We calculate by IP: how to deal with spam on a social network
Spamming on social networks and instant messengers is a pain. Pain for both honest users and developers. How they fight it in Badoo, said Mikhail Ovchinnikov on Highload ++, then the text version of this report.
About the speaker: Mikhail Ovchinnikov has been working at Badoo and has been anti-spam for the past five years.
Badoo has 390 million registered users (data for October 2017). If we compare the size of the service’s audience with the population of Russia, we can say that, according to statistics, every 100 million people are protected by 500 thousand police officers, and in Badoo, only one Antispam employee protects every 100 million users from spam. But even such a small number of programmers can protect users from various troubles on the Internet.
We have a large audience, and it can have different users:
Who have to fight
Spam can be different, often it cannot be distinguished at all from the behavior of an ordinary user. It can be manual or automatic - bots that are engaged in automatic mailing also want to get to us.
This, of course, is a joke. The article will not have information that will simplify the life of spammers.

So who do we have to fight with? These are spammers and scammers.
Spam appeared a long time ago, from the very beginning of the development of the Internet. In our service, spammers, as a rule, try to register an account by uploading a photo of an attractive girl there . In the simplest form, they begin to send out the most obvious types of spam - links.
A more complicated option is when people don’t send anything explicit, don’t send any links, don’t advertise anything, but lure the user to a place more convenient for them, for example, instant messengers : Skype, Viber, WhatsApp. There they can, without our control, sell anything to the user, promote, etc.
But spammers are not the biggest problem . They are obvious and easy to fight. Much more complex and interesting characters are scammers who pretend to be another person and try to deceive users in all the ways that are on the Internet.
Of course, the actions of both spammers and scammers are not always very different from the behavior of ordinary users who also do this sometimes. There are many formal signs in both of those that do not allow a clear line to be drawn between them. This is almost never possible.
How to deal with spam in the Mesozoic era

First, I will show you the simplest methods of fighting spam that everyone can implement for themselves. Then I will tell you in detail about the more complex systems that we developed using machine learning and other heavy artillery.
The easiest ways to deal with spam
Manual moderation
In any service, you can hire moderators who will manually view the user's content and profile, and decide what to do with this user. Typically, this process looks like finding a needle in a haystack. We have a huge number of users, moderators less.

In addition to the fact that moderators obviously need a lot, you need a lot of infrastructure. But, in fact, the most difficult thing is another - a problem arises: how, on the contrary, protect users from moderators.
It is necessary to make sure that moderators do not get access to personal data. This is important because moderators can theoretically also try to do harm. That is, we need antispam for antispam, so that moderators are under tight control.
Obviously, you cannot verify all users in this way. NonethelessIn any case , moderation is needed , because any systems in the future need training and a human hand that will determine what to do with the user.
Statistics collection
You can try using statistics - to collect various parameters for each user.
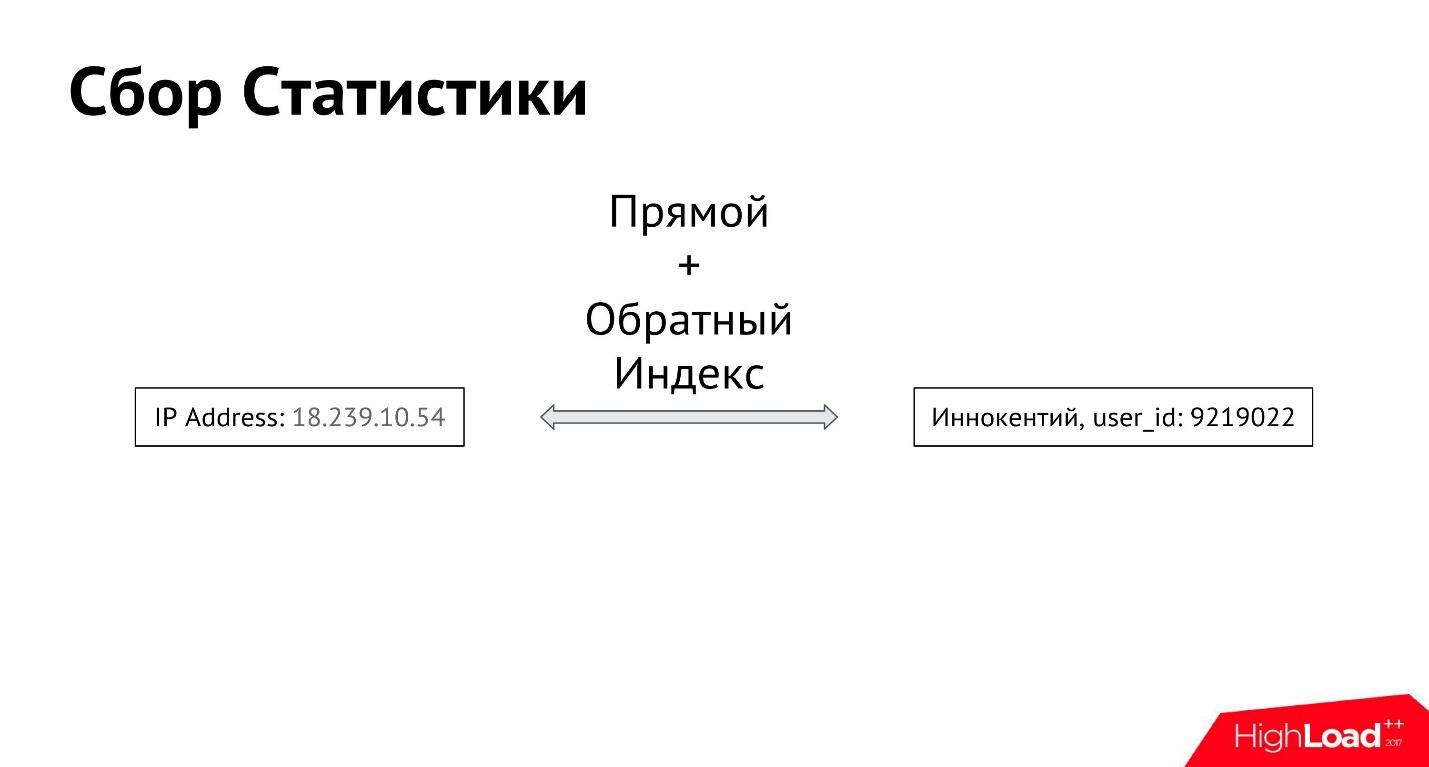
User Innokenty logs in from his IP address. The first thing we do is log in which IP address it entered. Next, we build a forward and reverse index between all IP addresses and all users, so that you can get all the IP addresses from which a specific user logs in, as well as all users who log in from a specific IP address.
This way we get the connection between the attribute and the user. There can be a lot of such attributes. We can begin to collect information not only about IP-addresses, but also photos, devices from which the user came in - about everything that we can determine.
