Ctrl-Alt-Del: learn to love Legacy code

What do Star Wars, Tatu and Ctrl-Alt-Del have to do with Legacy? What to do when you come to a big project and you encounter an abyss of incomprehensible old code? And how to effectively convey to the authorities that the labor costs for the elimination of technical debt justify themselves?
Reports of Dylan Beatty do not go without jokes, but these jokes accompany quite serious arguments about the main issues of development. This is well suited to complete the conference: when viewers have already heard a lot of hardcore and can no longer perceive slides with code, it's time for more general questions and a bright presentation. And when our .NET-conference DotNext 2018 Moscow finished Dylan's speech on the Legacy code, the audience liked it the most.
Therefore, now for Habr, we have made a translated text version of this speech: for the workers and for everyone else. In addition to the text, under the cut there is the original English-language video.
Hello, my name is Dylan Beatty. The topic of conversation is very close to me and, in my opinion, is extremely important for everyone who develops software: it’s about legacy code.
First I will say a few words about myself. I started developing websites back in 1992, by the standards of our industry, in prehistoric times. Now I am CTO of the London company SkillsMatter. I started working there this year, thereby inheriting the code base: 75 thousand lines of code written not by me became my responsibility. In part, my report is based on this experience. In addition, I am a Microsoft MVP and head of the .NET user group in London.

What do Dr. Who, modern Star Wars, Sherlock and Paddington have in common? When working on them was used Legacy code. I know this, because for 15 years I worked at Spotlight. This is a London based company that provides an online tool for professional actors who act in films and on television. The software, written by me and my team, was used in the work on all the mentioned projects and many others.
In the new "Star Wars" someone did not like the actors, others did not like the plot. But no one came out of the cinema with the words “I don’t like that when the classic ASP was used during the creation”!
Because it doesn't matter. This code base has been in production for a very long time, and yes, there is the classic ASP - code that is older than the entire .NET - that is still used in casting for movies and TV shows today. It is necessary to put accents correctly: these films and series are important, and the code exists only to solve problems. Until you run it, the code itself does not mean anything. Value arises in it only when you launch it, and with its help you do something. That's what people pay for - Netflix or DVD. The problem is that it is very easy to forget about it.
In general, today I want, among other things, to share with you my experience with the same code base over the years. I watched how it evolved, and how other people got to know and learn how to use it. And the other side of this equation is my new work, which allowed me to see the same process from the other side, when I myself had to get acquainted with someone else's code.
But first, let's talk about how quickly things are changing in IT.

Take a look at the very first iPhone - today it looks completely ancient and bulky. And this model is only 11 years old, it appeared in 2007, and then it cost $ 800. If in 2007 you bought a washing machine, a guitar or a bicycle, today you could still use them. But the first iPhone is no longer working - even if you manage to find a copy with a battery and a charger, all the things that made the smartphone such an amazing device will not work in it.
You cannot open the map because the map servers no longer exist. You will not be able to log in to Twitter, because the latest versions of the Twitter application require an iOS version that cannot be installed on iPhone 1. The Twitter client will simply answer you: “endpoint not found”. In essence, you will have a fossil in your hands. And the only thing that will work in it is the function of a regular phone, you can still call it. Because in this area, unlike IT, the standards for 11 years have not changed.
Let's take a little time travel. Remember this one?
And remember what year it was? Tatu performed at Eurovision in 2003. And in 2003 I wrote ASP-code, which is still used in production now.
It seems to us that it was a long time ago, but this code still works. Mobile phone manufacturers managed to get people to buy a new phone every two years, so they can afford to get rid of old practices, disable API, endpoints, services. But many companies do not have such an opportunity, and therefore they continue to maintain the code written when Tatu performed at Eurovision. This code is important because it still performs important functions, it brings income - that is, it is a legacy code.
And although we all agree that legacy exists, the question remains: what exactly is it? Here is a sample code:

Look, think: is it legacy or not? How do you think?
I invented the device, I want to sell next year. You insert it into the USB connector, highlight a piece of code, and the device tells you if it’s a legacy or not!

