How Sberbank Online applications work: Workflow API and frameworks
Many people use the Sberbank Online application, but few know how it works. It is time to open the veil of secrecy - in this article we will talk about some of the approaches that we use in development.

There will not be a big date, blockchain, agile or other rocket science. But the API on which our most popular applications work will be described. The value of this article is not in breakthrough ideas, but in approaches and practices that work in a large application with one of the most demanding audiences.
We hope that our experience will help readers to make their product better, and most importantly scalable, because most of the cones in the development of the API we have already caught and fixed.
We will tell you how payment scenarios work in Sberbank Online’s mobile and web applications, namely, about the API between applications and the server-side.
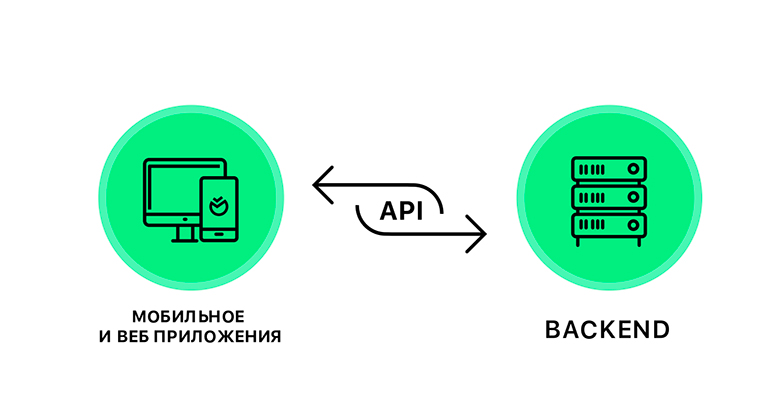
Why focus on API? Everything is simple - this is actually the only bridge that connects client applications and the backend. If the project is small, then we can easily change the API and rewrite applications for it. But if the project is large-scale (such as ours), then even small API changes require the involvement of a large amount of resources both on the front and on the backend, and become very expensive. And the second point - the earlier we fixed the API, the earlier the front and back teams can begin development. They just need to come together at one point.
First, we will talk a little about our capabilities and limitations, so that it is clear why we chose this and not another solution, and then we will present the API protocol itself at the top level.
The applications are great. When we wrote this article, the Sberbank Online application on Android occupied about 800,000 lines of code, on iOS - 500,000 lines of code. And this is just our code, without plug-in libraries.
Backward compatibility and many users. MAU - 32 million active users of the mobile application. And if we do not do backward compatibility at the API level, so many users across the country will have to download applications again. This is very bad. By the way, this is one of the reasons why we have so much code.
Sberbank Online develops many small teams. You probably heard about Agile at Sberbank. It’s true, we work on Agile in teams of 9 people.
Banking application:despite the fact that the functionality of banking applications is growing very rapidly, the main thing that happens in remote banking is a sequential process (processing of client applications). We call such processes workflow. These applications can be of various kinds and they are processed by a huge number of interconnected services in the perimeter of the bank.
Two types of teams. There are platform ones - they are responsible for developing the application core. And there are feature commands - they create application functionality for end users, using the architecture and tools that the platform provides.
Omnichannel.A very important story. In order not to develop backing several times — separately for mobile applications and separately, for example, for the web version and ATMs, you need to make the API as similar as possible for all channels (at least the answer structure should be the same).
Data changes dynamically. The most popular operations in a mobile application are payment and transfer. Details of service providers, a set of fields that a user needs to fill out, is dynamic information that can change frequently.
However, users may not update the application after installing it on the device. Just because they can. More often there are good reasons for this, for example, to update the application you need to update the OS version, and for this, buy a new phone. Therefore, we need a solution that allows us to change data without releasing the application.
Mobile Internet:Our applications should work everywhere, even where the Internet is unstable and slow. Therefore, we always fight for the size and number of messages between mobile applications and the server side.
Best customer experience: we have chosen for ourselves the basic technology for the development of mobile applications - development in native languages. This is the only way to get the best customer experience.
If to summarize all these requirements, applications should be developed in native languages, have reusable components inside themselves, but at the same time, all business logic should be managed by the server.
After we have identified the boundary conditions, we will tell you what existing solutions we have analyzed.
Programming in JSON
Logic is easier to describe imperatively with code than to invent (and learn!) A new declarative language, which will always be more limited than the native language of the platform. In addition, it is necessary to provide a sandbox, error handling, some stage of piloting - the pseudo-code should gradually spread to user devices and roll back if there are any failures. All this complicates the development without tangible benefits.
