Why SQLite Doesn't Use Git
- Transfer
Content
1. Introduction
SQLite does not use Git. Instead, we have the Fossil version control system, specially designed and written to support SQLite.
People sometimes ask why SQLite doesn't use Git like everyone else. In the article we will try to answer this question. In addition, section 3 provides tips for Git users on how to easily access the SQLite source code.
1.1. Edits
The article has been revised several times to clarify, respond to concerns and worries, and to correct errors identified by Hacker News , Reddit, and Lobsters . Full edit history here .
2. Several reasons why SQLite does not use Git
All the reasons why SQLite does not use the Git system can be expressed in one sentence: the leading SQLite developer considers this unacceptable. If you like Git and want to use it, then great. I don’t like Git and would prefer something better, in my opinion.
Below are some reasons why I don't like Git:
2.1. Git makes finding descendants difficult after committing
Git makes it easy to go back in time. Given the last check-in in the branch, Git shows all of its ancestors. But movement in the other direction is difficult. If you take some past commit, then in Git it is quite difficult to find out what followed. This can be done, but difficult enough, so people rarely take this opportunity. Popular interfaces for Git, such as GitHub, do not support this feature.
Yes, Git has the ability to find descendants. It's just that complicated. For example, this StackOverflow page describes a sequence of commands under Unix to search for descendants:
git rev-list --all --parents | grep ".\{40\}.*.*" | awk '{print $1}'It is difficult to remember such a sequence of commands and type them for a long time (you can create a bash alias or a small shell script if the command is often used). But this is not quite right. Such a command gives a list of descendants without an important branch structure. For comparison, Fossil offers such a mapping . This is a huge help when analyzing the consequences of the changes made.
And the point is not only to find descendants from time to time after return. The fact that they are easily accessible on Fossil means that the information automatically goes to the web pages that Fossil issues. One example: on each Fossil page with commit information ( example) there is a small graph "Context" indicating the immediate ancestor and descendants. This helps for better situational awareness, and also provides various useful features, such as the ability to move to the next commit in sequence. Another example: Fossil easily shows the context near a specific commit ( example ), which again helps to increase situational awareness and a deeper understanding of what is happening in the code.
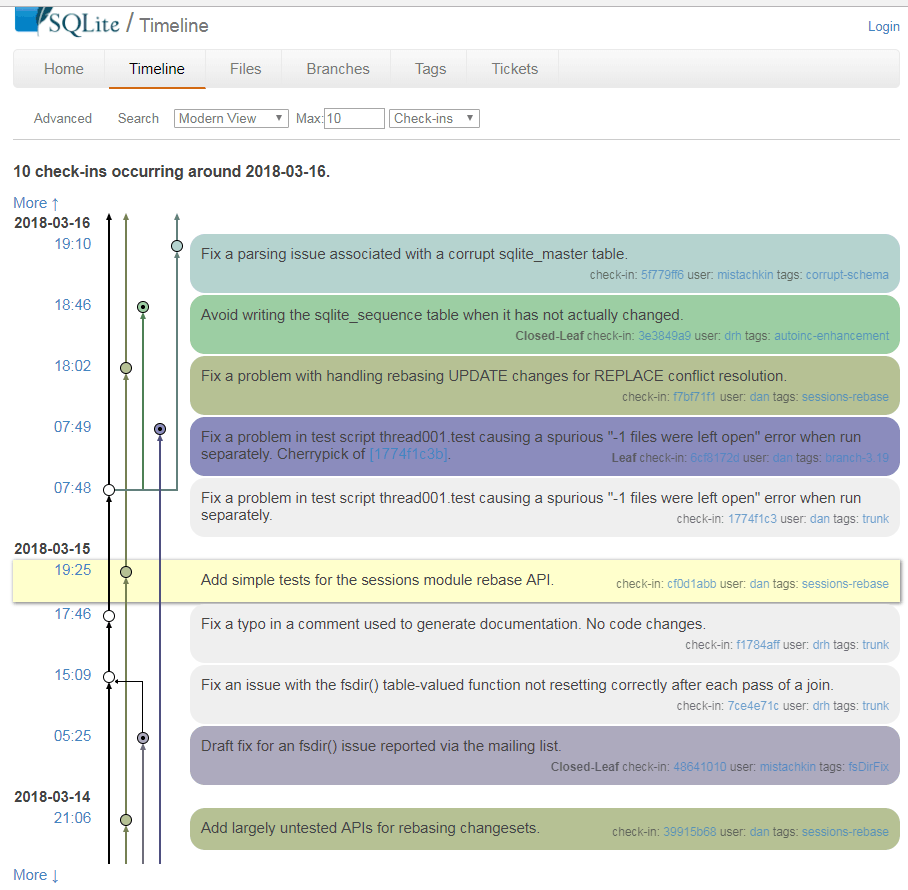
All of the above is possible with Git, if you use the right extensions, tools and the right commands. But this is not so simple, and therefore is rarely done. Consequently, developers are less aware of what is happening in the code.
2.2. The Git mental model is overly complex
The complexity of Git distracts attention from software development. A Git user should always keep in mind:
- Working directory.
- An “index” or staging area.
