The theory of happiness. Statistics, as a scientific way to not know anything
I continue to acquaint Habr's readers with chapters from his book “The Theory of Happiness” with the subtitle “Mathematical foundations of the laws of meanness”. This is not yet a popular science book published, very informally telling how mathematics allows us to look at the world and life of people with a new degree of awareness. It is for those who are interested in science and for those who are interested in life. And since our life is complex and, by and large, unpredictable, the emphasis in the book is mainly on probability theory and mathematical statistics. Here theorems are not proved and the fundamentals of science are not given; this is by no means a textbook, but what is called recreational science. But it is this almost playful approach that allows us to develop intuition, brighten up with vivid examples lectures for students and, finally, explain to nemathematicians and our children,
This chapter deals with statistics, weather, and even philosophy. Don't be scared, just a little bit. No more than what can be used for tabletalk in a decent society.

How often in the summer we plan on our weekends a trip to nature, a walk in the park or a picnic, and then the rain breaks our plans, sharpening us in the house! And it would be okay if this happened once or twice in a season, sometimes it seems that the bad weather is following the weekends, getting on Saturday or Sunday time after time!
A relatively recently published article by Australian researchers: "Weekly cycles of peak temperature and intensity of urban heat islands." She was picked up by the news publications and reprinted the results with the title: “You don’t think! Scientists have found out: the weather is on the weekend, really worse than on weekdays ". The paper cites statistics of temperature and precipitation over many years in several cities in Australia, indeed, revealing a decrease in temperature at certain times on Saturdays and Sundays. After that, an explanation is given that relates the local weather to the level of air pollution due to the increasing traffic flow. Shortly before, a similar study was conducted in Germany and led to about the same conclusions.
Agree that a fraction of a degree is a very subtle effect. While complaining about the bad weather on the long-awaited Saturday, we are discussing whether it was a sunny or rainy day, this fact is easier to register, and later to recall, even without possessing accurate instruments. We will conduct our own little research on this topic and get a wonderful result: we can confidently say that we do not know whether day and week are connected in Kamchatka. Research with a negative result usually does not fall on the pages of magazines and news feeds, but it’s important for you and I to understand on what basis I, in general, can confidently say something about random processes. And in this regard, a negative result becomes no worse than a positive one.
Statistics are accused of the mass of sins: both of lies and possibilities of manipulation and, finally, of incomprehensibility. But I really want to rehabilitate this area of knowledge, to show how difficult the task is for which it is intended and how difficult it is to understand the answer given by statistics.
Probability theory operates with accurate knowledge of random variables in the form of distributions or exhaustive combinatorial calculations. I emphasize once again that it is possible to have accurate knowledge of a random variable. But what if this exact knowledge is not available to us, and the only thing we have is observation? The developer of a new drug has some limited number of tests, the creator of the traffic control system has only a series of measurements on a real road, the sociologist has the results of surveys, and he can be sure that answering some questions, the respondents just lied.
It is clear that one observation does not give anything. Two - a little more than nothing, three, four ... one hundred ... how many observations are needed to gain any knowledge of a random quantity, which one could be sure of with mathematical precision? And what is this knowledge? Most likely, it will be presented in the form of a table or a histogram, making it possible to estimate some parameters of a random variable, they are called statisticians (for example, domain, average or variance, asymmetry, etc.). Perhaps, looking at the histogram, it will be possible to guess the exact form of the distribution. But attention! - all the results of the observations themselves will be random variables! While we do not have accurate knowledge of the distribution, all the results of observations give us only a probabilistic description of a random process!
What makes mathematical statistics an exact science? Her methods allow us to conclude our ignorance in a clearly limited framework and give a computable measure of confidence that within these frameworks our knowledge is consistent with the facts. It is a language in which one can reason about unknown random variables so that the reasoning makes sense. Such an approach is very useful in philosophy, psychology or sociology, where it is very easy to embark on lengthy arguments and discussions without any hope of obtaining positive knowledge and, moreover, on evidence. Literate statistical processing of data is devoted to the mass of literature, because it is an absolutely necessary tool for physicians, sociologists, economists, physicists, psychologists ... in a word, for all scientifically researching the so-called "real world"
Now take another look at the epigraph to this chapter and realize that statistics, which is so scornfully called the third degree of lies, is the only thing that natural sciences have. Is not the main law of the meanness of the universe! All the laws of nature known to us, from physical to economic, are built on mathematical models and their properties, but they are verified by statistical methods in the course of measurements and observations. In everyday life, our mind makes generalizations and notices patterns, selects and recognizes repetitive images, this is probably the best that the human brain can do. This is exactly what artificial intelligence is taught today. But the mind saves its strength and is inclined to draw conclusions on individual observations, without much worrying about the accuracy or validity of these conclusions.“Everyone makes general conclusions from one example. At least that's what I do . ” And while we are talking about art, the character of pets or a discussion of politics, you can not worry about it. However, during the construction of the aircraft, the organization of the airport's dispatch service or the testing of a new drug, it is no longer possible to refer to the fact that “I think so,” “intuition tells” and “anything can happen in life”. Here you have to limit your mind within the framework of rigorous mathematical methods.
Our book is not a textbook, and we will not study in detail the statistical methods and confine ourselves to only one thing - the technique of testing hypotheses. But I would like to show the course of reasoning and the form of the results characteristic of this area of knowledge. And, perhaps, to some of the readers, the future student, not only it becomes clear why he is being tortured with mathematical statistics, all these QQ-diagrams, t-and F-distributions, but another important question comes to mind: how is it possible to know sure about a random occurrence? And what exactly do we learn using statistics?
The main pillars of mathematical statistics are probability theory, the law of large numbers, and the central limit theorem .
The law of large numbers, in a free interpretation, says that a large number of observations of a random variable almost certainly reflects its distribution , so the observed statistics: mean, variance and other characteristics tend to exact values corresponding to a random variable. In other words, the histogram of the observed values with an infinite number of data, almost certainly tends to the distribution, which we can consider to be true. It is this law that binds the “domestic” frequency interpretation of probability and the theoretical one, as measures on a probability space.
The central limit theorem, again, in a free interpretation, says that one of the most likely forms of distribution of a random variable is the normal (Gaussian) distribution. The exact formulation sounds different: the average value of a large number of identically distributed real random variables, regardless of their distribution, is described by a normal distribution.This theorem is usually proved by applying functional analysis methods, but we will see later that it can be understood and even expanded by introducing the concept of entropy, as a measure of the probability of the system state: the normal distribution has the greatest entropy with the least number of restrictions. In this sense, it is optimal when describing an unknown random variable, or a random variable, which is a combination of many other variables, the distribution of which is also unknown.
These two laws form the basis of quantitative assessments of the reliability of our knowledge based on observations. Here we are talking about a statistical confirmation or refutation of the assumption that can be made from some general basis and a mathematical model. This may seem strange, but in itself, statistics do not produce new knowledge. A set of facts turns into knowledge only after building links between the facts that form a certain structure. It is these structures and relationships that allow making predictions and making general assumptions based on something that goes beyond statistics. Such assumptions are called hypotheses . It's time to recall one of the laws of merphology, Percig's postulate :
The task of mathematical statistics to limit this infinite number, or rather to reduce them to one, and not necessarily true. To move to a more complex (and often more desirable) hypothesis, it is necessary, using observational data, to refute a simpler and more general hypothesis, or to support it and abandon the further development of the theory. The hypothesis often tested in this way is called null , and there is a deep meaning in it.
What can play the role of the null hypothesis? In a sense, anything, any statement, but on condition that it can be translated into a measurement language. Most often, the hypothesis is the expected value of a parameter that turns into a random variable during the measurement, or the absence of a relationship (correlation) between two random variables. Sometimes it is assumed the type of distribution, random process, some mathematical model is proposed. The classical statement of the question is as follows: do observations allow one to reject the null hypothesis or not? More precisely, with what degree of confidence can we say that observations cannot be obtained on the basis of the null hypothesis? In this case, if we could not rely on statistical data to prove that the null hypothesis is false, then it is assumed to be true.
And here you would think that researchers are forced to make one of the classic logical errors, which bears the resounding Latin name ad ignorantiam. This is the argument of the truth of a statement, based on the absence of evidence of its falsity. A classic example is the words spoken by Senator Joseph McCarthy when he was asked to present facts to support the accusation that a certain person is a communist: “I have some information on this issue, except for the general statement of the competent authorities that there is nothing in his file , to exclude his connection with the Communists . " Or even brighter: “The snowman exists, because no one has proven otherwise”. Identifying the difference between a scientific hypothesis and similar tricks is the subject of a whole field of philosophy: the methodology of scientific knowledge . One of its striking results is the criterion of falsifiability , put forward by the remarkable philosopher Karl Popper in the first half of the 20th century. This criterion is designed to separate scientific knowledge from unscientific, and, at first glance, it seems paradoxical:
What is not the law of meanness! It turns out that any scientific theory is automatically potentially incorrect, and a theory that is true “by definition” cannot be considered scientific. Moreover, such criteria as mathematics and logic do not satisfy this criterion. However, they are referred not to the natural sciences, but to the formal ones , which do not require checking for falsifiability. And if we add another result of the same time: the principle of Gödel ’s incompleteness , which asserts that within any formal system one can formulate an assertion that can neither be proved nor disproved, then it becomes unclear why, in general, to be engaged in the whole science. However, it is important to understand that Popper’s falsifiability principle says nothing about the truththeory, but only about whether it is scientific or not. It can help determine whether a certain theory gives a language in which it makes sense to talk about the world or not.
