Info Desk: «Internet Archive» — history, mission and subsidiary projects
- Translation

Probably, there are not so many users on Habr who have never heard about the «Internet Archive», a service that searches and stores the digital data that is important for all mankind, whether it be the Internet pages, books, videos or other type of information.
Who manages the Internet archive, when it appeared and what is its mission? Read about it in the today's «Inquiry».
Why do we even need an «Archive»?
This is far from just entertainment. The mission of the organization is to provide the universal access to all information. The «Internet archive» seeks to fight the monopoly of the provision of information by both telecommunication companies (Google, Facebook, etc.) and governments.
At the same time, the «Archive» is a law-abiding organization. If under the U.S. law some information needs to be removed, the organization does so.
The «Internet archive» also serves as a tool for scientists, security agencies, historians (for example, archaeologists) and representatives of many other fields, not to mention individual users.
When did the «Internet archive» appear?
The creator of the “Archive” is Brewster Cale from the US, who created the company Alexa Internet. Both of his services have become extremely popular, both of them are still prosperous.
The «Internet archive» has started to archive the information from the websites and to keep the copies of the web pages in 1996. The headquarters of this nonprofit organization is located in San Francisco, USA.
However, for five years the data were unavailable for public access — the data was stored on the servers of the «Archive», and that's all, only the administration of the service could view the old copies of the sites. Since 2001, the service administration has decided to provide access to the stored data to everyone.
In the beginning, the «Internet archive» was just a web archive, but then the organization started saving books, audio files, moving images, software. Now the «Internet archive» acts as a repository for photos and other images of NASA, open Library texts, etc.
How does the organization exist?
The «Archive» exists on voluntary donations — both from the organizations and from the individuals. You can provide support in bitcoins, the wallet number is 1Archive1n2C579dMsAu3iC6tWzuQJz8dN. This wallet, by the way, has received 357.47245492 BTC during its existence, which is about $2.25 million at the current rate.
How does «Archive» work?
Most of the staff are employed in the book scanning centers, doing routine, but rather time-consuming work. The organization has three data centers located in California, USA. One in San Francisco, one in the Redwood city, one in Richmond. In order to avoid the risk of data loss in the event of a natural disaster or other catastrophes, the «Archive» has spare capacity in Egypt and Amsterdam.
«Millions of people have spent a lot of time and effort to share with others what we know in the form of the Internet. We want to create a library for this new publishing platform, » said Brewster Kahle, the founder of the Internet Archive)
How big is the «Archive» now?
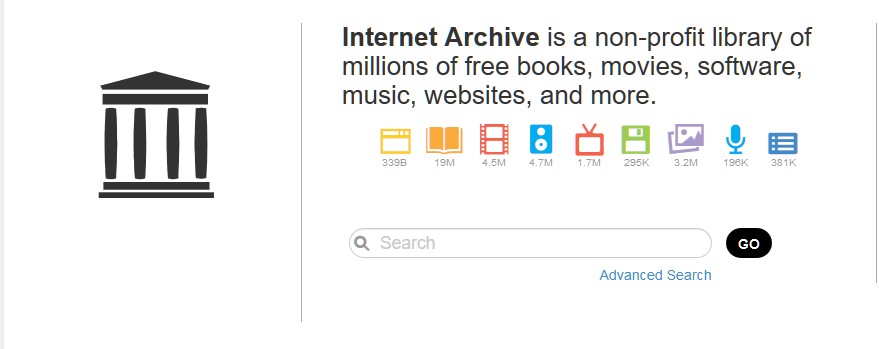
The «Internet archive» has several divisions, and the one that collects information from the sites has its own name — Wayback Machine. At the time of writing the «Inquiry», the archive contained 339 billion saved web pages. In 2017, the «Archive» stored 30 petabytes of information, which is about 300 billion web pages, 12 million books, 4 million audio recordings, 3.3 million videos, 1.5 million photos and 170 thousand different software distributions. In just a year, the service significantly «added weight». Now the «Archive» stores 339 billion web pages, 19 million books, 4.5 million video files, 4.7 million audio files, 3.2 million images of various kinds, 381 thousand software distributions.
