Naive Spellchecking, or search for the closest words from a dictionary by the Levenshtein metric on Scala
- Tutorial
Greetings! This article will show an algorithm for finding the words closest to a given word from the corpus in terms of the Levenshtein metric. It is called naive spellchecking because it does not take into account either morphology, context, or the likelihood of a corrected word appearing in a sentence, however, it will come down completely as a first approximation. Also, the algorithm can be expanded to search for the nearest sequences from any other comparable objects than the simple alphabet from Char-s, and, after finishing with a file, it can also be adapted to take into account the probability of occurrence of corrected words. But in this article we will focus on the basic algorithm for words of a certain alphabet, say, English.
The code in the article will be on Scala.
I ask everyone interested under cat.
Вообще говоря, для поиска в метрическом пространстве существуют специализированные структуры данных, такие как VP-Tree (Vantage Point Tree). Однако эксперименты показывают, что для пространства слов с метрикой Левенштейна VP-дерево работает крайне плохо. Причина банальна — данное метрическое пространство очень плотное. У слова из, скажем, 4х букв, имеется огромное множество соседей на расстоянии 1. На больших расстояниях количество вариантов становится сопоставимо с размером всего множества, что делает поиск в VP-дереве ничуть не более производительным, чем линейный поиск по множеству. К счастью, для строк существует более оптимальное решение, и сейчас мы его разберем.
Для компактного хранения множества слов с общим префиксом используем такую структуру данных, как бор (trie).
In a nutshell, the algorithm is described as a simple search by the Dijkstra algorithm on the implicit graph of options for the prefix match of the searched word and the words in the bore (trie). The nodes of the graph in a fuzzy search will be the above options, and the weights of the edges will be the actual Levenshtein distance of the specified string prefix and boron node.
To begin with, we describe the boron node, write an algorithm for inserting and clearly searching for a word in the boron. We will leave a fuzzy search for a snack.
As you can see, nothing supernatural. A boron node is an object with a reference to the parent, the Mapth reference to the descendants, the literal value of the node, and the flag whether the node is the final node for any string.
Now we describe a clear search in the bore:
Nothing complicated. We go down the children of the knot until we meet a coincidence (t.ends) or see that there is nowhere else to go down.
Now insert:
Our boron is immutable, so the + function returns a new boron to us.
Building a boron from a corpus of words looks something like this:
The base build is ready.
Let's describe the graph node:
Pos - the position at which the prefix of the desired line ends in the considered option. Node - boron prefix in the considered option. Penalty - Levenshtein distance of line prefix and boron prefix.
The curried case-class means that the equals / hashCode functions will be generated by the compiler only for the first argument-list. Penalty versus Variants are not taken into account .
The enumeration of graph nodes with non-decreasing penalty is controlled by a function with this signature:
To implement it, we will write a small helper that generates Stream with a function-generator:
Now we implement the immutable context of the search, which we will pass to the function above, and which contains everything that is needed to iterate over the nodes of the implicit graph by the Dijkstra algorithm: a priority queue and many visited nodes:
The node queue is made from simple immutable TreeMaps. The nodes in the queue are sorted by increasing penalty and decreasing prefix pos.
And finally, the stream generator itself:
Of course, genvars deserves the greatest attention here . For a given node of the graph, it generates edges emanating from it. For each descendant of the boron node of this search option, we generate a variant with the insertion of a symbol
and replacing the character
If you haven’t reached the end of the line, then we’ll also generate an option to delete the character
Of course, the prefixes function for general use is of little use. We’ll write wrappers that allow us to look more or less meaningfully. To begin with, we limit the enumeration of variants to some reasonable value of penalty to prevent the algorithm from getting stuck on some word for which there is no more or less adequate replacement in the dictionary
Next, we filter out the options with a complete, not prefix, match, that is, those with pos equal to the length of the string to search for, and node points to the final node with the ends == true flag:
And finally , we’ll convert the stream of options into a stream of words, for this in the Trie class we will write a code that returns the found word:
Nothing complicated. We go up by parents, writing down the values of the nodes until we meet the root of the boron.
And finally:
I must say that the matches function is very universal. Using it, you can search for K nearest, doing just
or search for Delta-nearest, that is, lines at a distance of no more than D:
Another algorithm can be expanded by introducing different weights for inserting / deleting / replacing characters. You can add specific replace / delete / insert counters to the Variant class. Trie can be generalized so that it is possible to store values in the end nodes and use not only strings as keys, but also indexed sequences of any comparable types of keys. You can also mark each boron node with the probability of meeting it (for the final node it is the probability of meeting a word + the probability of meeting all descendant words, for the intermediate node it is only the sum of the probabilities of the descendants) and consider this weight when calculating penalty, but this is already beyond the scope of this article .
I hope it was interesting. Code here
The code in the article will be on Scala.
I ask everyone interested under cat.
Intro
Вообще говоря, для поиска в метрическом пространстве существуют специализированные структуры данных, такие как VP-Tree (Vantage Point Tree). Однако эксперименты показывают, что для пространства слов с метрикой Левенштейна VP-дерево работает крайне плохо. Причина банальна — данное метрическое пространство очень плотное. У слова из, скажем, 4х букв, имеется огромное множество соседей на расстоянии 1. На больших расстояниях количество вариантов становится сопоставимо с размером всего множества, что делает поиск в VP-дереве ничуть не более производительным, чем линейный поиск по множеству. К счастью, для строк существует более оптимальное решение, и сейчас мы его разберем.
Описание
Для компактного хранения множества слов с общим префиксом используем такую структуру данных, как бор (trie).
Картинка бора из Википедии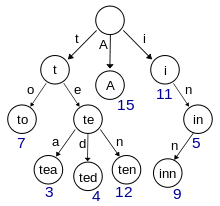
In a nutshell, the algorithm is described as a simple search by the Dijkstra algorithm on the implicit graph of options for the prefix match of the searched word and the words in the bore (trie). The nodes of the graph in a fuzzy search will be the above options, and the weights of the edges will be the actual Levenshtein distance of the specified string prefix and boron node.
Basic implementation of boron
To begin with, we describe the boron node, write an algorithm for inserting and clearly searching for a word in the boron. We will leave a fuzzy search for a snack.
class Trie(
val ends: Boolean = false, // whether this node is end of some string
private val parent: Trie = null,
private val childs : TreeMap[Char, Trie] = null,
val value : Char = 0x0)
As you can see, nothing supernatural. A boron node is an object with a reference to the parent, the Mapth reference to the descendants, the literal value of the node, and the flag whether the node is the final node for any string.
Now we describe a clear search in the bore:
/// exact search
def contains(s: String) = {
@tailrec def impl(t: Trie, pos: Int): Boolean =
if (s.size < pos) false
else if (s.size == pos) t.ends
else if (t.childs == null) false
else if (t.childs.contains(s(pos)) == false) false
else impl(t.childs(s(pos)), pos + 1)
impl(this, 0)
}
Nothing complicated. We go down the children of the knot until we meet a coincidence (t.ends) or see that there is nowhere else to go down.
Now insert:
/// insertion
def +(s: String) = {
def insert(trie: Trie, pos: Int = 0) : Trie =
if (s.size < pos) trie
else if (pos == 0 && trie.contains(s)) trie
else if (s.size == pos)
if (trie.ends) trie
else new Trie(true, trie.parent, trie.childs, trie.value)
else {
val c = s(pos)
val children = Option(trie.childs).getOrElse(TreeMap.empty[Char, Trie])
val child = children.getOrElse(
c, new Trie(s.size == pos + 1, trie, null, c))
new Trie(
trie.ends,
trie.parent,
children + (c, insert(child, pos + 1)),
trie.value)
}
insert(this, 0)
}
Our boron is immutable, so the + function returns a new boron to us.
Building a boron from a corpus of words looks something like this:
object Trie {
def apply(seq: Iterator[String]) : Trie =
seq.filter(_.nonEmpty).foldLeft(new Trie)(_ + _)
def apply(seq: Seq[String]) : Trie = apply(seq.iterator)
}
The base build is ready.
Fuzzy search, basic function
Let's describe the graph node:
case class Variant(val pos: Int, val node: Trie)(val penalty: Int)
Pos - the position at which the prefix of the desired line ends in the considered option. Node - boron prefix in the considered option. Penalty - Levenshtein distance of line prefix and boron prefix.
The curried case-class means that the equals / hashCode functions will be generated by the compiler only for the first argument-list. Penalty versus Variants are not taken into account .
The enumeration of graph nodes with non-decreasing penalty is controlled by a function with this signature:
def prefixes(toFind: String): Stream[Variant]
To implement it, we will write a small helper that generates Stream with a function-generator:
def streamGen[Ctx, A]
(init: Ctx)(gen: Ctx => Option[(A, Ctx)]): Stream[A] =
{
val op = gen(init)
if (op.isEmpty) Stream.Empty
else op.get._1 #:: streamGen(op.get._2)(gen)
}
Now we implement the immutable context of the search, which we will pass to the function above, and which contains everything that is needed to iterate over the nodes of the implicit graph by the Dijkstra algorithm: a priority queue and many visited nodes:
private class Context(
// immutable priority queue, Map of (penalty-, prefix pos+) -> List[Variant]
val q: TreeMap[(Int, Int), List[Variant]],
// immutable visited nodes cache
val cache: HashSet[Variant])
{
// extract from 'q' value with lowest penalty and greatest prefix position
def pop: (Option[Variant], Context) = {
if (q.isEmpty) (None, this)
else {
val (key, list) = q.head
if (list.tail.nonEmpty)
(Some(list.head), new Context(q - key + (key, list.tail), cache))
else
(Some(list.head), new Context(q - key, cache))
}
}
// enqueue nodes
def ++(vars: Seq[Variant]) = {
val newq = vars.filterNot(cache.contains).foldLeft(q) { (q, v) =>
val key = (v.penalty, v.pos)
if (q.contains(key)) { val l = q(key); q - key + (key, v :: l) }
else q + (key, v :: Nil)
}
new Context(newq, cache)
}
// searches node in cache
def apply(v: Variant) = cache(v)
// adds node to cache; it marks it as visited
def addCache(v: Variant) = new Context(q, cache + v)
}
private object Context {
def apply(init: Variant) = {
// ordering of prefix queue: min by penalty, max by prefix pos
val ordering = new Ordering[(Int, Int)] {
def compare(v1: (Int, Int), v2: (Int, Int)) =
if (v1._1 == v2._1) v2._2 - v1._2 else v1._1 - v2._1
}
new Context(
TreeMap(((init.penalty, init.pos), init :: Nil))(ordering),
HashSet.empty[Variant])
}
}
The node queue is made from simple immutable TreeMaps. The nodes in the queue are sorted by increasing penalty and decreasing prefix pos.
