Three-dimensional Excel formula engine for dummies
- Tutorial
In this article I will tell you how I managed to port the rendering algorithm of three-dimensional scenes to Excel formulas (without macros).
For those who are not familiar with computer graphics, I tried to describe all the steps as simply and as easily as possible. In principle, to understand the formulas, knowledge of the school course in mathematics (+ the ability to multiply a three-dimensional matrix by a vector) should be sufficient.
I also made a small web application where you can practice creating formulas for arbitrary shapes and generate your Excel file.
Caution: 19 pictures and 3 animations under the cut.
What happened
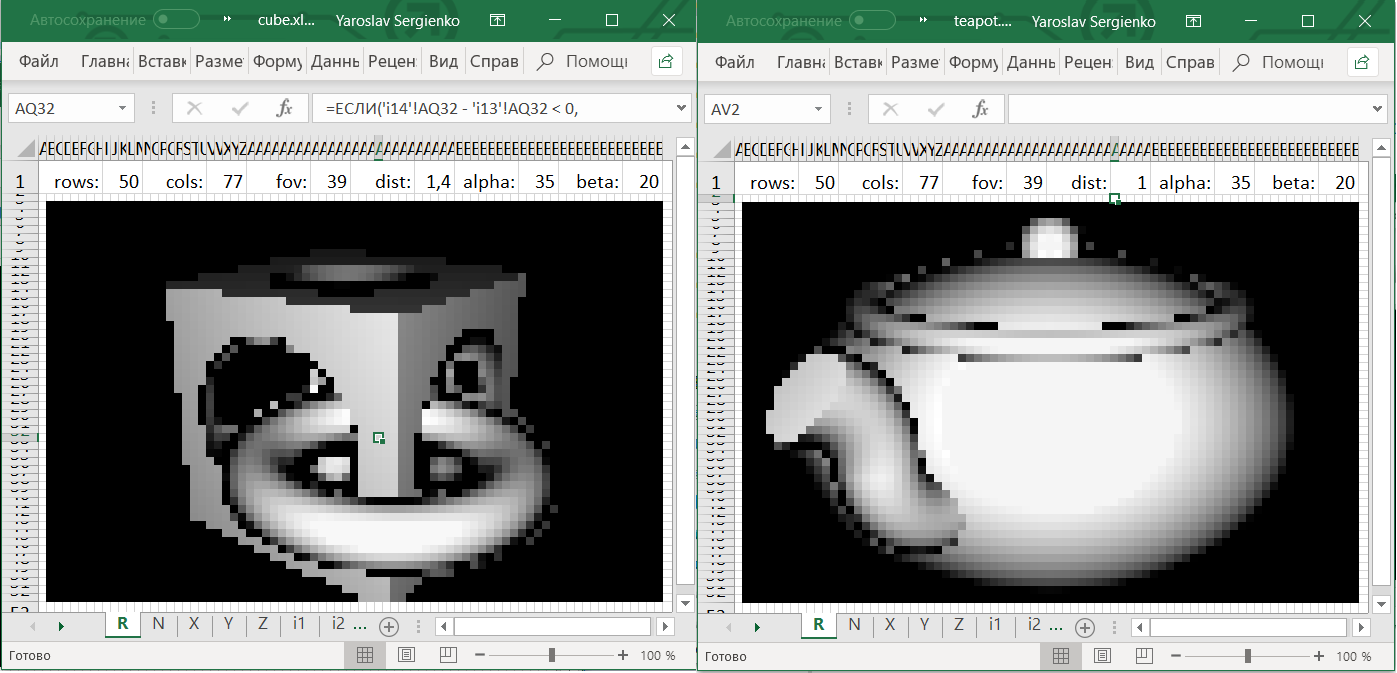
In Excel files at the top, you can change the following cells:
alpha:horizontal rotation of the camera in degrees,beta:vertical rotation of the camera in degrees,dist:distance from the camera to the origin,fov:“Zoom” the camera.
To rotate the camera, you must give Excel permission to modify the file.
