New Year dataset 2018: open semantics of the Russian language
The open semantics of the Russian language, about the history of the creation of which you can read here and here , received a big update. We collected enough data to apply machine learning on top of the collected markup and build a semantic language model. What came out of this look under the cut.

Take two groups of words:
It is not difficult for a person to determine that the first group contains nouns that call actions or events ; in the second - calling people . Our goal is to teach the machine to solve such problems.
For this you need:
The result of the work published in the repository on the GC and available for download is a description of the class hierarchy and markup (manual and automatic) of nouns by these classes.
For acquaintance to dataset it is possible to use the interactive navigator (the link in a repository). There is also a simplified version of the set in which we removed the entire hierarchy and assigned each word one single major semantic tag: “people”, “animals”, “places”, “things”, “actions”, etc.
Link to GitHab: open semantics of the Russian language (dataset) .
In classification problems, the classes themselves are often dictated by the problem being solved, and the work of the data engineer comes down to finding a successful set of features, over which you can build a working model.
In our problem, classes of words, strictly speaking, are not known in advance. Here a large amount of research on semantics done by domestic and foreign linguistic scholars, familiarity with existing semantic dictionaries and WordNet comes to the rescue.
This is a good help, but the final decision is already formed within our own research. The point here is this. Many semantic resources began to be created in the precomputer era (at least in the modern understanding of computer) and the choice of classes was largely dictated by the language intuition of their creators. At the end of the previous century, WordNet's found active use in automatic text analysis tasks, and many of the newly created resources were sharpened for specific practical applications.
The result was that these language resources simultaneously contain both linguistic and extra-lingual, encyclopedic information about language units. It is logical to assume that it is impossible to build a model that would test extra-linguistic information based only on statistical analysis of the texts, because the data source simply does not contain the necessary information.
Based on this assumption, we are looking only for natural classes that can be detected and automatically verified based on a purely linguistic model. At the same time, the system architecture allows the addition of an arbitrarily large number of additional layers of information about language units, which may be useful in practical applications.
Let's demonstrate the above with a concrete example, having analyzed the word “refrigerator”. From the linguistic model, we can find out that a “refrigerator” is a material object, a construction, is a container of the “box or bag” type, i.e. not suitable for storing liquids or bulk solids without additional capacity. At the same time, it is not clear from this model that the “refrigerator” is a commodity, and a durable product, and it is also unclear that this is an artifact, i.e. man-made object. This is extra-language information that must be supplied separately.
Be that as it may, a person, in the process of learning and cognition of reality, strung additional information about the objects and phenomena around him onto the natural frame he had learned in childhood. However, some concepts are universal, independent of the subject area, and can be successfully reused.
Say "seller" is a person + functional role. In some cases, the seller may be a group of people or an organization, but at the same time subjectivity is always preserved: otherwise, the performance of the target action will be impossible. The words “sharing” or “learning” refer to actions, i.e. they have participants, duration and result. The exact content of these actions may vary considerably depending on the situation and subject area, but certain aspects will be an invariant. This is the linguistic framework on which the variable extra-linguistic knowledge is layered.
Our goal is to find and explore the maximum of available intralingual information and build on its basis an explanatory language model. This will improve the existing algorithms for automatic text processing, including such complex ones as resolution of lexical ambiguity, resolution of anaphor, complex cases of morphological marking. In the process, we will definitely rest on the need to attract extra-linguistic knowledge, but at least we will know where that border is when the internal knowledge of the language is no longer enough.
So far we are working only with nouns, therefore, below, saying “word”, we will mean signs relating only to this part of speech. Since we decided to use only intra-linguistic information, we will work with texts with morphological markup.
As signs let's take all possible microcontexts in which this word occurs. For nouns, these will be:
There are more types of microcontexts, but the above are the most frequent and already give a good result when learning.
All microcontexts are reduced to the basic form and make up a set of features from them. Next, for each word we compose a vector, the i-th coordinate of which will correlate with the occurrence of the given word in the i-th microcontext.
A language has natural mechanisms for re-using words, which causes such a phenomenon as polysemy. However, sometimes not just individual words are reused, but a metaphorical transfer of whole concepts is done. This is especially noticeable in the transition from real concepts to abstract ones.
This fact dictates the need for a hierarchical classification, in which semantic sections are arranged in a tree structure and splitting occurs in each internal node. This makes it much more efficient to cope with ambiguity in microcontext.
