We write our own tricky thread_pool dispatcher for SObjectizer
What is this article about?
One of the main distinguishing features of the C ++ SObjectizer framework is the availability of dispatchers. Dispatchers determine where and how actors (agents in SObjectizer terminology) will process their events: on a separate thread, on a pool of working threads, on one thread common to a group of actors, etc.
SObjectizer already includes eight full-time dispatchers (plus one more in the set of extensions for SObjectizer) But even with all this diversity, there are situations when it makes sense to make your own dispatcher for a specific specific task. The article just discusses one of these situations and shows how you can make your own dispatcher if the regular dispatchers for some reason do not suit us. And at the same time it will be shown how easy it is to change the behavior of an application by simply linking the same actor to different dispatchers. Well and some more interesting trifles and not so trifles.
In general, if someone is interested in touching on the details of the implementation of one of the few living and developing actor frameworks for C ++, then you can safely read on.
Preamble
Recently, one of the users of SObjectizer talked about a specific problem that he had to deal with while using SObjectizer. The point is that based on SObjectizer agents, an application is being developed for managing devices connected to a computer. Some operations (namely, the initialization and reinitialization operation of the device) are performed synchronously, which leads to the blocking of the working thread for some time. The I / O operations are carried out asynchronously, therefore, the initiation of reading / writing and processing of the read-write result are much faster and do not block the working thread for a long time.
There are many devices, from a few hundred to several thousand, so using the "one device - one working thread" scheme is not profitable. Because of this, a small pool of working threads is used, on which all operations with devices are performed.
But such a simple approach has an unpleasant feature. When a large number of applications for initialization and reinitialization of devices arise, then these applications begin to be distributed across all threads from the pool. And situations regularly happen when all the working threads of a pool are busy with performing lengthy operations, while short operations, like read-write, accumulate in queues and are not processed for a long time. This situation is stably observed, for example, at the start of the application, when a large “bundle” of applications for initializing devices is immediately formed. And until this “bundle” is disassembled, I / O operations on already initialized devices are not performed.
To eliminate this trouble, you can use several approaches. In this article we will analyze one of them, namely, writing your own cunning thread_pool dispatcher that analyzes types of applications.
What do we want to achieve?
The problem is that long-running handlers (i.e., handlers for initializing and reinitializing devices) block all working threads in the pool and, because of this request, can wait for short operations (i.e., I / O) Queues are very long. We want to get such a scheduling scheme so that when a request appears for a short operation, its waiting in queues is minimized.
Imitation "stand"
In the article we will use an imitation of the problem described above . Why imitation? Because, firstly, we only have an idea of the essence of the user's problem, but we don’t know the details and never saw his code. And, secondly, imitation allows you to concentrate on the most significant aspects of the problem being solved, without scattering attention to small details, of which there are a great many in the real production code.
However, there is one important detail that we have learned from our user and which has the most serious effect on the solution described below. The fact is that in SObjectizer there is a concept of thread-safety for message handlers. Those. if the message handler is marked as thread-safe, then SObjectizer has the right to run this handler in parallel with other thread-safe handlers. And there is a adv_thread_pool dispatcher that does just that.
So, our user used a stateless agent tied to the adv_thread_pool manager to manage devices. This greatly simplifies the entire kitchen.
So what are we going to consider?
We made an imitation consisting of the same agents. One agent is an auxiliary agent of type a_dashboard_t. Its task is to collect and record statistics by which we will judge the results of simulation experiments. We will not consider the implementation of this agent.
The second agent, implemented by the a_device_manager_t class , simulates working with devices. We will talk a little about how this agent works below, because this can be an interesting example of how agents that do not need to change their state can be implemented in SObjectizer.
The simulation includes two applications that do almost the same thing: they parse the command line arguments and start the simulation with a_dashboard_t and a_device_manager_t agents inside. But the first application binds a_device_manager_t to the adv_thread_pool manager. But the second application implements its own type of dispatcher and binds a_device_manager_t to this own dispatcher.
Based on the results of each of the applications, it will be possible to see how different types of dispatchers affect the nature of service applications.
Agent a_device_manager_t
In this section, we will try to highlight the main points in the implementation of the a_device_manager_t agent. All other details can be seen in the full agent code . Or clarify in the comments.
