Million video calls per day or “Call mom!”
From the user's point of view, the call services look pretty simple: you go to the page to another user, you call, he picks up the phone, you talk to him. Outside it seems that everything is simple, but few know how to make such a service. But Alexander Tobol ( alatobol ) not only knows, but also willingly shares his experience.

Further the text version of the report on HighLoad ++ Siberia, from which you will learn:
About the speaker: Alexander Tobol leads the development of the Video and Tape platforms at ok.ru.
Video call history
The first video call device appeared in 1960, it was called a picherphone, used dedicated networks and was extremely expensive. In 2006, Skype added video calls to its application. In 2010, Flash supported the RTMFP protocol, and we at Odnoklassniki launched Flash video calls. In 2016, Chrome stopped supporting Flash, and in August 2017 we restarted calls with the new technology, which I will talk about today. Having finalized the service, for another six months we received a significant increase in successfully completed calls. Recently, we also have masks in calls.

Architecture and TK
Since we work in a social network, we do not have technical tasks, and we don’t know what TK is. Usually the whole idea fits on one page and looks something like this.
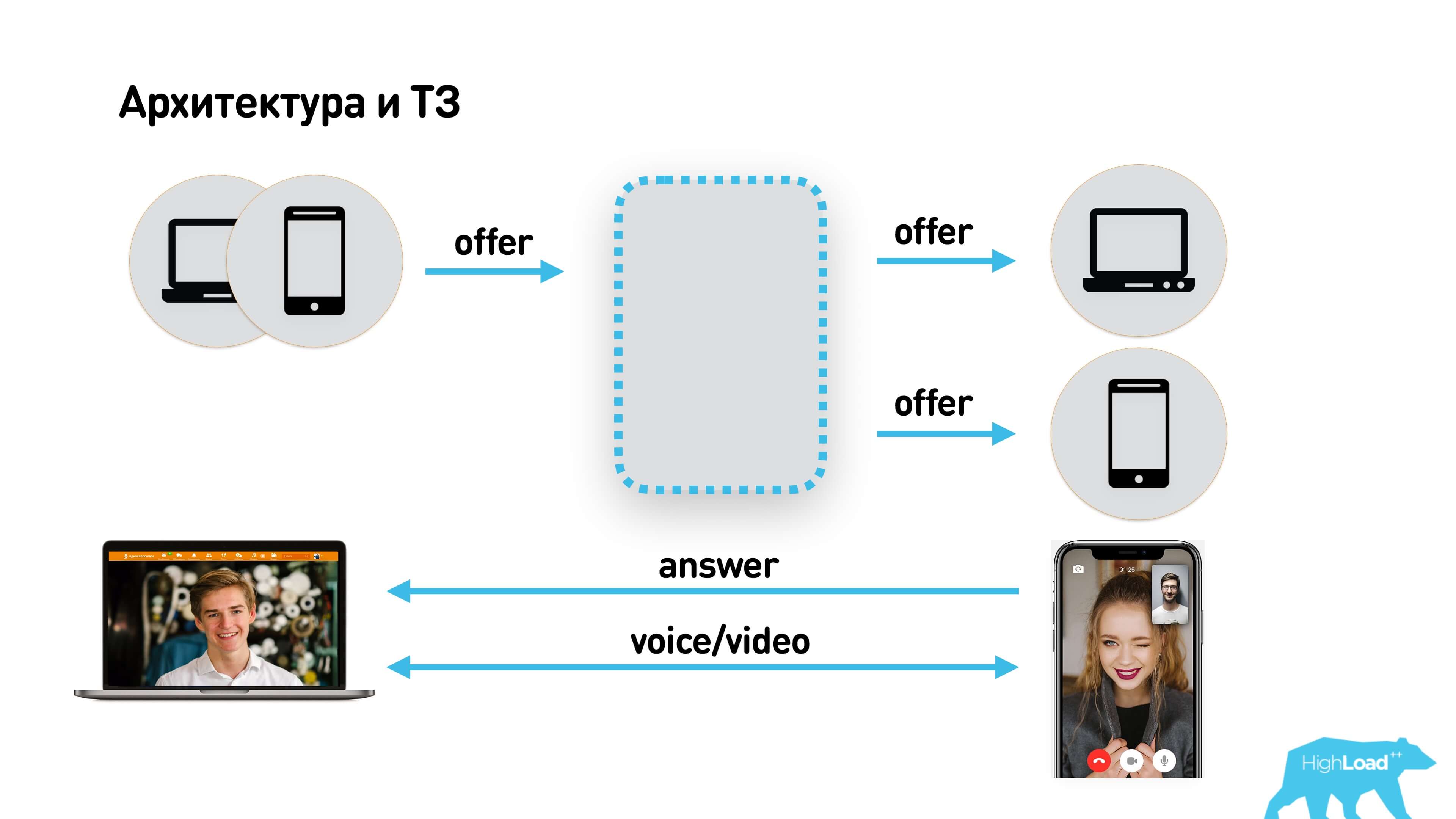
The user wants to call other users using a web or iOS / Android application. Another user may have multiple devices. The call comes to all devices, the user picks up the phone on one of them, they talk. Everything is simple.
Specifications
In order to make a quality call service, we need to understand what characteristics we want to track. We decided to start by looking for what annoys the user the most.
The user is definitely annoyed if he picks up the phone and is forced to wait until the connection is established.

The user is annoyed if the call quality is poor - something is interrupted, the video is scattered, the sound is bubbling.

But most of all the user is annoyed by the delay in calls. Latency is one of the important characteristics of calls. With latency in a conversation of the order of 5 seconds, it is absolutely impossible to conduct a dialogue.
We have determined for ourselves acceptable characteristics:

Polycom is a conferencing system installed in our offices. We have average polycom latencies of the order of 1.3 seconds. With such a delay, you do not always understand each other. If the delay increases to 2 seconds, then dialogue will not be possible.

Since we had already launched the platform, we roughly expected that we would have a million calls per day. This is a thousand calls in parallel. If all calls are launched through the server, there will be a thousand megabit calls per call. This is only 1 gigabit / sec one iron server will be enough.
Internet vs TTX
What can prevent you from achieving such cool features? The Internet!
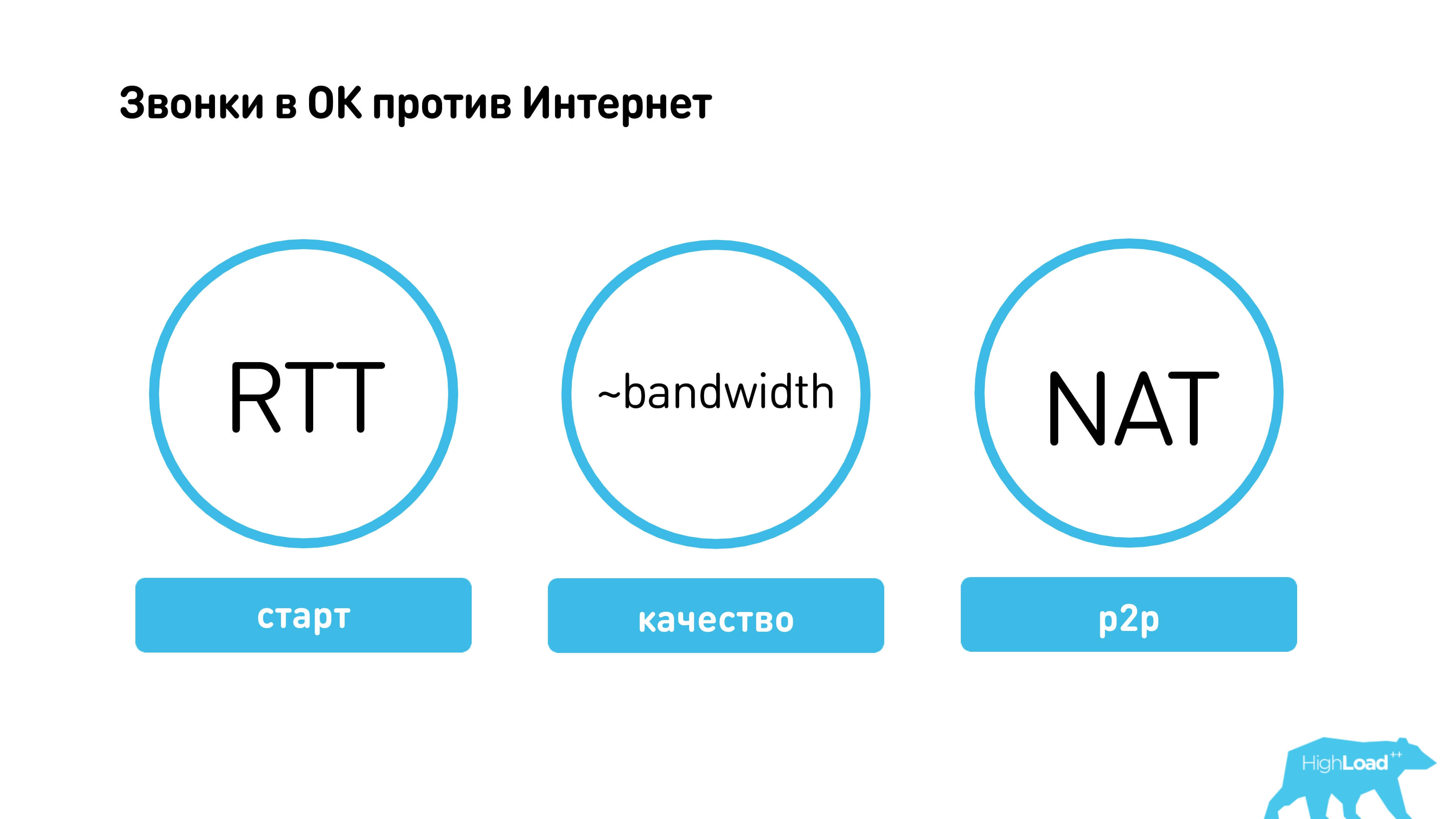
On the Internet, there are such things as round-trip time (RTT), which can not be overcome, there is a variable bandwidth, there is NAT.
Previously, we measured the transmission speed in the networks of our users.

We broke it down by the type of connection, looked at the average RTT, packet loss, speed, and decided that we would test calls on the average values of each of these networks.

There are other troubles on the Internet:

Consider the network settings listed above with a simple example.
I paged the website of Novosibirsk State University from my office and got such a strange ping.

The average jitter in this example is 30 ms, that is, the average interval between adjacent ping times is about 30 ms, and the average ping is 105 ms.
What is important in calls, why will we fight for p2p?

Obviously, if we managed to establish a p2p connection between our users who are trying to talk to each other in St. Petersburg, rather than through a server located in Novosibirsk, we will save about 100 ms round-trip and traffic to this service.
Therefore, most of the article is devoted to how to make good p2p.
History or legacy
As I said, we have had a call service since 2010, and now we have restarted it.

In 2006, when Skype started, Flash bought Amicima, which made RTMFP. Flash already had RTMP, which in principle can be used for calls, and it is often used for streaming. Flash later opened the RTMP specification. I wonder why they needed RTMFP? In 2010, we used RTMFP.
Compare the requirements for call protocols and real streaming protocols and see where this border is.

RTMP is more of a video streaming protocol. It uses TCP, it has cumulative delay. If you have a good internet connection, calls to RTMP will work.
RTMFP protocolDespite the difference in just one letter, it is the UDP protocol. It is free of buffering problems - those that are on TCP; It is deprived of head-of-line blocking - this is when you lost one packet, and TCP does not return the following packets until it is time to send the lost one again. RTMFP was able to handle NAT and was experiencing a change in the IP address of clients. Therefore, we launched the web on RTMFP in 2010.

Then only in 2011 did the initial draft WebRTC appear, which was not yet fully operational. In 2012, we started supporting calls on iOS / Android, then something else happened, and in 2016 Chrome stopped supporting Flash. We had to do something.

We looked at all the VoIP protocols: as always, in order to do something, we start by looking at competitors.
Competitors or where to start
We chose the most popular competitors: Skype, WhatsApp, Google Duo (similar to Hangouts) and ICQ.
To begin with, we measured the delay.

It is easy to do. Above is a photograph in which:
I won’t reveal all the cards yet, but we made sure that these devices could not establish p2p connections. Of course, the measurements were carried out in different networks, and this is just an example.

Skype still interrupts a little. It turned out that with Skype, in case it fails to connect p2p, the delay is 1.1 s.
Our test environment was complicated. We tested in different conditions (EDGE, 3G, LTE, WiFi), took into account that the channels are asymmetric, and I give the average values of all measurements.

In order to estimate the battery consumption, the load on the processor and everything else, we decided that you can simply measure the temperature of the phone with a pyrometer and assume that this is some average load on the phone’s GPU on the processor, on the battery. In principle, it’s very unpleasant to bring a hot phone to your ear, and even hold it in your hands. It seems to the user that now the application will use up its entire battery.

The result is:
Great, we got some metrics!

We tested the quality of video and voice on different networks, with different drops and everything else. As a result, we came to the conclusion that the highest quality video is on Google Duo, and the voice is on Skype , but this is in “bad” networks when there is already distortion. In general, everyone works approximately mediocre. WhatsApp has the most blurred picture.
Let's see what it is all implemented on.

Skype has its own proprietary protocol, and everyone else uses either a modification of WebRTC, or generally directly WebRTC. Hangouts, Google Duo, WhatsApp, Facebook Messenger can work with the web, and they all have WebRTC under the hood. They are all so different, with different characteristics, and they all have one WebRTC! So, you need to be able to cook it correctly. Plus there’s Telegram, for which some parts of WebRTC are responsible for the audio part, there is ICQ, which forked WebRTC for a long time and went on developing its own way.
WebRTC Architecture
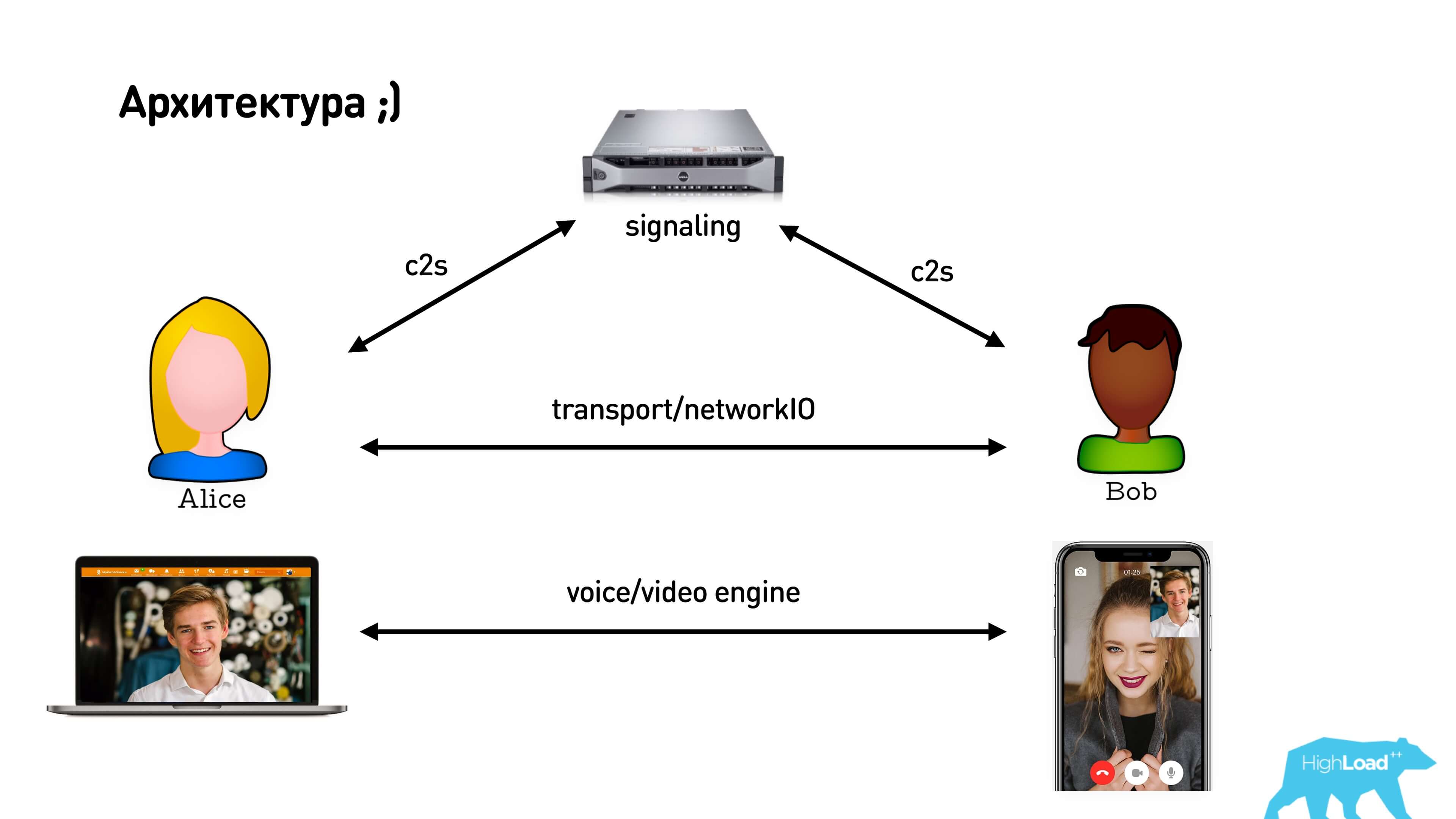
WebRTC implies the presence of a signaling server, an intermediary between clients, which is used to exchange messages during the establishment of a p2p connection between them. After establishing a direct connection, clients begin to exchange media data with each other.
WebRTC Demo
Let's start with a simple demo. There are 5 simple steps to establish a WebRTC connection.
It says the following:
Let’s figure out what is happening there and what we need to implement ourselves.
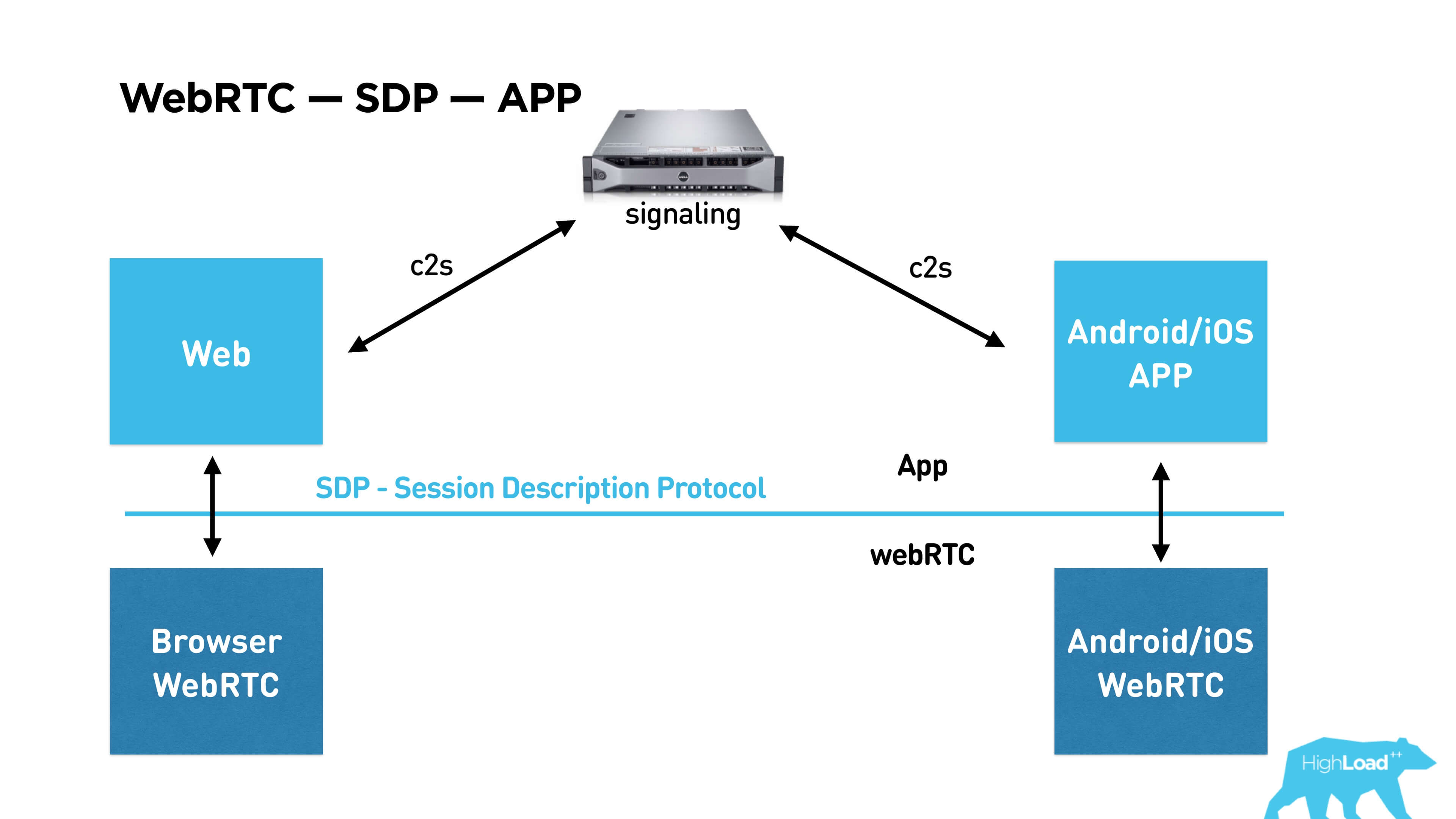
We look at the picture from the bottom up. There is a WebRTC library that is already built into the browser, supported by Chrome, Firefox, etc. You can build it under Android / iOS and communicate with it through the API and SDP (Session Description Protocol), which describes the session itself. Below I will tell you what is included in it. To use this library in your application, you must establish a connection between subscribers through signaling. Signaling is also your service that you have to write yourself, WebRTC does not provide it.
Further in the article we will discuss the network in order, then video / audio, and at the end we will write our signaling.
WebRTC network or p2p (actually c2s2c)
Setting up a p2p connection seems to be pretty simple.
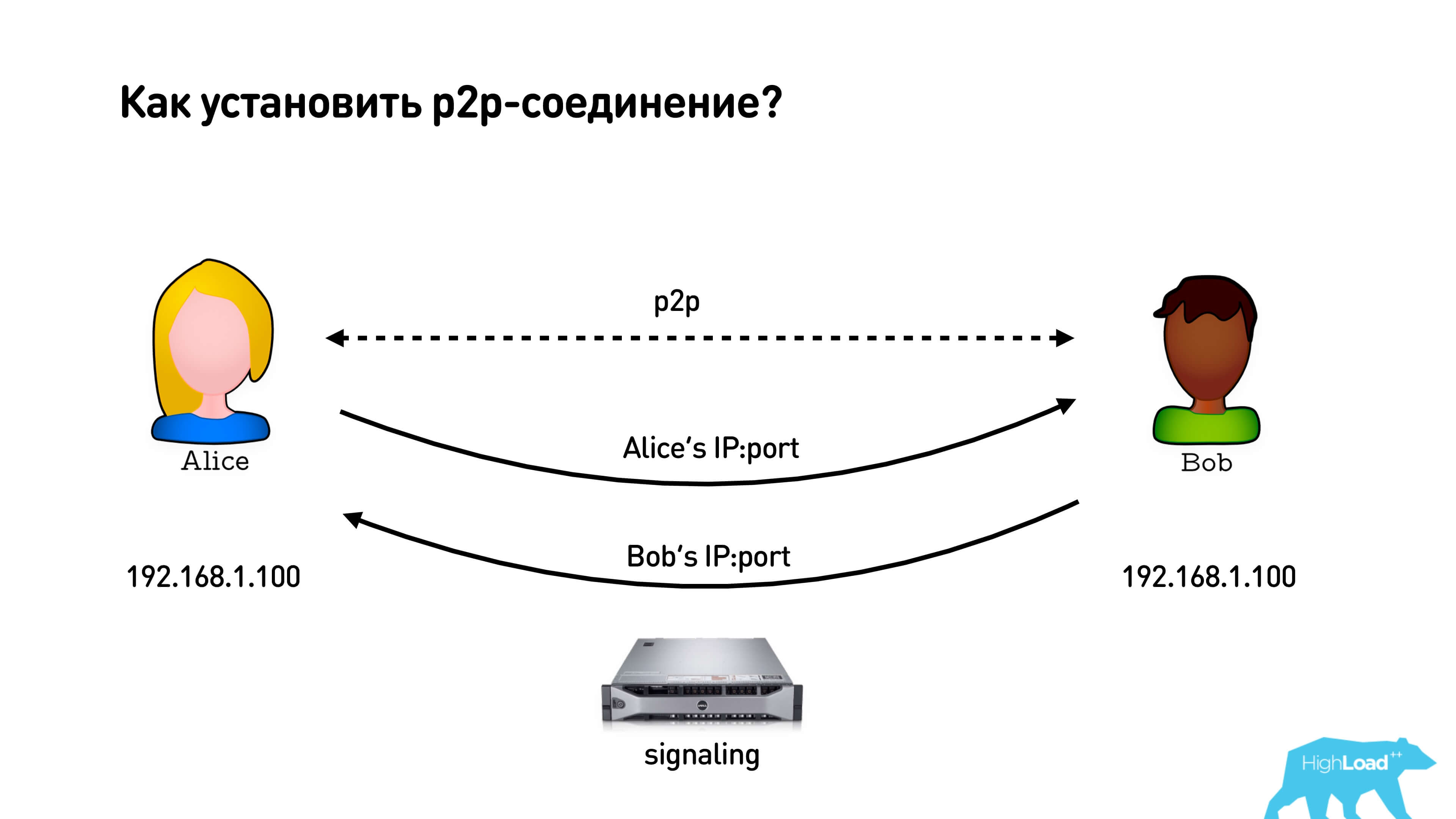
We have Alice and Bob who want to establish a p2p connection. They take their IP addresses, they have a signaling server to which they are both connected, and through which they can exchange these addresses. They exchange addresses, and oh! They have the same addresses, something went wrong!
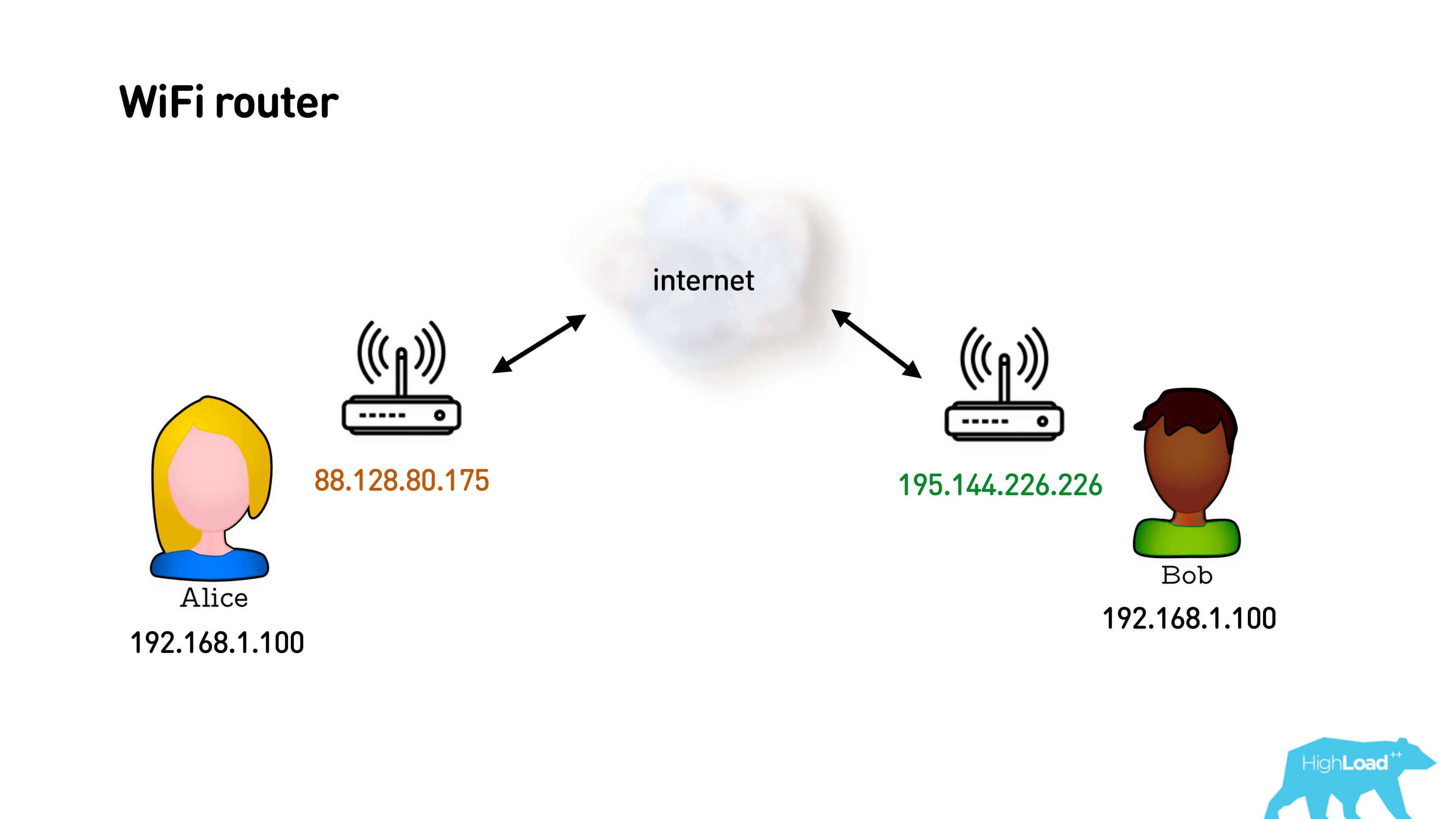
In fact, both users are most likely sitting behind Wi-Fi routers and these are their local gray IP addresses. The router provides them with a feature such as Network Address Translation (NAT). How does she work?

You have a gray subnet and an external IP address. You send a packet to the Internet from your gray address, NAT replaces your gray address with white and remembers the mapping: which port it sent from, to which user and which port it matches. When the return packet arrives, it resolves by this mapping and sends it to the sender. Everything is simple.
Below is an illustration of how it looks at my place.
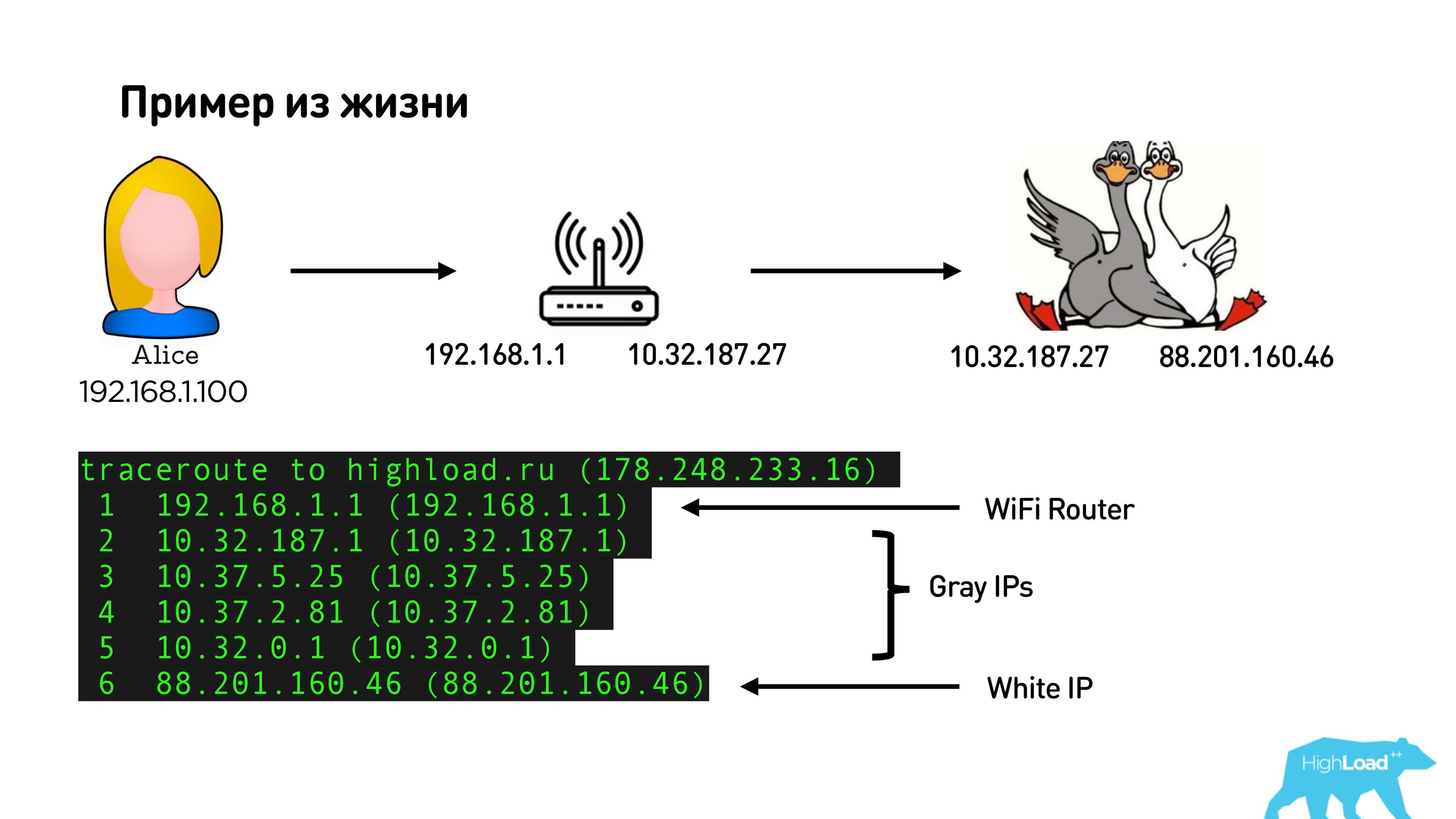
This is my internal IP address and the address of the router (by the way, also gray). If you trace and see the route, we will see my Wi-Fi router: a packet of gray provider addresses and an external white IP. Thus, in fact, I will have two NATs: one on which I am on Wi-Fi, and the other another one from the provider, unless, of course, I bought myself a dedicated external IP address.
NAT is so popular because:
Therefore, only 3% of users sit with an external IP, while all the rest go through NAT.
NAT allows you to safely go to any white addresses. But if you did not go anywhere, then no one can come to you.
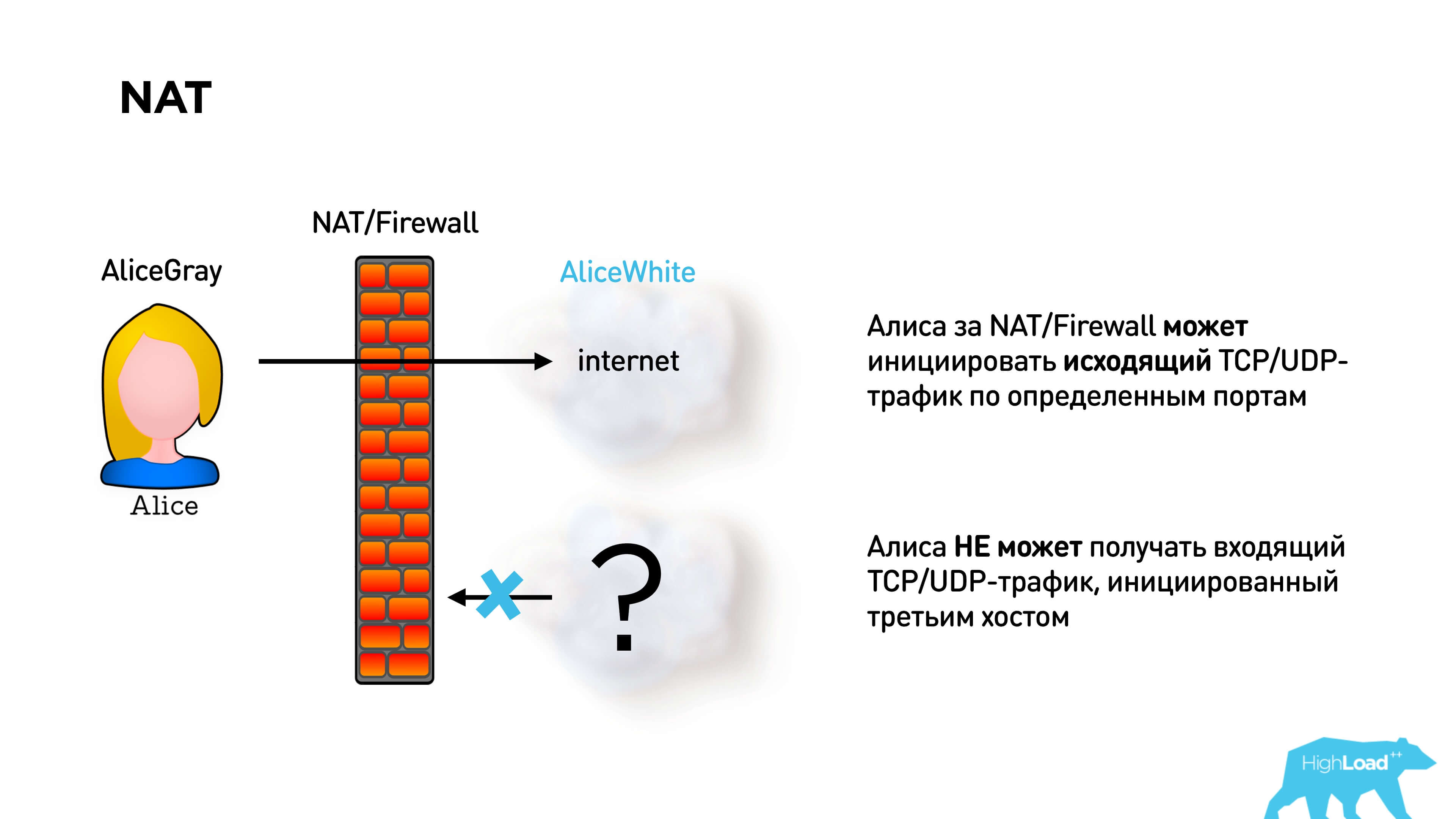
To establish a p2p connection is a problem. In fact, Alice and Bob cannot send packets to each other if they are both behind NAT.
WebRTC has a STUN protocol to solve this problem . It is proposed to deploy a STUN server. Then Alice connects to the STUN server, gets her IP address, sends it to Bob via signaling. Bob also gets his IP address and sends it to Alice. They send packets towards each other and thus break through NAT.

Question: Alice has a specific port open, NAT / Firewall has already been broken through to this port, and Bob is open. They know each other's addresses. Alice tries to send the packet to Bob; he sends the packet to Alice. Do you think they can talk or not?
In fact, you are right in any case, the result depends on the type of NAT pair that users have.

