How WebRTC Stats and Monitoring Changed VoIP Monitoring
- Transfer

Today we are publishing a translation about the next WebRTC trend, thanks for this to Tsahi's consultant. What changes the WebRTC technology brings to the world of VoIP and what the approach to statistics is changing: more on that under the cut. By the way, maybe you remember that Tsakhi Levent-Levy came to our Intercom 2017 conference - then he read a report about the history and impact of WebRTC on modern communications; however, at our nearest conference , alas, it will not be. But on the other hand, the bloggeek.me blog is always available, and we try to make it even more accessible with our translations :) So, we are talking about collecting statistics from video calls through clients, please, under cat.
To collect WebRTC statistics, monitoring is now shifting from the server to the client side.
WebRTC decentralizes everything related to VoIP. The significance of the backend begins to yield to that of the end devices. Although WebRTC is not particularly different from other VoIP solutions, we still use it and design services using it in a completely different way.
The main example - for group calls, we shifted focus from the mixing MCU model to the SFU routing model . And then - suddenly - the mere desire to deploy the MCU began to look ridiculous. I know what I'm talking about - I worked for a company where more than 60% of calls went through the MCU.
The transition to SFU means that we rely more on the capabilities and performance of the end device, give it more privileges for marking up the display (rather than doing this hard work on the backend using the MCU). The next step will be multi-connected networks, but I do not think that this will be implemented in the near future.
Actually, what I was leading to: something similar happens with VoIP performance statistics (more precisely, with WebRTC statistics). We stop collecting statistics on the backend, but prefer to take it directly from the browser / device.
Statistics collection and VoIP monitoring
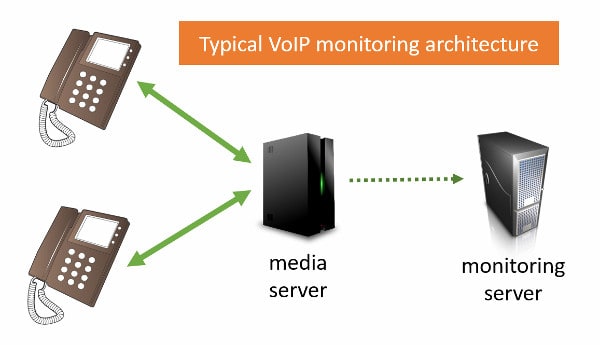
If you are not familiar with collecting statistics and monitoring VoIP, here is a short explanation:
VoIP is based on compatibility. Developers create a product and then test it according to the specification and for the sake of compatibility. Next, those involved in the deployment, collect and run the service. Sometimes this leads to the fact that one vendor is used, but more often the products of different vendors work in the same assembly.
There is no specification or standard on how to do monitoring or what statistics can / should / will be collected. There are several ways to collect statistics, the most common being using HEP / EEP . As the specification says:
“The Extensible Encapsulation protocol (“ EEP ”) provides a method to duplicate an IP datagram to a collector by encapsulating the original datagram and its relative header properties (as payload, in form of concatenated chunks) within a new IP datagram transmitted over UDP / TCP / SCTP connections for remote collection. Encapsulation allows for the original content to be transmitted without altering the original IP datagram and header contents and provides flexible allocation of additional chunks containing additional arbitrary data. The method is NOT designed or intended for “tunneling” of IP datagrams over network segments, and best serves as vector for passive duplication of packets intended for remote or centralized collection and long term storage and analysis. ”In simple language: media packets are duplicated in order to send duplicates for analysis to the monitoring service.