But still, why, if we cannot reject a hypothesis on the basis of statistical data, are we entitled to accept it as true? The fact is that the statistical hypothesis is not taken from the desire of the researcher or his preferences; it must flow from any general formal laws. For example, from the Central Limit Theorem, or from the principle of maximum entropy. These laws correctly reflect the degree of our ignorance , without unnecessarily adding unnecessary assumptions or hypotheses. In a sense, this is a direct use of the famous philosophical principle known as Occam's razor :
Thus, when we accept the null hypothesis, based on the absence of its refutation, we formally and honestly show that as a result of the experiment, the degree of our ignorance remained at the same level . In the example with the snowman, explicitly or implicitly, but the opposite is assumed: the lack of evidence that this mysterious creature does not exist seems to be something that can increase the degree of our knowledge about it.
In general, from the point of view of the principle of falsifiability, any statement about the existence of something is unscientific, because the absence of evidence does not prove anything. At the same time, the statement about the absence of something can be easily refuted by providing a copy, indirect evidence, or by proving the existence by construction. And in this sense, statistical testing of hypotheses analyzes the statements about the absence of the desired effect and can provide, in a certain sense, an exact refutation of this statement. This is precisely what fully justifies the term “null hypothesis”: it contains the necessary minimum knowledge of the system.
It is very important to emphasize that if the statistics suggest that the null hypothesis can be rejected, this does not mean that we thereby proved the truth of any alternative hypothesis. Statistics should not be confused with logic, therein lies a lot of subtle errors, especially when conditional probabilities for dependent events come into play. For example: it is very unlikely that a person can be Pope ( billion), does it follow from this that Pope John Paul II was not a man? The statement seems absurd, but, unfortunately, such an “obvious” conclusion is just as wrong: the test showed that the mobile test for the alcohol content in the blood gives no more
billion), does it follow from this that Pope John Paul II was not a man? The statement seems absurd, but, unfortunately, such an “obvious” conclusion is just as wrong: the test showed that the mobile test for the alcohol content in the blood gives no more both false positive and false negative results, therefore, in
both false positive and false negative results, therefore, in  cases, he correctly identify a drunk driver. Let's test
cases, he correctly identify a drunk driver. Let's test drivers and let
drivers and let  of will be really drunk. As a result, we get
of will be really drunk. As a result, we get false positives and
false positives and  a false negative result: that is, for one drunkard who has missed, nine innocently charged random drivers will fall. What is not the law of meanness! Parity will only be observed if the proportion of drunk drivers equals
a false negative result: that is, for one drunkard who has missed, nine innocently charged random drivers will fall. What is not the law of meanness! Parity will only be observed if the proportion of drunk drivers equals , or if the ratio of false positive and false negative results will be close to the real ratio of drunk drivers to sober. Moreover, the more sober the nation being surveyed, the more unfair the application of the device described by us!
, or if the ratio of false positive and false negative results will be close to the real ratio of drunk drivers to sober. Moreover, the more sober the nation being surveyed, the more unfair the application of the device described by us!
Here we are faced with dependent events . Remember, in the Kolmogorov definition of probability, we talked about the method of adding the probability of combining events: the probability of combining two events is equal to the sum of their probabilities minus the probability of their intersection. However, how the probability of intersection of events is calculated, these definitions do not speak. For this, a new concept is introduced: the conditional probability and the dependence of events on each other come to the fore.
The probability of intersection of events A and B is defined as the product of the probability of the event B and the probability of the event if you know what happened
if you know what happened  : and independent if
: and independent if  , or
, or  , or
, or  .
.
Thus, we complete the formal definition of probability, begun in the first chapter.
Intersection is a commutative operation, i.e. . This immediately follows the Bayes theorem:
. This immediately follows the Bayes theorem:
In our example with drivers and alcohol test, we have events: - the driver is drunk, - The test gave a positive result. Probabilities: - the likelihood of a stopped driver is drunk;
- the likelihood of a stopped driver is drunk;  - the probability that the test will give a positive result if it is known that the driver is drunk (excluded false negative results),
- the probability that the test will give a positive result if it is known that the driver is drunk (excluded false negative results),  - the probability that the test is drunk, if the test gave a positive result (excluded
- the probability that the test is drunk, if the test gave a positive result (excluded  false positive results). Calculate
false positive results). Calculate - probability of getting a positive test result on the road:
- probability of getting a positive test result on the road:
These examples are thoroughly analyzed by medical test students or legal practitioners. But, I am afraid that journalists or politicians are not taught either mathematical statistics or probability theory, but they willingly appeal to statistical data, freely interpret them and carry the resulting "knowledge" to the masses. Therefore, I urge my reader: I figured out the math myself, help me figure out another! I see no other antidote to ignorance.
We will consider and apply in practice only one of a variety of statistical methods: testing statistical hypotheses. For those who have already connected their lives with the natural or social sciences in these examples there will not be something shockingly new.
Suppose we repeatedly measure a random variable with an average value and standard deviation
and standard deviation  . According to the Central Limit Theorem, the observed average value will be distributed normally. It follows from the law of large numbers that its average will tend to, and from the properties of the normal distribution it follows that after
. According to the Central Limit Theorem, the observed average value will be distributed normally. It follows from the law of large numbers that its average will tend to, and from the properties of the normal distribution it follows that after  measurement the observed variance of the mean will decrease as
measurement the observed variance of the mean will decrease as  . The standard deviation can be considered as an absolute error of measurement of the mean, the relative error will be equal to
. The standard deviation can be considered as an absolute error of measurement of the mean, the relative error will be equal to . These are very general conclusions that do not depend on sufficiently largeon the specific distribution form of the random variable under study. Two useful rules follow (not laws):
. These are very general conclusions that do not depend on sufficiently largeon the specific distribution form of the random variable under study. Two useful rules follow (not laws):
1. Minimum number of tests should be dictated by the desired relative error  . However, if
. However, if . Withclose to zero, the relative error is better to replace the absolute.
. Withclose to zero, the relative error is better to replace the absolute.
2. Let the null hypothesis be the assumption that the observed average value is. Then, if the observed average does not exceed the limits , the probability that the null hypothesis is true will be at least .
, the probability that the null hypothesis is true will be at least .
If replaced in these rules on
on  then the degree of confidence will rise to
then the degree of confidence will rise to  this is a very strong rule which in physical sciences separates the assumptions from the experimentally established fact.
this is a very strong rule which in physical sciences separates the assumptions from the experimentally established fact.