Network address translation
There are 4 types of NAT:
In the basic version, Alice sends a packet to the STUN server, she opens some port. Bob somehow finds out about her port and sends a return packet. If this is Full cone NAT - the easiest one that just maps the external port to the internal port, then Bob will be able to immediately send Alice a packet, establish a connection, and they will talk.
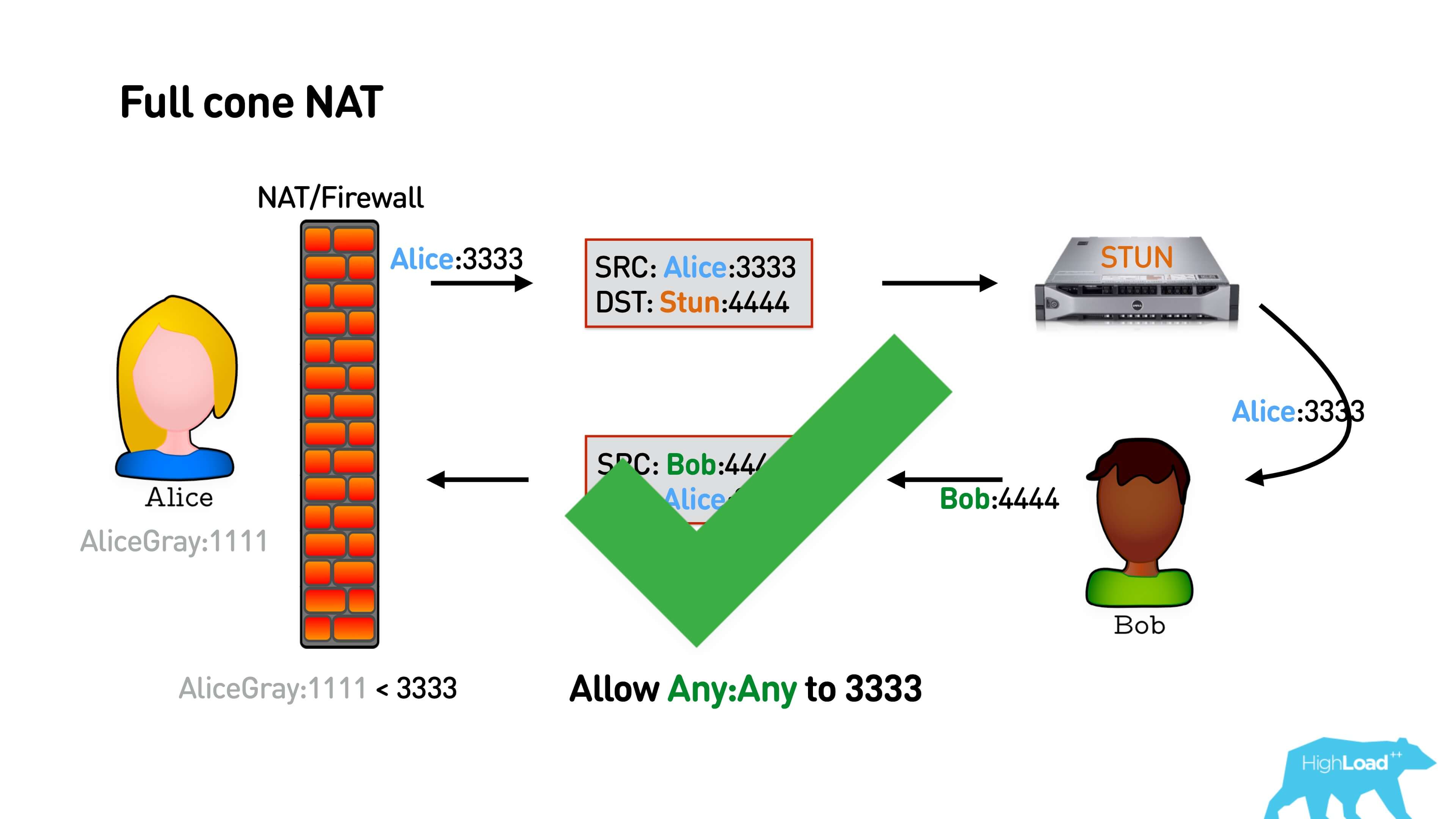
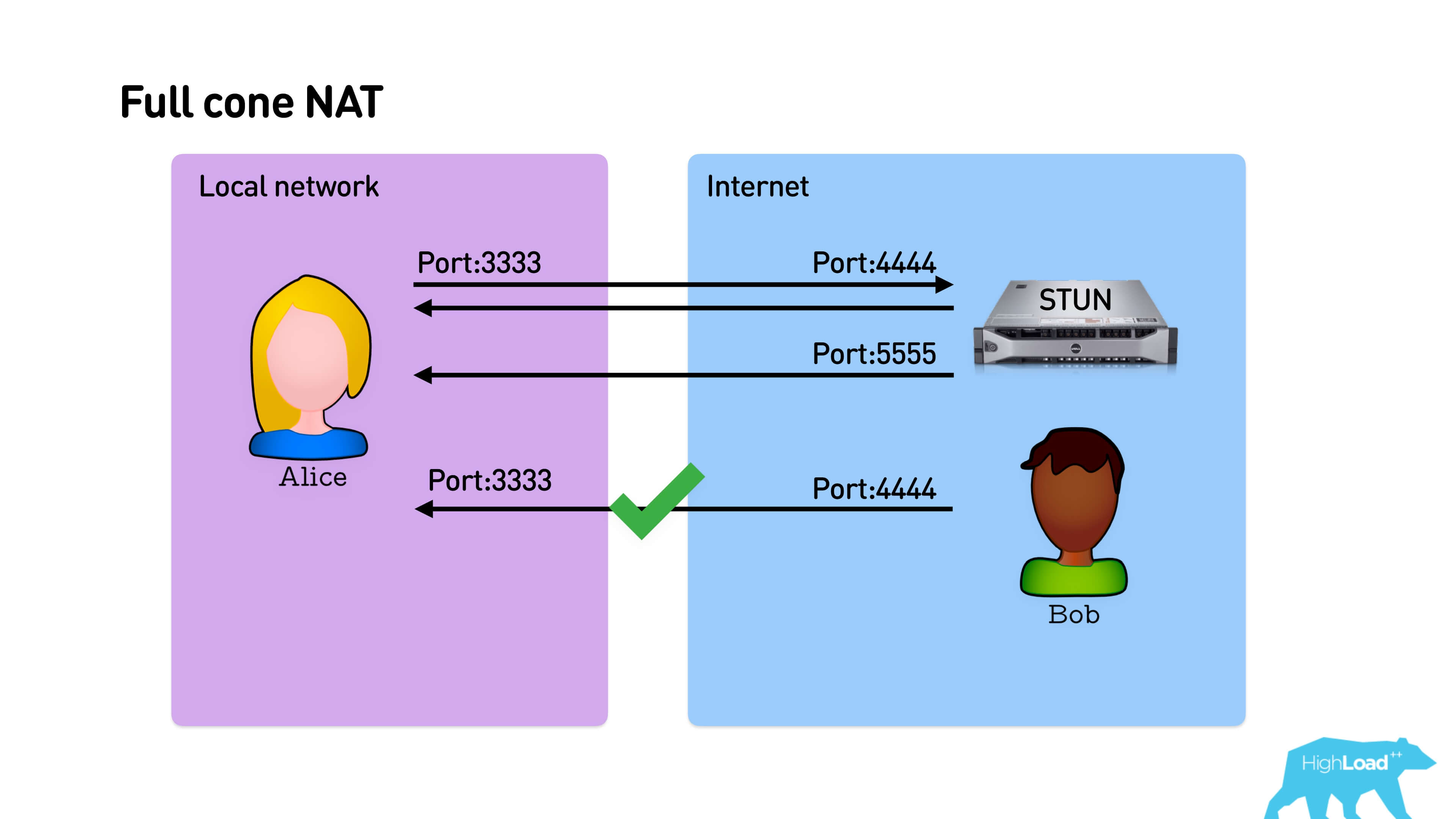
Below is the interaction scheme: Alice from some port sends a packet to the STUN port, STUN answers her with her external address. STUN can respond from any address, if it's Full cone NAT, it will still punch through NAT, and Bob can respond to the same address.
In case of Restricted cone NATeverything is a little more complicated. It remembers not just the port from which you need to map to the internal address, but also the external address that you went to. That is, if you have established a connection only to the IP STUN server, then no one else on the network will be able to answer you, and then Bob’s packet will not reach.
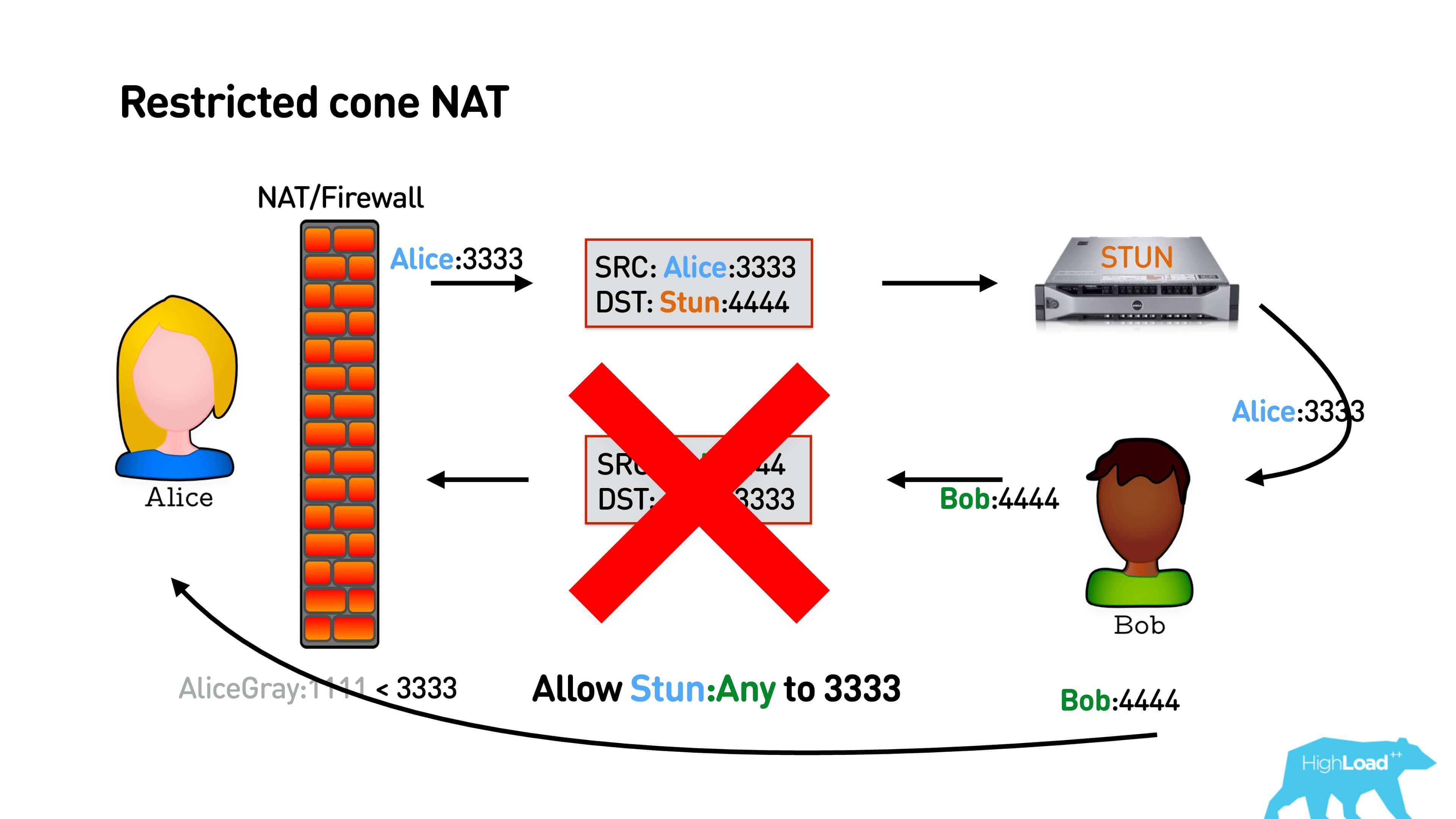
How is this problem solved? In a simple scheme (see illustration below) like this: Alice sends a packet to STUN, he answers her with her IP. STUN can respond to it from any port as long as it is Restricted cone NAT. Bob cannot answer Alice because he has a different address. Alice responds with a packet, knowing Bob's IP address. She opens NAT to Bob, Bob answers her. Hooray, they talked.

A bit more complicated option - Port restricted cone NAT. All the same, only STUN should respond exactly from the port to which it was accessed. Everything will work too.
The most harmful thing is Symmetric NAT .
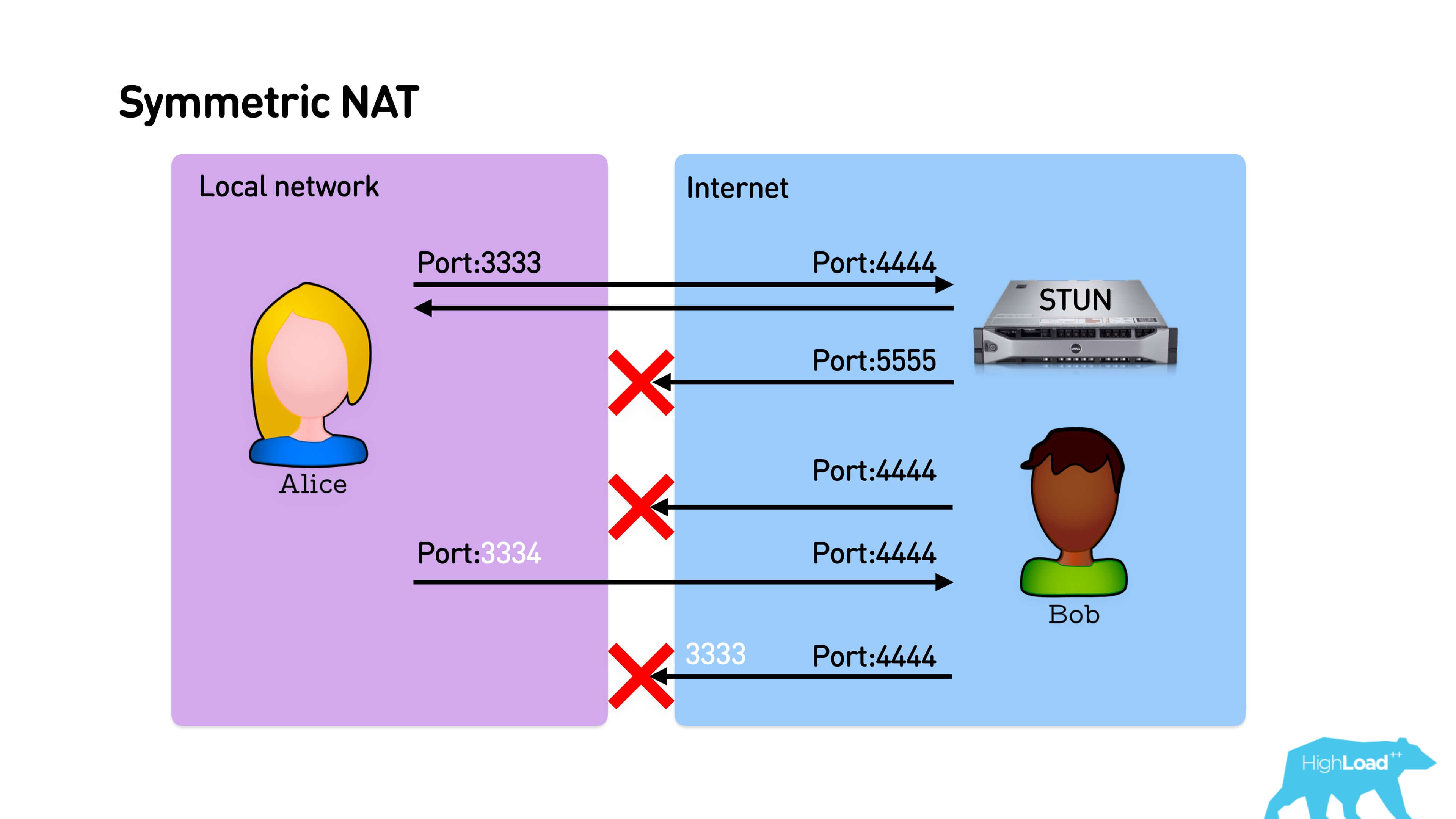
At first, everything works in exactly the same way - Alice sends the packet to the STUN server, it responds from the same port. Bob cannot answer Alice, but she sends the packet to Bob. And here, despite the fact that Alice sends a packet to port 4444, mapping allocates a new port for her. Symmetric NAT differs in that when each new connection is established, each time it issues a new port on the router. Accordingly, Bob is beating in the port from which Alice went to STUN, and they can not connect.
In the opposite direction, if Bob has an open IP address, Alice may just come to him and they will establish a connection.
All options are collected in one table below.

