About fractals, martingales and random integrals. Part one
- Tutorial

In my opinion, stochastic calculus is one of those magnificent sections of higher mathematics (along with topology and complex analysis), where formulas meet with poetry; this is the place where they find beauty, the place where the scope for artistic creation begins. Many of those who read the article Wiener Chaos or Another way to flip a coin , even if they understood a little, still managed to appreciate the magnificence of this theory. Today we will continue our mathematical journey, we will plunge into the world of random processes, non-trivial integration, financial mathematics, and even a little touch on functional programming. I warn you, keep your gyrus ready, as we have a serious conversation.

By the way, if you are interested in reading in a separate article, then suddenly it turned out that

The hidden threat of fractals
Imagine some simple function
 at some interval
at some interval ![$ [t, t + \ Delta t] $](https://habrastorage.org/getpro/habr/formulas/0e6/b9b/52b/0e6b9b52b1c0506d5504263c8f6f4d28.svg) . Presented? In standard mathematical analysis, we are used to the fact that if the size of this interval is reduced for a sufficiently long time, then the function given to us starts to behave quite smoothly, and we can approximate it by a straight line, in extreme cases, a parabola. All thanks to the function decomposition theorem formulated by the English scientist Brooke Taylor in 1715:
. Presented? In standard mathematical analysis, we are used to the fact that if the size of this interval is reduced for a sufficiently long time, then the function given to us starts to behave quite smoothly, and we can approximate it by a straight line, in extreme cases, a parabola. All thanks to the function decomposition theorem formulated by the English scientist Brooke Taylor in 1715:
By the time Benoit Mandelbrot came up with the very concept of “fractals”, they had not let many world scientists sleep for a hundred years. One of the first to whom fractals tarnished the reputation was Andre-Marie Ampère. In 1806, the scientist put forward a rather convincing "proof" that any function can be divided into intervals of continuous functions, and those, in turn, due to continuity, must have a derivative. And many of his contemporaries mathematicians agreed with him. In general, Ampère cannot be blamed for this seemingly rather crude mistake. The mathematicians of the beginning of the 19th century had a rather vague definition of such now basic concepts of mathematical analysis as continuity and differentiability, and, as a result, could be very mistaken in their proofs. Not even an exception were such eminent scientists as Gauss, Fourier, Cauchy, Legendre, Galois,
Nevertheless, in 1872, Karl Weierstrass refuted the hypothesis of the existence of derivatives of continuous functions by presenting the world's first fractal monster, which is continuous everywhere and nowhere differentiable.
Here, for example, how a similar function is set:

The Brownian movement also possesses the same property (by the way, for some reason, it’s not Br but Unovsky, the surname is British, nevertheless). Brownian motion is a continuous random process
 such that all its increments are independent and have a normal distribution:
such that all its increments are independent and have a normal distribution: 
Endless variation of Brownian motion
Let's imagine a function again
on the interval ![$ t \ in [0, T] $](https://habrastorage.org/getpro/habr/formulas/2a4/936/236/2a493623631f7bc34d584c8b288e8e89.svg) and divide this interval into many of
and divide this interval into many of  disjoint subintervals:
disjoint subintervals: 
 , dividing this interval, the size of the maximum step is much more interesting:
, dividing this interval, the size of the maximum step is much more interesting:  We will call the quantity
We will call the quantity ![$ V _ {[0, T]} ^ f = \ lim _ {\ | \ Pi \ | \ rightarrow 0} \ sum_ {i = 1} ^ n | f (t_ {i}) - f (t_ {i-1}) | $](https://habrastorage.org/getpro/habr/formulas/c6f/ca1/723/c6fca17239230f203c6171cd2a02105d.svg)
(also called common variation). If![$ V _ {[0, T]} ^ f <\ infty $](https://habrastorage.org/getpro/habr/formulas/d21/987/c12/d21987c1240be4d61beb6154cb111eeb.svg) then we will say that has a finite variation. For example, a variation of a sufficiently “smooth” function
then we will say that has a finite variation. For example, a variation of a sufficiently “smooth” function
will be the ultimate. In which case are we not so sure? Well, for example, the function will not have final variation

 for all rational
for all rational  and
and  for all irrational. Similar logic can be extended to random functions. Let it
for all irrational. Similar logic can be extended to random functions. Let it Is a random process. Variation for it is set in the same way:
Is a random process. Variation for it is set in the same way:![$ V _ {[0, T]} ^ X (\ omega) = \ lim _ {\ | \ Pi \ | \ rightarrow 0} \ sum_ {i = 1} ^ n | X (t_ {i}) - X (t_ {i-1}) | (\ omega). $](https://habrastorage.org/getpro/habr/formulas/5b1/c6c/5d2/5b1c6c5d23280a288d5491d4e2a2f6a6.svg)
 can be omitted for convenience, but he is here hinting that the variation from a random process is a mapping from the space of random events
can be omitted for convenience, but he is here hinting that the variation from a random process is a mapping from the space of random events  in
in  )
) Here's what a fairly simple implementation of variation on Haskell will look like:
-- | 'totalVariation' calculates total variation of the sample process X(t)
totalVariation :: [Double] -- process trajectory X(t)
-> Double -- V(X(t))
totalVariation x@(_:tx) = sum $ zipWith (\x xm1 -> abs $ x - xm1) tx x
Where in the real world do random processes occur? One of the most famous examples today is financial markets, namely the movement of prices for currencies, stocks, options and various securities. Let it
Is the value of an Apple share. At some point in time you decide to buy stock price
stock price  , and after a certain period of time the price changed and became equal to
, and after a certain period of time the price changed and became equal to  . As a result you
. As a result you net profit / loss, where
net profit / loss, where  . You decided to buy / sell part of the shares and now you are holding
. You decided to buy / sell part of the shares and now you are holding valuable papers. After some time, your income / loss will amount to
valuable papers. After some time, your income / loss will amount to , etc. In the end, you will earn / lose
, etc. In the end, you will earn / lose
 The problem is that we do not yet know how to take integrals over random processes and their trajectories. But we remember by what principle the standard Lebesgue integral (-Stieltjes) is determined. Usually, you first need to set the appropriate measure. Take a non-decreasing process, for simplicity, starting from scratch:
The problem is that we do not yet know how to take integrals over random processes and their trajectories. But we remember by what principle the standard Lebesgue integral (-Stieltjes) is determined. Usually, you first need to set the appropriate measure. Take a non-decreasing process, for simplicity, starting from scratch:  , and a non-negative measure corresponding to its increments
, and a non-negative measure corresponding to its increments![$ \ mu_X (a, b]: = X (b) -X (a). $](https://habrastorage.org/getpro/habr/formulas/ecc/681/731/ecc6817310fd452e5487602c4688adf6.svg)
limited and measurable (recall the functional analysis), we can determine the integral for it on the interval ![$ [0, T] $](https://habrastorage.org/getpro/habr/formulas/95b/70a/428/95b70a428ee561bcdf9d705d448e72ef.svg) as
as ![$ \ int_0 ^ T f (t) dX (t) = \ int _ {[0, T]} f (t) \ mu_X (dt). $](https://habrastorage.org/getpro/habr/formulas/8fc/16c/8c0/8fc16c8c08f8247dcf50d413d9c93cb0.svg)
 and then we define the Lebesgue integral as
and then we define the Lebesgue integral as ![$ \ int_0 ^ T f (t) dX (t) = \ int _ {[0, T]} f (t) \ mu_ {X ^ +} (dt) - \ int _ {[0, T]} f (t ) \ mu_ {X ^ -} (dt). $](https://habrastorage.org/getpro/habr/formulas/1a6/d93/243/1a6d932433e94708a2222c8fab755ada.svg)
![$ V _ {[0, T]} ^ X $](https://habrastorage.org/getpro/habr/formulas/7ce/1f2/c8e/7ce1f2c8e66d224d03df7b9a57690e2e.svg) . Indeed, if our process consists of the difference of two non-decreasing processes, then it has a finite variation (in the second line we used the triangle inequality):
. Indeed, if our process consists of the difference of two non-decreasing processes, then it has a finite variation (in the second line we used the triangle inequality):![$ \ begin {aligned} V _ {[0, T]} ^ X & = \ lim _ {\ | \ Pi \ | \ rightarrow 0} \ sum_ {i = 1} ^ n | X (t_ {i}) - X (t_ {i-1}) | \\ & \ leq \ lim _ {\ | \ Pi \ | \ rightarrow 0} \ Big (\ sum_ {i = 1} ^ n | X ^ + (t_ {i}) - X ^ + (t_ {i-1}) | + \ sum_ {i = 1} ^ n | X ^ - (t_ {i}) - X ^ - (t_ {i-1}) | \ Big) \\ & = X ^ + (T) + X ^ - (T) <\ infty. \ end {aligned} $](https://habrastorage.org/getpro/habr/formulas/f61/012/242/f610122421a040730562b452b61fd828.svg)
with finite variation, then we can determine  and
and  . Monotony and equality
. Monotony and equality easy to prove.