The code that you just saw is not legacy. It was written by Andrey Akinshin ( DreamWalker ) four days ago. This is taken from BenchmarkDotNet.
The fact of the matter is that it is impossible to determine whether a code is legacy just by looking at it. Moreover, the code itself has nothing to do with it. What is important is what is happening around it: people, culture, processes, tests, and so on.
If you open the article "Legacy code" in the English-language Wikipedia, you can read the following: "This is the source code related to the operating system or any other computer technology, support or production of which is discontinued." We are: "well, okay." And further it is written: "This term was first used by George Olivetti in relation to the code, which was supported by the administrator, who himself did not write this code."

At the end of this sentence is a link to the blog of a certain Samuel Mullen. We think: "Interesting, we'll see." But if we open the post , we see that this Mullen, in turn, refers to Wikipedia!

And it seems that no one else knows who this George Olivetti was. So it seems that we should look for a better definition.
One of the most popular definitions in the industry was given by Michael Fazers: “Legacy is simply code without tests.” And Michael wrote a whole book on this subject , so he definitely knows what he is talking about. But still I do not fully agree with his definition.
Therefore, I have been using my definition for several years now: “Inherited code is a code that is too scary to update it, but too profitable to delete it.”

Later it turned out that a very similar definition was already given independently of me: “a very profitable code that we are afraid to change”. I wonder where this fear comes from. What is there in the tests that turns the code without them into a legacy?
One of the oldest business tools in the world is a double entry accounting system. It has many hundreds of years, and each transaction of a bank or company is taken into account twice: in one column I write down how much money I paid, and in the other - the value I received for them. At the same time, the sums of both columns must be equal, if there is a discrepancy, an error is made somewhere.

It seems to me that the fundamental idea of this approach is very important: all the decisions we make have influence twice, and if you change one thing, then somewhere else there will also be changes that need to be monitored. This dual approach can be applied to the code and tests, or to the code and monitoring system, or to the code and documentation.
Many systems that we consider Legacy also exist in two versions, but these are versions "in code and in someone's head." And here, in my opinion, lies one of our main difficulties.
I remember the one-page comic "This is why you shouldn't interrupt a programmer." The developer looks at a simple line of code, and in his head immediately begins to think about what needs to be rewritten in the navigation menu, how it will affect the debugger, and then it will have to be changed in the code. Someone comes up to him and asks: “did you receive my letter?”, And then all this complicated tree of edits flies out of my head.
When we work, we enter an altered state of consciousness, our brain builds complex models that explain the operation of the code. When the code is written by one person (for example, in a startup or an open source project), there is often nothing but the model in the head and the model in the code. This allows you to work very quickly - you simply broadcast what you have in your head, in the code. The correct model is the one in the head, so if something is wrong in the code, it is enough to look at it, compare it with what is in the head, and the error will be immediately visible. And when you find a bug, it often shows you that you have not thought about any aspect sufficiently, and you first update the model in your head, and then the code.
There is a wonderful post by Jessica Kerrwhere, among other things, it says that invention is how to run down the mountain, and analysis how to go up the mountain. We like to write code, it is interesting and easy: you start from scratch and invent something new, solve problems, write algorithms, methods and classes. But to read the code is difficult - from the very beginning you have a huge array of someone else's code, and this is a completely different work.

Therefore, in many organizations one can observe a phenomenon that Alberto Brandolini called the “dungeon master”: this is the person who wrote the first version of the system. I was this person in Spotlight - I wrote a significant part of the first version alone, and I wrote it on a classic ASP, without documentation and without unit tests. With this tool they began to make films, they made Star Wars, we had money and everything was great. But then we started hiring new employees who initially could not figure out how it all worked, and within two or three months they had to get acquainted with the system.
Soon, conversations began about how to port the system to .NET, since classic ASP is not sufficiently reliable and not fast enough. Such conversations will always be there - no matter what code you write, someone will insist that it should be rewritten. This happens because this person does not understand your code, and it is more interesting to write new code than to delve into the old one. Programming is a job that brings pleasure, we like it very much. Therefore, it is quite natural that, being presented before a choice, we will lean in favor of the option that is more fascinating.
The owner of the dungeon is a person who knows all the pitfalls in the code. He knows about the button that can not be pressed, otherwise the application will fall; the one on which hangs TODO from 2014, to which no one has reached out. We in our industry have learned not to create such systems anymore. This is what I like events like DotNext, user groups, community and StackOverflow: when you start a new project, you will be sure to explain that you need to write tests, do the integration, monitoring, integration. So our future is serverless F # microservices with one hundred percent coverage of code with tests.
But the problem is not in the software that we have to write: in our world is already full of software. And, if to present this software in the form of a pyramid, then serverless F # will occupy only the very top. A little more will be ASP.NET, somehow covered with tests. Even more - Visual Basic on Windows XP. But the most popular commercial product development platform in history is Excel spreadsheets.

I am ready to bet that every time you buy a plane ticket or stay at a hotel, one way or another, your name ends up in some Excel table. Development through testing does not take into account this huge baggage of already written code.
But why insist on rewriting old code? At first, people don't like classic ASP and they want to rewrite everything in .NET. Then it turns out that you need to rewrite everything on version 4.5, then 4.6, then .NET Core. JQuery is no good, so you need to switch to Angular, then the React queue will come, then Vue.
I suspect that at least one of the reasons here lies in the pursuit of fashion. We all communicate with each other, and a significant part of the highest quality work in our industry was done because the authors wanted to gain recognition and respect from the people of their profession. It seems to me that we in the industry have an excessive predilection for everything new and glossy, and programming languages are subject to fashion trends. But after all, those for which the fashion passes, by themselves have not changed in any way, all their advantages remained the same as they were.
Imagine that you have two summaries in front of you:

For me, there is no doubt with which of them I will be better able to work on really important issues. But if you talk to people from HR, or to those who have just completed a programming course, you will see that, in their opinion, the skills of the first programmer can be well earned, and the skills of the second program are considered obsolete. But after all, they are not outdated at all - there are still many problems that this person can work on.
I think one of the reasons for this attitude is that people are scared. Some of my colleagues left our team because they wanted to work for Angular or NodeJS. When I asked them why they needed it, they replied that if they continued to work only on .NET, they would not be able to find a job in two years. I answer them: guys, we and our .NET just helped to do Star Wars! And they say: yes, but it is still not Angular.
Understand me correctly, I respect their decision. There can be no question of any corruption, just people are worried about their future and the future of their family if they have to look for work. And in our industry, this security issue is usually interpreted in the light of the need to re-examine everything from scratch every year and a half, otherwise you will lose competitiveness. Very often, we are much more interested in the technology itself, than our ability to solve problems.
In addition to the fear of falling behind and becoming obsolete here, in my opinion, a big role is played by the fear of changing the system, which you do not understand. They give you a code about which you know nothing, but if something breaks in it, it will be your responsibility, and if it falls in the middle of the night, they will wake you up. This is where fear comes from.

As we know from the same "Star Wars", fear leads to anger, anger leads to hatred, hatred leads to suffering, suffering leads to JavaScript. How do we work with our fear and with the fear of our colleagues? In my opinion, there are three main aspects: understanding , trust and control .
The trust- at the same time the simplest and most difficult of these three. I trust this laptop because it has never crashed during the presentation. As soon as this happens, my trust in him will disappear. In English, there is a saying “trust is gained drop by drop, but lost by buckets”. After a month of working with a person, you will be ready to admit that he may understand his business, in two you will say that he understands well, in three you will agree that he knows his business very well. And after three months and one day, his code will reveal a vulnerability to SQL injections, and you will say, "Ah, I always said that there was no use for him."
Trusting other people is always difficult, because it always means giving up some degree of control. The credibility of the code is also an important topic. After you have worked with the system for some time, you want to believe that it will work in accordance with your expectations. Your operating systems are stable and reliable, and you hope that they will not fall. You trust the databases of your information and expect that they will not lose it. You expect that the cloud providers will ensure the regular operation of your site and will not sell the information of your customers on the black market.
There is no quick way to gain trust. True, trust is transitive: if I trust you and you trust someone else, then, most likely, I can also trust this person. If I listen to your opinion, and you think that you can trust Amazon, AWS, Azure or Google App Engine, then I will be ready to believe that these are good services. But there is no quick way to gain trust.
Let's move on to understanding . At university I studied computer science for three years. If the principle underlying our education were followed by civil engineers, then in the first year they would build wooden sheds, in the second course - metal, and in the third, advanced - glass.