It shows that almost everything is possible except when we try to establish connections through Symmetric NAT with Port restricted cone NAT or Symmetric NAT on the other end.
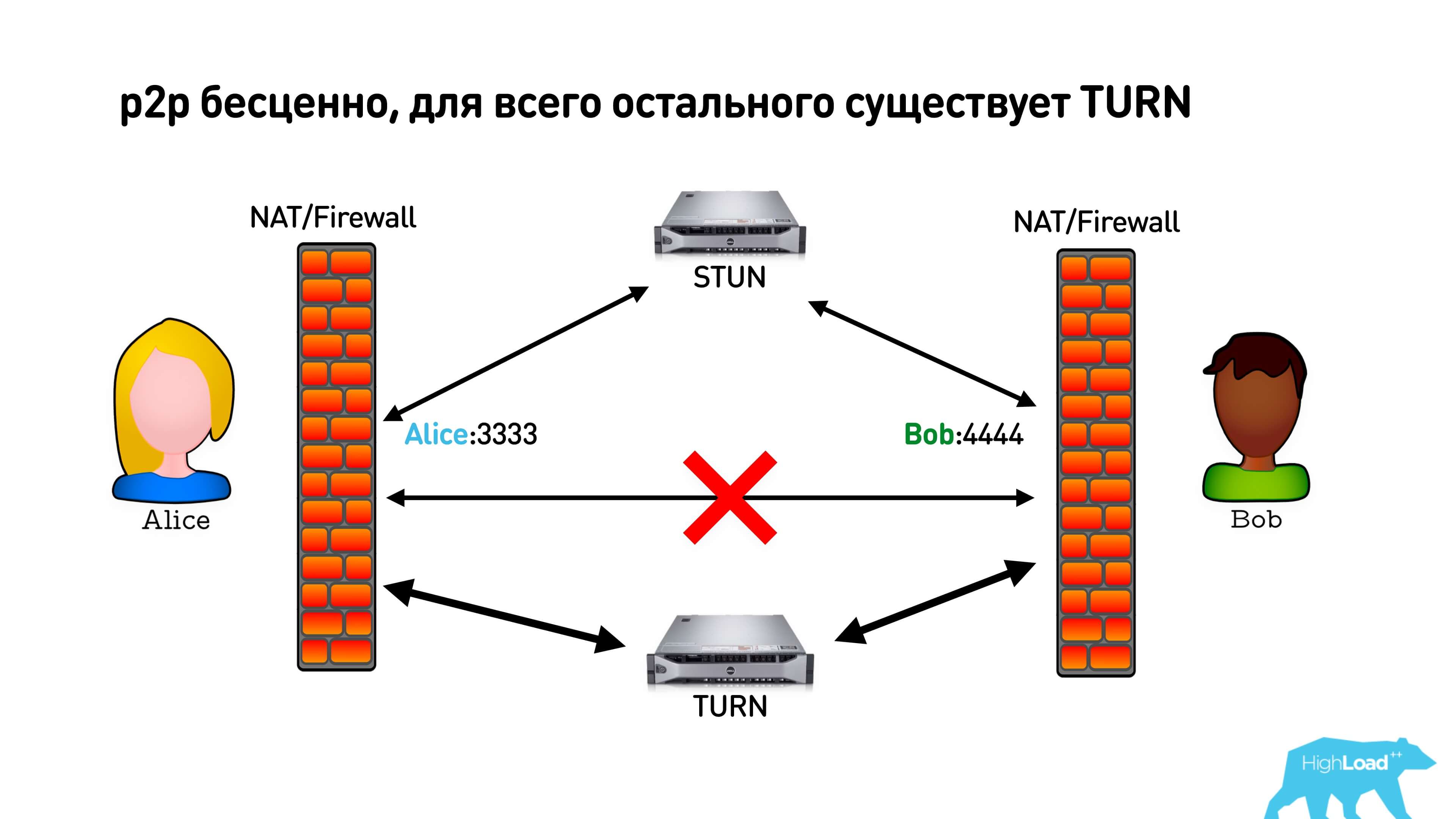
As we found out, p2p is priceless for us in terms of latency, but if it was not possible to install it, then WebRTC offers us a TURN server. When we realized that p2p will not install, we can just connect to TURN, which will proxy all traffic. However, at the same time you will pay for traffic, and users may have some additional delays.
Practice
Google has free STUN servers. You can put them in the library, it will work.
TURN servers have credential (login and password). Most likely, you will have to raise your own, it is rather difficult to find free.
Examples of free STUN servers from Google:
And a free TURN server with passwords: url: 'turn: 192.158.29.39: 3478? Transport = udp', credential: 'JZEOEt2V3Qb0y27GRntt2u2PAYA =', username: '28224511: 1379330808 ′.
We use coturn .
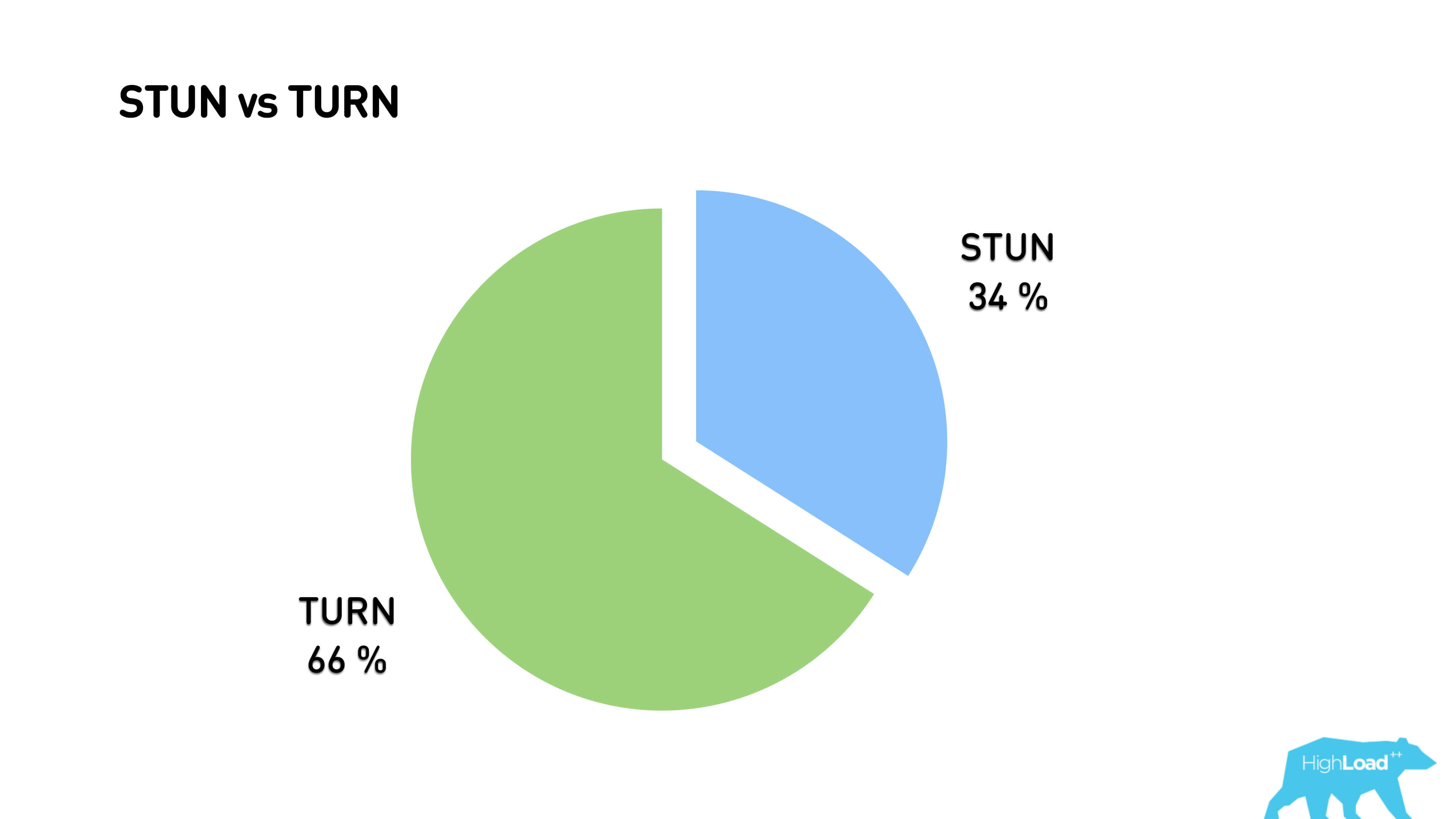
As a result, 34% of traffic passes through the p2p connection, everything else is proxied through the TURN server.
What else is interesting in the STUN protocol?
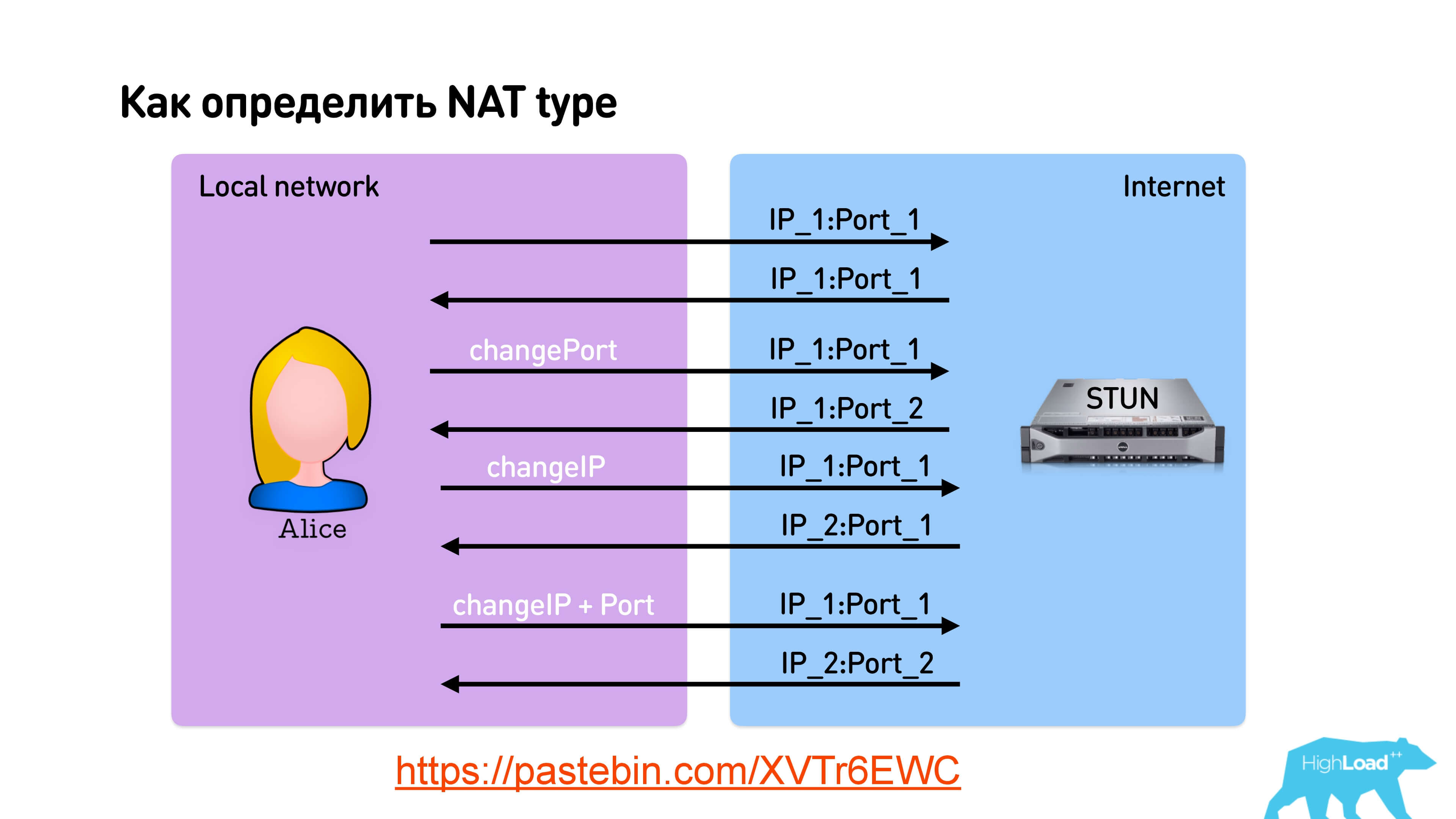
STUN allows you to determine the type of NAT.
Link on the slide
When sending a packet, you can indicate that you want to receive a response from the same port or ask STUN to reply from another port, from a different IP, or even from a different IP and port. Thus, for 4 queries to the STUN server, you can determine the type of NAT .
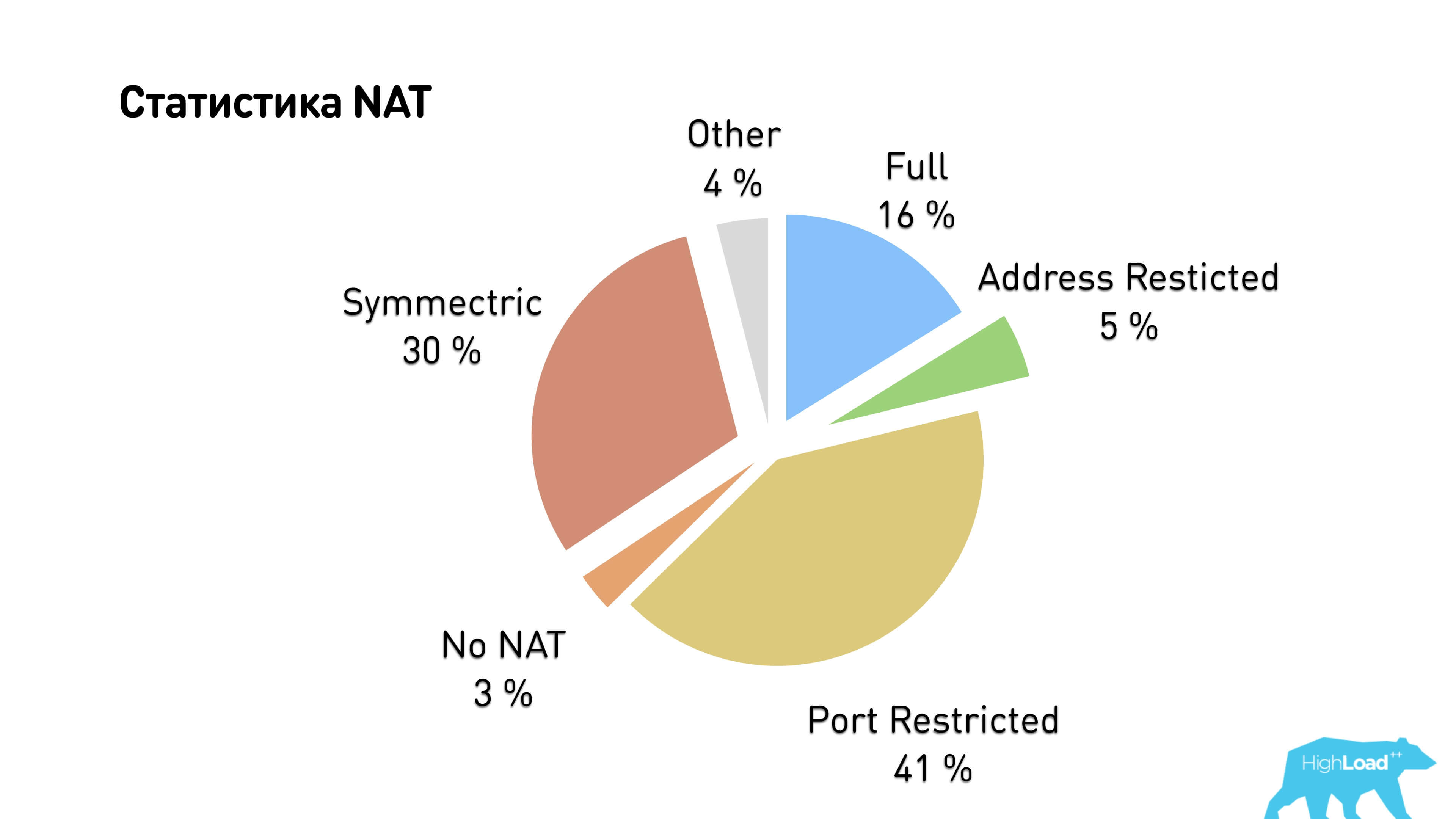
We counted the types of NAT and we got that almost all users have either Symmetric NAT or Port restricted cone NAT. Hence, it turns out that only a third of users can establish a p2p connection.
You may ask why I'm telling you all this if you could just take the STUN from Google, put it into WebRTC, and it seems like everything will work.
Because you can actually determine the type of NAT yourself.

This is a linkto a Java application that does nothing tricky: it just pings different ports and different STUN servers, and looks at which port it sees in the end. If you have Open Full cone NAT, then the STUN server will have the same port. With Restricted cone NAT, you will have different ports for each STUN request.

With Symmetric NAT, it turns out like this in my office. There are completely different ports.
But sometimes there is an interesting pattern that for each connection, the port number increases by one.

That is, many NATs are configured so that they increase or decrease the port by a constant. This constant can be found and thus break through Symmetric NAT.

Thus we break through NAT - we go to one STUN server, to another, look at the difference, compare and try again to give our port already with this increment or decrement. That is, Alice is trying to give Bob her port, already adjusted for a constant, knowing that next time it will be just that.
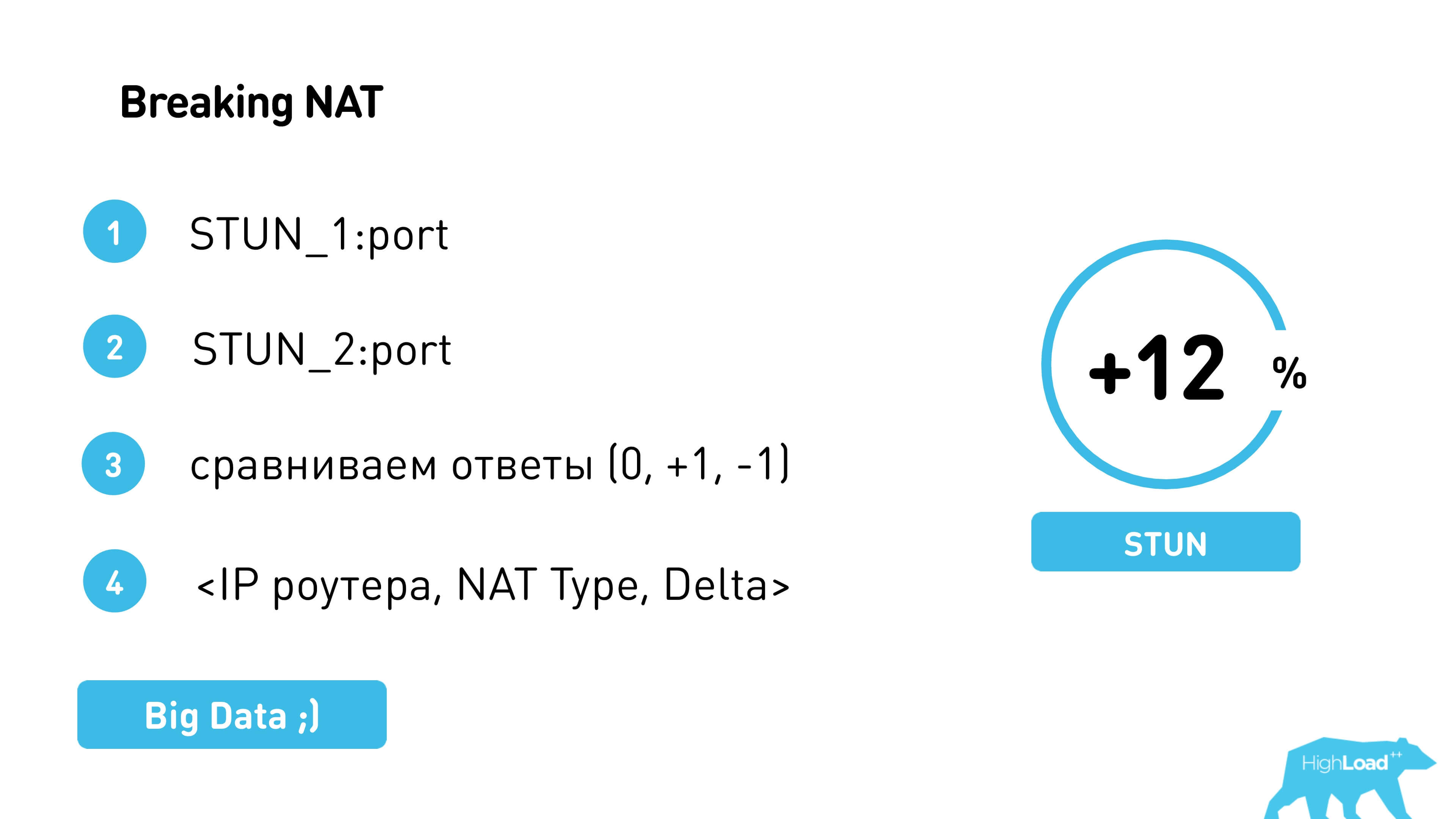
So we managed to weld another 12% peer-to-peer .
In fact, sometimes external routers with the same IP behave the same. Therefore, if you collect statistics and if Symmetric NAT is a feature of the provider, and not a feature of the user's Wi-Fi router, then the delta can be predicted, immediately send it to the user so that he uses it and does not spend too much time determining it.
CDN Relay or what to do if you could not establish a P2P connection
If we still use the TURN server and work not in p2p, but in real mode, passing all the traffic through the server, we can still add a CDN. Unless, of course, you have a playground. We have our own CDN sites, so for us it was quite simple. But it was necessary to determine where it is better to send a person: to a CDN site or, say, to a channel to Moscow. This is not a very trivial task, so we did this:

There is a CDN in Novosibirsk. If everything works for you through Moscow, then the 99th percentile of RTT is 1.3 seconds. Through CDN, everything works much faster (0.4 seconds).
Is it always better to use a p2p connection and not use a server? An interesting example is the two Krasnoyarsk providers Optibyte and Mobra (names may have changed). For some reason, the connection between them on p2p is much worse than through MSK. Probably they are not friends with each other.

We analyzed all such cases, randomly sending users to p2p or via MSK, collected statistics and built predictions. We know that statistics need to be updated, so for some users we specially establish different connections to check if something has changed in the networks.
We measured such simple characteristics as round time, packet loss, bandwidth - it remains to learn how to compare them correctly.

How to understand which is better: 2 Mbit / s Internet, 400 ms RTT and 5% packet Loss or 100 Kbit / s, 100 ms delay and scanty packet loss?
There is no exact answer, the assessment of video call quality is very subjective. Therefore, after the end of the call, we asked users to evaluate the quality in asterisks and set the constants according to the results. It turned out that, for example, RTT is less than 300 ms - it doesn’t matter anymore, bitrate is more important.
Higher user ratings on Android and iOS. It is seen that iOS users are more likely to put a unit and more often five. I don’t know why, probably, the specifics of the platform. But we pulled the constants along them, so that we had, as it seems to us, good.
Back to our outline for the article, we are still discussing the network.
What does the connection setup look like?

We send STUN and TURN servers to PeerConnection (), a connection is established. Alice finds out her IP, sends it to signaling; Bob learns about Alice's IP. Alice gets Bob's IP. They exchange packets, maybe break through NAT, maybe set TURN and communicate.

In the 5 steps of establishing the connection that we discussed earlier, we figured out the servers, figured out where to get them, and that ICE candidates are external IP addresses that we exchange through signaling. Internal IP addresses of clients, if they are within the range of one Wi-Fi, can also be tried to break through.
Let's move on to the part of the video.
Video and audio
WebRTC supports a certain set of video and audio codecs, but you can add your own codec there. Basically supported by H.264 and VP8 for video . VP8 is a software codec, therefore it consumes a lot of battery. H.264 is not available on all devices (it is usually native), so the default priority is on VP8.
Inside SDP (Session Description Protocol), there is codec negotiation: when one client sends a list of its codecs, the other sends its own with priority, and they agree on which codecs they will use for communication. If desired, you can change the priority of the VP8 and H.264 codecs, and due to this, you can save battery on some devices, where 264 is native. Here is an exampleof how this can be done. We did this, it seemed to us that users did not complain about the quality, but at the same time the battery charge was consumed much less.
For audio, WebRTC has OPUS or G711 , usually all OPUS always work, nothing needs to be done with it.
Below are temperature measurements after 10 minutes of use.

It is clear that we tested different devices. This is an example of an iPhone, and on it, the OK application uses the battery the least, because the temperature of the device is the least.
The second thing that you can enable if you use WebRTC is to automatically turn off the video when the connection is very poor .
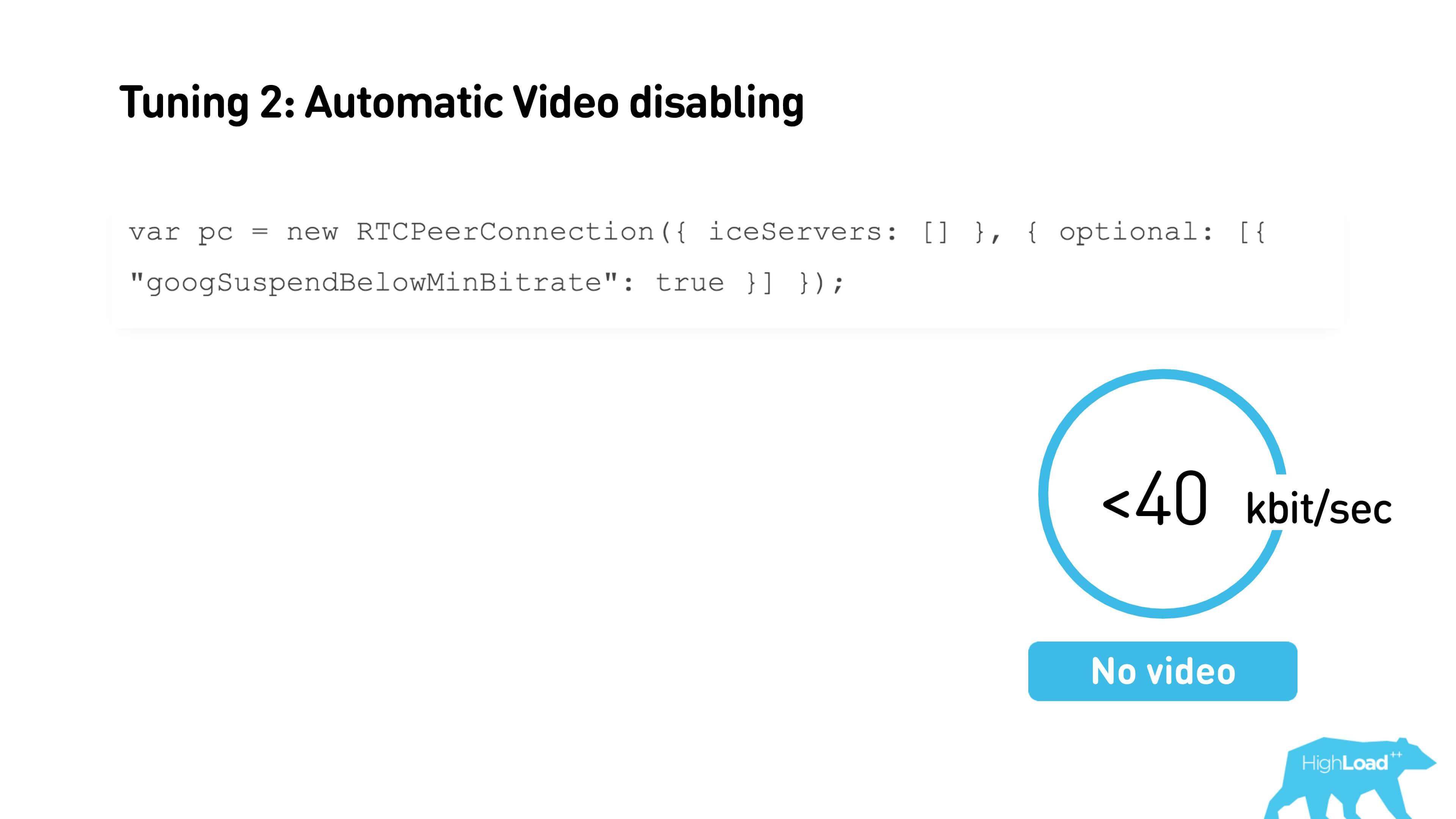
If you have less than 40 Kbps, the video will turn off. You just need to check the box when creating the connection, the threshold value can be configured through the interface. You can also set the minimum and maximum starting current bitrate.

