Never Fail Twice, or how to build a monitoring system from scratch
We had 2 virtual machines, 75 sites, tens of thousands of monitoring machines, thousands of metrics, two databases and one ActiveMQ queue, Python and a whole host of libraries of all kinds and colors, pandas, as well as numpy, dash, flask, SQL Alchemy. Not that it was a necessary supply for the system, but if you started collecting components, it becomes difficult to stop. The only thing that worried me was JavaScript. Nothing in the world is more helpless, irresponsible and vicious than JS zombies. I knew that sooner or later we will move on to this rubbish.

Monitoring distributed systems is a fairly non-trivial task, where there are pitfalls. On the other hand, there are a huge number of both commercial and open-source solutions for various monitoring tasks. Under the cat about why open solutions did not suit us, what we understood from the analysis of successful and unsuccessful monitoring projects, and why it was decided to build Yet Another Alert System. It was a fascinating adventure, where at the stages from data analysis in Python to the final solution and building the system, we met almost all of Computer Science and even a bit of matana.
If we consider the monitoring problem as a whole, then the tasks are divided into two main groups.
Why is it difficult?
- Monitoring a complex distributed system is an engineering problem in itself
- Various problems lead to implicit changes in the system behavior
- Many different metrics of one system
- Various metrics correlate with each other
I work as a Technical Architect in a large company, and we had problems with timely detection of problems in production systems.
We handle financial transactions in highly regulated markets. The system architecture is service-oriented, the components have a complex business logic, there are different backend options for different customers (B2B) of the company.
Firstly, due to the high complexity of the products and the huge number of settings, there are situations where incorrect settings lead to the degradation of financial performance, or hidden bugs in the logic affect the overall functionality of the entire system.
Secondly, there are specific 3d-party integrations for different countries, and problems that arise with partners begin to flow to us. Problems of this kind are not caught by low level monitoring; to solve them, you need to monitor key indicators (KPI), compare them with statistics on the system and look for correlations.
The company had previously implemented a solution from Hewlett Packard Service Health Analyzer, which was (to put it mildly) imperfect. Judging by the marketing prospectus, this is a system that learns itself and provides early detection of problems (SHA can take data streams from multiple sources and apply advanced, predictive algorithms in order to alert to and diagnose potential problems before they occur). In fact, it was a black box that could not be configured, you had to contact HP with all the problems and wait for months until the support engineers did something that would also not work as it should. And also - the terrible user interface, the old JVM ecosystem (Java 6.0), and, most importantly - a large number of False Positives and (even worse) False Negatives, that is, some serious problems were either not detected,
The figure shows that the SHA granularity of 15 minutes means that even in case of problems the minimum reaction time is 15 minutes ...
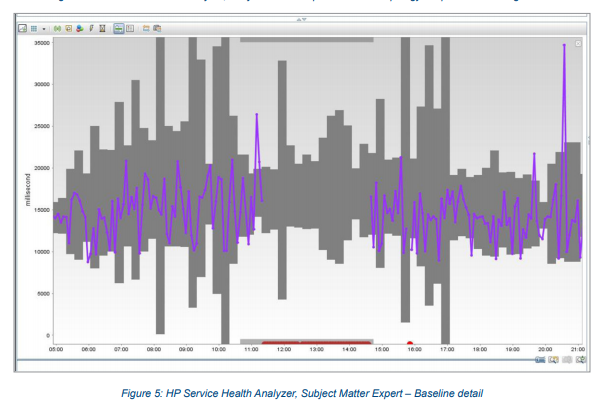
That is, it often looked like this ...

Many companies have tried to build their monitoring system. These have not always been success stories.
Etsy is an online marketplace for handmade goods. The company is headquartered in New York. The company collected more than 250,000 different metrics from its servers and tried to look for anomalies in the metrics using sophisticated mathematical algorithms. But ...
Meet Kale.
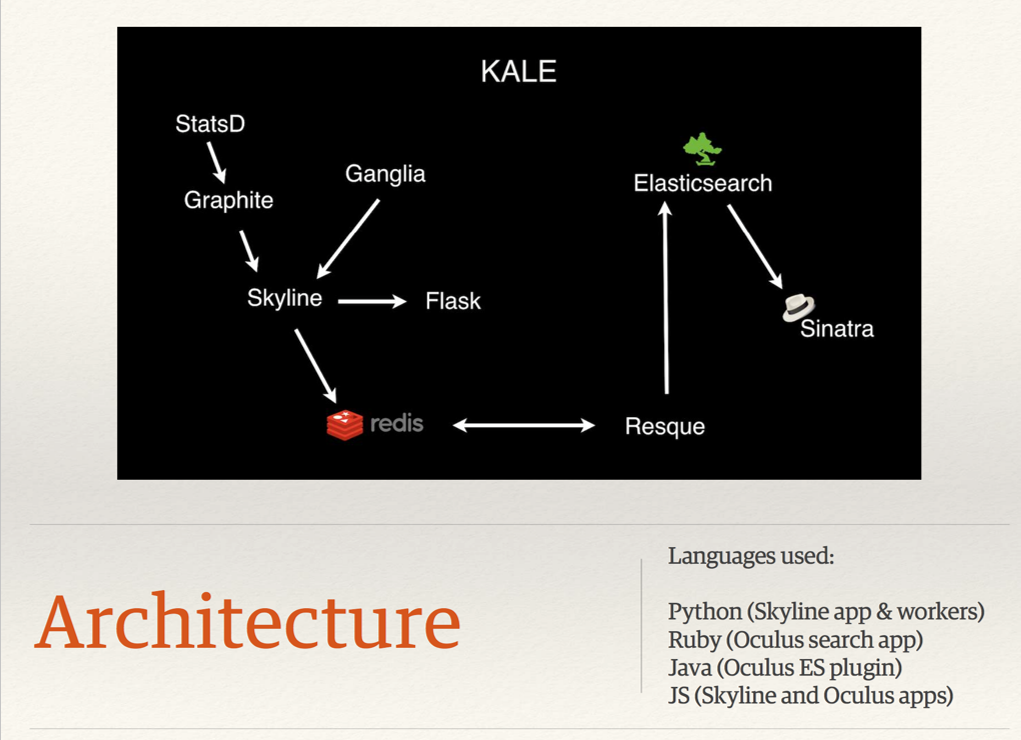
One of Kale's problems was that the system used many different technology stacks. In the diagram, you can see 4 different stacks, plus 2 frameworks. To develop and maintain the system, highly skilled engineers familiar with these stacks were required. Finding bugs also required knowledge in many stacks.
The second problem is the monitoring approach itself. Kale was only looking for anomalies. But if you have 250,000 metrics, then hundreds of anomalies will be statistically observed for each tick. If you expand the boundaries, then problems will slip. If you narrow down, there will be a huge amount of false positives.
Etsy engineers tried to fight the number of False Positives, but after three years of development, the project was closed. There is a good video on this subject from Andrew Clegg.
I want to highlight one slide from this video.

Finding anomalies is more than just catching outliers. Outliers emissions will be observed on any real production data in normal operation. Not all anomalies should lead to the inclusion of anxiety at all levels.
A universal approach is not suitable for anything; There are no free lunches. That's why HP's SHA solution does not work as it should, trying to be a universal tool.
And interestingly, possible approaches to solving these problems.
Send Alert on anomalies in business and user metrics
Use other metrics for Root Cause analysis.
The book Site Reliability Engineering has a whole chapter devoted to the problem of monitoring the production of Google systems. In short, then
Google built the successful BorgMon system on these principles.
A time series is a series of data indexed by time. If we take as a number economic processes (from the production of champagne to sales in stores or online transactions), then they have some common properties: the processes are regular, have some periodicity, usually have seasonal periods and trend lines. Using this information can simplify the analysis.