We in the first year wrote small programs in Lisp, in the second - small programs in Java, in the third - small programs in Scheme and Prolog. We did not write large programs, and, more importantly, did not try to understand them.
But civil engineers are not taught by the example of barns, they are forced to sort out skyscrapers, bridges, philharmonic societies and buildings like the one we are in now. These students learn from the largest and most impressive projects in their industry. And if they had studied according to the same principle that computer science was taught, then a student, faced with a real order for a skyscraper, would have never thought of anything but placing sheds on each other until Petronas towers were obtained.

This is exactly the position of a student who has completed a computer science course and has been assigned to write a distributed commercial procurement system. Much of the existing software is about the same as was written. The people who wrote it were not irresponsible, but simply inexperienced. They were very good at everything they did at the university, and this created false self-confidence. That was how I was at one time, and I am sure many of you were the same at the time. We acted like this: write a web page, make a link to another page, then another, copy the code and everyone will be happy - customers have a product, a company has money, we have a bonus. And in five years you look at this nightmare and think: how could such a thing be written?
The problem is partly the ability to learn software. Civil engineers are well able to study buildings, aviation engineers are well able to study aircraft. Take the literature: in “War and Peace” there can be 45 thousand lines (depending on the edition). This is one of the largest books in the world, it requires a very serious study from the people who are engaged in literary criticism. In other words, the study of such a large object is a job. The size of the longest piece of Shakespeare, Hamlet - 6 thousand lines. And now think: the Linux kernel is three times longer than War and Peace. And we are talking about a very compact code, well organized, with extensive documentation and a large community. And nevertheless, to sort it out in the same way as three times in War and Peace.

Look at this chart, which shows the number of lines in the books Hamlet, Moby Dick, The Brothers Karamazov, The Lord of the Rings, Atlas Shrugged and War and Peace, as well as in the Linux and Mono kernels .
Does this ratio seem realistic to you? Please forgive me for misleading you. This graph is actually exponential.
And the line graph on the next slide:

The idea here is very simple: the software is huge, just sit down and read it is impossible. To ask someone to get acquainted with the Linux kernel is similar to asking a person to read War and Peace, Atlas Shrugged, Lord of the Rings, and all Harry Potters in a row. Imagine that you have come to a new company, and they tell you from the doorway that you need to study all these books, and only then you will not be allowed to the code. Of course they don’t.
Reading the code is a very useful exercise - you can understand how some patterns work, learn some examples. But you cannot understand a large system if you read it the way you read a book. Perhaps, in this approach there is something noble, but it does not lead to anything, as it seems to me. There is too much code, and it is written worse than these books.
If simply reading the code is ineffective, then how to study it correctly? Recall Richard Feynman, Nobel Prize in Physics. For him the question of teaching science was of great importance. He believed that the need to teach people is not science, but how to properly do science. He was invited to the University of São Paulo in Brazil, because in Brazil, the students received very high marks, but at the same time to establish high-tech production did not work. Feynman was asked to help figure out what the problem was.
For several years, he visited Brazil every year for several weeks, and talked with students. He saw that Brazilian students knew very well, for example, the name of a phenomenon that occurs when pressure is applied to a crystalline body - triboluminescence. But none of them knew that if at home in a dark room you could crush a piece of sugar with pliers, you would see how sparks would slip through - and this is triboluminescence. Feynman explained that students were only drafted through textbooks to pass exams, but they did not do any experiments.
In my opinion, this is an important lesson for our industry. Reading the code is similar to reading an exam textbook, and we need to set up experiments. To do this, let us turn to the basics of the scientific method, which formed the basis of modern physics, chemistry, medicine, and so on. Suppose you are learning some code.
The first step is observation . Try to run the system you are analyzing and watch how it behaves.
The next step is the formation of a hypothesis . You assume that if you make some changes to the code, it will cause certain consequences. For example, if you add an index to a table, then a web page will be displayed faster.
Next, based on the hypothesis, you formulateprediction . To test it, you set up an experiment . The results of this experiment you are analyzing . And then you communicate them to your team or, if it is an open source project, to the community.
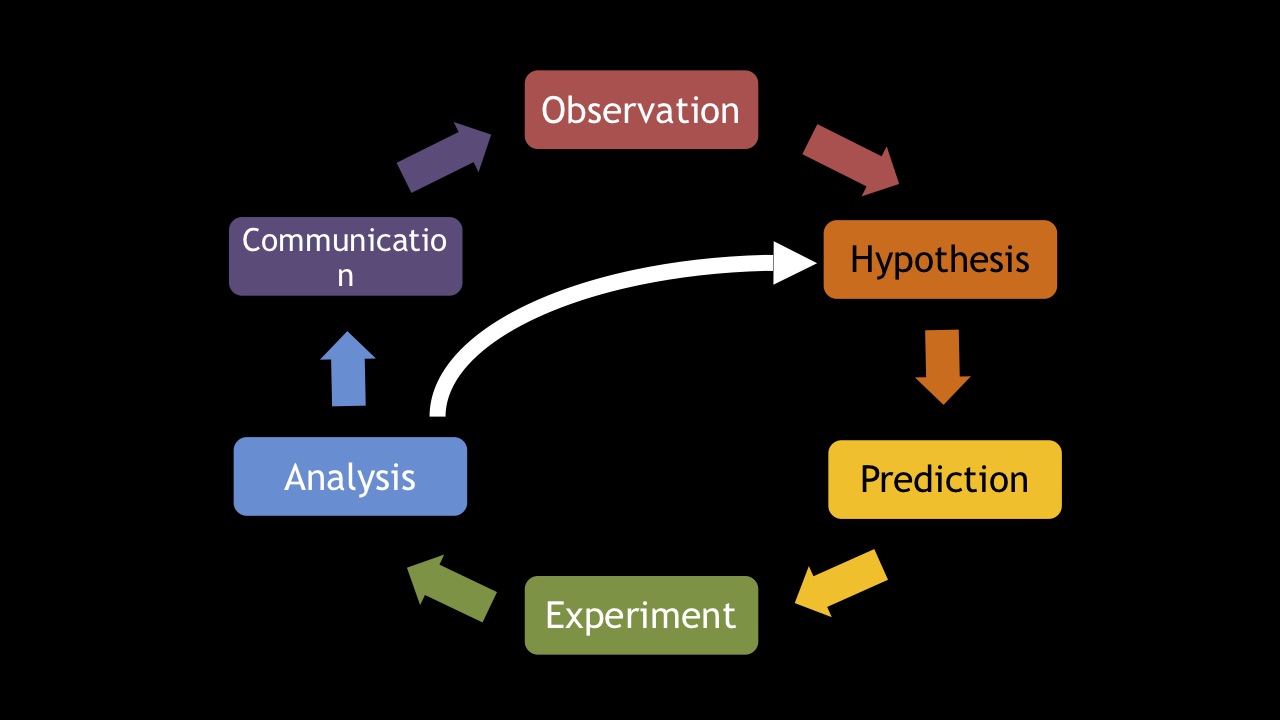
Very often, as a result of the analysis, you understand that your hypothesis was incorrect - for example, the reason for the slow page display was not the database index, but the network. Perhaps, if you reconfigure the network so that there is no firewall between the web server and the database server, everything will work faster? With the new hypothesis, you formulate a new prediction and set up a new experiment.
The problem with such experiments with Legacy code is that at the beginning of the process, you act almost blindly, so you can easily break something. Experiments on running systems are always risky.

