Memory Segmentation (Computer Memory Scheme)
- Transfer
I present to you a translation of an article by one of the PHP developers, including version 7 and higher, of a certified ZendFramework engineer. Currently working in SensioLabs and most of the work is in low-level things, including programming in C under Unix. The original article is here.
I plan to write technical articles on PHP related to a deep understanding of memory in the future. I need my readers to have knowledge that will help them understand some of the concepts of further explanation. In order to answer this question, we will have to rewind time back to the 1960s. I’m going to explain to you how a computer works, or rather, how memory is accessed in a modern computer, and then you will understand why this strange error message is happening - Segmentation Fault .
What you will read here is a summary of the basics of computer architecture design. I will not go too far if it is not necessary, and I will use well-known formulations, so whoever works with a computer every day can understand such important concepts about how a PC works. There are many books on computer architecture. If you want to delve further into this topic, I suggest you get some of them and start reading. Also, open the source code of the OS kernel and study it, whether it be the Linux kernel, or any other.
Even at the time when computers were huge machines, heavier than tons, inside you could find one processor with something like 16Kb of random access memory (RAM). Let's not go further =) During this period, the computer cost about $ 150,000 and could perform exactly one task at a time. If at that time we drew a diagram of his memory, then the architecture would look like this:

As you can see, the memory size is 16Kb, and consists of two parts:
The role of the operating system was to control interruptions of the central process by hardware. Thus, the operating system needed memory for itself in order to copy data from the device and work with it (PIO mode). To provide data on the screen, the main memory was also needed, since the video adapters had from zero to several kilobytes of memory. And our solo program used the memory of the OS to achieve the tasks.
But one of the main problems of this model is that a computer (costing $ 150,000) could perform only one task at a time, and this task took an awful long time: whole days to process several KB of data. At such a huge price, it is clearly not possible to buy several cars to perform several procedures at the same time. So people tried to allocate the resources of the machine. It was the time of the birth of multitasking. Keep in mind that it was still very early to talk about multiprocessor PCs. How can we force one machine with one processor, and actually solve several different problems? The answer to this question is planning. While one process is busy waiting for I / O (waiting for an interrupt), the processor can start another process. We will not talk about planning at all levels (too broad a topic), only about memory. If a machine can perform several tasks, one process after another, then this means that the memory will be allocated in approximately this way:
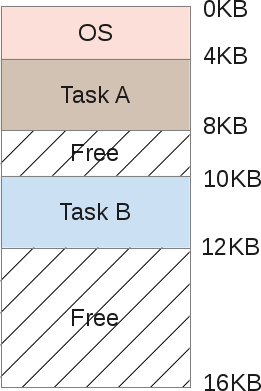
Both tasks A and B are stored in RAM, since copying them back and forth to disk is a too time-consuming process. Data should remain in RAM on an ongoing basis, as their respective tasks still work. The scheduler gives some processor time, then task A, then B, etc ... each time providing access to its memory area. But wait, there is a problem. When one programmer writes the code for task B, he must know the addresses of the memory boundaries. For example, task B will range from 10Kb of memory to 12Kb. Therefore, each address in the program must be rigidly written precisely in these limits. If the machine then performs 3 more tasks, the address space will be divided into more areas, and the memory boundaries of task B will move. The programmer would have to rewrite his program,
Another problem is obvious here: what if task B gets access to the memory of task A? This can easily happen because when you manipulate pointers, a small error in the calculation leads to a completely different address. This can spoil the data of task A (overwrite them). There is also a security issue, what if task A works with very sensitive data? There is no way to prevent task B from reading some memory area of task A. And lastly, what if task B overwrites the OS memory by mistake? For example, OS memory from 0Kb to 4Kb, if task B overwrites this area, the operating system will probably fail.
Thus, you need the help of the operating system and hardware in order to be able to run several tasks in memory. One way to help is to create what is called an address space. Address space is an abstraction of memory that the operating system will give the process, and this concept is absolutely fundamental, because nowadays every part of the computer that you meet in your life is designed in this way. Now there is no other model (in civil society, the army can keep a secret).
The address space contains all the tasks (processes) that must be run:
The address space is divided as follows:

Since the stack and heap are expandable zones, they are located in opposite places in the same address space: the stack will grow up, and the heap will go down. They can both grow freely, each in the direction of the other. The OS should simply check that the zones do not overlap, using virtual space correctly.
If task A received an address space, such as we saw, as well as task B. Then how can we place them in memory? It seems strange, but the address space of task A starts from 0KB to 16Kb, just like task B. The trick is to create a virtual environment. Actually the picture of placing A and B in memory:
When task A tries to access memory in its address space, such as the 11K index, somewhere on its own stack, the operating system will hack and actually load the memory index 1500, because the 11K index belongs to task B. Actually, the entire address space of each program in memory is just virtual memory. Each program running on a computer accesses virtual addresses; using some hardware chips, the OS will spoof a process when it tries to access any memory zone.
The OS virtualizes memory and ensures that any task cannot access memory that it does not own. Virtualization of memory isolates the process. Task A can no longer access the memory of task B and cannot access the OS memory. And all this is completely transparent for tasks at the user level, thanks to tons of complex OS kernel code. Thus, the operating system serves each request for process memory. This works very efficiently - even if too many different programs are running. To achieve this, the process receives help from the hardware, mainly from the processor and some of the electronic components around it, such as a memory management unit (MMU). MMU appeared in the early 70s, along with IBM, as separate chips. Now they are built directly into our CPU chips and are required for any modern OS to run. In fact, the operating system does not perform tons of operations, but relies on some hardware behavior features that will facilitate access to memory.
Here is a small C program showing some memory addresses:
On my LP64 x86_64 machine, it shows:
We can see that the stack address is much higher than the heap address, and the code is located below the stack. But each of these 3 addresses are fakes: in physical memory, at the address 0x7ffe60a1465c, the integer 3 is not exactly located. Remember that each user program manipulates virtual memory addresses, while kernel-level programs, such as the kernel of the OS itself ( or driver hardware code) can manipulate physical RAM addresses.
Address translation is a wording behind which a certain magical technique is hidden. Hardware (MMU) translates each virtual address of a user-level program into the correct physical address. Thus, the operating system remembers for each task the correspondence between its virtual addresses and physical ones. And that is a challenge. The operating system manages the entire memory of tasks at the user level for each memory access requirement, thereby providing a complete illusion of the process. Thus, the operating system converts all physical memory into a useful, powerful, and simple abstraction.
Let's take a closer look at a simple scenario:
When the process starts, the operating system reserves a fixed area of physical memory, say, 16KB. It then stores the starting address of this space in a special variable called the base. Then it sets another special variable, called the boundaries (or limit) of the space width - 16KB. The operating system will then store these two values in a process table called a PCB (Process Control Block).
And here is the virtual address space process:
And here is its physical image:

The OS decided to store it in physical memory in the address range from 4K to 20K. Thus, the base address is set to 4K, and the limit is set to 4 + 16 = 20K. When this process is planned (taking into account the processor time), the operating system reads back the limit values from the PCB and copies them to specific processor registers. When the CPU during operation tries to load, for example, a 2K virtual address (something in its heap), the CPU will add this base address received from the operating system. Thus, the memory access process will result in a physical location of 2K + 4K = 6K.
Physical address = virtual address + limit
If the received physical address (6K) is out of bounds (-4K | 20K-), this means that the process tried to access the wrong part of the memory that it does not own. The processor will throw an exception, and since the OS has an exception handler for this event, the OS is activated by the processor and will know that a memory exception has just occurred on the CPU. Then, by default, the OS will send a signal to the damaged SIGSEGV process. A segmentation error, which by default (this can be changed) will complete the task with the message “There was a failure in working with invalid memory access”.
Even better, if task A is not planned, this means that it is retrieved from the CPU, as the scheduler asked to start another task (say, task B). When performing task B, the OS can freely move the entire physical address space of task A. The operating system often receives processor time when performing user tasks. When the last system call ends, the CPU control returns to the OS, and before the system call is completed, the OS can do whatever it wants, managing the memory, moving the entire process space to various physical memory card slots.
This is relatively simple: the operating system moves the 16K region to another 16K of free space, and simply updates the base and related variables of task A. When the task is resumed and transferred to the CPU, the address translation process will still work, but it won’t same physical address as before.
Task A did not notice anything, from her point of view, her address space still starts from 0K to 16K. The operating system and hardware of the MMU take complete control of each memory access for task A, giving it a complete illusion. The task programmer A manipulates his allowed virtual addresses, from 0 to 16, and the MMU will take care of positioning in physical memory.
The memory image after moving will look like this:

Currently, a programmer no longer has to wonder where his program resides in RAM, if another task works next to his own, and what addresses to manipulate. This is done by the OS itself, together with a very productive and smart hardware - “Memory Management Unit” (MMU).
Pay attention to the appearance of the word “segmentation” - we are close to explaining why segmentation errors occur. In the previous chapter, we explained about translation and moving memory, but the model we used has its drawbacks:
We hypothesized that each virtual address space is fixed at 16Kb wide. Obviously, this is not so in reality. The operating system must maintain a list of physical memory of free slots (16 Kb wide) in order to be able to find a place for any new process with a request to start or move a running process. How to do it effectively so as not to slow down the whole system? As you can see, each process takes up 16 Kb of memory, even if the process does not use all of its address space, which is very likely. This model clearly consumes a lot of memory, the process consumes 1KB of memory, and its piece of memory in the physical memory is 16KB. Such waste is called internal fragmentation: memory is reserved but never used.
To solve some of these problems, we are going to dive into a more complex organization of memory in the OS - segmentation. Segmentation is easy to understand: we are expanding the idea of “base and boundaries” of three logical memory segments: heap, code, and stack; of each process - instead of simply considering the image of memory as one unique object.
With this concept, the memory between the stack and the heap is no longer wasted. Like this:

Now it’s easy to notice that the free space in virtual memory for tasks A is no longer allocated in physical memory, the use of memory becomes much more efficient. The only difference is that currently for any task, the OS must remember not one pair of bases / borders, but three: one pair for each type of segment. MMU takes care of the translation, as it did before, and now supports 3 basic units, and 3 borders.
For example, here, a bunch of task A has a 126K base and 2K boundaries. Then the task asks for access to the virtual address 3KB, on the heap; 3Kb physical address - 2Kb (heap start) = 1Kb + 126K (offset) = 127K. 127K is in front of 128K - this is the correct memory address that can be executed.
Segmenting physical memory not only solves the problem of free virtual memory by freeing up more physical memory, but it also allows you to separate physical segments using various virtual address space processes. If you run the same task twice, task A, for example, the code segment is exactly the same: both tasks perform the same processor commands. Both tasks will use their own stack and heap, access their own data sets. Ineffectively duplicate a code segment in memory. The OS can now split it and save even more memory. For example, like this:

In the picture above, A and B have their own code area in their corresponding virtual memory space, but under the hood. The operating system shares this area in the same physical memory segments. Both tasks A and B absolutely do not see this, for both of them - they own their memory. To achieve this goal, the OS must implement another feature: the segment protection bit. The OS will create, register boundaries / limits for each physical segment for the correct operation of the MMU, but it will also register a permission flag.
Because the code is not mutable, code segments are all created with the RX enable flag. A process may load this memory area for execution, but any process that attempts to write to this memory area will be terminated by the OS. The other two segments: heap and stack are RW, processes can read and write from their own stack / heap, but they cannot execute code from it (this prevents program security flaws where a bad user may want to damage the heap or stack to enter code to run, which will be available to the OS kernel. This is not possible, since the heap and stack of segments are often not executable. Please note that this was not always because it requires additional hardware support for efficient operation, this o called "NX bit" under the Intel processor). Permission memory segments are mutable at runtime: the task may require mprotect () from the OS. These memory segments are clearly visible under Linux, use the / proc / {pid} / maps or / usr / bin / pmap utilities
The following is an example for PHP:
Here we see in detail all the memory mappings. Addresses are virtual and display their resolution of the memory area. As we can see, each shared object (.so) is mapped to the address space as several mappings (probably code and data), and the code areas are executable, and under the hood they are divided in physical memory between each process that maps such a shared object to it own address space ...
The biggest advantage of shared objects under Linux (and Unix) is the saving of memory. It is also possible to create a common zone leading to a common physical memory segment using the mmap () system call. The letter 's' appearing next to this area means “shared”.
We have seen that segmentation solves the problem of unused virtual memory. When a process does not use a certain amount of memory, this process is not mapped to physical memory due to segments that correspond to the selected memory. However, this is not entirely true. What if the process requires 16Kb heap? The OS is likely to create a 16KB physical memory segment. But if the user then frees up 2KB of such memory? Then, the OS should reduce the 16Kb segment to 14kb. What if now a programmer asks for a 30Kb heap? The old 14Kb segment should now grow to 30 KB, but can it do that? Other segments can now surround our 14kb segment, inhibiting its growth. Then the OS will have to look for 30 KB free space, and then move the segment.
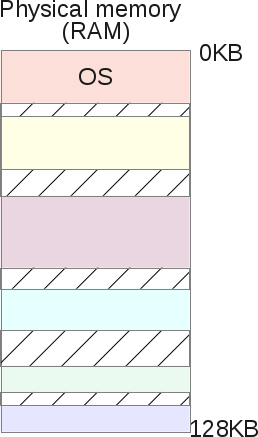
The big problem with segments is that they lead to very fragmented physical memory because they continue to grow as user tasks request and free up memory. The operating system must maintain a list of free pieces of memory and manage them.
Sometimes, by summing up all free segments, the OS gets some available space, but since it does not touch, it cannot use this space and must refuse the memory requirement of the processes, even if there is space in the physical memory. This is a very bad scenario. The operating system may try to compress the memory by merging all the free areas into one large piece, which could be used in the future to satisfy the memory request.
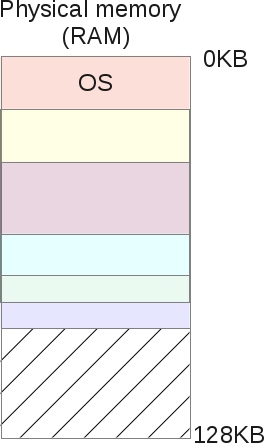
But such a compression algorithm is complicated for the CPU, and at this time no user process can get the CPU: the operating system is completely loaded with the reorganization of its physical memory, so the system becomes unusable. Memory segmentation solves many memory management and multitasking problems, but it also shows real flaws. Thus, there is a need to expand segmentation capabilities and correct these shortcomings. From here another concept was formed - “memory pagination”.
Pagination of memory pages shares some of the concepts of memory segmentation and tries to solve its problems. We saw that the main problem with memory segmentation is that segments will increase and decrease very often, as the user process requests and frees memory. Sometimes the operating system runs into a problem. It cannot find a large area of free space to satisfy the memory request of the user process because physical memory has become very fragmented over time: it contains many segments of different sizes throughout physical memory, which leads to highly fragmented physical memory.
The breakdown solves this problem with a simple concept: what if a fixed size is allocated for each physical distribution? Pages are segments of physical memory of a fixed size. If the operating system uses fixed-size distributions, it is much easier to manage the space, which ultimately negates memory fragmentation.
Let's show an example again, assuming a small 16KB virtual address space to make the presentation easier:
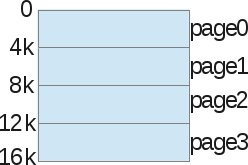
With pagination, we are not talking about a heap, stack, or code segment. We will divide the entire virtual memory process into zones of fixed size: we call them pages. In the above example, we divided the address space in the form of 4 pages, 4KB each.
Then we do the same with physical memory.
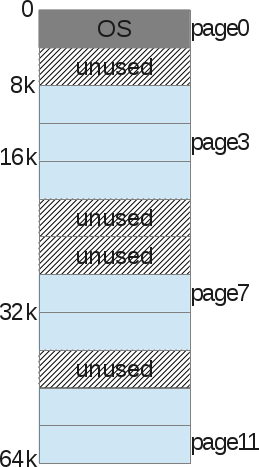
And the operating system simply stores what is called the “Processor Page Table” —the relationship between one page of the process’s virtual memory and the underlying physical page (which we call the “frame page”).

With this memory management method, there is no longer any problem with free space management. The page frame is displayed (used) or not, it is easy for the kernel to find enough pages to satisfy the memory request of the user process. It simply stores a list of free frame pages, and also scans it with every memory request. A page is the smallest unit of memory that the OS can control. A page (at our level) is indivisible. Together with the pages, each process is accompanied by a page table that stores address translations. Translations no longer use border values, as was the case with segmentation, but use the “virtual page number (VPN)” and “offset” on this page.
Let's show an example of address translation with pagination. 16Kb virtual address space, i.e. we need 14 bits to represent the address (2 ^ 14 = 16Kb). The page size is 4 Kb, so we need 4kb (16/4) to select our page:

Now when the process wants to load, for example, the address 9438 (out of 16384 possibilities), this gives 10.0100.1101.1110 in the binary system, which leads to to the following:

That is, the 1246th byte of the virtual page 2 ("0100.1101.1110" byte in the "10" page). Now, the operating system should look for this page of the process table to find out which page is the 2nd map. According to what we suggested, page 2 is 8K bytes in physical memory. Thus, virtual address 9438 leads to physical address 9442 (8k + 1246 offset). We found our data! As we already said, there is only one page table for each process, since each process will have its own address translations, just like with segments. But wait, where are these page tables actually stored? Guess ...: in physical memory, yes, but where else can she be? If the page tables themselves are stored in memory, therefore, for each memory access, the memory must have access to retrieve the VPN. Thus, with pages, one memory access is actually equal to two memory accesses: one to retrieve a page table entry, and one to access “real” data. Knowing that access to memory is a slow process, we get that this is not a good idea.
Using paging as a kernel mechanism to support virtual memory can lead to high overhead performance. Shredding the address space into small fixed-sized units (pages) requires a lot of information about the map. Because card information is usually stored in physical memory. Logical swap search requires an additional memory search for each virtual address generated by the program. And here again the hardware comes in to speed up and help the OS. In pagination, as in segmentation, hardware helps the OS kernel translate addresses in an efficient, acceptable way. TLB is part of the MMU, just a simple cache of some VPN transfers. The TLB will prevent the OS from accessing memory from accessing the process page table, to get the physical memory address from virtual. The MMU hardware will fire on each virtual memory access, retrieving the VPN from this address, and searching for the TLB if it matches for that particular VPN. If he coincided, then he simply fulfilled his role. If he gets a miss, he will look for a table of pages of the process, and if the memory link is valid, it will update the TLB, so that any further memory access of this page will fall into the TLB.
As with any cache, you will more often get there than get a miss, since a miss situation causes a search page, as a result, access to memory will be slow. You will guess about it. The more pages, the better the TLB hits, but the more unused space you will have on each page. A compromise must be found here. Modern kernels use different page sizes. The Linux kernel can use what is called “huge pages,” 2Mb pages larger than traditional 4Kb. In addition, information is best stored in adjacent memory addresses. If you shorten your data in memory, you will most likely suffer from TLB gaps or TLB overflows. This is what TLB Spatial Locality Efficiency is called: The data right next to you,
To switch contexts, the TLB also stores what is called an ASID in each of its entries. This is an address space identifier that is something like a PID. Each scheduled process has its own ASID, therefore TLB can manage any process address without risk of invalid addresses from other processes. Also, if the user process tries to load the wrong address, the address will most likely not be saved in the TLB, therefore, a miss will occur in the search for the process page table entry. Now the address is saved, but with the wrong bit. Under X86, each translation uses 4 bytes, so there are many bits. And often you can find a valid bit along with other components, such as a dirty bit, protection bits, a reference bit, etc. ... If an entry is marked as invalid, The OS uses SIGSEGV by default, which leads to a “segmentation error”, even if here we are no longer talking about segments. You should know that swapping is more complicated in modern OS than I explained. Modern operating systems, as a rule, use multi-level page tables, multi-page sizes, as well as an important concept that we will not explain. An eviction page known as “swaping” (A process where the kernel swaps memory pages for disk space in order to efficiently use main memory and create the illusion for user processes that main memory is unlimited in space). they use multi-level page tables, multi-page sizes, and also an important concept that we will not explain. An eviction page known as “swaping” (A process where the kernel swaps memory pages for disk space in order to efficiently use main memory and create the illusion for user processes that main memory is unlimited in space). they use multi-level page tables, multi-page sizes, and also an important concept that we will not explain. An eviction page known as “swaping” (A process where the kernel swaps memory pages for disk space in order to efficiently use main memory and create the illusion for user processes that main memory is unlimited in space).
Now you know what is under the “Segmentation Error” message. The operating system uses segments to display virtual memory in physical memory. When the kernel process wants to access some memory, it issues a requirement that the MMU translate to the physical memory address. But if this address is not correct, from the physical segment, or if the security rights of the segment are not suitable, then the OS sends a signal to the process that caused the failure by default: SIGSEGV, which has a default handler. It kills the process and displays the message: “Segmentation Error”. In other operating systems (I suppose) often the message looks like “General protection failure”. With Linux - we are lucky, we have the ability to access the source code, herethere is a source code space for the X86 / 64 platforms that manages memory access errors, as is SIGSEGV here. If you are interested in developing segments for X86 / 64 platforms, you can look at their definition in the Linux kernel. You will also find interesting paging memory material that supports a longer way of segmenting memory than using classic segments. I liked writing this article, it took me to the late nineties when I was programming my first CPU: Motorola 68HC11 using C, VHDL and direct mounting. I did not program virtual OS memory management, but used physical addresses directly (my processor does not need such complex mechanisms). Then I went to the Web; but my first knowledge came from electronics, the systems that we use every day ...
Segmentation Error: (Computer memory layout)
A few words about what this blog post is about.
I plan to write technical articles on PHP related to a deep understanding of memory in the future. I need my readers to have knowledge that will help them understand some of the concepts of further explanation. In order to answer this question, we will have to rewind time back to the 1960s. I’m going to explain to you how a computer works, or rather, how memory is accessed in a modern computer, and then you will understand why this strange error message is happening - Segmentation Fault .
What you will read here is a summary of the basics of computer architecture design. I will not go too far if it is not necessary, and I will use well-known formulations, so whoever works with a computer every day can understand such important concepts about how a PC works. There are many books on computer architecture. If you want to delve further into this topic, I suggest you get some of them and start reading. Also, open the source code of the OS kernel and study it, whether it be the Linux kernel, or any other.
A bit of computer science history
Even at the time when computers were huge machines, heavier than tons, inside you could find one processor with something like 16Kb of random access memory (RAM). Let's not go further =) During this period, the computer cost about $ 150,000 and could perform exactly one task at a time. If at that time we drew a diagram of his memory, then the architecture would look like this:
As you can see, the memory size is 16Kb, and consists of two parts:
- Operating system memory area (4kb)
- The memory area of running processes (12Kb)
The role of the operating system was to control interruptions of the central process by hardware. Thus, the operating system needed memory for itself in order to copy data from the device and work with it (PIO mode). To provide data on the screen, the main memory was also needed, since the video adapters had from zero to several kilobytes of memory. And our solo program used the memory of the OS to achieve the tasks.
<Computer sharing
But one of the main problems of this model is that a computer (costing $ 150,000) could perform only one task at a time, and this task took an awful long time: whole days to process several KB of data. At such a huge price, it is clearly not possible to buy several cars to perform several procedures at the same time. So people tried to allocate the resources of the machine. It was the time of the birth of multitasking. Keep in mind that it was still very early to talk about multiprocessor PCs. How can we force one machine with one processor, and actually solve several different problems? The answer to this question is planning. While one process is busy waiting for I / O (waiting for an interrupt), the processor can start another process. We will not talk about planning at all levels (too broad a topic), only about memory. If a machine can perform several tasks, one process after another, then this means that the memory will be allocated in approximately this way:
Both tasks A and B are stored in RAM, since copying them back and forth to disk is a too time-consuming process. Data should remain in RAM on an ongoing basis, as their respective tasks still work. The scheduler gives some processor time, then task A, then B, etc ... each time providing access to its memory area. But wait, there is a problem. When one programmer writes the code for task B, he must know the addresses of the memory boundaries. For example, task B will range from 10Kb of memory to 12Kb. Therefore, each address in the program must be rigidly written precisely in these limits. If the machine then performs 3 more tasks, the address space will be divided into more areas, and the memory boundaries of task B will move. The programmer would have to rewrite his program,
Another problem is obvious here: what if task B gets access to the memory of task A? This can easily happen because when you manipulate pointers, a small error in the calculation leads to a completely different address. This can spoil the data of task A (overwrite them). There is also a security issue, what if task A works with very sensitive data? There is no way to prevent task B from reading some memory area of task A. And lastly, what if task B overwrites the OS memory by mistake? For example, OS memory from 0Kb to 4Kb, if task B overwrites this area, the operating system will probably fail.
Address space
Thus, you need the help of the operating system and hardware in order to be able to run several tasks in memory. One way to help is to create what is called an address space. Address space is an abstraction of memory that the operating system will give the process, and this concept is absolutely fundamental, because nowadays every part of the computer that you meet in your life is designed in this way. Now there is no other model (in civil society, the army can keep a secret).
Each system is currently organized with a memory layout such as “code - stack - heap”, and this is frustrating.
The address space contains all the tasks (processes) that must be run:
- Code: These are machine instructions that the processor must process.
- Data: data of machine instructions that are processed with them.
The address space is divided as follows:
- The stack is a memory area where the program stores information about the called functions, their arguments and each local variable in the function.
- A heap is a memory area where a programmer is free to do anything.
- Code is the memory area where the instructions of the CPU of the compiled program will be stored. These instructions are generated by the compiler, but can be written manually. Please note that the code segment is usually divided into three parts (text, data and BSS), but we will not dive so deeply.
- The code is always fixed size created by the compiler and will weigh (in our example) 1Kb.
- The stack, however, is a variable zone since the program is running. When functions are called, the stack expands; when it returns from a function: the stack decreases.
- The heap is also a mutable zone, when the programmer allocates memory from the heap (malloc ()), it expands, and when the programmer frees memory back (free ()), the heap is narrowed.
Since the stack and heap are expandable zones, they are located in opposite places in the same address space: the stack will grow up, and the heap will go down. They can both grow freely, each in the direction of the other. The OS should simply check that the zones do not overlap, using virtual space correctly.
Memory virtualization
If task A received an address space, such as we saw, as well as task B. Then how can we place them in memory? It seems strange, but the address space of task A starts from 0KB to 16Kb, just like task B. The trick is to create a virtual environment. Actually the picture of placing A and B in memory:
When task A tries to access memory in its address space, such as the 11K index, somewhere on its own stack, the operating system will hack and actually load the memory index 1500, because the 11K index belongs to task B. Actually, the entire address space of each program in memory is just virtual memory. Each program running on a computer accesses virtual addresses; using some hardware chips, the OS will spoof a process when it tries to access any memory zone.
The OS virtualizes memory and ensures that any task cannot access memory that it does not own. Virtualization of memory isolates the process. Task A can no longer access the memory of task B and cannot access the OS memory. And all this is completely transparent for tasks at the user level, thanks to tons of complex OS kernel code. Thus, the operating system serves each request for process memory. This works very efficiently - even if too many different programs are running. To achieve this, the process receives help from the hardware, mainly from the processor and some of the electronic components around it, such as a memory management unit (MMU). MMU appeared in the early 70s, along with IBM, as separate chips. Now they are built directly into our CPU chips and are required for any modern OS to run. In fact, the operating system does not perform tons of operations, but relies on some hardware behavior features that will facilitate access to memory.
Here is a small C program showing some memory addresses:
#include
#include
int main (int argc, символ ** argv)
{
int v = 3;
printf("Code is at %p \n", (void *)main);
printf("Stack is at %p \n", (void *)&v);
printf("Heap is at %p \n", malloc(8));
return 0;
}
On my LP64 x86_64 machine, it shows:
Code is at 0x40054c
Stack is at 0x7ffe60a1465c
Heap is at 0x1ecf010We can see that the stack address is much higher than the heap address, and the code is located below the stack. But each of these 3 addresses are fakes: in physical memory, at the address 0x7ffe60a1465c, the integer 3 is not exactly located. Remember that each user program manipulates virtual memory addresses, while kernel-level programs, such as the kernel of the OS itself ( or driver hardware code) can manipulate physical RAM addresses.
Address translation
Address translation is a wording behind which a certain magical technique is hidden. Hardware (MMU) translates each virtual address of a user-level program into the correct physical address. Thus, the operating system remembers for each task the correspondence between its virtual addresses and physical ones. And that is a challenge. The operating system manages the entire memory of tasks at the user level for each memory access requirement, thereby providing a complete illusion of the process. Thus, the operating system converts all physical memory into a useful, powerful, and simple abstraction.
Let's take a closer look at a simple scenario:
When the process starts, the operating system reserves a fixed area of physical memory, say, 16KB. It then stores the starting address of this space in a special variable called the base. Then it sets another special variable, called the boundaries (or limit) of the space width - 16KB. The operating system will then store these two values in a process table called a PCB (Process Control Block).
And here is the virtual address space process:
And here is its physical image:
The OS decided to store it in physical memory in the address range from 4K to 20K. Thus, the base address is set to 4K, and the limit is set to 4 + 16 = 20K. When this process is planned (taking into account the processor time), the operating system reads back the limit values from the PCB and copies them to specific processor registers. When the CPU during operation tries to load, for example, a 2K virtual address (something in its heap), the CPU will add this base address received from the operating system. Thus, the memory access process will result in a physical location of 2K + 4K = 6K.
Physical address = virtual address + limit
If the received physical address (6K) is out of bounds (-4K | 20K-), this means that the process tried to access the wrong part of the memory that it does not own. The processor will throw an exception, and since the OS has an exception handler for this event, the OS is activated by the processor and will know that a memory exception has just occurred on the CPU. Then, by default, the OS will send a signal to the damaged SIGSEGV process. A segmentation error, which by default (this can be changed) will complete the task with the message “There was a failure in working with invalid memory access”.
Memory moving
Even better, if task A is not planned, this means that it is retrieved from the CPU, as the scheduler asked to start another task (say, task B). When performing task B, the OS can freely move the entire physical address space of task A. The operating system often receives processor time when performing user tasks. When the last system call ends, the CPU control returns to the OS, and before the system call is completed, the OS can do whatever it wants, managing the memory, moving the entire process space to various physical memory card slots.
This is relatively simple: the operating system moves the 16K region to another 16K of free space, and simply updates the base and related variables of task A. When the task is resumed and transferred to the CPU, the address translation process will still work, but it won’t same physical address as before.
Task A did not notice anything, from her point of view, her address space still starts from 0K to 16K. The operating system and hardware of the MMU take complete control of each memory access for task A, giving it a complete illusion. The task programmer A manipulates his allowed virtual addresses, from 0 to 16, and the MMU will take care of positioning in physical memory.
The memory image after moving will look like this:
Currently, a programmer no longer has to wonder where his program resides in RAM, if another task works next to his own, and what addresses to manipulate. This is done by the OS itself, together with a very productive and smart hardware - “Memory Management Unit” (MMU).
Memory segmentation
Pay attention to the appearance of the word “segmentation” - we are close to explaining why segmentation errors occur. In the previous chapter, we explained about translation and moving memory, but the model we used has its drawbacks:
We hypothesized that each virtual address space is fixed at 16Kb wide. Obviously, this is not so in reality. The operating system must maintain a list of physical memory of free slots (16 Kb wide) in order to be able to find a place for any new process with a request to start or move a running process. How to do it effectively so as not to slow down the whole system? As you can see, each process takes up 16 Kb of memory, even if the process does not use all of its address space, which is very likely. This model clearly consumes a lot of memory, the process consumes 1KB of memory, and its piece of memory in the physical memory is 16KB. Such waste is called internal fragmentation: memory is reserved but never used.
To solve some of these problems, we are going to dive into a more complex organization of memory in the OS - segmentation. Segmentation is easy to understand: we are expanding the idea of “base and boundaries” of three logical memory segments: heap, code, and stack; of each process - instead of simply considering the image of memory as one unique object.
With this concept, the memory between the stack and the heap is no longer wasted. Like this:
Now it’s easy to notice that the free space in virtual memory for tasks A is no longer allocated in physical memory, the use of memory becomes much more efficient. The only difference is that currently for any task, the OS must remember not one pair of bases / borders, but three: one pair for each type of segment. MMU takes care of the translation, as it did before, and now supports 3 basic units, and 3 borders.
For example, here, a bunch of task A has a 126K base and 2K boundaries. Then the task asks for access to the virtual address 3KB, on the heap; 3Kb physical address - 2Kb (heap start) = 1Kb + 126K (offset) = 127K. 127K is in front of 128K - this is the correct memory address that can be executed.
Segment Sharing
Segmenting physical memory not only solves the problem of free virtual memory by freeing up more physical memory, but it also allows you to separate physical segments using various virtual address space processes. If you run the same task twice, task A, for example, the code segment is exactly the same: both tasks perform the same processor commands. Both tasks will use their own stack and heap, access their own data sets. Ineffectively duplicate a code segment in memory. The OS can now split it and save even more memory. For example, like this:
In the picture above, A and B have their own code area in their corresponding virtual memory space, but under the hood. The operating system shares this area in the same physical memory segments. Both tasks A and B absolutely do not see this, for both of them - they own their memory. To achieve this goal, the OS must implement another feature: the segment protection bit. The OS will create, register boundaries / limits for each physical segment for the correct operation of the MMU, but it will also register a permission flag.
Because the code is not mutable, code segments are all created with the RX enable flag. A process may load this memory area for execution, but any process that attempts to write to this memory area will be terminated by the OS. The other two segments: heap and stack are RW, processes can read and write from their own stack / heap, but they cannot execute code from it (this prevents program security flaws where a bad user may want to damage the heap or stack to enter code to run, which will be available to the OS kernel. This is not possible, since the heap and stack of segments are often not executable. Please note that this was not always because it requires additional hardware support for efficient operation, this o called "NX bit" under the Intel processor). Permission memory segments are mutable at runtime: the task may require mprotect () from the OS. These memory segments are clearly visible under Linux, use the / proc / {pid} / maps or / usr / bin / pmap utilities
The following is an example for PHP:
$ pmap -x 31329
0000000000400000 10300 2004 0 r-x-- php
000000000100e000 832 460 76 rw--- php
00000000010de000 148 72 72 rw--- [ anon ]
000000000197a000 2784 2696 2696 rw--- [ anon ]
00007ff772bc4000 12 12 0 r-x-- libuuid.so.0.0.0
00007ff772bc7000 1020 0 0 ----- libuuid.so.0.0.0
00007ff772cc6000 4 4 4 rw--- libuuid.so.0.0.0
... ...Here we see in detail all the memory mappings. Addresses are virtual and display their resolution of the memory area. As we can see, each shared object (.so) is mapped to the address space as several mappings (probably code and data), and the code areas are executable, and under the hood they are divided in physical memory between each process that maps such a shared object to it own address space ...
The biggest advantage of shared objects under Linux (and Unix) is the saving of memory. It is also possible to create a common zone leading to a common physical memory segment using the mmap () system call. The letter 's' appearing next to this area means “shared”.
Segmentation Limits
We have seen that segmentation solves the problem of unused virtual memory. When a process does not use a certain amount of memory, this process is not mapped to physical memory due to segments that correspond to the selected memory. However, this is not entirely true. What if the process requires 16Kb heap? The OS is likely to create a 16KB physical memory segment. But if the user then frees up 2KB of such memory? Then, the OS should reduce the 16Kb segment to 14kb. What if now a programmer asks for a 30Kb heap? The old 14Kb segment should now grow to 30 KB, but can it do that? Other segments can now surround our 14kb segment, inhibiting its growth. Then the OS will have to look for 30 KB free space, and then move the segment.
The big problem with segments is that they lead to very fragmented physical memory because they continue to grow as user tasks request and free up memory. The operating system must maintain a list of free pieces of memory and manage them.
Sometimes, by summing up all free segments, the OS gets some available space, but since it does not touch, it cannot use this space and must refuse the memory requirement of the processes, even if there is space in the physical memory. This is a very bad scenario. The operating system may try to compress the memory by merging all the free areas into one large piece, which could be used in the future to satisfy the memory request.
But such a compression algorithm is complicated for the CPU, and at this time no user process can get the CPU: the operating system is completely loaded with the reorganization of its physical memory, so the system becomes unusable. Memory segmentation solves many memory management and multitasking problems, but it also shows real flaws. Thus, there is a need to expand segmentation capabilities and correct these shortcomings. From here another concept was formed - “memory pagination”.
Memory pagination
Pagination of memory pages shares some of the concepts of memory segmentation and tries to solve its problems. We saw that the main problem with memory segmentation is that segments will increase and decrease very often, as the user process requests and frees memory. Sometimes the operating system runs into a problem. It cannot find a large area of free space to satisfy the memory request of the user process because physical memory has become very fragmented over time: it contains many segments of different sizes throughout physical memory, which leads to highly fragmented physical memory.
The breakdown solves this problem with a simple concept: what if a fixed size is allocated for each physical distribution? Pages are segments of physical memory of a fixed size. If the operating system uses fixed-size distributions, it is much easier to manage the space, which ultimately negates memory fragmentation.
Let's show an example again, assuming a small 16KB virtual address space to make the presentation easier:
With pagination, we are not talking about a heap, stack, or code segment. We will divide the entire virtual memory process into zones of fixed size: we call them pages. In the above example, we divided the address space in the form of 4 pages, 4KB each.
Then we do the same with physical memory.
And the operating system simply stores what is called the “Processor Page Table” —the relationship between one page of the process’s virtual memory and the underlying physical page (which we call the “frame page”).
With this memory management method, there is no longer any problem with free space management. The page frame is displayed (used) or not, it is easy for the kernel to find enough pages to satisfy the memory request of the user process. It simply stores a list of free frame pages, and also scans it with every memory request. A page is the smallest unit of memory that the OS can control. A page (at our level) is indivisible. Together with the pages, each process is accompanied by a page table that stores address translations. Translations no longer use border values, as was the case with segmentation, but use the “virtual page number (VPN)” and “offset” on this page.
Let's show an example of address translation with pagination. 16Kb virtual address space, i.e. we need 14 bits to represent the address (2 ^ 14 = 16Kb). The page size is 4 Kb, so we need 4kb (16/4) to select our page:
Now when the process wants to load, for example, the address 9438 (out of 16384 possibilities), this gives 10.0100.1101.1110 in the binary system, which leads to to the following:
That is, the 1246th byte of the virtual page 2 ("0100.1101.1110" byte in the "10" page). Now, the operating system should look for this page of the process table to find out which page is the 2nd map. According to what we suggested, page 2 is 8K bytes in physical memory. Thus, virtual address 9438 leads to physical address 9442 (8k + 1246 offset). We found our data! As we already said, there is only one page table for each process, since each process will have its own address translations, just like with segments. But wait, where are these page tables actually stored? Guess ...: in physical memory, yes, but where else can she be? If the page tables themselves are stored in memory, therefore, for each memory access, the memory must have access to retrieve the VPN. Thus, with pages, one memory access is actually equal to two memory accesses: one to retrieve a page table entry, and one to access “real” data. Knowing that access to memory is a slow process, we get that this is not a good idea.
Translation Associative Buffer: TLB
Using paging as a kernel mechanism to support virtual memory can lead to high overhead performance. Shredding the address space into small fixed-sized units (pages) requires a lot of information about the map. Because card information is usually stored in physical memory. Logical swap search requires an additional memory search for each virtual address generated by the program. And here again the hardware comes in to speed up and help the OS. In pagination, as in segmentation, hardware helps the OS kernel translate addresses in an efficient, acceptable way. TLB is part of the MMU, just a simple cache of some VPN transfers. The TLB will prevent the OS from accessing memory from accessing the process page table, to get the physical memory address from virtual. The MMU hardware will fire on each virtual memory access, retrieving the VPN from this address, and searching for the TLB if it matches for that particular VPN. If he coincided, then he simply fulfilled his role. If he gets a miss, he will look for a table of pages of the process, and if the memory link is valid, it will update the TLB, so that any further memory access of this page will fall into the TLB.
As with any cache, you will more often get there than get a miss, since a miss situation causes a search page, as a result, access to memory will be slow. You will guess about it. The more pages, the better the TLB hits, but the more unused space you will have on each page. A compromise must be found here. Modern kernels use different page sizes. The Linux kernel can use what is called “huge pages,” 2Mb pages larger than traditional 4Kb. In addition, information is best stored in adjacent memory addresses. If you shorten your data in memory, you will most likely suffer from TLB gaps or TLB overflows. This is what TLB Spatial Locality Efficiency is called: The data right next to you,
To switch contexts, the TLB also stores what is called an ASID in each of its entries. This is an address space identifier that is something like a PID. Each scheduled process has its own ASID, therefore TLB can manage any process address without risk of invalid addresses from other processes. Also, if the user process tries to load the wrong address, the address will most likely not be saved in the TLB, therefore, a miss will occur in the search for the process page table entry. Now the address is saved, but with the wrong bit. Under X86, each translation uses 4 bytes, so there are many bits. And often you can find a valid bit along with other components, such as a dirty bit, protection bits, a reference bit, etc. ... If an entry is marked as invalid, The OS uses SIGSEGV by default, which leads to a “segmentation error”, even if here we are no longer talking about segments. You should know that swapping is more complicated in modern OS than I explained. Modern operating systems, as a rule, use multi-level page tables, multi-page sizes, as well as an important concept that we will not explain. An eviction page known as “swaping” (A process where the kernel swaps memory pages for disk space in order to efficiently use main memory and create the illusion for user processes that main memory is unlimited in space). they use multi-level page tables, multi-page sizes, and also an important concept that we will not explain. An eviction page known as “swaping” (A process where the kernel swaps memory pages for disk space in order to efficiently use main memory and create the illusion for user processes that main memory is unlimited in space). they use multi-level page tables, multi-page sizes, and also an important concept that we will not explain. An eviction page known as “swaping” (A process where the kernel swaps memory pages for disk space in order to efficiently use main memory and create the illusion for user processes that main memory is unlimited in space).
Conclusion
Now you know what is under the “Segmentation Error” message. The operating system uses segments to display virtual memory in physical memory. When the kernel process wants to access some memory, it issues a requirement that the MMU translate to the physical memory address. But if this address is not correct, from the physical segment, or if the security rights of the segment are not suitable, then the OS sends a signal to the process that caused the failure by default: SIGSEGV, which has a default handler. It kills the process and displays the message: “Segmentation Error”. In other operating systems (I suppose) often the message looks like “General protection failure”. With Linux - we are lucky, we have the ability to access the source code, herethere is a source code space for the X86 / 64 platforms that manages memory access errors, as is SIGSEGV here. If you are interested in developing segments for X86 / 64 platforms, you can look at their definition in the Linux kernel. You will also find interesting paging memory material that supports a longer way of segmenting memory than using classic segments. I liked writing this article, it took me to the late nineties when I was programming my first CPU: Motorola 68HC11 using C, VHDL and direct mounting. I did not program virtual OS memory management, but used physical addresses directly (my processor does not need such complex mechanisms). Then I went to the Web; but my first knowledge came from electronics, the systems that we use every day ...