It will be useful for us to consider the application of these rules to the Bernoulli distribution describing a random variable that takes exactly two values, conventionally called “success” and “failure”, with a given probability of success. . In this case
. In this case and
and  so that for the required number of experiments and a confidence interval we get
so that for the required number of experiments and a confidence interval we get
Rulefor the Bernoulli distribution can be used to determine the confidence interval when constructing histograms. Essentially, each histogram bar represents a random variable with two values: “hit” - “missed”, where the probability of hitting corresponds to the simulated probability function. As a demonstration, we will generate a set of samples for three distributions: uniform, geometric, and normal, after which we compare the estimates of the spread of the observed data with the observed spread. And here we again see echoes of the central limit theorem, manifested in the fact that the distribution of data around the average values in histograms is close to normal. However, near zero, the scatter becomes asymmetric and approaches another very likely distribution, the exponential. This example shows well what I meant
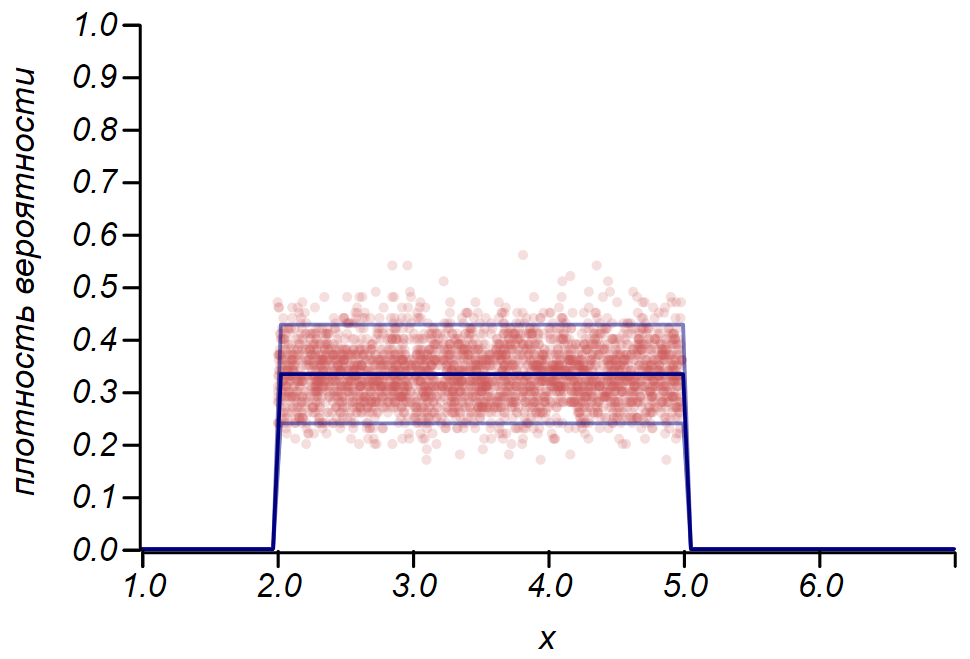
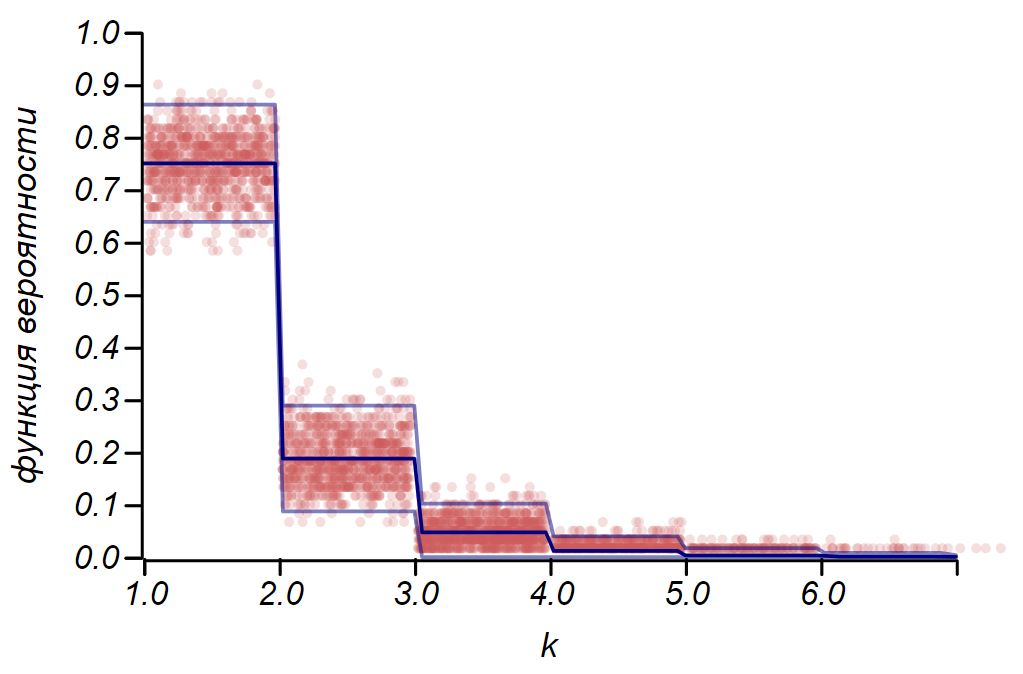
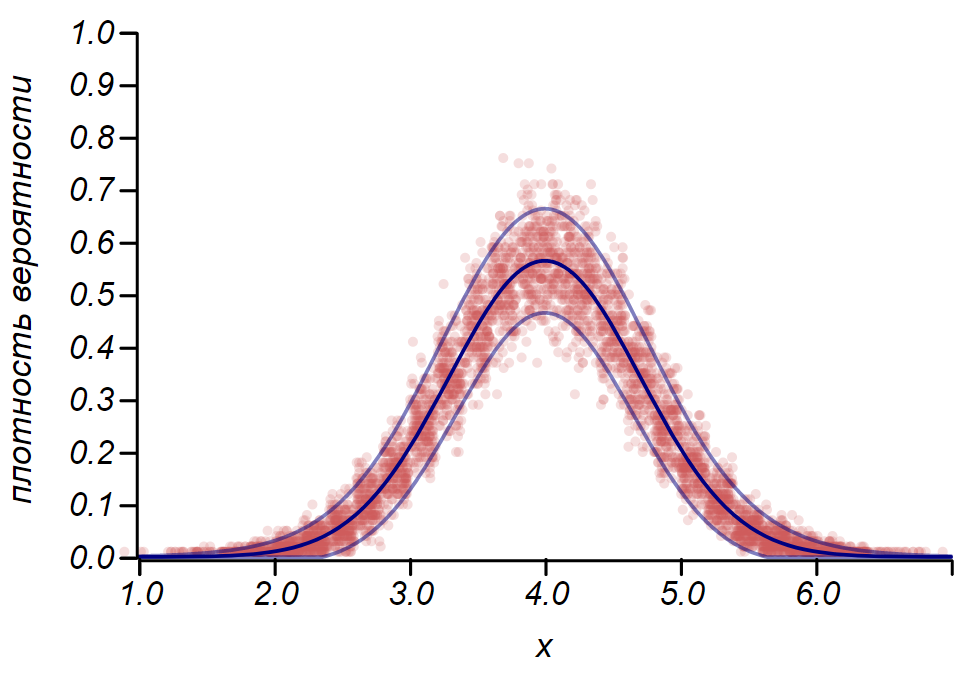 An example showing the ratio of the scatter estimate made according to the rule and the observed spread for three random variables.
An example showing the ratio of the scatter estimate made according to the rule and the observed spread for three random variables.
It is important to understand that the rules and even do not save us from mistakes. They do not guarantee the truth of any statement, they are not evidence. Statistics limit the degree of distrust of the hypothesis, and nothing more.
The mathematician and author of the excellent course in probability theory Gian-Carlo Roth, at his lectures at MIT, gave this example. Imagine a scientific journal, the editorial staff of which made a volitional decision: to accept for publication only articles with positive results that satisfy the rule.or stricter. At the same time, the editorial column states that readers can be confident that with probabilitythe reader will not find the wrong result on the pages of this magazine! Alas, this statement is easily refuted by the same reasoning, which led us to a flagrant injustice when testing drivers for alcohol. Let be researchers subjected to experience hypotheses, of which only some part is true, say,  . Based on the meaning of hypothesis testing, it can be expected that
. Based on the meaning of hypothesis testing, it can be expected that erroneous hypotheses will not be mistakenly rejected, and will be logged along with
erroneous hypotheses will not be mistakenly rejected, and will be logged along with  correct results. Total of
correct results. Total of results a good third would be wrong!
results a good third would be wrong!
This example perfectly demonstrates our domestic law of meanness, which has not yet entered into the anthology of merphology, Chernomyrdin's law :
It is easy to get a general estimate of the proportion of incorrect results that will be included in the journal issues, assuming that the proportion of correct hypotheses is equal and the probability of making an erroneous hypothesis is :
and the probability of making an erroneous hypothesis is :
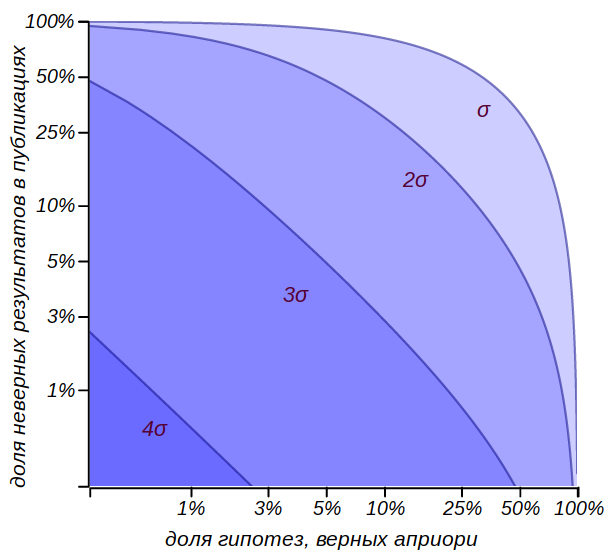 Estimation of the share of publications containing deliberately incorrect results when adopting various criteria for testing hypotheses. It can be seen that taking hypotheses by the rule may be risky, while the criterion
Estimation of the share of publications containing deliberately incorrect results when adopting various criteria for testing hypotheses. It can be seen that taking hypotheses by the rule may be risky, while the criterion  can already be considered quite strong.
can already be considered quite strong.
Of course, we don't know that. , and we will never know, but it is obviously less than one, which means, in any case, the statement from the editorial column cannot be taken seriously. You can limit yourself to a rigid framework of the criterion., but it requires a very large number of tests. This means that it is necessary to increase the proportion of correct hypotheses in the set of possible assumptions. The standard approaches of the scientific method of knowledge are aimed at this - the logical consistency of hypotheses, their consistency with facts and theories that have proven their applicability, reliance on mathematical models and critical thinking.