I somehow accidentally replaced the whole working site with one page labeled "I love LAMP", because I thought that I had a fuse when deployed, but it did not work. But everything ended well - the error was so awkward that no one thought of us, the users felt that the problem was on their side. The moral is simple: if you break the system, then the bigger, the better, then they won't think about you.
To avoid this kind of accidents, we need a safe environment, a sandbox in which to conduct our experiments. First you need to make sure that you have the source code. Often companies ask you to figure out a system for which there is only a DLL. It is like cooking a pizza according to the recipe, throwing it away, and then requiring the person to cook the exact same. True, even from this situation there is a way out - you can decompile, or analyze calls to modules. And nevertheless further I assume that you have the source code, otherwise - my condolences.
The next question is - can you collect this code? Does it compile? Sometimes code can be collected only on a build server, “we just change something and send it there”. This situation needs to be corrected, it is necessary to ensure that the code can be collected locally. Then the collected code needs to be run, and see where it falls. On the code in production, you can put very interesting observations, if you start it by turning off Wi-Fi. Without Wi-Fi, nothing terrible is likely to happen, because you do not communicate with any external dependencies. Then you start to study the errors: for example, the system fell because you could not find the database - then how can I run it with the database? And so on.
In many old systems, you will not find the configuration file, the code will directly state what the system should address. I had cases when I simply copied the host file and changed all external dependencies in it, so that they pointed to my machine.
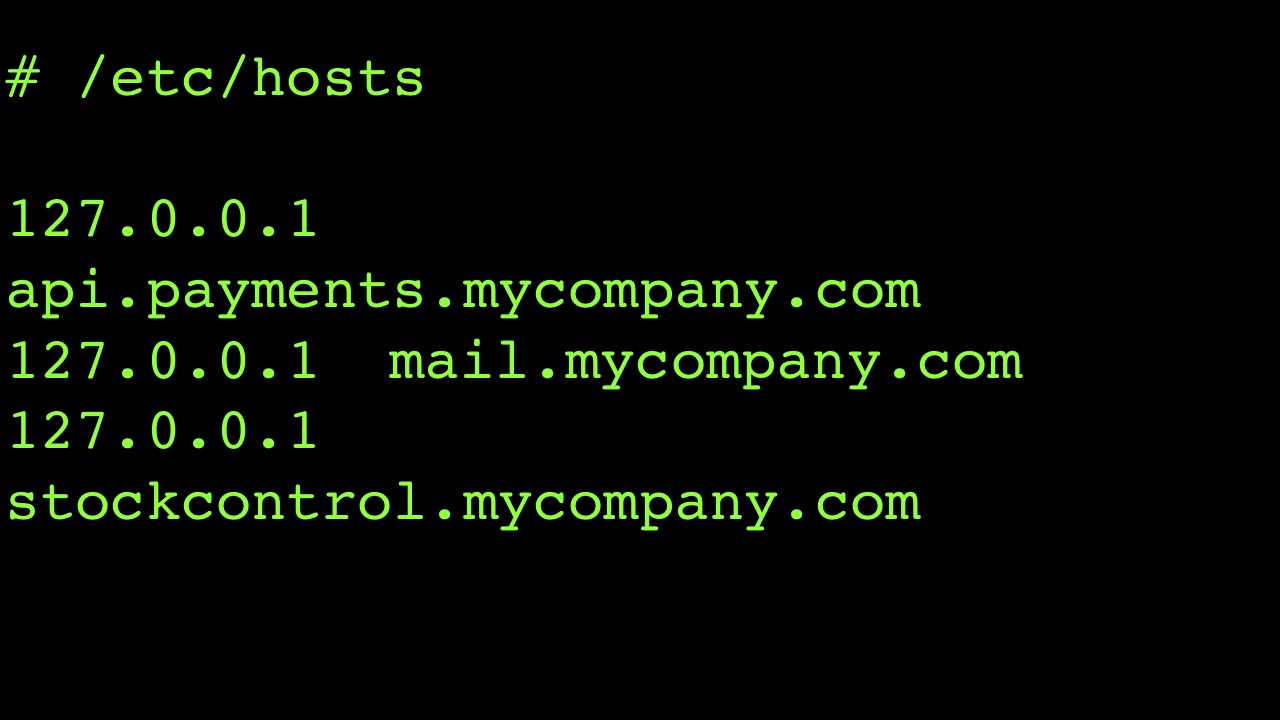
This allowed me to observe all network interactions, to then create stubs. For example, I see that something from my DLL is accessing api.payments.mycompany.com. I can not change anything in the DLL itself, but I control the environment in which the software works, variables, what this DLL connects to, incoming and outgoing traffic. And this is the first step: you need to gain control of the code .
When this is done, you can start thinking about the second step: how to make changes to the codeand then transfer them from safe sandbox to production. This process can be extremely difficult. There are companies that have a deployment cycle of three months: you make some changes, another team copies this code into its repository, and so on.
This is too long. I understand if a pharmaceutical company or an air traffic control center works this way, because they can kill me with their mistakes. But most of us in such organizations do not work, and we need to ensure that the changes get into production as quickly as possible. The easiest thing to do here is to start with invisible changes: for example, add an invisible comment to the main page of your site, and see how quickly it gets into production. You can find all points of this process, where you need to do something with your hands, and automate them. Gradually improve this process.
We tried this approach in Spotlight, when we decided to switch to Amazon Web Services from the classic ASP on our servers. It took us two years to start the process of deploying code with GitHub in production without any manual checks and balances. Often, people lose heart after two days, and they return to the old system, so you need to sensibly estimate the amount of labor needed to achieve automation.
An interesting feature of legacy systems is that often the older they are, the better their support. In Windows 2016, it is enough to put one flag to enable support for classic ASP, which was no longer supported in 2003.