The a_device_manager_t agent should simulate working with many devices of the same type, but at the same time it should be a “stateless agent”, ie he should not change his state in the process. It is precisely that the agent does not change its state and allows it to have thread-safe event handlers.
However, if the a_device_manager_t agent does not change its state, then how does it determine which device should be initialized, which device should be reinitialized, and with which device I / O operations should be performed? It's simple: all this information is sent inside messages that the a_device_manager_t agent sends to itself.
At start, the a_device_manager_t agent sends itself N init_device_t messages. Upon receiving such a message, the a_device_manager_t agent creates an instance of the “device” - an object of type device_t and initializes it. Then point to this instance is sent in a perform_io_t message. It looks like this:
void on_init_device(mhood_t cmd) const {
// Обновим статистику по этой операции.
handle_msg_delay(a_dashboard_t::op_type_t::init, *cmd);
// Нужно создать новое устройство и проимитировать паузу,
// связанную с его инициализацией.
auto dev = std::make_unique(cmd->id_,
calculate_io_period(),
calculate_io_ops_before_reinit(),
calculate_reinits_before_recreate());
std::this_thread::sleep_for(args_.device_init_time_);
// Отсылаем первое сообщение о необходимости выполнить IO-операцию
// на этом устройстве.
send_perform_io_msg(std::move(dev));
} Upon receiving the perform_io_t message, the a_device_manager_t agent simulates the I / O operation for the device, a pointer to which is located inside the perform_io_t message. At the same time, the counter of IO operations is decremented for device_t. If this counter reaches zero, then a_device_manager_t either sends itself a reinit_device_t message (if the reinitialization counter has not yet been reset), or an init_device_t message to recreate the device. This simple logic imitates the behavior of real devices that have the property of “sticking” (that is, stop performing normal IO operations) and then they need to be reinitialized. And also the sad fact that each device has a limited resource, after which the device must be replaced.
If the counter of IO operations has not yet been reset, then the a_device_manager_t agent once again sends itself a perform_io_t message.
In the code, it all looks like this:
void on_perform_io(mutable_mhood_t cmd) const {
// Обновим статистику по этой операции.
handle_msg_delay(a_dashboard_t::op_type_t::io_op, *cmd);
// Выполняем задержку имитируя реальную IO-операцию.
std::this_thread::sleep_for(args_.io_op_time_);
// Количество оставшихся IO-операций должно уменьшиться.
cmd->device_->remaining_io_ops_ -= 1;
// Возможно, пришло время переинициализировать устройство.
// Или даже пересоздавать, если исчерпан лимит попыток переинициализации.
if(0 == cmd->device_->remaining_io_ops_) {
if(0 == cmd->device_->remaining_reinits_)
// Устройство нужно пересоздать. Под тем же самым идентификатором.
so_5::send(*this, cmd->device_->id_);
else
// Попытки переинициализации еще не исчерпаны.
so_5::send>(*this, std::move(cmd->device_));
}
else
// Время переинициализации еще не пришло, продолжаем IO-операции.
send_perform_io_msg(std::move(cmd->device_));
} Here is such a simple logic, regarding which clarification of some details may make sense.
Sending information to a_dashboard_t agent
In the message handlers init_device_t, reinit_device_t and perform_io_t, the first line is a similar construction:
handle_msg_delay(a_dashboard_t::op_type_t::init, *cmd);This is the transfer to the agent a_dashboard_t of information about how much a particular message spent in the request queue. Based on this information, statistics are built precisely.
In principle, accurate information about how much time the message spent in the application queue could be obtained only by embedding into the offal of the SObjectizer: then we could fix the time of placing the application in the queue and the time of its extraction from there. But for such a simple experiment, we will not engage in such extreme sports. Let's do it simpler: when sending the next message, we will store the expected arrival time of the message in it. For example, if we send a message delayed by 250ms, then we wait for it to arrive at the moment (Tc + 250ms), where Tc is the current time. If the message came through (Tc + 350ms), then it spent 100ms in the queue.
This, of course, is not an exact way, but it is quite suitable for our imitation.