easy to prove. Now we can easily integrate something. Take the trajectory of some continuous random process and call it
 . Using the Lagrange mean theorem, we can show that for a continuous function the variation will be equal
. Using the Lagrange mean theorem, we can show that for a continuous function the variation will be equal ![$ V _ {[0, T]} ^ g = \ int_0 ^ T | g '(t) | dt $](https://habrastorage.org/getpro/habr/formulas/fdd/bda/701/fddbda70104e00c5b0c75460fc850b4b.svg) . If this integral exists, then under the conditions of boundedness and measurability mentioned above we can count
. If this integral exists, then under the conditions of boundedness and measurability mentioned above we can count 
 .
.
So the question is: is it possible to take the integral in the sense of Lebesgue from the Brownian motion? We calculate the variation, and if it is finite, then we should not have any problems. Let's go from the side of the so-called quadratic variation :
![$ [B] (T) = \ lim _ {\ | \ Pi \ | \ rightarrow 0} \ sum_ {i = 1} ^ n \ big (B (t_ {i + 1}) - B (t_i) \ big) ^ 2 $](https://habrastorage.org/getpro/habr/formulas/b91/6ec/675/b916ec6756a81474275f5da0c2617453.svg)
![$ [B] (T) -T $](https://habrastorage.org/getpro/habr/formulas/f03/bb6/ddf/f03bb6ddf7354e3050fb72896e45d61a.svg) and show that its dispersion is zero:
and show that its dispersion is zero: 

 are independent and have a chi-square distribution with degree 1, it is easy to calculate that
are independent and have a chi-square distribution with degree 1, it is easy to calculate that ![$\mathbb{E}[(Z_i^2-1)^2]=\operatorname{Var}(Z_i^2)=2.$](https://habrastorage.org/getpro/habr/formulas/308/3ae/f51/3083aef5127971c23d44324c740985c0.svg)
![$\begin{aligned} \mathbb{E}\bigg[\Big( \sum_{i=1}^n \big(B(t_{i+1})-B(t_i)\big)^2 -T\Big)^2\bigg]&=\sum_{i=1}^n \mathbb{E}[(Z_i^2-1)^2(t_{i+1}-t_i)^2]\\ &=2\sum_{i=1}^n (t_{i+1}-t_i)^2 \\ & \leq \| \Pi \| \cdot 2\sum_{i=1}^n (t_{i+1}-t_i) \rightarrow 0. \end{aligned}$](https://habrastorage.org/getpro/habr/formulas/606/087/e68/606087e681f74de3ed70714f0fed8ef7.svg)
 = T.$](https://habrastorage.org/getpro/habr/formulas/ae6/bfa/2dc/ae6bfa2dc3740f8f295b69f3f2293166.svg)
Note that
 = \operatorname{Var}(B(T))$](https://habrastorage.org/getpro/habr/formulas/e99/a52/26f/e99a5226fb3ce1a34722575132f78f2d.svg) However, the methods for calculating these two quantities are completely different. The variance of the Brownian motion is considered to be the averaging of all its trajectories, given their probabilities. The quadratic variation is taken from one single random trajectory along which the movement occurred, and the probabilities do not play a role here. While the variance can only be calculated theoretically, since it requires averaging of all implementations, the quadratic implementation can be calculated explicitly (with a sufficient data discretization). The above formula is interesting in particular in that, by definition, a quadratic variation, like a variation of the first kindis a random variable. However, the feature of Brownian motion is that its quadratic variation degenerates and assumes only one single value, corresponding to the length of the interval, regardless of which trajectory the movement took.