As an algorithm, we used logistic regression. This is due to several factors:
The algorithm demonstrated quite good accuracy:
Errors arising from the automatic classification are due to three main factors:
At this stage, we pay attention only to errors of the third type and correct the selected boundary between the classes. Errors of the first two types in a given system configuration are unavoidable, but with sufficient volume of labeled data they do not pose a big problem - this can be seen from the accuracy of the layout of the upper projections.
At the moment, dataset covers most of the nouns that exist in the Russian language and are presented in the corpus in a sufficient variety of contexts. The main focus was on real objects - as the most understandable and developed in scientific works. The remaining tasks are to refine the existing markup, taking into account the data obtained from the algorithm, and work with classes on the lower tiers, where there is a drop in the prediction accuracy due to the blurring of boundaries between categories.
But this is a kind of routine work, which is always there. A qualitatively new layer of research will deal with the possibility of classifying a word in a particular context or sentence, which will take into account the phenomena of homonymy and polysemy, including metaphor (figurative meanings).
We also have several related projects in our work:
The tonal dictionary is the words and expressions of OC, marked by the tonality and intensity of the emotional-evaluative charge. Simply put, how a word is "bad" or "good."
Currently 67.392 characters are marked (55.532 words out of them and 11.860 expressions).
We welcome any feedback in the comments - from criticism of the work and the approaches we have chosen to links to interesting research and articles on the topic.
If you have friends or colleagues who may be interested in a published dataset, send them a link to the article or repository to help distribute open data.
Dataset: open semantics of the Russian language
Dataset is distributed under the license CC BY-NC-SA 4.0 .
What are we doing
Take two groups of words:
- running, shooting, drawing, walking, walking;
- runner, photographer, engineer, tourist, athlete.
It is not difficult for a person to determine that the first group contains nouns that call actions or events ; in the second - calling people . Our goal is to teach the machine to solve such problems.
For this you need:
- Find out which natural classes exist in the language.
- Mark a sufficient number of words for belonging to the classes from p.1 .
- Create an algorithm that learns on the markup from p.2 and reproduces the classification on unfamiliar words.
Can this problem be solved with the help of distributive semantics?
word2vec представляет собой отличный инструмент, но всё же он отдаёт предпочтение тематической близости слов, а не сходству их семантических классов. Для демонстрации этого факта запустим алгоритм на словах из примера:
w1 | w2 | cosine_sim |
| | |
бег | бег | 1.0000 |
бег | бегун | 0.6618 |
бег | ходьба | 0.5410 |
бег | атлет | 0.3389 |
бег | поход | 0.1531 |
бег | съёмка | 0.1342 |
бег | черчение | 0.1067 |
бег | турист | 0.0681 |
бег | инженер | 0.0458 |
бег | фотограф | 0.0373 |
| | |
съёмка | съёмка | 1.0000 |
съёмка | фотограф | 0.5782 |
съёмка | турист | 0.2525 |
съёмка | черчение | 0.2116 |
съёмка | поход | 0.1644 |
съёмка | инженер | 0.1579 |
съёмка | бег | 0.1342 |
съёмка | бегун | 0.1275 |
съёмка | ходьба | 0.1100 |
съёмка | атлет | 0.0975 |
| | |
черчение | черчение | 1.0000 |
черчение | инженер | 0.3575 |
черчение | съёмка | 0.2116 |
черчение | фотограф | 0.1587 |
черчение | ходьба | 0.1207 |
черчение | бег | 0.1067 |
черчение | атлет | 0.0889 |
черчение | поход | 0.0794 |
черчение | бегун | 0.0705 |
черчение | турист | 0.0430 |
| | |
поход | поход | 1.0000 |
поход | турист | 0.1896 |
поход | ходьба | 0.1753 |
поход | съёмка | 0.1644 |
поход | бегун | 0.1548 |
поход | бег | 0.1531 |
поход | атлет | 0.0889 |
поход | черчение | 0.0794 |
поход | инженер | 0.0568 |
поход | фотограф | -0.0013 |
| | |
ходьба | ходьба | 1.0000 |
ходьба | бег | 0.5410 |
ходьба | бегун | 0.3442 |
ходьба | атлет | 0.2469 |
ходьба | поход | 0.1753 |
ходьба | турист | 0.1650 |
ходьба | черчение | 0.1207 |
ходьба | съёмка | 0.1100 |
ходьба | инженер | 0.0673 |
ходьба | фотограф | 0.0642 |
| | |
бегун | бегун | 1.0000 |
бегун | бег | 0.6618 |
бегун | атлет | 0.4909 |
бегун | ходьба | 0.3442 |
бегун | поход | 0.1548 |
бегун | турист | 0.1427 |
бегун | инженер | 0.1422 |
бегун | съёмка | 0.1275 |
бегун | фотограф | 0.1209 |
бегун | черчение | 0.0705 |
| | |
фотограф | фотограф | 1.0000 |
фотограф | съёмка | 0.5782 |
фотограф | турист | 0.3687 |
фотограф | инженер | 0.2334 |
фотограф | атлет | 0.1911 |
фотограф | черчение | 0.1587 |
фотограф | бегун | 0.1209 |
фотограф | ходьба | 0.0642 |
фотограф | бег | 0.0373 |
фотограф | поход | -0.0013 |
| | |
инженер | инженер | 1.0000 |
инженер | черчение | 0.3575 |
инженер | фотограф | 0.2334 |
инженер | съёмка | 0.1579 |
инженер | турист | 0.1503 |
инженер | атлет | 0.1447 |
инженер | бегун | 0.1422 |
инженер | ходьба | 0.0673 |
инженер | поход | 0.0568 |
инженер | бег | 0.0458 |
| | |
турист | турист | 1.0000 |
турист | фотограф | 0.3687 |
турист | съёмка | 0.2525 |
турист | поход | 0.1896 |
турист | ходьба | 0.1650 |
турист | инженер | 0.1503 |
турист | атлет | 0.1495 |
турист | бегун | 0.1427 |
турист | бег | 0.0681 |
турист | черчение | 0.0430 |
| | |
атлет | атлет | 1.0000 |
атлет | бегун | 0.4909 |
атлет | бег | 0.3389 |
атлет | ходьба | 0.2469 |
атлет | фотограф | 0.1911 |
атлет | турист | 0.1495 |
атлет | инженер | 0.1447 |
атлет | съёмка | 0.0975 |
атлет | поход | 0.0889 |
атлет | черчение | 0.0889 |How this problem is solved by open semantics
Поиск по семантическому словарю даёт следующий результат:
слово | семантический тег |
| |
бег | ABSTRACT:ACTION |
съёмка | ABSTRACT:ACTION |
черчение | ABSTRACT:ACTION |
поход | ABSTRACT:ACTION |
ходьба | ABSTRACT:ACTION |
бегун | HUMAN |
фотограф | HUMAN |
инженер | HUMAN |
турист | HUMAN |
атлет | HUMAN |What has been done and where to download
The result of the work published in the repository on the GC and available for download is a description of the class hierarchy and markup (manual and automatic) of nouns by these classes.
For acquaintance to dataset it is possible to use the interactive navigator (the link in a repository). There is also a simplified version of the set in which we removed the entire hierarchy and assigned each word one single major semantic tag: “people”, “animals”, “places”, “things”, “actions”, etc.
Link to GitHab: open semantics of the Russian language (dataset) .
About classes of words
In classification problems, the classes themselves are often dictated by the problem being solved, and the work of the data engineer comes down to finding a successful set of features, over which you can build a working model.
In our problem, classes of words, strictly speaking, are not known in advance. Here a large amount of research on semantics done by domestic and foreign linguistic scholars, familiarity with existing semantic dictionaries and WordNet comes to the rescue.
This is a good help, but the final decision is already formed within our own research. The point here is this. Many semantic resources began to be created in the precomputer era (at least in the modern understanding of computer) and the choice of classes was largely dictated by the language intuition of their creators. At the end of the previous century, WordNet's found active use in automatic text analysis tasks, and many of the newly created resources were sharpened for specific practical applications.
The result was that these language resources simultaneously contain both linguistic and extra-lingual, encyclopedic information about language units. It is logical to assume that it is impossible to build a model that would test extra-linguistic information based only on statistical analysis of the texts, because the data source simply does not contain the necessary information.
Based on this assumption, we are looking only for natural classes that can be detected and automatically verified based on a purely linguistic model. At the same time, the system architecture allows the addition of an arbitrarily large number of additional layers of information about language units, which may be useful in practical applications.
Let's demonstrate the above with a concrete example, having analyzed the word “refrigerator”. From the linguistic model, we can find out that a “refrigerator” is a material object, a construction, is a container of the “box or bag” type, i.e. not suitable for storing liquids or bulk solids without additional capacity. At the same time, it is not clear from this model that the “refrigerator” is a commodity, and a durable product, and it is also unclear that this is an artifact, i.e. man-made object. This is extra-language information that must be supplied separately.
The result of the model for the word "refrigerator"
Why is all this necessary
Be that as it may, a person, in the process of learning and cognition of reality, strung additional information about the objects and phenomena around him onto the natural frame he had learned in childhood. However, some concepts are universal, independent of the subject area, and can be successfully reused.
Say "seller" is a person + functional role. In some cases, the seller may be a group of people or an organization, but at the same time subjectivity is always preserved: otherwise, the performance of the target action will be impossible. The words “sharing” or “learning” refer to actions, i.e. they have participants, duration and result. The exact content of these actions may vary considerably depending on the situation and subject area, but certain aspects will be an invariant. This is the linguistic framework on which the variable extra-linguistic knowledge is layered.
Our goal is to find and explore the maximum of available intralingual information and build on its basis an explanatory language model. This will improve the existing algorithms for automatic text processing, including such complex ones as resolution of lexical ambiguity, resolution of anaphor, complex cases of morphological marking. In the process, we will definitely rest on the need to attract extra-linguistic knowledge, but at least we will know where that border is when the internal knowledge of the language is no longer enough.
Classification and training, a set of signs
So far we are working only with nouns, therefore, below, saying “word”, we will mean signs relating only to this part of speech. Since we decided to use only intra-linguistic information, we will work with texts with morphological markup.
As signs let's take all possible microcontexts in which this word occurs. For nouns, these will be:
- ADJ + X (beautiful X: eyes)
- GLAUGH + X (Throw X: Thread)
- GLAUGH + PREVIOUS + X (enter X: door)
- X + SUSCH_ROD (X: table edge)
- SUSCH + X_ROD (handle X: sabers)
- X_SUBJECT + GL (X: plot evolves)
There are more types of microcontexts, but the above are the most frequent and already give a good result when learning.
All microcontexts are reduced to the basic form and make up a set of features from them. Next, for each word we compose a vector, the i-th coordinate of which will correlate with the occurrence of the given word in the i-th microcontext.
Table of microcontexts for the word "backpack"
микроконтекст | тип | встречаемость | значение |
| | | |
достать из | VBP_РОД | 3043 | 1.0000 |
тяжёлый | ADJ | 2426 | 0.9717 |
карман | NX_NG | 1438 | 0.9065 |
вытащить из | VBP_РОД | 1415 | 0.9045 |
полезть в | VBP_ВИН_НЕОД | 1300 | 0.8940 |
лямка | NX_NG | 1292 | 0.8932 |
свой | NX_NG | 1259 | 0.8900 |
небольшой | ADJ | 1230 | 0.8871 |
огромный | ADJ | 1116 | 0.8749 |
большой | ADJ | 903 | 0.8485 |
набитый | ADJ | 849 | 0.8408 |
содержимое | NX_NG | 814 | 0.8356 |
походный | ADJ | 795 | 0.8326 |
пустой | ADJ | 794 | 0.8325 |
порыться в | VBP_ПРЕД | 728 | 0.8217 |
тяжеленный | ADJ | 587 | 0.7948 |
школьный | ADJ | 587 | 0.7948 |
положить в | VBP_ВИН_НЕОД | 567 | 0.7905 |
рыться в | VBP_ПРЕД | 549 | 0.7865 |
сунуть в | VBP_ВИН_НЕОД | 538 | 0.7840 |
лежать в | VBP_ПРЕД | 495 | 0.7736 |
вынуть из | VBP_РОД | 484 | 0.7708 |
день | NX_NG | 476 | 0.7687 |
старый | ADJ | 463 | 0.7652 |
тяжесть | NX_NG | 459 | 0.7642 |Target Value, Semantic Slice Hierarchy
A language has natural mechanisms for re-using words, which causes such a phenomenon as polysemy. However, sometimes not just individual words are reused, but a metaphorical transfer of whole concepts is done. This is especially noticeable in the transition from real concepts to abstract ones.