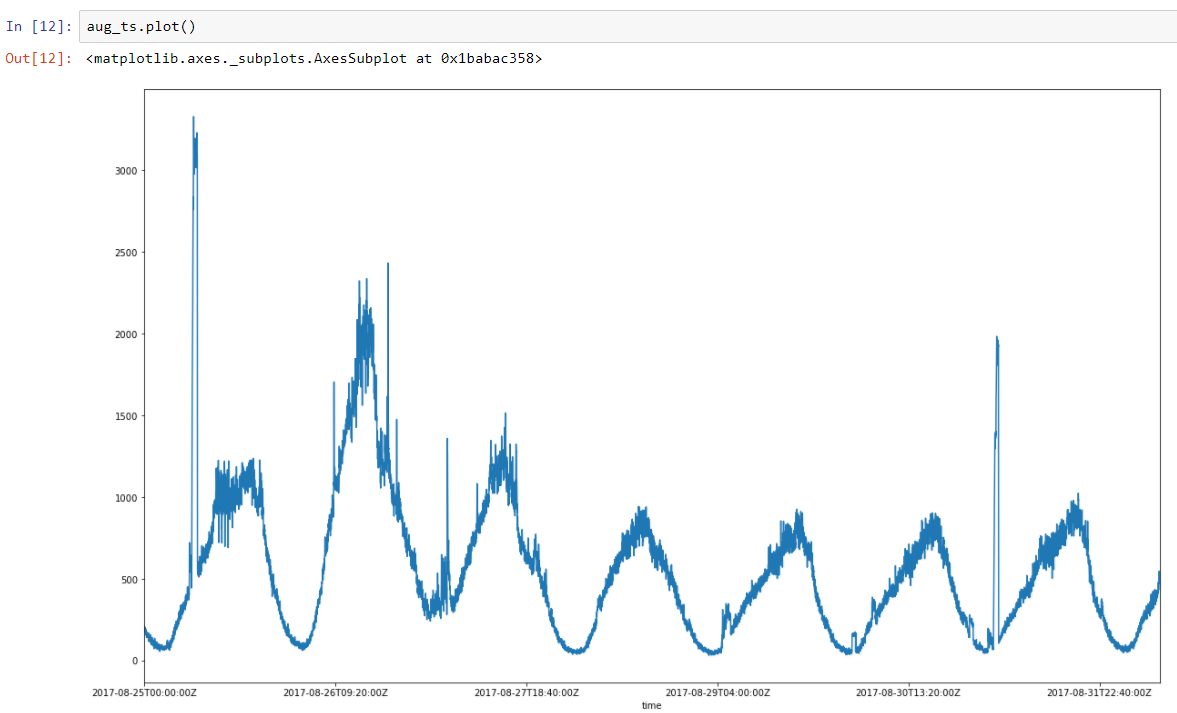
Take a weekly series of real data on the number of transactions. We can see pronounced regularity (two peaks are performance tests). There is daily regularity, plus an increase in activity on Friday and at the weekend, after which the activity begins to decline until the next weekend.
On Habré there were a lot of good materials on this subject, for example here .
On the Medium there is my introduction to time series modeling (in english): Time series modeling .
In a nutshell: each measurement contains signal components and measurement / noise errors. There are many factors that affect both the processes themselves and the collected metrics.
Point = Sig + err
We have a model that describes the signal. If you subtract the model from the measurement, then the better the model catches the signal, the more the result of the subtraction will tend to stationary or white noise - and this is already easy to verify.
In an article on the Medium, I gave examples of modeling linear and segmented regression.
For the monitoring system, I chose modeling using moving statistics for the average and the spread. The moving average is essentially a low pass filter that smooths out noise and leaves the main trend lines. Here is our data on the number of transactions in another week, after a moving average of 60 minutes with a window (peaks removed):
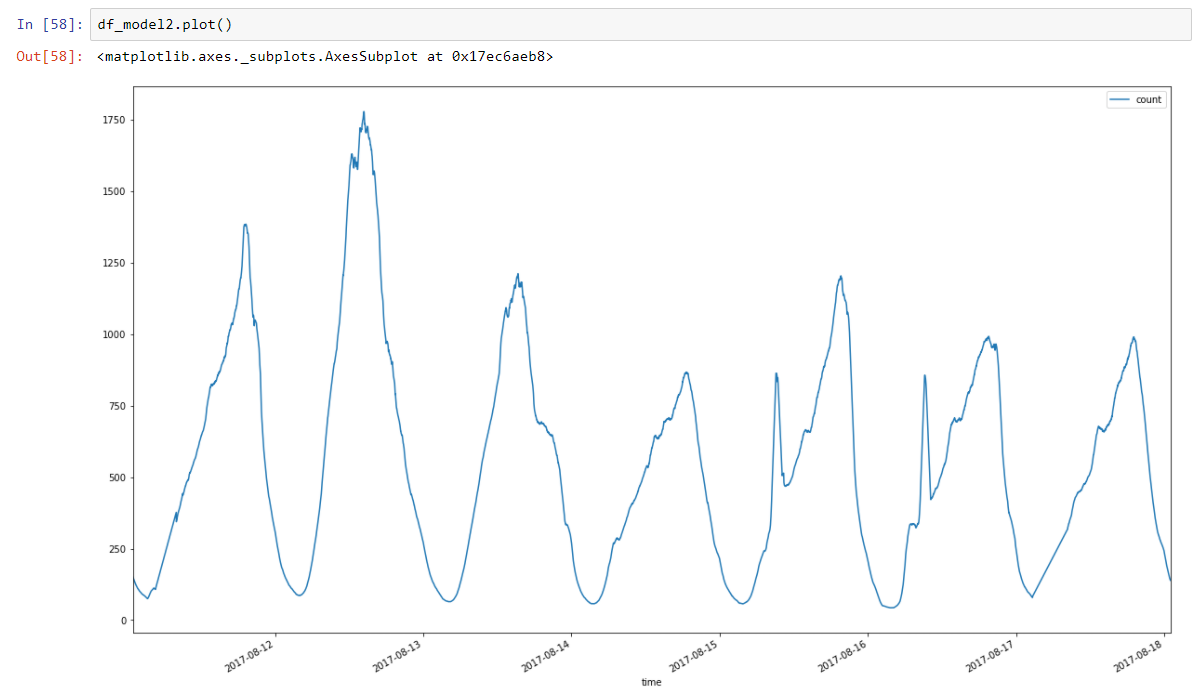
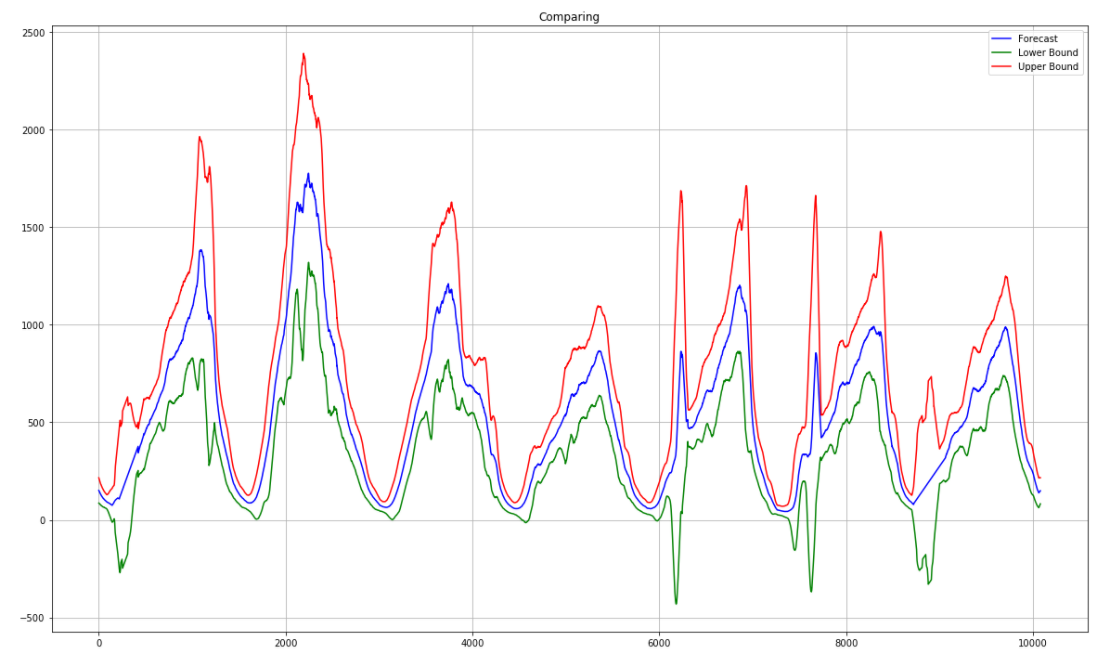
We also collect moving variance to set the acceptable boundaries of the model. As a result, we get something from Salvador Dali.
We will enter here the data for another week and immediately we can see outliers.