This is a very useful thing. If when you establish a connection, you know in advance what bitrate you are expecting, you can transfer it, the call will start from it, and you will not need to adapt the bitrate. Plus, if you know that you often have packet loss or bandwidth drawdowns on your channel, then the maximum value can also be limited.
WhatsApp works with very soapy videos, but with small delays, as it aggressively compresses the bitrate from above.
We collected statistics using MaxMind and mapped it.
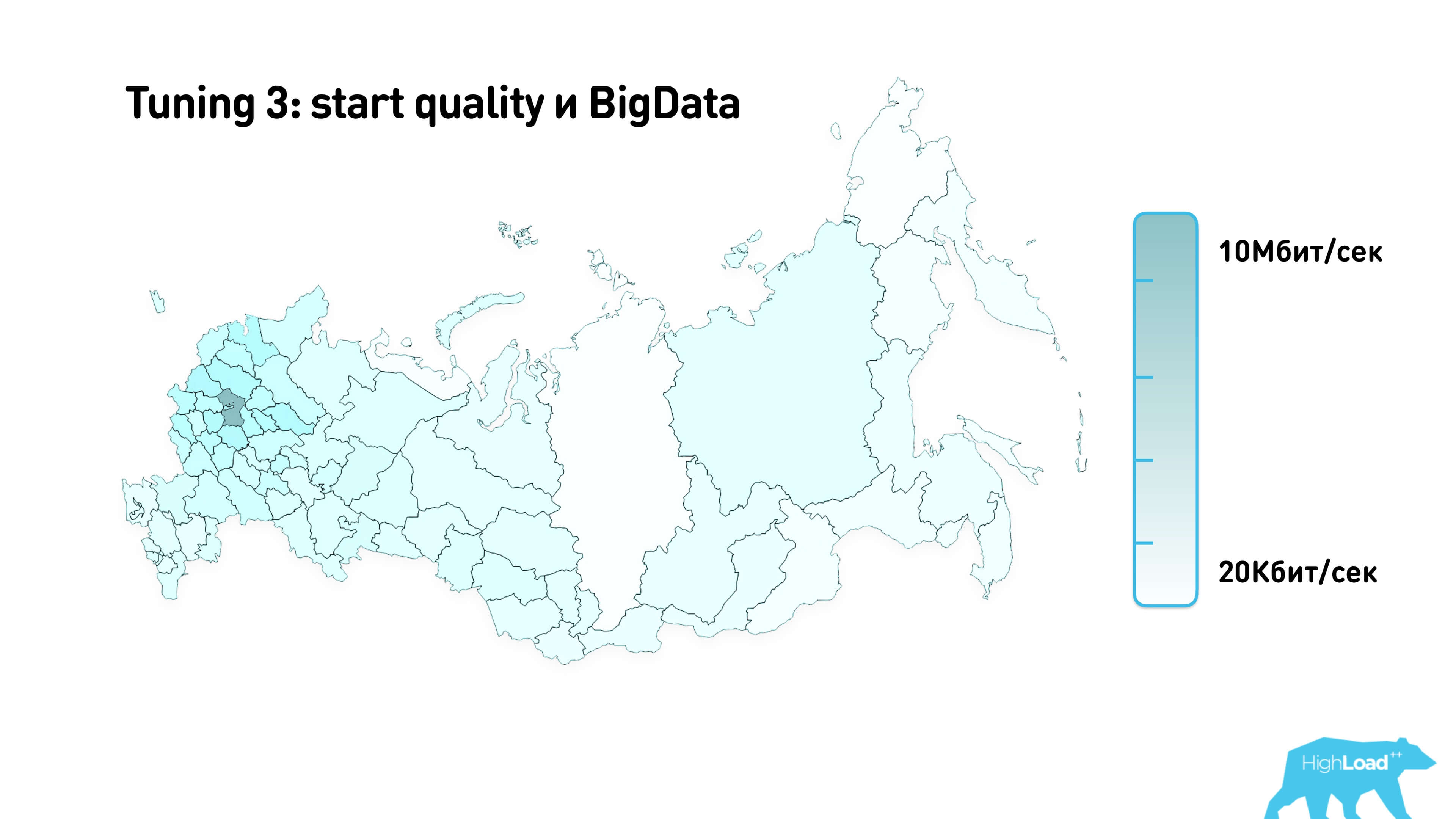
This is an approximate starting quality that we use for calls in different regions of Russia.
Signaling
You will most likely have to write this part if you want to make calls. There are all sorts of pitfalls. Recall how it looks.

There is an application with signaling that connects and exchanges with SDP, and the SDP below is the interface to WebRTC.
This is what simple signaling looks like:
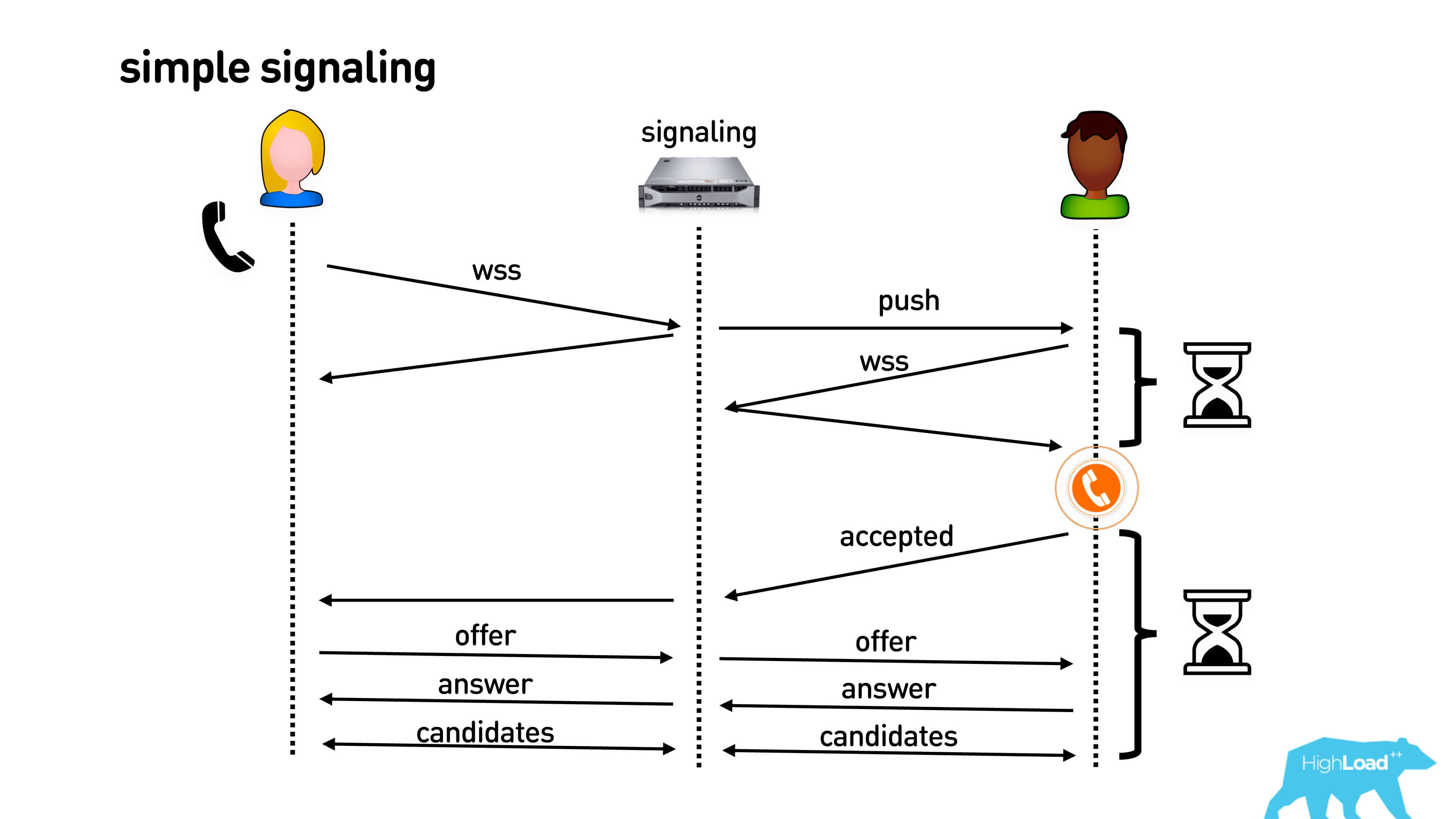
Alice calls Bob. It connects, for example, via a web-socket connection. Bob receives a push on his mobile phone or browser, or in some kind of open connection, connects via a web-socket and after that the phone starts ringing in his pocket. Bob picks up the phone, Alice sends him his codecs and other WebRTC features that she supports. Bob answers her the same, and after that they exchange the candidates they saw. Hooray, call!
It all looks pretty long. First, until you establish a web-socket connection, until push comes and everything else, Bob’s phone will not ring in his pocket. Alice will wait all the time, think where Bob is, why he does not pick up the phone. After confirmation, it all takes seconds, and even on good connections it can be 3-5 seconds, and on bad connections - all 10.
Something needs to be done with this! You will tell me that everything can be done very simply.
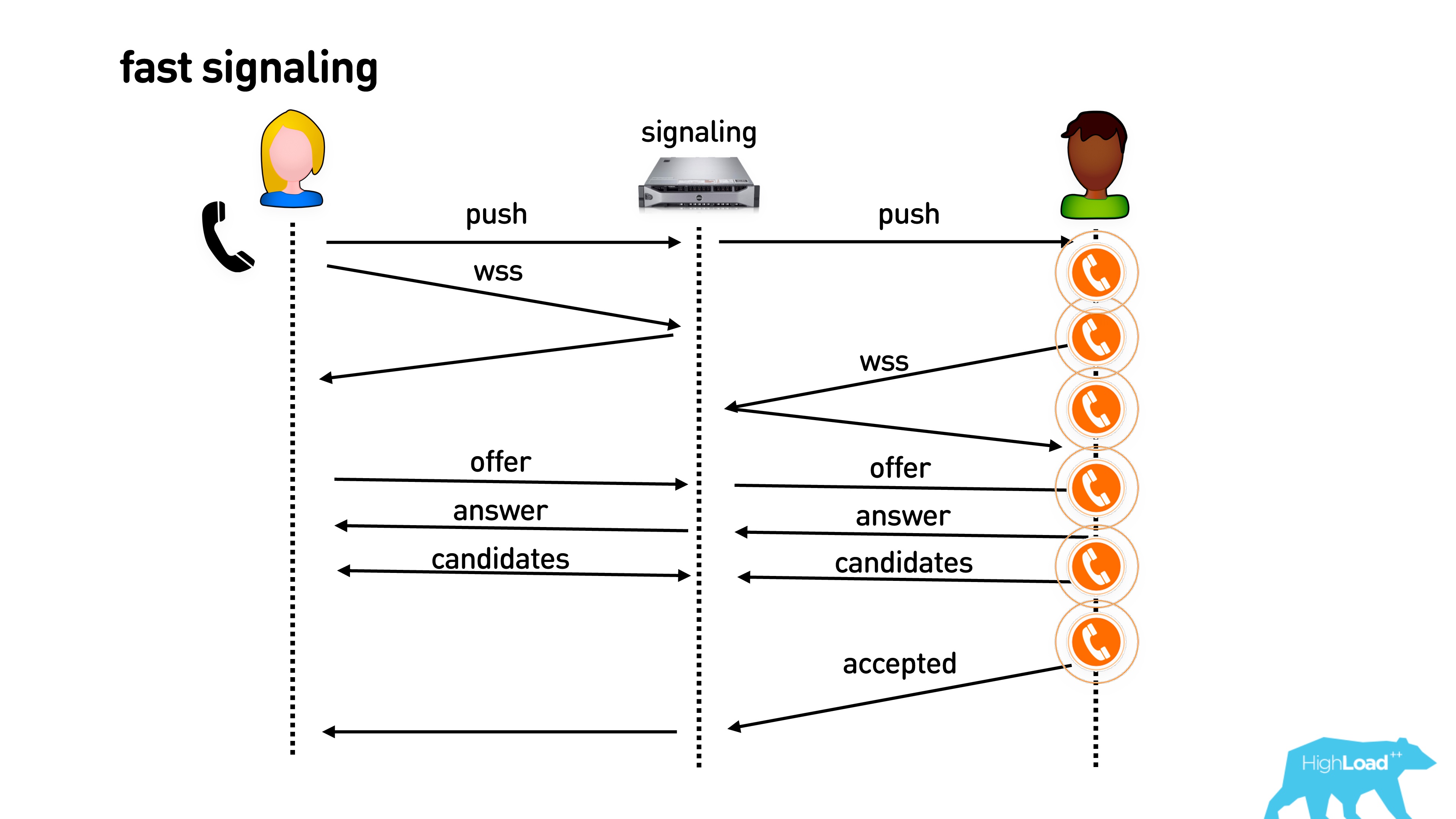
If you already have an open connection for your application, you can immediately send a push to establish a connection, connect to the desired signaling server and immediately start making calls.
Then another optimization. Even if the phone is still ringing in your pocket and you haven’t picked up the phone, you can actually exchange information about the supported codecs, external IP addresses, start sending empty video packets, and in general everything will be warmed up. Once you pick up the phone, everything will be great.
We did so, and it seemed that everything was cool. But no.
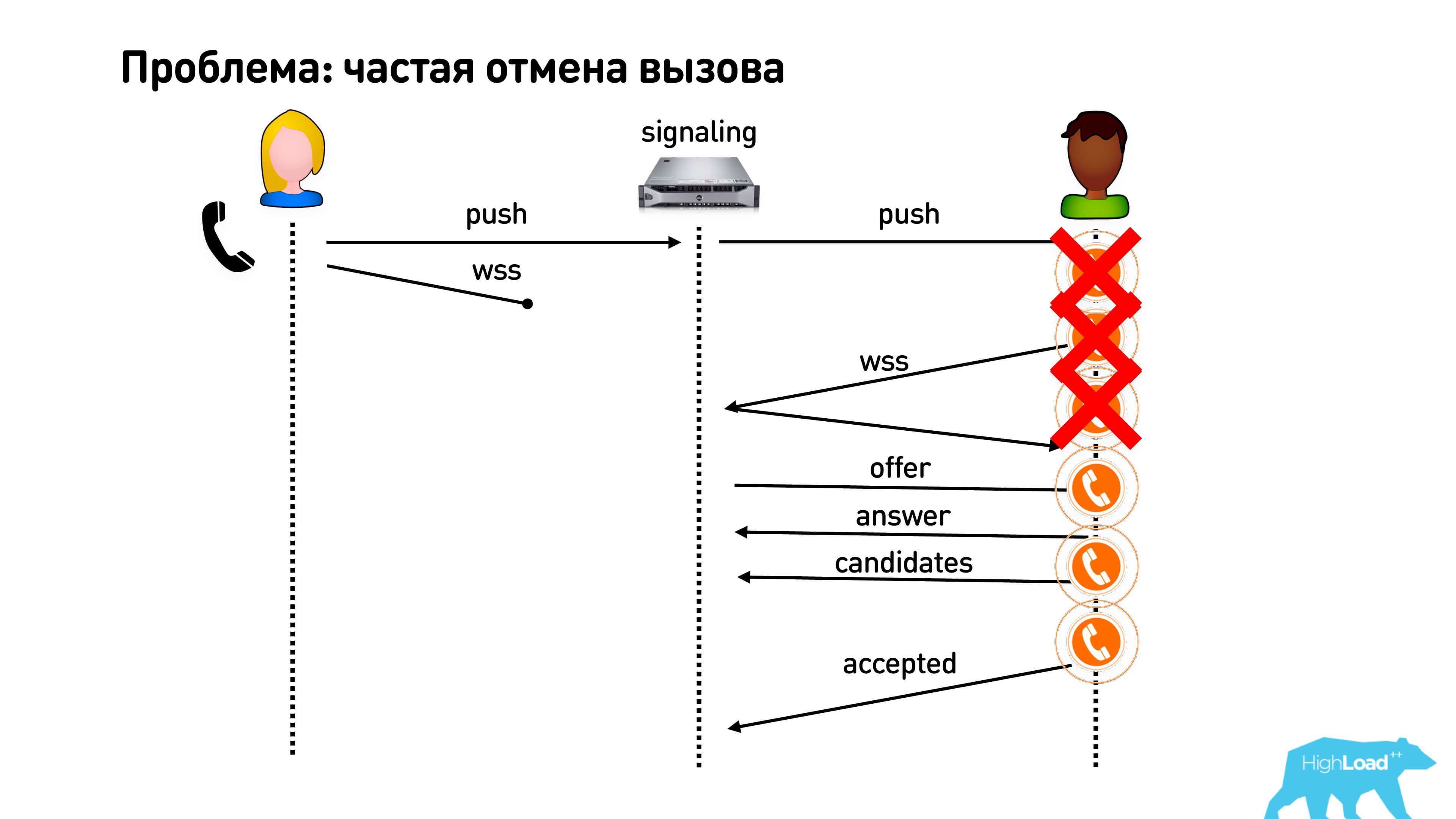
The first problem is that users often cancel the call. They click “Call” and immediately cancel. Accordingly, the push goes to the call, and the user disappears (he has lost the Internet or something else). Meanwhile, someone's phone rings, he picks up the phone, and he is not expected there. Therefore, our primitive optimization in order to start calling as quickly as possible does not really work.
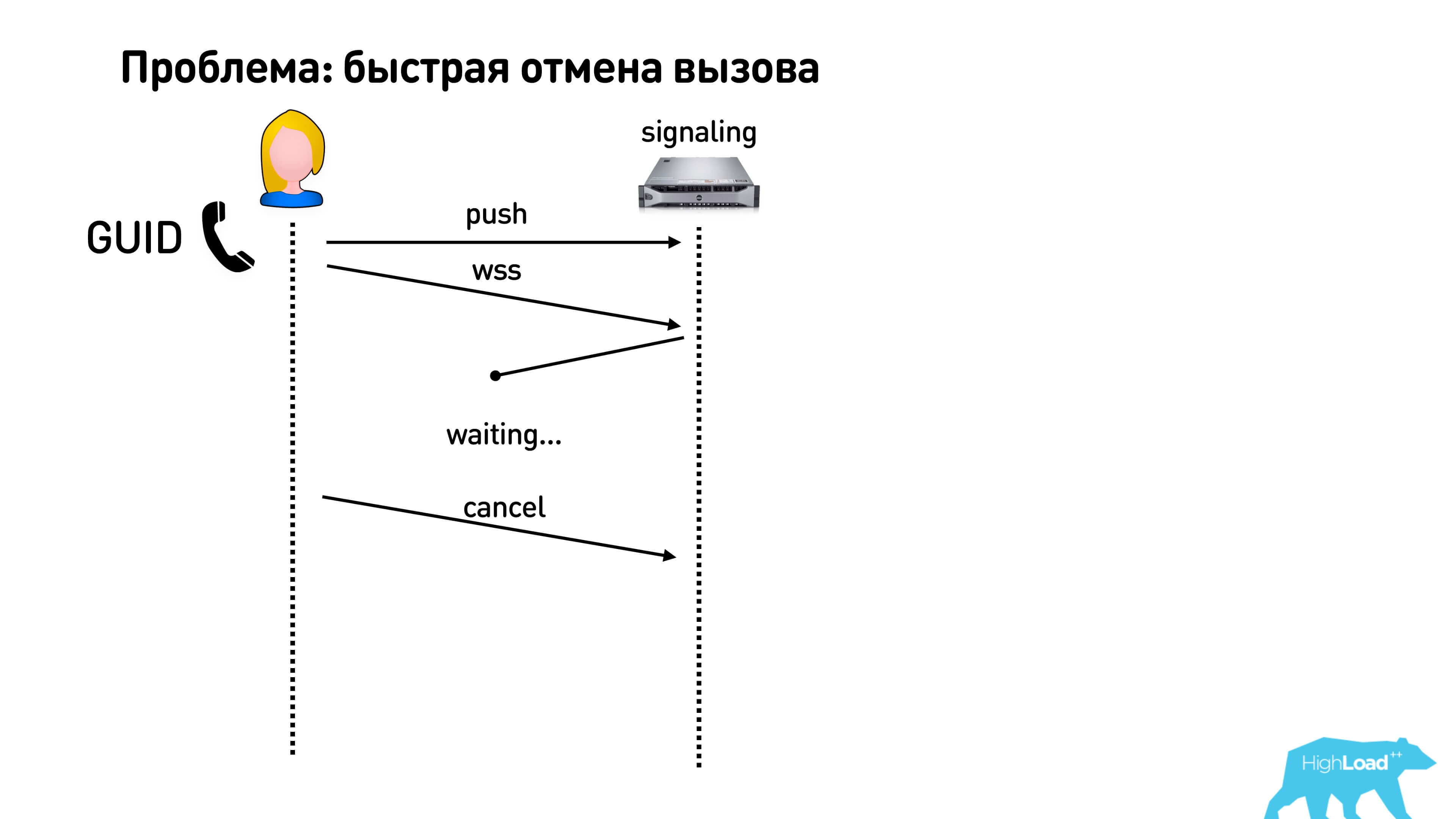
With a quick call cancellation, there is a second harmful thing. If you generate the ID of your conversation on the server, then you need to wait for a response. That is, you create a call, get an ID, and only after that you can do whatever you want: send packets, exchange, including cancel the call. This is a very bad story, because it turns out that until response has arrived, you cannot actually cancel anything from the client. Therefore, it is best to generate some kind of ID on the client such as a GUID and say that you started the call. People often do this: they called, canceled and immediately called again. To prevent this from getting messed up, do a GUID and submit it.