, and we will never know, but it is obviously less than one, which means, in any case, the statement from the editorial column cannot be taken seriously. You can limit yourself to a rigid framework of the criterion., but it requires a very large number of tests. This means that it is necessary to increase the proportion of correct hypotheses in the set of possible assumptions. The standard approaches of the scientific method of knowledge are aimed at this - the logical consistency of hypotheses, their consistency with facts and theories that have proven their applicability, reliance on mathematical models and critical thinking.
At the beginning of the chapter we talked about the fact that weekends and bad weather coincide more often than we would like. Let's try to complete this study. Every rainy day can be viewed as the observation of a random variable — a day of the week that obeys the Bernoulli distribution with probability . We take as the null hypothesis the assumption that all days of the week are the same in terms of weather and it can rain in any of them equally likely. We have two weekends, in total, we get the expected probability of coincidence of a bad weather day and a holiday equal to
. We take as the null hypothesis the assumption that all days of the week are the same in terms of weather and it can rain in any of them equally likely. We have two weekends, in total, we get the expected probability of coincidence of a bad weather day and a holiday equal to , this value will be a parameter of the Bernoulli distribution. How often does it rain? At different times of the year, of course, in different ways, but in Petropavlovsk-Kamchatsky, on average, there are ninety rainy or snowy days per year. So the flow of precipitation days has an intensity of about
, this value will be a parameter of the Bernoulli distribution. How often does it rain? At different times of the year, of course, in different ways, but in Petropavlovsk-Kamchatsky, on average, there are ninety rainy or snowy days per year. So the flow of precipitation days has an intensity of about . Let's calculate how many rainy weekends we have to register in order to be sure that there is some pattern. The results are shown in the table.
. Let's calculate how many rainy weekends we have to register in order to be sure that there is some pattern. The results are shown in the table.
What do these numbers say? If it seems to you that that year in a row there was no summer, that the evil fate is haunting your weekend by sending rain on them, you can check and confirm it. However, during the summer, evil rock can only be caught if more than two-fifths of the weekend turns out to be rainy. The null hypothesis suggests that only a quarter of the weekend should coincide with inclement weather. For five years of observations, one can hope to notice subtle deviations beyond the limits of and, if necessary, proceed to their explanation.
and, if necessary, proceed to their explanation.
I used the school weather diary, which was conducted from 2014 to 2018, and found out what happened during these five years. rainy days of them
rainy days of them  come on the weekend. This is indeed more than the expected number on
come on the weekend. This is indeed more than the expected number on days, but significant deviations begin with
days, but significant deviations begin with days, so this, as we said in childhood: "does not count." This is how the data series and the histogram look, showing the distribution of the weather by days of the week. Horizontal lines on the histogram indicate the interval in which a random deviation from a uniform distribution can be observed with the same data volume.
days, so this, as we said in childhood: "does not count." This is how the data series and the histogram look, showing the distribution of the weather by days of the week. Horizontal lines on the histogram indicate the interval in which a random deviation from a uniform distribution can be observed with the same data volume.
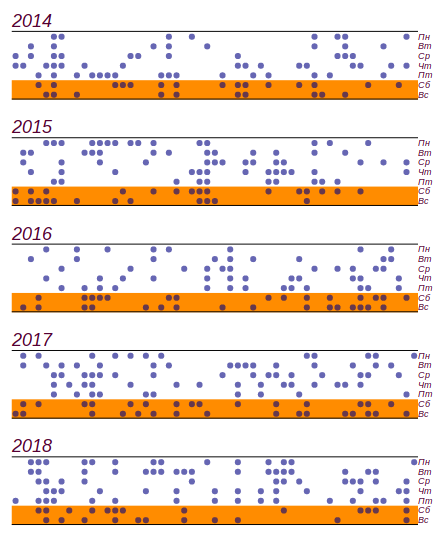
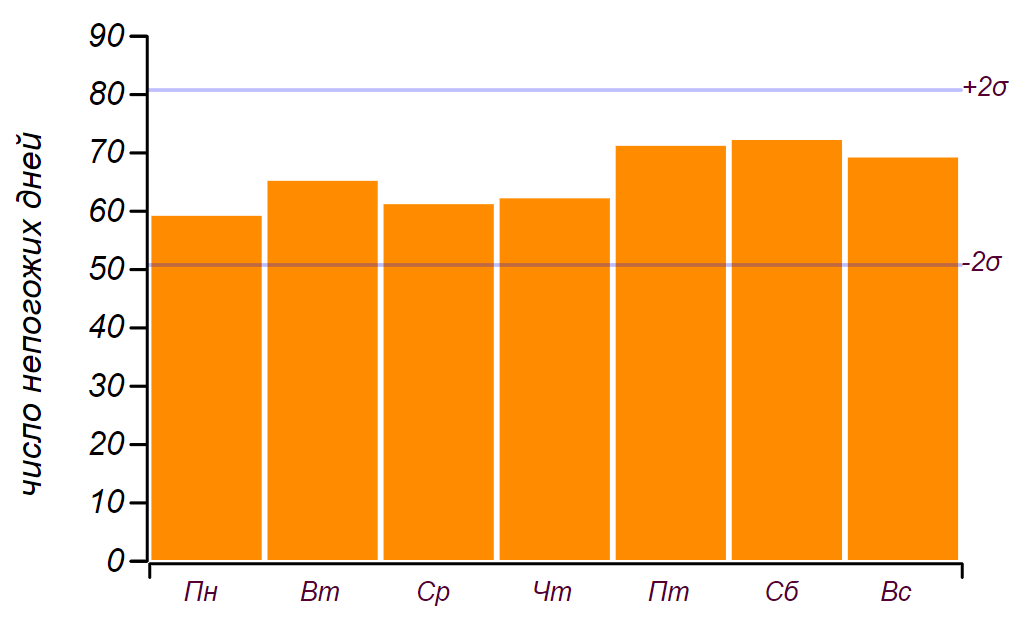
The initial data series and the distribution of bad days by days of the week, obtained from five years of observations.
It can be seen that since Friday there is indeed an increase in the number of days with bad weather. But to find the reason for this growth, the prerequisites are not enough: the same result can be obtained simply by going through random numbers. Conclusion: for five years of weather observation, I have accumulated almost two thousand records, but I did not learn anything new about the distribution of weather by days of the week.
When looking at the diary entries, it is clearly striking that the bad weather does not come one by one, but two or three days or even weekly cyclones. Does it somehow affect the result? You can try to take this observation into account, and assume that it rains an average of two days (in fact, days), then the probability to cut off the weekend increases to
days), then the probability to cut off the weekend increases to  . With such a probability, the expected number of matches for five years should be
. With such a probability, the expected number of matches for five years should be that is from
that is from  before
before  time. Observed valuedoes not fall within this range, which means that the hypothesis of the effect of double weather days can be safely rejected. Did we learn something new? Yes, we learned: it would seem that the obvious feature of the process does not entail any effect. This is worth considering, and we will do it a little later. But the main conclusion: there are no reasons to consider any more subtle effects, since observations and, most importantly, their number, consistently speak in favor of the simplest explanation.
time. Observed valuedoes not fall within this range, which means that the hypothesis of the effect of double weather days can be safely rejected. Did we learn something new? Yes, we learned: it would seem that the obvious feature of the process does not entail any effect. This is worth considering, and we will do it a little later. But the main conclusion: there are no reasons to consider any more subtle effects, since observations and, most importantly, their number, consistently speak in favor of the simplest explanation.
But our discontent is caused not by five-year or even annual statistics, human memory is not so long. It's a shame when it rains on the weekend three or four times in a row! How often can this be observed? Especially if you remember that the nasty weather does not come alone. The problem can be formulated as follows: “What is the probability that Weekend in a row will be rainy? ”It is reasonable to assume that bad days form a Poisson stream with intensity  . This means that, on average, a quarter of the days of any period will be bad weather. Observing only the weekends, we should not change the intensity of the flow and from all the weekends the bad weather should make up, on average, also a quarter. So, we put forward the null hypothesis: the Poisson flow of bad weather, with a known parameter, and therefore, the intervals between Poisson events are described by an exponential distribution. We are interested in discrete intervals:
. This means that, on average, a quarter of the days of any period will be bad weather. Observing only the weekends, we should not change the intensity of the flow and from all the weekends the bad weather should make up, on average, also a quarter. So, we put forward the null hypothesis: the Poisson flow of bad weather, with a known parameter, and therefore, the intervals between Poisson events are described by an exponential distribution. We are interested in discrete intervals: of the day, etc., so we can use the discrete analog of the exponential distribution — the geometric distribution with the parameter . The figure shows that we have succeeded and it is clear that the assumption that we are observing the Poisson process has no reason to reject.
of the day, etc., so we can use the discrete analog of the exponential distribution — the geometric distribution with the parameter . The figure shows that we have succeeded and it is clear that the assumption that we are observing the Poisson process has no reason to reject.