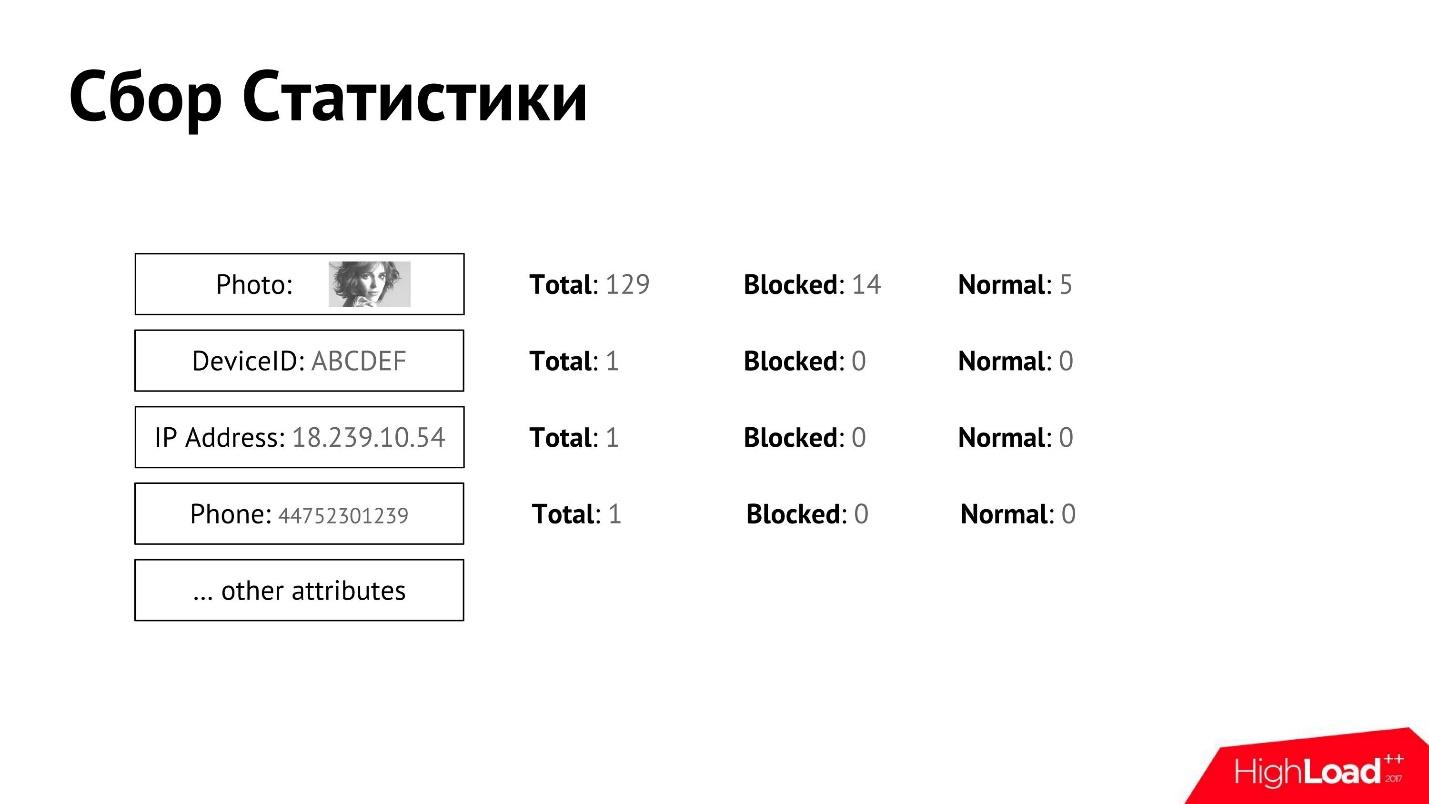
We collect such statistics and associate it with the user. For each of the attributes we can collect detailed counters.
We have a manual moderation that decides which user is good, which is bad, and at some point the user is blocked or recognized as normal. We can separately obtain data for each attribute, how many total users, how many of them are blocked, how many are recognized as normal.
Having such statistics for each of the attributes, we can roughly determine who the spammer is, who is not.

Let's say we have two IP addresses - 80% of spammers on one and 1% on the second. Obviously, the first is much more spammed, you need to do something with it and apply some kind of sanctions.
The simplest thing is to write heuristic rules.. For example, if blocked users are more than 80%, and those who are considered normal - less than 5%, then this IP address is considered bad. Then we ban or do something else with all users with this IP address.
Collection of statistics from texts
In addition to the obvious attributes that users have, you can also do text analysis. You can automatically parse user messages, isolate from them everything that is related to spam: mention messengers, phones, email, links, domains, etc., and collect exactly the same statistics from them.

For example, if a domain name was sent in messages by 100 users, of which 50 were blocked, then this domain name is bad. It can be blacklisted.
We will receive a large amount of additional statistics for each of the users based on message texts. No machine learning is needed for this.
Stop words
In addition to the obvious things - telephones and links - you can extract phrases or words from the text that are especially common for spammers. You can maintain this list of stop words manually.
For example, on the accounts of spammers and scammers, the phrase: “There are a lot of fakes” is often found. They write that they are generally the only ones here who are set up for something serious, all the other fakes, which in no case can be trusted.
On dating sites according to statistics, spammers more often than ordinary people use the phrase: "I am looking for a serious relationship." It is unlikely that an ordinary person will write this on a dating site - with a probability of 70% this is a spammer who is trying to lure someone.
Search for similar accounts
With statistics on attributes and stop words found in texts, you can build a system to search for similar accounts. This is necessary to find and ban all accounts created by the same person. A spammer who has been blocked can immediately register a new account.
For example, a user Harold logs in, logs on to the site and provides his rather unique attributes: IP address, photo, stop word that he used. Maybe he even signed up with a fake Facebook account.
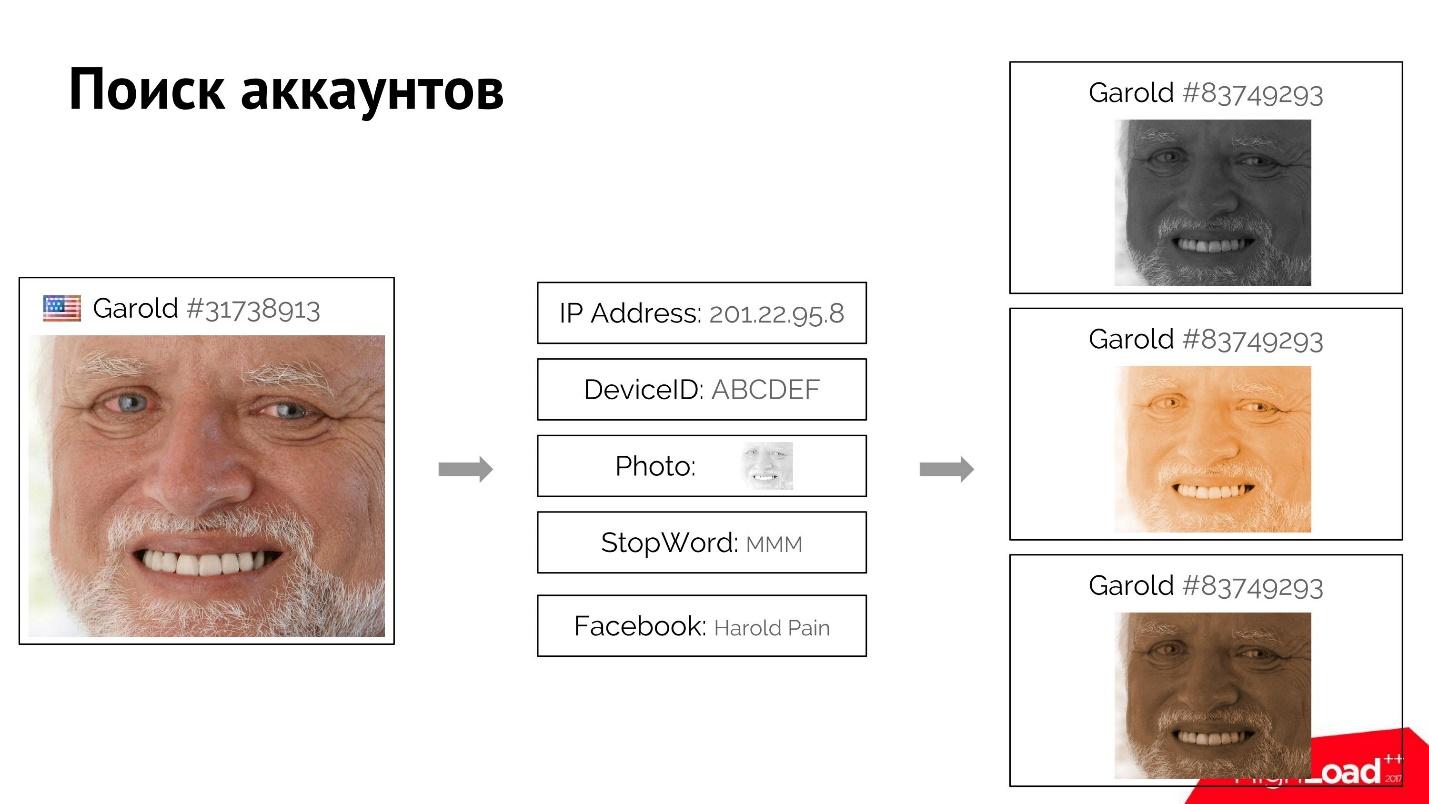
We can find all users similar to him who have one or more of these attributes matching. When we know for sure that these users are connected, using the very forward and reverse index, we find the attributes, and by them of all users, and rank them. If, let's say the first Harold, we block, then the rest is also easy to "kill" using this system.