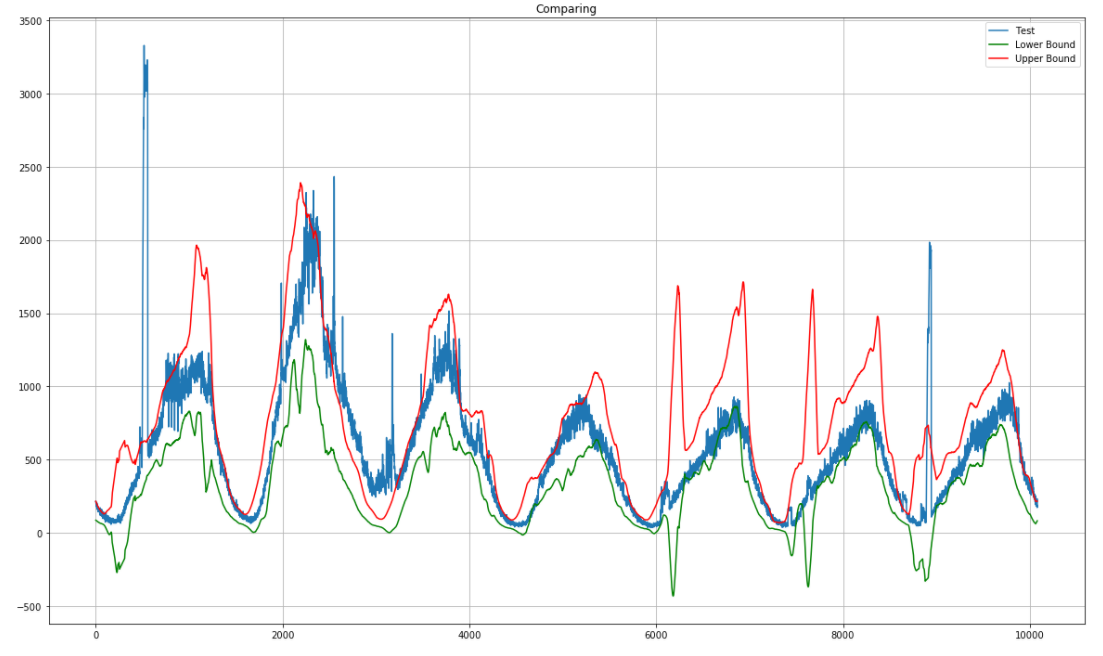
Now we have everything necessary to build our Alert System.
The experience of the Kale project indicates a very important point. Alerting is not the same as searching for anomalies and outliers in metrics, because, as already mentioned, anomalies on unit metrics will always be.
In fact, we have two logical levels.
- The first is a search for anomalies in metrics and sending a notification of a violation if an anomaly is found. This is the level of information emission.
- The second level is a component that receives information about violations and makes decisions about whether this is a critical incident or not.
This is how we humans act when we examine the problem. We look at something, when we find deviations from the norm, we look again, and then we make a decision based on observations.
At the beginning of the project, we decided to try Kapacitor, since it has the ability to define custom functions in Python. But each function sits in a separate process, which would create an overhead for hundreds and thousands of metrics. Due to this and some other problems, it was decided to refuse it.
Python was chosen as the main stack for building its own system, since there is an excellent ecosystem for data analysis, fast libraries (pandas, numpy, etc.), excellent support for web solutions. You name it.
For me, this was the first big project entirely implemented in Python. I myself came to Python from the Java world. I did not want to multiply the zoo stacks for one system, which was ultimately rewarded.
The system is built as a set of loosely coupled components or services that spin in their processes on their Python VM. This is natural for the general logical partitioning (events emitter / rules engine) and gives other advantages.
Each component does a limited number of specific things. In the future, this will allow you to quickly expand the system and add new user interfaces without affecting the core logic and not being afraid to break it. Between the components, fairly clear boundaries are drawn.
Distributed deploy is convenient if you need to place the agent locally closer to the site that it monitors - or you can aggregate a large number of different systems together.
Communication should be built on the basis of messages, since the entire system must be asynchronous.
I chose ActiveMQ as the Message Queue, but if you want to change, for example, to RabbitMQ, there will be no problems, since all components communicate using the standard STOMP protocol.
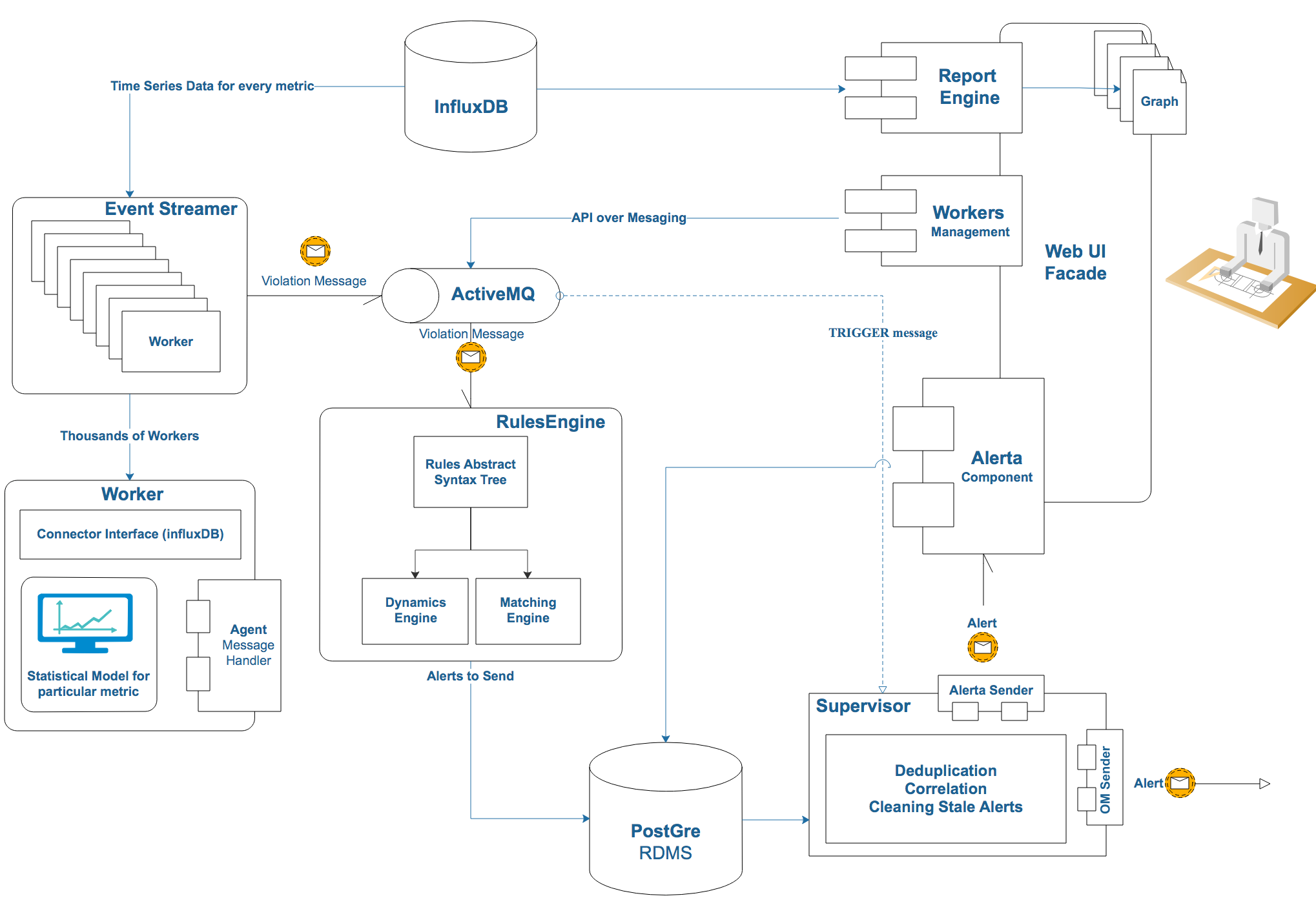
Event streamer is a component that stores statistical models, selects data with a certain frequency, and finds outliers. It is quite simple:
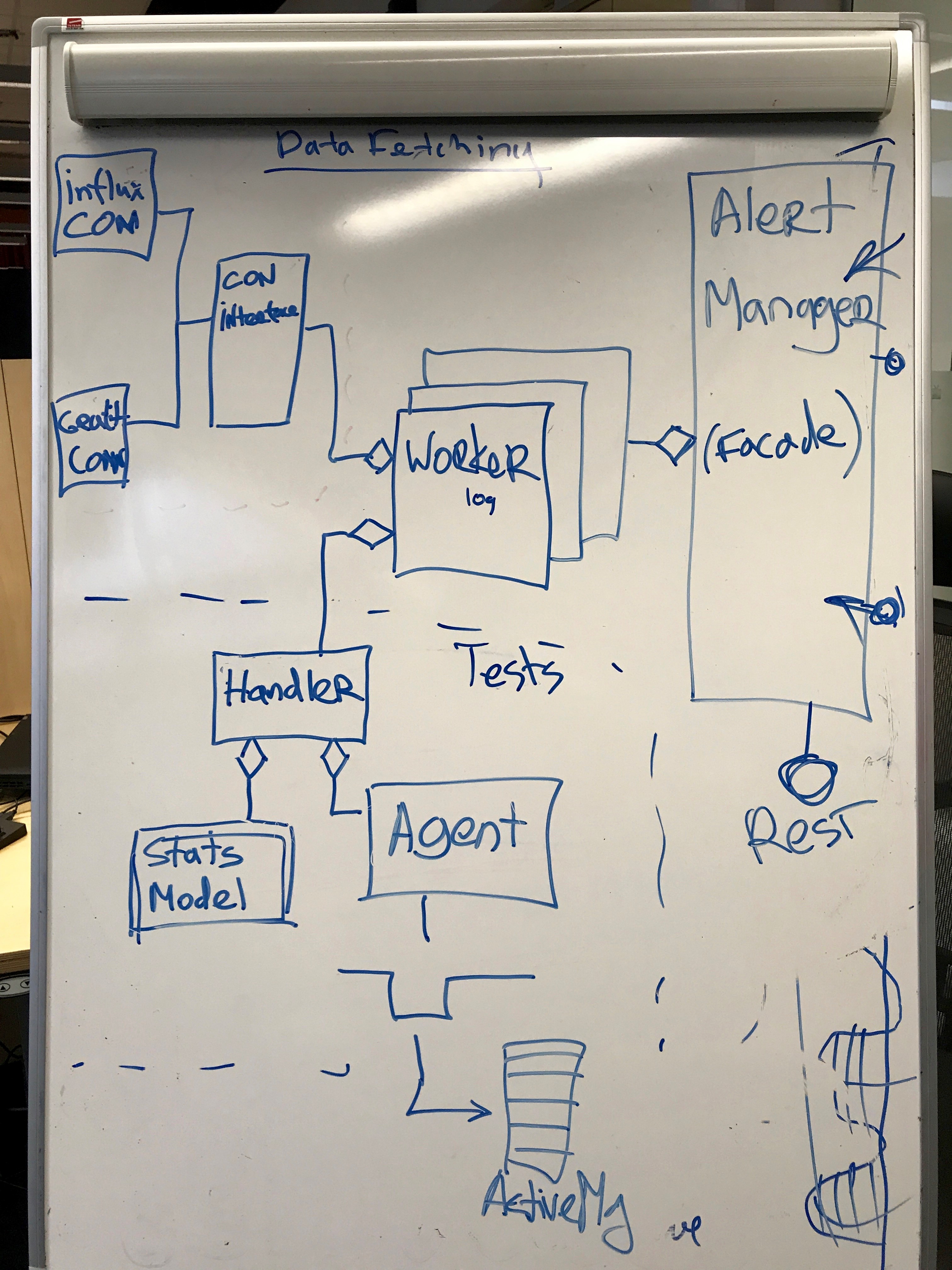
Worker is the main working unit that stores one model of one metric along with meta-information. It consists of the date of the connector and the handler to which the data is transmitted. Handler tests them on a statistical model, and if it detects violations, then passes them to the agent who sends the event to the queue.
Workerscompletely independent of each other, each cycle is performed through a pool of threads. Since most of the time is spent on I / O operations, the Global Interpreter Lock Python does not greatly affect the result. The number of threads is set in the config; on the current configuration, the optimal number was 8 threads.
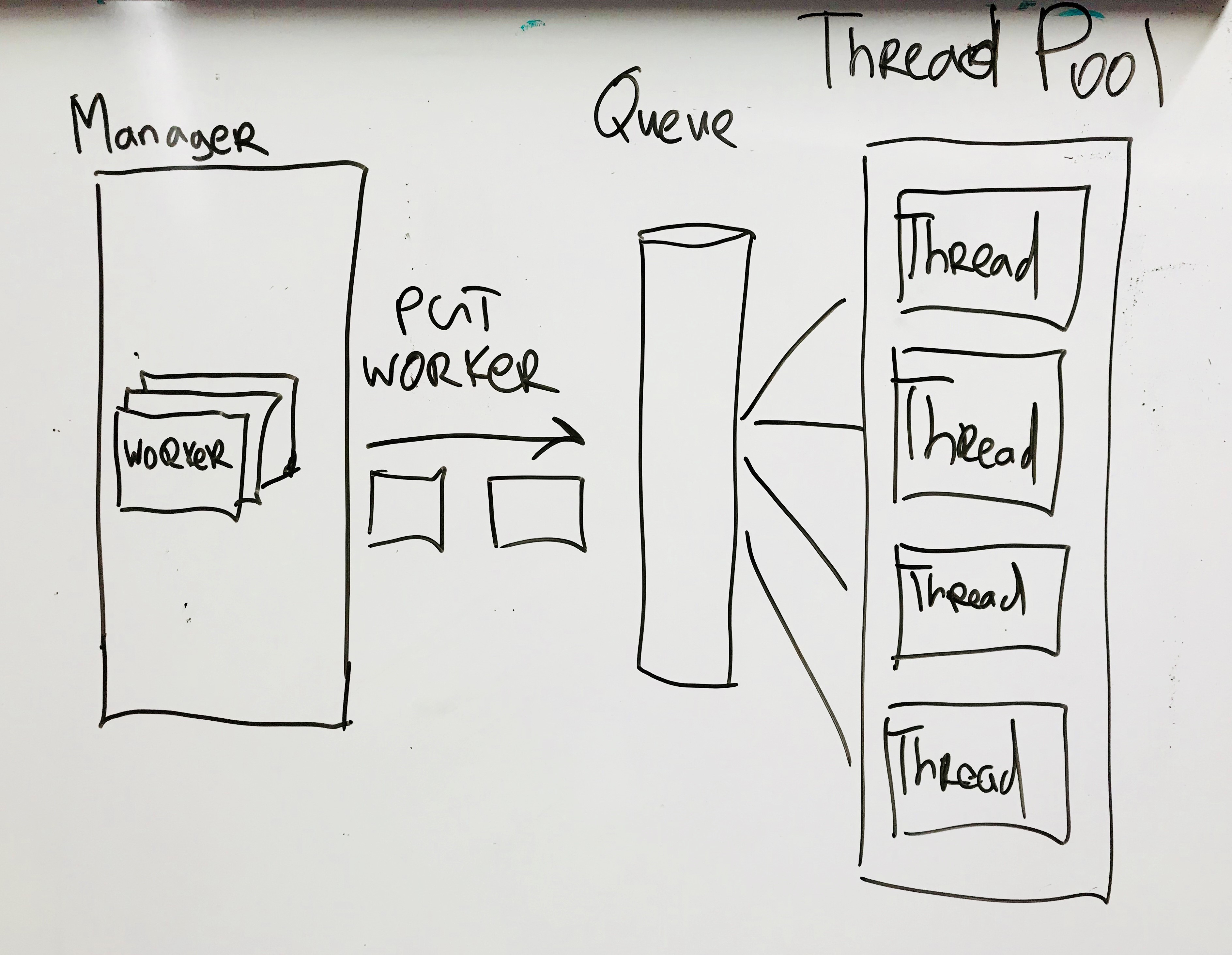
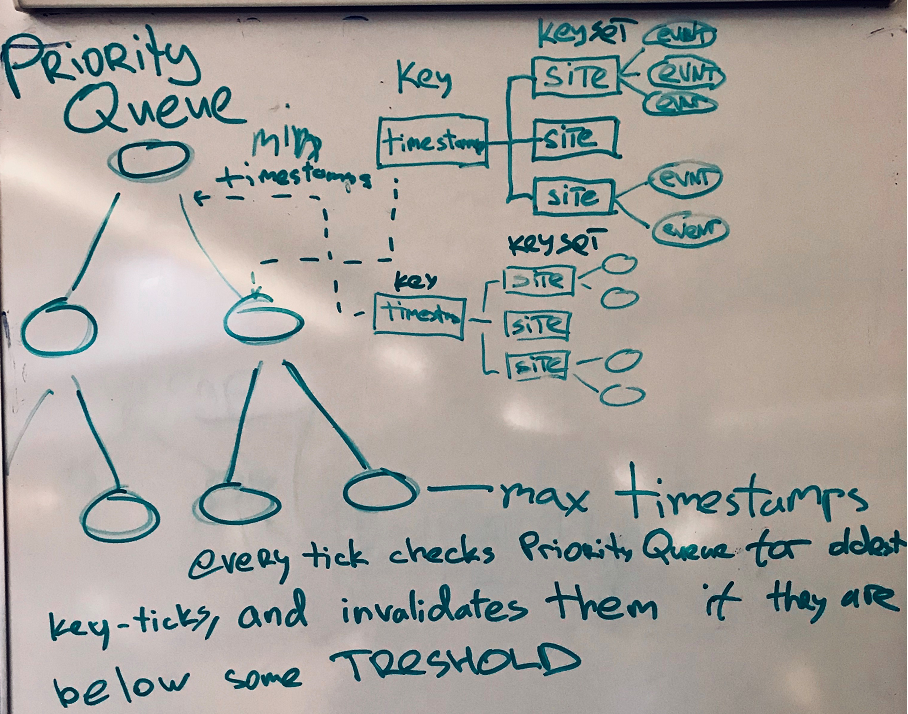
Now let's move on to the Consumer part. The component is subscribed to the topic in the queue and, when a message arrives, adds it to the dictionary associated with the tick and with each site. The system stores all events in a certain window and, upon receipt of each new message, deletes the oldest. In order not to view the entire dictionary, the keys are stored in a Priority Queue sorted by timestamp.
