Next Generation Video: Introducing AV1
- Transfer
 AV1 is the new universal video codec developed by the Alliance for Open Media. The alliance took as a basis the VPX codec from Google, Thor from Cisco and Daala from Mozilla / Xiph.Org. The AV1 codec is superior in performance to VP9 and HEVC, which makes it a codec not tomorrow, but the day after tomorrow. The AV1 format is free of any royalties and will always remain so with a licensing license for free and open source software.
AV1 is the new universal video codec developed by the Alliance for Open Media. The alliance took as a basis the VPX codec from Google, Thor from Cisco and Daala from Mozilla / Xiph.Org. The AV1 codec is superior in performance to VP9 and HEVC, which makes it a codec not tomorrow, but the day after tomorrow. The AV1 format is free of any royalties and will always remain so with a licensing license for free and open source software.Triple platform
Those who followed the development of Daala know that after the formation of the Alliance for Open Media (AOM), Xiph and Mozilla proposed our Daala codec as one of the bases for the new standard. In addition to it, Google introduced its VP9 codec, and Cisco introduced Thor. The idea was to create a new codec, including based on these three solutions. From that moment, I did not publish any demos about new technologies in Daala or AV1; for a long time we knew little about the final codec.
About two years ago, AOM voted to establish the fundamental structure of the new codec based on VP9, not Daala or Thor. Alliance member companies wanted to get a useful codec without royalties and licensing as soon as possible, so they chose VP9 as the least risky option. I agree with that choice. Although Daala was nominated as a candidate, I still think that the elimination of block artifacts by lapping arrpoach and frequency domain techniques in Daala (then and now) were not yet mature enough for real deployment. Daala still had unresolved technical issues, and choosing VP9 as the starting point solved most of these problems.
Due to the fact that VP9 is taken as a basis, the AV1 codec (AOM Video Codec 1) will be basically an understandable and familiar codec built on traditional block conversion code. Of course, it also includes some very interesting new things, some of which are taken from Daala! Now that we are quickly approaching the final specifications, it's time to introduce the long-awaited technological demonstrations of the codec in the context of AV1.
A New Look at Luminance Color Prediction (CfL)
Prediction of color by brightness (Chroma from Luma, abbreviated CfL) is one of the new forecasting methods adopted for AV1. As the name implies, it predicts colors in an image (chroma) based on brightness values (luma). First, luminance values are encoded and decoded, and then CfL performs reasonable color prediction. If the assumption is good, then this reduces the amount of color information for encoding and saves space.
In fact, CfL in AV1 is not a completely new technique. A fundamental CfL scientific article came out in 2009, and LG and Samsung jointly proposed the first CfL implementation called LM Mode , which was rejected during the HEVC design phase. Do you remember what I wrote aboutEspecially advanced version of CfL, which is used in the Daala codec . Cisco's Thor codec also uses the CfL technique similar to LM Mode, and HEVC eventually added an improved version called Cross-Channel Prediction (CCP) as the HEVC Range Extension (RExt).
| LM Mode | Thor cfl | Daala cfl | HEVC CCP | AV1 CfL | |
|---|---|---|---|---|---|
| Forecasting Area | the space -governmental | the space -governmental | frequency | the space -governmental | the space -governmental |
| Coding | not | not | sign bit | index + signs | joint sign + index |
| Activation mechanism | LM_MODE | threshold | signal | binary flag | CFL_PRED (in uv mode only) |
| Requires PVQ | not | not | Yes | not | not |
| Modeling a decoder? | Yes | Yes | not | not | not |
LM Mode and Thor are similar in that the encoder and decoder simultaneously run the same prediction model and do not require encoding any parameters. Unfortunately, this parallel / implicit model reduces the accuracy of approximation and complicates the decoder.
Unlike others, Daala's CfL operates in the frequency domain. This only transmits the activation bit and the sign bit, and other parameter information is already implicitly encoded through PVQ.
The final implementation of the AV1 CfL is based on the Daala implementation, borrowing the ideas of the model from Thor, and improving both options by introducing additional research. This avoids an increase in complexity in the decoder, implements a model search, which also reduces the complexity of the encoder compared to its predecessors and especially improves the accuracy and approximation of the encoded model.
The need for better intra prediction
At a fundamental level, compression is the art of forecasting. Prior to the latest generation of codecs, video compression relied mainly on inter-frame coding prediction , that is, coding a frame as a set of changes compared to other frames. Those frames on which interframe coding is based are called reference frames . The prediction of inter-frame coding over the past few decades has become an incredibly powerful tool.