All the methods that I just described are very simple: it’s easy to collect statistics, then it’s easy to search for users using these attributes. But, despite the ease, with the help of such simple things - simple moderation, simple statistics, simple stop words - they manage to defeat 50% of spam .
In our company, for the first six months of work, the Antispam department defeated 50% of spam. The remaining 50%, as you know, are much more complicated.
How to make life difficult for spammers
Spammers are inventing something, trying to complicate our lives, and we are trying to fight them. This is an endless war. There are much more of them than us, and at each step we come up with their own multi-path.
Unfortunately, we are not invited to such conferences.
But we can make life difficult for spammers. For example, instead of directly showing the user the window “You are locked”, you can use the so-called Stealth banning - this is when we do not say to the user that he is banned. He should not even suspect it.

The user gets into the sandbox (Silent Hill), where everything seems to be real: you can send messages, vote, but in fact it all goes into the void, into the fog. No one will ever see and hear, no one will receive his messages and votes.
We had a case when one spammer spammed for a long time, promoted his bad goods and services, and six months later decided to use the service as intended. He registered his real account: real photos, name, etc. Naturally, our search engine for similar accounts quickly figured it out and put it in Stealth ban. After that, he wrote for six months in the void that he was very lonely, no one answered. In general, he poured out his whole soul to the fog of Silent Hill, but did not receive any answer.
Spammers, of course, are not fools. They are trying somehow to determine that they got into the sandbox and that they were blocked, quit the old account and find a new one. We sometimes even get the idea that it would be nice to send several of these spammers to the sandbox together, so that there they would sell to each other everything they want and have fun as you like. But while we have not reached this point, we are devising other methods, for example, photo and telephone verification.

As you know, it is difficult for a spammer who is a bot and not a person to pass verification by phone or photo.
In our case, verification by photo looks like this: the user is asked to take a picture with a certain gesture, the resulting photo is compared with photos that are already loaded in the profile. If the faces are the same, then most likely the person is real, uploaded his real photos and can be left behind for some time.
It’s not easy for spammers to pass this test. We even got a small game inside the company called Guess Who the Spammer is. Given four photos, you need to understand which of them is a spammer.
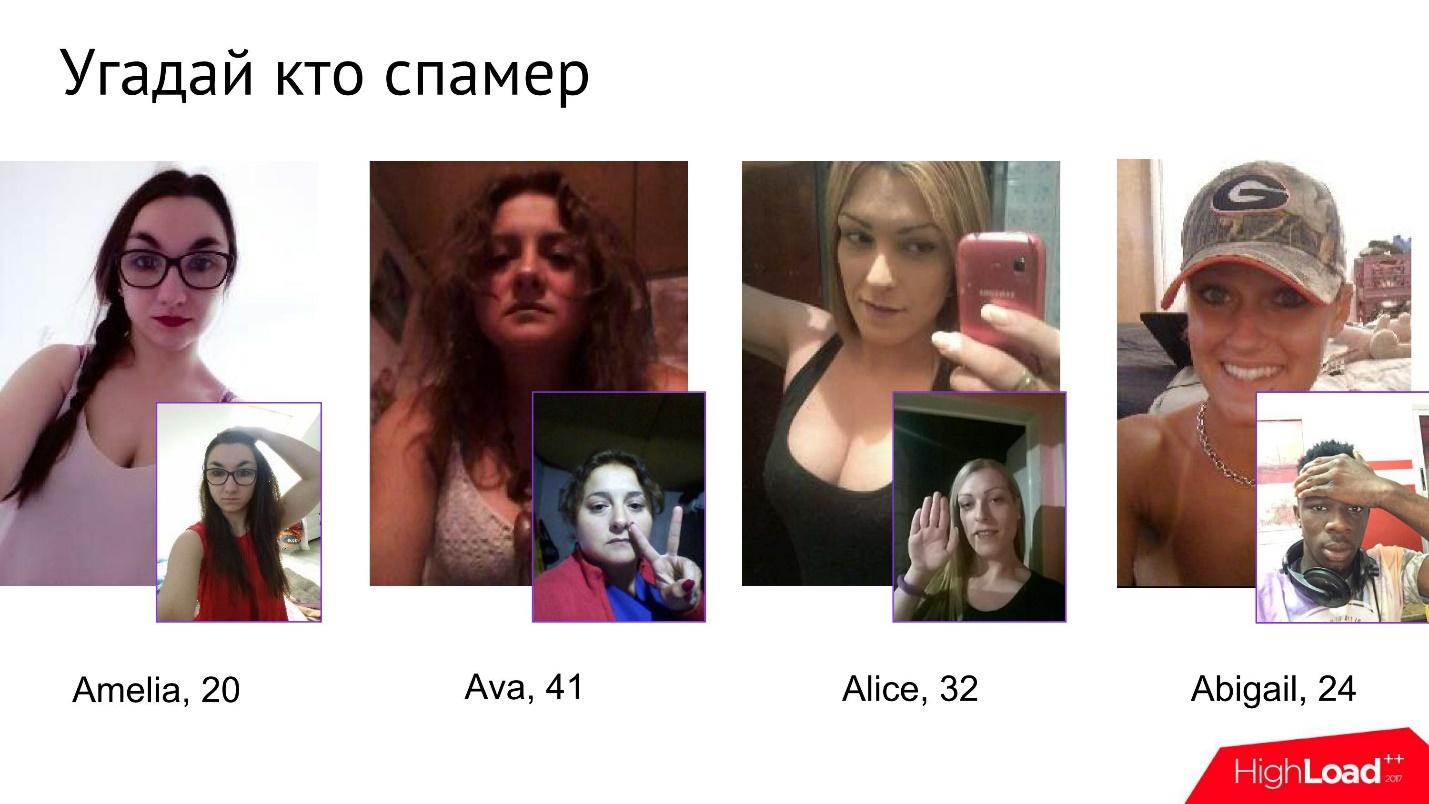
At first glance, these girls look completely harmless, but as soon as they begin to undergo photo verification, at some point it becomes clear that one of them is completely not what she claims to be.
In any case, spammers have a hard time fighting photo verification. They really suffer, try to somehow get around it, deceive, and demonstrate all their photoshop skills.

Spammers are doing everything they can, and sometimes they think, probably, that all this is completely processed by some incredible modern technologies that are so poorly constructed that they are so easy to fool.
They do not know that each photo is then again manually checked by moderators.
No time!
In fact, despite the fact that we come up with various ways to make life difficult for spammers, there is usually not enough time, because anti-spam should work instantly. He must find and neutralize the user before he begins his negative activity.
The best thing that can be done is to determine at the registration stage that the user is not very good. This can be done, for example, using clustering.
