Distributed architecture concepts I met when building a large payment system
- Transfer
I joined Uber two years ago as a mobile developer with some experience in backend development. Here I was developing the functionality of payments in the application - and in the process rewrote the application itself . After which I moved to the development management and headed the team itself. Thanks to this, I was able to get to know the backend much closer, because my team is responsible for many of our backend systems that allow payments.
Prior to my work at Uber, I had no experience with distributed systems. I received a traditional education in Computer Science, after which I was engaged in full-stack development for a decade. Therefore, even if I could draw various diagrams and talk about compromises (tradeoffs ) systems, by the time I was not well understood and perceived the concept of distributed - such as for example consistency ( consistency ), availability ( availability Available ) or idempotency ( idempotency ).
In this post, I’m going to talk about several concepts that I needed to study and put into practice when building the large-scale high-availability distributed payment system that today works in Uber. This is a system with a load of up to several thousand requests per second, in which the critical functionality of payments should work correctly even in cases where certain parts of the system stop working.
Is this a complete list? Probably not. However, if I personally learned about these concepts before, it would make my life much easier.
So, let's get down to our immersion in SLA, consistency, data longevity, message security, idempotency, and some other things that I needed to learn at my new job.
In large systems that process millions of events per day, some things are simply, by definition, bound to go wrong. That’s why, before diving into system planning, the most important step is to make a decision about what a “healthy” system means to us. The degree of “health” should be something that can actually be measured. The generally accepted way to measure the “health” of a system is SLA ( service level agreements ). Here are some of the most common types of SLAs I have encountered in practice:
Why are SLAs needed when creating a large payment system? We are creating a new system to replace the existing one. To make sure that we are doing everything right, and that our new system will be “better” than its predecessor, we used SLA to determine our expectations from it. Availability was one of the most important requirements. Once we set a goal, we needed to deal with compromises in architecture in order to achieve these targets.
As the business that uses our freshly created system grows, the load on it will only increase. At some point, the existing installation will not be able to withstand a further increase in load, and we will need to increase the permissible load. Two common scaling strategies are vertical or horizontal scaling.
Horizontal scaling is to add a large number of machines (or nodes) in the system to increase the bandwidth ( capacity ). Horizontal scaling is the most popular way to scale distributed systems.
Vertical scaling is essentially “buy a bigger / stronger machine” - a (virtual) machine with more cores, better processing power and more memory. In the case of distributed systems, vertical scaling is usually less popular because it can be more expensive than horizontal scaling. However, some well-known large sites, such as Stack Overflow, have successfully scaled vertically to fit the load.
Why does a scaling strategy make sense when you create a large payment system?At an early stage, we decided that we would build a system that would scale horizontally. Despite the fact that vertical scaling is acceptable in some cases, our payment system had already reached the predicted load by that time and we were pessimistic about the assumption that the only super-expensive mainframe could withstand this load today, not to mention the future . In addition, our team included several people who worked in large providers of payment services and had negative experience trying to scale vertically even on the most powerful machines that could be bought for money in those years.
The availability of any of the systems is important. Distributed systems are often built from machines whose availability individually is lower than the availability of the entire system. Let our goal be to build a system with an availability of 99.999% (downtime is approximately 5 minutes / year). We use machines / nodes that have an average of 99.9% availability (they are in downtime for about 8 hours / year). A direct way to achieve the accessibility indicator we need is to add a few more of these machines / nodes to the cluster. Even if some of the nodes are “down”, others will continue to remain in service and the overall availability of the system will be higher than the availability of its individual components.
Consistency is a key issue in highly accessible systems. The system is consistent if all nodes see and return the same data at the same time. Unlike our previous model, when we added more nodes to achieve greater accessibility, making sure that the system remains consistent is far from trivial. To ensure that each node contains the same information, they must send messages to each other in order to be constantly synchronized. However, the messages they send to each other may not be delivered — they may be lost and some of the nodes may not be available.
Consistency is a concept that took me the most time to realize before I understood and appreciated it. Existmore consistency species most commonly used in distributed systems is a strong coherence ( strong consistency ), the weak consistency ( weak consistency ) and the consistency in the end ( eventual consistency ). You can read a useful practical discussion of the advantages and disadvantages of each of the models in this article . Usually, the weaker the required level of consistency, the faster the system can work - but the more likely it is that it will not return the most recent data set.