If you download your Excel file from ObservableHQ, the cells must be painted manually. You need to select all the small square cells and select "Conditional formatting" → "Color scales."
Ray marching
Ray Marching algorithm was popularized by Iñigo Quilez in 2008 after the presentation of "Rendering Worlds with Two Triangles" about a compact three-dimensional engine for the demo scene .
After that, Iñigo Quilez created the Shadertoy website , and most of the work submitted there uses the described technique. It turned out that with it you can create photorealistic scenes, look, for example, this gallery .
Ray Marching is a very easy to implement and efficient algorithm that allows you to render quite complex scenes. Why then is it not used on video cards? The fact is that video cards are sharpened for working with three-dimensional figures consisting of triangles, for which Ray Marching is not so effective.
Update: See alsothis comment is from DrZlodberg about the flaws of this method.
The principle of the engine
- An object is described as a function.
- Match each pixel of the result with a ray exiting the camera.
- For each ray, find the coordinates of the intersection with the object.
- Using the intersection point, determine the color of the pixel.
I think that in one form or another, all these subtasks are solved in any three-dimensional engine.
Property Description
There are three ways to describe a three-dimensional object:
- An explicit formula that returns the point of intersection with the object (or, for example, the direction of the tangent in it) by the ray leaving the camera.
- Membership function. By a point in space it reports whether it belongs to an object or not.
- Real function. For points inside the object, it is negative, outside it is positive.
This article will use a special case of the third option, called signed distance function (SDF) .
SDF receives a point in space and returns the distance to the nearest point in the object. For points inside it is equal to the distance to the border of the object with a minus sign
Finding the intersection of the beam and the object
Suppose we have a ray coming from the camera, and we want to find the point of intersection with the object.
Several ways come to mind to find this point:
- Go through the points on the beam with a certain step.
- Having points inside and outside the object, run a binary search to specify the intersection.
- Or, start any method for finding the roots of the SDF function (which is negative inside the object and positive outside) limited on the ray.
But here we will use another method: Ray Marching .
This is a simple algorithm that works only with SDF.

Let's parameterize the ray by the distance from its beginning by the function r a y ( t ) = ( x , y , z ) .
Thenr a y ( 0 ) is the camera itself. Here is the algorithm:
- t = 0
- To repeat N times:
- t = t + S D F ( r a y ( t ) )
- If a t < T M a x , then returnr a y ( t ) as the intersection point, otherwise inform that the beam does not intersect the object.
Here N is the number of iterations that we can afford.
More thanN , the more accurate the algorithm.
NumberT M a x is the distance from the camera within which we expect to find an object.
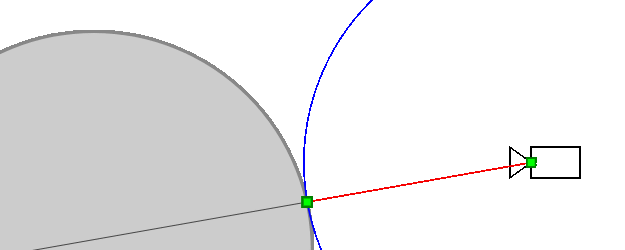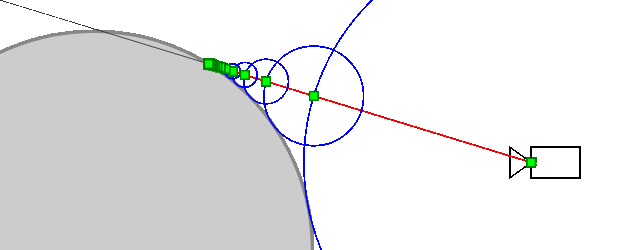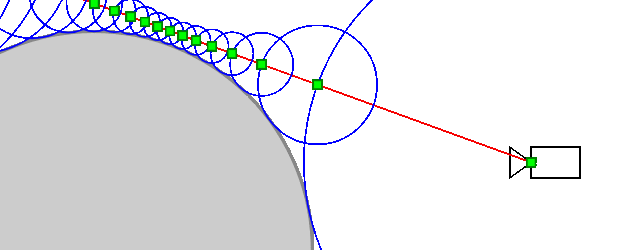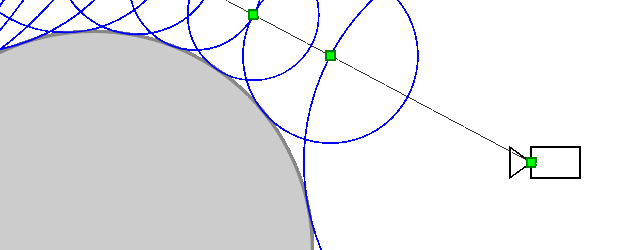
Why the algorithm works
Will the algorithm always reach the point of intersection with the object (more precisely, will tend to it)? The object can have a complex shape and its other parts can come close to the beam, preventing the algorithm from converging to the intersection point. In fact, this cannot be: other parts of the object will necessarily be at some non-zero distance from the ray (otherwise it would intersect them), which we denoteδ > 0 . Then the SDF function will be largerδ for any point of the ray (except for points very close to the intersection point). Therefore, sooner or later he will approach the point of intersection.