CSS 3000
We do not use the description of component styles, since they can vary from form factor, platform, and even mode of operation (portrait / landscape orientation, responsive on the web). Style declarations in the final implementation will always be better, closer to reality and work more correctly with boundary cases. In addition, it happens that components with similar logic work fundamentally differently on different devices: for example, entering a phone number - with the phone book on a mobile device and without it on the web.
Fixing the data model in the application interface
This method is also called "nailing." The point is that the application interface is built on the unique identifiers of objects that are transmitted from the server. In such a scheme, any changes on the server side lead to the processing of the client part. Cannot reuse code. It’s hard to maintain.
The only reason you should choose this method on your project is 99% confidence that the API will not change. Well, or if the project is very small and designing an API is more expensive than quickly remaking the user interface for changes to the API.
Styles
Add a style attribute to each object. UI applications are built on the basis of this feature. There are a limited number of styles, so it becomes possible to build the interface dynamically. But with an increase in the functionality of the UI, one has to increase the number of styles.
In this option, it becomes possible to control the display of individual elements, but the complexity of implementing the connection between different fields increases. And most importantly - with the increasing variability of the UI, you will have a constant need to expand the API protocol.
JSON API
The JSON API детально описаны рекомендации по структурированию данных и описанию взаимосвязей между ними, но нет ничего, что могло бы описывать представление. Наша задача затрагивает в том числе визуальное расширение – добавление новых полей ввода, так что такой вариант нам не подходит.
Web Components / React Components API
Концепция веб-компонентов, которая в том числе значительно повлияла на API компонентов React, нам подходит уже намного лучше: с одной стороны, у нас есть контроль за отображением, с другой стороны – есть возможность привязывать данные к элементам UI.
К сожалению, всё слишком сильно завязано на HTML + CSS + JS. Напрямую не используешь, но запомним – потом пригодится.
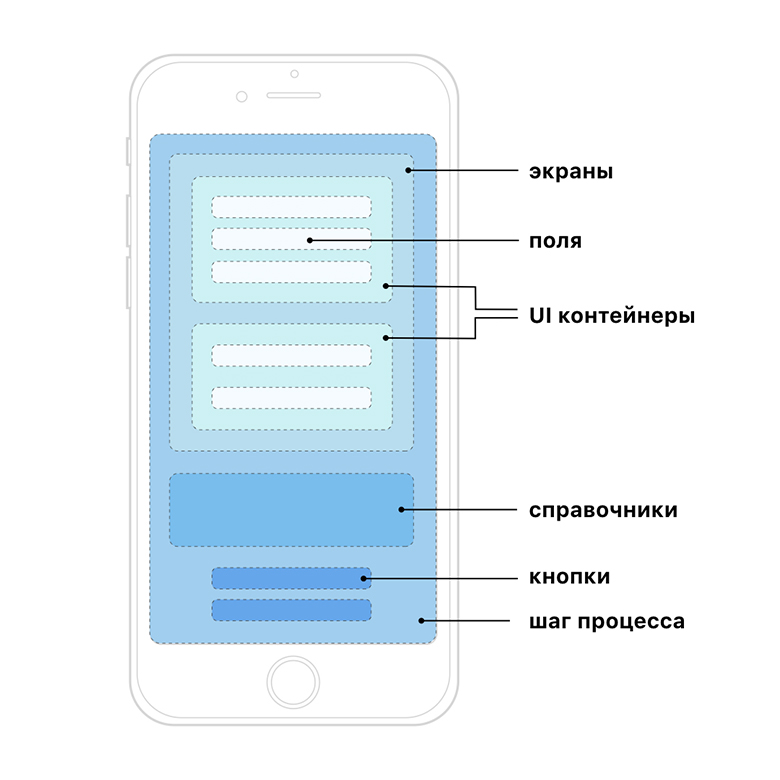
UI containers
Objects are packed into containers, we build presentation logic of the application on these containers. The main advantage is that we can group several simple objects into one container. This gives freedom to program UX / UI on the client, for example, we can control the hiding / displaying of one field when filling in data in another. Moreover, the basic types of objects are a limited number, and all business transport is implemented on them.
We have chosen this approach. First we describe the API protocol, and then how the frameworks are arranged inside mobile and web applications.