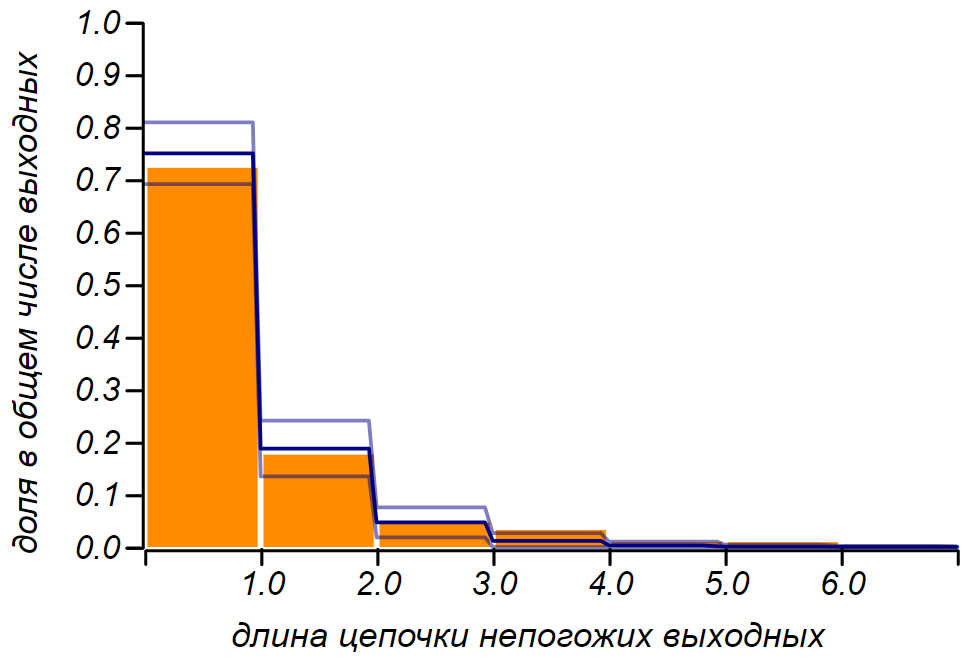
The observed distribution of the lengths of the failed output chains is theoretical. The thin line shows the tolerances for the number of observations that we have.
One may ask, such a question: how many years it is necessary to conduct observations, in order that we notice the difference indays could you confidently confirm or reject as random rejection? It is easy to calculate: the observed probability different from expected
different from expected  on
on  . To fix the difference in hundredths, an absolute error is required, not exceeding
. To fix the difference in hundredths, an absolute error is required, not exceeding , what is
, what is  from the measured value. From here we obtain the required sample size.
from the measured value. From here we obtain the required sample size. rainy days. It will require about
rainy days. It will require about years of continuous meteorological observations, because only every fourth day it rains or snows. Alas, this is more than the time that Kamchatka is in Russia, so I don’t have a chance to find out how things are “in fact”. Especially if we take into account that during this time the climate has changed dramatically - from the Little Ice Age, nature emerged at the next optimum.
years of continuous meteorological observations, because only every fourth day it rains or snows. Alas, this is more than the time that Kamchatka is in Russia, so I don’t have a chance to find out how things are “in fact”. Especially if we take into account that during this time the climate has changed dramatically - from the Little Ice Age, nature emerged at the next optimum.
So how did Australian researchers fix the deviation of temperature in a fraction of a degree, and why does it make sense to consider this study? The fact is that they used hourly temperature data that was not “thinned out” by any random process. So for years of meteorological observations, it was possible to accumulate more than a quarter of a million counts, which makes it possible to reduce the standard deviation of the average
years of meteorological observations, it was possible to accumulate more than a quarter of a million counts, which makes it possible to reduce the standard deviation of the average  times relative to standard daily temperature deviation. This is quite enough to talk about accuracy in tenths of a degree. In addition, the authors used another beautiful method that confirms the existence of a time cycle: random mixing of the time series. Such mixing preserves statistical properties, such as flow intensity, but “erases” temporal patterns, making the process truly Poisson. Comparison of the set of synthetic series and the experimental one makes sure that the observed deviations from the Poisson process are significant. In the same way, the seismologist A. A. Gusev was shownthat earthquakes in any area form a kind of self-similar flow with clustering properties. This means that earthquakes tend to cluster in time, forming a very unpleasant flow compaction. Later it turned out that the sequence of large volcanic eruptions has the same property.
times relative to standard daily temperature deviation. This is quite enough to talk about accuracy in tenths of a degree. In addition, the authors used another beautiful method that confirms the existence of a time cycle: random mixing of the time series. Such mixing preserves statistical properties, such as flow intensity, but “erases” temporal patterns, making the process truly Poisson. Comparison of the set of synthetic series and the experimental one makes sure that the observed deviations from the Poisson process are significant. In the same way, the seismologist A. A. Gusev was shownthat earthquakes in any area form a kind of self-similar flow with clustering properties. This means that earthquakes tend to cluster in time, forming a very unpleasant flow compaction. Later it turned out that the sequence of large volcanic eruptions has the same property.
Of course, the weather, like earthquakes, cannot be described by the Poisson process - these are dynamic processes in which the current state is a function of the previous ones. Why do our weekend weather observations speak in favor of a simple stochastic model? The fact is that we map the regular process of precipitation formation to a set of seven days, or, speaking in the language of mathematics, to a system of residues modulo seven . This projection process is capable of generating chaos from well-ordered data series. Hence, for example, there is a visible randomness in the sequence of digits of the decimal notation of the majority of real numbers.
We have already spoken of rational numbers, those expressed in integer fractions. They have an internal structure, which is determined by two numbers: the numerator and the denominator. But when writing in decimal form, one can observe jumps from regularity in the representation of such numbers as , or
, or  before periodic repetition, already completely disordered sequences in such numbers as
before periodic repetition, already completely disordered sequences in such numbers as  . Irrational numbers do not have a finite or periodic record in decimal form and in this case chaos reigns in the sequence of numbers. But this does not mean that there is no order in these numbers! For example, the first irrational number encountered by mathematicians
. Irrational numbers do not have a finite or periodic record in decimal form and in this case chaos reigns in the sequence of numbers. But this does not mean that there is no order in these numbers! For example, the first irrational number encountered by mathematicians in decimal notation it generates a chaotic set of numbers. However, on the other hand, this number can be represented as an infinite continued fraction:
in decimal notation it generates a chaotic set of numbers. However, on the other hand, this number can be represented as an infinite continued fraction:
Continued fractions with repeating coefficients are written briefly, like periodic decimal fractions, for example:![$ \ sqrt {2} = [1, \ bar {2}] $](https://habrastorage.org/getpro/habr/formulas/1cc/2a9/46a/1cc2a946a36da254a3ea48722766a2dd.svg) ,
, ![$ \ sqrt {3} = [1, \ overline {1,2}] $](https://habrastorage.org/getpro/habr/formulas/fd8/bbd/268/fd8bbd26870af7fa22d050c8eec3d162.svg) . The famous golden section in this sense is the simplest arranged irrational number:
. The famous golden section in this sense is the simplest arranged irrational number:![$ \ varphi = [1, \ bar {1}] $](https://habrastorage.org/getpro/habr/formulas/85e/85e/c93/85e85ec93313767dd395cbd64f29ef59.svg) . All rational numbers are represented as finite continued fractions, some irrational ones - as infinite, but periodic, they are called algebraic , the same ones that do not have a finite notation even in this form - transcendental . The most famous of the transcendental is the number
. All rational numbers are represented as finite continued fractions, some irrational ones - as infinite, but periodic, they are called algebraic , the same ones that do not have a finite notation even in this form - transcendental . The most famous of the transcendental is the number , it creates chaos both in decimal notation and in the form of a continued fraction:
, it creates chaos both in decimal notation and in the form of a continued fraction: ![$ \ pi \ approx [3, 7,15,1,292,1,1,1,1,1,1,3,1,14,2,1, ...] $](https://habrastorage.org/getpro/habr/formulas/882/c53/2e9/882c532e9f2854d3a0292f7d027a1835.svg) . But the Euler number
. But the Euler number while remaining transcendental, in the form of a continued fraction, it exhibits an internal structure hidden in the decimal notation:
while remaining transcendental, in the form of a continued fraction, it exhibits an internal structure hidden in the decimal notation: ![$ e \ approx [2,1,2,1,1,4,1,1,6,1,1,8,1,1,10, ...] $](https://habrastorage.org/getpro/habr/formulas/35b/3ed/66e/35b3ed66e0f74a28cf36165bc2a84935.svg) .
.
Probably not one mathematician, starting with Pythagoras, suspected the world of cunning, discovering what is necessary, such a fundamental numberhas such an elusively complex chaotic structure. Of course, it can be represented in the form of sums of quite elegant number series, but these series do not directly speak of the nature of this number and they are not universal. I believe that the mathematicians of the future will open up some new representation of numbers, as universal as continued fractions, which will reveal the strict order hidden by nature in the number.