On the other hand, if the algorithm converges to some point, then the distance between adjacent iterations tends to zero ⇒ SDF (distance to the nearest point of the object) also tends to zero⇒ in the limitS D F = 0⇒ the algorithm converges to the point of intersection of the beam with the object.
Getting the color of the pixel at the intersection point
Imagine that for each pixel we found the intersection point with the object. We can draw these values (that is, the distance from the camera to the intersection point) directly and get such pictures:

Given that this was obtained using Excel, not bad. But I want to know if it is impossible to make colors more like the way we see objects in life.
In computer graphics, the basic method for calculating color is Phong shading . According to Phong, the resulting color consists of three components: background, mirror and diffuse. Given the fact that we do not strive for photorealistic renderings, it is sufficient to use only the diffuse component. The formula for this component follows from Lambert’s law and states that the color of the pixel is proportional to the cosinethe angle between the normal to the surface and the direction to the light source.
Further, to simplify the calculations, suppose that the light source and the camera are the same. Then, in fact, we need to find the sine of the angle between the beam coming from the camera and the surface of the object:

Desired angle φ, I designated one arc in the drawing. The value of its sine is indicated ask .
Usually, when using the Ray Marching method, to find the normal to the object, do the following: calculate the SDF value at six points (it is easy to reduce the number of points to four) next to the intersection point and find the gradient of this function, which should coincide with the normal. It seemed to me that this was too much calculation for Excel, and I would like to find the desired angle easier.
If you look at the convergence rate of the algorithm, you will notice that if the angle between the beam and the object is straight, then one iteration is enough. If the angle is small, then the algorithm will converge very slowly.
Is it possible to obtain information about the angle to the surface based on the rate of convergence of the algorithm?If this is the case, then no additional calculations are required at all: it is enough to analyze the values of previous iterations.
Draw a drawing. We denoteI n andI n + 1 - points obtained at adjacent iterations of the algorithm. Suppose that the points are close enough to the object, that it can be replaced by the plane, the angle from which we want to find. Let beR = S D F ( I n ) ,r = S D F ( I n + 1 ) - distances from pointsI n andI n + 1 to the plane. Then, according to the algorithm, the distance betweenI n andI n + 1 isThe R .