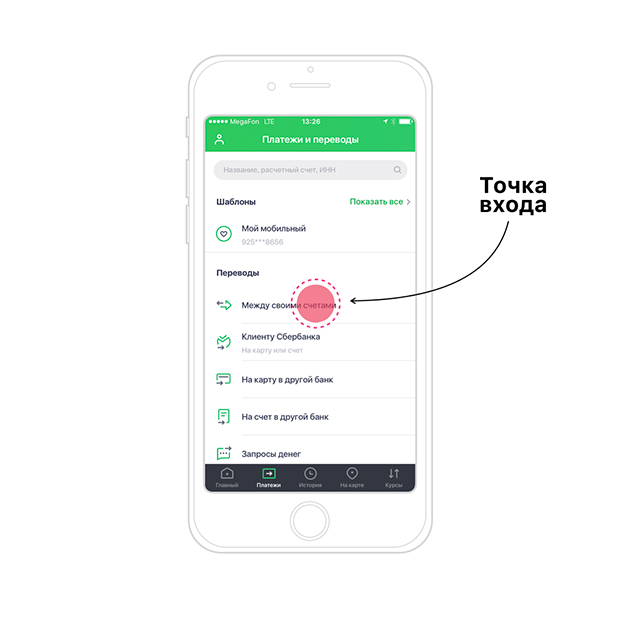
To make it clearer, let's look at the API using an example of a simple process, for example, a transfer between your accounts. How we get to the entry point, we don’t consider - this is not a process and for this we have our own API (we will also talk about it somehow). In total, the process starts at the entry point:
To begin with, we will agree on the basic principles - how to transmit data. We take the simplest approach as a basis - key-value pairs. The key is a string of letters of the Latin alphabet, the value is also strings, but already arbitrary.
Forms for filling are complex, with nested elements and subsections, which means that nesting must be allowed. You can name keys in camelCase format, but they can be poorly readable (for example, in the logs) or even “spoil” in case-insensitive systems. You must enter a separator.
The most obvious delimiter, the dot, is used in many languages to access object properties. With careless use, keys with such a separator will create dictionaries (or objects) in which collisions are possible. For example, “foo.bar” = “foobar” and “foo.bar.baz” = “foobarbaz” in javascript can overwrite the “bar” property of the “foo” object from a string to the object. In the end, we agreed on a colon: on the one hand, explicit visual separation and semantic reflection of nesting, on the other hand, is quite safe for all languages used.
What to do with repeatable fields? We introduce an additional rule: between a pair of delimiters there can be either Latin letters or numbers. We get constructions of the form: children: 5: name: first .
Having lived for some time with such a structure, we find a limitation: multiple choice is not trivial to implement and requires additional tricks on the backend to hold a high load.
Solution: value is either a string or a list of strings. So the solution looks typical, but at the same time, the overhead is insignificant.
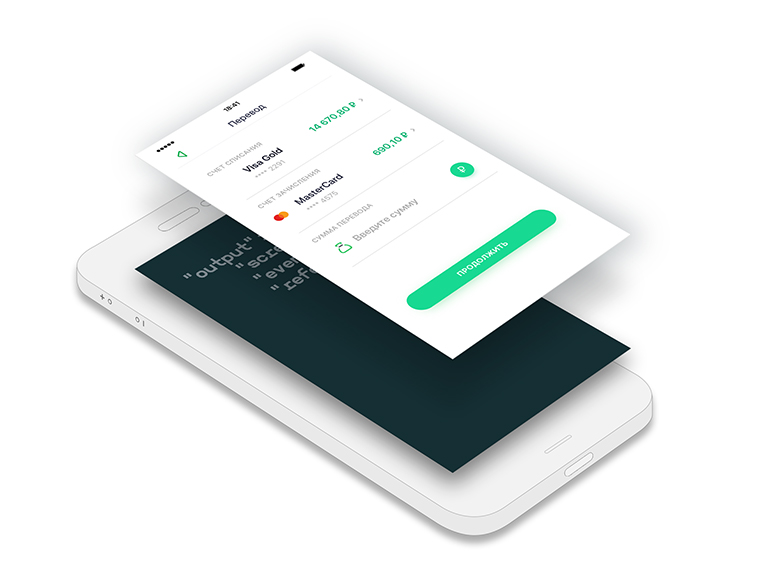
A step is a state of a process. The first step with us is the selection of the debiting account and the crediting account and entering the amount.

The UI in this picture is not visible, because the step is about server logic, and not about presentation logic. There are two approaches to working with steps: you can transfer only the difference from the server (cumulative total in the client application) or each step as a whole (cumulative total on the server).
An analysis of the requirements showed that during the process the screen can be formed differently at different steps (branching of the processes), therefore, instead of adding control commands to convert already transferred entities, it is easier to transfer each step completely in the way the user should see it.
Of the additional advantages: when returning to editing, you do not need to play the entire script or pass an additional parameter “give everything”. At the start of the step, the client application immediately receives all the necessary information for building screens.