Blocking the current thread for a while
Also in the code of message handlers init_device_t, reinit_device_t and perform_io_t you can see the call to std :: this_thread :: sleep_for. This is nothing more than a simulation of synchronous operations with a device that should block the current thread.
Delay times can be set via the command line, and by default the following values are used: for init_device_t - 1250ms, for perform_io_t - 50ms. The duration for reinit_device_t is calculated as 2/3 of the init_device duration (i.e. 833ms by default).
Using mutable messages
Perhaps the most interesting feature of the a_device_manager_t agent is how the lifetime of dynamically created device_t objects is provided. After all, the device_t instance is created dynamically during init_device_t processing and then it must remain alive until attempts to reinitialize this device are exhausted. And when the reinitialization attempts are exhausted, the device_t instance must be destroyed.
At the same time, a_device_manager_t should not change its state. Those. we cannot get in a_device_manager_t some kind of std :: map or std :: unordered_map, which would be a dictionary of living device_t.
To solve this problem, use the following trick. The reinit_device_t and perform_io_t messages contain unique_ptr containing a pointer to the device_t instance. Accordingly, when we process reinit_device_t or perform_io_t and want to send the next message for this device, we simply transfer unique_ptr from the old message instance to the new instance. And if we no longer need the instance, i.e. we no longer send reinit_device_t or perform_io_t for it, then the device_t instance is destroyed automatically, because the unique_ptr instance in the already processed message is destroyed.
But there is a little trick. Typically, messages in SObjectizer are sent as immutable objects that should not be modified. This is because SObjectizer implements the Pub / Sub model, and sending a message to mbox in the general case, it is impossible to say with certainty exactly how many subscribers will receive the message. Maybe there will be ten. Maybe a hundred. Maybe a thousand. Accordingly, some subscribers will process the message at the same time. And therefore, you cannot allow one subscriber to modify an instance of a message while another subscriber tries to work with that instance. It is because of this that regular messages are passed to the handler by a constant link.
However, there are situations when a message is guaranteed to be sent to a single recipient. And this recipient wants to modify the received message instance. Here's how in our example, when we want to take the unique_ptr value from the resulting perform_io_t and pass this value to a new reinit_device_t instance.
For such cases, support for mutable messages was added to SObjectizer-5.5.19 . These messages are specially marked. And SObjectizer in run-time checks if mutable messages are sent to multi-producer / multi-consumer mbox-s. Those. A mutable message can be delivered to no more than one recipient. Therefore, it is transmitted to the recipient by a regular, non-constant link, which allows you to modify the contents of the message.
Traces of this are found in a_device_manager_t code. For example, this handler signature indicates that the handler is expecting a mutable message:
void on_perform_io(mutable_mhood_t cmd) const But this code says that an instance of mutable message is sent:
so_5::send>(*this, std::move(cmd->device_)); Simulation using adv_thread_pool dispatcher
In order to see how our a_device_manager_t will behave with a regular adv_thread_pool manager, you need to create a cooperation of a_dashboard_t and a_device_manager_t agents, linking a_device_manager_t to adv_thread_pool manager. Which looks like this :
void run_example(const args_t & args ) {
print_args(args);
so_5::launch([&](so_5::environment_t & env) {
env.introduce_coop([&](so_5::coop_t & coop) {
const auto dashboard_mbox =
coop.make_agent()->so_direct_mbox();
// Агента для управления устройствами запускаем на отдельном
// adv_thread_pool-диспетчере.
namespace disp = so_5::disp::adv_thread_pool;
coop.make_agent_with_binder(
disp::create_private_disp(env, args.thread_pool_size_)->
binder(disp::bind_params_t{}),
args,
dashboard_mbox);
});
});
} As a result of a test run with 20 work threads in the pool and the rest of the default values, we get the following picture:

You can see a big "blue" peak at the very beginning (this is a mass creation of devices at startup), as well as large "gray" peaks shortly after the start work. First, we receive a large number of init_device_t messages, some of which wait a long time for their turn to process. Then perform_io_t is processed very quickly and a large number of reinit_device_t are generated. Some of these reinit_device_t are waiting in lines, hence the noticeable gray peaks. You can also see noticeable dips in the green lines. This is a drop in the number of processed perform_io_t messages at those moments when reinit_device_t and init_device_t are being mass processed.