Packet duplication occurs on the backend, through the media servers of the VoIP network. This is how it is illustrated on the HOMER / SIPCAPTURE website :
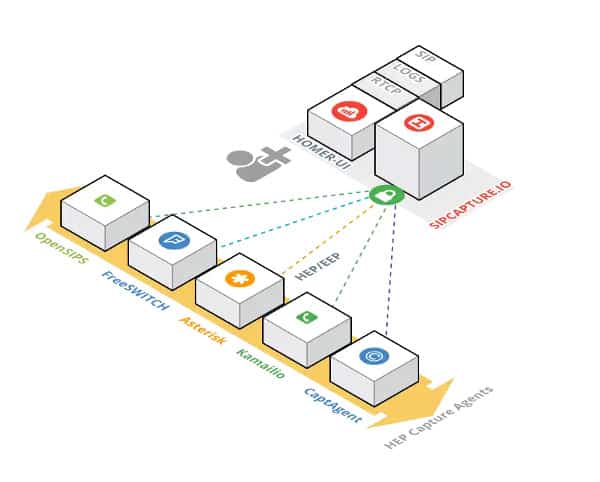
HOMER receives data directly from servers - OpenSIPS, FreeSWITCH, Asterisk, Kamailio - these are not user devices, only backend servers.
Other systems rely on switches, routers and network devices, which again are in the backend infrastructure. Since in VoIP networks we almost always send media through backend servers, it is logical to assume that collecting data is easier here than from user devices.
This works fine, but it is not needed or useful for WebRTC.
WebRTC statistics collection and monitoring
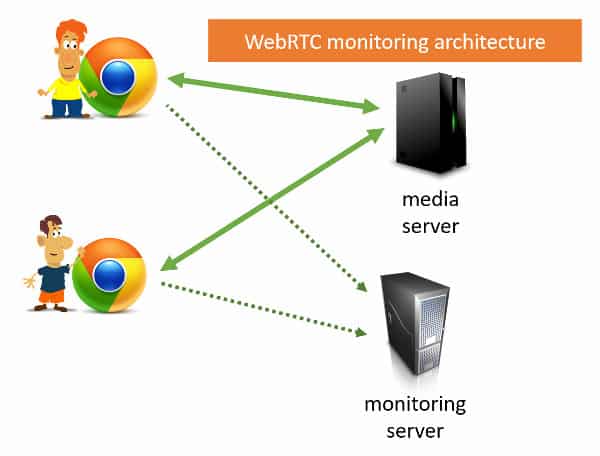
There are few browsers that work with WebRTC (4 browsers, to be precise), and all of them work with a similar API (in fact, with WebRTC). These browsers have a getstats () method that returns the same as chrome: // webrtc-internals .
Many implementations use peer-to-peer, in which media is transmitted
directly over the Internet without affecting the backend. Google Hangouts started doing this 2 years ago. Jitsi service added this feature under the name Jitsi P2P4121 . How do these services monitor quality for their users?
If you look at other services, you will understand that they are only a few years old. And WebRTC is already 6 years old. So everyone has already focused on functionality and stability; quality and monitoring are no longer in the spotlight.
This led to the fact that applications on WebRTC collect statistics directly from browsers and end devices and do not try to get it from media servers.
Final result? Open source projects - for example, rtcstats - and commercial services like callstats.io . They are based on WebRTC statistics (collected using the getstats () API in the interval from 1 to several seconds), which are sent to the server for monitoring - there statistics are collected, stored and analyzed. We use a similar circuit in testRTCto collect, analyze and visualize the results of our measurements.
What does this give us?
- The end-user has accurate performance indications - since statistics are collected from the client device, there is no more information loss due to the backend.
- Easy access to information because common methods are used to collect information. In addition, they can be embedded in native mobile and desktop applications that use WebRTC.
- Trust in end devices is a trend in WebRTC that we see everywhere.
What's next?
WebRTC is changing a lot in the way we are used to thinking about VoIP networks. Specifically, the approach about collecting statistics, why and how this is done - I did not see this being actively discussed, so I wanted to talk about it.
I have three reasons for this:
- Some people have been asking me this here in recent days, so it made sense to write a detailed answer.
- We at testRTC are considering offering a “local” passive monitoring service. If you want to collect, store and analyze your WebRTC statistics without giving them to a third-party cloud service, write to us .
- My online WebRTC course is now being updated, plus I'm preparing new seminars. It will be in April (on the day of publication, the course had an update of September 2017, details on the website bloggeek.me - translator comment ). Sign up for a course if you want to learn WebRTC.