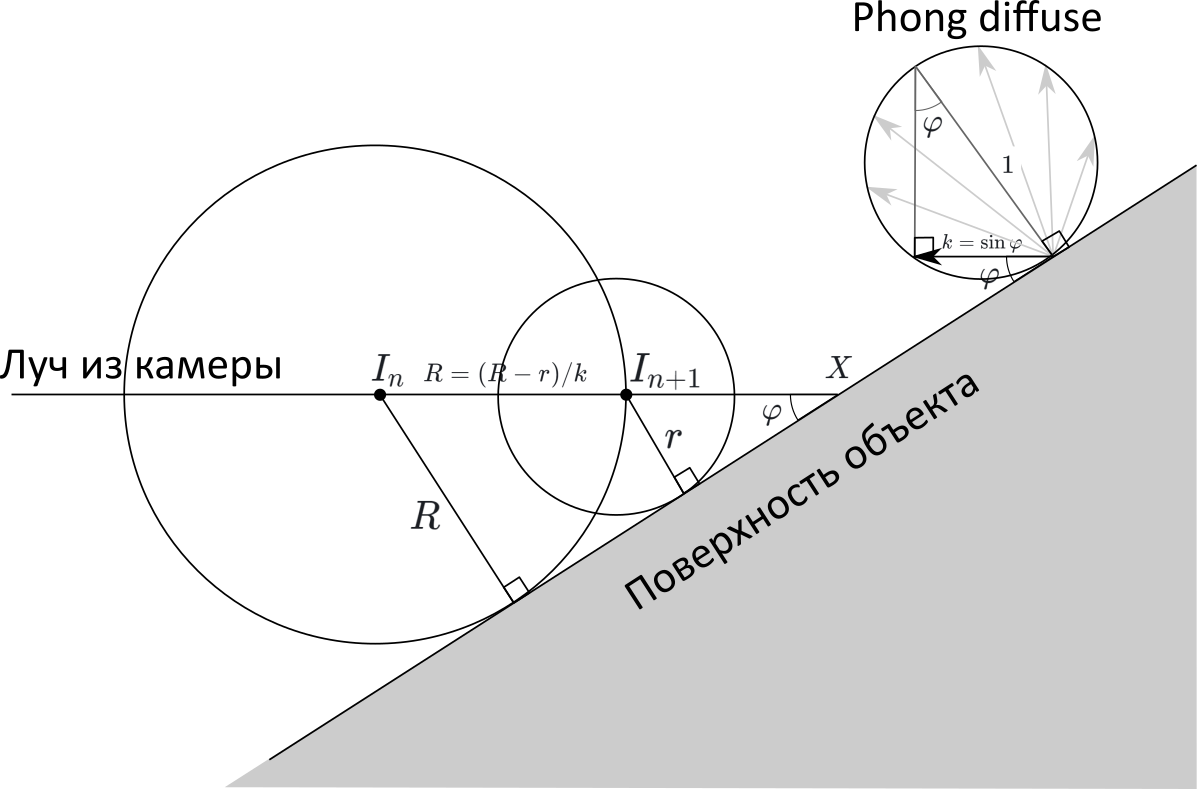
On the other hand, if we denoteX is the intersection point of the ray and the figure, then
I n X = R / k , andI n + 1 X = r / k , therefore
R = I n I n + 1 = I n X - I n + 1 X = R - rk
k = R - rR =1-rR =1-SDF(I n + 1 )S D F ( I n )
That is, the pixel intensity is equal to one minus the ratio of the SDF functions of neighboring iterations!
We describe simple shapes
Examples of SDFs for a sphere, cube, and torus:
| √x 2 + y 2 + z 2 -r |  |
| max ( | x | , | y | , | z | ) - s i d e / 2 |  |
| √( √x 2 + z 2 -R)2+y2-r |  |
Shapes can be moved and compressed along the axes:
 | |
 |
Shapes can also be combined, intersected, and subtracted. That is, SDF supports the basic operations of structural solid geometry :
 | |
 | |
 |
An attentive reader could notice that for some figures (for example, a cube), as well as for some operations (for example, compression), the above formulas do not always return the distance to the nearest point of the object, that is, formally they are not SDFs. Nevertheless, it turned out that they can still be fed to the SDF engine input and it will display them correctly.