Our task is precisely to reduce the number of “gray” bursts and make the “green” dips not so deep.
The idea of your own cunning thread_pool dispatcher
The problem with adv_thread_pool-dispatcher is that for him all requests are equal. Therefore, as soon as he frees the working thread, he gives her the first application from the queue. Absolutely not understanding what type of application this is. This leads to situations when all working threads are busy processing requests init_device_t or reinit_device_t, while requests of the type perform_io_t are accumulated in the queue.
To get rid of this problem, we will make our own cunning thread_pool manager, which will have two subpools of two types of work threads.
Worker threads of the first type can process applications of any type. Priority is given to requests of type init_device_t and reinit_device_t, but if they are not currently available, then performances of type perform_io_t can also be processed.
Worker threads of the second type cannot process requests of the type init_device_t and reinit_device_t. A request of type perform_io_t can be processed, but a request of type init_device_t cannot.
Thus, if we have 50 claims of the reinit_device_t type and 150 claims of the perform_io_t type, then the first subpool will rake the reinit_device_t claims, and the second subpool will rake the perform_io_t claims at the same time. When all requests of the reinit_device_t type are processed, the working threads from the first subpool will be freed and will be able to help process the remaining requests of the type perform_io_t.
It turns out that our cunning thread_pool dispatcher holds a separate set of threads for processing short requests, and this allows us not to slow down short orders even when there are a large number of long requests (as, say, at the very beginning of work, when sending a large number of init_device_t at a time).
Simulation using the cunning thread_pool dispatcher
In order to do the same simulation, but with a different dispatcher, we only need to redo the run_example function shown above:
void run_example(const args_t & args ) {
print_args(args);
so_5::launch([&](so_5::environment_t & env) {
env.introduce_coop([&](so_5::coop_t & coop) {
const auto dashboard_mbox =
coop.make_agent()->so_direct_mbox();
// Агента для управления устройствами запускаем на отдельном
// хитром диспетчере.
coop.make_agent_with_binder(
tricky_dispatcher_t::make(env, args.thread_pool_size_)->binder(),
args,
dashboard_mbox);
});
});
} Those. we create all the same agents, only this time we bind a_device_manager_t to another dispatcher.
As a result of the launch with the same parameters, we will see another picture:
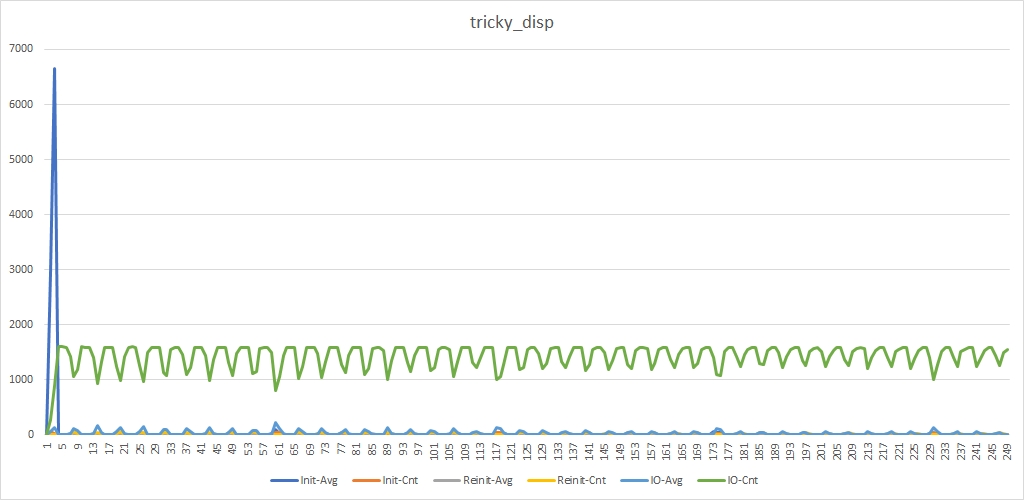
There is still the same “blue” peak. Now it has become even higher, which is not surprising, because fewer work threads are now allocated to handle init_device_t. But we do not see “gray” peaks and “green” dips have become less deep.
Those. we got the result we wanted. And now we can look at the code of this most cunning dispatcher.