However, the methods for calculating these two quantities are completely different. The variance of the Brownian motion is considered to be the averaging of all its trajectories, given their probabilities. The quadratic variation is taken from one single random trajectory along which the movement occurred, and the probabilities do not play a role here. While the variance can only be calculated theoretically, since it requires averaging of all implementations, the quadratic implementation can be calculated explicitly (with a sufficient data discretization). The above formula is interesting in particular in that, by definition, a quadratic variation, like a variation of the first kindis a random variable. However, the feature of Brownian motion is that its quadratic variation degenerates and assumes only one single value, corresponding to the length of the interval, regardless of which trajectory the movement took. Let's write a code that considers the quadratic variation of the implementation of a random process
:-- | 'quadraticVariation' calculates quadratic variation of the sample process X(t)
quadraticVariation :: [Double] -- process trajectory X(t)
-> Double -- [X(t)]
quadraticVariation x@(_:tx) = sum $ zipWith (\x xm1 -> (x - xm1) ^ 2) tx x
So, now we are ready to return to calculating the variation of interest to us
![$V_{[0,T]}^B$](https://habrastorage.org/getpro/habr/formulas/17f/b95/24a/17fb9524a952693414f6c5bc1a947520.svg) . We found out that
. We found out that
: 
We know that Brownian motion is a continuous process, which means

![$\sum_{i=1}^n | B(t_{i+1}) - B(t_i) | \rightarrow V_{[0,T]}^B.$](https://habrastorage.org/getpro/habr/formulas/44a/879/82e/44a87982e5cd8ea17491beaf50ab6faf.svg) And as a consequence,
And as a consequence, ![$V_{[0,T]}^B = \infty.$](https://habrastorage.org/getpro/habr/formulas/4df/859/f9f/4df859f9f53f285e02f970d9e6df74d6.svg)
Oh yeah ...

Ito Integral or New Hope
In 1827, the English botanist Robert Brown, observing pollen grains in water through a microscope, noticed that the particles inside their cavity move in a certain way; however, he was then unable to identify the mechanisms that caused this movement. In 1905, Albert Einstein published an article explaining in detail how the movement observed by Brown was the result of pollen moving by individual water molecules. In 1923, the child prodigy and “father of cybernetics,” Norbert Wiener, wrote an article on differentiable spaces, where he approached this movement from the side of mathematics, determined probability measures in the space of trajectories and, using the concept of Lebesgue integrals, laid the foundation for stochastic analysis. Since then, in the mathematical community, the Brownian motion is also called the Wiener process.
In 1938, a graduate of Tokyo University Kiyoshi Ito begins to work in the Bureau of Statistics, where in his free time he gets acquainted with the work of the founder of modern probability theory, Andrei Kolmogorov, and the French scientist Paul Levy, who was studying at that time various properties of the Brownian movement. He tries to combine Levy’s intuitive visions with Kolmogorov’s exact logic, and in 1942 he wrote “On Stochastic Processes and Infinitely Divisible Distribution Laws,” in which he reconstructs from scratch the concept of stochastic integrals and the associated theory of stochastic differential equations describing the motions caused by random events.
Ito integral for simple processes
Ito developed a fairly simple way to build an integral. First, we define the Ito integral for a simple piecewise constant process
 and then we extend this concept to more complex integrands. So let us have a split again
and then we extend this concept to more complex integrands. So let us have a split again . We believe that the values constant at each interval
. We believe that the values constant at each interval 

Imagine that
Is the value of a financial instrument at the time (Brownian movement can take negative values, so this is not a good model for price movement, but now we will ignore it). Let also - these are trading days (hours / seconds, it doesn’t matter), and
- these are trading days (hours / seconds, it doesn’t matter), and  - this is our position (the number of financial instruments on hand). We believe that depends only on information known at the time . By information, I mean the trajectory of the Brownian motion up to this point in time. Then our income will be:
- this is our position (the number of financial instruments on hand). We believe that depends only on information known at the time . By information, I mean the trajectory of the Brownian motion up to this point in time. Then our income will be:![$I(t) = \sum_{j=0}^k \Delta(t_j) [B(t_{j+1}-B(t_j)] + \Delta(t_k)[B(t)-B(t_k)].$](https://habrastorage.org/getpro/habr/formulas/6e1/75c/63a/6e175c63a7f492d1bd15857e155766a7.svg)
 called ito integral for a simple process and we will write it in the form
called ito integral for a simple process and we will write it in the form 
This integral has several interesting properties. The first and rather obvious: at the initial moment, its mathematical expectation at any point is zero:
![$\mathbb{E}[I(t)] = 0.$](https://habrastorage.org/getpro/habr/formulas/ff2/da2/457/ff2da24577302eda98e1c5253f4ac582.svg)
The calculation of the second moment / variance already requires additional calculations. Let it
 for
for  and
and  . Then we can rewrite the Ito integral in the form
. Then we can rewrite the Ito integral in the form
![$\mathbb{E}[D_j]=0$](https://habrastorage.org/getpro/habr/formulas/b49/eaf/3aa/b49eaf3aa99fd28733fa4625a64d473a.svg) and the fact that
and the fact that  and
and  independent for
independent for  we can calculate
we can calculate ![$\begin{aligned} \mathbb{E}[I^2(t)] &=\mathbb{E}\Big[ \sum_{j=0}^k \Delta^2(t_j)D_j^2 + 2\sum_{0 \leq i < j \leq k}\Delta(t_i)\Delta(t_j) D_iD_j\Big] \\ &= \sum_{j=0}^k \mathbb{E}\Big[ \Delta^2(t_j) D_j^2 \Big] + 2 \sum_{0 \leq i < j \leq k} \mathbb{E}[\Delta(t_i)\Delta(t_j) D_iD_j] \\ &= \sum_{j=0}^k \mathbb{E}\Big[ \Delta^2(t_j) \Big] \cdot \mathbb{E}[D_j^2] + 2 \sum_{0 \leq i < j \leq k} \mathbb{E}[\Delta(t_i)\Delta(t_j) D_i] \cdot \mathbb{E}[D_j] \\ &= \sum_{j=0}^{k-1} \mathbb{E}\Big[ \Delta^2(t_j) \Big] (t_{j+1}-t_j) + \mathbb{E}[\Delta^2(t_k)](t-t_k) \\ &= \sum_{j=0}^k \mathbb{E} \Big[\int_{t_j}^{t_{j+1}} \Delta^2(s) ds\Big] + \mathbb{E} \Big[ \int_{t_k}^t \Delta^2(s)ds \Big] \\ &=\mathbb{E} \Big[ \int_{0}^t \Delta^2(s)ds \Big]. \end{aligned}$](https://habrastorage.org/getpro/habr/formulas/715/262/3be/7152623be23b3553a46f9c7913b03724.svg)
![$\mathbb{E}[I^2(t)] = \mathbb{E}\Big[\int_0^t \Delta^2(s)ds \Big]$](https://habrastorage.org/getpro/habr/formulas/92b/65a/e18/92b65ae180c53a9ee0dfa7138238bd84.svg)
And finally, a quadratic variation. Let's first calculate the variation on each interval
![$[t_j, t_{j+1}]$](https://habrastorage.org/getpro/habr/formulas/157/303/e3d/157303e3db831f0e49622839e3386e0b.svg) where the values are constant, and then we put them all together. Take a partitioning interval
where the values are constant, and then we put them all together. Take a partitioning interval and consider
and consider ![$\begin{aligned} \sum_{i=0}^{m-1} [I(s_{i+1}) - I(s_i)]^2 &= \sum_{i=0}^{m-1}[\Delta(t_j)(B(s_{i+1})-B(s_i))^2 \\ &=\Delta^2(t_j) \sum_{t=0}^{m-1} (B(s_{i+1})-B(s_i))^2 \\ &\xrightarrow[m \rightarrow \infty]{} \Delta^2(t_j)(t_{j+1}-t_j) \\ &=\int_{t_j}^{t_{j+1}}\Delta^2(s)ds. \end{aligned}$](https://habrastorage.org/getpro/habr/formulas/7d5/bc2/6fb/7d5bc26fb63f7848e38c29f8cad8c9d9.svg)
![$[t_k, t]$](https://habrastorage.org/getpro/habr/formulas/744/931/9f3/7449319f38b3832634d27b566019b2fc.svg) . Summing up all these pieces, we get
. Summing up all these pieces, we get![$[I(t)]=\int_0^t \Delta^2(s)ds.$](https://habrastorage.org/getpro/habr/formulas/0ad/6b8/ce8/0ad6b8ce88aee41746a221f52b68fddb.svg)
Now we can clearly see the difference between dispersion and variation. If the process
is determinate then they match. But if we decide to change our strategy depending on the trajectory along which the Brownian motion has passed, then the variation will begin to change, while the variance is always equal to a certain value.Ito integral for complex processes
Now we are ready to expand the concept of the Ito integral to more complex processes. Let us have a function
 , which can continuously change over time and even have gaps. The only assumptions we want to keep are the quadratic process integrability:
, which can continuously change over time and even have gaps. The only assumptions we want to keep are the quadratic process integrability:![$\mathbb{E}\Big[ \int_0^T h^2(t)dt \Big] < \infty$](https://habrastorage.org/getpro/habr/formulas/eac/32b/199/eac32b199281d73c2f0e1b84a85ea89a.svg)
when we know the meaning we should already know the meaning . In the real world, we cannot first find out the value of shares for tomorrow, and then invest in them. In order to determine
 we approximate simple processes. The graph below shows how this can be done.