This is a small part of what you can do using the SDF, a complete list of figures and operations can be found at www.iquilezles.org/www/articles/distfunctions/distfunctions.htm
Combining all the above formulas, we get the first figure:
 |
Kettle formula
With a teapot a little more complicated: you need a plan. We
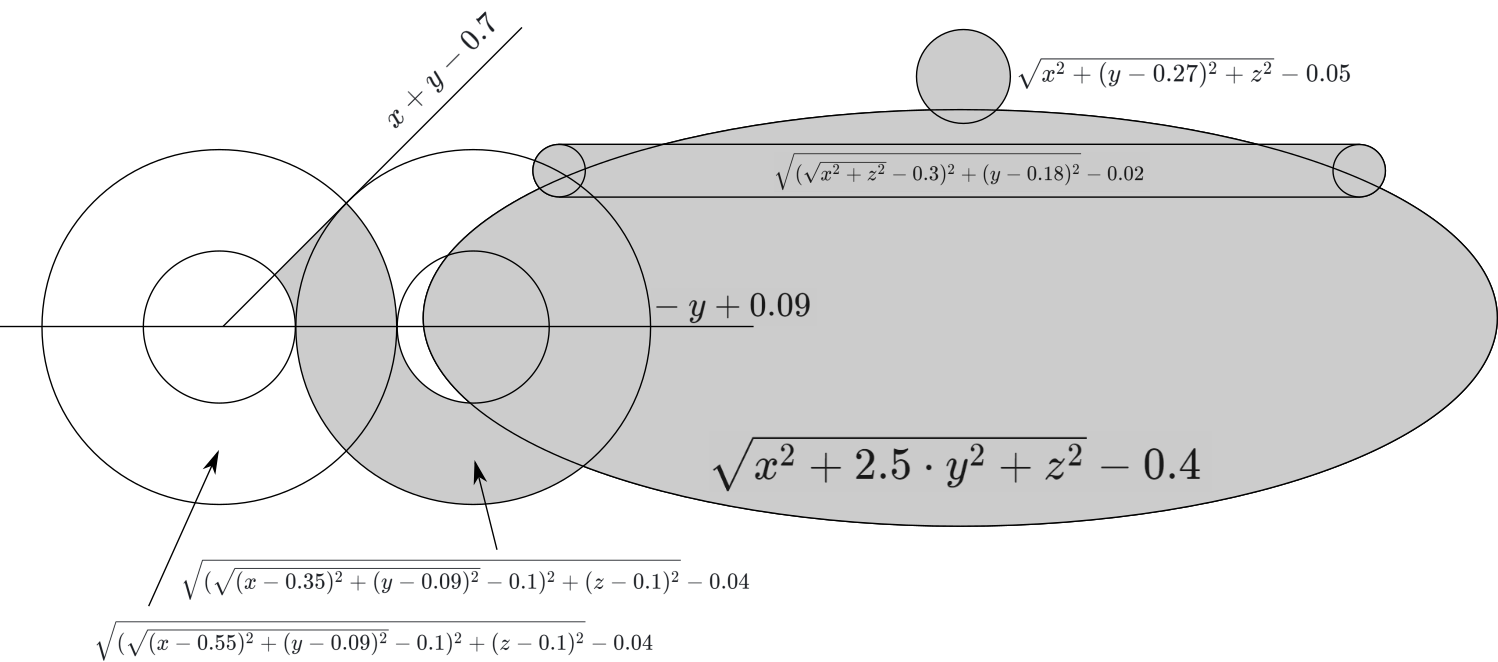
carefully write down the formula:
And we select the desired angle. Done:

Camera
All that remains for us is for a given pixel on the screen to find the corresponding ray in space coming out of the camera. More precisely, you need to be able to find the point of this beam by the distance to the camera. That is, we need a functionwhere Are the coordinates of the pixel, and - the distance from the beginning of the beam (camera).
For convenience of calculations, the coordinates of the pixels will be set relative to the center of the screen. Given that the screen consists of lines and columns, we expect coordinates within

Next, you need to determine the type of projection of the camera: orthogonal, perspective, or "fish eye". In terms of complexity of implementation, they are approximately the same, but in practice the most promising is most often used, so we will use it.