Despite the power of inter-frame forecasting, we still need separate reference frames. They, by definition, do not rely on information from any other frames - as a result, they can only use intra-frame forecasting , which works completely insideframe. Since reference frames use only intra-frame prediction, they are also often referred to as intra-frames. Reference or I-frames allow you to search the video, otherwise we would always have to play the video only from the very beginning *.

A histogram of the size in bits of the first sixty frames of the test video, starting with the reference frame. In this clip, the reference frame is 20-30 larger in size of subsequent intermediate frames. In slow motion or highly static footage, the reference frame can be hundreds of times larger than the intermediate.
The reference frames are extremely large compared to the intermediate ones, therefore they are usually used as rarely as possible and widely spaced from each other. Despite this, the intermediate frames are becoming smaller and smaller, and the reference frames occupy an increasing part of the bitstream. As a result, video codec research focused on finding new, more powerful forms of intra-frame prediction to reduce the size of the reference frames. And despite its name, intermediate frames can also benefit from intra-frame forecasting.
Improving intra prediction is a double victory!
Luminance color prediction works solely on the basis of luma blocks within a frame. Thus, it is an intra prediction technique.
Energy is power †
Energy Correlation Is Information
Why do we think that color can be predicted by brightness?
In most video implementations, channel correlation is reduced due to the use of a YUV color space. Y is the luminance channel, the version of the original video signal in grayscale generated by adding weighted versions of the original red, green, and blue signals. The color channels U and V subtract the luminance signal from blue and red, respectively. The YUV model is simple and significantly reduces channel coding duplication.

Image decomposition (leftmost) in the YUV model or, more precisely, in the bt.601 Y'CbCr color space. The second image on the left shows the luminance channel, and the two right ones show color channels. YUV has less inter-channel redundancy than the RGB image, but features of the original image are still clearly visible in all three channels after YUV decomposition; in all three channels, the outlines of objects are in the same places.
And yet, if you look at the decomposition of the frame on the YUV channels, it becomes obvious that the outlines of the boundaries of color and brightness are still in the same places on the frame. There remains a certain correlation that can be used to reduce bitrate. Let's try using some luminance data to predict color.
We get color crayons
Prediction of color by brightness is, in fact, the process of coloring a monochrome image based on reasonable guesses. About how to take an old black and white photograph, colored pencils - and start painting. Of course, CfL forecasts should be accurate, not pure guesswork.
The work is facilitated by the fact that modern video codecs divide the image into a hierarchy of smaller blocks, performing the bulk of the encoding independently on each block.

The AV1 encoder splits the frame into separate prediction blocks for maximum coding accuracy, and, equally importantly, to simplify the analysis and make adjustments to the prediction as the image is processed.
A model that predicts color immediately for the entire image would be too cumbersome, complex, and error prone - but we don’t need to predict the entire image. Since the encoder works in turn with small fragments, you only need to compare the correlations in small areas - and from them we can predict the color by brightness with a high degree of accuracy, using a fairly simple model. Consider a small part of the image below, in a red outline: A

single block in one frame of the video illustrates that localizing color prediction in small blocks is an effective way to simplify forecasting.
In the small range of this example, a good “rule” for coloring the image will be simple: the brighter areas are green, and the saturation decreases with brightness down to black. Most blocks have the same simple coloring rules. We can complicate them to our taste, but the simplest method also works very well, so let's start with a simple one and approximate the data to a simple line ax + β:

Cb and Cr (U and V) values relative to brightness (Y) for pixels in the selected block from the previous image. The quantized and coded linear model is approximated and superimposed in the form of a line on the scattering diagram. Note that the approximation consists of two lines; in this example, they overlap.
Well, well, we have two lines - one for channel U (difference with blue, Cb) and one for channel V (difference with red, Cr). In other words, if
 Are the restored brightness values, then we calculate the color values as follows:
Are the restored brightness values, then we calculate the color values as follows:

What do these parameters look like? Each
 corresponds to a certain tone (and antitone) from a two-dimensional palette, which are scaled and applied in accordance with the brightness indicator:
corresponds to a certain tone (and antitone) from a two-dimensional palette, which are scaled and applied in accordance with the brightness indicator: 
Parameters
in CfL choose a tone for coloring a block from a two-dimensional palette.Values
 change the zero crossing point for the color scale, that is, these are buttons for switching the minimum and maximum level of saturation during coloring. note thatallows you to apply a negative color. This is the opposite of the tone selected by.
change the zero crossing point for the color scale, that is, these are buttons for switching the minimum and maximum level of saturation during coloring. note thatallows you to apply a negative color. This is the opposite of the tone selected by. Now our task is to choose the right
and , and then coding them. Here is one example of a straightforward implicit approach for predicting chroma by luminance in AV1 :
It looks scarier than it really is. If translated into normal language: approximate the least squares of the color values from the restored brightness values to find
then use to solve color bias . At least this is one of the possible approximation methods. It is often used in CfL implementations (such as LM Mode and Thor) that do not transmit a signal.nor . In this case, the approximation is performed using the color values of neighboring pixels that have already been fully decoded.CFL in Daala
Daala performs all the prediction in the frequency domain, including CfL, providing the prediction vector as one of the input values for PVQ encoding . PVQ is gain / shape encoding. The luminance vector PVQ encodes the location of the outlines and borders in brightness, and we simply reuse it as a predictor for the outlines and color boundaries.
Daala codec does not need to encode value
, since it falls into the PVQ gain (except for the sign). Daala also does not need to encode a value: since Daala applies CfL only to AC color ratios, always zero. This gives us insight:conceptually is just a DC offset of chroma values. In fact, since the Daala codec uses PVQ to encode conversion blocks, it receives CfL at virtually no cost, both in terms of bits and in terms of additional computations in the encoder and decoder.
CFL to AV1
AV1 did not accept PVQ, so the cost of CfL is about the same when calculated in the pixel or frequency domain; there is no longer a special bonus for working in the frequency domain. In addition, the Time-Frequency resolution switching (TF) , which Daala uses to glue the smallest luma blocks and create sufficiently large sub-sampled chroma blocks, currently only works with DCT and Walsh-Hadamard transforms. Since AV1 also uses discrete sine and pixel domain identity transforms, we cannot easily perform AV1 CfL in the frequency domain, at least when using sub-sampled color.
But, unlike Daala, AV1 does not needin performing CfL in the frequency domain. So for AV1 we move CfL from the frequency domain back to the pixel domain. This is one of the great features of CfL - the basic equations work equally in both areas.
CfL in AV1 should keep reconstruction complexity to a minimum. For this reason, we explicitly code
so that the least-square least-square approximation does not occur in the decoder. Expenses of bits for explicit encoding more than pay off by the additional accuracy obtained in the calculation using chroma pixels of the current block instead of neighboring reconstructed chroma pixels. Then we optimize the approximation complexity on the encoder side. Daala operates in the frequency domain, so we only perform CfL with AC luminance factors. AV1 approximates the CfL in the pixel area, but we can subtract the average (that is, the already calculated DC value) from each pixel, which brings the pixel values to a zero average, equivalent to the contribution of the AC coefficient to Daala. Zero average brightness values reduce a significant part of the least squares equation, significantly reducing the cost of computing:
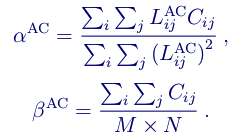
We can optimize even more. After all
- it’s just a DC chroma offset, so the encoder and decoder already perform DC prediction for chroma planes, since this is necessary for other prediction modes. Of course, the predicted DC value will not be as accurate as the explicitly encoded DC /, but tests showed that it still looks pretty good:
Neighboring Pixel Default DC Predictor Error Analysis and Explicit Value Coding
by pixels in the current block.As a result, we simply use an existing DC color prediction instead of
. Now not only does the need to codebut you don’t need to explicitly calculate of neither in the encoder nor in the decoder. Thus, our final CfL prediction equation is as follows: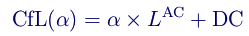
In cases where prediction alone is not enough for an accurate result, we encode the residual transform domain. And of course, when forecasting does not give any benefit in bits at all, we simply do not use it.
results
As with any prediction method, the effectiveness of CfL depends on the choice of test. AOM uses a number of standardized test suites hosted on Xiph.Org and accessible through the automated test tool “Are we already compressed?” (“Are We Compressed Yet?”, AWCY).
CfL is an intra prediction technique. To better evaluate its effectiveness in reference frames, take the test subset-1 image set :
| Bd-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Average | -0.53 | -0.31 | -0.34 | -4.87 | -12.87 | -10.75 | -0.34 |
Most of these metrics are color sensitive. They are simply always on, and it's nice to see that the CfL technique does not harm them. Of course, it should not, because more efficient color coding simultaneously frees up bits that can be used to better represent brightness.
However, it makes sense to look at the CIE delta-E 2000; it shows the metric of perceptually uniform color error. We see that CfL saves almost 5% in bitrate, taking into account both brightness and color! This is a stunning result for a single forecasting method.
