Jupyter notebook. It emphasizes composability as fundamental design principles, making it an ideal part of our vision.
The most common complaint from our users is the lack of native visualization for all languages, especially for non-Python languages. Nteract's Data Explorer is a good example of how to make complex things easy by providing a language-independent way to quickly explore data.
You can look at the Data Explorer in action on this example on MyBinder. (loading may take several minutes)

Visualizing the World Happiness Report dataset with nteract's Data Explorer
We are also introducing built-in support for parameterization, which makes it easier to schedule notebook startup, and create reusable templates.
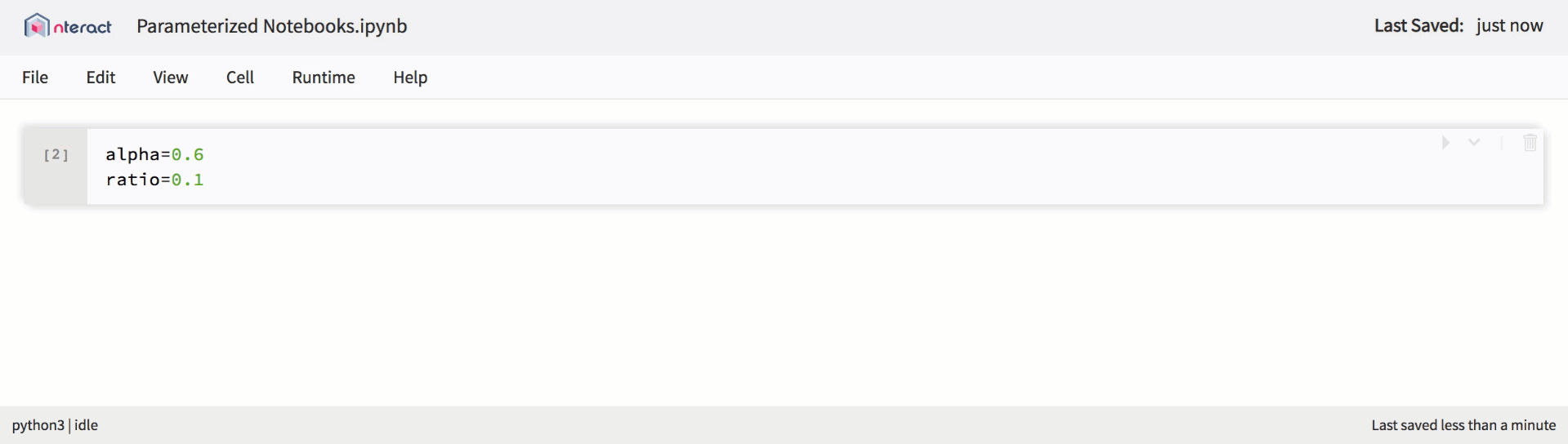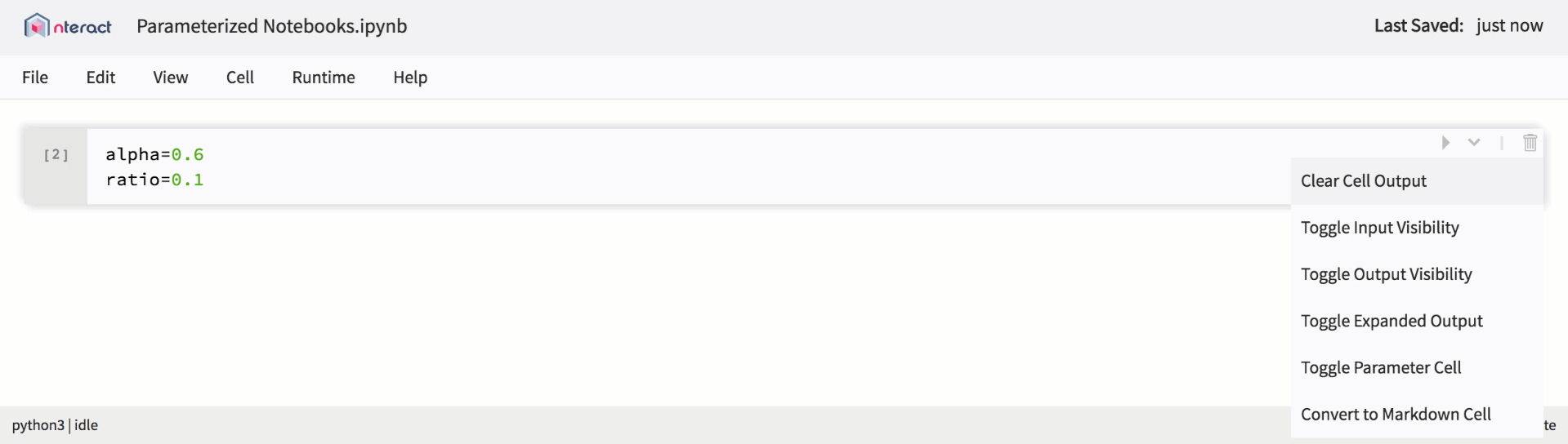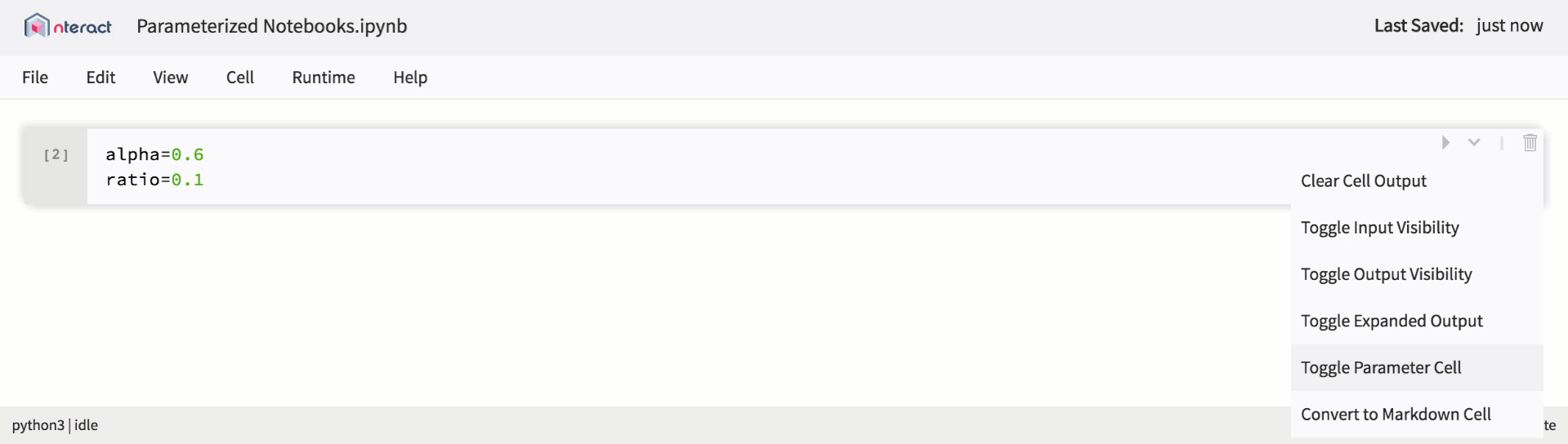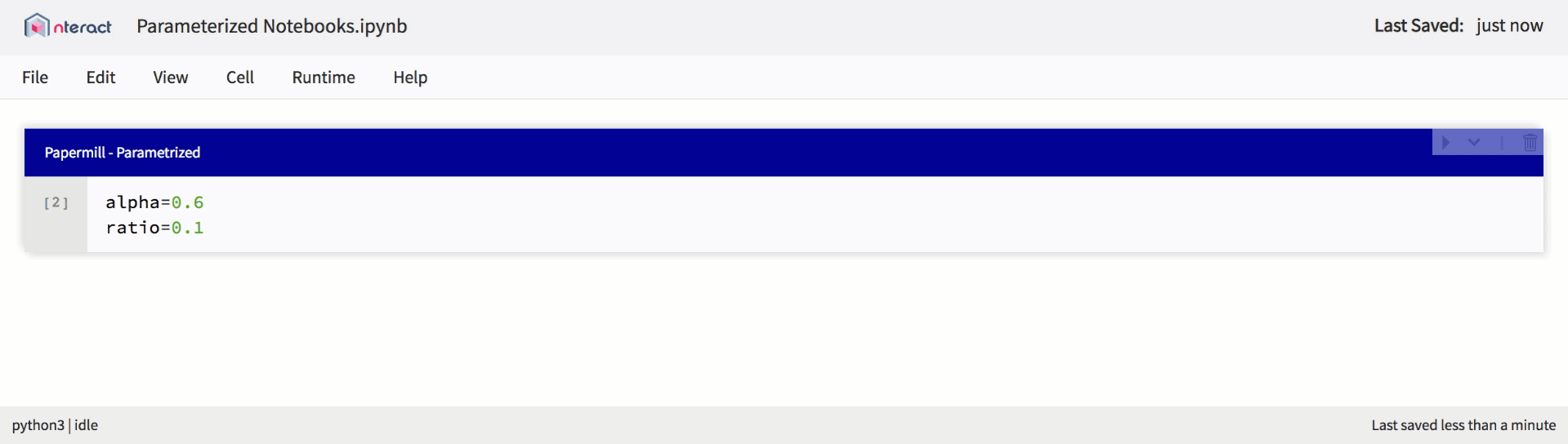
Native support for parameterized notebooks in nteract
Despite the fact that Jupyter notebook has already brought considerable benefits, we are only at the beginning of the journey. We know that a large investment is needed in both the front end and the backend to improve the experience with notebook. Our work over the next 12 months will focus on improving reliability, transparency and collaboration. Context is of