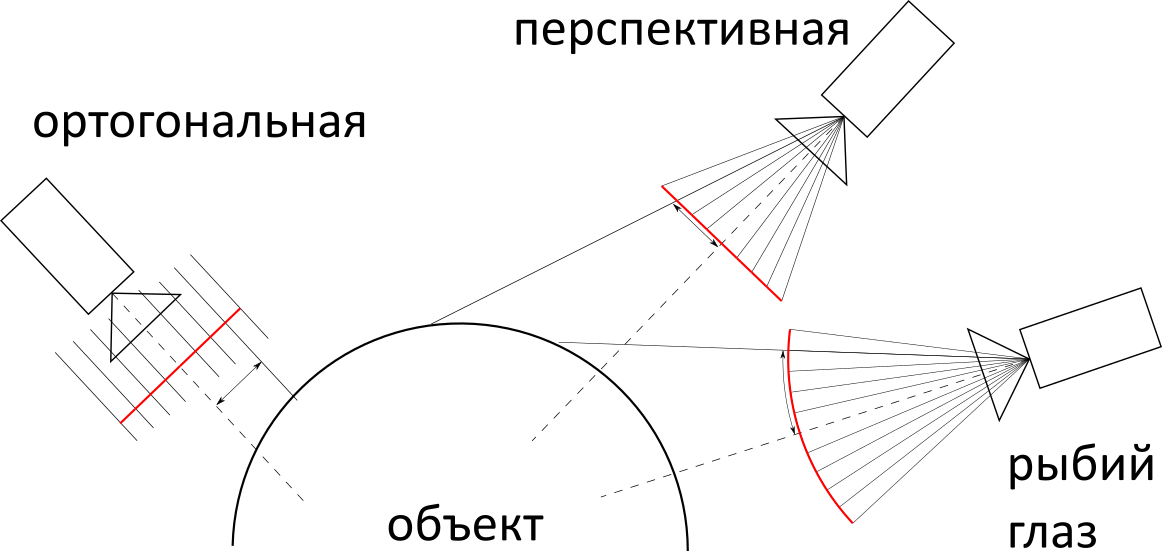
Most of the calculations in this chapter could have been avoided, for example by placing the camera at a point and directing along the axis . But taking into account the fact that the figures are also aligned along the axes, the result would be a not very interesting angle. So in the case of a cube, we would see it as a square.
To provide the ability to rotate the camera, you need to carefully carry out a number of calculations with Euler angles . Thus we get three variables at the input: the angleangle and distance . They determine both the position and direction of the camera (the camera always looks at the origin).
Using WolframAlpha we find the rotation matrix:
If you apply it to a vector , we’ll get the coordinates of the camera (do not ask me where the minus disappeared):
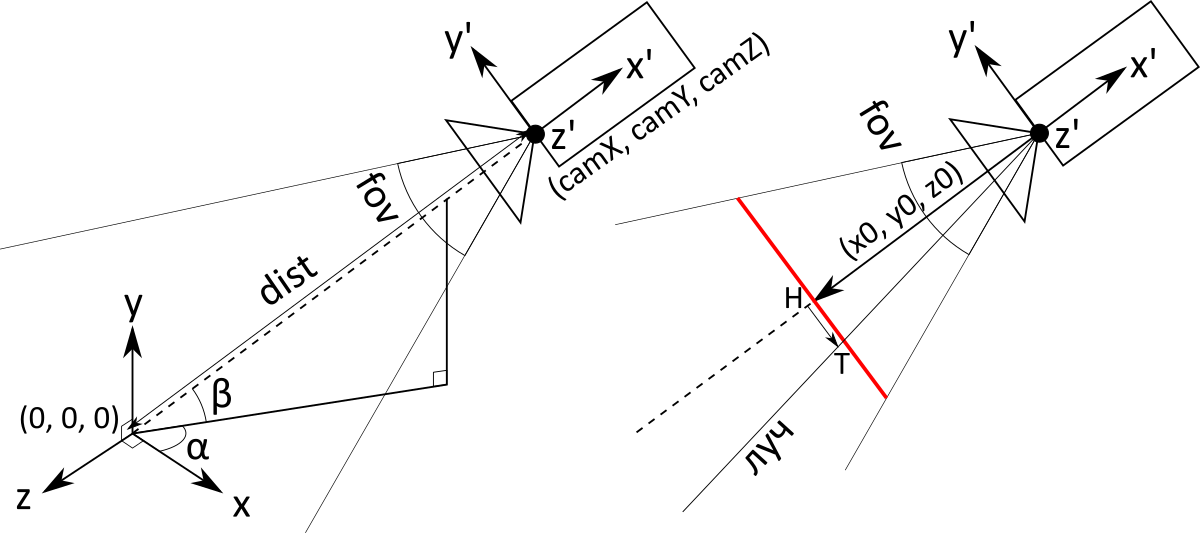
Subsequent calculations will be specific to perspective projection. The main object is the screen (in the figure it is red, in the text in italics). This is an imaginary rectangle at some distance in front of the camera, which, as you might guess, has a one-to-one correspondence with the pixels of a regular screen. The camera is actually just a point with coordinates. The rays corresponding to the pixels begin at the point of the camera and pass through the corresponding point on the screen .