How is the data storage organized?
The information is stored on hard drives in the so-called «data nodes». These are the servers. Each of them contains 36 hard drives (plus two operating system drives). Data nodes are grouped into arrays of 10 machines and represent a cluster storage. In 2016, the «Archive» used 8-terabyte HDD, now the situation is about the same. It turns out that one node stores about 288 terabytes of data. In general, the hard drives of other sizes are also used: 2.3 and 4 TB.
In 2016, there were about 20,000 hard drives. The data centers of the «Archive» are equipped with air conditioning units for climate control with constant characteristics. A clustered storage of 10 nodes consumes about 5 kilowatts of energy.
The structure of the Internet Archive is a virtual «library», which is divided into sections such as books, movies, music, etc. For each element there is a description in the catalog — usually the name, the author's name and additional information. From a technical point of view, the elements are structured and located in Linux directories.
The total amount of data stored by the «Archive» is 22 PB, and now there is room for another 22 PB. «Because we are paranoid,» — state the representatives of the service.

Look at the screenshot of the directory contents — there is a file with the name ending with "_files.xml". This is a directory with information about all files in the directory.
What will happen to the data if one or more servers fail?
Nothing bad — the data is duplicated. As soon as a new item appears in the «Archive» library, it's immediately replicated and placed on different hard drives on different servers. The process of the content «mirroring» helps to cope with problems like power outages and file system failures.
If the hard disk fails, it is replaced with a new one. Thanks to the mirrored and reduplicated data structure, it's immediately filled with data that was on the old HDD that failed.
The «Archive» has a specialized system that monitors the status of the HDD. During a day, you have to replace 6 to 7 of the failed drives.
What is Wayback Machine?