CfL is also available for intra-frame blocks within intermediate frames. During development of the AV1 objective-1-fast kit was a standard test set for evaluating indicators of motion sequences:
| Bd-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Среднее | -0.43 | -0.42 | -0.38 | -2.41 | -5.85 | -5.51 | -0.40 |
| 1080p | -0.32 | -0.37 | -0.28 | -2.52 | -6.80 | -5.31 | -0.31 |
| 1080p-screen | -1.82 | -1.72 | -1.71 | -8.22 | -17.76 | -12.00 | -1.75 |
| 720p | -0.12 | -0.11 | -0.07 | -0.52 | -1.08 | -1.23 | -0.12 |
| 360p | -0.15 | -0.05 | -0.10 | -0.80 | -2.17 | -6.45 | -0.04 |
As expected, we still see a solid increase, although the contribution of CfL is somewhat weakened due to the predominance of interpolation. Intra-frame blocks are mainly used in reference frames, each of these test sequences encodes only one reference frame, and intra-frame coding is not often used in intermediate frames.
An obvious exception is the content “1080p-screen”, where we see a huge decrease in bitrate by 8%. This is logical, because a significant part of the screencasts are quite static, and if the area changes, then it is almost always a major update, suitable for intra-frame encoding, and not smooth motion, suitable for inter-frame encoding. In these screencasts, intraframe blocks are actively encoded - and therefore, the benefits of CfL are more noticeable.
This applies to both synthetic content and rendering:
| Bd-rate | |||||||
| PSNR | PSNR-HVS | SSIM | CIEDE2000 | PSNR Cb | PSNR Cr | MS SSIM | |
| Twitch | -1.01 | -0.93 | -0.90 | -5.74 | -15.58 | -9.96 | -0.81 |
The Twitch test suite consists entirely of video game broadcasts, and here we also see a significant reduction in bitrate.
Of course, predicting chroma by brightness is not the only technique that the AV1 codec will open for mass use for the first time. In the next article, we will look at a really completely new technique from AV1: a filter with a fixed directional gain (Constrained Directional Enhancement Filter).
Posted by Monty (monty@xiph.org, cmontgomery@mozilla.com). Published April 9, 2018.
* Есть возможность «размазать» опорный кадр по другим кадрам, используя прокат I-кадра (rolling intra). В случае проката отдельные опорные кадры делятся на отдельные блоки, которые рассеиваются среди предшествующих опорных кадров. Вместо поиска опорного кадра и начала воспроизведения с этой точки кодек с поддержкой проката I-кадров ищет первый предыдущий блок, считывает все остальные необходимые фрагменты опорного кадра и начинает воспроизведение после сбора достаточного количества информации для восстановления полного опорного кадра. Прокат I-кадра не улучшает сжатие; он просто размазывает всплески битрейта, вызванные большими опорными кадрами. Его также можно использовать для повышения устойчивости к ошибкам. [вернуться]
† Технически, энергия — это произведение мощности на время. При сравнении яблок и апельсинов важно выражать оба фрукта в ватт-часах. [вернуться]
Дополнительные ресурсы
- Проектный документ Альянса за открытые медиа: CfL в AV1, Люк Трюдо, Дэвид Майкл Барр
- Основополагающая научная статья по прогнозированию цветности по яркости в пространственной области: «Метод внутрикадрового прогнозирования, основанный на линейной связи между каналами во внутрикадровом кодировании YUV 4:2:0», Сан Хен Ли, 16-я международная конференция IEEE по обработке изображений (ICIP), 2009
- Предложение LG включить пространственное прогнозирование CfL в HEVC: «Новая техника внутрикадрового прогнозирования цветности с использованием межканальной корреляции», Ким и др., 2010
- Совместное предложение Samsung и LG по LM Mode в HEVC: «Внутрикадровое прогнозирование цветности по реконструированным образцам яркости», Ким и др., 2011
- Реализация CfL в Daala: «Прогнозирование цветности по яркости во внутрикадровой частотной области», Натан Эгги, Жан-Марк Валин, 10 марта 2016 г.
- «Прогнозирование цветности по яркости в AV1», Люк Трюдо, Натан Эгги, Дэвид Барр, 17 января 2018 г.
- Демо-страница частотновременного переключения разрешения в Daala
- Демо-страница CfL в Daala
- CfL presentation from VideoLan Dev Days 2017: “CfL in AV1” , Luke Trudeau, David Barr, September 2017
- Presentation from the Data Compression Conference: “CfL Intra Frame Prediction for AV1” , Luke Trudeau, Nathan Aggie, David Barr, March 2018
- Xiph.Org standard 'derf' test suites at media.xiph.org
- Automated testing system and metrics used in the development of Daala and AV1: "Are we already compressed?"