The screen does not have an exact location and size. More precisely, they depend on the distance to the camera: if you move the screen further, you will need to do more. Therefore, we agree that the distance from the camera to the screen is 1. Then we can calculate the value of the vectorconnecting the point of the camera and the center of the screen (it is the same as the center of the camera, only multiplied not by but on ):
Now we need to determine the screen size . It depends on the viewing angle of the camera, which is measured in degrees and corresponds to what is called “zoom” in video cameras. The user sets it using a variable(field of view). Since the screen is not square, it is necessary to clarify what is meant by the vertical viewing angle.
So, to determine the height of the screen, you need to find the base of an isosceles triangle with a vertex angle and height 1: remembering trigonometry, we get . Based on this, you can determine the size of one pixel on the screen :
Next, applying the rotation matrix to the vectors and we get the vectors and defining the horizontal and vertical directions of the screen (to simplify the calculations, they are also pre-multiplied by):
Thus, we now have all the components to find the direction of the beam exiting the camera and corresponding to the pixel with coordinates
This is almost what you need. It is only necessary to take into account that the beginning of the ray is at the point of the camera and that the direction vector must be normalized
So we got the desired function which returns the point of the beam at a distance from its beginning, corresponding to a pixel with coordinates .
Excel
The Excel file that results is a book consisting of> 6 sheets:
- The first sheet of R contains everything that the end user needs: cells with parameters, as well as cells with the result, painted on a black and white scale.
- Sheet N predicts values.
- Sheets X , Y , Z calculate the coordinates vectors and .
- Sheets i1 , i2 , ... contain iterations of the Ray Marching algorithm for each pixel.
All sheets are built in the same way:

- The first line contains 1-6 “global” variables (blue). They can be used on all sheets.
- Most of the sheet is occupied by pixel calculations (green). This is a size rectangle. In the tables at the end of the article, these cells are indicated as
** - Sheets X , Y, and Z also use intermediate calculations for rows and columns (orange). The second row and the first column are reserved for them. In the tables at the end of the article, these cells are indicated by
A*and*2. The idea is to store values for all pixels, it is not necessary to add three more sheets (for each of the coordinates) since its calculation formula is divided into the sum of two components:
Thus, we calculate the first term in the columns and the second in the rows, and when we need to get the value , we add the cell value for the row and column .