The screen is a division of the process into stages in the client application. Screens are typically used to make the form easier to read. In our case, everything is simple: one step - one screen.
For the screens, we introduced two rules:
This means that screens, in fact, become simple groups and can be transferred from the backend immediately upon entering a step.
UI component - an independent component that implements client logic and fills the document with data. In essence, this is an association between the management team in the protocol and a piece of code and markup in the application. The first screen has three components:

Sometimes, something may go wrong: for example, a new process was transferred to the old version of the application or the old version of the block was deleted in the client application, but remained in one of the server application processes. In this case, the application performs soft degradation: the block is replaced by a system (a simple group of fields), which does not have any additional logic, but simply shows the fields in the composition. More details will be below.
In this case, the form will be less beautiful, but at least the user can fill in the data and send it to the server. Then the server will validate the input and return errors that can be fixed.
Fields are atomic components that act as a transport for individual data elements and process user input in case of block degradation. There are a limited number of field types and all of them are supported at the framework level: text, checkbox, select, multiselect.
This means that any version of the application can draw an interface based on field types only.
Fields in the UI components from our example:
1. A field with a link to the directory in the write-off account and the transfer account. Why link to a static directory? Because we select the account from the list of cards (accounts), without unnecessary access to the server.
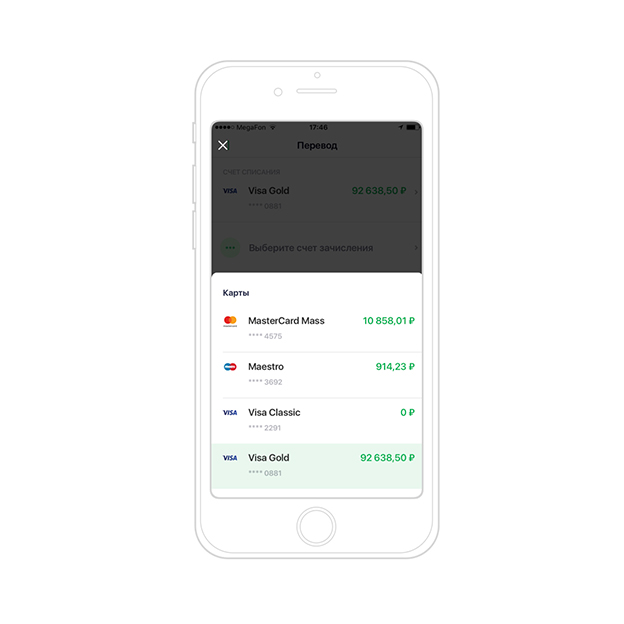
2. Two separate fields for the amount and currency in the input component of the sum

Thus, the format for the fields has the following structure:
Since applications do not know anything about the process, it is logical that the events (buttons that the user sees) are also part of the response from the server.
We divided events into two types.
1) Basic - they are on almost every screen in the usual places for the user. As an example, these are the events “backward” and “continue”. The first moves one step back, and the second collects the completed data from the client form and sends it to the server along with the "Go to the next step" command.
2) And special ones - for non-standard actions that we cannot predict in advance, and there is no sense in laying them in part of the engine, since they are rarely used.
In our case, only the main events on the screen are “continue” and “back”. They are implemented at the platform level.

All events have a number of attributes, such as the type of event itself, title and sign of visibility. And no UI on the server side like button size, position and color. This logic is implemented at the front.
With reference books everything is standard. If it is small, then we send it completely in response from the server and call it static. This is done in order to minimize the number of requests to the server-side and the response time to user action in the interface. To display it in a form on the screen, add a field with the type - selectList, one of the properties of which is a link to a static directory.
If the directory is large, then it is implemented as a separate rest service. In the interface, it looks like a text field, as it fills up, a list of possible options is returned from the directory.
Since the main interface element is the data input field, it is logical to validate it on the client. Validation rules and messages are sent along with the fields, which are displayed if validation fails.
The structure of the answer looks something like this:
Now a little about how frameworks inside applications work with this protocol. Conditionally, frameworks can be divided into two main parts: workflow engine + UI container handler. This separation is caused not only by application architecture, but also by organizational structure. The engine is developed and supported by platform commands, and UI containers are actually extension points and feature commands program them. Thus, more teams do not need to make changes to the kernel.
The engine inside the application (web and mobile) knows that the process of working with the document has begun and that according to the protocol it will receive a number of attributes: steps, screens, UI containers and field types. On this data, the basic interface is drawn - the lower and upper menus, the main buttons, UI on simple types of fields, if used.
At the same time, the engine does not know exactly how many steps of the process will be in the script, how the steps will be divided on the screens, and what fields there will be.