User clustering
We can collect all possible information right after registration. We still do not have any devices with which the user logs in, nor photographs, there are no statistics. We have nothing to send him for verification, he has not done anything suspicious. But we already have primary information:
All of this information can be used to locate user clusters. We use the simple and popular K-means clustering algorithm . It is perfectly implemented everywhere, it is supported in any MachineLearning libraries, it is perfectly parallel, it works quickly. There are streaming versions of this algorithm that allow you to distribute users on clusters on the fly. Even in our volumes, all this works quite quickly.
Having received such user groups (clusters), we can do any actions. If users are very similar (the cluster is highly connected), then most likely this is mass registration, it must be stopped immediately. The user has not had time to do anything yet, just clicked the “Register” button - and that’s all, he already got into the sandbox.
Statistics can be collected on clusters - if 50% of the cluster is blocked, then the remaining 50% can be sent for verification, or individually moderated all clusters manually, look at the attributes by which they coincide, and make a decision. Based on such data, analysts can identify patterns.
Patterns
Patterns are sets of the simplest user attributes that we immediately know. Some of the patterns actually work very effectively against certain types of spammers.
For example, consider a combination of three completely independent, fairly common attributes:
These three attributes, seemingly separately representing nothing of themselves, together give the likelihood that this is a spammer, almost 90%.
You can extract such patterns as many as you like for each type of spammer. This is much more efficient and easier than manually viewing all accounts or even clusters.
Text clustering
In addition to clustering users by attributes, you can find users who write the same texts. Of course, this is not so simple. The fact is that our service works in so many languages. Moreover, users often write with abbreviations, slang, sometimes with errors. Well, the messages themselves are usually very short, literally 3-4 words (about 25 characters).
Accordingly, if we want to find similar texts among the billions of messages that users write, we need to come up with something unusual. If you try to use classical methods based on the analysis of morphology and true honest processing of the language, then with all these restrictions, slangs, acronyms and a bunch of languages, this is very difficult.
You can do a little more simply - apply the n-gram algorithm. Each message that appears is broken down into n-grams. If n = 2, then these are bigrams (pairs of letters). Gradually, the entire message is divided into pairs of letters and statistics are collected, how many times each bigram occurs in the text.

You can not stop at bigrams, but add trigrams, skipgrams (statistics on letters after 1, 2, etc. letters). The more information we get, the better. But even bigrams already work quite well.
Then we get a vector from the bigrams of each message whose length is equal to the square of the length of the alphabet.
It is very convenient to work with this vector and cluster it, because:
But that is not all. Unfortunately, if we simply collect all the messages that are similar in frequency to the bigrams, we get messages that are similar in frequency to the bigrams. However, they do not have to be in fact at least somewhat similar in meaning. Often there are long texts in which the vectors are very close, almost the same, but the texts themselves are completely different. Moreover, starting from a certain length of text, this clustering method will generally stop working, because the frequencies of the bigrams are equal.

Therefore, you need to add filtering. Since the clusters already exist, they are quite small, we can easily do filtering inside the cluster using Stemming or Bag of Words. Inside a small cluster, you can literally compare all messages with everyone, and get the cluster in which there are guaranteed to be the same messages, which coincide not only in statistics, but also in reality.
So, we have done clustering - and yet, for us (and for clustering) it is very important to know the truth about the user. If he is trying to hide the truth from us, then we need to take some action.
Information hiding
A typical type of information hiding is VPN, TOR, Proxy, and Anonymizers. The user uses them, trying to pretend that he is from America, although in fact he is from Nigeria.
In order to overcome this problem, we took the most famous textbook “How to calculate by IP”.

With the help of this tutorial, we wrote a VPN classifier - that is, a classifier that receives an IP address as input and says whether this IP address is a VPN, Proxy or not.
To implement the classifier, we need several ingredients:
Taking all this information, you can build a classifier that will eventually say whether the IP address is VPN or not.
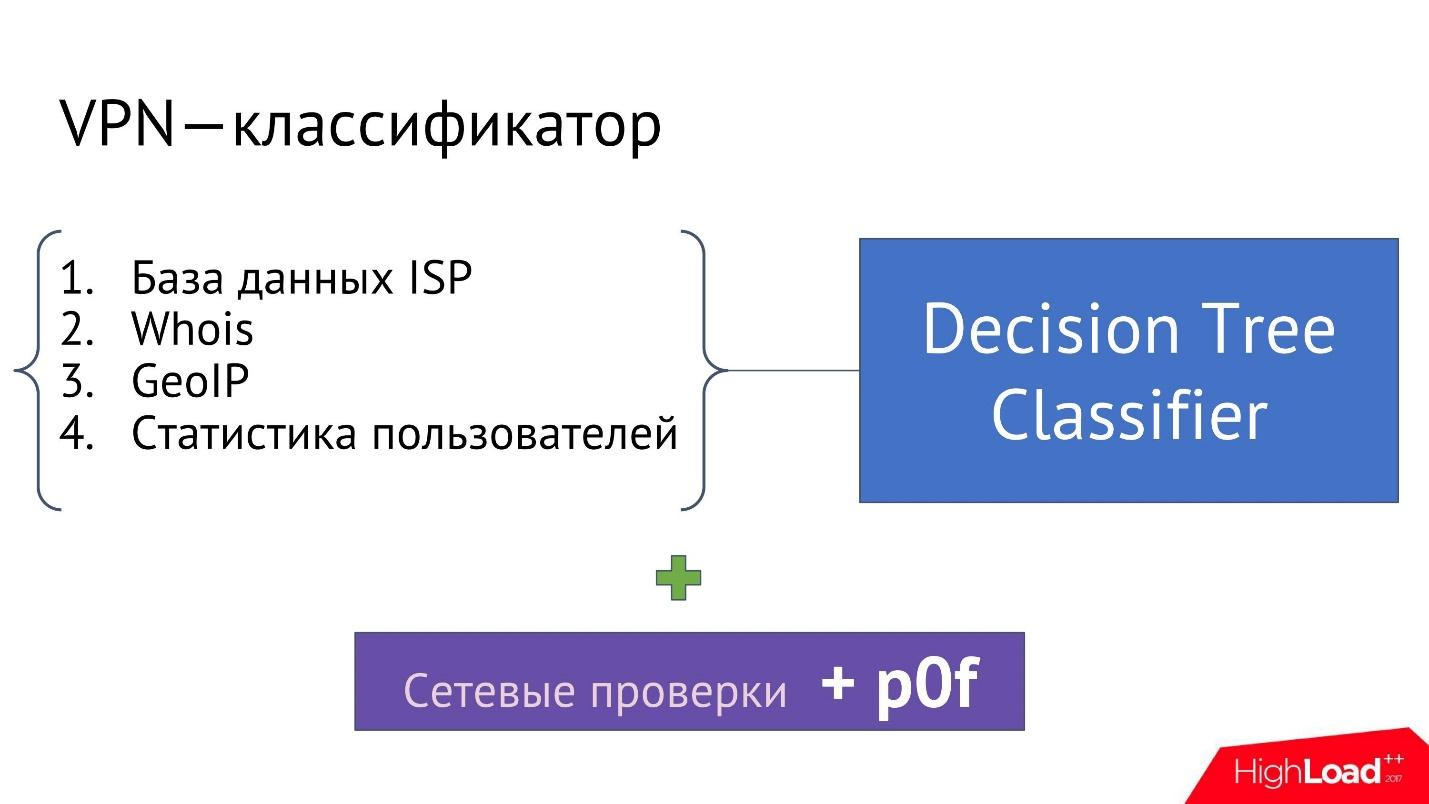
We chose decision trees because they are very good at finding the very patterns — specific combinations of providers, countries, statistics, etc., which ultimately make it possible to determine that the IP address is a VPN.
Of course, this data is very general. No matter how well we train the classifier, no matter how hard we try to use advanced techniques, it still will not work with 100% accuracy. Therefore, additional network checks are a key factor here.