This is just one of the «Internet archive» services that specializes in saving web pages. The service has its own «spider», which regularly examines all the sites available on the network and stores them on specialized servers. The more popular a website is, the more often the robot copies its content. If the resource administrator doesn't want the site information to be copied by the bot, it's enough to register a ban in the robots.txt file.
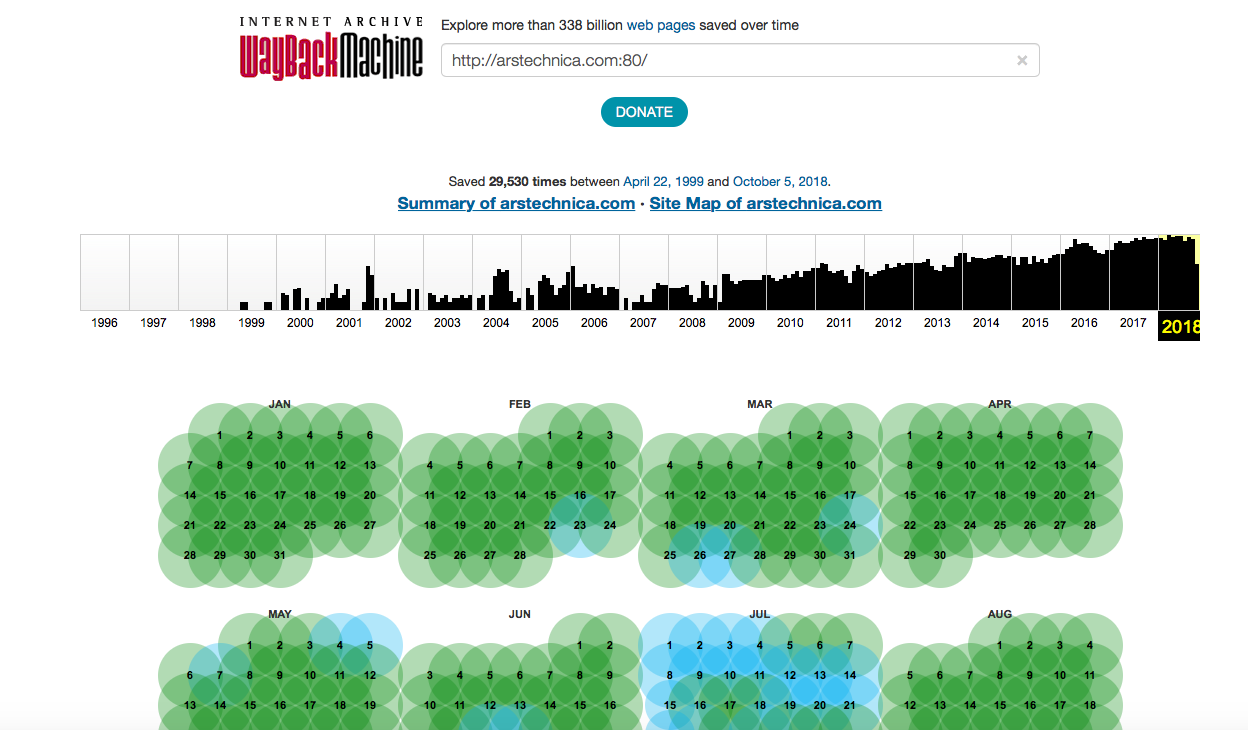
Popular resources are copied frequently — almost daily. Wayback Machine indexes even the social networks, including Twitter, Facebook
In 2017, the «Archive» launched the updated Wayback Machine, promising more convenient access to the saved web pages. The service was greatly redesigned, if not coded from scratch. Now it supports a number of file formats that previously simply couldn't be saved. In the same 2017, the organization said that every week its servers save about 1 billion web pages.
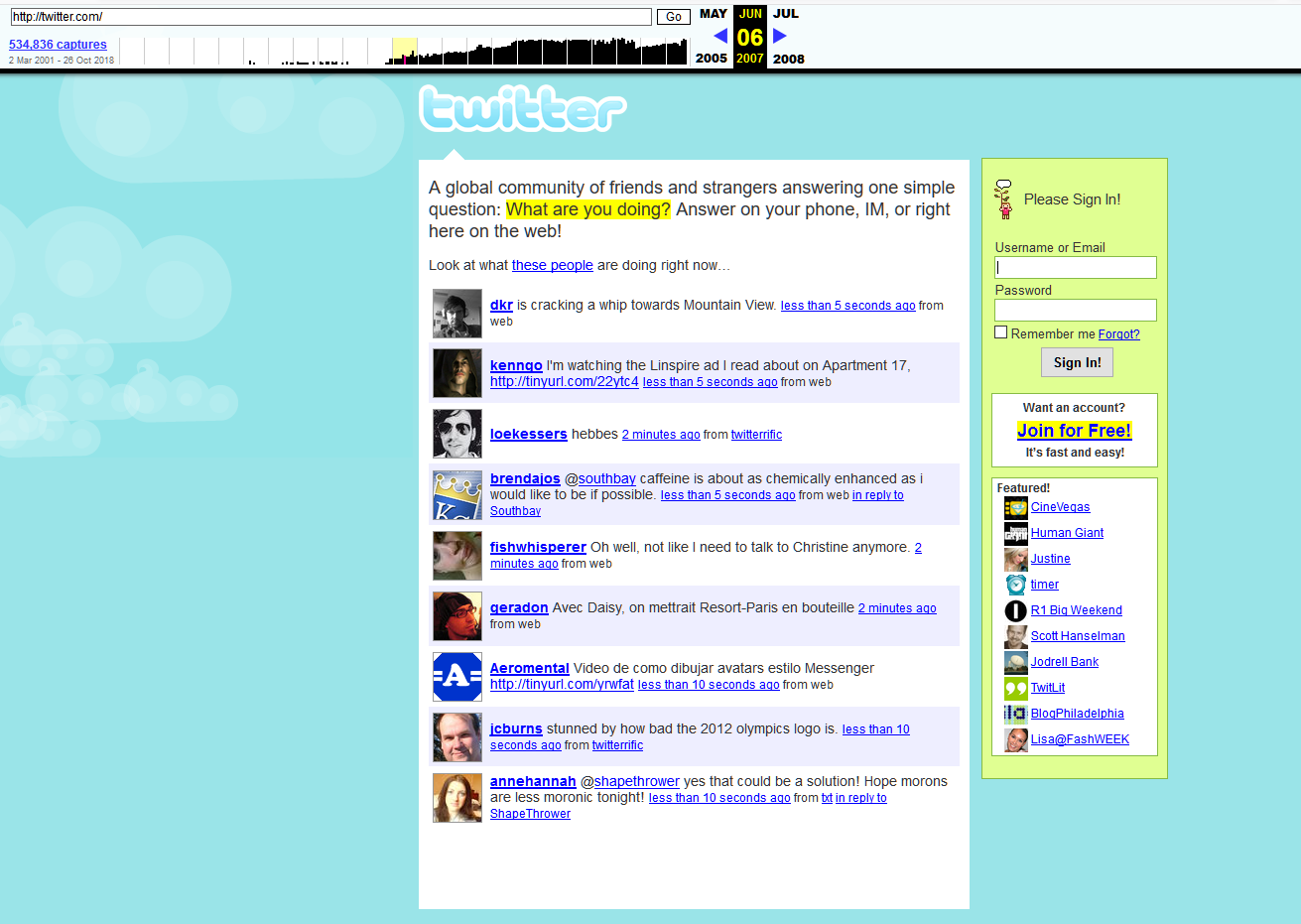
This is what Twitter looked like in 2007
What else can be found in the «Internet archive» database?
Books. The collection of the organization is huge, it includes digitized books, both common and very rare editions. The books are saved not only in English, but also in many other languages. The «Archive» has specialized centers for scanning books, 33 of such centers in total. They are located in five countries around the world.
The center's staff scans about 1,000 books a day. The database of the service contains millions of publications. The work on their digitization is funded by both ordinary people and various organizations, including libraries and foundations.
Since 2007, the «Internet archive» has been storing public books from Google Book Search in its database. After the launch, the book database has grown rapidly — in 2013, there were more than 900 thousand books saved from the Google service.
One of the services of the «Archive» also provides access to the books that are fully open. There is more than a million of them already. This service is called Open Library.