If the scenario changes, for example, if you need to display a new field, then it will be enough to add it to the server’s response, and the client application will display it. For this, releasing a front-end application release is not required.
An analysis of the needs of designers and business customers has shown that it will not be possible to satisfy all needs by simply expanding the attribute structure of the fields.
Therefore, extension points were needed. These expansion points are UI components - this is the native implementation of the code in the applications themselves, which is identified by the engine by name. In essence, this is a grouping of a field / several fields into a logical unit that can display a custom UI. Moreover, the protocol data model is used only for transporting data to the backend, the entire UX and UI are implemented on the application side.
Two framework modes
When the engine parses the data model, it compares the list of names of UI containers with the registry, which is stored inside the application. If the application does not find the name of the component, then the interface is built on simple types of fields. The process will be fully operational, but on standard UI elements.
On the left is how a container can be displayed for entering a sum on a list of simple field types. Right - if there is a UI container in the application assembly. Despite the fact that in the list of simple fields there is no slider and there is a separate field instead of an icon with a currency choice, we can transfer all the data from PL and the process will work.
And here we get one of the main advantages of the engine - to deliver changes to the user without updating the application. In the assembly, there is a mapping of component names to classes in which the UI of these components is programmed and the user interface is built on it.
What rules we try to adhere to when working with UI components:
We tried very hard to write concisely, but this is the first technical article about the Sberbank Online platform and it had to cover a lot.
Write in the comments what is not clear, what is interesting - we will try to write less, but more often and on purpose. We have many interesting challenges, and therefore a lot of material.
The authors:
There will not be a big date, blockchain, agile or other rocket science. But the API on which our most popular applications work will be described. The value of this article is not in breakthrough ideas, but in approaches and practices that work in a large application with one of the most demanding audiences.
We hope that our experience will help readers to make their product better, and most importantly scalable, because most of the cones in the development of the API we have already caught and fixed.
What will be discussed
We will tell you how payment scenarios work in Sberbank Online’s mobile and web applications, namely, about the API between applications and the server-side.
Why focus on API? Everything is simple - this is actually the only bridge that connects client applications and the backend. If the project is small, then we can easily change the API and rewrite applications for it. But if the project is large-scale (such as ours), then even small API changes require the involvement of a large amount of resources both on the front and on the backend, and become very expensive. And the second point - the earlier we fixed the API, the earlier the front and back teams can begin development. They just need to come together at one point.
First, we will talk a little about our capabilities and limitations, so that it is clear why we chose this and not another solution, and then we will present the API protocol itself at the top level.
Specificity and Motivation
The applications are great. When we wrote this article, the Sberbank Online application on Android occupied about 800,000 lines of code, on iOS - 500,000 lines of code. And this is just our code, without plug-in libraries.
Backward compatibility and many users. MAU - 32 million active users of the mobile application. And if we do not do backward compatibility at the API level, so many users across the country will have to download applications again. This is very bad. By the way, this is one of the reasons why we have so much code.
Sberbank Online develops many small teams. You probably heard about Agile at Sberbank. It’s true, we work on Agile in teams of 9 people.
Banking application:despite the fact that the functionality of banking applications is growing very rapidly, the main thing that happens in remote banking is a sequential process (processing of client applications). We call such processes workflow. These applications can be of various kinds and they are processed by a huge number of interconnected services in the perimeter of the bank.
Two types of teams. There are platform ones - they are responsible for developing the application core. And there are feature commands - they create application functionality for end users, using the architecture and tools that the platform provides.
Omnichannel.A very important story. In order not to develop backing several times — separately for mobile applications and separately, for example, for the web version and ATMs, you need to make the API as similar as possible for all channels (at least the answer structure should be the same).
Mobile app
Data changes dynamically. The most popular operations in a mobile application are payment and transfer. Details of service providers, a set of fields that a user needs to fill out, is dynamic information that can change frequently.
However, users may not update the application after installing it on the device. Just because they can. More often there are good reasons for this, for example, to update the application you need to update the OS version, and for this, buy a new phone. Therefore, we need a solution that allows us to change data without releasing the application.
Mobile Internet:Our applications should work everywhere, even where the Internet is unstable and slow. Therefore, we always fight for the size and number of messages between mobile applications and the server side.
Best customer experience: we have chosen for ourselves the basic technology for the development of mobile applications - development in native languages. This is the only way to get the best customer experience.
If to summarize all these requirements, applications should be developed in native languages, have reusable components inside themselves, but at the same time, all business logic should be managed by the server.
How not to do
After we have identified the boundary conditions, we will tell you what existing solutions we have analyzed.