In other words, the code that I wrote when Tatu performed at Eurovision will work out of the box on Windows 2016 without compiler flags, dependencies or changes. But the code on ASP.NET MVC 2 does not work that way, because it was an advanced product at that time, which very quickly switched to version 3, and then 4. DLLs, which are needed to build projects on ASP.NET MVC 2, according to - still lie somewhere on microsoft.com, but in those projects that we have, Nuget is not used for dependencies, because they were written before it appeared. They are looking for dependencies in Program Files. We tried to run the code on ASP.NET MVC 2 for a couple of weeks until we understood what was wrong.
The problem is that knowledge about reliable and durable systems is the worst-spread. To understand why this is so, you can use the example of a stoplight in a car. If you are driving, ask yourself a question: do you know how a regular brake light works?

And now look at the photo: does the person who made this device know how the brake light is arranged?

I think he is well versed in how this system works, because it constantly breaks with him, and he has to deal with its support. In this example, it is a serviceable brake light - legacy-system, because its operator does not know how it works. And the switch assembled on the knee is an actively supported system. See for yourself, it is supported by electrical tape!
Therefore, there are always great difficulties when in a system that has been working properly for years, it suddenly turns out that something needs to be changed - nobody already knows how it functions.
Our company had an excellent example of such a situation with the system, which, when placing acting jobs, generated personalized notifications for suitable candidates. At first, we had 50,000 potential recipients, and the system each time looked for suitable ones among them and sent notifications. Later, the number of possible recipients grew - 100,000, 200,000 ... In general, after four and a half years, we had an Int32 overflow. We understood what happened only when someone noticed an id of two billion with something. It is interesting here that the database supported such numbers, but in the code that sent the messages, int was used, and it overflowed.
Each of us has stacks in which such problems lie, and they do not bother anyone just because they have not yet failed. One of the most powerful means to combat this state of affairs is to create visibility. Understand what is most important in the functioning of the components of your system, and make it visible.

To do this, you can take measurements, use the dashboard, monitor the performance of your database and so on. Take a look at what identities are used in your database, 32 bits or 64, and how far they are from overflow. See how much space you have on your hard drive, if you have enough resources and how the network is used. All these indicators should be visible. If you are responsible for a huge system that cannot be sorted out by simply reading it, you need as many viewpoints as possible. Run the system in the sandbox, make monitors for production, ensure visibility in the deployment pipeline. You need to see everything that your system does to understand how it works.
One of the reasons for the emergence of all these difficulties is that in the 80s and 90s, when many of these legacy systems were created, we actively convinced all other people that we would solve all their problems once and for all. Employees from sales departments and consultants created the impression that people could automate everything and dismiss all employees. We sold the idea that the product could be completed.