Implementing the tricky thread_pool dispatcher
Dispatchers in SObjectizer are divided into two types:
Firstly, public dispatchers. Each public dispatcher must have a unique name. Typically, dispatcher instances are created before starting SObjectizer, when SObjectizer starts, public dispatchers start, and when SObjectizer finishes, they stop. These controllers must have a specific interface . But this is an outdated type of dispatchers. There is far from a zero chance that there will be no more public dispatchers in the next major version of SObjectizer.
Secondly, private dispatchers. The user creates such dispatchers at any time after starting the SObjectizer. A private dispatcher should start immediately after creation and it will finish its work after it is no longer used. Just for our simulation we will create a dispatcher that can only be used as a private dispatcher.
Let's look at the main points associated with our dispatcher.
disp_binder for our dispatcher
Private dispatchers do not have a rigidly defined interface, as all basic operations are carried out in the constructor and destructor. But the private dispatcher must have a public method, usually called binder (), which returns a special binder object. This binder object will bind the agent to a specific dispatcher. And binder should already have a definite interface - disp_binder_t .
Therefore, for our dispatcher, we make our own binder type that implements the disp_binder_t interface:
class tricky_dispatcher_t
: public std::enable_shared_from_this {
friend class tricky_event_queue_t;
friend class tricky_disp_binder_t;
class tricky_event_queue_t : public so_5::event_queue_t {...};
class tricky_disp_binder_t : public so_5::disp_binder_t {
std::shared_ptr disp_;
public:
tricky_disp_binder_t(std::shared_ptr disp)
: disp_{std::move(disp)} {}
virtual so_5::disp_binding_activator_t bind_agent(
so_5::environment_t &,
so_5::agent_ref_t agent) override {
return [d = disp_, agent] {
agent->so_bind_to_dispatcher(d->event_queue_);
};
}
virtual void unbind_agent(
so_5::environment_t &,
so_5::agent_ref_t) override {
// Ничего не нужно делать.
}
};
...
// Объект, реализующий интерфейс so_5::event_queue_t для того,
// чтобы выполнять привязку агентов к диспетчеру.
tricky_event_queue_t event_queue_;
...
public:
...
// Создать биндера, который сможет привязать агента к этому диспетчеру.
so_5::disp_binder_unique_ptr_t binder() {
return so_5::disp_binder_unique_ptr_t{
new tricky_disp_binder_t{shared_from_this()}};
}
}; Our tricky_dispatcher_t class inherits from std :: enable_shared_from_this so that we can use the reference counter to control the dispatcher's lifetime. As soon as the dispatcher ceases to be used, the reference counter is reset and the dispatcher is automatically destroyed.
The ticky_dispatcher_t class has a public binder () method that returns a new instance of tricky_disp_binder_t. A smart pointer to the dispatcher itself is passed to this instance. This then allows you to associate a specific agent with a specific dispatcher, as we saw earlier in the run_example code:
// Агента для управления устройствами запускаем на отдельном
// хитром диспетчере.
coop.make_agent_with_binder(
tricky_dispatcher_t::make(env, args.thread_pool_size_)->binder(),
args,
dashboard_mbox);
});
});
The binder object must do two things. The first is binding the agent to the dispatcher. What is done in the bind_agent () method. Although, in fact, the binding of the agent to the dispatcher is carried out in two stages. First, in the process of registering cooperation, the bind_agent () method is called and this method should create all the resources necessary for the agent. For example, if an agent binds to the active_obj dispatcher, then a new working thread must be allocated for the agent. This is exactly what should happen in bind_agent (). The bind_agent () method returns a functor that will already complete the agent binding procedure using previously allocated resources. Those. it turns out that when registering cooperation, bind_agent () is called first, and a little later, the functor returned by bind_agent () is called.
In our case, bind_agent () is very simple. No resources need to be allocated, just return the functor, which will connect the agent to the dispatcher (more on this below).
The second action is to untie the agent from the dispatcher. This untying occurs when the agent is removed from the SObjectizer (deregistered). In this case, you may need to clear some resources that have been allocated to the agent. For example, the dispatcher active_obj stops the working thread allocated to the agent.