Architecturally, the component looks like this.
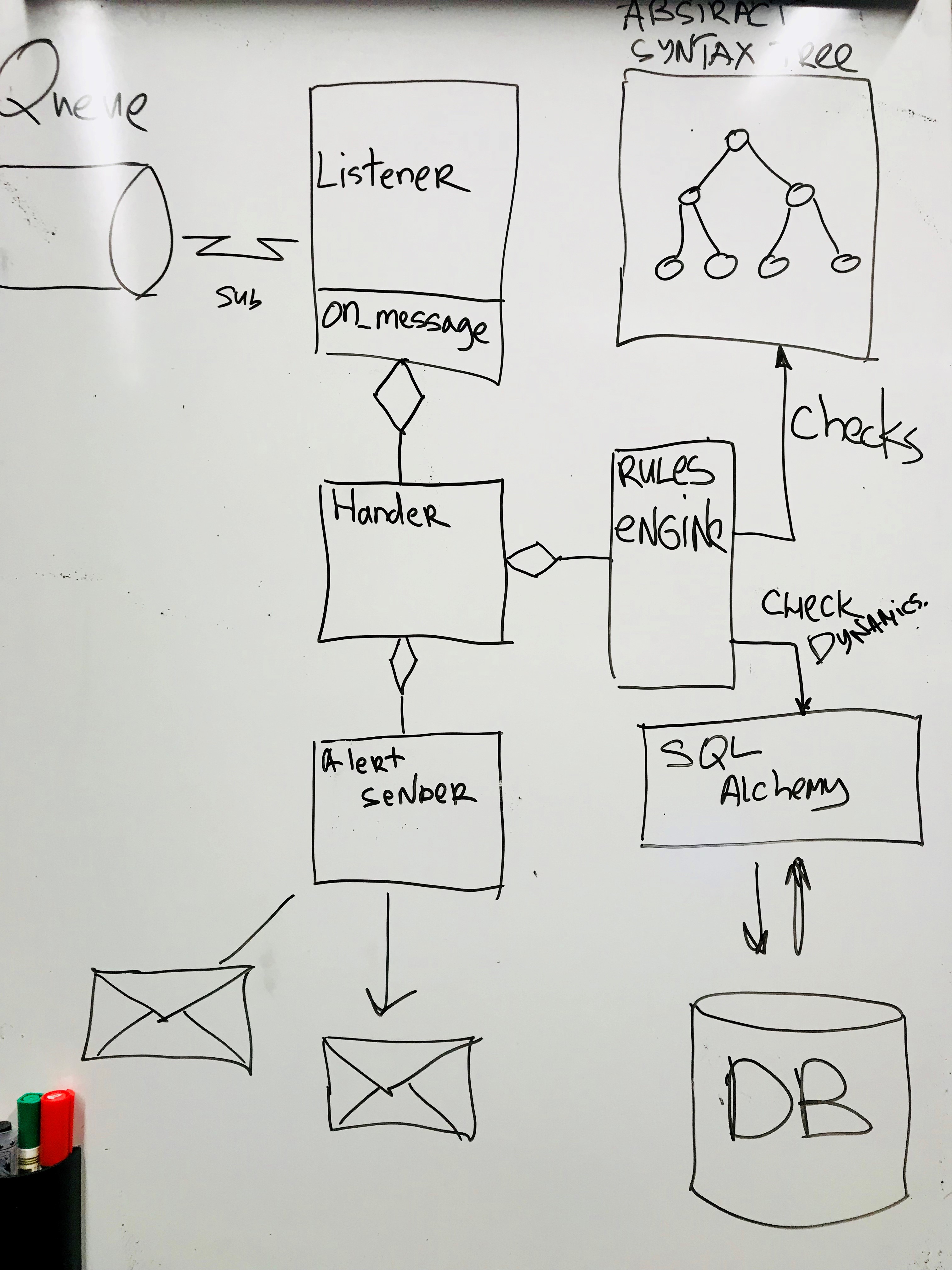
Each message is sent to the Rule Engine, and here the fun begins. At the very beginning of development, I rigidly set the rules in the code: when one metric falls and the other grows, then send an alert. But this solution is not universal and requires getting into the code for any extension. Therefore, we needed some kind of language that sets the rules. Here I had to recall Abstract Syntactic Trees and define a simple language for describing the rules.
Rules are described in YAML format, but you can use any other, just add your own parser. Rules are defined as regular expressions for metric names or simply metric prefixes. Speed is the rate of degradation of metrics, see below.
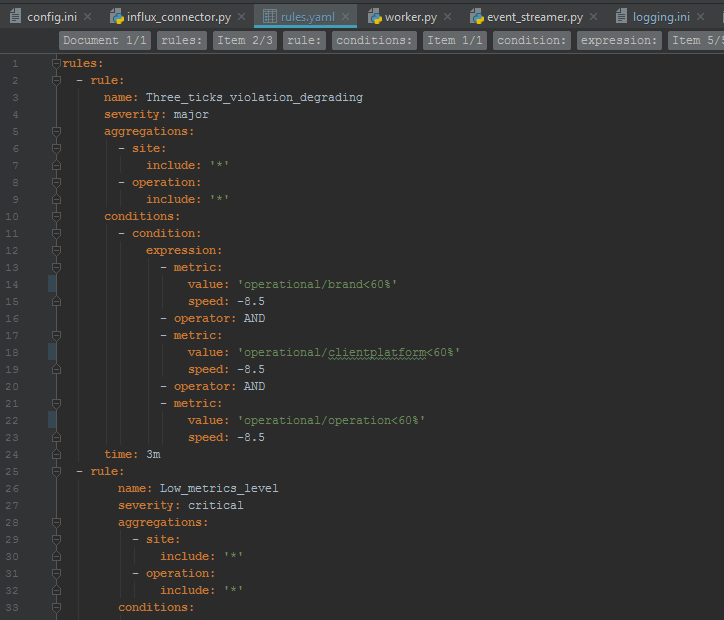
When the component starts, the rules are read and a syntax tree is built. Upon receipt of each message, all events from this site in one tick are checked according to the specified rules, and if the rule is triggered, an alert is generated. There may be several triggered rules.
If we consider the dynamics of incidents that develop over time, we can also take into account the rate of fall (severity level) and the change in speed (forecast of severity change)

Speed is an angular coefficient or a discrete derivative that is calculated for each violation. The same goes for acceleration, a second-order discrete derivative.
These values can be set in the rules. Cumulative derivatives of the first and second orders can be taken into account in the overall assessment of the incident.
To store historical events, a database is used through ORM (SQL Alchemy).
So, we have a working backend. Now you need a user interface for managing the system and reporting about metrics that worked on a specific rule.
I wanted to stay to the maximum on one stack. And here Dash comes to the rescue dash.plot.ly.
It is a framework for data visualization an add-on over Flask and Plotly. You can make interactive web interfaces not in a week or two, but in a matter of hours. Not a single line of Javascript, easy extensibility, and the output is ReactJS-based WebUI and perfect integration with Python.
One of the components through the WebUI controls the start, stop, assembly of Workers. Since we do not know in what state the component that stores the workers, whether the calculations have finished or not, all API calls go through messages (Remote Procedures Call over Messaging).
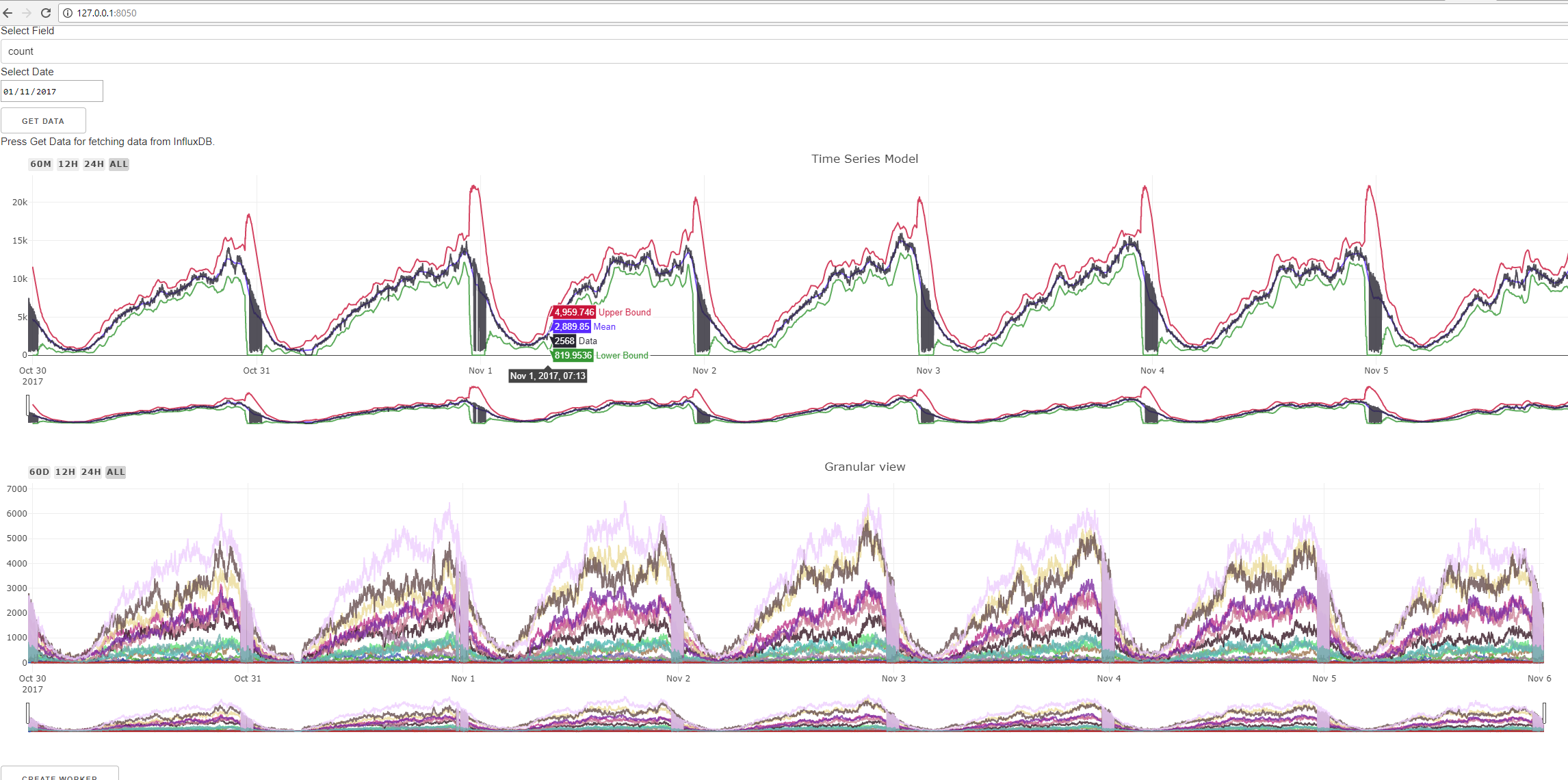
A separate component builds an on-demand dynamic report, which contains the metrics associated with this alert. When generating an alert, a report link is generated in one of the properties. Also, if desired, it is possible to receive a live stream.
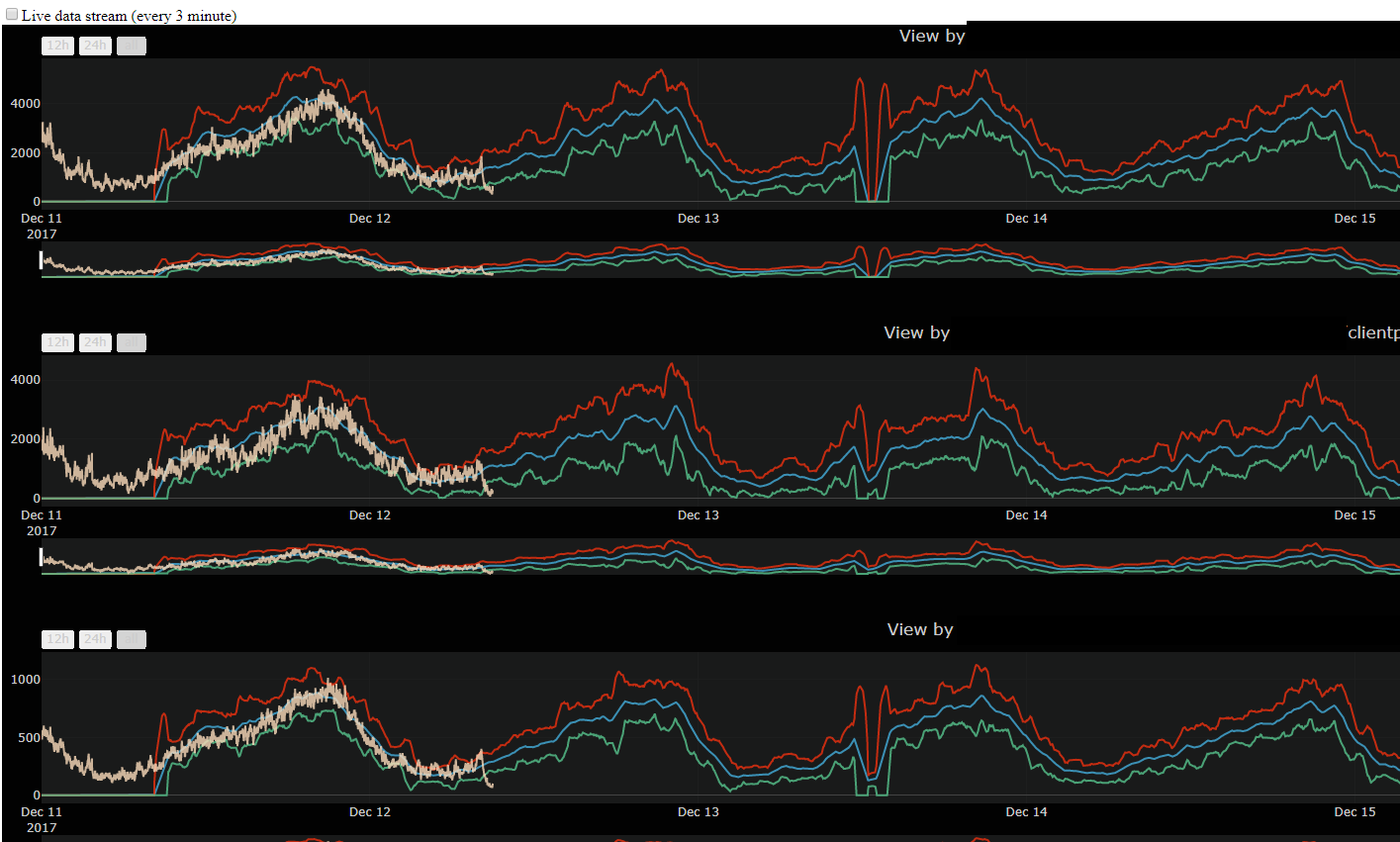
Also integration with Grafana has been done and you can follow the link to go to Grafana.
There is one more moment. Since alerts take off every time the rules work, with a long downtime, several alerts will be generated every minute. We need a system of accounting and deduplication. Our company already had such a system and I integrated there, but my colleague found a great alternative solution.
Meet Alerta .