we approximate simple processes. The graph below shows how this can be done.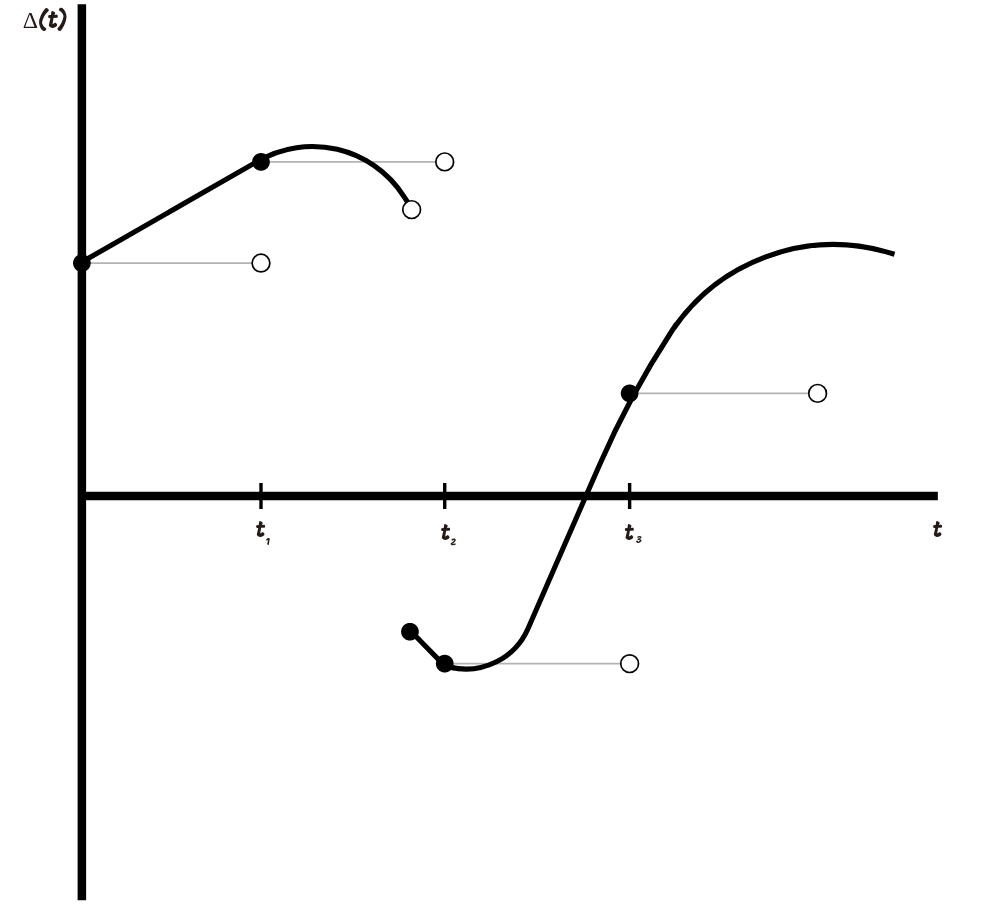
The approximation is as follows: we choose a partition
 , then create a simple process whose values are equal
, then create a simple process whose values are equal  for everybody
for everybody  and do not change on the segment . The smaller the maximum step of our partition becomes, the closer the approximating simple process becomes to our integrand.
and do not change on the segment . The smaller the maximum step of our partition becomes, the closer the approximating simple process becomes to our integrand. In general, it is possible to choose a sequence of simple processes
 such that it will converge to . By convergence we mean
such that it will converge to . By convergence we mean![$\lim_{n \rightarrow \infty} \mathbb{E}\Big[ \int_0^T |h_n(t)-h(t)|^2 dt \Big] = 0.$](https://habrastorage.org/getpro/habr/formulas/dee/5f7/262/dee5f726244da318d77d385d7ff1c559.svg)
Ito integral is already defined and we define the Ito integral for a continuously changing process as a limit: 
- Its trajectories are continuous
- It is adapted. It is logical, because at every moment of time we must know our value of income.
- It is linear:

- He is a martingale, but more on that near the end of the article.