The unbind_agent () method is responsible for performing the second action. But in our case, it is empty, since for tricky_dispatcher_t, cleaning resources when untying an agent is not required.
tricky_event_queue_t
Above we talked about “binding an agent to a dispatcher”, but what is the point of this binding? The point is two simple things.
Firstly, some dispatchers, like active_obj mentioned above, must allocate certain resources to the agent at the time of binding.
Secondly, in SObjectizer agents do not have their own message / request queues. This is the fundamental difference between SObjectizer and implementations of the “classic Actor Model”, in which each actor has its own mailbox (and, therefore, its own message queue).
In SObjectizer, dispatchers own queues of applications. It is the dispatchers who determine where and how applications are stored (i.e. messages addressed to the agent), where, when and how applications are retrieved and processed.
Accordingly, when the agent starts working inside the SObjectizer, it is necessary to establish a connection between the agent and the order queue, in which messages addressed to the agent should be added. To do this, you need to call the special method so_bind_to_dispatcher () on the agent and pass a reference to the object that implements the event_queue_t interface to this method . Which, in fact, we see in the implementation of tricky_disp_binder_t :: bind_agent ().
But the question is what exactly tricky_disp_binder_t gives to so_bind_to_dispatcher (). In our case, this is a special implementation of the event_queue_t interface, which serves as just a thin proxy for calling tricky_dispatcher_t :: push_demand ():
class tricky_event_queue_t : public so_5::event_queue_t {
tricky_dispatcher_t & disp_;
public:
tricky_event_queue_t(tricky_dispatcher_t & disp) : disp_{disp} {}
virtual void push(so_5::execution_demand_t demand) override {
disp_.push_demand(std::move(demand));
}
};What does tricky_dispatcher_t :: push_demand hide?
So, in our tricky_dispatcher_t there is one single instance of tricky_event_queue_t, a link to which is passed to all agents bound to the dispatcher. And this instance itself simply delegates all the work to the tricky_dispatcher_t :: push_demand () method. It's time to look inside push_demand:
void push_demand(so_5::execution_demand_t demand) {
if(init_device_type == demand.m_msg_type ||
reinit_device_type == demand.m_msg_type) {
// Эти заявки должны идти в свою собственную очередь.
so_5::send(init_reinit_ch_, std::move(demand));
}
else {
// Это заявка, которая должна попасть в общую очередь.
so_5::send(other_demands_ch_, std::move(demand));
}
} Everything is simple here. For each new application, its type is checked. If the request relates to init_device_t or reinit_device_t messages, then it is put in one place. If this is an application of any other type, then it is put in another place.
The most interesting part is what are init_reinit_ch_ and other_demands_ch_? And they represent nothing more than CSP channels that are called mchains in SObjectizer :
// Каналы, которые будут использоваться в качестве очередей сообщений.
so_5::mchain_t init_reinit_ch_;
so_5::mchain_t other_demands_ch_;It turns out that when a new application is generated for the agent and this application reaches push_demand, its type is analyzed and the application is sent either to one channel or to another. And already working threads that are part of the dispatcher pool are already extracting and processing applications.
Implementing dispatcher threads
As mentioned above, our tricky dispatcher uses two types of work threads. Now it’s already clear that the working threads of the first type should read the requests from init_reinit_ch_ and execute them. And if init_reinit_ch_ is empty, then you need to read and execute applications from other_demands_ch_. If both channels are empty, then you need to sleep until one of the channels receives an application. Or until both channels are closed.
With working threads of the second type is even simpler: you need to read applications only from other_demands_ch_.
Actually, this is exactly what we see in the tricky_dispatcher_t code:
// Обработчик объектов so_5::execution_demand_t.
static void exec_demand_handler(so_5::execution_demand_t d) {
d.call_handler(so_5::null_current_thread_id());
}
// Тело рабочей нити первого типа.
void first_type_thread_body() {
// Выполняем работу до тех пор, пока не будут закрыты все каналы.
so_5::select(so_5::from_all(),
case_(init_reinit_ch_, exec_demand_handler),
case_(other_demands_ch_, exec_demand_handler));
}
// Тело рабочей нити второго типа.
void second_type_thread_body() {
// Выполняем работу до тех пор, пока не будут закрыты все каналы.
so_5::select(so_5::from_all(),
case_(other_demands_ch_, exec_demand_handler));
}Those. a thread of the first type hangs on the select of two channels. Whereas the thread of the second type is on select from only one channel (in principle, inside second_type_thread_body () one could use so_5 :: receive () instead of so_5 :: select ()).