| Sheet R | ||
I1 | rows: | 50 |
V1 | cols: | 77 |
AI1 | fov: | 39 |
AV1 | dist: | 1,4 |
BI1 | alpha: | 35 |
Bv1 | beta: | 20 |
** | =ЕСЛИ(i14!XN - i13!XN < 0,00000000000001; 0,09; МАКС(0; МИН(1; (i15!XN - i14!XN) / (i14!XN - i13!XN)))) | |
| Sheet N | ||
I1 | pixelSize: | =TAN(R!AI1 / 2) / (R!I1 / 2) |
** | =1 / КОРЕНЬ(СТЕПЕНЬ(X!AN + X!X2; 2) + СТЕПЕНЬ(Y!AN; 2) + СТЕПЕНЬ(Z!AN + Z!X2; 2)) | |
| Sheet X | ||
I1 | camX: | =R!AV1 * COS(R!BV1) * COS(R!BI1) |
V1 | ux: | =-N!I1 * SIN(R!BI1) |
AI1 | vx: | =N!I1 * SIN(R!BV1) * COS(R!BI1) |
AV1 | x0: | =-COS(R!BV1) * COS(R!BI1) |
A * | =AI1 * (СТРОКА() - 2 - (R!I1 + 1) / 2) | |
* 2 | =AV1 + V1 * (СТОЛБЕЦ() - 1 - (R!V1 + 1) / 2) | |
** | =(Z2 + AN) * N!ZN | |
| Sheet y | ||
I1 | camY: | =R!AV1 * SIN(R!BV1) |
V1 | vy: | =-N!I1 * COS(R!BV1) |
AI1 | y0: | =-SIN(R!BV1) |
A * | =AI1 + V1 * (СТРОКА() - 2 - (R!I1 + 1) / 2) | |
** | =AN * N!ZN | |
| Sheet z | ||
I1 | camZ: | =R!AV1 * COS(R!BV1)) * SIN(R!BI1) |
V1 | uz: | = N!I1 * COS(R!BI1) |
AI1 | vz: | = N!I1 * SIN(R!BV1) * SIN(R!BI1) |
AV1 | z0: | =-COS(R!BV1) * SIN(R!BI1) |
A * | =AI1 * (СТРОКА() - 2 - (R!I1 + 1) / 2) | |
* 2 | =AV1 + V1 * (СТОЛБЕЦ() - 1 - (R!V1 + 1) / 2) | |
** | =(Z2 + AN) * N!ZN | |
| Sheet i1 | ||
I1 | dist0: | =formula(X!I1, Y!I1, Z!I1) |
** | =I1 + formula(X!I1 + X!XN * I1, Y!I1 + Y!XN * I1, Z!I1 + Z!XN * I1) | |
| Sheets i2 , i3 , ... | ||
** | =i(n-1)!XN + formula(X!I1 + X!XN * i(n-1)!XN, Y!I1 + Y!XN * i(n-1)!XN, Z!I1 + Z!XN * i(n-1)!XN) | |
Notes:
- Since Excel calculates in radians, the arguments of all trigonometric functions are multiplied by (Excel has a function for this
RADIANS). In order not to confuse the formulas, I removed these multiplications in the tables above. - Where it is written
formula, you must insert one of these formulas:Excel Torus Cube FormulaMIN( MAX( ABS(x) - 0.3, ABS(y) - 0.3, ABS(z) - 0.3, -SQRT(POWER(x, 2) + POWER(y, 2) + POWER(z, 2)) + 0.375 ), SQRT(POWER(SQRT(POWER(x - 0.25, 2) + POWER(z - 0.25, 2)) - 0.25, 2) + POWER(y, 2)) - 0.05 )Kettle formula in ExcelMIN( SQRT(POWER(SQRT(POWER(x, 2) + POWER(z, 2)) - 0.3, 2) + POWER(y - 0.18, 2)) - 0.02, SQRT(POWER(x, 2) + POWER(y, 2) * 2.5 + POWER(z, 2)) - 0.4, MAX( x + y - 0.15 - 0.05 - 0.5, - (y) + 0.19 - 0.1, SQRT(POWER(SQRT(POWER(x - 0.55, 2) + POWER(y - 0.09, 2)) - 0.1, 2) + POWER(z - 0.1, 2)) - 0.04 ), MAX( -(- (y) + 0.19 - 0.1), SQRT(POWER(SQRT(POWER(x - 0.35, 2) + POWER(y - 0.09, 2)) - 0.1, 2) + POWER(z - 0.1, 2)) - 0.04 ), SQRT(POWER(x, 2) + POWER(y - 0.27, 2) + POWER(z, 2)) - 0.05 )
How does this article relate to the article “3D engine written on MS Excel formulas” ?
That engine is only suitable for rendering mazes and ellipsoids. A one-dimensional Raycaster is used, from which up and down stripes are drawn, creating the illusion of walls. But then there is implemented a full-fledged game logic, here the goal is only a three-dimensional engine.