- Iso Itometry saved:
![$\mathbb{E}[I^2(t)] = \mathbb{E}\Big[\int_0^t h^2(s)ds \Big]$](https://habrastorage.org/getpro/habr/formulas/3b4/a51/d58/3b4a51d585684780d6315dab11ea0b3b.svg) .
. - Its quadratic variation:
![$[I(t)]=\int_0^th^2(s)ds.$](https://habrastorage.org/getpro/habr/formulas/0e9/b83/20e/0e9b8320e9fb9a7f29dddc57201c77fa.svg)
A small remark: for those who want to study the construction of the Ito integral in more detail or are generally interested in financial mathematics, I highly recommend Steven Shreve's book “Stochastic Calculus for Finance. Volume II ".
Let's go?
For the following reasoning, we will denote the Itô integral in a slightly different form:

 . Thus, we prepare ourselves for the idea that the Itô integral is a map acting from the space of quadratically integrable functions
. Thus, we prepare ourselves for the idea that the Itô integral is a map acting from the space of quadratically integrable functions![$L^2([0,T])$](https://habrastorage.org/getpro/habr/formulas/6c0/d96/b56/6c0d96b562d716a3fa0a83690b6aff4e.svg) into the probability space of random processes. So for example, you can go from the old notation to the new one:
into the probability space of random processes. So for example, you can go from the old notation to the new one:![$I(t) = \int_0^T h(s) \cdot 1_{[0,t]}(s)ds = I(h \cdot 1_{[0,t]}).$](https://habrastorage.org/getpro/habr/formulas/b97/d0a/c74/b97d0ac74898cbacc05a6f2a78fe4f15.svg)
In the previous article, we implemented the Gaussian process:
 . We know that a Gaussian process is a mapping from a Hilbert space to a probability one, which is essentially a generalized case of the Ito integral, a mapping from a space of functions to a space of random processes. Really,
. We know that a Gaussian process is a mapping from a Hilbert space to a probability one, which is essentially a generalized case of the Ito integral, a mapping from a space of functions to a space of random processes. Really,data L2Map = L2Map {norm_l2 :: Double -> Double}
type ItoIntegral = Seed -- ω, random state
-> Int -- n, sample size
-> Double -- T, end of the time interval
-> L2Map -- h, L2-function
-> [Double] -- list of values sampled from Ito integral
-- | 'itoIntegral'' trajectory of Ito integral on the time interval [0, T]
itoIntegral' :: ItoIntegral
itoIntegral' seed n endT h = 0 : (toList $ gp !! 0)
where gp = gaussianProcess seed 1 (n-1) (\(i, j) -> norm_l2 h $ fromIntegral (min i j + 1) * t)
t = endT / fromIntegral n
The itoIntegral function ' takes seed as an input - a parameter for a random generator, n - the dimension of the output vector, endT - parameter
and the function h from the L2Map class, for which the norm_l2 function is defined , which returns the norm of the integrand: . At the output, itoIntegral issues an implementation of the Ito integral on the intervalwith a sampling rate corresponding to parameter n . Naturally, a similar way of implementing the Ito integral is in some sense an overkill, but it allows you to tune in to the functional thinking that is so necessary for further reasoning. We will write a faster implementation that does not require work with giant matrices.
. At the output, itoIntegral issues an implementation of the Ito integral on the intervalwith a sampling rate corresponding to parameter n . Naturally, a similar way of implementing the Ito integral is in some sense an overkill, but it allows you to tune in to the functional thinking that is so necessary for further reasoning. We will write a faster implementation that does not require work with giant matrices.-- | 'mapOverInterval' map function f over the interval [0, T]
mapOverInterval :: (Fractional a) => Int -- n, size of the output list
-> a -- T, end of the time interval
-> (a -> b) -- f, function that maps from fractional numbers to some abstract space
-> [b] -- list of values f(t), t \in [0, T]
mapOverInterval n endT fn = [fn $ (endT * fromIntegral i) / fromIntegral (n - 1) | i <- [0..(n-1)]]
-- | 'itoIntegral' faster implementation of itoIntegral' function
itoIntegral :: ItoIntegral
itoIntegral seed 0 _ _ = []
itoIntegral seed n endT h = scanl (+) 0 increments
where increments = toList $ (sigmas hnorms) * gaussianVector
gaussianVector = flatten $ gaussianSample seed (n-1) (vector [0]) (H.sym $ matrix 1 [1])
sigmas s@(_:ts) = fromList $ zipWith (\x y -> sqrt(x-y)) ts s
hnorms = mapOverInterval n endT $ norm_l2 h
Now, using this function, we can implement, for example, the ordinary Brownian motion:
 . The function h is a function, in which the norm norm_l2 will
. The function h is a function, in which the norm norm_l2 will , identical function.