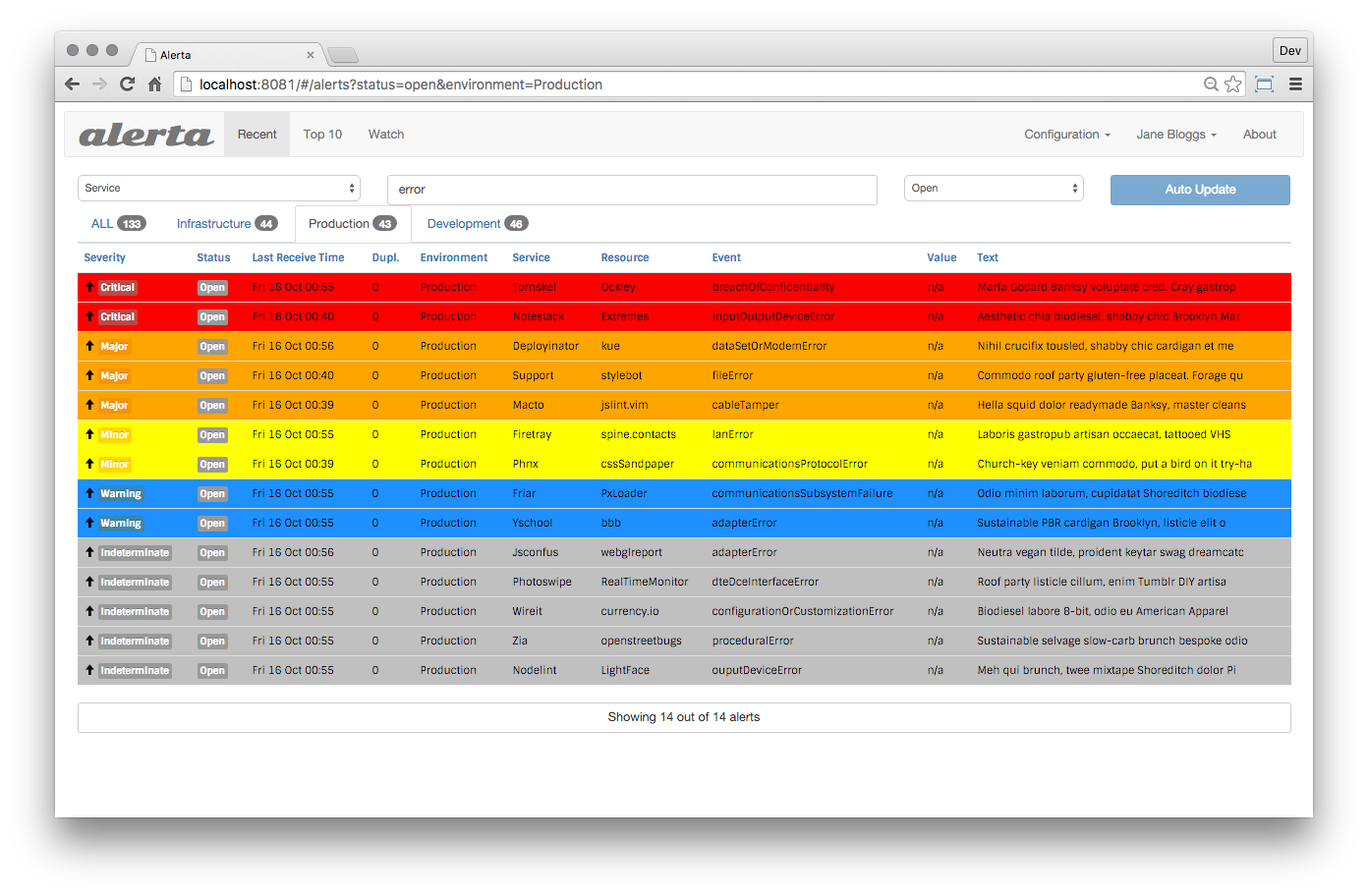
This is a great tool that integrates very easily, including the user interface that I built into WebUI systems. The Alert has ready-made integrations with Email, Slack, HipChat and so on. She can write Alerts back to influxDB for further visualization in Grafana.
From the moment of the first meeting to the release in production, a little more than 6 months passed. We catch most of the incidents a few minutes earlier (on average 12-15) than the old HP alert system. In addition, the system detects and signals some problems that have slipped through other monitoring systems.
Now we are developing statistics in the prod to fine-tune the rules. There are further plans for the development of the system, for example, try looking at metrics through Convolution Networks (a third-party project).
It was a very interesting adventure, which met abstract syntax trees, priority queues, matan, and much more. At the moment, the system consists of 5 components (microservices), along with Alert - 7 components. The company has the intention to release this system in open source, but this requires a few more months.
An adventure that is still ongoing.
Never fail twice is impossible, but failing on fails detection is even worse
Monitoring distributed systems is a fairly non-trivial task, where there are pitfalls. On the other hand, there are a huge number of both commercial and open-source solutions for various monitoring tasks. Under the cat about why open solutions did not suit us, what we understood from the analysis of successful and unsuccessful monitoring projects, and why it was decided to build Yet Another Alert System. It was a fascinating adventure, where at the stages from data analysis in Python to the final solution and building the system, we met almost all of Computer Science and even a bit of matana.
If we consider the monitoring problem as a whole, then the tasks are divided into two main groups.
- Low Level Monitoring - monitoring the infrastructure by the parameters of CPU, Disk usage networking, Java Heap Usage, GC cycles and so on. Everything is quite simple here and there are many working ready-made solutions. In many cases, simple thresholds are sufficient; in the case of the JVM, you can monitor the regularity of processes according to sawtooth Java heap plots - an increase in the peak frequency can indicate problems in memory management and frequent GC cycles.
- High Level Monitoring - when business indicators (BI) or Key Performance Indicators (KPI) are selected as metrics, such as volumes of user sessions, transactions, payments, etc. Low level monitoring cannot adequately reflect what is happening in the system at the level of business logic.
Why is it difficult?
- Monitoring a complex distributed system is an engineering problem in itself
- Various problems lead to implicit changes in the system behavior
- Many different metrics of one system
- Various metrics correlate with each other
I work as a Technical Architect in a large company, and we had problems with timely detection of problems in production systems.
We handle financial transactions in highly regulated markets. The system architecture is service-oriented, the components have a complex business logic, there are different backend options for different customers (B2B) of the company.
Low level monitoring and tests do not cover a number of problems
Firstly, due to the high complexity of the products and the huge number of settings, there are situations where incorrect settings lead to the degradation of financial performance, or hidden bugs in the logic affect the overall functionality of the entire system.
Secondly, there are specific 3d-party integrations for different countries, and problems that arise with partners begin to flow to us. Problems of this kind are not caught by low level monitoring; to solve them, you need to monitor key indicators (KPI), compare them with statistics on the system and look for correlations.
The company had previously implemented a solution from Hewlett Packard Service Health Analyzer, which was (to put it mildly) imperfect. Judging by the marketing prospectus, this is a system that learns itself and provides early detection of problems (SHA can take data streams from multiple sources and apply advanced, predictive algorithms in order to alert to and diagnose potential problems before they occur). In fact, it was a black box that could not be configured, you had to contact HP with all the problems and wait for months until the support engineers did something that would also not work as it should. And also - the terrible user interface, the old JVM ecosystem (Java 6.0), and, most importantly - a large number of False Positives and (even worse) False Negatives, that is, some serious problems were either not detected,
The figure shows that the SHA granularity of 15 minutes means that even in case of problems the minimum reaction time is 15 minutes ...
That is, it often looked like this ...
On the shoulders of giants
Many companies have tried to build their monitoring system. These have not always been success stories.
Etsy - Kale System
Etsy is an online marketplace for handmade goods. The company is headquartered in New York. The company collected more than 250,000 different metrics from its servers and tried to look for anomalies in the metrics using sophisticated mathematical algorithms. But ...
Meet Kale.
One of Kale's problems was that the system used many different technology stacks. In the diagram, you can see 4 different stacks, plus 2 frameworks. To develop and maintain the system, highly skilled engineers familiar with these stacks were required. Finding bugs also required knowledge in many stacks.
The second problem is the monitoring approach itself. Kale was only looking for anomalies. But if you have 250,000 metrics, then hundreds of anomalies will be statistically observed for each tick. If you expand the boundaries, then problems will slip. If you narrow down, there will be a huge amount of false positives.
Etsy engineers tried to fight the number of False Positives, but after three years of development, the project was closed. There is a good video on this subject from Andrew Clegg.
I want to highlight one slide from this video.