This fact dictates the need for a hierarchical classification, in which semantic sections are arranged in a tree structure and splitting occurs in each internal node. This makes it much more efficient to cope with ambiguity in microcontext.
Examples of metaphorical transfer of concepts
Кроме решения насущных практических задач компьютерной лингвистики, наша работа преследует целью исследование слова и различных языковых явлений. Метафорический перенос концептов из вещественной плоскости в область абстрактного — явление, хорошо известное когнитивным лингвистам. Так, например, одним из ярчайших концептов в материальном мире является класс «контейнер» (в русскоязычной литературе часто именуемый «вместилище»).
Построенная нами модель действует в едином пространстве признаков и позволяет обучаться на вещественных примерах, а предсказания делать в области абстрактного. Это позволяет делать описанный выше перенос. Так, например, следующие слова представляют собой абстрактные контейнеры, что вполне согласуется с интуитивным представлением:

Ещё одним интересным примером может служить перенос концепции «жидкости» в сферу нематериального:
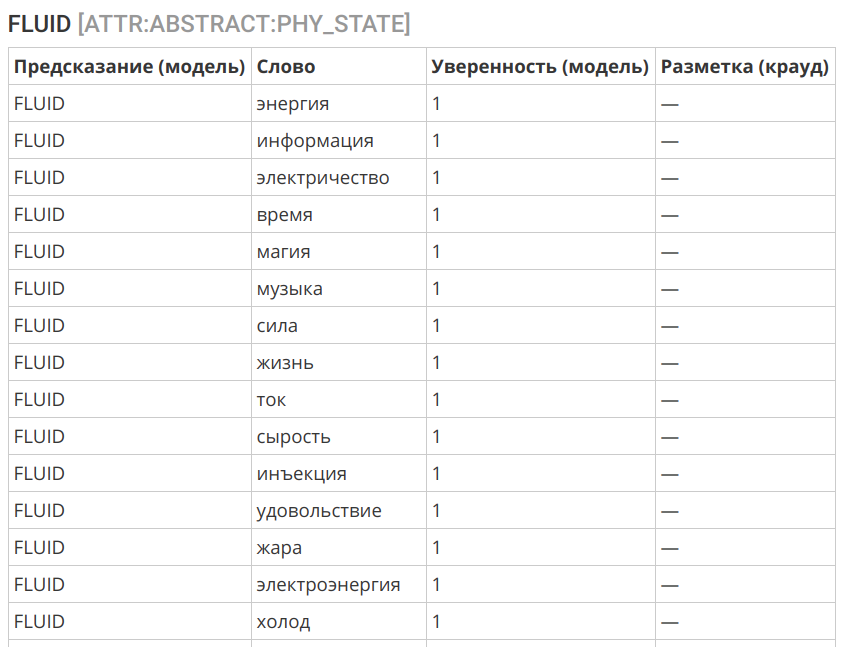
Другая вездесущая онтологическая метафора — это метафора контейнера, или вместилища (container), предполагающая проведение границ в континууме нашего опыта и осмысление его через пространственные категории. По мнению авторов, способ восприятия окружающего мира человеком определяется его опытом обращения с дискретными материальными объектами и в частности его восприятием себя, своего тела. Человек — существо, отграниченное от остального мира кожей. Он — вместилище (container), и потому ему свойственно воспринимать прочие сущности как вместилища с внутренней частью и наружной поверхностью.
Скребцова Т. Г. Когнитивная лингвистика: классические теории, новые
подходы
Построенная нами модель действует в едином пространстве признаков и позволяет обучаться на вещественных примерах, а предсказания делать в области абстрактного. Это позволяет делать описанный выше перенос. Так, например, следующие слова представляют собой абстрактные контейнеры, что вполне согласуется с интуитивным представлением:
Ещё одним интересным примером может служить перенос концепции «жидкости» в сферу нематериального:
Algorithm selection
As an algorithm, we used logistic regression. This is due to several factors:
- The original markup somehow contains a certain amount of errors and noise.
- Signs can be unbalanced and also contain errors - polysemy and metaphorical (figurative) use of the word.
- A preliminary analysis suggests that an adequately selected interface should be fixed by a fairly simple algorithm.
- Important is the good interpretability of the algorithm.
The algorithm demonstrated quite good accuracy:
Logs of the markup algorithm
== ENTITY ==
slice | label | count | correctCount | accuracy |
| | | | |
ENTITY | PHYSICAL | 12249 | 11777 | 0.9615 |
ENTITY | ABSTRACT | 9854 | 9298 | 0.9436 |
| | | | |
| | | | 0.9535 |
== PHYSICAL:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:ROLE | ORGANIC | 7001 | 6525 | 0.9320 |
PHYSICAL:ROLE | INORGANIC | 3805 | 3496 | 0.9188 |
| | | | |
| | | | 0.9274 |
== PHYSICAL:ORGANIC:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:ORGANIC:ROLE | HUMAN | 4879 | 4759 | 0.9754 |
PHYSICAL:ORGANIC:ROLE | ANIMAL | 675 | 629 | 0.9319 |
PHYSICAL:ORGANIC:ROLE | FOOD | 488 | 411 | 0.8422 |
PHYSICAL:ORGANIC:ROLE | ANATOMY | 190 | 154 | 0.8105 |
PHYSICAL:ORGANIC:ROLE | PLANT | 285 | 221 | 0.7754 |
| | | | |
| | | | 0.9474 |
== PHYSICAL:INORGANIC:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:INORGANIC:ROLE | CONSTRUCTION | 1045 | 933 | 0.8928 |
PHYSICAL:INORGANIC:ROLE | THING | 2385 | 2123 | 0.8901 |
PHYSICAL:INORGANIC:ROLE | SUBSTANCE | 399 | 336 | 0.8421 |
| | | | |
| | | | 0.8859 |
== PHYSICAL:CONSTRUCTION:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:CONSTRUCTION:ROLE | TRANSPORT | 188 | 178 | 0.9468 |
PHYSICAL:CONSTRUCTION:ROLE | APARTMENT | 270 | 241 | 0.8926 |
PHYSICAL:CONSTRUCTION:ROLE | TERRAIN | 285 | 253 | 0.8877 |
| | | | |
| | | | 0.9044 |
== PHYSICAL:THING:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:THING:ROLE | WEARABLE | 386 | 357 | 0.9249 |
PHYSICAL:THING:ROLE | TOOLS | 792 | 701 | 0.8851 |
PHYSICAL:THING:ROLE | DISHES | 199 | 174 | 0.8744 |
PHYSICAL:THING:ROLE | MUSIC_INSTRUMENTS | 63 | 51 | 0.8095 |
PHYSICAL:THING:ROLE | WEAPONS | 107 | 69 | 0.6449 |
| | | | |
| | | | 0.8739 |
== PHYSICAL:TOOLS:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
PHYSICAL:TOOLS:ROLE | PHY_INTERACTION | 213 | 190 | 0.8920 |
PHYSICAL:TOOLS:ROLE | INFORMATION | 101 | 71 | 0.7030 |
PHYSICAL:TOOLS:ROLE | EM_ENERGY | 72 | 49 | 0.6806 |
| | | | |
| | | | 0.8031 |
== ATTR:INORGANIC:WEARABLE ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:INORGANIC:WEARABLE | NON_WEARABLE | 538 | 526 | 0.9777 |
ATTR:INORGANIC:WEARABLE | WEARABLE | 282 | 269 | 0.9539 |
| | | | |
| | | | 0.9695 |
== ATTR:PHYSICAL:CONTAINER ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:PHYSICAL:CONTAINER | CONTAINER | 636 | 627 | 0.9858 |
ATTR:PHYSICAL:CONTAINER | NOT_A_CONTAINER | 1225 | 1116 | 0.9110 |
| | | | |
| | | | 0.9366 |
== ATTR:PHYSICAL:CONTAINER:TYPE ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:PHYSICAL:CONTAINER:TYPE | CONFINED_SPACE | 291 | 287 | 0.9863 |
ATTR:PHYSICAL:CONTAINER:TYPE | CONTAINER | 140 | 131 | 0.9357 |
ATTR:PHYSICAL:CONTAINER:TYPE | OPEN_AIR | 72 | 64 | 0.8889 |
ATTR:PHYSICAL:CONTAINER:TYPE | BAG_OR_BOX | 43 | 31 | 0.7209 |
ATTR:PHYSICAL:CONTAINER:TYPE | CAVITY | 30 | 20 | 0.6667 |
| | | | |
| | | | 0.9253 |
== ATTR:PHYSICAL:PHY_STATE ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:PHYSICAL:PHY_STATE | SOLID | 308 | 274 | 0.8896 |
ATTR:PHYSICAL:PHY_STATE | FLUID | 250 | 213 | 0.8520 |
ATTR:PHYSICAL:PHY_STATE | FABRIC | 72 | 51 | 0.7083 |
ATTR:PHYSICAL:PHY_STATE | PLASTIC | 78 | 42 | 0.5385 |
ATTR:PHYSICAL:PHY_STATE | SAND | 70 | 31 | 0.4429 |
| | | | |
| | | | 0.7853 |
== ATTR:PHYSICAL:PLACE ==
slice | label | count | correctCount | accuracy |
| | | | |
ATTR:PHYSICAL:PLACE | NOT_A_PLACE | 855 | 821 | 0.9602 |
ATTR:PHYSICAL:PLACE | PLACE | 954 | 914 | 0.9581 |
| | | | |
| | | | 0.9591 |
== ABSTRACT:ROLE ==
slice | label | count | correctCount | accuracy |
| | | | |
ABSTRACT:ROLE | ACTION | 1497 | 1330 | 0.8884 |
ABSTRACT:ROLE | HUMAN | 473 | 327 | 0.6913 |
ABSTRACT:ROLE | PHYSICS | 257 | 171 | 0.6654 |
ABSTRACT:ROLE | INFORMATION | 222 | 146 | 0.6577 |
ABSTRACT:ROLE | ABSTRACT | 70 | 15 | 0.2143 |
| | | | |
| | | | 0.7896 |Error analysis
Errors arising from the automatic classification are due to three main factors:
- Homonymy and polysemy: the words having the same mark can have a different value (torment a and m have minute, stopping the process and stop as the location ). This also includes metaphorical use of words and metonymy (for example, a door will be classified as a closed space - this is an expected feature of the language).
- Imbalance of contexts of the use of the word. Some organic uses may not be present in the original package, leading to errors in classification.
- Incorrectly selected class boundary. It is possible to draw such boundaries that are not computable from contexts and require the involvement of extra-linguistic knowledge. Here the algorithm will be powerless.
At this stage, we pay attention only to errors of the third type and correct the selected boundary between the classes. Errors of the first two types in a given system configuration are unavoidable, but with sufficient volume of labeled data they do not pose a big problem - this can be seen from the accuracy of the layout of the upper projections.
What's next
At the moment, dataset covers most of the nouns that exist in the Russian language and are presented in the corpus in a sufficient variety of contexts. The main focus was on real objects - as the most understandable and developed in scientific works. The remaining tasks are to refine the existing markup, taking into account the data obtained from the algorithm, and work with classes on the lower tiers, where there is a drop in the prediction accuracy due to the blurring of boundaries between categories.
But this is a kind of routine work, which is always there. A qualitatively new layer of research will deal with the possibility of classifying a word in a particular context or sentence, which will take into account the phenomena of homonymy and polysemy, including metaphor (figurative meanings).
We also have several related projects in our work:
- vocabulary of word recognition: a variation of the frequency dictionary, where the comprehensibility and familiarity of a word is evaluated as a result of crowdsourcing markup, and not calculated by the body of the text.
- open corpus on the resolution of lexical ambiguity: based on the RUSSE 2018 competition, the WSI & D Shared Task held at the Dialog-2018 conference , it became clear that the corps is useful with the removed lexical ambiguity for testing automatic algorithms for disambiguating and clustering word meanings. We will also need this corpus to proceed to the stage of work on open semantics described in the previous paragraph.
Tonal dictionary of the Russian language
The tonal dictionary is the words and expressions of OC, marked by the tonality and intensity of the emotional-evaluative charge. Simply put, how a word is "bad" or "good."
Currently 67.392 characters are marked (55.532 words out of them and 11.860 expressions).
Feedback and distribution of dataset
We welcome any feedback in the comments - from criticism of the work and the approaches we have chosen to links to interesting research and articles on the topic.
If you have friends or colleagues who may be interested in a published dataset, send them a link to the article or repository to help distribute open data.
Download link and license
Dataset: open semantics of the Russian language
Dataset is distributed under the license CC BY-NC-SA 4.0 .