And finally, the stream generator itself:
// impresize search lookup, returns stream of prefix match variants with lowest penalty
def prefixes(toFind: String) : Stream[Variant] = {
val init = Variant(0, this)(0)
// returns first unvisited node
@tailrec def whileCached(ctx: Context): (Option[Variant], Context) =
{
val (v, ctx2) = ctx.pop
if (v.isEmpty) (v, ctx2)
else if (!ctx2(v.get)) (Some(v.get), ctx2)
else whileCached(ctx2)
}
// generates graph edges from current node
def genvars(v: Variant): List[Variant] = {
val replacePass: List[Variant] =
if (v.node.childs == null) Nil
else v.node.childs.toList flatMap { pair =>
val (key, child) = pair
val pass = Variant(v.pos, child)(v.penalty + 1) :: Nil
if (v.pos < toFind.length)
Variant(v.pos + 1, child)(v.penalty + {if (toFind(v.pos) == key) 0 else 1}) :: pass
else pass
}
if (v.pos != toFind.length) {
Variant(v.pos + 1, v.node)(v.penalty + 1) :: replacePass
} else replacePass
}
streamGen(Context(init)) { ctx =>
val (best, ctx2) = whileCached(ctx)
best.map { v =>
(v, (ctx2 ++ genvars(v)).addCache(v))
}
}
}
Of course, genvars deserves the greatest attention here . For a given node of the graph, it generates edges emanating from it. For each descendant of the boron node of this search option, we generate a variant with the insertion of a symbol
val pass = Variant(v.pos, child)(v.penalty + 1)and replacing the character
Variant(v.pos + 1, child)(v.penalty + {if (toFind(v.pos) == key) 0 else 1})If you haven’t reached the end of the line, then we’ll also generate an option to delete the character
Variant(v.pos + 1, v.node)(v.penalty + 1)Fuzzy search, usability
Of course, the prefixes function for general use is of little use. We’ll write wrappers that allow us to look more or less meaningfully. To begin with, we limit the enumeration of variants to some reasonable value of penalty to prevent the algorithm from getting stuck on some word for which there is no more or less adequate replacement in the dictionary
def limitedPrefixes(toFind: String, penaltyLimit: Int = 5): Stream[Variant] = {
prefixes(toFind).takeWhile(_.penalty < penaltyLimit)
}
Next, we filter out the options with a complete, not prefix, match, that is, those with pos equal to the length of the string to search for, and node points to the final node with the ends == true flag:
def matches(toFind: String, penaltyLimit: Int = 5): Stream[Variant] = {
limitedPrefixes(toFind, penaltyLimit).filter { v => v.node.ends && v.pos == toFind.size }
}
And finally , we’ll convert the stream of options into a stream of words, for this in the Trie class we will write a code that returns the found word:
def makeString() : String = {
@tailrec def helper(t: Trie, sb: StringBuilder): String =
if (t == null || t.parent == null) sb.result.reverse
else {
helper(t.parent, sb += t.value)
}
helper(this, new StringBuilder)
}
Nothing complicated. We go up by parents, writing down the values of the nodes until we meet the root of the boron.
And finally:
def matchValues(toFind: String, penaltyLimit: Int = 5): Stream[String] = {
matches(toFind, penaltyLimit).map(_.node.makeString)
}
Total
I must say that the matches function is very universal. Using it, you can search for K nearest, doing just
matches(toFind).take(k).map(_.node.makeString)or search for Delta-nearest, that is, lines at a distance of no more than D:
matches(toFind).takeWhile(_.penalty < d).map(_.node.makeString)Another algorithm can be expanded by introducing different weights for inserting / deleting / replacing characters. You can add specific replace / delete / insert counters to the Variant class. Trie can be generalized so that it is possible to store values in the end nodes and use not only strings as keys, but also indexed sequences of any comparable types of keys. You can also mark each boron node with the probability of meeting it (for the final node it is the probability of meeting a word + the probability of meeting all descendant words, for the intermediate node it is only the sum of the probabilities of the descendants) and consider this weight when calculating penalty, but this is already beyond the scope of this article .
I hope it was interesting. Code here