Actually, this was all we needed to do to organize two thread-safe queues of applications and reading these queues on different work threads.
Start-stop our tricky dispatcher
For completeness, it makes sense to bring in the article also the code related to the start and stop of tricky_dispatcher_t. Start is performed in the constructor, and stop, respectively, in the destructor:
// Конструктор сразу же запускает все рабочие нити.
tricky_dispatcher_t(
// SObjectizer Environment, на котором нужно будет работать.
so_5::environment_t & env,
// Количество рабочих потоков, которые должны быть созаны диспетчером.
unsigned pool_size)
: event_queue_{*this}
, init_reinit_ch_{so_5::create_mchain(env)}
, other_demands_ch_{so_5::create_mchain(env)} {
const auto [first_type_count, second_type_count] =
calculate_pools_sizes(pool_size);
launch_work_threads(first_type_count, second_type_count);
}
~tricky_dispatcher_t() noexcept {
// Все работающие нити должны быть остановлены.
shutdown_work_threads();
}In the constructor, you can also see the creation of the init_reinit_ch_ and other_demands_ch_ channels.
The helper methods launch_work_threads () and shutdown_work_threads () look like this:
// Запуск всех рабочих нитей.
// Если в процессе запуска произойдет сбой, то ранее запущенные нити
// должны быть остановлены.
void launch_work_threads(
unsigned first_type_threads_count,
unsigned second_type_threads_count) {
work_threads_.reserve(first_type_threads_count + second_type_threads_count);
try {
for(auto i = 0u; i < first_type_threads_count; ++i)
work_threads_.emplace_back([this]{ first_type_thread_body(); });
for(auto i = 0u; i < second_type_threads_count; ++i)
work_threads_.emplace_back([this]{ second_type_thread_body(); });
}
catch(...) {
shutdown_work_threads();
throw; // Пусть с исключениями разбираются выше.
}
}
// Вспомогательный метод для того, чтобы завершить работу всех нитей.
void shutdown_work_threads() noexcept {
// Сначала закроем оба канала.
so_5::close_drop_content(init_reinit_ch_);
so_5::close_drop_content(other_demands_ch_);
// Теперь можно дождаться момента, когда все рабочие нити закончат
// свою работу.
for(auto & t : work_threads_)
t.join();
// Пул рабочих нитей должен быть очищен.
work_threads_.clear();
}Here, perhaps, the only tricky point is the need to catch exceptions in launch_work_threads, call shutdown_work_threads, and then throw the exception further. Everything else seems to be trivial and should not cause difficulties.
Conclusion
Generally speaking, the development of dispatchers for SObjectizer is not an easy topic. And the standard dispatchers included in SO-5.5 and so_5_extra have a much more sophisticated implementation than the tricky_dispatcher_t shown in this article. Nevertheless, in some specific situations, when not a single full-time dispatcher is 100% suitable, you can implement your own dispatcher specially tailored for your task. If you do not try to touch on such a complex topic as run-time monitoring and statistics, then writing your own dispatcher does not look such an extremely prohibitive topic.
It should also be noted that the tricky_dispatcher_t shown above turned out to be simple due to the very important assumption that the events of all agents bound to it will be thread-safe and they can be called in parallel without thinking about anything. However, this is usually not the case. In most cases, agents have only thread-unsafe handlers. But even when thread-safe handlers are encountered, they exist simultaneously with thread-unsafe handlers. And when dispatching applications, you have to check the type of the next handler. For example, if the handler for the next thread-safe application, and thread-unsafe is working now, you need to wait until the previously launched thread-unsafe handler finishes. Just the regular adv_thread_pool dispatcher deals with all this. But it is rarely used in practice. More often, other dispatchers are used,
In conclusion, I want to say that the ability to work with mutable messages mentioned in the article was added to SObjectizer after talking on the sidelines after a report about SObjectizer at C ++ Russia 2017 . If someone wants to chat with the SObjectizer developers live and tell them everything you think about this, then this can be done in C ++ Russia 2018 .