Programming in JSON
Logic is easier to describe imperatively with code than to invent (and learn!) A new declarative language, which will always be more limited than the native language of the platform. In addition, it is necessary to provide a sandbox, error handling, some stage of piloting - the pseudo-code should gradually spread to user devices and roll back if there are any failures. All this complicates the development without tangible benefits.
CSS 3000
We do not use the description of component styles, since they can vary from form factor, platform, and even mode of operation (portrait / landscape orientation, responsive on the web). Style declarations in the final implementation will always be better, closer to reality and work more correctly with boundary cases. In addition, it happens that components with similar logic work fundamentally differently on different devices: for example, entering a phone number - with the phone book on a mobile device and without it on the web.
Fixing the data model in the application interface
This method is also called "nailing." The point is that the application interface is built on the unique identifiers of objects that are transmitted from the server. In such a scheme, any changes on the server side lead to the processing of the client part. Cannot reuse code. It’s hard to maintain.
The only reason you should choose this method on your project is 99% confidence that the API will not change. Well, or if the project is very small and designing an API is more expensive than quickly remaking the user interface for changes to the API.
Styles
Add a style attribute to each object. UI applications are built on the basis of this feature. There are a limited number of styles, so it becomes possible to build the interface dynamically. But with an increase in the functionality of the UI, one has to increase the number of styles.
In this option, it becomes possible to control the display of individual elements, but the complexity of implementing the connection between different fields increases. And most importantly - with the increasing variability of the UI, you will have a constant need to expand the API protocol.
JSON API
The JSON API детально описаны рекомендации по структурированию данных и описанию взаимосвязей между ними, но нет ничего, что могло бы описывать представление. Наша задача затрагивает в том числе визуальное расширение – добавление новых полей ввода, так что такой вариант нам не подходит.
Web Components / React Components API
Концепция веб-компонентов, которая в том числе значительно повлияла на API компонентов React, нам подходит уже намного лучше: с одной стороны, у нас есть контроль за отображением, с другой стороны – есть возможность привязывать данные к элементам UI.
К сожалению, всё слишком сильно завязано на HTML + CSS + JS. Напрямую не используешь, но запомним – потом пригодится.
Как решили делать
UI containers
Objects are packed into containers, we build presentation logic of the application on these containers. The main advantage is that we can group several simple objects into one container. This gives freedom to program UX / UI on the client, for example, we can control the hiding / displaying of one field when filling in data in another. Moreover, the basic types of objects are a limited number, and all business transport is implemented on them.
We have chosen this approach. First we describe the API protocol, and then how the frameworks are arranged inside mobile and web applications.
API
To make it clearer, let's look at the API using an example of a simple process, for example, a transfer between your accounts. How we get to the entry point, we don’t consider - this is not a process and for this we have our own API (we will also talk about it somehow). In total, the process starts at the entry point:
Data transport
To begin with, we will agree on the basic principles - how to transmit data. We take the simplest approach as a basis - key-value pairs. The key is a string of letters of the Latin alphabet, the value is also strings, but already arbitrary.
Forms for filling are complex, with nested elements and subsections, which means that nesting must be allowed. You can name keys in camelCase format, but they can be poorly readable (for example, in the logs) or even “spoil” in case-insensitive systems. You must enter a separator.
The most obvious delimiter, the dot, is used in many languages to access object properties. With careless use, keys with such a separator will create dictionaries (or objects) in which collisions are possible. For example, “foo.bar” = “foobar” and “foo.bar.baz” = “foobarbaz” in javascript can overwrite the “bar” property of the “foo” object from a string to the object. In the end, we agreed on a colon: on the one hand, explicit visual separation and semantic reflection of nesting, on the other hand, is quite safe for all languages used.
What to do with repeatable fields? We introduce an additional rule: between a pair of delimiters there can be either Latin letters or numbers. We get constructions of the form: children: 5: name: first .
Having lived for some time with such a structure, we find a limitation: multiple choice is not trivial to implement and requires additional tricks on the backend to hold a high load.
Solution: value is either a string or a list of strings. So the solution looks typical, but at the same time, the overhead is insignificant.
Steps
A step is a state of a process. The first step with us is the selection of the debiting account and the crediting account and entering the amount.
The UI in this picture is not visible, because the step is about server logic, and not about presentation logic. There are two approaches to working with steps: you can transfer only the difference from the server (cumulative total in the client application) or each step as a whole (cumulative total on the server).
An analysis of the requirements showed that during the process the screen can be formed differently at different steps (branching of the processes), therefore, instead of adding control commands to convert already transferred entities, it is easier to transfer each step completely in the way the user should see it.