It seems to be nothing, but there is another problem. If Bob has two phones, or somewhere else the browser remains open, then our whole magic scheme in order to exchange packets, establish a connection does not work if he suddenly answered from another device.
What to do? Let's go back to our basic simple slow signaling scheme and optimize it, send the push a little earlier. The user will begin to connect faster, but this will save some pennies.

What to do with the longest part after he picked up the phone and started the exchange?

You can do the following. It’s clear that Alice already knows all her codecs and can send them to both of Bob’s phones. She can resolve all her IP addresses and also send them to signaling, which will keep them in her queue, but will not send to any of the clients so that they can start connecting to her ahead of time.
What can Bob do? Having received the offer, he can see what codecs were there, generate his own, write what he has, and send it too. But Bob has two phones, and they have different codec negotiation, so signaling will keep it all for himself and will wait in line until he finds out on which device they will pick up the phone. Candidates will also generate both devices and send them to signaling.
Thus, signaling has one message queue from Alice and several message queues from Bob on different devices. He stores all of this, and as soon as they pick up the phone on one of these devices, he simply throws the whole set of packages already prepared.
It works pretty fast. We managed with such an algorithm to reach characteristics similar to Google Duo and WhatsApp.

You can probably come up with something even better. For example, keep several queues not for signaling, but send them to the client, and then say which number, but, most likely, the gain will be very small. We decided to stop there.
What other problems await you?

There is such a thing as a return call: one calls another, the other rings back. It would be nice if they didn’t try to compete - at the signaling level add a command that says that if someone came second, you need to switch to the mode when you simply accept the call and immediately pick up the phone.

It happens that the network disappears, messages are lost, so everything needs to be done through queues. That is, you must have a dispatch queue on the client. Messages that you send from the client should be deleted from the queue only after the server has confirmed that it has processed them. The server also has a queue for sending, and also with confirmation.
So all this is implemented with us internally, taking into account that we have a 24/7 service, we want to be able to lose data centers, shift and update the version of our software.
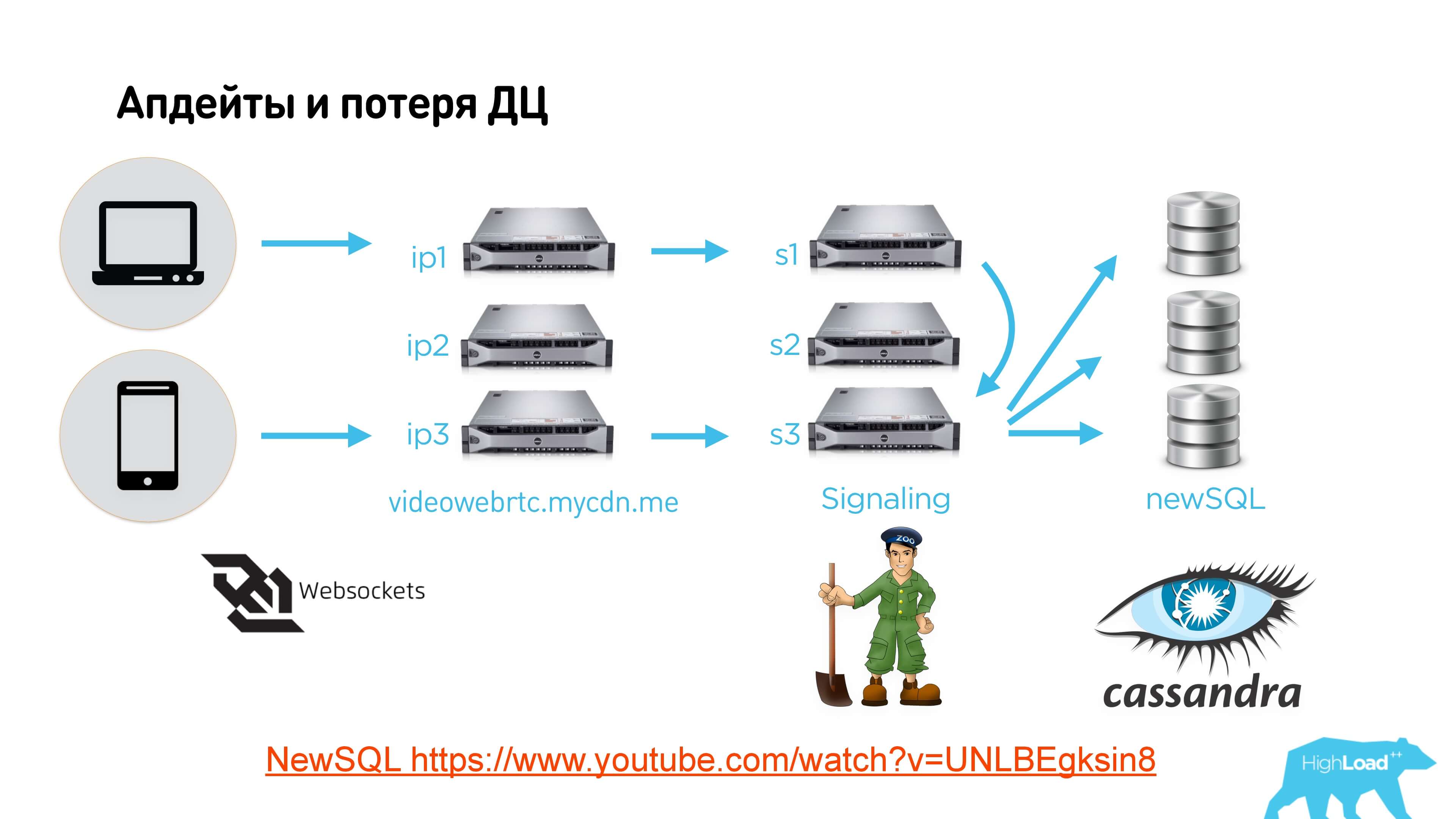
Link on the slide to the video and link to the text version
Clients connect via web-socket to some load balancer, it sends to signaling servers in different data centers, different clients can come to different servers. At Zookeeper, we make a Leader Election, which defines the signaling server that now manages this conversation. If the server is not the leader of this conversation, he simply throws all messages to another.
Next we use some distributed storage, we have NewSQL on top of Cassandra. It really doesn't matter what to use. You can save the status of all the queues that are on signaling anywhere so that if the signaling server disappears, the power goes out or something else happens, the Leader Election works on Zookeeper, another server that becomes the leader gets up, restores all queues from the database messages and start sending.
The algorithm looks like this:
All packages are provided with unique numbers so as not to be confused.
From the point of view of the database, we use an add-on over Cassandra, which allows you to make transactions on it (the video is just about that).
So, you have learned:

We got:
Wow!
Security Man in the middle attack for WebRTC
Let's talk about man in the middle attack for WebRTC. In fact, WebRTC is a very difficult protocol in that it is based on RTP, which is still 1996, and SDP came in 1998 from SIP.
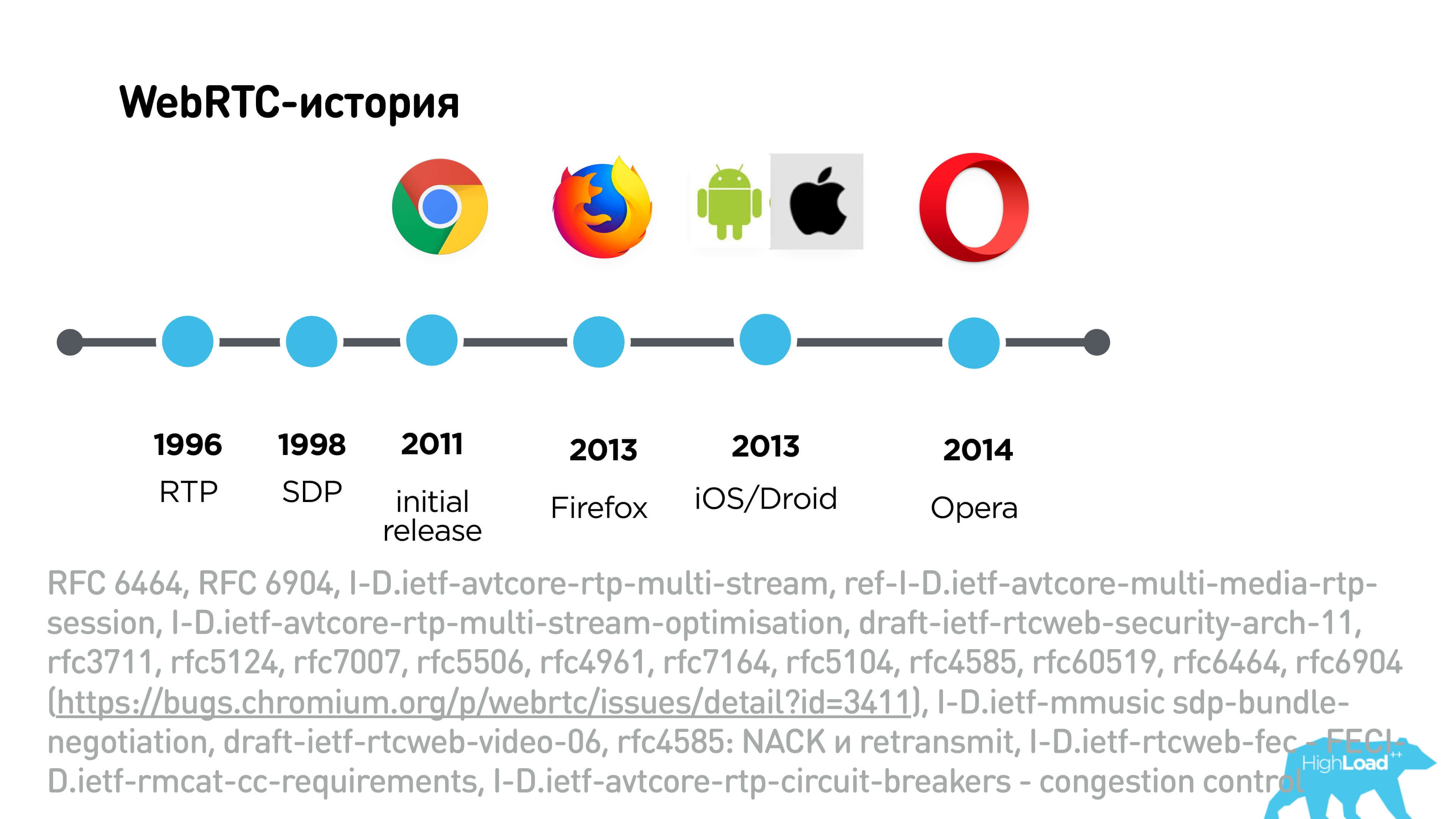
At the bottom, a huge list is a bunch of RFCs and other RTP extensions that make RTP WebRTC.
The first two interesting RFCs on the list - one of them adds an audio level to packets, and the other says that it is unsafe to transmit the audio level in packets openly, and encrypts them. Accordingly, when you exchange SDP, it is important for you to know which set of extensions the clients support. There are even several congestion algorithms, several algorithms for recovering lost packets and just about everything.
The history of WebRTC was complicated. The first draft release was released in 2011, in 2013 Firefox supported this protocol, then it began to be built on iOS / Android, in 2014 Opera. In general, it developed for many, many years, but still does not solve one interesting problem.
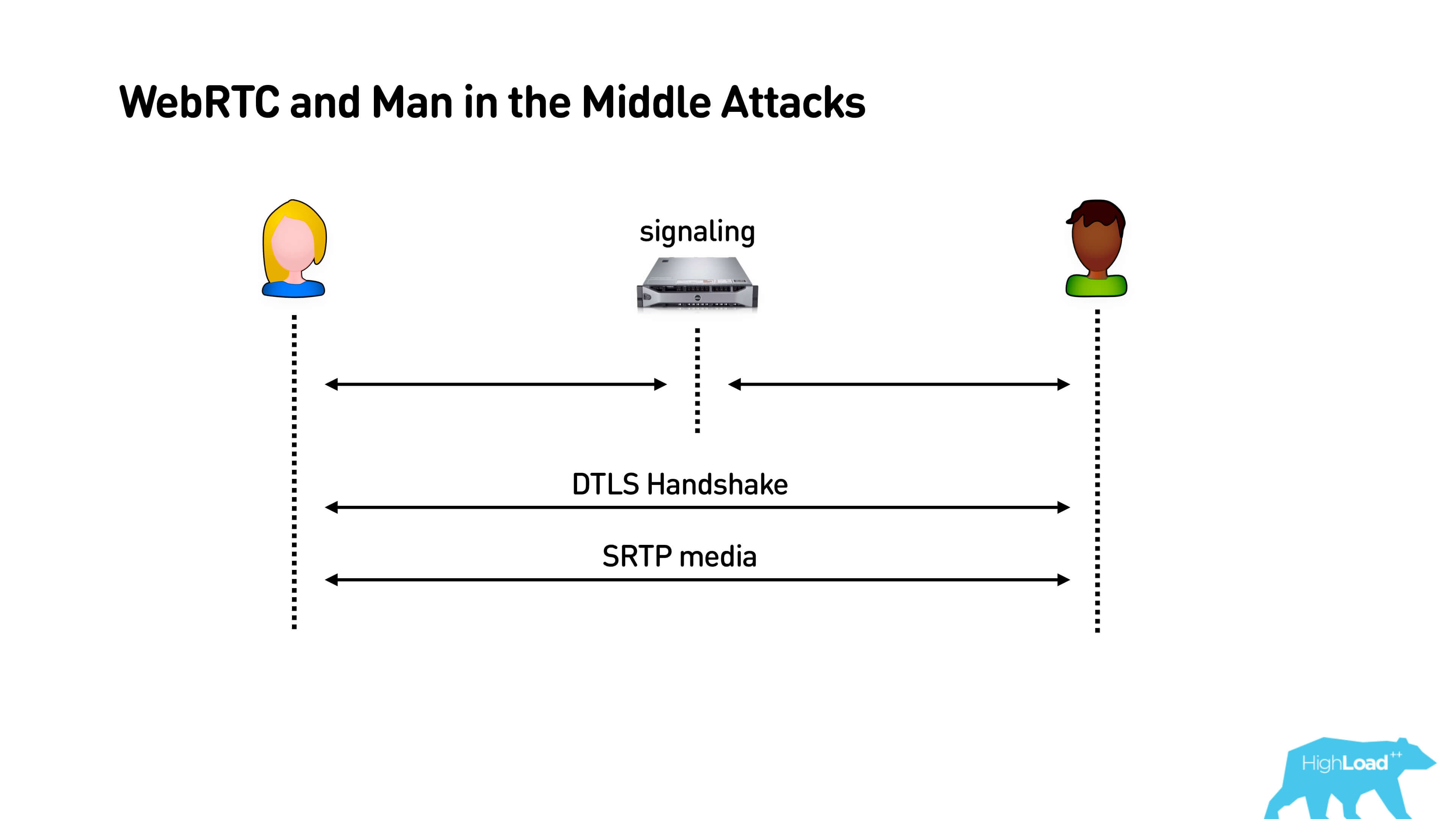
When Alice and Bob connect to signaling, then they use this channel, establish DTLS Handshake and secure connection. Everything is great, but if it turned out to be not our signaling, then, in principle, the person in the middle has the opportunity to "make money" with both Alice and Bob, to block all traffic and eavesdrop on what is happening there.
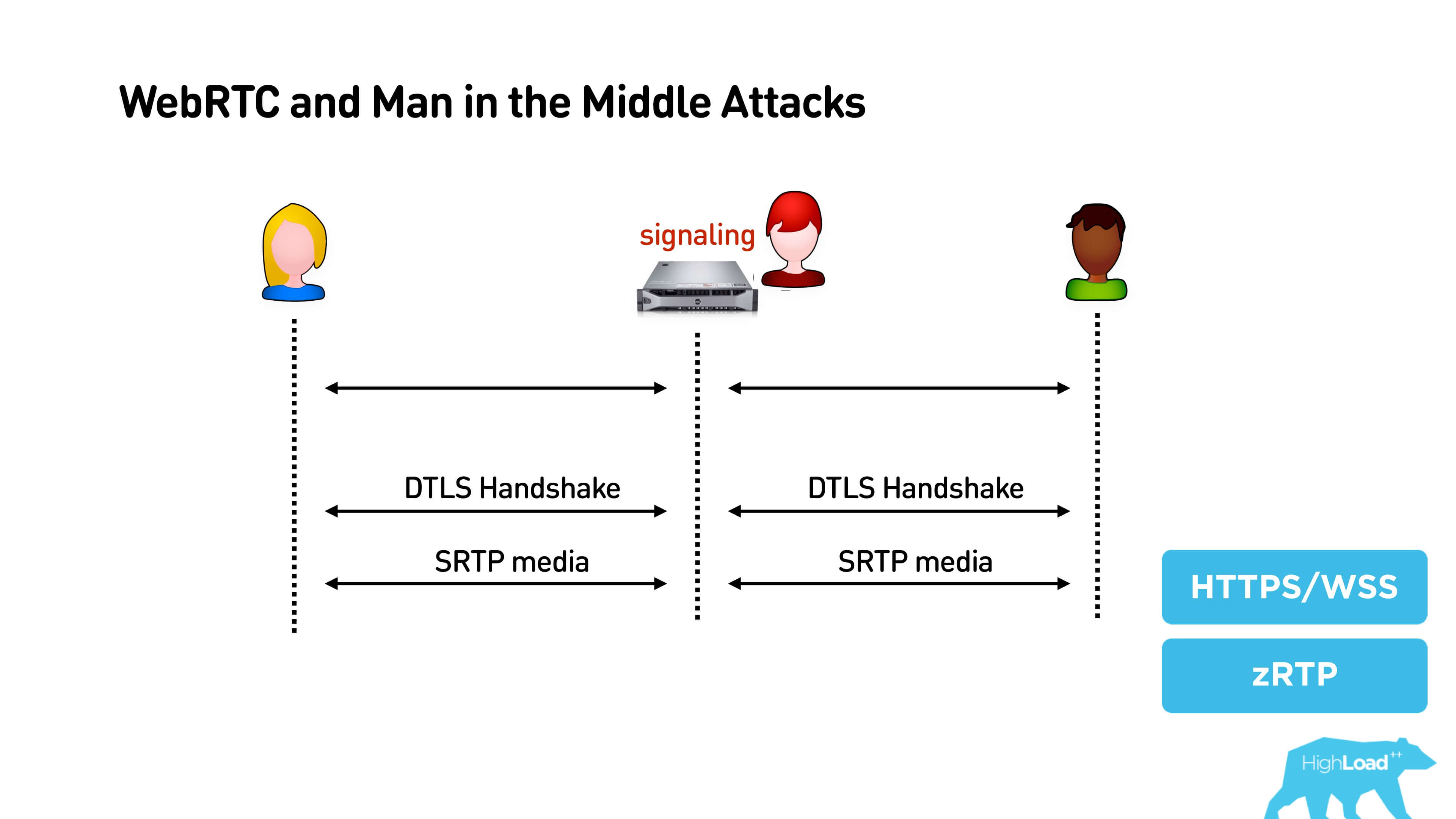
If you have a service with high trust, then, of course, you definitely need to use HTTPS, WSS, etc. There is another interesting solution - ZRTP, it is used, for example, by Telegram.
Many have seen emoji on Telegram when a connection is established, but few use it. In fact, if you tell a friend what emojis you have, he will verify that he has exactly the same, then you have absolutely guaranteed a secure p2p connection.
How it works?
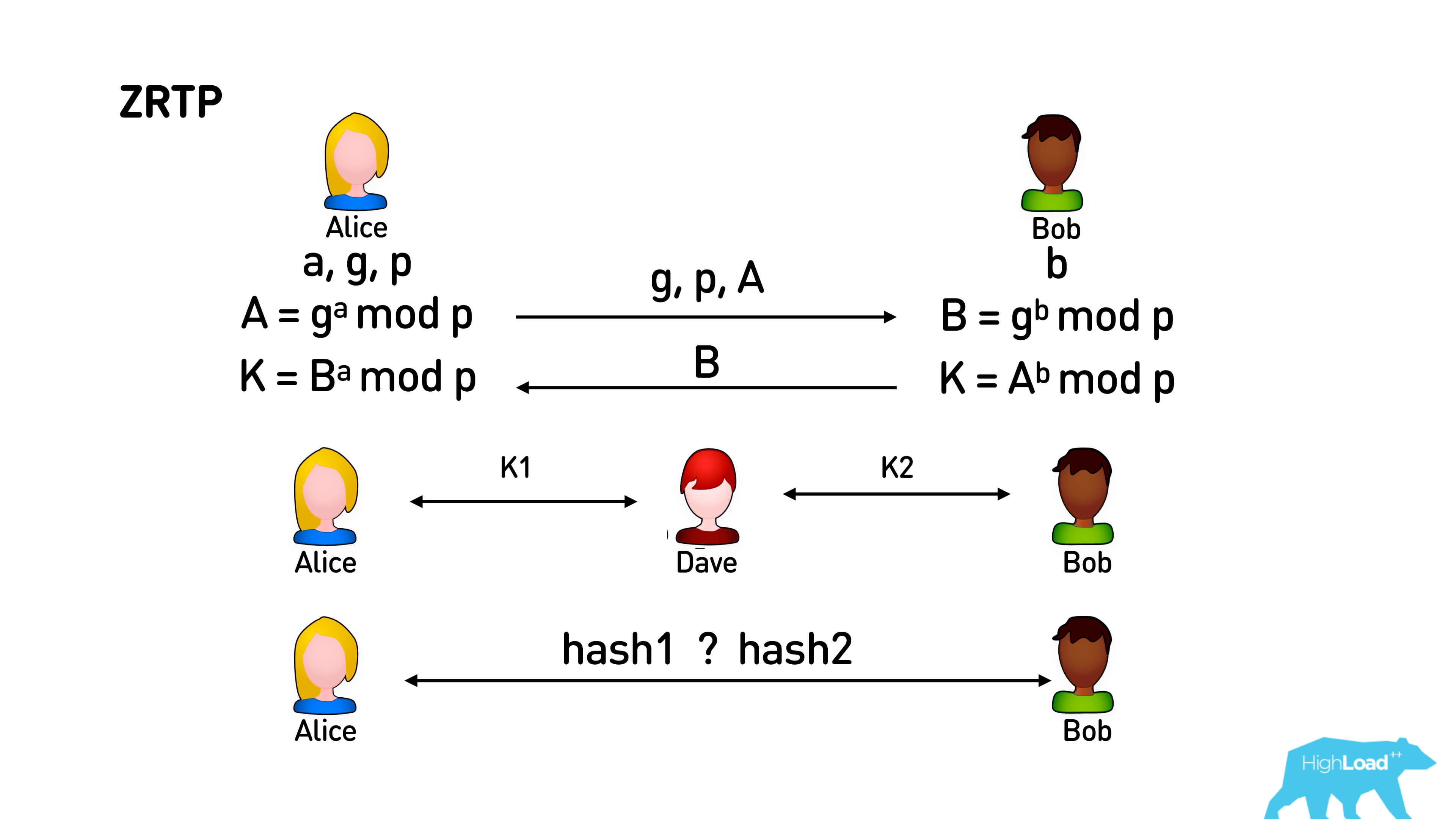
Inside all these protocols, the usual Diffie-Hellman algorithm is initially used. Alice generates some numbers, sends them all but one to Bob. Bob also generates a random number and sends it to Alice. As a result of this exchange, Alice and Bob get a certain large number K, about which the man in the middle who listened to their entire channel knows nothing and can not guess at all.
When Dave appears between Alice and Bob, they exchange the same keys with him, and they get K 1and K 2, respectively. There is no way to track the presence of this person in the middle. Then such a trick is applied. These keys K 1 and K 2 will definitely be different for Dave, since Alice and Bob generate their keys randomly. We just take some hash from K 1 and K 2 and display it in the emoji: in an apple, in a pear - in anything, and people simply call the pictures they see with their voice. Since you can identify each other by voice, and if these pictures are different, then there is someone between you and maybe he is listening to you.
results