Once we have received information that the IP address supposedly belongs to the VPN, we can actually check what this IP address is. You can try to connect to it, see what ports are open on it. If there is a SOCKS-proxy, you can try to open a connection and determine exactly whether this IP address is anonymized or not.
In addition, there is still a wonderful technology, the implementation of which is still in our plans, which is called p0f . This is a utility that makes fingerprinting traffic at the network level and allows you to immediately determine what is on the other side of the connection: regular user client, VPN client, Proxy, etc. The utility contains a large set of patterns that define all this.
Most suspicious action
After we wrote various systems, clusters, classifiers, collected statistics, we thought: what can the most suspicious user do on our service? To register is already suspicious! If the user has registered, then we immediately begin to look at him with a very sly squint and analyze him in every possible way, trying to understand what he meant.
We often have an internal desire - and not to ban us all immediately after registration? This would greatly facilitate the work of the Antispam department. We can immediately drink tea 2 times longer, and we will not have any problems.
In order to stop such thoughts not only from ourselves, but also from the systems that we write, and not to ban all good users, especially immediately after registration, we are forced to create systems that struggle with our other systems, that is, they organize their own limitations.

How can you limit yourself so as not to ban good users, not to make mistakes and not to get confused?
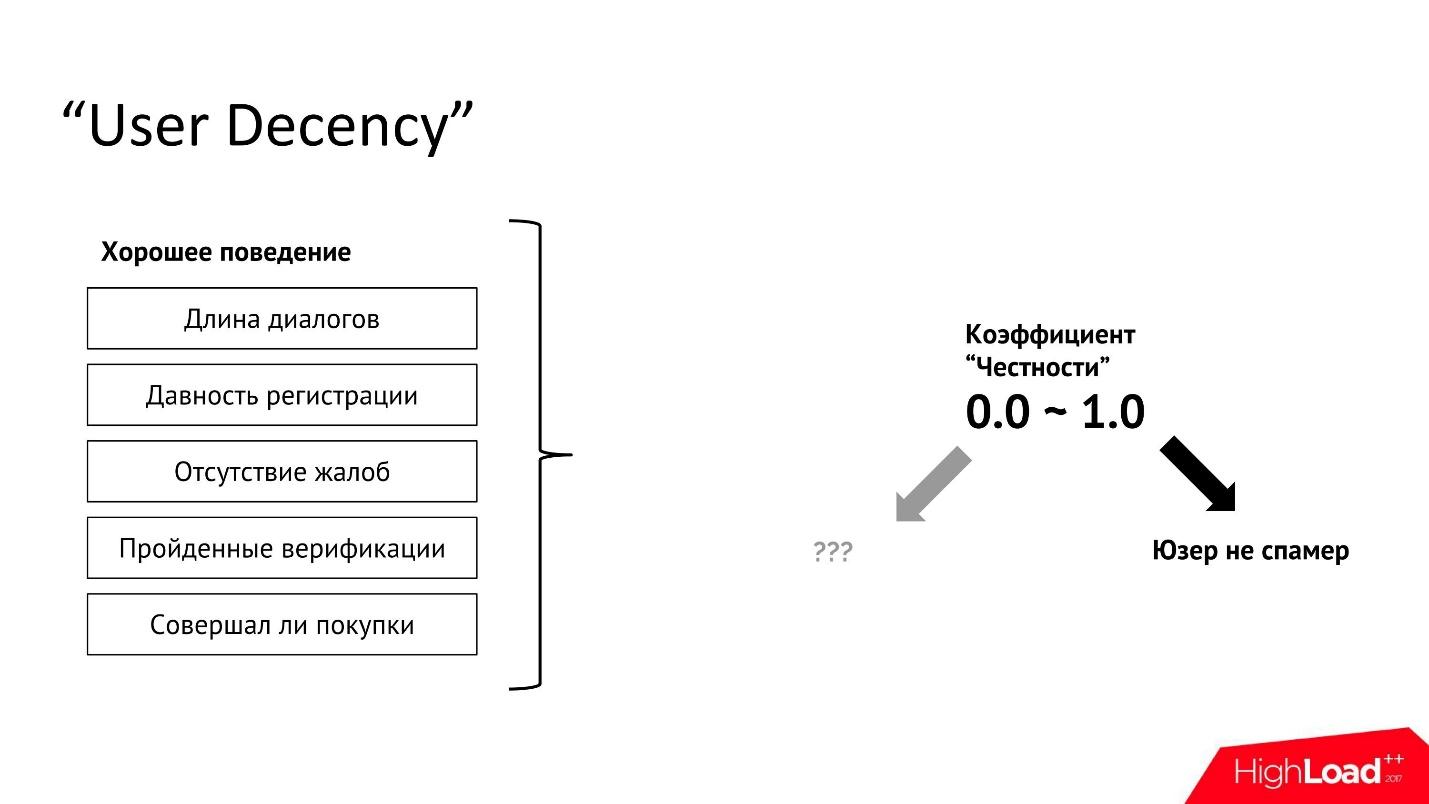
"User Decency"
We classify users by honesty - we will make an isolated model that will take all the positive characteristics of the user and do an analysis on them.
An example of the characteristics of a “good” behavior:
On a dataset of all individual exceptionally good user characteristics, a classifier or regression can be trained. We have a simple logistic regression . This model is easy to port, because it is just a set of coefficients, and it is easy to implement in any system and in any language, it is very well transferred between platforms and infrastructures.
Taking the user and driving him through this model, we get a coefficient that we call the “ honesty coefficient ”. If it is zero, then, as a rule, this means that we have almost no information about this user. Then we do not get any additional information from the classification.
If the user’s honesty coefficient is 1, then most likely the user is a good guy, we won’t touch him - there will be no verification and no ban will come to him.
Such an isolated thing allows us to prevent many common mistakes.
False positive
The second thing you can do is look for various false positives. It happens that users accidentally come from the same IP address. For example, two are sitting in an Internet cafe, even their computer may be the same. The browser, fingerprint, which we count on the computer, on the browser, on the device - everything will absolutely coincide, and we can assume that both users are spammers, although it is not a fact that they are somehow connected.
Another example: a good user in a dialogue with a spammer can ask again in response to an advertisement: “Hey, I didn’t understand what Pornhub is — why are you advertising it to me?” At such a moment, the system sees that the user has written a stop word and can consider that this user is a spammer and should be banned as soon as possible.
Therefore, we have to search for anomalies. We take users, their attributes, and look for those users among them who got into a bad company by accident.
For example, take the stop word “Pornhub”. For each stop word, we have statistics for all users who have ever used it.