Of the additional advantages: when returning to editing, you do not need to play the entire script or pass an additional parameter “give everything”. At the start of the step, the client application immediately receives all the necessary information for building screens.
"output":
"screens":
"events":
"references":Screens
The screen is a division of the process into stages in the client application. Screens are typically used to make the form easier to read. In our case, everything is simple: one step - one screen.
For the screens, we introduced two rules:
- the transition between screens can only be linear, without branching;
- switching between screens does not require interactions with the backend.
This means that screens, in fact, become simple groups and can be transferred from the backend immediately upon entering a step.
"screens":
"title":
"UI Block":
"properties":UI components (blocks)
UI component - an independent component that implements client logic and fills the document with data. In essence, this is an association between the management team in the protocol and a piece of code and markup in the application. The first screen has three components:
- Write-off account
- The same component for an enrollment account
- Transfer amount
Sometimes, something may go wrong: for example, a new process was transferred to the old version of the application or the old version of the block was deleted in the client application, but remained in one of the server application processes. In this case, the application performs soft degradation: the block is replaced by a system (a simple group of fields), which does not have any additional logic, but simply shows the fields in the composition. More details will be below.
In this case, the form will be less beautiful, but at least the user can fill in the data and send it to the server. Then the server will validate the input and return errors that can be fixed.
"UI Block":
"type":
"properties":
"field": Fields
Fields are atomic components that act as a transport for individual data elements and process user input in case of block degradation. There are a limited number of field types and all of them are supported at the framework level: text, checkbox, select, multiselect.
This means that any version of the application can draw an interface based on field types only.
Fields in the UI components from our example:
1. A field with a link to the directory in the write-off account and the transfer account. Why link to a static directory? Because we select the account from the list of cards (accounts), without unnecessary access to the server.
2. Two separate fields for the amount and currency in the input component of the sum
Thus, the format for the fields has the following structure:
"field":
"id":
"type":
"title":
"value":
"style":
"validator":
Events
Since applications do not know anything about the process, it is logical that the events (buttons that the user sees) are also part of the response from the server.
We divided events into two types.
1) Basic - they are on almost every screen in the usual places for the user. As an example, these are the events “backward” and “continue”. The first moves one step back, and the second collects the completed data from the client form and sends it to the server along with the "Go to the next step" command.
2) And special ones - for non-standard actions that we cannot predict in advance, and there is no sense in laying them in part of the engine, since they are rarely used.
In our case, only the main events on the screen are “continue” and “back”. They are implemented at the platform level.
All events have a number of attributes, such as the type of event itself, title and sign of visibility. And no UI on the server side like button size, position and color. This logic is implemented at the front.
"events":
"name":
"type":
"title":
"description":Directories
With reference books everything is standard. If it is small, then we send it completely in response from the server and call it static. This is done in order to minimize the number of requests to the server-side and the response time to user action in the interface. To display it in a form on the screen, add a field with the type - selectList, one of the properties of which is a link to a static directory.
If the directory is large, then it is implemented as a separate rest service. In the interface, it looks like a text field, as it fills up, a list of possible options is returned from the directory.
"references":
"referenceId":Validation errors on client and server
Since the main interface element is the data input field, it is logical to validate it on the client. Validation rules and messages are sent along with the fields, which are displayed if validation fails.
"validator":
"value":
"message":
"type":The structure of the answer looks something like this:
"output":
"screens":
"title":
"UI Block":
"type":
"properties":
"field":
"id":
"type":
"title":
"value":
"style":
"validator":
"value":
"message":
"type":
"properties":
"events":
"name":
"type":
"title":
"description":
"references":
"referenceId":Frameworks
Now a little about how frameworks inside applications work with this protocol. Conditionally, frameworks can be divided into two main parts: workflow engine + UI container handler. This separation is caused not only by application architecture, but also by organizational structure. The engine is developed and supported by platform commands, and UI containers are actually extension points and feature commands program them. Thus, more teams do not need to make changes to the kernel.
Workflow engine
The engine inside the application (web and mobile) knows that the process of working with the document has begun and that according to the protocol it will receive a number of attributes: steps, screens, UI containers and field types. On this data, the basic interface is drawn - the lower and upper menus, the main buttons, UI on simple types of fields, if used.
At the same time, the engine does not know exactly how many steps of the process will be in the script, how the steps will be divided on the screens, and what fields there will be.
If the scenario changes, for example, if you need to display a new field, then it will be enough to add it to the server’s response, and the client application will display it. For this, releasing a front-end application release is not required.
How do UI containers work?