The graph shows that at first there were old calls to RTMFP, then when we switched to WebRTC, there is a slight failure, and then the peak rises. Not everything worked out right away! As a result, now the number of calls held has increased by 4 times.
Simple instruction
If you do not need all this, there is a very simple instruction:
Everything will ring, and ringing is pretty good.
Further the text version of the report on HighLoad ++ Siberia, from which you will learn:
- how video call services work under the hood;
- how beautiful it is to break through NAT - this will be interesting for game specialists who need a peer-to-peer connection;
- how WebRTC works, what protocols it includes;
- how can I tune WebRTC through BigData.
About the speaker: Alexander Tobol leads the development of the Video and Tape platforms at ok.ru.
Video call history
The first video call device appeared in 1960, it was called a picherphone, used dedicated networks and was extremely expensive. In 2006, Skype added video calls to its application. In 2010, Flash supported the RTMFP protocol, and we at Odnoklassniki launched Flash video calls. In 2016, Chrome stopped supporting Flash, and in August 2017 we restarted calls with the new technology, which I will talk about today. Having finalized the service, for another six months we received a significant increase in successfully completed calls. Recently, we also have masks in calls.
Architecture and TK
Since we work in a social network, we do not have technical tasks, and we don’t know what TK is. Usually the whole idea fits on one page and looks something like this.
The user wants to call other users using a web or iOS / Android application. Another user may have multiple devices. The call comes to all devices, the user picks up the phone on one of them, they talk. Everything is simple.
Specifications
In order to make a quality call service, we need to understand what characteristics we want to track. We decided to start by looking for what annoys the user the most.
The user is definitely annoyed if he picks up the phone and is forced to wait until the connection is established.
The user is annoyed if the call quality is poor - something is interrupted, the video is scattered, the sound is bubbling.
But most of all the user is annoyed by the delay in calls. Latency is one of the important characteristics of calls. With latency in a conversation of the order of 5 seconds, it is absolutely impossible to conduct a dialogue.
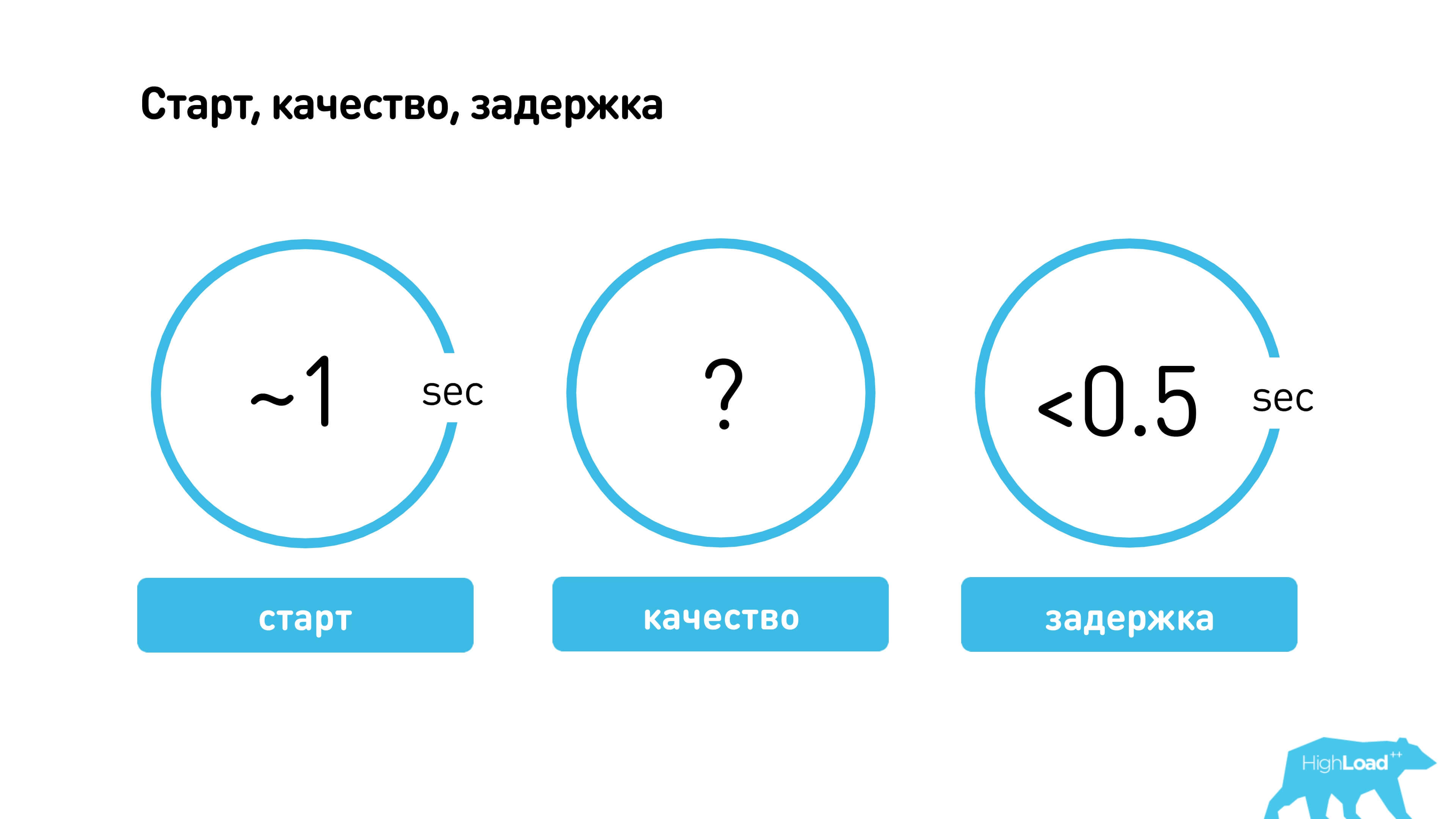
We have determined for ourselves acceptable characteristics:
- Start - we decided it was good to start the call in a second. Those. connecting after the user has answered, should take no more than 1 second.
- Quality is a very subjective indicator. You can measure, for example, the signal-to-noise ratio (SNR), but there are still missing frames and other artifacts. We measured quality rather subjectively and then evaluated the happiness of users.
- Latency should be less than 0.5 seconds. If Latency is more than 0.5 seconds, then you already hear delays and begin to interrupt each other.
Polycom is a conferencing system installed in our offices. We have average polycom latencies of the order of 1.3 seconds. With such a delay, you do not always understand each other. If the delay increases to 2 seconds, then dialogue will not be possible.
Since we had already launched the platform, we roughly expected that we would have a million calls per day. This is a thousand calls in parallel. If all calls are launched through the server, there will be a thousand megabit calls per call. This is only 1 gigabit / sec one iron server will be enough.
Internet vs TTX
What can prevent you from achieving such cool features? The Internet!
On the Internet, there are such things as round-trip time (RTT), which can not be overcome, there is a variable bandwidth, there is NAT.
Previously, we measured the transmission speed in the networks of our users.
We broke it down by the type of connection, looked at the average RTT, packet loss, speed, and decided that we would test calls on the average values of each of these networks.
There are other troubles on the Internet:
- Packet loss - we measured 0.6% random packet loss (we do not take into account congestion packet loss with an excessive number of packets).
- Reordering - you send packets in the same order, and the network re-sorts them.
- Jitter - send a video or audio stream at a certain interval, and packets come together on the client side in bundles, for example, due to buffering on network devices.
- NAT - it turned out that more than 97% of users are behind NAT. We’ll talk about why, what and how.
Consider the network settings listed above with a simple example.
I paged the website of Novosibirsk State University from my office and got such a strange ping.
The average jitter in this example is 30 ms, that is, the average interval between adjacent ping times is about 30 ms, and the average ping is 105 ms.
What is important in calls, why will we fight for p2p?
Obviously, if we managed to establish a p2p connection between our users who are trying to talk to each other in St. Petersburg, rather than through a server located in Novosibirsk, we will save about 100 ms round-trip and traffic to this service.
Therefore, most of the article is devoted to how to make good p2p.
History or legacy
As I said, we have had a call service since 2010, and now we have restarted it.
In 2006, when Skype started, Flash bought Amicima, which made RTMFP. Flash already had RTMP, which in principle can be used for calls, and it is often used for streaming. Flash later opened the RTMP specification. I wonder why they needed RTMFP? In 2010, we used RTMFP.
Compare the requirements for call protocols and real streaming protocols and see where this border is.
RTMP is more of a video streaming protocol. It uses TCP, it has cumulative delay. If you have a good internet connection, calls to RTMP will work.
RTMFP protocolDespite the difference in just one letter, it is the UDP protocol. It is free of buffering problems - those that are on TCP; It is deprived of head-of-line blocking - this is when you lost one packet, and TCP does not return the following packets until it is time to send the lost one again. RTMFP was able to handle NAT and was experiencing a change in the IP address of clients. Therefore, we launched the web on RTMFP in 2010.
Then only in 2011 did the initial draft WebRTC appear, which was not yet fully operational. In 2012, we started supporting calls on iOS / Android, then something else happened, and in 2016 Chrome stopped supporting Flash. We had to do something.
We looked at all the VoIP protocols: as always, in order to do something, we start by looking at competitors.
Competitors or where to start
We chose the most popular competitors: Skype, WhatsApp, Google Duo (similar to Hangouts) and ICQ.
To begin with, we measured the delay.
It is easy to do. Above is a photograph in which:
- Stopwatch (see phone at the top left), which shows the time (03:08).
- The nearby telephone makes a call and takes the first telephone as a video. From the moment the image got into the phone’s camera, and you saw it, it took about 100 ms.
- A call to another phone (white) and one more time. Here the delay is about 310 ms with Google Duo.
I won’t reveal all the cards yet, but we made sure that these devices could not establish p2p connections. Of course, the measurements were carried out in different networks, and this is just an example.
Skype still interrupts a little. It turned out that with Skype, in case it fails to connect p2p, the delay is 1.1 s.
Our test environment was complicated. We tested in different conditions (EDGE, 3G, LTE, WiFi), took into account that the channels are asymmetric, and I give the average values of all measurements.
In order to estimate the battery consumption, the load on the processor and everything else, we decided that you can simply measure the temperature of the phone with a pyrometer and assume that this is some average load on the phone’s GPU on the processor, on the battery. In principle, it’s very unpleasant to bring a hot phone to your ear, and even hold it in your hands. It seems to the user that now the application will use up its entire battery.
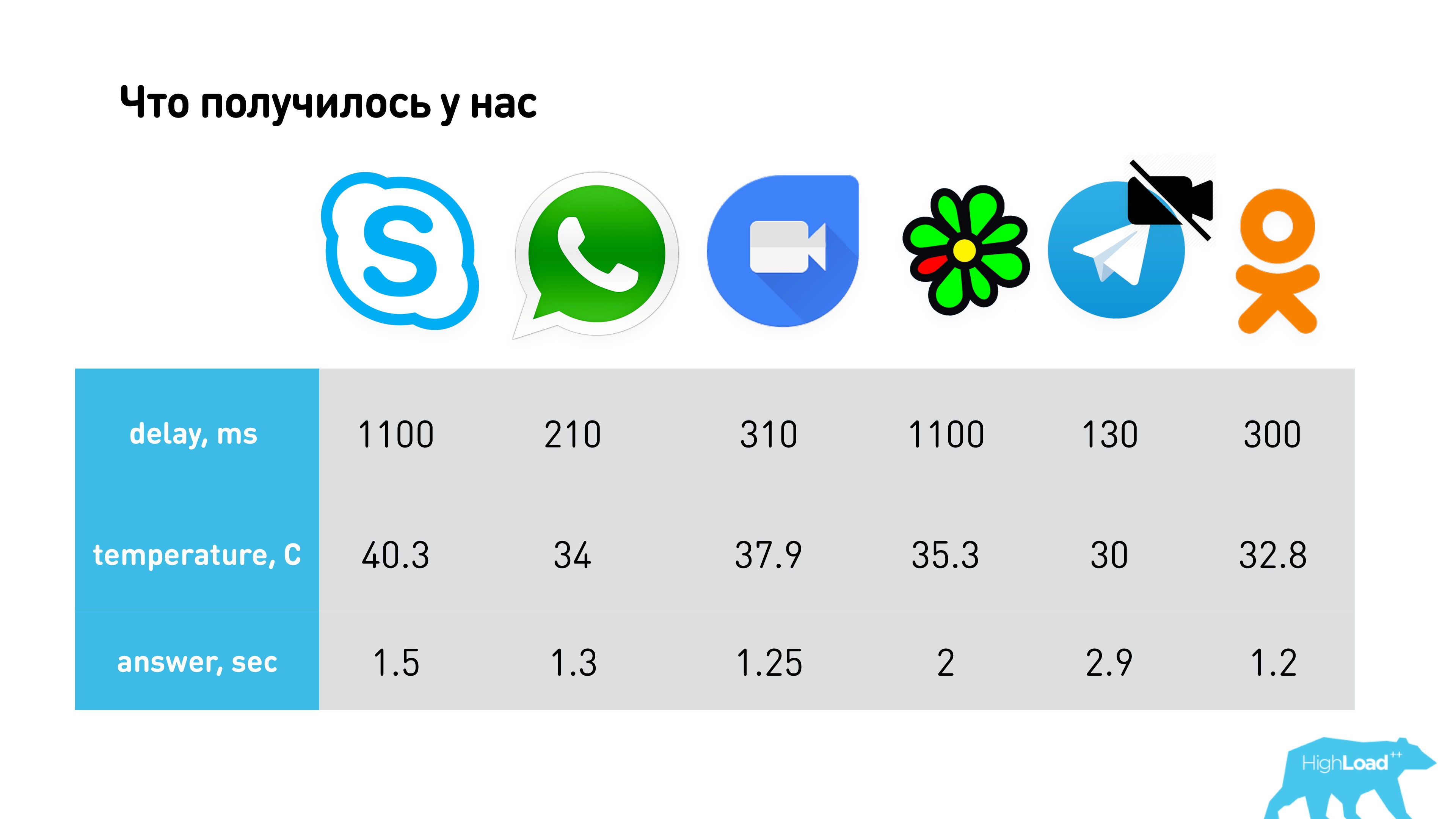
The result is:
- The slowest in the delay were ICQ and Skype, and the fastest - Telegram. This is not a completely correct comparison, since Telegram does not have video calls, but they have minimal latency in audio. WhatsApp (about 200 ms) and Hangouts - 390 ms work great.
- By temperature, Telegram eats the least without video, and Skype the most.
- In terms of response time, Telegram establishes the connection for the longest time, and the fastest WhatsApp and Google Duo.
Great, we got some metrics!
We tested the quality of video and voice on different networks, with different drops and everything else. As a result, we came to the conclusion that the highest quality video is on Google Duo, and the voice is on Skype , but this is in “bad” networks when there is already distortion. In general, everyone works approximately mediocre. WhatsApp has the most blurred picture.
Let's see what it is all implemented on.
Skype has its own proprietary protocol, and everyone else uses either a modification of WebRTC, or generally directly WebRTC. Hangouts, Google Duo, WhatsApp, Facebook Messenger can work with the web, and they all have WebRTC under the hood. They are all so different, with different characteristics, and they all have one WebRTC! So, you need to be able to cook it correctly. Plus there’s Telegram, for which some parts of WebRTC are responsible for the audio part, there is ICQ, which forked WebRTC for a long time and went on developing its own way.
WebRTC Architecture
WebRTC implies the presence of a signaling server, an intermediary between clients, which is used to exchange messages during the establishment of a p2p connection between them. After establishing a direct connection, clients begin to exchange media data with each other.
WebRTC Demo
Let's start with a simple demo. There are 5 simple steps to establish a WebRTC connection.
Detailed example code
1. // Step #1: Getting local video stream and initializing a peer connection with it (both caller and callee)
2.
3. var localStream = null;
4. var localVideo = document.getElementById('localVideo');
5.
6. navigator
7. .mediaDevices
8. .getUserMedia({ audio: true, video: true })
9. .then(stream => {
10. localVideo.srcObject = stream;
11. localStream = stream;
12. });
13.
14. var pc = new RTCPeerConnection({ iceServers: [...] });
15.
16. localStream
17. .getTracks()
18. .forEach(track => pc.addTrack(track, localStream));
19.
20. // Step #2: Creating SDP offer (caller)
21.
22. pc.createOffer({ offerToReceiveAudio: true, offerToReceiveVideo: true })
23. .then(offer => signaling.send('offer', offer));
24.
25. // Step #3: Handling SDP offer and sending SDP answer (callee)
26.
27. signaling.on('offer', offer => {
28. pc.setRemoteDescription(offer)
29. .then(() => pc.createAnswer())
30. .then(answer => signaling.send('answer', answer))
31. });
32.
33. // Step #4: Handling SDP answer (calleer)
34.
35. signaling.on('answer', answer => pc.setRemoteDescription(answer));
36.
37. // Step #5: Exchanging ICE candidates
38.
39. pc.onicecandidate = event => signaling.send('candidate', event.candidate);
40.
41. signaling.on('candidate', candidate => pc.addIceCandidate(candidate));
42.
43. // Step #6: Getting remote video stream (both caller and callee)
44.
45. var remoteVideo = document.getElementById('remoteVideo');
46.
47. pc.onaddstream = event => remoteVideo.srcObject = event.streams[0];
It says the following:
- Take a video and establish a peer connection, transfer some kind of iceServers (it’s not immediately clear what it is).
- Create an SDP offer and send it to signaling, and signaling WebRTC will not implement for you in any way.
- Then you need to make a wrapper for the one coming from signaling, and this is also not part of WebRTC.
- Further exchange some candidates.
- Finally get the remote video stream.
Let’s figure out what is happening there and what we need to implement ourselves.
We look at the picture from the bottom up. There is a WebRTC library that is already built into the browser, supported by Chrome, Firefox, etc. You can build it under Android / iOS and communicate with it through the API and SDP (Session Description Protocol), which describes the session itself. Below I will tell you what is included in it. To use this library in your application, you must establish a connection between subscribers through signaling. Signaling is also your service that you have to write yourself, WebRTC does not provide it.
Further in the article we will discuss the network in order, then video / audio, and at the end we will write our signaling.
WebRTC network or p2p (actually c2s2c)
Setting up a p2p connection seems to be pretty simple.
We have Alice and Bob who want to establish a p2p connection. They take their IP addresses, they have a signaling server to which they are both connected, and through which they can exchange these addresses. They exchange addresses, and oh! They have the same addresses, something went wrong!
In fact, both users are most likely sitting behind Wi-Fi routers and these are their local gray IP addresses. The router provides them with a feature such as Network Address Translation (NAT). How does she work?
You have a gray subnet and an external IP address. You send a packet to the Internet from your gray address, NAT replaces your gray address with white and remembers the mapping: which port it sent from, to which user and which port it matches. When the return packet arrives, it resolves by this mapping and sends it to the sender. Everything is simple.
Below is an illustration of how it looks at my place.
This is my internal IP address and the address of the router (by the way, also gray). If you trace and see the route, we will see my Wi-Fi router: a packet of gray provider addresses and an external white IP. Thus, in fact, I will have two NATs: one on which I am on Wi-Fi, and the other another one from the provider, unless, of course, I bought myself a dedicated external IP address.
NAT is so popular because:
- до сих пор у многих IPv4, и адресов не хватает;
- NAT вроде как защищает сеть;
- это стандартная функция роутера: подключаетесь к Wi-Fi, там сразу есть NAT, он работает.
Therefore, only 3% of users sit with an external IP, while all the rest go through NAT.
NAT allows you to safely go to any white addresses. But if you did not go anywhere, then no one can come to you.
To establish a p2p connection is a problem. In fact, Alice and Bob cannot send packets to each other if they are both behind NAT.
WebRTC has a STUN protocol to solve this problem . It is proposed to deploy a STUN server. Then Alice connects to the STUN server, gets her IP address, sends it to Bob via signaling. Bob also gets his IP address and sends it to Alice. They send packets towards each other and thus break through NAT.
Question: Alice has a specific port open, NAT / Firewall has already been broken through to this port, and Bob is open. They know each other's addresses. Alice tries to send the packet to Bob; he sends the packet to Alice. Do you think they can talk or not?
In fact, you are right in any case, the result depends on the type of NAT pair that users have.
Network address translation
There are 4 types of NAT:
- Full cone NAT;
- Restricted cone NAT;
- Port restricted cone NAT;
- Symmetric NAT
In the basic version, Alice sends a packet to the STUN server, she opens some port. Bob somehow finds out about her port and sends a return packet. If this is Full cone NAT - the easiest one that just maps the external port to the internal port, then Bob will be able to immediately send Alice a packet, establish a connection, and they will talk.
Below is the interaction scheme: Alice from some port sends a packet to the STUN port, STUN answers her with her external address. STUN can respond from any address, if it's Full cone NAT, it will still punch through NAT, and Bob can respond to the same address.
In case of Restricted cone NATeverything is a little more complicated. It remembers not just the port from which you need to map to the internal address, but also the external address that you went to. That is, if you have established a connection only to the IP STUN server, then no one else on the network will be able to answer you, and then Bob’s packet will not reach.
How is this problem solved? In a simple scheme (see illustration below) like this: Alice sends a packet to STUN, he answers her with her IP. STUN can respond to it from any port as long as it is Restricted cone NAT. Bob cannot answer Alice because he has a different address. Alice responds with a packet, knowing Bob's IP address. She opens NAT to Bob, Bob answers her. Hooray, they talked.
A bit more complicated option - Port restricted cone NAT. All the same, only STUN should respond exactly from the port to which it was accessed. Everything will work too.
The most harmful thing is Symmetric NAT .
At first, everything works in exactly the same way - Alice sends the packet to the STUN server, it responds from the same port. Bob cannot answer Alice, but she sends the packet to Bob. And here, despite the fact that Alice sends a packet to port 4444, mapping allocates a new port for her. Symmetric NAT differs in that when each new connection is established, each time it issues a new port on the router. Accordingly, Bob is beating in the port from which Alice went to STUN, and they can not connect.
In the opposite direction, if Bob has an open IP address, Alice may just come to him and they will establish a connection.
All options are collected in one table below.
It shows that almost everything is possible except when we try to establish connections through Symmetric NAT with Port restricted cone NAT or Symmetric NAT on the other end.
As we found out, p2p is priceless for us in terms of latency, but if it was not possible to install it, then WebRTC offers us a TURN server. When we realized that p2p will not install, we can just connect to TURN, which will proxy all traffic. However, at the same time you will pay for traffic, and users may have some additional delays.
Practice
Google has free STUN servers. You can put them in the library, it will work.
TURN servers have credential (login and password). Most likely, you will have to raise your own, it is rather difficult to find free.
Examples of free STUN servers from Google:
- stun: stun.l.google.com: 19302
- stun: stun1.l.google.com: 19302
- stun: stun2.l.google.com: 19302
- stun: stun3.l.google.com: 19302
And a free TURN server with passwords: url: 'turn: 192.158.29.39: 3478? Transport = udp', credential: 'JZEOEt2V3Qb0y27GRntt2u2PAYA =', username: '28224511: 1379330808 ′.
We use coturn .
As a result, 34% of traffic passes through the p2p connection, everything else is proxied through the TURN server.
What else is interesting in the STUN protocol?