- Local Header (HEAD).
- Local copy of the deleted header.
- The real remote header.
Git has commands (or command options) for moving and comparing content between all these locations.
For comparison, Fossil users only think about their working directory and the code they are working on. This is 60% less distraction. The working memory of any developer is limited. Fossil requires less working memory, freeing up intellectual resources directly for programming.
One user of Git and Fossil wrote in HN :
"Fossil gives peace of mind and the feeling that everything is in order ... synchronizes with the server with one command ... Such peace of mind has never happened with Git."
2.3. Git does not track historical branch names
Git saves the full DAG commit sequence. But branch tags are local information that is not synchronized or saved after the branch is closed. This makes tedious analysis of old branches.
Compare the display of one historical SQLite branchon github and on fossil .
Fossil clearly shows that the branch eventually merged back. Its beginning is clearly marked and two cases are visible when changes from the trunk joined the branch. GitHub shows none of this. In fact, displaying GitHub almost does not help to figure out what happened.
Many readers have recommended various third-party GUIs for Git that better show development history. Some of them may work better than their native Git and / or GitHub, but they will all suffer from the fact that Git does not preserve historical branch names during synchronization. And even if they really help, the fact of the need to use third-party tools does not speak in favor of the base system.
2.4. Git requires additional administrative support
Git is sophisticated software. To install Git on the developer's computer or to update, some installer is required. Setting up a Git server is nontrivial. One could use GitHub, but this introduces another third-party dependency, and a centralized service eliminates the key advantage of Git, which is its "distribution". There are various free alternatives like GitLab, but there are also a lot of dependencies and a serious server setup is required.
In contrast, Fossil is one separate binary that is set by placing in $ PATH. This single binary contains all the functionality of Git, as well as GitHub and / or GitLab. It manages a community server with a wiki and a bug tracker, provides batch downloads for users, authorization management and more - without additional programs.
Less administration means that programmers spend more time on software development (in this case, SQLite) and less on vanity with the version control system.
2.5. Git is inconvenient to use
This caricature is an exaggeration, but it hits almost the target:

- This is Git. He tracks collaboration on projects with the help of a beautiful distributed tree model from graph theory.
- Cool. How to use it?
- No idea. Just remember these shell commands. Enter them when you need to sync. If an error pops up, save your work somewhere, delete the project and download a fresh copy.
We will be realistic. Few argue that Git has a sub-optimal user interface. It is so bad that there is even a parody site that generates pages of a fake git manual .
Designing software is difficult. This requires a lot of concentration. A good version control system should help the developer, not upset him. Over the past decade, Git has improved in this regard, but there is still a long way to go. Until then, SQLite developers will continue to use another version control system.
3. Git User Guide for Accessing SQLite Source Code
If you're a dedicated Git user, you can still easily access SQLite. This section provides some tips.
3.1. GitHub Mirrors
There is a mirror of the SQLite source tree on GitHub. It is supported by the user mackyle , who is not associated with the SQLite development team and is unknown to us. We don't know McCail, but we see his amazing work of keeping the mirror up to date. Therefore, if you want to access the source SQLite code on GitHub, then its mirror is the recommended source.
3.2. Web access
The SQLite Fossil repository contains download links for Tarball, ZIP, or SQLite for any version of SQLite. URLs are simple, so version downloads are easy to automate. The format is this:
https://sqlite.org/src/tarball/VERSION/sqlite.tar.gzJust replace VERSION with the download version number. This can be a prefix of the cryptographic hash of a particular inclusion or the name of the branch (in this case, the latest version of the branch is selected), or a tag for a specific build, for example, “version-3.23.1”:
https://sqlite.org/src/tarball/version-3.23.1/sqlite.tar.gzTo download the latest release, use “release” instead of VERSION:
https://sqlite.org/src/tarball/release/sqlite.tar.gzTo to get the last trunk return, use “trunk” instead of VERSION:
https://sqlite.org/src/tarball/trunk/sqlite.tar.gzAnd so on. For ZIP and SQLite archives, simply change the “/ tarball /” element to either “/ zip /” or “/ sqlar /”, and you can also change the name of the downloaded file to “.zip” or “.sqlar”.
3.3. Access via Fossil
Fossil is easy to install and use. Here is a step-by-step instruction for Unix (for Windows, the instruction is similar).
- Download the stand-alone Fossil executable from this page and place it somewhere in $ PATH.
mkdir ~/fossilsfossil clone https://sqlite.org/src ~/fossils/sqlite.fossilmkdir ~/sqlite; cd ~/sqlitefossil open ~/fossils/sqlite.fossil
You are now ready to type
./configure; make(or on Windows with MSVC nmake /f Makefile.msc). To upgrade to another version of Fossil, use the command
update: fossil update VERSIONUse “trunk” for the latest version of SQLite. Alternatively, the cryptographic hash prefix, the name of a branch or tag. See the wiki for more information on what names can be used for VERSION.
The command
fossil uiin ~ / sqLite picks up a local copy of the website. See here for more Fossil documentation .
Do not be afraid to explore and experiment. Without authorization, you cannot push any changes, so do not damage the project.
4. Optional
Here are a few more pages discussing Fossil and Git: