Predictive word processing
Works related to natural language is one of the key tasks for creating artificial intelligence. Their complexity has been greatly underestimated for a long time. One of the reasons for early optimism in the field of natural language was Noam Chomsky's pioneering work on generative grammars. In his book Syntactic Structures and other works, Chomsky proposed an idea that now seems completely ordinary, but then revolutionized: he transformed a sentence in natural language into a tree that shows the relationship between the different words in the sentence.
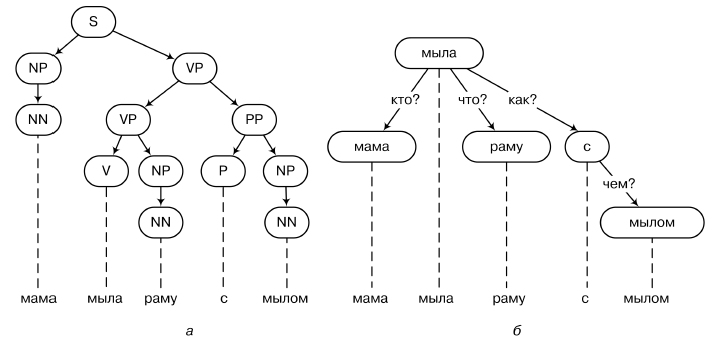
An example of a parsing tree is shown in the figure above (a - parsing based on the structure of the direct components; b - based on the dependency grammar). A generating grammar is a set of rules of the form S → NP VP or VP → V NP by which such trees can be generated. On the trees of parsing, you can build fairly strict constructions, try to determine, for example, the logic of a natural language, with real axioms and rules of inference.
Now this approach to parsing is called structure-based analysis.
direct components, or phrase-structural grammars (phrasestructure based parsing). Chomsky, of course, put forward other hypotheses along the way - in particular, one of his central ideas was the idea of a “universal grammar” of the human language, which, at least partially, was laid down at the genetic level, even before the birth of a child, but it is important for us now it is this new connection between natural language and mathematics, which over time has turned linguistics into one of the most “exact” of the humanities.
For artificial intelligence, at first this linguistic breakthrough looked like an indulgence of unbridled optimism: it seemed that since natural language could be represented in the form of such rigorous mathematical constructions, then soon we could finally formalize it, transfer the formalization to a computer, and it could soon talk to us . However, in practice, this program met, to put it mildly, significant difficulties: it turned out that natural language is not as formal as it seemed before, and most importantly, it depends to a large extent on implicit assumptions, which are not easy to formalize. Moreover, it turns out that in order to understand the natural language one often needs to not just “parse” such a nevertheless sufficiently well-defined formal object as a sequence of letters or words,
A simple and understandable example of such an extremely complex task is the resolution of anaphora (anaphora resolution), that is, an understanding of what this or that pronoun in the text refers to. Compare the two sentences: “Mom washed the frame, and now she’s shining” and “Mom washed the frame, and now she’s tired.” Structurally, they are exactly the same. But imagine how much the computer needs to know and understand in order to correctly determine what the pronoun “she” refers to in each of these phrases!
And this is not some specially invented perverse example, but the everyday reality of our language with you; we constantly make references to what people understand “naturally” ... but for a computer model this is completely illogical! It is “commonsense reasoning” that is the main stumbling block for modern natural language processing. By the way, specialists in natural language processing have long been trying to specifically work in this direction; For more than ten years, an annual seminar on “common sense”, the International Symposium on Logical Formalization on Commonsense Reasoning, has been held, and recently a common-sense task contest, called the Winograd Schema Challenge in honor of Terry Vinograd, has also begun.
The tasks there are approximately the following: “The cup did not fit in the suitcase because it was too large; what was too large, a suitcase or a cup? ”
So, although people work on word processing and even make significant progress, computers have not yet learned to talk. Yes, and understanding the written text is still a disaster, although they also work with the help of deep learning on speech recognition and synthesis. But before we begin to apply neural networks to natural language, we need to discuss another question that the reader must have already raised: what, in fact, does it mean to “understand the text”? Machine learning lessons taught us that first of all we need to define a task, a goal function that we want to optimize. How to optimize "understanding"?
Of course, intellectual text processing is not one task, but a lot, and all of them are one way or another subject to man and are connected with the “holy grail” of understanding the text. Let's list and briefly comment on the main easily quantifiable word processing problems; some of these will be discussed later in this chapter; we will try to go from simple to complex and conditionally divide them into three classes.
1. The tasks of the first class can be conditionally called syntactic; here the tasks are, as a rule, very well defined and represent classification problems or problems of generating discrete objects, and many of them are now being solved quite well, for example:
(i) part-of-speech tagging: mark words in a given text according to parts of speech (noun, verb, adjective ...) and, possibly, according to morphological characteristics (gender, case ...);
(ii) morphological segmentation: divide words in a given text into morphemes, that is, syntactic units like prefixes, suffixes and endings; for some languages (for example, English) this is not very relevant, but there are a lot of morphologies in the Russian language;
(iii) another version of the problem of the morphology of individual words - stemming, in which it is necessary to highlight the basics of words, or lemmatization (lemmatization), in which the word must be reduced to the basic form (for example, the singular form of the masculine gender);
(iv) sentence boundary disambiguation: split the given text into sentences; it may seem that they are separated by dots and other punctuation marks and begin with a capital letter, but remember, for example, how “in 1995 T. Vinograd became the supervisor of L. Page,” and you will realize that the task is not easy; and in languages like Chinese, even the task of word segmentation becomes very non-trivial, because the stream of hieroglyphs without spaces can be divided into words in different ways;
(v) named entity recognition: to find in the text the proper names of people, geographical and other objects, marking them by type of entity (names, toponyms, etc.);
(vi) word sense disambiguation: choose which of the homonyms, which of the different meanings of the same word is used in this passage of the text;
(vii) syntactic parsing: according to a given sentence (and, possibly, its context) to construct a syntax tree, directly according to Chomsky;
(viii) coreference resolution: to determine which objects or other parts of the text refer to certain words and phrases; A special case of this problem is the very resolution of anaphora, which we discussed above.
2. The second class consists of tasks that generally require an understanding of the text, but in terms of form they are still well-defined tasks with correct answers (for example, classification problems), for which it is easy to come up with no doubt quality metrics. Such tasks include, but are not limited to:
(i) language models: for a given passage of text, predict the next word or symbol; this task is very important, for example, for speech recognition (see a little below);
(ii) information retrieval, the central task that Google and Yandex solve: by a given query and a huge number of documents, find among them the most relevant to this query;
(iii) sentiment analysis: to determine its tonality from the text, i.e. whether the text is positive or negative; tonality analysis is used in online trading to analyze user reviews, in finance and trading to analyze articles in the press, company reports, and similar texts, etc .;
(iv) extraction of relations or facts (relationship extraction, fact extraction): to extract from the text well-defined relations or facts about the entities mentioned there; for example, who is in family relationship with whom, in what year is the company mentioned in the text founded, etc.
(v) question answering questions: answer the question asked; depending on the setting, it can be either a pure classification (a choice from answer options, as in the test), or a classification with a very large number of classes (answers to factual questions like “who?” or “in which year?”), or even a result text (if you need to answer questions as part of a natural dialogue).
3. And finally, in the third class we assign tasks in which it is necessary not only to understand the already written text, but also to generate a new one. Here, quality metrics are no longer always obvious, and we will discuss this issue below. Such tasks include, for example:
(i) the actual generation of text (text generation);
(ii) automatic summarization: from the text to generate its summary, abstract, so to speak; this can be considered as a classification problem, if you ask the model to choose ready-made sentences from the text that best reflect the general meaning, or as a generation problem, if you need to write a brief summary from scratch;
(iii) machine translation: from a text in one language, generate the corresponding text in another language;
(iv) dialog and conversational models: maintain a conversation with a person; the first chat bots began to appear in the 1970s, and today it is a big industry; and although it is still not possible to conduct a full-fledged dialogue and pass the Turing test, the dialogue models are already working in full swing (for example, the first line of “online consultants” on different trading sites is almost always chat bots).
An important problem for the models of the last class is quality assessment. You can have a set of parallel translations that we think are good, but how do you evaluate the new translation made by the model? Or, even more interesting, how to evaluate the response of the dialogue model in a conversation? One possible answer to this question is BLEU (Bilingual Evaluation Understudy) [48], a class of metrics designed for machine translation but also used for other tasks. BLEU is a modification of the accuracy of the coincidence of the answer of the model and the “right answer”, re-weighted so as not to give an ideal rating to the answer from one correct word. For the entire test case, BLEU is considered as follows:
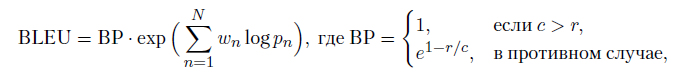
where r is the total length of the correct answer, c is the length of the model response, pn is the modified accuracy, and wn are the positive weights that add up to one. There are other similar metrics: METEOR [298] - harmonic mean of accuracy and completeness over unigrams, TER (translation edit rate) [513] calculates the relative number of corrections that need to be made to the model output to get a reference output, ROUGE [326] counts the fraction of the intersection of the sets of n-grams of words in the standard and in the resulting text, and LEPOR [204] completely combines several different metrics with different weights, which can also be trained (many authors of these articles are French, and the abbreviations are French-speaking).
However, it is curious that although metrics like BLEU and METEOR are still commonly used, it’s actually not at all a fact that this is the best choice. Firstly, BLEU has a discrete set of values, so that it cannot be directly optimized by gradient descent. But it is even more interesting that in [232] very surprising results of using various similar quality metrics in the context of evaluating model responses in a dialogue are presented. There, correlations (both ordinary and rank) of human assessments of the quality of answers and assessments by different metrics are calculated ... and it turns out that these correlations are almost always close to zero, and sometimes completely negative! The best version of BLEU was able to achieve a correlation with human ratings of about 0.35 on one dataset, and on the other a total of 0, 12 (try publishing the scientific result with such a correlation!). Moreover, such poor results do not mean that the correct answer does not exist at all: the ratings of different people always had correlation with each other at the level of 0.95 and higher, so that the “gold standard” of quality assessment certainly exists, but how to formalize it, we we don’t understand at all yet. This criticism has already led to new designs of automatically-trained quality metrics [537], and we hope that new results will appear in this direction. Nevertheless, while there are no easily applicable alternatives to metrics like BLEU, and they are usually used. so, the “gold standard” of quality assessment certainly exists, but we still do not understand how to formalize it. This criticism has already led to new designs of automatically-trained quality metrics [537], and we hope that new results will appear in this direction. Nevertheless, while there are no easily applicable alternatives to metrics like BLEU, and they are usually used. so, the “gold standard” of quality assessment certainly exists, but we still do not understand how to formalize it. This criticism has already led to new designs of automatically-trained quality metrics [537], and we hope that new results will appear in this direction. Nevertheless, while there are no easily applicable alternatives to metrics like BLEU, and they are usually used.
In addition, there is still a wide class of tasks related to text, but accepting not an sequence of characters as input, but an input of a different nature. For example, without understanding the language, it is almost impossible to learn how to perfectly recognize speech: although it seems that speech recognition is just a task of classifying phonemes by sound, in reality a person misses a lot of sounds and completes a significant part of what he hears based on his understanding of the language. Back in the 1990s, speech recognition systems reached a human level in recognizing individual phonemes: if you seat people to a tape recorder, let them listen to sounds without context and ask them to distinguish “a” from “o”, the results will not be outstanding; therefore, for example, to write down what is being dictated to you, you need to know the language in which it occurs.
We will return to many of these tasks in the future. However, the main content of this chapter is not to solve a specific problem of natural language processing, but to talk about the designs on which almost all modern neural network approaches to such problems are based - about distributed representations of words.
An excerpt from the book by Sergei Nikolenko, Arthur Kadurin and Ekaterina Arkhangelskaya “Deep Learning”
An example of a parsing tree is shown in the figure above (a - parsing based on the structure of the direct components; b - based on the dependency grammar). A generating grammar is a set of rules of the form S → NP VP or VP → V NP by which such trees can be generated. On the trees of parsing, you can build fairly strict constructions, try to determine, for example, the logic of a natural language, with real axioms and rules of inference.
Now this approach to parsing is called structure-based analysis.
direct components, or phrase-structural grammars (phrasestructure based parsing). Chomsky, of course, put forward other hypotheses along the way - in particular, one of his central ideas was the idea of a “universal grammar” of the human language, which, at least partially, was laid down at the genetic level, even before the birth of a child, but it is important for us now it is this new connection between natural language and mathematics, which over time has turned linguistics into one of the most “exact” of the humanities.
For artificial intelligence, at first this linguistic breakthrough looked like an indulgence of unbridled optimism: it seemed that since natural language could be represented in the form of such rigorous mathematical constructions, then soon we could finally formalize it, transfer the formalization to a computer, and it could soon talk to us . However, in practice, this program met, to put it mildly, significant difficulties: it turned out that natural language is not as formal as it seemed before, and most importantly, it depends to a large extent on implicit assumptions, which are not easy to formalize. Moreover, it turns out that in order to understand the natural language one often needs to not just “parse” such a nevertheless sufficiently well-defined formal object as a sequence of letters or words,
A simple and understandable example of such an extremely complex task is the resolution of anaphora (anaphora resolution), that is, an understanding of what this or that pronoun in the text refers to. Compare the two sentences: “Mom washed the frame, and now she’s shining” and “Mom washed the frame, and now she’s tired.” Structurally, they are exactly the same. But imagine how much the computer needs to know and understand in order to correctly determine what the pronoun “she” refers to in each of these phrases!
And this is not some specially invented perverse example, but the everyday reality of our language with you; we constantly make references to what people understand “naturally” ... but for a computer model this is completely illogical! It is “commonsense reasoning” that is the main stumbling block for modern natural language processing. By the way, specialists in natural language processing have long been trying to specifically work in this direction; For more than ten years, an annual seminar on “common sense”, the International Symposium on Logical Formalization on Commonsense Reasoning, has been held, and recently a common-sense task contest, called the Winograd Schema Challenge in honor of Terry Vinograd, has also begun.
The tasks there are approximately the following: “The cup did not fit in the suitcase because it was too large; what was too large, a suitcase or a cup? ”
So, although people work on word processing and even make significant progress, computers have not yet learned to talk. Yes, and understanding the written text is still a disaster, although they also work with the help of deep learning on speech recognition and synthesis. But before we begin to apply neural networks to natural language, we need to discuss another question that the reader must have already raised: what, in fact, does it mean to “understand the text”? Machine learning lessons taught us that first of all we need to define a task, a goal function that we want to optimize. How to optimize "understanding"?
Of course, intellectual text processing is not one task, but a lot, and all of them are one way or another subject to man and are connected with the “holy grail” of understanding the text. Let's list and briefly comment on the main easily quantifiable word processing problems; some of these will be discussed later in this chapter; we will try to go from simple to complex and conditionally divide them into three classes.
1. The tasks of the first class can be conditionally called syntactic; here the tasks are, as a rule, very well defined and represent classification problems or problems of generating discrete objects, and many of them are now being solved quite well, for example:
(i) part-of-speech tagging: mark words in a given text according to parts of speech (noun, verb, adjective ...) and, possibly, according to morphological characteristics (gender, case ...);
(ii) morphological segmentation: divide words in a given text into morphemes, that is, syntactic units like prefixes, suffixes and endings; for some languages (for example, English) this is not very relevant, but there are a lot of morphologies in the Russian language;
(iii) another version of the problem of the morphology of individual words - stemming, in which it is necessary to highlight the basics of words, or lemmatization (lemmatization), in which the word must be reduced to the basic form (for example, the singular form of the masculine gender);
(iv) sentence boundary disambiguation: split the given text into sentences; it may seem that they are separated by dots and other punctuation marks and begin with a capital letter, but remember, for example, how “in 1995 T. Vinograd became the supervisor of L. Page,” and you will realize that the task is not easy; and in languages like Chinese, even the task of word segmentation becomes very non-trivial, because the stream of hieroglyphs without spaces can be divided into words in different ways;
(v) named entity recognition: to find in the text the proper names of people, geographical and other objects, marking them by type of entity (names, toponyms, etc.);
(vi) word sense disambiguation: choose which of the homonyms, which of the different meanings of the same word is used in this passage of the text;
(vii) syntactic parsing: according to a given sentence (and, possibly, its context) to construct a syntax tree, directly according to Chomsky;
(viii) coreference resolution: to determine which objects or other parts of the text refer to certain words and phrases; A special case of this problem is the very resolution of anaphora, which we discussed above.
2. The second class consists of tasks that generally require an understanding of the text, but in terms of form they are still well-defined tasks with correct answers (for example, classification problems), for which it is easy to come up with no doubt quality metrics. Such tasks include, but are not limited to:
(i) language models: for a given passage of text, predict the next word or symbol; this task is very important, for example, for speech recognition (see a little below);
(ii) information retrieval, the central task that Google and Yandex solve: by a given query and a huge number of documents, find among them the most relevant to this query;
(iii) sentiment analysis: to determine its tonality from the text, i.e. whether the text is positive or negative; tonality analysis is used in online trading to analyze user reviews, in finance and trading to analyze articles in the press, company reports, and similar texts, etc .;
(iv) extraction of relations or facts (relationship extraction, fact extraction): to extract from the text well-defined relations or facts about the entities mentioned there; for example, who is in family relationship with whom, in what year is the company mentioned in the text founded, etc.
(v) question answering questions: answer the question asked; depending on the setting, it can be either a pure classification (a choice from answer options, as in the test), or a classification with a very large number of classes (answers to factual questions like “who?” or “in which year?”), or even a result text (if you need to answer questions as part of a natural dialogue).
3. And finally, in the third class we assign tasks in which it is necessary not only to understand the already written text, but also to generate a new one. Here, quality metrics are no longer always obvious, and we will discuss this issue below. Such tasks include, for example:
(i) the actual generation of text (text generation);
(ii) automatic summarization: from the text to generate its summary, abstract, so to speak; this can be considered as a classification problem, if you ask the model to choose ready-made sentences from the text that best reflect the general meaning, or as a generation problem, if you need to write a brief summary from scratch;
(iii) machine translation: from a text in one language, generate the corresponding text in another language;
(iv) dialog and conversational models: maintain a conversation with a person; the first chat bots began to appear in the 1970s, and today it is a big industry; and although it is still not possible to conduct a full-fledged dialogue and pass the Turing test, the dialogue models are already working in full swing (for example, the first line of “online consultants” on different trading sites is almost always chat bots).
An important problem for the models of the last class is quality assessment. You can have a set of parallel translations that we think are good, but how do you evaluate the new translation made by the model? Or, even more interesting, how to evaluate the response of the dialogue model in a conversation? One possible answer to this question is BLEU (Bilingual Evaluation Understudy) [48], a class of metrics designed for machine translation but also used for other tasks. BLEU is a modification of the accuracy of the coincidence of the answer of the model and the “right answer”, re-weighted so as not to give an ideal rating to the answer from one correct word. For the entire test case, BLEU is considered as follows:
where r is the total length of the correct answer, c is the length of the model response, pn is the modified accuracy, and wn are the positive weights that add up to one. There are other similar metrics: METEOR [298] - harmonic mean of accuracy and completeness over unigrams, TER (translation edit rate) [513] calculates the relative number of corrections that need to be made to the model output to get a reference output, ROUGE [326] counts the fraction of the intersection of the sets of n-grams of words in the standard and in the resulting text, and LEPOR [204] completely combines several different metrics with different weights, which can also be trained (many authors of these articles are French, and the abbreviations are French-speaking).
However, it is curious that although metrics like BLEU and METEOR are still commonly used, it’s actually not at all a fact that this is the best choice. Firstly, BLEU has a discrete set of values, so that it cannot be directly optimized by gradient descent. But it is even more interesting that in [232] very surprising results of using various similar quality metrics in the context of evaluating model responses in a dialogue are presented. There, correlations (both ordinary and rank) of human assessments of the quality of answers and assessments by different metrics are calculated ... and it turns out that these correlations are almost always close to zero, and sometimes completely negative! The best version of BLEU was able to achieve a correlation with human ratings of about 0.35 on one dataset, and on the other a total of 0, 12 (try publishing the scientific result with such a correlation!). Moreover, such poor results do not mean that the correct answer does not exist at all: the ratings of different people always had correlation with each other at the level of 0.95 and higher, so that the “gold standard” of quality assessment certainly exists, but how to formalize it, we we don’t understand at all yet. This criticism has already led to new designs of automatically-trained quality metrics [537], and we hope that new results will appear in this direction. Nevertheless, while there are no easily applicable alternatives to metrics like BLEU, and they are usually used. so, the “gold standard” of quality assessment certainly exists, but we still do not understand how to formalize it. This criticism has already led to new designs of automatically-trained quality metrics [537], and we hope that new results will appear in this direction. Nevertheless, while there are no easily applicable alternatives to metrics like BLEU, and they are usually used. so, the “gold standard” of quality assessment certainly exists, but we still do not understand how to formalize it. This criticism has already led to new designs of automatically-trained quality metrics [537], and we hope that new results will appear in this direction. Nevertheless, while there are no easily applicable alternatives to metrics like BLEU, and they are usually used.
In addition, there is still a wide class of tasks related to text, but accepting not an sequence of characters as input, but an input of a different nature. For example, without understanding the language, it is almost impossible to learn how to perfectly recognize speech: although it seems that speech recognition is just a task of classifying phonemes by sound, in reality a person misses a lot of sounds and completes a significant part of what he hears based on his understanding of the language. Back in the 1990s, speech recognition systems reached a human level in recognizing individual phonemes: if you seat people to a tape recorder, let them listen to sounds without context and ask them to distinguish “a” from “o”, the results will not be outstanding; therefore, for example, to write down what is being dictated to you, you need to know the language in which it occurs.
We will return to many of these tasks in the future. However, the main content of this chapter is not to solve a specific problem of natural language processing, but to talk about the designs on which almost all modern neural network approaches to such problems are based - about distributed representations of words.
An excerpt from the book by Sergei Nikolenko, Arthur Kadurin and Ekaterina Arkhangelskaya “Deep Learning”