The results of this chapter are, for the most part, negative. And as an author who wants to surprise the reader with hidden patterns and unexpected discoveries, I wondered whether to include it in the book. But our conversation about the weather went into a very important topic - about the value and meaningfulness of the natural science approach.
One wise girl, Sonya Shatalova, looking at the world through the lens of autism, at the age of ten gave a very concise and precise definition: “Science is a system of knowledge based on doubt”. The real world is unsteady and tries to hide behind the complexity, apparent coincidence and unreliability of measurements. Doubt in the natural sciences is inevitable. Mathematics seems to be the realm of certainty, in which, it seems, you can forget about doubt. And it is very tempting to hide behind the walls of this kingdom; consider instead of the difficult to recognize world models that can be thoroughly investigated; read and calculate, the benefit of the formula ready to digest anything. But nevertheless, mathematics is a science and doubt in it is a deep inner honesty, which does not give rest until the mathematical construction is cleared of additional assumptions and unnecessary hypotheses. In the realm of mathematics, they speak a complex but well-formed language suitable for reasoning about the real world. It’s very important to get a little familiar with this language,
Published chapters:
• Introduction to Merphology
• Accidents are random?
• The dizzying flight of a butter sandwich
• Statistics, as a scientific way to not know anything
• The law of watermelon rind and normality of abnormality
• The law of zebra and foreign line
• Director's curse and damned printers
• Thermodynamics of class inequality
• Accidents are random?
• The dizzying flight of a butter sandwich
• Statistics, as a scientific way to not know anything
• The law of watermelon rind and normality of abnormality
• The law of zebra and foreign line
• Director's curse and damned printers
• Thermodynamics of class inequality
This chapter deals with statistics, weather, and even philosophy. Don't be scared, just a little bit. No more than what can be used for tabletalk in a decent society.
Figures are deceptive, especially when I do them myself; on this occasion, the statement attributed to Disraeli is true: "There are three types of lies: lies, blatant lies, and statistics."
Mark Twain
How often in the summer we plan on our weekends a trip to nature, a walk in the park or a picnic, and then the rain breaks our plans, sharpening us in the house! And it would be okay if this happened once or twice in a season, sometimes it seems that the bad weather is following the weekends, getting on Saturday or Sunday time after time!
A relatively recently published article by Australian researchers: "Weekly cycles of peak temperature and intensity of urban heat islands." She was picked up by the news publications and reprinted the results with the title: “You don’t think! Scientists have found out: the weather is on the weekend, really worse than on weekdays ". The paper cites statistics of temperature and precipitation over many years in several cities in Australia, indeed, revealing a decrease in temperature at certain times on Saturdays and Sundays. After that, an explanation is given that relates the local weather to the level of air pollution due to the increasing traffic flow. Shortly before, a similar study was conducted in Germany and led to about the same conclusions.
Agree that a fraction of a degree is a very subtle effect. While complaining about the bad weather on the long-awaited Saturday, we are discussing whether it was a sunny or rainy day, this fact is easier to register, and later to recall, even without possessing accurate instruments. We will conduct our own little research on this topic and get a wonderful result: we can confidently say that we do not know whether day and week are connected in Kamchatka. Research with a negative result usually does not fall on the pages of magazines and news feeds, but it’s important for you and I to understand on what basis I, in general, can confidently say something about random processes. And in this regard, a negative result becomes no worse than a positive one.
Word in defense of statistics
Statistics are accused of the mass of sins: both of lies and possibilities of manipulation and, finally, of incomprehensibility. But I really want to rehabilitate this area of knowledge, to show how difficult the task is for which it is intended and how difficult it is to understand the answer given by statistics.
Probability theory operates with accurate knowledge of random variables in the form of distributions or exhaustive combinatorial calculations. I emphasize once again that it is possible to have accurate knowledge of a random variable. But what if this exact knowledge is not available to us, and the only thing we have is observation? The developer of a new drug has some limited number of tests, the creator of the traffic control system has only a series of measurements on a real road, the sociologist has the results of surveys, and he can be sure that answering some questions, the respondents just lied.
It is clear that one observation does not give anything. Two - a little more than nothing, three, four ... one hundred ... how many observations are needed to gain any knowledge of a random quantity, which one could be sure of with mathematical precision? And what is this knowledge? Most likely, it will be presented in the form of a table or a histogram, making it possible to estimate some parameters of a random variable, they are called statisticians (for example, domain, average or variance, asymmetry, etc.). Perhaps, looking at the histogram, it will be possible to guess the exact form of the distribution. But attention! - all the results of the observations themselves will be random variables! While we do not have accurate knowledge of the distribution, all the results of observations give us only a probabilistic description of a random process!
What makes mathematical statistics an exact science? Her methods allow us to conclude our ignorance in a clearly limited framework and give a computable measure of confidence that within these frameworks our knowledge is consistent with the facts. It is a language in which one can reason about unknown random variables so that the reasoning makes sense. Such an approach is very useful in philosophy, psychology or sociology, where it is very easy to embark on lengthy arguments and discussions without any hope of obtaining positive knowledge and, moreover, on evidence. Literate statistical processing of data is devoted to the mass of literature, because it is an absolutely necessary tool for physicians, sociologists, economists, physicists, psychologists ... in a word, for all scientifically researching the so-called "real world"
Now take another look at the epigraph to this chapter and realize that statistics, which is so scornfully called the third degree of lies, is the only thing that natural sciences have. Is not the main law of the meanness of the universe! All the laws of nature known to us, from physical to economic, are built on mathematical models and their properties, but they are verified by statistical methods in the course of measurements and observations. In everyday life, our mind makes generalizations and notices patterns, selects and recognizes repetitive images, this is probably the best that the human brain can do. This is exactly what artificial intelligence is taught today. But the mind saves its strength and is inclined to draw conclusions on individual observations, without much worrying about the accuracy or validity of these conclusions.“Everyone makes general conclusions from one example. At least that's what I do . ” And while we are talking about art, the character of pets or a discussion of politics, you can not worry about it. However, during the construction of the aircraft, the organization of the airport's dispatch service or the testing of a new drug, it is no longer possible to refer to the fact that “I think so,” “intuition tells” and “anything can happen in life”. Here you have to limit your mind within the framework of rigorous mathematical methods.
Our book is not a textbook, and we will not study in detail the statistical methods and confine ourselves to only one thing - the technique of testing hypotheses. But I would like to show the course of reasoning and the form of the results characteristic of this area of knowledge. And, perhaps, to some of the readers, the future student, not only it becomes clear why he is being tortured with mathematical statistics, all these QQ-diagrams, t-and F-distributions, but another important question comes to mind: how is it possible to know sure about a random occurrence? And what exactly do we learn using statistics?
Three pillars of statistics
The main pillars of mathematical statistics are probability theory, the law of large numbers, and the central limit theorem .
The law of large numbers, in a free interpretation, says that a large number of observations of a random variable almost certainly reflects its distribution , so the observed statistics: mean, variance and other characteristics tend to exact values corresponding to a random variable. In other words, the histogram of the observed values with an infinite number of data, almost certainly tends to the distribution, which we can consider to be true. It is this law that binds the “domestic” frequency interpretation of probability and the theoretical one, as measures on a probability space.
The central limit theorem, again, in a free interpretation, says that one of the most likely forms of distribution of a random variable is the normal (Gaussian) distribution. The exact formulation sounds different: the average value of a large number of identically distributed real random variables, regardless of their distribution, is described by a normal distribution.This theorem is usually proved by applying functional analysis methods, but we will see later that it can be understood and even expanded by introducing the concept of entropy, as a measure of the probability of the system state: the normal distribution has the greatest entropy with the least number of restrictions. In this sense, it is optimal when describing an unknown random variable, or a random variable, which is a combination of many other variables, the distribution of which is also unknown.
These two laws form the basis of quantitative assessments of the reliability of our knowledge based on observations. Here we are talking about a statistical confirmation or refutation of the assumption that can be made from some general basis and a mathematical model. This may seem strange, but in itself, statistics do not produce new knowledge. A set of facts turns into knowledge only after building links between the facts that form a certain structure. It is these structures and relationships that allow making predictions and making general assumptions based on something that goes beyond statistics. Such assumptions are called hypotheses . It's time to recall one of the laws of merphology, Percig's postulate :
The number of reasonable hypotheses explaining any given phenomenon is infinite.
The task of mathematical statistics to limit this infinite number, or rather to reduce them to one, and not necessarily true. To move to a more complex (and often more desirable) hypothesis, it is necessary, using observational data, to refute a simpler and more general hypothesis, or to support it and abandon the further development of the theory. The hypothesis often tested in this way is called null , and there is a deep meaning in it.
What can play the role of the null hypothesis? In a sense, anything, any statement, but on condition that it can be translated into a measurement language. Most often, the hypothesis is the expected value of a parameter that turns into a random variable during the measurement, or the absence of a relationship (correlation) between two random variables. Sometimes it is assumed the type of distribution, random process, some mathematical model is proposed. The classical statement of the question is as follows: do observations allow one to reject the null hypothesis or not? More precisely, with what degree of confidence can we say that observations cannot be obtained on the basis of the null hypothesis? In this case, if we could not rely on statistical data to prove that the null hypothesis is false, then it is assumed to be true.