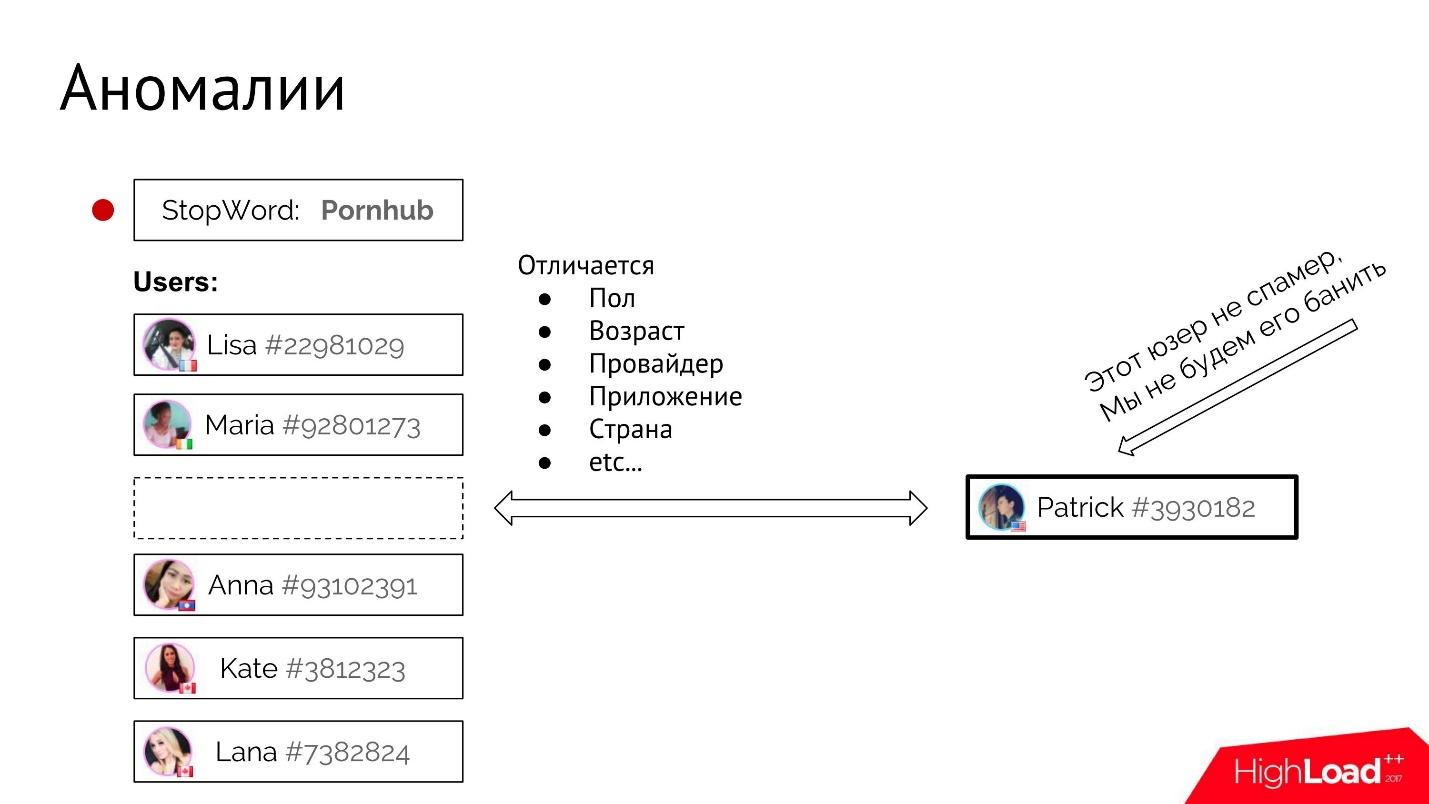
At some point, a new user Patrick uses the same stop word, and we need to add it to this bad company and ban it.
Here you need to check whether the new Patrick user is different from all the old, already known spammers. You can compare its typical attributes: gender, age, provider, application, country, etc. Here it’s important for us to understand how large the “distance” in this attribute space is between the user and the main group. If it is very large, then Patrick most likely got there by accident. He did not mean anything bad, he should not be immediately banned, but it is better to send it for manual inspection.
When we built such a system, we began to experience much less typical false-positives.
Universal Mega Classifier
You may ask - why not immediately make a great classy system with MachineLearning, neural networks and decision trees, which will receive all the information about users as an input and give out just 0 or 1 - the person is a spammer or not.
Trying to create one universal model, it is very easy to come to a situation when we face a black box that is difficult to control. In it, the good is not separated from the bad, the system itself is not isolated from itself in any way, and it is protected from errors only by manual verification and indirect metrics. In addition, on a large amount of data, collecting all the information and statistics in order to submit an input to the mega-system is quite difficult.
Moreover, all known machine learning systems are not one model - they are a dozen models. Any voice assistant or face recognition system - these are several models connected to one very complex system.
As a result, it became clear to us that the way is more correct (from our point of view) when separate classifiers and clustering systems are created that solve their own separate problem. It is ideal that, as in our case, a separate model is created for each separate type of spam and monitored separately in various ways: other models, indirect metrics, as well as manually. This is the only way to hopefully avoid most of the false positives.
About the speaker: Mikhail Ovchinnikov has been working at Badoo and has been anti-spam for the past five years.
Badoo has 390 million registered users (data for October 2017). If we compare the size of the service’s audience with the population of Russia, we can say that, according to statistics, every 100 million people are protected by 500 thousand police officers, and in Badoo, only one Antispam employee protects every 100 million users from spam. But even such a small number of programmers can protect users from various troubles on the Internet.
We have a large audience, and it can have different users:
- Good and very good, our favorite paying customers;
- The bad ones are those who, on the contrary, are trying to make money from us: they send spam, scam money, and engage in fraud.
Who have to fight
Spam can be different, often it cannot be distinguished at all from the behavior of an ordinary user. It can be manual or automatic - bots that are engaged in automatic mailing also want to get to us.
Perhaps you also once wrote bots - were creating scripts for automatic posting. If you are doing this now, it’s better not to read further - you should by no means find out what I will tell you now.
This, of course, is a joke. The article will not have information that will simplify the life of spammers.
So who do we have to fight with? These are spammers and scammers.
Spam appeared a long time ago, from the very beginning of the development of the Internet. In our service, spammers, as a rule, try to register an account by uploading a photo of an attractive girl there . In the simplest form, they begin to send out the most obvious types of spam - links.
A more complicated option is when people don’t send anything explicit, don’t send any links, don’t advertise anything, but lure the user to a place more convenient for them, for example, instant messengers : Skype, Viber, WhatsApp. There they can, without our control, sell anything to the user, promote, etc.
But spammers are not the biggest problem . They are obvious and easy to fight. Much more complex and interesting characters are scammers who pretend to be another person and try to deceive users in all the ways that are on the Internet.
Of course, the actions of both spammers and scammers are not always very different from the behavior of ordinary users who also do this sometimes. There are many formal signs in both of those that do not allow a clear line to be drawn between them. This is almost never possible.
How to deal with spam in the Mesozoic era
- The simplest thing that could be done was to write separate regular expressions for each type of spam and enter each bad word and each separate domain into this regular. All this was done manually, and, of course, it was as inconvenient and inefficient as possible.
- You can manually find dubious IP addresses and enter them in the server config so that suspicious users will never again access your resource. This is inefficient because IP addresses are constantly reassigned, redistributed.
- Write one-time scripts for each type of spammer or bot, scrape their logs, manually find patterns. If a little something changes in the behavior of the spammer, everything stops working - also completely ineffective.
First, I will show you the simplest methods of fighting spam that everyone can implement for themselves. Then I will tell you in detail about the more complex systems that we developed using machine learning and other heavy artillery.
The easiest ways to deal with spam
Manual moderation
In any service, you can hire moderators who will manually view the user's content and profile, and decide what to do with this user. Typically, this process looks like finding a needle in a haystack. We have a huge number of users, moderators less.
In addition to the fact that moderators obviously need a lot, you need a lot of infrastructure. But, in fact, the most difficult thing is another - a problem arises: how, on the contrary, protect users from moderators.
It is necessary to make sure that moderators do not get access to personal data. This is important because moderators can theoretically also try to do harm. That is, we need antispam for antispam, so that moderators are under tight control.
Obviously, you cannot verify all users in this way. NonethelessIn any case , moderation is needed , because any systems in the future need training and a human hand that will determine what to do with the user.
Statistics collection
You can try using statistics - to collect various parameters for each user.
User Innokenty logs in from his IP address. The first thing we do is log in which IP address it entered. Next, we build a forward and reverse index between all IP addresses and all users, so that you can get all the IP addresses from which a specific user logs in, as well as all users who log in from a specific IP address.
This way we get the connection between the attribute and the user. There can be a lot of such attributes. We can begin to collect information not only about IP-addresses, but also photos, devices from which the user came in - about everything that we can determine.
We collect such statistics and associate it with the user. For each of the attributes we can collect detailed counters.