Finding anomalies is more than just catching outliers. Outliers emissions will be observed on any real production data in normal operation. Not all anomalies should lead to the inclusion of anxiety at all levels.
A universal approach is not suitable for anything; There are no free lunches. That's why HP's SHA solution does not work as it should, trying to be a universal tool.
And interestingly, possible approaches to solving these problems.
Send Alert on anomalies in business and user metrics
Use other metrics for Root Cause analysis.
Google SRE teams BorgMon
The book Site Reliability Engineering has a whole chapter devoted to the problem of monitoring the production of Google systems. In short, then
- Google aimed for simpler and faster monitoring systems with better tools for post hoc analysis.
- Their goal was to avoid magical systems that automatically learn thresholds or automatically look for correlations. A person should understand well what is happening in the system and by what rules alerts are generated.
- The rules for problem response systems were kept as simple as possible. They gave a very fast response time to simple, localized, serious anomalies.
- A person should understand well what is happening in the system and by what rules alerts are generated.
Google built the successful BorgMon system on these principles.
Time series
A time series is a series of data indexed by time. If we take as a number economic processes (from the production of champagne to sales in stores or online transactions), then they have some common properties: the processes are regular, have some periodicity, usually have seasonal periods and trend lines. Using this information can simplify the analysis.
Take a weekly series of real data on the number of transactions. We can see pronounced regularity (two peaks are performance tests). There is daily regularity, plus an increase in activity on Friday and at the weekend, after which the activity begins to decline until the next weekend.
On Habré there were a lot of good materials on this subject, for example here .
On the Medium there is my introduction to time series modeling (in english): Time series modeling .
In a nutshell: each measurement contains signal components and measurement / noise errors. There are many factors that affect both the processes themselves and the collected metrics.
Point = Sig + err
We have a model that describes the signal. If you subtract the model from the measurement, then the better the model catches the signal, the more the result of the subtraction will tend to stationary or white noise - and this is already easy to verify.
In an article on the Medium, I gave examples of modeling linear and segmented regression.
For the monitoring system, I chose modeling using moving statistics for the average and the spread. The moving average is essentially a low pass filter that smooths out noise and leaves the main trend lines. Here is our data on the number of transactions in another week, after a moving average of 60 minutes with a window (peaks removed):
We also collect moving variance to set the acceptable boundaries of the model. As a result, we get something from Salvador Dali.
We will enter here the data for another week and immediately we can see outliers.
Now we have everything necessary to build our Alert System.
An important digression.
The experience of the Kale project indicates a very important point. Alerting is not the same as searching for anomalies and outliers in metrics, because, as already mentioned, anomalies on unit metrics will always be.
In fact, we have two logical levels.
- The first is a search for anomalies in metrics and sending a notification of a violation if an anomaly is found. This is the level of information emission.
- The second level is a component that receives information about violations and makes decisions about whether this is a critical incident or not.
This is how we humans act when we examine the problem. We look at something, when we find deviations from the norm, we look again, and then we make a decision based on observations.
At the beginning of the project, we decided to try Kapacitor, since it has the ability to define custom functions in Python. But each function sits in a separate process, which would create an overhead for hundreds and thousands of metrics. Due to this and some other problems, it was decided to refuse it.
Python was chosen as the main stack for building its own system, since there is an excellent ecosystem for data analysis, fast libraries (pandas, numpy, etc.), excellent support for web solutions. You name it.
For me, this was the first big project entirely implemented in Python. I myself came to Python from the Java world. I did not want to multiply the zoo stacks for one system, which was ultimately rewarded.
General architecture.
The system is built as a set of loosely coupled components or services that spin in their processes on their Python VM. This is natural for the general logical partitioning (events emitter / rules engine) and gives other advantages.
Each component does a limited number of specific things. In the future, this will allow you to quickly expand the system and add new user interfaces without affecting the core logic and not being afraid to break it. Between the components, fairly clear boundaries are drawn.
Distributed deploy is convenient if you need to place the agent locally closer to the site that it monitors - or you can aggregate a large number of different systems together.
Communication should be built on the basis of messages, since the entire system must be asynchronous.
I chose ActiveMQ as the Message Queue, but if you want to change, for example, to RabbitMQ, there will be no problems, since all components communicate using the standard STOMP protocol.
Event streamer is a component that stores statistical models, selects data with a certain frequency, and finds outliers. It is quite simple:
Worker is the main working unit that stores one model of one metric along with meta-information. It consists of the date of the connector and the handler to which the data is transmitted. Handler tests them on a statistical model, and if it detects violations, then passes them to the agent who sends the event to the queue.
Workerscompletely independent of each other, each cycle is performed through a pool of threads. Since most of the time is spent on I / O operations, the Global Interpreter Lock Python does not greatly affect the result. The number of threads is set in the config; on the current configuration, the optimal number was 8 threads.
Now let's move on to the Consumer part. The component is subscribed to the topic in the queue and, when a message arrives, adds it to the dictionary associated with the tick and with each site. The system stores all events in a certain window and, upon receipt of each new message, deletes the oldest. In order not to view the entire dictionary, the keys are stored in a Priority Queue sorted by timestamp.
Architecturally, the component looks like this.
Each message is sent to the Rule Engine, and here the fun begins. At the very beginning of development, I rigidly set the rules in the code: when one metric falls and the other grows, then send an alert. But this solution is not universal and requires getting into the code for any extension. Therefore, we needed some kind of language that sets the rules. Here I had to recall Abstract Syntactic Trees and define a simple language for describing the rules.
Rules are described in YAML format, but you can use any other, just add your own parser. Rules are defined as regular expressions for metric names or simply metric prefixes. Speed is the rate of degradation of metrics, see below.
When the component starts, the rules are read and a syntax tree is built. Upon receipt of each message, all events from this site in one tick are checked according to the specified rules, and if the rule is triggered, an alert is generated. There may be several triggered rules.
If we consider the dynamics of incidents that develop over time, we can also take into account the rate of fall (severity level) and the change in speed (forecast of severity change)
Speed is an angular coefficient or a discrete derivative that is calculated for each violation. The same goes for acceleration, a second-order discrete derivative.
These values can be set in the rules. Cumulative derivatives of the first and second orders can be taken into account in the overall assessment of the incident.
To store historical events, a database is used through ORM (SQL Alchemy).
So, we have a working backend. Now you need a user interface for managing the system and reporting about metrics that worked on a specific rule.
I wanted to stay to the maximum on one stack. And here Dash comes to the rescue dash.plot.ly.
It is a framework for data visualization an add-on over Flask and Plotly. You can make interactive web interfaces not in a week or two, but in a matter of hours. Not a single line of Javascript, easy extensibility, and the output is ReactJS-based WebUI and perfect integration with Python.
One of the components through the WebUI controls the start, stop, assembly of Workers. Since we do not know in what state the component that stores the workers, whether the calculations have finished or not, all API calls go through messages (Remote Procedures Call over Messaging).
A separate component builds an on-demand dynamic report, which contains the metrics associated with this alert. When generating an alert, a report link is generated in one of the properties. Also, if desired, it is possible to receive a live stream.
Also integration with Grafana has been done and you can follow the link to go to Grafana.
There is one more moment. Since alerts take off every time the rules work, with a long downtime, several alerts will be generated every minute. We need a system of accounting and deduplication. Our company already had such a system and I integrated there, but my colleague found a great alternative solution.
Meet Alerta .
The alerta monitoring system is a tool used to consolidate and de-duplicate alerts from multiple sources for quick 'at-a-glance' visualization. With just one system you can monitor alerts from many other monitoring tools on a single screen.Alert is a tool used to consolidate and deduplicate signals from many sources along with their visualization and accounting.
This is a great tool that integrates very easily, including the user interface that I built into WebUI systems. The Alert has ready-made integrations with Email, Slack, HipChat and so on. She can write Alerts back to influxDB for further visualization in Grafana.
From the moment of the first meeting to the release in production, a little more than 6 months passed. We catch most of the incidents a few minutes earlier (on average 12-15) than the old HP alert system. In addition, the system detects and signals some problems that have slipped through other monitoring systems.
Now we are developing statistics in the prod to fine-tune the rules. There are further plans for the development of the system, for example, try looking at metrics through Convolution Networks (a third-party project).
It was a very interesting adventure, which met abstract syntax trees, priority queues, matan, and much more. At the moment, the system consists of 5 components (microservices), along with Alert - 7 components. The company has the intention to release this system in open source, but this requires a few more months.
An adventure that is still ongoing.