Why is consistency worth considering when creating a large payment system?Data in the system must be consistent. But how much are agreed? For some parts of the system, only highly consistent data is suitable. For example, we need to keep in a very consistent form the information that the payment has been initiated. For other parts of the system that are not so important, consistency can ultimately be considered a reasonable compromise.
This is well illustrated by the conclusion of a list of recent transactions: they can be implemented using eventual consistency - that is, the last transaction can appear in some parts of the system only some time later, but thanks to this, a list query will return a result with a lower delay or will require less resources to complete.
Durability means that once the data has been successfully added to the data warehouse, it will be available to us in the future. This will be true even if the nodes of the system go offline, they will fail or the data of the nodes will be damaged.
Different distributed databases have different levels of data longevity. Some of them support data durability at the machine / node level, others do it at the cluster level, and some do not provide this functionality out of the box. Some form of replication is usually used to increase durability - if the data is stored on several nodes and one of the nodes stops working, the data will still be available. Here is a good articleexplaining why achieving longevity in distributed systems can be a serious challenge.
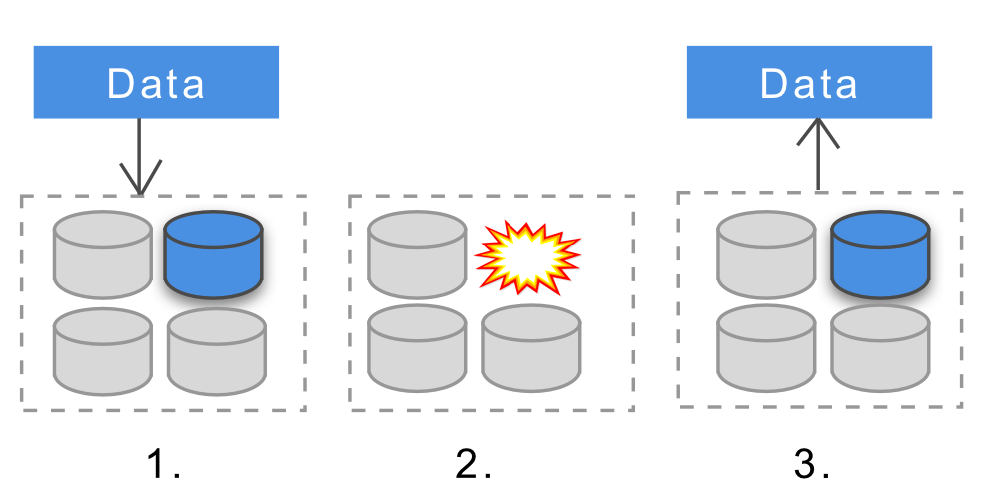
Why does data durability matter when building a payment system? If the data is critical (for example, payments), then we cannot afford to lose it in many of the parts of our system. The distributed data warehouses that we built had to maintain data longevity at the cluster level - so even if the instances “fall”, completed transactions will be saved. Nowadays, most distributed storage services - like Cassandra, MongoDB, HDFS or Dynamodb - all support durability at various levels and can all be configured to provide cluster-level durability.
Nodes in distributed systems perform calculations, store data, and send messages to each other. A key characteristic of sending messages is how reliably these messages arrive. For critical systems, there is often a requirement that none of the messages be lost.
In the case of distributed systems, messaging is usually done using some distributed messaging service - RabbitMQ, Kafka or others. These message brokers can support (or are configured to support) various levels of message delivery reliability.
The safety of the message means that when a failure occurs on the node that processes the message, the message will still be available for processing after the problem is resolved. Message longevity is typically used at the message queue level . Using a long message queue, if the queue (or node) goes offline when the message is sent, it will still receive the message when it returns online. A good detailed article on this subject is available here .

Why does the safety and durability of messages matter when building large payment systems?We had messages that we could not afford to lose - for example, a message that a person initiated a payment to pay for a trip. This meant that the messaging system that we were supposed to use was supposed to work without loss: each message had to be delivered once. However, the creation of a system that delivers each message exactly once than at least once is a task that varies considerably in its difficulty. We decided to implement a messaging system that delivers at least once, and chose a messaging bus , on top of which we decided to build it (we opted for Kafka, creating a lossless cluster, which was required in our case).
In the case of distributed systems, anything can go wrong - connections may fall off in the middle or requests may fall out by timeout. Customers will often repeat these requests. An idempotent system ensures that no matter what happens, and no matter how many times a particular request is executed, the actual execution of this request occurs only once. A good example is making a payment. If the client creates a payment request, the request is successful, but if the client falls into timeout, then the client can repeat the same request. In the case of an idempotent system, money will not be deducted twice from the person making the payment; but for a non-idemponent system this is quite a possible occurrence.
Designing idempotent distributed systems requires some kind of distributed locking strategy. This is where the concepts we discussed earlier come into play. Let's say we intend to realize idempotency using optimistic locking to avoid concurrent updates. In order for us to resort to optimistic locking, the system must be strictly coordinated - thanks to which, during the operation, we can check whether another operation has been started using some form of versioning.
There are many ways to achieve idempotency, and each particular choice will depend on the limitations of the system and the type of operation performed. Designing idempotent approaches is a worthy challenge for the developer - just look at the postsBen Nadela, in which he talks about the various strategies that he used , which include distributed locks and database constraints . When you design a distributed system, idempotency can easily turn out to be one of the parts that you have lost sight of. In our practice, we were faced with cases in which my team was "burnt" on the fact that I was not convinced of the presence of the correct idempotency for some key operations.
Why does idempotency matter when building a large payment system?Most important: to avoid double charges and double refunds. Given that our messaging system has “at least once, lossless” delivery, we must assume that all messages can be delivered several times and systems must guarantee idempotency. We decided to handle this with versioning and optimistic locking, where our systems implement idempotent behavior using strictly consistent storage as their data source.
Distributed systems often need to store much more data than a single node can afford. So how do we save the data set on the right number of machines? The most popular technique for this is sharding . Data is horizontally partitioned using some hash assigned to the partition. Although many distributed databases today implement sharding under their hood, it is an interesting topic in itself that is worth exploring - especially resharding . Foursquare had a 17-hour downtime in 2010 due to sharding on the edge case, after which the company shared an interesting post-mortem that shed light on the root of the problem.
Many distributed systems have data or calculations that are replicated between multiple nodes. To make sure that the operations are carried out in a coordinated manner, a voting approach is determined in which to recognize the operation as successful, it is necessary that a certain number of nodes receive the same result. This process is called quorum.
Why do quorum and sharding make sense when building a large payment system in Uber? Both of these concepts are simple and are used almost universally. I met them when we set up replication in Cassandra. Cassandra (and other distributed systems) uses quorum and local quorum ( local quorum ) in order to ensure consistency between the clusters.
The familiar vocabulary that we use to describe programming practices — things like variables, interfaces, method calls — involves systems from one machine. When we talk about distributed systems, we must use other approaches. A common way to describe such systems is the actor model , in which we see the code in terms of communication. This model is popular due to the fact that it coincides with the mental model of how we imagine, for example, the interaction of people in an organization. Another, no less popular way of describing distributed systems is CSP, interacting sequential processes .
The actor model is based on actors who send messages to each other and respond to them. Each actor can do a limited set of things - create other actors, send messages to others, or decide what to do with the next message. With the help of a few simple rules, we can fairly well describe complex distributed systems that can recover themselves after the actor “falls”. If you are not familiar with this approach, then I recommend you the article Model actors in 10 minutes by Brian Storty . For many languages, there are libraries or frameworks that implement the actor model . For example, at Uber, we use Akka for some of our systems.
Why does it make sense to apply the actor model in a large payment system? Many engineers took part in the development of our system, most of whom already had experience working with distributed systems. We decided to follow a standard distributed model instead of engaging in “bicycles” and inventing our own distributed principles.
When building large distributed systems, the goal is usually to make them fault tolerant, flexible and scalable. Whether it’s a payment system or some other highly loaded system, the patterns for achieving what you want can be the same. Those involved in such systems regularly discover and disseminate best practices for building them - and reactive architecture is a similarly popular and widely used pattern.
To familiarize yourself with reactive architecture, I suggest reading the Jet Manifesto ( in Russian ) and watching a 12-minute video link .
Why does reactive architecture make sense if you are creating a large payment system? AkaThe library we used to create most of our new payment system is heavily influenced by reactive architecture. Many of our engineers who were building this system were already familiar with the best reactive programming practices. Following reactive principles - creating a responsive, fault-tolerant, flexible system based on messages ( message-driven ), we came to this conclusion in a natural way. The ability to have a model that you can rely on and with which you can evaluate the development progress and its direction has been extremely useful, and I will rely on it in the future when creating new systems.