And here you would think that researchers are forced to make one of the classic logical errors, which bears the resounding Latin name ad ignorantiam. This is the argument of the truth of a statement, based on the absence of evidence of its falsity. A classic example is the words spoken by Senator Joseph McCarthy when he was asked to present facts to support the accusation that a certain person is a communist: “I have some information on this issue, except for the general statement of the competent authorities that there is nothing in his file , to exclude his connection with the Communists . " Or even brighter: “The snowman exists, because no one has proven otherwise”. Identifying the difference between a scientific hypothesis and similar tricks is the subject of a whole field of philosophy: the methodology of scientific knowledge . One of its striking results is the criterion of falsifiability , put forward by the remarkable philosopher Karl Popper in the first half of the 20th century. This criterion is designed to separate scientific knowledge from unscientific, and, at first glance, it seems paradoxical:
The theory or hypothesis can be considered scientific only if there is, even if hypothetically, a way to refute it.
What is not the law of meanness! It turns out that any scientific theory is automatically potentially incorrect, and a theory that is true “by definition” cannot be considered scientific. Moreover, such criteria as mathematics and logic do not satisfy this criterion. However, they are referred not to the natural sciences, but to the formal ones , which do not require checking for falsifiability. And if we add another result of the same time: the principle of Gödel ’s incompleteness , which asserts that within any formal system one can formulate an assertion that can neither be proved nor disproved, then it becomes unclear why, in general, to be engaged in the whole science. However, it is important to understand that Popper’s falsifiability principle says nothing about the truththeory, but only about whether it is scientific or not. It can help determine whether a certain theory gives a language in which it makes sense to talk about the world or not.
But still, why, if we cannot reject a hypothesis on the basis of statistical data, are we entitled to accept it as true? The fact is that the statistical hypothesis is not taken from the desire of the researcher or his preferences; it must flow from any general formal laws. For example, from the Central Limit Theorem, or from the principle of maximum entropy. These laws correctly reflect the degree of our ignorance , without unnecessarily adding unnecessary assumptions or hypotheses. In a sense, this is a direct use of the famous philosophical principle known as Occam's razor :
What can be done on the basis of fewer assumptions should not be done on the basis of the larger.
Thus, when we accept the null hypothesis, based on the absence of its refutation, we formally and honestly show that as a result of the experiment, the degree of our ignorance remained at the same level . In the example with the snowman, explicitly or implicitly, but the opposite is assumed: the lack of evidence that this mysterious creature does not exist seems to be something that can increase the degree of our knowledge about it.
In general, from the point of view of the principle of falsifiability, any statement about the existence of something is unscientific, because the absence of evidence does not prove anything. At the same time, the statement about the absence of something can be easily refuted by providing a copy, indirect evidence, or by proving the existence by construction. And in this sense, statistical testing of hypotheses analyzes the statements about the absence of the desired effect and can provide, in a certain sense, an exact refutation of this statement. This is precisely what fully justifies the term “null hypothesis”: it contains the necessary minimum knowledge of the system.
How to confuse statistics and how to unravel
It is very important to emphasize that if the statistics suggest that the null hypothesis can be rejected, this does not mean that we thereby proved the truth of any alternative hypothesis. Statistics should not be confused with logic, therein lies a lot of subtle errors, especially when conditional probabilities for dependent events come into play. For example: it is very unlikely that a person can be Pope (
billion), does it follow from this that Pope John Paul II was not a man? The statement seems absurd, but, unfortunately, such an “obvious” conclusion is just as wrong: the test showed that the mobile test for the alcohol content in the blood gives no more both false positive and false negative results, therefore, in cases, he correctly identify a drunk driver. Let's test drivers and let of will be really drunk. As a result, we get false positives and a false negative result: that is, for one drunkard who has missed, nine innocently charged random drivers will fall. What is not the law of meanness! Parity will only be observed if the proportion of drunk drivers equals, or if the ratio of false positive and false negative results will be close to the real ratio of drunk drivers to sober. Moreover, the more sober the nation being surveyed, the more unfair the application of the device described by us! Here we are faced with dependent events . Remember, in the Kolmogorov definition of probability, we talked about the method of adding the probability of combining events: the probability of combining two events is equal to the sum of their probabilities minus the probability of their intersection. However, how the probability of intersection of events is calculated, these definitions do not speak. For this, a new concept is introduced: the conditional probability and the dependence of events on each other come to the fore.
The probability of intersection of events A and B is defined as the product of the probability of the event B and the probability of the event
if you know what happened : 
and independent if , or , or . Thus, we complete the formal definition of probability, begun in the first chapter.
Intersection is a commutative operation, i.e.
. This immediately follows the Bayes theorem:
In our example with drivers and alcohol test, we have events:
- the driver is drunk, - The test gave a positive result. Probabilities: - the likelihood of a stopped driver is drunk; - the probability that the test will give a positive result if it is known that the driver is drunk (excluded false negative results), - the probability that the test is drunk, if the test gave a positive result (excluded false positive results). Calculate - probability of getting a positive test result on the road:
These examples are thoroughly analyzed by medical test students or legal practitioners. But, I am afraid that journalists or politicians are not taught either mathematical statistics or probability theory, but they willingly appeal to statistical data, freely interpret them and carry the resulting "knowledge" to the masses. Therefore, I urge my reader: I figured out the math myself, help me figure out another! I see no other antidote to ignorance.
We measure our gullibility
We will consider and apply in practice only one of a variety of statistical methods: testing statistical hypotheses. For those who have already connected their lives with the natural or social sciences in these examples there will not be something shockingly new.
Suppose we repeatedly measure a random variable with an average value
and standard deviation . According to the Central Limit Theorem, the observed average value will be distributed normally. It follows from the law of large numbers that its average will tend to, and from the properties of the normal distribution it follows that after measurement the observed variance of the mean will decrease as . The standard deviation can be considered as an absolute error of measurement of the mean, the relative error will be equal to. These are very general conclusions that do not depend on sufficiently largeon the specific distribution form of the random variable under study. Two useful rules follow (not laws): 1. Minimum number of tests
should be dictated by the desired relative error . However, if
. Withclose to zero, the relative error is better to replace the absolute. 2. Let the null hypothesis be the assumption that the observed average value is
. Then, if the observed average does not exceed the limits, the probability that the null hypothesis is true will be at least . If replaced in these rules
on then the degree of confidence will rise to this is a very strong rule which in physical sciences separates the assumptions from the experimentally established fact. It will be useful for us to consider the application of these rules to the Bernoulli distribution describing a random variable that takes exactly two values, conventionally called “success” and “failure”, with a given probability of success.
. In this case and so that for the required number of experiments and a confidence interval we get 
Rule
for the Bernoulli distribution can be used to determine the confidence interval when constructing histograms. Essentially, each histogram bar represents a random variable with two values: “hit” - “missed”, where the probability of hitting corresponds to the simulated probability function. As a demonstration, we will generate a set of samples for three distributions: uniform, geometric, and normal, after which we compare the estimates of the spread of the observed data with the observed spread. And here we again see echoes of the central limit theorem, manifested in the fact that the distribution of data around the average values in histograms is close to normal. However, near zero, the scatter becomes asymmetric and approaches another very likely distribution, the exponential. This example shows well what I meant and the observed spread for three random variables. It is important to understand that the rules
and even do not save us from mistakes. They do not guarantee the truth of any statement, they are not evidence. Statistics limit the degree of distrust of the hypothesis, and nothing more. The mathematician and author of the excellent course in probability theory Gian-Carlo Roth, at his lectures at MIT, gave this example. Imagine a scientific journal, the editorial staff of which made a volitional decision: to accept for publication only articles with positive results that satisfy the rule.
or stricter. At the same time, the editorial column states that readers can be confident that with probabilitythe reader will not find the wrong result on the pages of this magazine! Alas, this statement is easily refuted by the same reasoning, which led us to a flagrant injustice when testing drivers for alcohol. Let be researchers subjected to experience hypotheses, of which only some part is true, say, . Based on the meaning of hypothesis testing, it can be expected that erroneous hypotheses will not be mistakenly rejected, and will be logged along with correct results. Total ofresults a good third would be wrong! This example perfectly demonstrates our domestic law of meanness, which has not yet entered into the anthology of merphology, Chernomyrdin's law :
We wanted the best, but it turned out, as always.
It is easy to get a general estimate of the proportion of incorrect results that will be included in the journal issues, assuming that the proportion of correct hypotheses is equal
and the probability of making an erroneous hypothesis is :
may be risky, while the criterion can already be considered quite strong. Of course, we don't know that.