paramount importance to users, so we are improving the visibility of cluster status, kernel state, task history, and so on. We are also working on an automatic version control system, an integrated scheduler in the application, improved support for Spark DataFrames visualization, and stability of Scala cores. We will discuss this work in more detail in the next article.
Open source projects
Netflix is an open source proponent. We value enthusiasm, open standards, and the exchange of ideas arising from collaboration. Many of the applications that we developed for the Netflix Data Platform are already open in Netflix OSS . We also do not intend to create one-time solutions and not succumb to the mentality of “Not Invented Here”. Whenever possible, we use and contribute to existing open source projects such as Spark , Jupyter and pandas .
The infrastructure that we described relies heavily on the Jupyter Project ecosystem, but at some points we decided to do otherwise. For example, we chose nteract as the notebook UI in Netflix. A similar decision was made for many reasons, including compliance with the company's technology stack and design philosophy. As we continue to push the boundaries of our capabilities, the Jupyter Notebook is likely to create new tools, libraries, and services. These projects will also be open source as part of the nteract ecosystem.
We are aware that not everything that suits Netflix will be relevant to the rest. Therefore, when creating these projects, we tried to make them modular so that you could select and use only those components that are necessary for you. For example, Papermill, which does not require the use of the entire ecosystem.
What's Next
As a platform development team, our responsibility is to enable Netflixers to do amazing things with data. Notebook already has a significant impact on Netflix. Given the huge investments that we make in this environment, we are pleased to see how this influence is growing. There could be a link to the netflix vacancy that was deleted before the arrival of the UFO.
Fuh! Thank you for being able to master this huge post. We only touched on the top of what we do with notebook. This post is the first of a series of articles about using notebook in Netflix that we will be publishing over the next few weeks. At the moment, two articles have already been published:
Part I: Notebook Innovation (this post)
Part II: Scheduling Notebooks
From a translator:
The words Scheduling and workflows are difficult to translate into Russian, if you know a concise version of the translation, let me know in the comments.