But in fact, the product is never complete. Only recently we began to realize that the development of software is a long-term investment of effort, software requires constant support. In the same way, the building of your office needs not only to be built, but also to ensure the permanent operation of the bathroom, electricity, it needs to be cleaned and washed all the time, change light bulbs and so on. We didn’t bother to explain at the time that the software needs constant support throughout its operation.
At the same time, we often sold systems that implemented only one mode of business operation. When people do the work in the usual way, that is, manually, they have a considerable degree of flexibility. If a hotel guest says that he is allergic to mushrooms, the employee will simply write this information on a piece of paper and send it to the kitchen. And when, instead of a living person, a resident communicates with an automatic registration system, he does not have the opportunity to inform her about his problem - there is no special button “do not serve mushrooms” in the system. The lodger will eventually turn to the administration, and it turns out that you need to make a change request, which will cost five thousand dollars. Then the administration thinks: “Maybe a lodger can eat mushrooms once?”
An alternative to a system that is adapted to perform its function in one and only way is a system in which all components are flexible and customizable. When you try to do this, it usually becomes so big that it never turns out. Both approaches are far from ideal; we do not need absolutely flexible systems, and we do not need single-task systems - we need constant interaction with the system, thanks to which the code will not become legacy. To achieve this goal is very difficult. All the time you need to deal with shareholders, then with the owners of the product, and instead of support they always need new features. And nevertheless, it is necessary to provide continuous interaction with the system.

In my experience, the easiest way to get time from the owners of the product to work with the system is as follows. Suppose you say you need four weeks. During this time you will not make any new features for clients and will not provide direct income, and yet this time is necessary to spend. And then at each discussion you should have an analysis of technical debt, which you managed to get rid of in these four weeks. So if you are asked how long it will take to increase the number of clients the system can work with, you answer - generally speaking, 12 weeks, but thanks to the refactoring we have spent, it will take only 3 weeks.
With this approach, product owners are beginning to understand that refactoring is vital, it’s not just fun for geeks, as they initially thought. They made an investment in you, allowing you four weeks to do things they did not understand. You must return this attachment, explaining that our software is now better and increasing its capabilities is now much easier.
Finally, let's answer the question - which project can be considered completed? What is our “definition of done”?
The project, whose code is deleted, the GitHub repositories are archived, the database is disabled, the servers no longer work, and the team sits on the beach and drinks beer.

Very often in the code of your organization there will be large chunks in which there is no need anymore. They exist only because they are afraid to get rid of them. Thanks to tools like Google Analytics, you now know that your site has a page that nobody has ever visited. This page is exactly with us. These pages still exist, because no one has gone through them and has not deleted everything unnecessary. Just software makes it "invisible", we do not see all these unnecessary things, and therefore do not pay attention to them. But over time, they make themselves felt - the code becomes more voluminous, the deployment is slower. The number of places where you may have a vulnerability in JavaScript is directly proportional to the size of the code being run. Therefore, you need to think about how to remove all this extra code.
When we create a project, we usually have metrics with which we try to match — the duration of the deployment cycle, performance, and so on. I have always been interested in trying to make a limit on the number of lines in a project - say, not more than 20 thousand. And if you need a new feature, you need to decide which feature we should get rid of.
This approach is quite successfully used in aircraft construction: when designing an aircraft, we know in advance the weight that we should not exceed. In construction, we know in advance the dimensions beyond which a building cannot be. People are perfectly able to work with this kind of strict restrictions on the size of the project in other engineering industries, but when developing software, the size is considered arbitrary. We have at our disposal terabyte hard drives and as much GitHub space as you need. But because of this lack of restrictions, code accumulates that no longer produces any value. And this is my third thought: when you have already understood the code, do not be afraid to start cleaning it and deleting unnecessary segments .
Our world works on legacy code. I’m sure that there are a lot of people among you who write great new progressive systems, but I’m also sure that you have a lot of people involved in, for example, integration with banking systems on COBOL. Has anyone in the room dealt with MUMPS? Ah, lucky ones. It is the world's worst programming language, it was created in the 1960s, and is still used in the 26 largest hospitals in the United States. If you want to earn a lot by a programmer in the US, learn it. He is terrible, his knowledge is very highly paid, and the health of millions of people in the United States is still dependent on this kind of software.
Legacy code is very important, and one cannot simply "add unit tests" or "replace with microservices". We need to learn to understand the inherited code and become its owners.

And from here the title of my report: we need to learn to control (control), change (alter) and delete (delete) the legacy code .
Thanks for attention.
If you are a netbook, pay attention: the next DotNext will take place on May 15-16 in Petersburg . There will be a lot of specifics on .NET-development (for an example, you can watch the top 10 of the previous conference), and some speakers are already known - for example, John Galloway from the .NET Foundation. You can see all the latest information on the conference website , buy tickets in the same place - and over time they become more expensive.