We have a manual moderation that decides which user is good, which is bad, and at some point the user is blocked or recognized as normal. We can separately obtain data for each attribute, how many total users, how many of them are blocked, how many are recognized as normal.
Having such statistics for each of the attributes, we can roughly determine who the spammer is, who is not.
Let's say we have two IP addresses - 80% of spammers on one and 1% on the second. Obviously, the first is much more spammed, you need to do something with it and apply some kind of sanctions.
The simplest thing is to write heuristic rules.. For example, if blocked users are more than 80%, and those who are considered normal - less than 5%, then this IP address is considered bad. Then we ban or do something else with all users with this IP address.
Collection of statistics from texts
In addition to the obvious attributes that users have, you can also do text analysis. You can automatically parse user messages, isolate from them everything that is related to spam: mention messengers, phones, email, links, domains, etc., and collect exactly the same statistics from them.
For example, if a domain name was sent in messages by 100 users, of which 50 were blocked, then this domain name is bad. It can be blacklisted.
We will receive a large amount of additional statistics for each of the users based on message texts. No machine learning is needed for this.
Stop words
In addition to the obvious things - telephones and links - you can extract phrases or words from the text that are especially common for spammers. You can maintain this list of stop words manually.
For example, on the accounts of spammers and scammers, the phrase: “There are a lot of fakes” is often found. They write that they are generally the only ones here who are set up for something serious, all the other fakes, which in no case can be trusted.
On dating sites according to statistics, spammers more often than ordinary people use the phrase: "I am looking for a serious relationship." It is unlikely that an ordinary person will write this on a dating site - with a probability of 70% this is a spammer who is trying to lure someone.
Search for similar accounts
With statistics on attributes and stop words found in texts, you can build a system to search for similar accounts. This is necessary to find and ban all accounts created by the same person. A spammer who has been blocked can immediately register a new account.
For example, a user Harold logs in, logs on to the site and provides his rather unique attributes: IP address, photo, stop word that he used. Maybe he even signed up with a fake Facebook account.
We can find all users similar to him who have one or more of these attributes matching. When we know for sure that these users are connected, using the very forward and reverse index, we find the attributes, and by them of all users, and rank them. If, let's say the first Harold, we block, then the rest is also easy to "kill" using this system.
All the methods that I just described are very simple: it’s easy to collect statistics, then it’s easy to search for users using these attributes. But, despite the ease, with the help of such simple things - simple moderation, simple statistics, simple stop words - they manage to defeat 50% of spam .
In our company, for the first six months of work, the Antispam department defeated 50% of spam. The remaining 50%, as you know, are much more complicated.
How to make life difficult for spammers
Spammers are inventing something, trying to complicate our lives, and we are trying to fight them. This is an endless war. There are much more of them than us, and at each step we come up with their own multi-path.
I am sure that spammers' conferences are taking place somewhere where speakers talk about how they defeated Badoo Antispam, about their KPIs, or about how to build scalable fault-tolerant spam using the latest technology.
Unfortunately, we are not invited to such conferences.
But we can make life difficult for spammers. For example, instead of directly showing the user the window “You are locked”, you can use the so-called Stealth banning - this is when we do not say to the user that he is banned. He should not even suspect it.
The user gets into the sandbox (Silent Hill), where everything seems to be real: you can send messages, vote, but in fact it all goes into the void, into the fog. No one will ever see and hear, no one will receive his messages and votes.
We had a case when one spammer spammed for a long time, promoted his bad goods and services, and six months later decided to use the service as intended. He registered his real account: real photos, name, etc. Naturally, our search engine for similar accounts quickly figured it out and put it in Stealth ban. After that, he wrote for six months in the void that he was very lonely, no one answered. In general, he poured out his whole soul to the fog of Silent Hill, but did not receive any answer.
Spammers, of course, are not fools. They are trying somehow to determine that they got into the sandbox and that they were blocked, quit the old account and find a new one. We sometimes even get the idea that it would be nice to send several of these spammers to the sandbox together, so that there they would sell to each other everything they want and have fun as you like. But while we have not reached this point, we are devising other methods, for example, photo and telephone verification.
As you know, it is difficult for a spammer who is a bot and not a person to pass verification by phone or photo.
In our case, verification by photo looks like this: the user is asked to take a picture with a certain gesture, the resulting photo is compared with photos that are already loaded in the profile. If the faces are the same, then most likely the person is real, uploaded his real photos and can be left behind for some time.
It’s not easy for spammers to pass this test. We even got a small game inside the company called Guess Who the Spammer is. Given four photos, you need to understand which of them is a spammer.
At first glance, these girls look completely harmless, but as soon as they begin to undergo photo verification, at some point it becomes clear that one of them is completely not what she claims to be.
In any case, spammers have a hard time fighting photo verification. They really suffer, try to somehow get around it, deceive, and demonstrate all their photoshop skills.
Spammers are doing everything they can, and sometimes they think, probably, that all this is completely processed by some incredible modern technologies that are so poorly constructed that they are so easy to fool.
They do not know that each photo is then again manually checked by moderators.
No time!
In fact, despite the fact that we come up with various ways to make life difficult for spammers, there is usually not enough time, because anti-spam should work instantly. He must find and neutralize the user before he begins his negative activity.
The best thing that can be done is to determine at the registration stage that the user is not very good. This can be done, for example, using clustering.
User clustering
We can collect all possible information right after registration. We still do not have any devices with which the user logs in, nor photographs, there are no statistics. We have nothing to send him for verification, he has not done anything suspicious. But we already have primary information:
- floor;
- age;
- country of registration;
- country and IP provider;
- Email domain
- telephone operator (if any);
- data from fb (if any) - how many friends he has, how many photos he uploaded, how long he registered there, etc.
All of this information can be used to locate user clusters. We use the simple and popular K-means clustering algorithm . It is perfectly implemented everywhere, it is supported in any MachineLearning libraries, it is perfectly parallel, it works quickly. There are streaming versions of this algorithm that allow you to distribute users on clusters on the fly. Even in our volumes, all this works quite quickly.
Having received such user groups (clusters), we can do any actions. If users are very similar (the cluster is highly connected), then most likely this is mass registration, it must be stopped immediately. The user has not had time to do anything yet, just clicked the “Register” button - and that’s all, he already got into the sandbox.
Statistics can be collected on clusters - if 50% of the cluster is blocked, then the remaining 50% can be sent for verification, or individually moderated all clusters manually, look at the attributes by which they coincide, and make a decision. Based on such data, analysts can identify patterns.
Patterns
Patterns are sets of the simplest user attributes that we immediately know. Some of the patterns actually work very effectively against certain types of spammers.
For example, consider a combination of three completely independent, fairly common attributes:
- User is registered in the USA;
- Its provider is Privax LTD (VPN operator);
- Email-Domain: [mail.ru, list.ru, bk.ru, inbox.ru].
These three attributes, seemingly separately representing nothing of themselves, together give the likelihood that this is a spammer, almost 90%.
You can extract such patterns as many as you like for each type of spammer. This is much more efficient and easier than manually viewing all accounts or even clusters.
Text clustering
In addition to clustering users by attributes, you can find users who write the same texts. Of course, this is not so simple. The fact is that our service works in so many languages. Moreover, users often write with abbreviations, slang, sometimes with errors. Well, the messages themselves are usually very short, literally 3-4 words (about 25 characters).
Accordingly, if we want to find similar texts among the billions of messages that users write, we need to come up with something unusual. If you try to use classical methods based on the analysis of morphology and true honest processing of the language, then with all these restrictions, slangs, acronyms and a bunch of languages, this is very difficult.
You can do a little more simply - apply the n-gram algorithm. Each message that appears is broken down into n-grams. If n = 2, then these are bigrams (pairs of letters). Gradually, the entire message is divided into pairs of letters and statistics are collected, how many times each bigram occurs in the text.