Video. The service stores 4.5 million videos. They are divided into topics and have a very different focus. The «Archive» servers store films, documentaries, sports events, TV shows and many other materials.
In 2015, the «Archive» gave rise to a large-scale project — digitization of the video cassettes. At first, it was about 40 thousand cassettes from the archive of Marion Stokes, a woman who has been recording the news on tape for decades. Then other video tapes added up. They were sent to the «Archive» by the fans of the idea of digitizing data that are important for humanity.
Audio files. Similarly to the videos, the «Archive» stores audio files, which are also divided by subjects. Last year, the «Archive» began to implement its new project — the decoding of shellac records, the oldest format of audio recordings. The sound was preserved on the plates of shellac — a natural resin, which is isolated by the female scale insects. In total, the archive Great 78 Project contains several hundred thousand records.
Software. Of course, it's simply impossible to store all the software created by mankind, even for the «Archive». The servers store vintage — for example, the programs for Macintosh, software for DOS and other software. In 2016, the «Archive» employees posted over 1500 programs for Windows 3.1. You can work directly in the browser. In 2017, the Internet Archive has released the archive of software for the first Macintosh.
Games. Yes, the «Archive» provides access to a huge number of games. Some of them can be played in the browser emulator environment. A variety of games is stored, including the one for the portable analog-digital consoles. There are games for MS-DOS and console games for Atari and ColecoVision.

For the first time the archive of old games was uploaded by the organization in 2013. We are talking about the titles of 30-40 years ago, which could be played directly in the browser. These are the games for Atari 2600 (1977), Atari 7800 (1986), ColecoVision (1982), Philips Videopac G7000 (1978) and Astrocade (1983). The most interesting thing is that the Internet Archive has ensured that you can play quite legally. Now the collection has more than 3400 games and it keeps growing.