I was lucky to take part in rebuilding a large-scale, distributed and critically important system: one that allows you to work with payments in Uber. Working in this environment, I became acquainted with many distributed concepts that I had never used before. I gathered them here in the hope that the rest will find my story useful to start studying distributed systems or learn something new for myself.
This post was devoted exclusively to the planning and architecture of such systems. There are many different subtleties that are worth talking about - about the construction, deployment and migration of highly loaded systems - and also about their reliable operation; I am going to raise all these topics in subsequent posts.
Prior to my work at Uber, I had no experience with distributed systems. I received a traditional education in Computer Science, after which I was engaged in full-stack development for a decade. Therefore, even if I could draw various diagrams and talk about compromises (tradeoffs ) systems, by the time I was not well understood and perceived the concept of distributed - such as for example consistency ( consistency ), availability ( availability Available ) or idempotency ( idempotency ).
In this post, I’m going to talk about several concepts that I needed to study and put into practice when building the large-scale high-availability distributed payment system that today works in Uber. This is a system with a load of up to several thousand requests per second, in which the critical functionality of payments should work correctly even in cases where certain parts of the system stop working.
Is this a complete list? Probably not. However, if I personally learned about these concepts before, it would make my life much easier.
So, let's get down to our immersion in SLA, consistency, data longevity, message security, idempotency, and some other things that I needed to learn at my new job.
SLA
In large systems that process millions of events per day, some things are simply, by definition, bound to go wrong. That’s why, before diving into system planning, the most important step is to make a decision about what a “healthy” system means to us. The degree of “health” should be something that can actually be measured. The generally accepted way to measure the “health” of a system is SLA ( service level agreements ). Here are some of the most common types of SLAs I have encountered in practice:
- Availability : The percentage of time that a service is operational. Even if there is a temptation to achieve 100% accessibility, achieving this result can turn out to be a really difficult task, and in addition very expensive. Even large and critical systems like the network of VISA cards, Gmail or Internet providers do not have 100% availability - over the years they will accumulate seconds, minutes or hours spent in downtime. For many systems, four nines availability (99.99%, or about 50 minutes of downtime per year ) is considered high availability. In order to get to this level, you have to sweat pretty.
- Accuracy : is data loss acceptable or inaccurate? If so, what percentage is acceptable? For the payment system I was working on, this figure should have been 100%, since the data could not be lost.
- Capacity : What load must the system withstand? This metric is usually expressed in queries per second.
- Latency : How long should the system respond? How long should 95% and 99% of requests be served? In such systems, usually many of the queries are “noise”, so the p95 and p99 delays find more practical application in the real world.
Why are SLAs needed when creating a large payment system? We are creating a new system to replace the existing one. To make sure that we are doing everything right, and that our new system will be “better” than its predecessor, we used SLA to determine our expectations from it. Availability was one of the most important requirements. Once we set a goal, we needed to deal with compromises in architecture in order to achieve these targets.
Horizontal and vertical scaling
As the business that uses our freshly created system grows, the load on it will only increase. At some point, the existing installation will not be able to withstand a further increase in load, and we will need to increase the permissible load. Two common scaling strategies are vertical or horizontal scaling.
Horizontal scaling is to add a large number of machines (or nodes) in the system to increase the bandwidth ( capacity ). Horizontal scaling is the most popular way to scale distributed systems.
Vertical scaling is essentially “buy a bigger / stronger machine” - a (virtual) machine with more cores, better processing power and more memory. In the case of distributed systems, vertical scaling is usually less popular because it can be more expensive than horizontal scaling. However, some well-known large sites, such as Stack Overflow, have successfully scaled vertically to fit the load.
Why does a scaling strategy make sense when you create a large payment system?At an early stage, we decided that we would build a system that would scale horizontally. Despite the fact that vertical scaling is acceptable in some cases, our payment system had already reached the predicted load by that time and we were pessimistic about the assumption that the only super-expensive mainframe could withstand this load today, not to mention the future . In addition, our team included several people who worked in large providers of payment services and had negative experience trying to scale vertically even on the most powerful machines that could be bought for money in those years.
Consistency
The availability of any of the systems is important. Distributed systems are often built from machines whose availability individually is lower than the availability of the entire system. Let our goal be to build a system with an availability of 99.999% (downtime is approximately 5 minutes / year). We use machines / nodes that have an average of 99.9% availability (they are in downtime for about 8 hours / year). A direct way to achieve the accessibility indicator we need is to add a few more of these machines / nodes to the cluster. Even if some of the nodes are “down”, others will continue to remain in service and the overall availability of the system will be higher than the availability of its individual components.
Consistency is a key issue in highly accessible systems. The system is consistent if all nodes see and return the same data at the same time. Unlike our previous model, when we added more nodes to achieve greater accessibility, making sure that the system remains consistent is far from trivial. To ensure that each node contains the same information, they must send messages to each other in order to be constantly synchronized. However, the messages they send to each other may not be delivered — they may be lost and some of the nodes may not be available.
Consistency is a concept that took me the most time to realize before I understood and appreciated it. Existmore consistency species most commonly used in distributed systems is a strong coherence ( strong consistency ), the weak consistency ( weak consistency ) and the consistency in the end ( eventual consistency ). You can read a useful practical discussion of the advantages and disadvantages of each of the models in this article . Usually, the weaker the required level of consistency, the faster the system can work - but the more likely it is that it will not return the most recent data set.
Why is consistency worth considering when creating a large payment system?Data in the system must be consistent. But how much are agreed? For some parts of the system, only highly consistent data is suitable. For example, we need to keep in a very consistent form the information that the payment has been initiated. For other parts of the system that are not so important, consistency can ultimately be considered a reasonable compromise.
This is well illustrated by the conclusion of a list of recent transactions: they can be implemented using eventual consistency - that is, the last transaction can appear in some parts of the system only some time later, but thanks to this, a list query will return a result with a lower delay or will require less resources to complete.
Data durability
Durability means that once the data has been successfully added to the data warehouse, it will be available to us in the future. This will be true even if the nodes of the system go offline, they will fail or the data of the nodes will be damaged.
Different distributed databases have different levels of data longevity. Some of them support data durability at the machine / node level, others do it at the cluster level, and some do not provide this functionality out of the box. Some form of replication is usually used to increase durability - if the data is stored on several nodes and one of the nodes stops working, the data will still be available. Here is a good articleexplaining why achieving longevity in distributed systems can be a serious challenge.
Why does data durability matter when building a payment system? If the data is critical (for example, payments), then we cannot afford to lose it in many of the parts of our system. The distributed data warehouses that we built had to maintain data longevity at the cluster level - so even if the instances “fall”, completed transactions will be saved. Nowadays, most distributed storage services - like Cassandra, MongoDB, HDFS or Dynamodb - all support durability at various levels and can all be configured to provide cluster-level durability.
Message persistence and durability
Nodes in distributed systems perform calculations, store data, and send messages to each other. A key characteristic of sending messages is how reliably these messages arrive. For critical systems, there is often a requirement that none of the messages be lost.
In the case of distributed systems, messaging is usually done using some distributed messaging service - RabbitMQ, Kafka or others. These message brokers can support (or are configured to support) various levels of message delivery reliability.
The safety of the message means that when a failure occurs on the node that processes the message, the message will still be available for processing after the problem is resolved. Message longevity is typically used at the message queue level . Using a long message queue, if the queue (or node) goes offline when the message is sent, it will still receive the message when it returns online. A good detailed article on this subject is available here .
Why does the safety and durability of messages matter when building large payment systems?We had messages that we could not afford to lose - for example, a message that a person initiated a payment to pay for a trip. This meant that the messaging system that we were supposed to use was supposed to work without loss: each message had to be delivered once. However, the creation of a system that delivers each message exactly once than at least once is a task that varies considerably in its difficulty. We decided to implement a messaging system that delivers at least once, and chose a messaging bus , on top of which we decided to build it (we opted for Kafka, creating a lossless cluster, which was required in our case).
Idempotency
In the case of distributed systems, anything can go wrong - connections may fall off in the middle or requests may fall out by timeout. Customers will often repeat these requests. An idempotent system ensures that no matter what happens, and no matter how many times a particular request is executed, the actual execution of this request occurs only once. A good example is making a payment. If the client creates a payment request, the request is successful, but if the client falls into timeout, then the client can repeat the same request. In the case of an idempotent system, money will not be deducted twice from the person making the payment; but for a non-idemponent system this is quite a possible occurrence.
Designing idempotent distributed systems requires some kind of distributed locking strategy. This is where the concepts we discussed earlier come into play. Let's say we intend to realize idempotency using optimistic locking to avoid concurrent updates. In order for us to resort to optimistic locking, the system must be strictly coordinated - thanks to which, during the operation, we can check whether another operation has been started using some form of versioning.