, and we will never know, but it is obviously less than one, which means, in any case, the statement from the editorial column cannot be taken seriously. You can limit yourself to a rigid framework of the criterion., but it requires a very large number of tests. This means that it is necessary to increase the proportion of correct hypotheses in the set of possible assumptions. The standard approaches of the scientific method of knowledge are aimed at this - the logical consistency of hypotheses, their consistency with facts and theories that have proven their applicability, reliance on mathematical models and critical thinking.And again about the weather
At the beginning of the chapter we talked about the fact that weekends and bad weather coincide more often than we would like. Let's try to complete this study. Every rainy day can be viewed as the observation of a random variable — a day of the week that obeys the Bernoulli distribution with probability
. We take as the null hypothesis the assumption that all days of the week are the same in terms of weather and it can rain in any of them equally likely. We have two weekends, in total, we get the expected probability of coincidence of a bad weather day and a holiday equal to, this value will be a parameter of the Bernoulli distribution. How often does it rain? At different times of the year, of course, in different ways, but in Petropavlovsk-Kamchatsky, on average, there are ninety rainy or snowy days per year. So the flow of precipitation days has an intensity of about. Let's calculate how many rainy weekends we have to register in order to be sure that there is some pattern. The results are shown in the table.| Observation period | summer | year |  years old years old |
|---|---|---|---|
| Expected number of observations |  |  |  |
| Expected number of positive outcomes |  |  | |
| Significant deviation |  |  | |
| Significant proportion of bad weather in the total number of days off |  |  |  |
What do these numbers say? If it seems to you that that year in a row there was no summer, that the evil fate is haunting your weekend by sending rain on them, you can check and confirm it. However, during the summer, evil rock can only be caught if more than two-fifths of the weekend turns out to be rainy. The null hypothesis suggests that only a quarter of the weekend should coincide with inclement weather. For five years of observations, one can hope to notice subtle deviations beyond the limits of
and, if necessary, proceed to their explanation. I used the school weather diary, which was conducted from 2014 to 2018, and found out what happened during these five years.
rainy days of them come on the weekend. This is indeed more than the expected number ondays, but significant deviations begin withdays, so this, as we said in childhood: "does not count." This is how the data series and the histogram look, showing the distribution of the weather by days of the week. Horizontal lines on the histogram indicate the interval in which a random deviation from a uniform distribution can be observed with the same data volume. The initial data series and the distribution of bad days by days of the week, obtained from five years of observations.
It can be seen that since Friday there is indeed an increase in the number of days with bad weather. But to find the reason for this growth, the prerequisites are not enough: the same result can be obtained simply by going through random numbers. Conclusion: for five years of weather observation, I have accumulated almost two thousand records, but I did not learn anything new about the distribution of weather by days of the week.
When looking at the diary entries, it is clearly striking that the bad weather does not come one by one, but two or three days or even weekly cyclones. Does it somehow affect the result? You can try to take this observation into account, and assume that it rains an average of two days (in fact,
days), then the probability to cut off the weekend increases to . With such a probability, the expected number of matches for five years should bethat is from before time. Observed valuedoes not fall within this range, which means that the hypothesis of the effect of double weather days can be safely rejected. Did we learn something new? Yes, we learned: it would seem that the obvious feature of the process does not entail any effect. This is worth considering, and we will do it a little later. But the main conclusion: there are no reasons to consider any more subtle effects, since observations and, most importantly, their number, consistently speak in favor of the simplest explanation. But our discontent is caused not by five-year or even annual statistics, human memory is not so long. It's a shame when it rains on the weekend three or four times in a row! How often can this be observed? Especially if you remember that the nasty weather does not come alone. The problem can be formulated as follows: “What is the probability that
Weekend in a row will be rainy? ”It is reasonable to assume that bad days form a Poisson stream with intensity . This means that, on average, a quarter of the days of any period will be bad weather. Observing only the weekends, we should not change the intensity of the flow and from all the weekends the bad weather should make up, on average, also a quarter. So, we put forward the null hypothesis: the Poisson flow of bad weather, with a known parameter, and therefore, the intervals between Poisson events are described by an exponential distribution. We are interested in discrete intervals: of the day, etc., so we can use the discrete analog of the exponential distribution — the geometric distribution with the parameter . The figure shows that we have succeeded and it is clear that the assumption that we are observing the Poisson process has no reason to reject.The observed distribution of the lengths of the failed output chains is theoretical. The thin line shows the tolerances for the number of observations that we have.
One may ask, such a question: how many years it is necessary to conduct observations, in order that we notice the difference in
days could you confidently confirm or reject as random rejection? It is easy to calculate: the observed probability different from expected on . To fix the difference in hundredths, an absolute error is required, not exceeding, what is from the measured value. From here we obtain the required sample size.rainy days. It will require aboutyears of continuous meteorological observations, because only every fourth day it rains or snows. Alas, this is more than the time that Kamchatka is in Russia, so I don’t have a chance to find out how things are “in fact”. Especially if we take into account that during this time the climate has changed dramatically - from the Little Ice Age, nature emerged at the next optimum. So how did Australian researchers fix the deviation of temperature in a fraction of a degree, and why does it make sense to consider this study? The fact is that they used hourly temperature data that was not “thinned out” by any random process. So for
years of meteorological observations, it was possible to accumulate more than a quarter of a million counts, which makes it possible to reduce the standard deviation of the average times relative to standard daily temperature deviation. This is quite enough to talk about accuracy in tenths of a degree. In addition, the authors used another beautiful method that confirms the existence of a time cycle: random mixing of the time series. Such mixing preserves statistical properties, such as flow intensity, but “erases” temporal patterns, making the process truly Poisson. Comparison of the set of synthetic series and the experimental one makes sure that the observed deviations from the Poisson process are significant. In the same way, the seismologist A. A. Gusev was shownthat earthquakes in any area form a kind of self-similar flow with clustering properties. This means that earthquakes tend to cluster in time, forming a very unpleasant flow compaction. Later it turned out that the sequence of large volcanic eruptions has the same property.Another source of chance
Of course, the weather, like earthquakes, cannot be described by the Poisson process - these are dynamic processes in which the current state is a function of the previous ones. Why do our weekend weather observations speak in favor of a simple stochastic model? The fact is that we map the regular process of precipitation formation to a set of seven days, or, speaking in the language of mathematics, to a system of residues modulo seven . This projection process is capable of generating chaos from well-ordered data series. Hence, for example, there is a visible randomness in the sequence of digits of the decimal notation of the majority of real numbers.
We have already spoken of rational numbers, those expressed in integer fractions. They have an internal structure, which is determined by two numbers: the numerator and the denominator. But when writing in decimal form, one can observe jumps from regularity in the representation of such numbers as
, or before periodic repetition, already completely disordered sequences in such numbers as . Irrational numbers do not have a finite or periodic record in decimal form and in this case chaos reigns in the sequence of numbers. But this does not mean that there is no order in these numbers! For example, the first irrational number encountered by mathematiciansin decimal notation it generates a chaotic set of numbers. However, on the other hand, this number can be represented as an infinite continued fraction:

Continued fractions with repeating coefficients are written briefly, like periodic decimal fractions, for example:
, . The famous golden section in this sense is the simplest arranged irrational number:. All rational numbers are represented as finite continued fractions, some irrational ones - as infinite, but periodic, they are called algebraic , the same ones that do not have a finite notation even in this form - transcendental . The most famous of the transcendental is the number, it creates chaos both in decimal notation and in the form of a continued fraction: . But the Euler numberwhile remaining transcendental, in the form of a continued fraction, it exhibits an internal structure hidden in the decimal notation: . Probably not one mathematician, starting with Pythagoras, suspected the world of cunning, discovering what is necessary, such a fundamental number
has such an elusively complex chaotic structure. Of course, it can be represented in the form of sums of quite elegant number series, but these series do not directly speak of the nature of this number and they are not universal. I believe that the mathematicians of the future will open up some new representation of numbers, as universal as continued fractions, which will reveal the strict order hidden by nature in the number.
The results of this chapter are, for the most part, negative. And as an author who wants to surprise the reader with hidden patterns and unexpected discoveries, I wondered whether to include it in the book. But our conversation about the weather went into a very important topic - about the value and meaningfulness of the natural science approach.
One wise girl, Sonya Shatalova, looking at the world through the lens of autism, at the age of ten gave a very concise and precise definition: “Science is a system of knowledge based on doubt”. The real world is unsteady and tries to hide behind the complexity, apparent coincidence and unreliability of measurements. Doubt in the natural sciences is inevitable. Mathematics seems to be the realm of certainty, in which, it seems, you can forget about doubt. And it is very tempting to hide behind the walls of this kingdom; consider instead of the difficult to recognize world models that can be thoroughly investigated; read and calculate, the benefit of the formula ready to digest anything. But nevertheless, mathematics is a science and doubt in it is a deep inner honesty, which does not give rest until the mathematical construction is cleared of additional assumptions and unnecessary hypotheses. In the realm of mathematics, they speak a complex but well-formed language suitable for reasoning about the real world. It’s very important to get a little familiar with this language,