An analysis of the needs of designers and business customers has shown that it will not be possible to satisfy all needs by simply expanding the attribute structure of the fields.
Therefore, extension points were needed. These expansion points are UI components - this is the native implementation of the code in the applications themselves, which is identified by the engine by name. In essence, this is a grouping of a field / several fields into a logical unit that can display a custom UI. Moreover, the protocol data model is used only for transporting data to the backend, the entire UX and UI are implemented on the application side.
Two framework modes
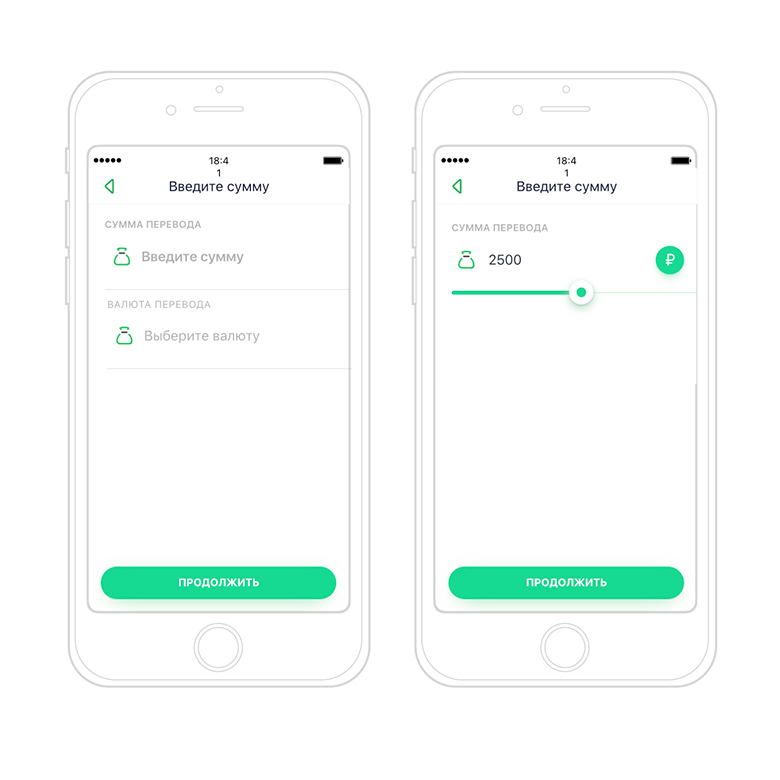
When the engine parses the data model, it compares the list of names of UI containers with the registry, which is stored inside the application. If the application does not find the name of the component, then the interface is built on simple types of fields. The process will be fully operational, but on standard UI elements.
On the left is how a container can be displayed for entering a sum on a list of simple field types. Right - if there is a UI container in the application assembly. Despite the fact that in the list of simple fields there is no slider and there is a separate field instead of an icon with a currency choice, we can transfer all the data from PL and the process will work.
And here we get one of the main advantages of the engine - to deliver changes to the user without updating the application. In the assembly, there is a mapping of component names to classes in which the UI of these components is programmed and the user interface is built on it.
What rules we try to adhere to when working with UI components:
- Maintain the functionality of the functional in the list mode of simple field types. Any application project is tempted to turn a dynamic protocol into a static one. Therefore, we ask everyone to first develop functionality on a typical UI container, and then enrich the UX / UI by adding custom containers on this data model. This will not only allow future processes to be updated on older builds, but will automatically support the logical integrity of the API.
- Не менять модель данных (JSON) для UI-контейнера, если он уже готов (проходит финальное тестирование или уже в продакшене). Так как логика на PL жестко связана с моделью данных, её изменение сломает функционал на версиях мобильного приложения, которые не обновляются. Тем не менее, модель можно расширять при условии сохранения обратной совместимости.
- Называть свой UI-компонент системным именем. Так как имя UI-компонента – обязательный атрибут протокола и должен быть минимум один на каждом экране, мы ввели специальное системное имя, которые реализует простой список полей.
- Не реализовывать бизнес-логику на UI-компонентах. Логику необходимо реализовывать на сервере, почему – писали выше.
Coming soon…
We tried very hard to write concisely, but this is the first technical article about the Sberbank Online platform and it had to cover a lot.
Write in the comments what is not clear, what is interesting - we will try to write less, but more often and on purpose. We have many interesting challenges, and therefore a lot of material.
The authors:
- dmitry_zadorin Dmitry Zadorin, working on Sberbank Online in the team "Integration Platform", Digital Business Platform, Sberbank and Sberteh
- stcherenkov Stas Cherenkov, architect of the web application Sberbank Online, Sberbank and Sberteh