, identical function.l2_1 = L2Map {norm_l2 = id}
-- | 'brownianMotion' trajectory of Brownian motion a.k.a. Wiener process on the time interval [0, T]
brownianMotion :: Seed -- ω, random state
-> Int -- n, sample size
-> Double -- T, end of the time interval
-> [Double] -- list of values sampled from Brownian motion
brownianMotion seed n endT = itoIntegral seed n endT l2_1
Let's try to draw different options for the trajectories of Brownian motion
import Graphics.Plot
let endT = 1
let n = 500
let b1 = brownianMotion 1 n endT
let b2 = brownianMotion 2 n endT
let b3 = brownianMotion 3 n endT
mplot [linspace n (0, lastT), b1, b2, b3]

It's time to double-check our previous calculations. Let's calculate the variation of the Brownian motion trajectory on the interval
![$[0, 1]$](https://habrastorage.org/getpro/habr/formulas/a5d/538/f83/a5d538f83bd73f9d1c9e8338db9a398a.svg) .
.Prelude> totalVariation (brownianMotion 1 100 1)
8.167687948236862
Prelude> totalVariation (brownianMotion 1 10000 1)
80.5450335433388
Prelude> totalVariation (brownianMotion 1 1000000 1)
798.2689137110999
We can observe that with increasing accuracy, the variation takes on larger and larger values, while the quadratic variation tends to
 :
:Prelude> quadraticVariation (brownianMotion 1 100 1)
0.9984487348804609
Prelude> quadraticVariation (brownianMotion 1 10000 1)
1.0136583395467458
Prelude> quadraticVariation (brownianMotion 1 1000000 1)
1.0010717246843375
Try running the calculation of variations for arbitrary Ito integrals to make sure that
 = \int_0^T h^2(s)ds$](https://habrastorage.org/getpro/habr/formulas/a7d/a57/92c/a7da5792cd2b165c1db81b634d93e4c4.svg) regardless of the trajectory of movement.
regardless of the trajectory of movement.Martingales
There is such a class of random processes - martingales . In order to
was martingale, three conditions must be met:- It is adapted
- almost everywhere of course:
![$\mathbb{E}[|X(t)|] < \infty$](https://habrastorage.org/getpro/habr/formulas/ba3/dcc/24d/ba3dcc24d5aaed3929177e4881e6750a.svg)
- Conditional mathematical expectation of the future value equals its last known value:
![$\mathbb{E}[X(T)|X(t)] = X(t), \quad t < T.$](https://habrastorage.org/getpro/habr/formulas/e13/ccc/59f/e13ccc59f06832e5e57bc4d815241c95.svg)
Brownian movement - martingale. The fulfillment of the first condition is obvious, the fulfillment of the second condition follows from the properties of the normal distribution. The third condition is also easily verified:
![$\mathbb{E}[B(T)|B(t)] = \mathbb{E}[(B(T)-B(t)) + B(t)|B(t)] = B(t).$](https://habrastorage.org/getpro/habr/formulas/f2c/8e4/6e8/f2c8e46e8bf1981421d9abd0654e6e7f.svg)
- this is our strategy, the number of shares in our portfolio. Process may be random: we do not always know very much in advance how many stocks we want to keep, we will proceed from the price movement . But the main thing is that this process be adapted, that is, at the timewe know exactly how many stocks we have. We cannot return to the past and change this meaning. So, since the Ito integral is a martingale, it doesn’t matter which strategy we choose, on average, the gain from our trade will always go to zero. There is another interesting theorem, the so-called martingale representation theorem : if we have a martingale
 whose values are determined by the Brownian movement, that is, the only process that introduces uncertainty into the values , - this is then this martingale can be represented as
whose values are determined by the Brownian movement, that is, the only process that introduces uncertainty into the values , - this is then this martingale can be represented as 
 the only one. In the future, when we increase the number of integrals and even extend them to non-adapted processes, this theorem will help us a lot.
the only one. In the future, when we increase the number of integrals and even extend them to non-adapted processes, this theorem will help us a lot. And that's all for today.

Only registered users can participate in the survey. Please come in.
Is it worth it to talk about the Ito-Deblin lemma?
- 95% Yes, definitely worth it! 95
- 5% No, this is not Habr 5 format