You can not stop at bigrams, but add trigrams, skipgrams (statistics on letters after 1, 2, etc. letters). The more information we get, the better. But even bigrams already work quite well.
Then we get a vector from the bigrams of each message whose length is equal to the square of the length of the alphabet.
It is very convenient to work with this vector and cluster it, because:
- consists of numbers;
- compressed, there are no voids;
- always fixed size.
- the k-means algorithm with such compressed vectors of a fixed size is very fast. Our billions of messages are clustered in literally a few minutes.
But that is not all. Unfortunately, if we simply collect all the messages that are similar in frequency to the bigrams, we get messages that are similar in frequency to the bigrams. However, they do not have to be in fact at least somewhat similar in meaning. Often there are long texts in which the vectors are very close, almost the same, but the texts themselves are completely different. Moreover, starting from a certain length of text, this clustering method will generally stop working, because the frequencies of the bigrams are equal.
Therefore, you need to add filtering. Since the clusters already exist, they are quite small, we can easily do filtering inside the cluster using Stemming or Bag of Words. Inside a small cluster, you can literally compare all messages with everyone, and get the cluster in which there are guaranteed to be the same messages, which coincide not only in statistics, but also in reality.
So, we have done clustering - and yet, for us (and for clustering) it is very important to know the truth about the user. If he is trying to hide the truth from us, then we need to take some action.
Information hiding
A typical type of information hiding is VPN, TOR, Proxy, and Anonymizers. The user uses them, trying to pretend that he is from America, although in fact he is from Nigeria.
In order to overcome this problem, we took the most famous textbook “How to calculate by IP”.
With the help of this tutorial, we wrote a VPN classifier - that is, a classifier that receives an IP address as input and says whether this IP address is a VPN, Proxy or not.
To implement the classifier, we need several ingredients:
- The ISP (Internet Service Provider) database , i.e. the correspondence of IP addresses to all existing providers. Such a base can be purchased, it is not very expensive.
- Information from Whois . The IP address in Whois is available a lot of different information: country; Provider The subnet that includes the IP address sometimes the fact that this IP address belongs to the hosting, etc. You can analyze the text for specific words and see what the IP address is all about.
- Base GeolP. If the database tells us that the IP address is in Norway, and all users who use this Norwegian IP address are scattered across Africa, then there is probably something wrong with this IP address.
- User statistics - how many users of our service on this IP address are blocked, how many of them match the data of GeolP, Whois, how many do not match.
Taking all this information, you can build a classifier that will eventually say whether the IP address is VPN or not.
We chose decision trees because they are very good at finding the very patterns — specific combinations of providers, countries, statistics, etc., which ultimately make it possible to determine that the IP address is a VPN.
Of course, this data is very general. No matter how well we train the classifier, no matter how hard we try to use advanced techniques, it still will not work with 100% accuracy. Therefore, additional network checks are a key factor here.
Once we have received information that the IP address supposedly belongs to the VPN, we can actually check what this IP address is. You can try to connect to it, see what ports are open on it. If there is a SOCKS-proxy, you can try to open a connection and determine exactly whether this IP address is anonymized or not.
In addition, there is still a wonderful technology, the implementation of which is still in our plans, which is called p0f . This is a utility that makes fingerprinting traffic at the network level and allows you to immediately determine what is on the other side of the connection: regular user client, VPN client, Proxy, etc. The utility contains a large set of patterns that define all this.
Most suspicious action
After we wrote various systems, clusters, classifiers, collected statistics, we thought: what can the most suspicious user do on our service? To register is already suspicious! If the user has registered, then we immediately begin to look at him with a very sly squint and analyze him in every possible way, trying to understand what he meant.
We often have an internal desire - and not to ban us all immediately after registration? This would greatly facilitate the work of the Antispam department. We can immediately drink tea 2 times longer, and we will not have any problems.
In order to stop such thoughts not only from ourselves, but also from the systems that we write, and not to ban all good users, especially immediately after registration, we are forced to create systems that struggle with our other systems, that is, they organize their own limitations.
How can you limit yourself so as not to ban good users, not to make mistakes and not to get confused?
"User Decency"
We classify users by honesty - we will make an isolated model that will take all the positive characteristics of the user and do an analysis on them.
An example of the characteristics of a “good” behavior:
- the length of the dialogs;
- registration limitation;
- lack of complaints;
- Verifications passed
- purchases.
On a dataset of all individual exceptionally good user characteristics, a classifier or regression can be trained. We have a simple logistic regression . This model is easy to port, because it is just a set of coefficients, and it is easy to implement in any system and in any language, it is very well transferred between platforms and infrastructures.
Taking the user and driving him through this model, we get a coefficient that we call the “ honesty coefficient ”. If it is zero, then, as a rule, this means that we have almost no information about this user. Then we do not get any additional information from the classification.
If the user’s honesty coefficient is 1, then most likely the user is a good guy, we won’t touch him - there will be no verification and no ban will come to him.
Such an isolated thing allows us to prevent many common mistakes.
False positive
The second thing you can do is look for various false positives. It happens that users accidentally come from the same IP address. For example, two are sitting in an Internet cafe, even their computer may be the same. The browser, fingerprint, which we count on the computer, on the browser, on the device - everything will absolutely coincide, and we can assume that both users are spammers, although it is not a fact that they are somehow connected.
Another example: a good user in a dialogue with a spammer can ask again in response to an advertisement: “Hey, I didn’t understand what Pornhub is — why are you advertising it to me?” At such a moment, the system sees that the user has written a stop word and can consider that this user is a spammer and should be banned as soon as possible.
Therefore, we have to search for anomalies. We take users, their attributes, and look for those users among them who got into a bad company by accident.
For example, take the stop word “Pornhub”. For each stop word, we have statistics for all users who have ever used it.
At some point, a new user Patrick uses the same stop word, and we need to add it to this bad company and ban it.
Here you need to check whether the new Patrick user is different from all the old, already known spammers. You can compare its typical attributes: gender, age, provider, application, country, etc. Here it’s important for us to understand how large the “distance” in this attribute space is between the user and the main group. If it is very large, then Patrick most likely got there by accident. He did not mean anything bad, he should not be immediately banned, but it is better to send it for manual inspection.
When we built such a system, we began to experience much less typical false-positives.
Universal Mega Classifier
You may ask - why not immediately make a great classy system with MachineLearning, neural networks and decision trees, which will receive all the information about users as an input and give out just 0 or 1 - the person is a spammer or not.
Trying to create one universal model, it is very easy to come to a situation when we face a black box that is difficult to control. In it, the good is not separated from the bad, the system itself is not isolated from itself in any way, and it is protected from errors only by manual verification and indirect metrics. In addition, on a large amount of data, collecting all the information and statistics in order to submit an input to the mega-system is quite difficult.
Moreover, all known machine learning systems are not one model - they are a dozen models. Any voice assistant or face recognition system - these are several models connected to one very complex system.
As a result, it became clear to us that the way is more correct (from our point of view) when separate classifiers and clustering systems are created that solve their own separate problem. It is ideal that, as in our case, a separate model is created for each separate type of spam and monitored separately in various ways: other models, indirect metrics, as well as manually. This is the only way to hopefully avoid most of the false positives.
Приходите на HighLoad++ 2018, в этом году будет много докладов по машинному обучению и искусственному интеллекту, например:
- Сергей Виноградов представит стандартизацию жизненного цикла ML-модели и покажет, как их эксплуатировать в продакшне без приключений
- Дмитрий Коробченко из NVIDIA расскажет об алгоритмических трюках, которые используются под капотом реальных боевых нейронных сетей.
- Артем Кондюков разберет интересный use case машинного обучения в фармацевтике.
Видео прошедших докладов собираем на youtube-канале, новости о будущих темах публикуем в рассылке — подписывайтесь, если хотите быть в курсе обо всем в мире высоких нагрузок.