STUN allows you to determine the type of NAT.
Link on the slide
When sending a packet, you can indicate that you want to receive a response from the same port or ask STUN to reply from another port, from a different IP, or even from a different IP and port. Thus, for 4 queries to the STUN server, you can determine the type of NAT .
We counted the types of NAT and we got that almost all users have either Symmetric NAT or Port restricted cone NAT. Hence, it turns out that only a third of users can establish a p2p connection.
You may ask why I'm telling you all this if you could just take the STUN from Google, put it into WebRTC, and it seems like everything will work.
Because you can actually determine the type of NAT yourself.
This is a linkto a Java application that does nothing tricky: it just pings different ports and different STUN servers, and looks at which port it sees in the end. If you have Open Full cone NAT, then the STUN server will have the same port. With Restricted cone NAT, you will have different ports for each STUN request.
With Symmetric NAT, it turns out like this in my office. There are completely different ports.
But sometimes there is an interesting pattern that for each connection, the port number increases by one.
That is, many NATs are configured so that they increase or decrease the port by a constant. This constant can be found and thus break through Symmetric NAT.
Thus we break through NAT - we go to one STUN server, to another, look at the difference, compare and try again to give our port already with this increment or decrement. That is, Alice is trying to give Bob her port, already adjusted for a constant, knowing that next time it will be just that.
So we managed to weld another 12% peer-to-peer .
In fact, sometimes external routers with the same IP behave the same. Therefore, if you collect statistics and if Symmetric NAT is a feature of the provider, and not a feature of the user's Wi-Fi router, then the delta can be predicted, immediately send it to the user so that he uses it and does not spend too much time determining it.
CDN Relay or what to do if you could not establish a P2P connection
If we still use the TURN server and work not in p2p, but in real mode, passing all the traffic through the server, we can still add a CDN. Unless, of course, you have a playground. We have our own CDN sites, so for us it was quite simple. But it was necessary to determine where it is better to send a person: to a CDN site or, say, to a channel to Moscow. This is not a very trivial task, so we did this:
- Accidentally issued to some users of the Moscow site, some - remote.
- We collected statistics on the IP of the user, on the servers and on the characteristics of the network.
- By maxMind, we grouped the subnets, looked at the statistics and were able to understand by IP which user had the closest TURN server for the connection.
There is a CDN in Novosibirsk. If everything works for you through Moscow, then the 99th percentile of RTT is 1.3 seconds. Through CDN, everything works much faster (0.4 seconds).
Is it always better to use a p2p connection and not use a server? An interesting example is the two Krasnoyarsk providers Optibyte and Mobra (names may have changed). For some reason, the connection between them on p2p is much worse than through MSK. Probably they are not friends with each other.
We analyzed all such cases, randomly sending users to p2p or via MSK, collected statistics and built predictions. We know that statistics need to be updated, so for some users we specially establish different connections to check if something has changed in the networks.
We measured such simple characteristics as round time, packet loss, bandwidth - it remains to learn how to compare them correctly.
How to understand which is better: 2 Mbit / s Internet, 400 ms RTT and 5% packet Loss or 100 Kbit / s, 100 ms delay and scanty packet loss?
There is no exact answer, the assessment of video call quality is very subjective. Therefore, after the end of the call, we asked users to evaluate the quality in asterisks and set the constants according to the results. It turned out that, for example, RTT is less than 300 ms - it doesn’t matter anymore, bitrate is more important.
Higher user ratings on Android and iOS. It is seen that iOS users are more likely to put a unit and more often five. I don’t know why, probably, the specifics of the platform. But we pulled the constants along them, so that we had, as it seems to us, good.
Back to our outline for the article, we are still discussing the network.
What does the connection setup look like?
We send STUN and TURN servers to PeerConnection (), a connection is established. Alice finds out her IP, sends it to signaling; Bob learns about Alice's IP. Alice gets Bob's IP. They exchange packets, maybe break through NAT, maybe set TURN and communicate.
In the 5 steps of establishing the connection that we discussed earlier, we figured out the servers, figured out where to get them, and that ICE candidates are external IP addresses that we exchange through signaling. Internal IP addresses of clients, if they are within the range of one Wi-Fi, can also be tried to break through.
Let's move on to the part of the video.
Video and audio
WebRTC supports a certain set of video and audio codecs, but you can add your own codec there. Basically supported by H.264 and VP8 for video . VP8 is a software codec, therefore it consumes a lot of battery. H.264 is not available on all devices (it is usually native), so the default priority is on VP8.
Inside SDP (Session Description Protocol), there is codec negotiation: when one client sends a list of its codecs, the other sends its own with priority, and they agree on which codecs they will use for communication. If desired, you can change the priority of the VP8 and H.264 codecs, and due to this, you can save battery on some devices, where 264 is native. Here is an exampleof how this can be done. We did this, it seemed to us that users did not complain about the quality, but at the same time the battery charge was consumed much less.
For audio, WebRTC has OPUS or G711 , usually all OPUS always work, nothing needs to be done with it.
Below are temperature measurements after 10 minutes of use.
It is clear that we tested different devices. This is an example of an iPhone, and on it, the OK application uses the battery the least, because the temperature of the device is the least.
The second thing that you can enable if you use WebRTC is to automatically turn off the video when the connection is very poor .
If you have less than 40 Kbps, the video will turn off. You just need to check the box when creating the connection, the threshold value can be configured through the interface. You can also set the minimum and maximum starting current bitrate.
This is a very useful thing. If when you establish a connection, you know in advance what bitrate you are expecting, you can transfer it, the call will start from it, and you will not need to adapt the bitrate. Plus, if you know that you often have packet loss or bandwidth drawdowns on your channel, then the maximum value can also be limited.
WhatsApp works with very soapy videos, but with small delays, as it aggressively compresses the bitrate from above.
We collected statistics using MaxMind and mapped it.
This is an approximate starting quality that we use for calls in different regions of Russia.
Signaling
You will most likely have to write this part if you want to make calls. There are all sorts of pitfalls. Recall how it looks.
There is an application with signaling that connects and exchanges with SDP, and the SDP below is the interface to WebRTC.
This is what simple signaling looks like:
Alice calls Bob. It connects, for example, via a web-socket connection. Bob receives a push on his mobile phone or browser, or in some kind of open connection, connects via a web-socket and after that the phone starts ringing in his pocket. Bob picks up the phone, Alice sends him his codecs and other WebRTC features that she supports. Bob answers her the same, and after that they exchange the candidates they saw. Hooray, call!
It all looks pretty long. First, until you establish a web-socket connection, until push comes and everything else, Bob’s phone will not ring in his pocket. Alice will wait all the time, think where Bob is, why he does not pick up the phone. After confirmation, it all takes seconds, and even on good connections it can be 3-5 seconds, and on bad connections - all 10.
Something needs to be done with this! You will tell me that everything can be done very simply.
If you already have an open connection for your application, you can immediately send a push to establish a connection, connect to the desired signaling server and immediately start making calls.
Then another optimization. Even if the phone is still ringing in your pocket and you haven’t picked up the phone, you can actually exchange information about the supported codecs, external IP addresses, start sending empty video packets, and in general everything will be warmed up. Once you pick up the phone, everything will be great.
We did so, and it seemed that everything was cool. But no.
The first problem is that users often cancel the call. They click “Call” and immediately cancel. Accordingly, the push goes to the call, and the user disappears (he has lost the Internet or something else). Meanwhile, someone's phone rings, he picks up the phone, and he is not expected there. Therefore, our primitive optimization in order to start calling as quickly as possible does not really work.
With a quick call cancellation, there is a second harmful thing. If you generate the ID of your conversation on the server, then you need to wait for a response. That is, you create a call, get an ID, and only after that you can do whatever you want: send packets, exchange, including cancel the call. This is a very bad story, because it turns out that until response has arrived, you cannot actually cancel anything from the client. Therefore, it is best to generate some kind of ID on the client such as a GUID and say that you started the call. People often do this: they called, canceled and immediately called again. To prevent this from getting messed up, do a GUID and submit it.
It seems to be nothing, but there is another problem. If Bob has two phones, or somewhere else the browser remains open, then our whole magic scheme in order to exchange packets, establish a connection does not work if he suddenly answered from another device.
What to do? Let's go back to our basic simple slow signaling scheme and optimize it, send the push a little earlier. The user will begin to connect faster, but this will save some pennies.
What to do with the longest part after he picked up the phone and started the exchange?
You can do the following. It’s clear that Alice already knows all her codecs and can send them to both of Bob’s phones. She can resolve all her IP addresses and also send them to signaling, which will keep them in her queue, but will not send to any of the clients so that they can start connecting to her ahead of time.
What can Bob do? Having received the offer, he can see what codecs were there, generate his own, write what he has, and send it too. But Bob has two phones, and they have different codec negotiation, so signaling will keep it all for himself and will wait in line until he finds out on which device they will pick up the phone. Candidates will also generate both devices and send them to signaling.
Thus, signaling has one message queue from Alice and several message queues from Bob on different devices. He stores all of this, and as soon as they pick up the phone on one of these devices, he simply throws the whole set of packages already prepared.
It works pretty fast. We managed with such an algorithm to reach characteristics similar to Google Duo and WhatsApp.
You can probably come up with something even better. For example, keep several queues not for signaling, but send them to the client, and then say which number, but, most likely, the gain will be very small. We decided to stop there.
What other problems await you?
There is such a thing as a return call: one calls another, the other rings back. It would be nice if they didn’t try to compete - at the signaling level add a command that says that if someone came second, you need to switch to the mode when you simply accept the call and immediately pick up the phone.
It happens that the network disappears, messages are lost, so everything needs to be done through queues. That is, you must have a dispatch queue on the client. Messages that you send from the client should be deleted from the queue only after the server has confirmed that it has processed them. The server also has a queue for sending, and also with confirmation.
So all this is implemented with us internally, taking into account that we have a 24/7 service, we want to be able to lose data centers, shift and update the version of our software.
Link on the slide to the video and link to the text version
Clients connect via web-socket to some load balancer, it sends to signaling servers in different data centers, different clients can come to different servers. At Zookeeper, we make a Leader Election, which defines the signaling server that now manages this conversation. If the server is not the leader of this conversation, he simply throws all messages to another.
Next we use some distributed storage, we have NewSQL on top of Cassandra. It really doesn't matter what to use. You can save the status of all the queues that are on signaling anywhere so that if the signaling server disappears, the power goes out or something else happens, the Leader Election works on Zookeeper, another server that becomes the leader gets up, restores all queues from the database messages and start sending.
The algorithm looks like this:
- The client sends some message, let's say its external IP to signaling
- Signaling accepts, writes to the database.
- After he understands that everything has come, he replies that he received this message.
- The client removes this message from its queue.
All packages are provided with unique numbers so as not to be confused.
From the point of view of the database, we use an add-on over Cassandra, which allows you to make transactions on it (the video is just about that).
So, you have learned:
- what are iceServers and how to transfer them;
- what is the Session Description Protocol;
- that it must be generated and sent to the other side;
- that it must be taken from signaling and transferred to WebRTC on the other side, exchanged with external IP addresses;
- and start sending videos!
We got:
- calls with delay below the market average;
- we did not heat the phones very much;
- response time in our application at the top level.
Wow!
Security Man in the middle attack for WebRTC
Let's talk about man in the middle attack for WebRTC. In fact, WebRTC is a very difficult protocol in that it is based on RTP, which is still 1996, and SDP came in 1998 from SIP.
At the bottom, a huge list is a bunch of RFCs and other RTP extensions that make RTP WebRTC.
The first two interesting RFCs on the list - one of them adds an audio level to packets, and the other says that it is unsafe to transmit the audio level in packets openly, and encrypts them. Accordingly, when you exchange SDP, it is important for you to know which set of extensions the clients support. There are even several congestion algorithms, several algorithms for recovering lost packets and just about everything.
The history of WebRTC was complicated. The first draft release was released in 2011, in 2013 Firefox supported this protocol, then it began to be built on iOS / Android, in 2014 Opera. In general, it developed for many, many years, but still does not solve one interesting problem.
When Alice and Bob connect to signaling, then they use this channel, establish DTLS Handshake and secure connection. Everything is great, but if it turned out to be not our signaling, then, in principle, the person in the middle has the opportunity to "make money" with both Alice and Bob, to block all traffic and eavesdrop on what is happening there.
If you have a service with high trust, then, of course, you definitely need to use HTTPS, WSS, etc. There is another interesting solution - ZRTP, it is used, for example, by Telegram.
Many have seen emoji on Telegram when a connection is established, but few use it. In fact, if you tell a friend what emojis you have, he will verify that he has exactly the same, then you have absolutely guaranteed a secure p2p connection.
How it works?
Inside all these protocols, the usual Diffie-Hellman algorithm is initially used. Alice generates some numbers, sends them all but one to Bob. Bob also generates a random number and sends it to Alice. As a result of this exchange, Alice and Bob get a certain large number K, about which the man in the middle who listened to their entire channel knows nothing and can not guess at all.
When Dave appears between Alice and Bob, they exchange the same keys with him, and they get K 1and K 2, respectively. There is no way to track the presence of this person in the middle. Then such a trick is applied. These keys K 1 and K 2 will definitely be different for Dave, since Alice and Bob generate their keys randomly. We just take some hash from K 1 and K 2 and display it in the emoji: in an apple, in a pear - in anything, and people simply call the pictures they see with their voice. Since you can identify each other by voice, and if these pictures are different, then there is someone between you and maybe he is listening to you.
results
- We “mined” NAT type and broke through symmetric NAT.
- Statistically evaluated, which is better: p2p or relay, quality, CDN; and improved the quality of the stars from the point of view of users.
- Changed the priorities of the codecs, saved a little battery.
- Minimized delay on signaling.
The graph shows that at first there were old calls to RTMFP, then when we switched to WebRTC, there is a slight failure, and then the peak rises. Not everything worked out right away! As a result, now the number of calls held has increased by 4 times.
Simple instruction
If you do not need all this, there is a very simple instruction:
- download the code from WebRTC ( https://webrtc.org/native-code/development/ ), assemble it under iOS / Android, it already exists in all browsers;
- deploy coturn ( https://github.com/coturn/coturn );
- write signaling.
Everything will ring, and ringing is pretty good.
Listen to answers to questions after the report
In a week, Alexander Tobol will speak at HighLoad ++ with a report on the architecture of a scalable fault-tolerant 4K video streaming platform.
What other topics will be discussed, see the schedule . Although it is already clear, in 19 streams (10 for reports and 9 for mitaps and master classes) there is everything that is at least somehow connected with high loads. Be sure to come if your services do not have hundreds, but millions of users.