There are many ways to achieve idempotency, and each particular choice will depend on the limitations of the system and the type of operation performed. Designing idempotent approaches is a worthy challenge for the developer - just look at the postsBen Nadela, in which he talks about the various strategies that he used , which include distributed locks and database constraints . When you design a distributed system, idempotency can easily turn out to be one of the parts that you have lost sight of. In our practice, we were faced with cases in which my team was "burnt" on the fact that I was not convinced of the presence of the correct idempotency for some key operations.
Why does idempotency matter when building a large payment system?Most important: to avoid double charges and double refunds. Given that our messaging system has “at least once, lossless” delivery, we must assume that all messages can be delivered several times and systems must guarantee idempotency. We decided to handle this with versioning and optimistic locking, where our systems implement idempotent behavior using strictly consistent storage as their data source.
Sharding and quorum
Distributed systems often need to store much more data than a single node can afford. So how do we save the data set on the right number of machines? The most popular technique for this is sharding . Data is horizontally partitioned using some hash assigned to the partition. Although many distributed databases today implement sharding under their hood, it is an interesting topic in itself that is worth exploring - especially resharding . Foursquare had a 17-hour downtime in 2010 due to sharding on the edge case, after which the company shared an interesting post-mortem that shed light on the root of the problem.
Many distributed systems have data or calculations that are replicated between multiple nodes. To make sure that the operations are carried out in a coordinated manner, a voting approach is determined in which to recognize the operation as successful, it is necessary that a certain number of nodes receive the same result. This process is called quorum.
Why do quorum and sharding make sense when building a large payment system in Uber? Both of these concepts are simple and are used almost universally. I met them when we set up replication in Cassandra. Cassandra (and other distributed systems) uses quorum and local quorum ( local quorum ) in order to ensure consistency between the clusters.
Actor model
The familiar vocabulary that we use to describe programming practices — things like variables, interfaces, method calls — involves systems from one machine. When we talk about distributed systems, we must use other approaches. A common way to describe such systems is the actor model , in which we see the code in terms of communication. This model is popular due to the fact that it coincides with the mental model of how we imagine, for example, the interaction of people in an organization. Another, no less popular way of describing distributed systems is CSP, interacting sequential processes .
The actor model is based on actors who send messages to each other and respond to them. Each actor can do a limited set of things - create other actors, send messages to others, or decide what to do with the next message. With the help of a few simple rules, we can fairly well describe complex distributed systems that can recover themselves after the actor “falls”. If you are not familiar with this approach, then I recommend you the article Model actors in 10 minutes by Brian Storty . For many languages, there are libraries or frameworks that implement the actor model . For example, at Uber, we use Akka for some of our systems.
Why does it make sense to apply the actor model in a large payment system? Many engineers took part in the development of our system, most of whom already had experience working with distributed systems. We decided to follow a standard distributed model instead of engaging in “bicycles” and inventing our own distributed principles.
Reactive architecture
When building large distributed systems, the goal is usually to make them fault tolerant, flexible and scalable. Whether it’s a payment system or some other highly loaded system, the patterns for achieving what you want can be the same. Those involved in such systems regularly discover and disseminate best practices for building them - and reactive architecture is a similarly popular and widely used pattern.
To familiarize yourself with reactive architecture, I suggest reading the Jet Manifesto ( in Russian ) and watching a 12-minute video link .
Why does reactive architecture make sense if you are creating a large payment system? AkaThe library we used to create most of our new payment system is heavily influenced by reactive architecture. Many of our engineers who were building this system were already familiar with the best reactive programming practices. Following reactive principles - creating a responsive, fault-tolerant, flexible system based on messages ( message-driven ), we came to this conclusion in a natural way. The ability to have a model that you can rely on and with which you can evaluate the development progress and its direction has been extremely useful, and I will rely on it in the future when creating new systems.
Conclusion
I was lucky to take part in rebuilding a large-scale, distributed and critically important system: one that allows you to work with payments in Uber. Working in this environment, I became acquainted with many distributed concepts that I had never used before. I gathered them here in the hope that the rest will find my story useful to start studying distributed systems or learn something new for myself.
This post was devoted exclusively to the planning and architecture of such systems. There are many different subtleties that are worth talking about - about the construction, deployment and migration of highly loaded systems - and also about their reliable operation; I am going to raise all these topics in subsequent posts.